
大规模文本去重研究
2019-04-08 00:46周游贾创辉
现代计算机 2019年6期
周游,贾创辉
(四川大学计算机学院,成都610065)
0 引言
随着大数据时代的到来,数据呈爆炸式的增长,数据信息冗余过载的问题也随之而来,这也成为了个人以及企业比较头疼的一个问题。对于相似重复数据的相关理论和技术的研究,已成为了各界学者研究的热点话题,并取得了一定的成果。相似重复数据清洗的相关技术在论文抄袭检测、垃圾邮件检测、相似重复网页检测等领域都得到了一定程度的应用。而且,相似重复数据清洗技术对检测出的相似重复数据进行清洗,不仅降低了存储系统的消耗,而且优化了存储空间[1]。同时,也有效地减少了存储系统的访问量,提高了其性能。
本文针对相似重复数据检测过程中出现的准确度不高问题,提出了一种相似重复数据的清洗方法,能够提高相似重复数据检测的正确率,可以有效地甄别出相似重复的数据。在对相似检测算法Simhash算法进行了优化的基础上,计算出Simhash签名值,提高了相似重复数据识别的准确率。在大规模数据下,为了使得相似重复数据检测和清洗的效率得到提高,将提出的相似重复数据检测算法和大数据处理平台Spark相结合[2]。提高了数据清洗的速率,能够高效、快速地对相似重复数据进行清洗,为用户挖掘海量数据下的隐藏信息,做好了前期工作。
1 Simhash算法介绍
1.1 算法描述
Simhash算法是一种不同于传统的哈希算法,具有局部敏感性,该算法被Google应用在重复网页的去除工作上。Simhash算法于2007年第一次被三位Google的工程师提出,该算法可以把维度比较高的向量转换为维度比较低的指纹值。
传统的hash算法只是将内容随机的用一个hash值来表示,如果两个hash值不相等,则两个内容是不相等的,但是没有其他额外的信息,所以,无法通过传统的hash算法来表示内容的相似程度[3]。而Simhash算法则不同,该算法可以通过产生的指纹签名值表示内容之间的相似程度。
Simhash算法是用来检测相似或重复数据的高效hash算法,它不仅能检测出原数据的相似性,而且还能检测出不一样内容所造成的bit位的不同。Simhash算法主要通过将维度较高的特征向量转化为一个f位的指纹签名(Fingerprint),通过比较两个文件f位指纹签名的汉明距离来判断文章的相似性。本文对相似重复数据的研究中主要使用的方法就是以改进后的Simhash算法为基础,结合其他相关技术实现相似重复数据的识别。
1.2 Simhash算法的流程
(1)文本获取:通过相应的技术获取文本内容。
(2)分词:通过特定的分词技术对文本内容进行分词处理,过滤掉一些不重要的词,这些不重要的词指的是停用词,并去一些标点和干扰符号。
(3)生成hash值:通过hash生成算法把每个词变成一个个的哈希值,这样字和词语就变成了数字组成的序列串。
(4)加权:对上一步计算得到的hash值,根据每个词的权重,对其进行加权处理。
(5)合并:把上一步计算出的每个词的序列串进行相加,得到一个新的序列串。
(6)降维:把上一步计算出来的序列串转转变成只有01的串,最后生成Simhash指纹签名。如果每一位大于0记为1,小于0记为0。
根据上述的6个步骤,文本内容就会转化为一个自定义维度大小的指纹值。通常情况下,维度的维数有32、64和128位三种。按照上述流程就将两个文档内容的相似度判断变成了对两个指纹签名值的相似度进行判断。通过计算两个Simhash指纹签名海明距离,就可以判断出两个文档是否相似。
2 基于spark相似重复检测实现
在为了提高相似重复处理的速度,本文将基于Simhash相似重复检测算法于大数据处理平台相结合。在基于Spark的相似检测的实现过程中,主要分为两步,首先是对Simhash指纹签名分块并建立索引,其次是相似重复的计算。
2.1 建立Simhash顺序指纹索引
对于给定的文本,通过Simhash算法计算出文本的Simhash签名值,并以键值对的形式存入到Spark数据库中,为了方便在Spark平台上进行计算。为了提高相似检测的速度,本文对Simhash签名值进行分块操作,并建立索引。在本文中,需要将64位的Simhash签名值分成相等的4份,用字母ABCD、BACD、CABD、DABC表示,每份16位。分块之后的键值对数据如下为:
其中,fileId表示文件编号,ABCD表示按照A部分排序的指纹值,BACD表示按照B部分排序好的指纹值,以此类推。
对于以上描述的优化方法,存在一个问题。如果该指纹索引在指纹签名值F1中的分块的位置与指纹签名值F中的分块位置不相同,例如F的第1个指纹索引与F1的第2个指纹索引相同,但是分块的位置是不用的。所以,这次汉明距离的比较没有意义,会额外增加了比较时间和计算成本。
基于此本文采用在分段后的指纹值增加前缀编号,同时将原有的指纹值作为后缀,共同组成全新的指纹值。例如,将64位的Simhash签名值分成相等的4份,用字母 ABCD、BACD、CABD、DABC表示,则分段后的新的指纹值可以表示为00ABCD、01BACD、10CABD和11DABC,最后可以通过简单的计算将指纹值还原。新的指纹值数据格式为:
通过全新的指纹值按照00A、01B建立索引,将数据输入计算模型,在第一阶段对每个指纹记录进行遍历,输出组合的二元组key-value对,其中二元组为指纹值,表示为
输入阶段:
输出阶段:
<00A,
<01B,
<10C,
<11D
在模型计算的第二步的操作过程中,对第一步产生的结果做归并处理,并将得到的结果进行分组,输出的形式例如:
在基于Spark并行计算模型下,对文本内容的指纹签名按照建立的顺序索引进行指纹签名的分类操作,通过Spark并行计算模型中的相应的Map函数,把相同的顺序指纹索引所对应的文本的编号和后续的指纹值添加入顺序指纹索引中;通过Spark并行计算模型中的相应的Reduce函数,对相同的顺序指纹索引的文本编号和指纹值的键值对内容进行处理归并处理。
在进行归并的时候,将归并的步骤拆分为两步,第一步是局部的归并,对每一个键都添加一个随机数,例如10以内的随机数,此时原来的键就变成了新的键。例如(hello,1)(hello,1)(hello,1)(hello,1),就会变成(1_hello,1)(1_hello,1)(2_hello,1)(2_hello,1)。接着对新的键值对按照键进行归并操作,进行局部的归并操作,那么聚合后的结果就变成了(1_hello,2)(2_hello,2)。第二步是将各个键的前缀去掉,就变成了(hello,2)(hello,2),再次进行全局的归并操作,就得到了最终的结果了,例如(hello,4)。
通过采用二段聚合的方式,可以避免在shuffle阶段出现数据倾斜现象,提高Spark处理数据的速度和性能。
2.2 相似度检测计算
在数据规模非常大的情况下,数据相似度检测计算的任务量也是相当大的。所以本文在进行相似度检测计算时,充分利用了Spark在大规模数据处理下的优势,完成大规模数据下的相似度检测计算任务。
根据第一阶段的操作,对指纹值进行分块并建立索引后,并将键值相同的索引进行归并,得到的中间结果为
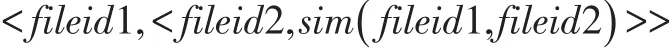
在第二个Map计算阶段,通过计算出两个文件之间的相似度,将相似度与阈值进行比较,来判断文件是否相似。利用如下公式计算相似度:
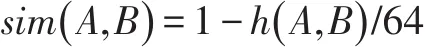
其中,A、B表示两个文本数据,h(A ,B)表示A和B的汉明距离。计算出sim(A,B)的值,即为文本A和文本B的指纹签名相似度。若sim(A,B)大于阈值,则证明文本A和文本B是相似重复的。具体流程示意图如图1所示。
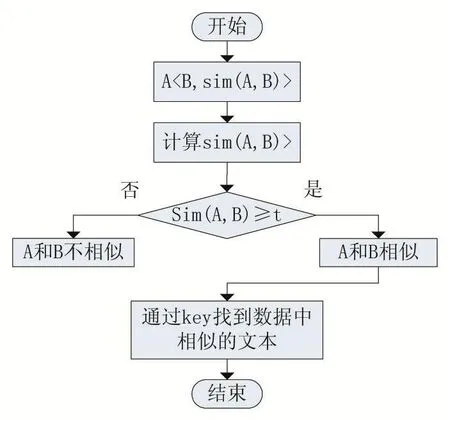
图1
在计算的第二阶段,主要是为了查找和待检测文本B相似度最接近的文本。所以,会根据文本之间的指纹签名值进行相似度大小的比较,找到相似度的文本。获取sim(A,B)的最大值的中间值,输出以A为key,B和sim(A,B)组 成 的 二 元 组 为value,即,其中,网页B代表这在文本集中已经存在的某个文本。找到文本A与文本集中的某个文本的最大相似值,也就是最相似的某个文本,为了以后的指纹库的更新也提供了方便。
3 算法实现效果
本文通过进行一系列对比实验的方方法,对本文优化后的Simhash相似检测算法的算法性能从准确率、召回率、F值以及执行时间等方面进行度量。将本文的Simhash算法分别和原有的Simhash算法、优化的Simhash算法以及Shingle算法做对比实验。
实验针对五类新闻数据,每一类随机选取2000条数据,其中包含500条相似重复数据。这500条相似重复数据作为实验之前已经知道的相似重复数据。分别用Shingle算法、原有的Simhash算法、优化后的Simhash算法和本文提出的Simhash算法在这些数据集上对比实验,分别对不同算法所得到的实验结果进行分析。如果算法检测出来的正确的相似重复数据的数量和原先设置的500条相似重复数据越接近,就说明算法本文的算法是切实可行的。

表1 算法准确度对比表
4 结语
本文提出的基于Spark的大规模相似重复数据清洗模型,通过对Simhash算法进行相应的优化,提高了相似重复数据检测的准确度和速度;将优化的Simhash算法和Spark相结合,有效地解决了单机环境下处理海量文本数据存在的效率低下、存储受限等问题。在此,对本文所研究的相关内容进行了如下小结:
(1)对相似检测技术和数据清洗的概念作了简要的介绍,并介绍了Simhash相似检测算法相关的技术,例如汉明距离以及Simhash算法的概念和算法思想。并基于传统的Simhash算法在计算权重的基础上做了相应的优化,以提高相似重复数据检测的准确度和匹配的速度。
(2)在针对Simhash算法权重计算的过程中,对Simhash算法进行了相应的优化。在指纹值匹配过程中,通过对指纹值进行分块并建立指纹值索引,使用了一种索引顺序匹配的方式,提高指纹值匹配的速度和效率。
(3)结合优化的Simhash算法,在深入研究了大数据处理平台Spark之后,提出了基于Spark的大数据相似重复数据清洗模型。首先,通过使用改进的Simhash算法进行指纹值的计算,对指纹值进行分块并建立顺序索引,然后通过计算海明距离判断是否相似。结合大数据处理平台Spark中的并行计算框架,对每一步计算产生的中间数据进行适当的变形。最后,在基于Spark大数据处理平台进行了相似重复数据的检测和清洗,将清洗之后的干净数据存入存储系统中。通过相关实验进行证明并对实验结果进行分析,证明了将优化的Simhash算法和Spark大数据处理平台相结合,提高了相似重复数据检测和清洗的准确度以及速度。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
房地产导刊(2022年4期)2022-04-19
心理学报(2022年4期)2022-04-12
能源工程(2021年6期)2022-01-06
建材发展导向(2021年12期)2021-07-22
电脑爱好者(2020年18期)2020-09-26
计算机应用与软件(2020年5期)2020-05-16
新生代·下半月(2019年5期)2019-09-10
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
