
中文句法异构蕴含语块标注和边界识别研究
2019-04-02 03:08金天华赵美倩
中文信息学报 2019年2期
金天华,姜 姗,于 东,2,赵美倩,刘 璐
(1. 北京语言大学 信息科学学院,北京 100083;2. 北京语言大学 语言资源高精尖创新中心,北京 100083)
0 引言
文本蕴含定义为一对文本之间的有向推理关系[1],其中蕴含前件记作P(premise),蕴含后件记作H(hypothesis)。文本蕴含识别(recognizing textual entailment, RTE)是基于语义理解,对两个句子之间的蕴含和矛盾关系做出判断的任务。文本蕴含作为语义理解的基础任务,可以建立起不同文本之间的语义推理关系网,促进关系识别、事件抽取、自动文摘等任务的发展,同时在问答系统、文本挖掘、阅读理解、信息检索等应用领域发挥关键作用。
文本蕴含识别早期的研究工作[2-4]多从词汇蕴含角度出发,探索近义词、上下位词、整体和部分等词汇关系在文本蕴含识别中的应用。然而单纯词汇蕴含并不能完全涵盖文本蕴含的所有范畴。目前对文本蕴含成因的定量研究仍处于初步阶段。另一方面,近年来,随着SICK[5]、SNLI[6]、MultiNLI[7]等数据集的提出,用机器学习方法建立end-to-end模型判断整句的句法蕴含关系成为研究热点[8-10]。此类模型可以有效判断整句级别的蕴含关系,但无法确定引起蕴含的关键语块位置,其结果缺乏可解释性,因而大大削弱了其应用价值。
针对第一个问题,本文将蕴含成因归纳为词汇蕴含、句法异构蕴含、常识和社会经验三种类型。我们翻译并校对了SNLI数据集中的3 766条蕴含句对数据,由人工对其蕴含成因类型进行标注,其中词汇蕴含仅占31.5%,说明词汇蕴含只是蕴含的一种类型。常识和社会经验占比为29.1%,由于常识的概念模糊,包含的信息粒度大,因而不在本文讨论范围内。标注结果中,句法异构导致的蕴含占比最多,达到占39.4%,故本文以此为研究对象。
所谓句法异构蕴含,是指通过语言的位移、添加、删除、替换等手段[11]对P的形式进行有选择的筛选和强调,得到H、P和H的句法变化,使得它们在语义上具有蕴含关系,则P和H是句法异构蕴含。如下文T1、T2的两组例句就是句法异构蕴含。
值得一提的是,句法异构蕴含与复述有本质区别。句法异构蕴含不追求语义信息的完整性和一致性。分析发现,句法异构蕴含会保留或概括P中需要强调的、不可省略的部分,而删除不需要强调的部分。例如,T1的H省略了P的地点状语“在蓝色卡车旁边”,突出强调了动词性谓语“拍摄”,这两句话具有句法异构蕴含关系。T2的H省略了P的谓语“拍摄”和宾语“电影”,而H的谓语和宾语是由P的地点状语“在蓝色卡车旁边”充当。P和H是句法异构的,它们之间也具有句法异构蕴含关系。
T1: P: 一群人在蓝色卡车旁边拍摄电影。
H: 一群人在拍摄电影。
T2: P: 一群人在蓝色卡车旁边拍摄电影。
H: 一群人在蓝色卡车旁边。
本文研究导致蕴含现象的句法异构类型,通过观察大量蕴含句对,分析归纳得出以下结论: 句法异构类型分为结构变化和省略变化;结构变化又分为成分抽取、从句抽取、语序变化;省略变化分为省略修饰语和省略中心语。
针对第二个问题,本文需深入语料内部确定引起整句级别蕴含关系的关键语块,我们认为这些关键语块可以被称为句法异构蕴含语块。语块的概念最早由Skehan提出[12],指兼具词汇和句法特征的半固定的语言结构。在本文中,句法异构蕴含语块是P和H中句法成分或句法结构不同,且具有蕴含关系的部分。蕴含语块可以是句中充当句法成分的词、短语,甚至是整个单句或者复句中的某个小句。例如“香甜的苹果—苹果”“漫长的夜晚—夜晚”都属于从“adj+的+n”到“n”的变化,那么“adj+的+n”和“n”就分别是P和H的句法异构蕴含语块。
显然,句法异构蕴含语块的确认依赖于蕴含成因的研究。从机器学习角度来说,句法异构蕴含语块的识别问题可以转化为边界识别问题。本文主要采用深度学习模型,处理整合P和H的蕴含信息用于识别蕴含边界下标。受Wang[13]的启发,我们利用match_LSTM计算获得包含P和H蕴含信息的表示向量,作为Ptr-Net的输入,进而寻找蕴含边界。
本文首先介绍国内外蕴含类型研究,在此基础上针对句法异构蕴含现象进行分析总结,归纳得到句法异构蕴含类型;接着介绍我们在蕴含语块标注方面的工作,从标注结果归纳得到一套简单有效的规则系统,并将该规则系统与深度学习模型应用于语块边界自动识别,分析比较两者在实验上的有效性,并对论文工作进行总结和展望。
1 相关工作
现有的文本蕴含数据集都是为解决文本蕴含问题而开发的,并没有专门研究蕴含类型成因的数据集。早期文本蕴含评测RTE-1至RTE-3[14-16]及SciTail[17]将文本蕴含视为二分类任务,句子对之间只存在蕴含和中立两种关系。近年来的大规模数据集,如SNLI、MultiNLI等,把文本蕴含关系分为“蕴含”“矛盾”“中立”三种,以供学界研究文本蕴含的整体类型。截止本文写稿期间,我们尚未看到单独讨论蕴含成因类型的研究和讨论句子内部导致蕴含关系的语言片段的研究。
在英文研究领域,Ido Dagan和Oren Glickman[18]从宏观角度把英语蕴含关系分成五类:Axion rule(公理),Reflexivity(自反性),Monotone extension(单调性扩张),Restrictive extension(限制性扩张),Transitive Chaining(传递链)。这些概念较为抽象,不便理解,在具体标注过程中难以实践。
在中文研究领域,RITE-3任务针对中文语料提出了19类蕴含现象和9类矛盾现象[19],包含了近义词、反义词、上下位词等词汇类别和从句、时态等句法类别。任函[20]提出了面向汉语文本推理的语言现象标注类别,包含了20个类别的语言现象体系,同样包含了同义词(近义词)、上下位词、反义词等词汇类别,该类别体系以词汇为主,句法特征的内容不多,仅有一个结构变化,较为笼统。
以上研究是从语言学角度对蕴含类型进行区分,没有考虑数据的实际情况,容易出现某些类别数据稀疏的情况。因此,本文将数据处理和蕴含类型相结合,利用现有数据集,深入语料寻找导致蕴含关系的语言片段,探究蕴含现象成因。
2 句法异构蕴含成因研究
我们根据汉语句法特点把句法异构蕴含的成因归纳成两类:一,结构变化:成分抽取、小句抽取、语序变化;二,省略变化:省略修饰语、省略中心语。这两个类别既可以独立存在,也可以同时存在。句法异构蕴含成因类型汇总如表1所示。

表1 句法异构蕴含成因类型
2.1 结构变化
汉语以语序和虚词作为主要语法手段[21],语序变化可以同时改变句子的表层结构和深层结构,也就是既改变句子的形式,又改变句子的意义。除了语序变化外,成分抽取、小句抽取也属于结构变化。
2.1.1 语序变化
“语序”不仅是表示语法结构、语法意义的形式,也是言语表达或修辞的手段[22]。语序变化类句法异构蕴含就是指由语法结构内部成分的线性顺序发生变化导致的蕴含。例如:
T3: P:三个女人和一个小女孩在和小狗玩。
H: 与小狗玩耍的女人们。
P属于“施受谓”语序,施事是“三个女人和一个小女孩”,受事是“一只小狗”,“谓”指谓语“玩”。在H中受事“小狗”谓语“玩耍”被提前到施事“女人们”前面。同时,H把一个陈述句变成了短语。
T4: P: 一家人正走在一些很大的独立的几何雕塑下面。
H: 人们在一些非常大的雕塑下行走。
P属于“主动——施谓”语序,“动”指动词,“谓”指谓词,在动词后面有一个表示地点的状语,H把句尾的地点状语提前到动词前面,两句话的语序发生了改变。
2.1.2 成分抽取
从P中把主谓宾结构的某一部分抽取出来,单独成句。被抽取出来的结构如果是一个定中结构,有可能变成一个简单的主谓句,也有可能变成一个存在句。例如:
T5: P:一个穿着黄色毛衣的年轻人看着那张上面摆着各种花的桌子。
H:这里有个人。
P的主语“一个穿着黄色毛衣的年轻人”被抽取出来,省略修饰后单独成句,H是一个表示人物存在的句子“这里有个人”。
T6: P:一个穿着黑色裤子没穿衬衫的男孩儿正在玩一个白色的气球。
H:男孩穿着黑色裤子。
P的主语“一个穿着黑色裤子没穿衬衫的男孩儿”被抽取出来,省略部分修饰语后变成一个简单的主谓句H,“男孩穿着黑色裤子”。
2.1.3 小句抽取
在有多个小句的复句中抽出某一个小句,单独成句。一般情况下,我们会选择保留包含完整信息的小句,而省略作为从属地位补充信息的小句。例如:
T7: P: 男人和女人在海滩上漫步,身后是绚丽的晚霞。
H: 一个男人和一个女人在海滩上散步。(NULL)
P是由一个主谓小句和一个表示背景信息的小句构成的,H省略了表示背景信息的小句。
T8: P: 小男孩在哭,因为他被雪球击中了。
H: 小男孩在哭。(NULL)
同理,P由一个包含了完整信息的主谓小句和一个表示原因的小句构成,H省略了表示原因的小句。
2.2 省略变化
语言具有递归性,相同或不同的语言结构层层嵌套,结构规则重复使用而不会造成结构上的混乱[11]。基于语言递归性,省略部分结构而得到蕴含现象也属于句法异构蕴含。省略变化主要有省略中心语、省略修饰语两类,这容易与上一节的小句抽取混淆。两者之间的区别主要在于他们作用于不同的语言单位。小句抽取是在复句中进行,而省略则是在某一简单句内部进行。
2.2.1 省略中心语
在偏正结构中,省略了核心谓词,而保留修饰语。被保留的修饰语可以是形容词性成分、地点状语、时间状语等。例如:
T9: P: 年长的白人女子在她的厨房做蛋糕。
H: 一位老太太在厨房里。
P是“主谓宾”结构,在主语“一位年长的白人女子”和谓语“做”之间有地点状语“在她的厨房”,H省略谓语和谓语的宾语“蛋糕”,只保留主语和地点状语。
T10: P: 一群人划独木舟穿过热带雨林。
H: 一群人正在划独木舟。
P中有2个谓词性短语“划独木舟”和“穿过热带雨林”,在这里“穿过热带雨林”可以看作是中心谓词,“划独木舟”是表示方式的方式状语,H省略了中心谓语,保留主语和方式状语,并在方式状语前加上表示动作持续的“正在”,构成一个新的主谓句。
2.2.2 省略修饰语
在偏正结构中省略修饰性成分,保留中心语。与上面的省略中心语相对,被省略的修饰语可以是表示地点、时间、工具的状语,也可以是表示事物性状的形容词性成分。
T11: P: 一个男人在晴天晾衣服。
H: 男人晾晒衣服。
H省略了时间状语“在晴天”。
T12: P: 穿着黑色衬衫的吧台服务员用一台大机器做咖啡。
H: 吧台侍者在做咖啡。(省略工具)
H省略了人物修饰语“穿着黑色衬衫的”和表示工具的状语信息“用一台大机器”。
此外,句法异构蕴含的成因不一定独立存在。比如T13中,P的主语“穿着红色连帽衫的男孩”被提取出来,单独成句为H,这属于成分抽取引发的蕴含。同时,P中的“红色连帽衫”和H中的“红色衣服”属于上下位词造成的蕴含。并且,P和H中,“穿着红色连帽衫(红色衣服)的男孩”和“男孩穿着红色衣服(红色连帽衫)”属于由语序调换造成的蕴含。文本蕴含语料中类似的实例说明了蕴含成因是混合的,不是单一的。
T13: P:穿着红色连帽衫的男孩走在人行道上。
H:男孩穿着红色衣服。
3 句法异构蕴含的语块边界标注
我们从英文开源数据集SNLI选取了一部分数据,将其翻译成中文,筛选出其中结构清晰、表达合适的4 000条蕴含数据进行了人工标注。经过校对后,获得有效标注3 766例。具体方法和流程在本节中详述。
3.1 数据选择
我们的数据来源于英文开源数据集SNLI。一方面,目前尚未出现大规模中文文本蕴含数据集,在2012年发布的RITE-2的几个中文数据集规模太小,并且不太容易获取,使用不方便,而英文领域有多个大规模开源数据集,例如SNLI、MultiNLI,获取和使用都很方便。另一方面,文本蕴含本质上是一种语义关系,不同语言之间的蕴含成因会有共同之处,所以我们可以借助英文数据集来研究中文蕴含。
SNLI[6]是目前主流的文本蕴含数据集,其中的数据全部是依靠众包(Crowdsourcing)人工生成的真实文本,语言形式灵活多样,数据质量较高,不会存在明显的语法错误。SNLI的数据规模巨大,拥有560 152条训练数据和10 000条测试数据,每条数据包含一句Premise和一句Hypothesis,以及一个关系标签,有充足的语料挑选余地。标注过程中需要考虑句子长度,若句子过长、结构复杂,则分析困难;若句子过短、信息太少,不具有标注价值。SNLI的Premise平均长度为14.1个单词,Hypothesis的平均长度为8.3,长度适中,便于人工标注。
基于以上考虑,我们将SNLI的部分训练数据翻译成中文,挑选出长度在5~35个汉字之间、结构清晰、表达符合汉语用语习惯的句子进行人工标注和分析。
3.2 标注方法
本文标注工作实质上是在已知蕴含关系的基础上确定句法异构语块边界。标注员首先要看完原句P和蕴含句H,对句子表达的内容有一个了解。根据H的内容回到P中寻找相关内容,分别标注出P和H的句法蕴含语块。
根据句法异构蕴含的类型划分标注语块的类型。省略类的蕴含语块往往是一个定中短语或状中短语;结构变化的蕴含语块类型多样,小句抽取的蕴含语块是复句中的小句,我们可以用逗号作为划分依据;成分抽取的蕴含语块是句中某个完整的句法成分,若句法成分前有修饰语,那么语块也要包括修饰语;语序变化的蕴含语块较为特殊,需要结合具体语料划分。
本文使用基于Web的文本标注工具BRAT进行蕴含语块标注,标注过程如图1所示。导入待标注文本,选择原句P和蕴含句H中的蕴含语块,分别标记为“Antedt”和“Consqt”。连接“Antedt”和“Consqt”,在弹出的对话框中为两个语块选择相应的句法异构关系。如果有标注错误,双击“Antedt”或“Consqt”或者关系类型,移动、添加、删除标注内容。标注结果由BRAT自动保存,示例如图2所示。完成整个文件中的数据标注后,得到一个后缀名为.ann的文件。
为了提高标注语料的一致性,在第一次标注结束两周后,我们按照最终标准对数据进行了二次标注。最后,分析提取得到的句法异构蕴含语块,人工校对修改,得到最后的标注结果。这在一定程度上解决了多人标注引起的不一致问题,提高了蕴含语块标注的准确性。
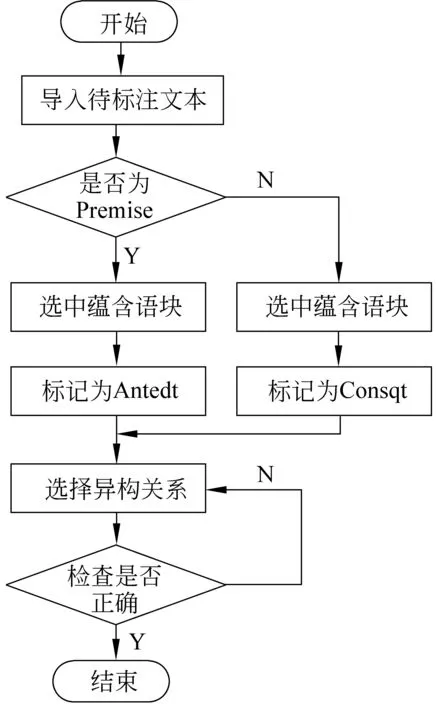
图1 BRAT标注过程
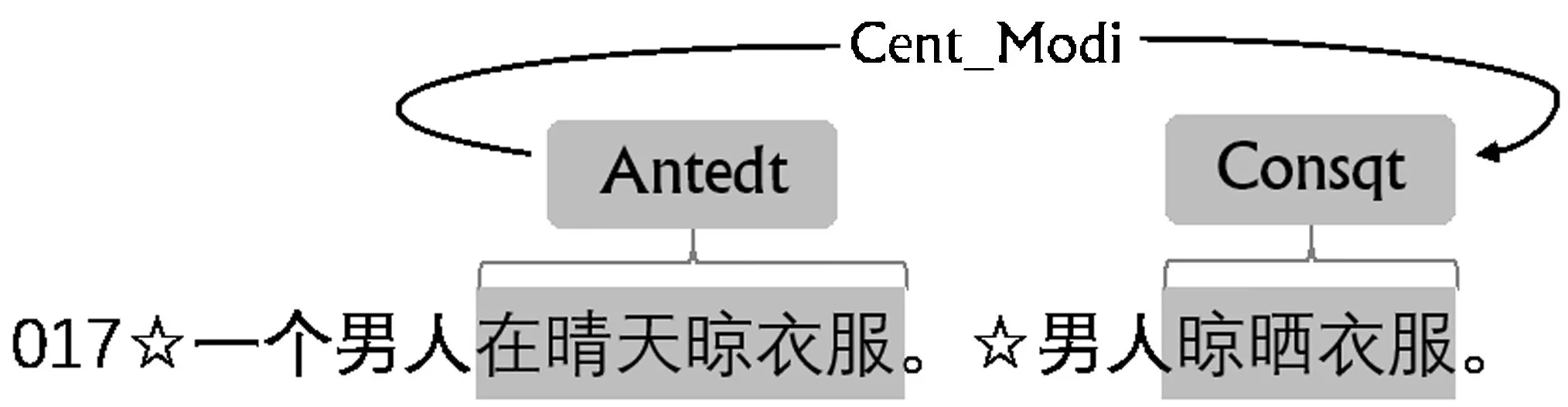
图2 BRAT标注示例
3.3 标注结果及数据分析
我们总共筛选出4 000条蕴含数据,获得有效标注结果3 766例,如表2所示。其中句法异构蕴含有1 483例,占39.40%;词汇蕴含1 188例,占31.50%;常识和社会经验蕴含1 095例,占29.10%。
最后我们又针对句法异构蕴含进行语料扩充,总共标注句法蕴含2 000例,结构变化类463例,占比23.15%;省略类1 537例,占比76.85%。
可以看到,文本蕴含主要还是通过词汇关系和句法异构产生的,其中句法异构略多于词汇关系,而在句法异构蕴含中又是以省略类为主,结构变化导致的蕴含较少。
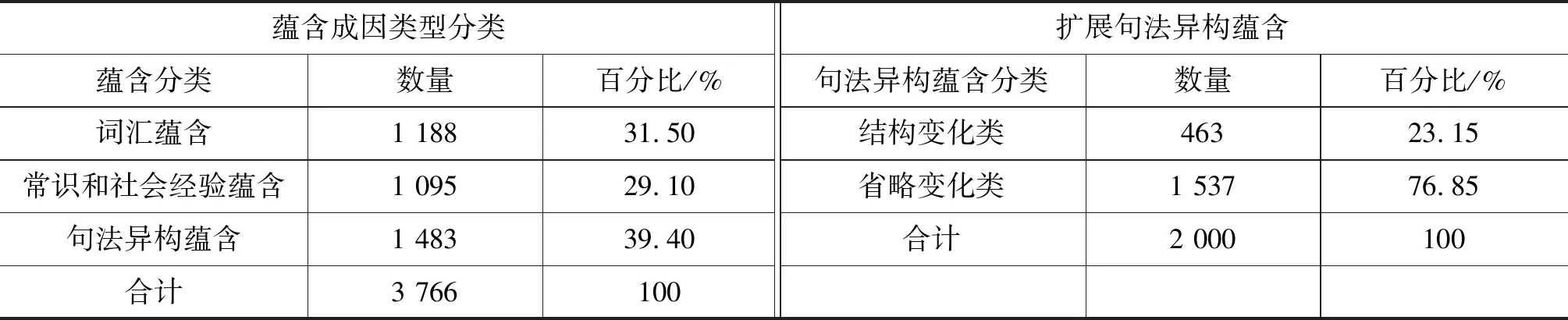
表2 蕴含分类统计
4 句法异构蕴含边界识别研究
4.1 句法规则识别方法
通过解析句法异构蕴含语块对的词性和句法依存分析,我们总结出了一套句法异构蕴含的规则系统。在依存句法体系中,“HED”指的是核心关系,通常是小句的谓语,“SBV”指的是主语,“VOB”指的是宾语,“IOB”指的是间接宾语,“POB”指的是后置定语,“ATT”指的是定语,“ADV”指的是状语,“COO”表示两个重复的成分。本文的句法异构中可以有规则匹配的类型归纳如下。
1. “被”“把”语块
我们通过匹配句子中的标志字“被”和“把”,并判断“被”和“把”在语块中担任“ADV”成分,则认为此语块为“被”结构或“把”结构语块。
LTP中的句法依存分析结果,“被”字语块一般被解析为如下结构:
(1) [ATT]* + FOB + 被 + [[ATT]* + POB] + HED
“把”字语块句法依存分析的主体结构为:
(2) [SVB] + 把 + [ATT]* + POB + HED + [[ATT]* + VOB]
“被”字语块蕴含的句法依存结构示例如图3所示。
S1: 大象正被一个男人骑着。
S2: 人在骑大象。
“把”字语块蕴含的句法依存结构示例如图4所示。
S3: 走过街道,把它打扫干净。
S4: 清扫街道。
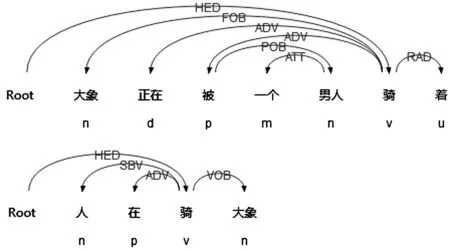
图3 S1、S2句法结构
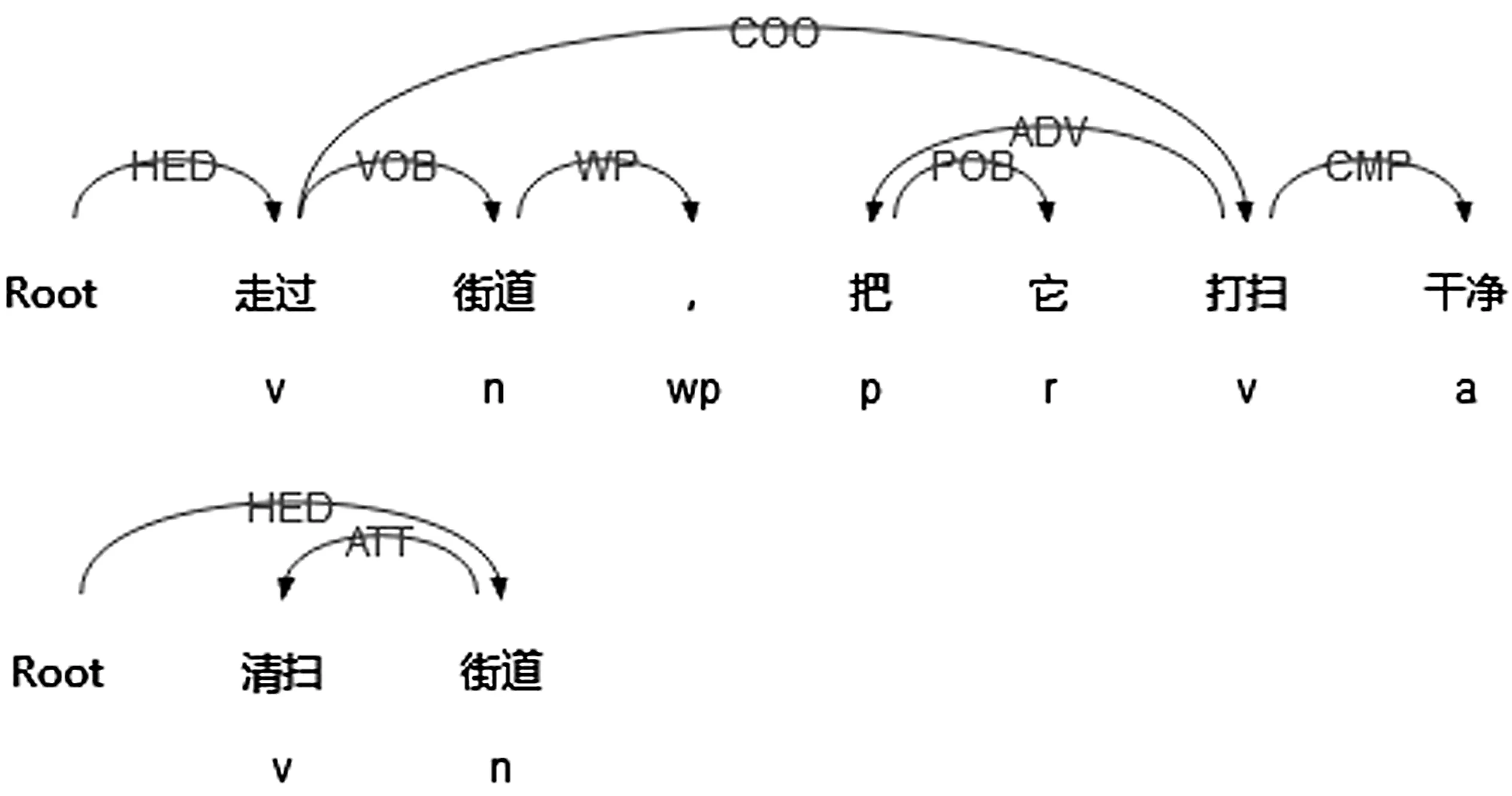
图4 S3、S4句法结构
2.普通语块
与“被”字语块和“把”字语块对应,一般语块的句法依存分析的主体结构如下:
(1) SBV + HED + VOB
蕴含语块对中,HED必须一致或有蕴含关系,并且FOB和VOB,POB和SBV一致或H句中的主体结构中某成分被省略。
H省略P中并列的信息: 即句法依存分析树的结构中,P有多个HED,H缺少P中标记为COO部分的子树。语块对的主体结构如下:
(2) P: SBV + [HEDP]* + VOB
H: SBV + [HEDH]* + VOB
其中[HEDH]* ∈ [HEDP]*, 示例如图5所示。
S5: 坐在滑板上在乡间滑行。
S6: 坐在滑板上。
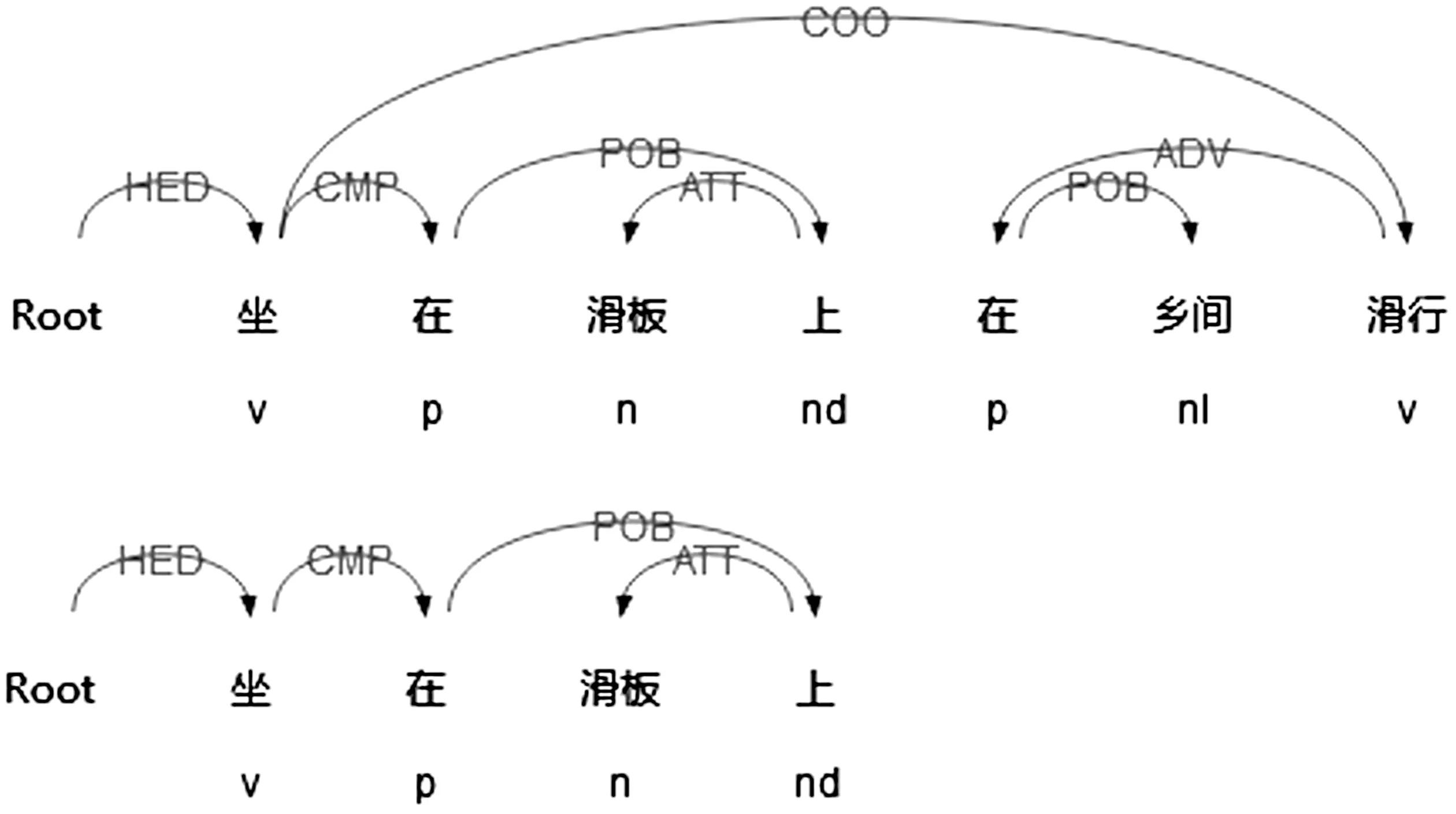
图5 S5、S6句法结构
H省略P中修饰的信息: 蕴含句对的HED相同,H中缺少P中的一个或几个ATT成分,其他成分相同,语块对的句法结构表示为:
(3) P: [ATT1P]* + SBV + HED + [ATT2P]* + VOB
H: [ATT1H]* + SBV + HED + [ATT2H]* + VOB
其中,[ATTH]* ∈ [ATTP]* ,P和H可以省略某一句子成分,且P的信息包含H的信息。例句如图6所示。
S7: 一个亚裔小女孩儿。
S8: 一个小女孩儿。
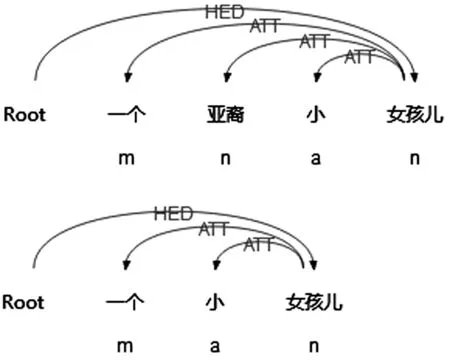
图6 S7、S8句法结构
H只保留了P中的HED,省略其他的句法成分。语块对的句法结构表示为:
(4) P: [[ATT]* + HEDP]*
H: HEDH
其中,P的结构为一组或多组修饰语加核心词,且[HEDH]∈[HEDP],如果[HEDH]包含多个短语,则用“和”连接。例句示例如下:
S9: 一个穿着比基尼的女人和一个打扮正常的男人。
S10: 男人和女人。
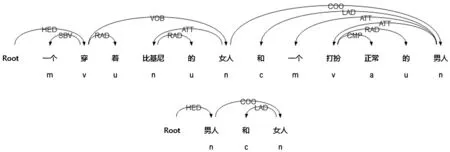
图7 S9、S10句法结构
按照上述6条规则自动抽取蕴含语料,每条规则抽取的数量与数据库中语块总数的比值为相应规则的覆盖度,每条规则抽取得到的语块数量与数据库中符合此规则的语块数量的比值为相应规则的有效性,为规则的具体评价。规则覆盖度评价如表3所示。
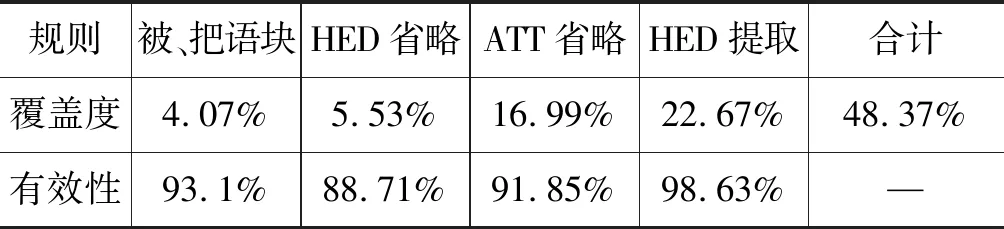
表3 句法规则覆盖度
句法异构的句对结构转化多样,句法成分位置灵活,以及同义词及上下位词的替换,使得我们难以用规则概括所有的句法异构蕴含。本文总结规律性强、较为常见的蕴含语块对,确保了抽取数据的有效性,但由于规则限制比较严格,未能覆盖全部数据。本节规则识别的结果为进一步的深度模型实验提供了参考标准。
4.2 基于深度学习方法的实验
4.2.1 模型
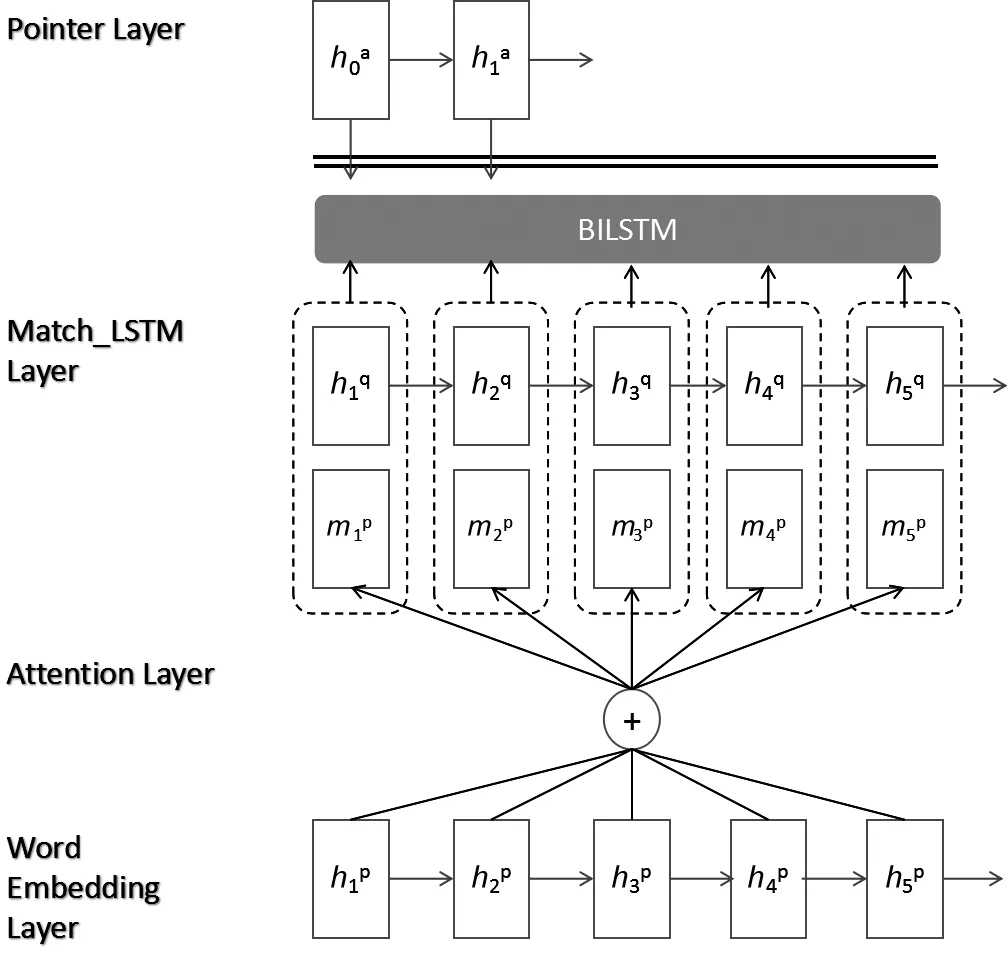
图8 模型结构图
本文采用深度学习模型处理整合P和H的蕴含信息,识别蕴含边界下标。基于Wang[13]的模型,如图8所示,此模型主要分为两个模块: match_LSTM和Pointer Network(Ptr-Net)。Wang[13]针对文本蕴含任务提出了match-LSTM模型,用来判断P是否蕴含H。与Wang[13]工作不同的是,我们没有利用match-LSTM判断P和H的蕴含类型,而是计算获得包含P和H蕴含信息的表示向量,作为Ptr-Net的输入。Ptr-Net由Vinyals[24]提出,它采用attention机制作为指针,选择输入序列的位置下标作为输出。在此我们采用Ptr-Net,在整合了P和H蕴含信息的向量中寻找蕴含边界。
4.2.2 实验设计与分析
我们在SNLI数据库中选取2 000条句法异构类型的蕴含对,采用前文的规则进行人工标注。其中,训练集包含1 700条数据,测试集包含300条数据。实验代码基于tensorflow框架,采用边界正确率作为评价指标。我们分别统计了P和H蕴含片段的前后正确率及总体正确率,实验结果如表4所示。
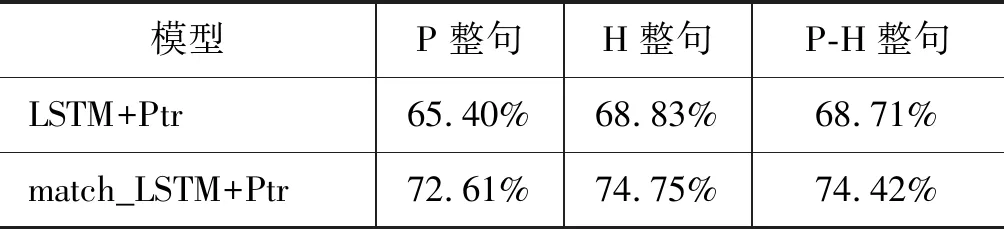
表4 实验结果
从表4可以看出,对于两个模型P和H两个蕴含边界识别总正确率分别为68.71%、74.42%,P的蕴含边界正确率分别为65.40%、72.61%,H的蕴含边界正确率分别为68.83%、74.75%。由实验结果知,模型对于H的蕴含片段识别能力略高于P,attention机制显著地提高了模型的正确率。
本文首次提出句法异构蕴含边界识别问题,并且首次采用深度学习模型探索端到端识别蕴含边界的可能性。我们对比了LSTM+Ptr-Net和match_LSTM+Ptr-Net两个模型,前者使用LSTM为序列建模,后者在LSTM的基础上增加了attention机制。
5 结语
本文通过标注蕴含句对,分析总结句法异构蕴含类型,归纳句法异构蕴含规则,并对该规则的有效性进行验证,结果表明基于规则的方法可以为进一步的深度模型实验提供参考标准。本文用深度学习模型识别蕴含语块边界,在小规模中文语料上提供了可靠的基准线。本文的实验代码和数据已经公布在Github网站,网址为https://github.com/blcunlp/CCHEP。
与整句级别的蕴含识别任务相比,本文在句法异构蕴含识别上的正确率还有待提高。我们计划进一步探讨句法异构蕴含规则,扩大规则覆盖范围,为深度学习模型提供更为可靠的外部知识。
本文的工作为日后蕴含成因分析与语块标注研究提供了可供改进的方向,其中包括: ①提高语块标注的准确性,解决因错误标注带来的语块边界不清问题; ②扩展蕴含成因类型,现有句法异构蕴含类型还能继续扩充,因常识和社会知识造成的蕴含也值得深入分析; ③扩展句法异构蕴含规则,现有规则较为简单,对中文特殊句式的研究不够深入,未能覆盖到大部分句法异构蕴含现象。
猜你喜欢
广东教育·综合(2021年11期)2021-12-02
大连民族大学学报(2021年2期)2021-07-16
牡丹江教育学院学报(2021年1期)2021-03-23
师道·教研(2020年3期)2020-04-02
中学生英语·教师版(2019年6期)2019-08-01
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
当代修辞学(2014年3期)2014-01-21
