
人工智能与期刊发展融合的机遇、挑战和实践路径研究
2019-04-01 05:40刘育猛
中国科技期刊研究 2019年3期
■陈 鸿 刘育猛 裴 孟
1)常州大学学报编辑部,江苏省常州市武进区滆湖中路21号 2131642)常州大学组织部,江苏省常州市武进区滆湖中路21号 2131643)常州大学环境与安全工程学院,江苏省常州市武进区滆湖中路21号 213164
1956年,人工智能(Artificial Intelligence,AI)一词首次被提出,经过半个多世纪的发展,人工智能已成为当前炙手可热的技术革新风口和产业转型抓手。2017年7月,国务院印发《新一代人工智能发展规划》,将人工智能发展上升到国家战略高度。期刊作为知识生产和文化传播产业的重要前沿阵地,应该在相关国家政策规划的导向下,顺应发展趋势,积极探索期刊与人工智能技术的融合应用。
事实上,人工智能正逐渐进入出版领域研究者的视野。有研究者就人工智能在学术出版流程再造[1-2]、学术不端行为检测[3]、出版模式创新[4-8]、论文指派和第三方专业评议[9]等领域的应用进行了有益探索。目前,人工智能与出版业融合的研究尚属凤毛麟角,更遑论人工智能与期刊融合的研究。这些研究多局限于出版学、新闻学的切入角度与研究方法,未能充分认识到人工智能与新闻生产、出版发行等的融合是涉及信息学、系统学、伦理学、法学等学科的跨界合作,是技术与伦理的双重共振,因此鲜有从宏观角度把握人工智能与出版业发展的研究,导致相关领域研究的浅表化、碎片化和偏狭化。
已有研究和实践为人工智能与期刊发展融合研究提供了充分而迫切的现实环境和问题语境。因此,本研究秉承问题意识,打破学科壁垒,拟从信息学、系统学、伦理学、法学角度切入,探讨人工智能与期刊融合的机遇、挑战和实践路径,以期在理论上丰富期刊研究的内容,在实践中为期刊主动适应行业转变,合理制定发展规划,调整发展路径,构建智能化期刊发展模式提供借鉴。
1 人工智能与期刊发展融合的机遇
1.1 政策支持
1.1.1 国家政策支持
从2015年提出《中国制造2025》,到2017年人工智能首次进入《政府工作报告》,再到2018年的大力推行;从产业到民生的多领域覆盖,从实体经济到精神文化的全方位升级,我们清晰地看到,当人工智能成为引领科技进步的重要驱动力时,我国紧追世界顶尖技术、加快技术创新、推动产业升级的国家意志。在国家政策支持下,科研投入的增加、人才红利的注入预期和技术革新的折叠效应,有利于加快人工智能与期刊的融合。
1.1.2 行业政策支持
就行业政策而言,2017年4月,《文化部“十三五”时期文化发展改革规划》提出要“大力培育基于大数据、云计算、物联网、人工智能等新技术的新型文化业态,形成文化产业新的增长点”[10]。同年7月,《2016—2017中国数字出版产业年度报告》显示,人工智能技术正在重塑出版流程。“语音录入、机器协助校稿、机器写作、增强用户交互体验等方兴未艾,机器人正在我们这个行业得到逐步的应用”[11]。这些行业政策成为催生人工智能与期刊深度融合的集结号。
1.2 技术支持
如果说政策支持是人工智能与期刊深度融合的导向因素,那么技术支持就是人工智能与期刊深度融合的可行基础。技术支持包括两个方面:(1)人工智能基础技术支持;(2)人工智能行业技术支持。
1.2.1 人工智能基础技术支持
人工智能从对人脑的模仿到自主深度学习,从提高劳动效率到替代人类劳动,从对数据的简单占有到算法技术的利用,其技术进入了折叠式增长。所谓折叠式的增长,从理论来看,一张纸可以无限折叠,不断重复之后,可以从地球叠加到月球。而当折叠厚度达到地球与月球距离的一半时,此时,只需要再折叠一次就可以到达月球,这就是折叠效应的威力。而现在人工智能技术的发展也正向这个方向趋近。在人类的努力下,目前人工智能技术实现了“‘数据—信息—知识—智慧—顿悟’的信息处理智能化晋级管道”[12],而人工智能基础技术的提升为其与行业技术融合奠定了基础。
1.2.2 人工智能行业技术支持
出版领域的人工智能技术介入与升级呈现迅猛上升态势。当前,数字出版有2个显著特征:(1)数字教育出版生态圈逐步形成;(2)学术期刊集群化向纵深发展[11]。这两个发展都离不开一个关键概念——垂直领域,而垂直领域的发展又离不开关键技术——人工智能。数字出版领域中,人工智能技术介入与升级的典型例子是:人工智能审核相关稿件,并将关键词、作者背景、重复率、内容价值、受众适用性等条件设为定量,根据一定的算法,决定是否通过、是否向读者推送,以及向哪些读者推送等。人工智能技术在出版行业的介入与升级,使得知识传播的专项服务、深度服务、私人订制成为可能。
1.3 观念支持
人工智能环境下,计算思维得到有力普及。问题、数据、算法是计算思维的3个重要元素。就计算思维来看,问题的解决基本上都是按照提出问题、占有数据、设计算法这个基本思路进行。在期刊发展领域,人们根据拟解决的具体学术问题,对占有相关专项数据而非传统的综合海量数据进行垂直搜索、筛选,从而解决问题。从某种意义来说,正是计算思维的普及倒逼着学术期刊走向集群化发展,“从综合性全领域海量平台向同一垂直领域(如科技、财经等)专业平台转变”[11]。
1.4 行为支持
近年来,世界顶级互联网公司在“智能+经济”模式下,在人工智能技术领域主动作为并大力投入。谷歌的谷歌大脑、IBM的Watson、微软的Adam和Skype,百度的深度学习、华为的“达芬奇计划”等,在文本获取、自然语言处理、机器翻译、深度学习、信息传递等与期刊发展密切相关领域进行了持续的技术创新。和期刊发展联系紧密的中国知网、万方等文献数据库在人工智能技术的应用方面也进行了积极探索。2018年中国知网与贵州省大数据发展管理局联合打造了国内首个人工智能大数据决策平台“贵州大数据智库平台”,旨在“提供更为完善、可靠的决策报告,真正实施政府科学决策和精准施政”[13];龙源数字传媒人工智能平台的“知识树”系统“目前已经能够在数千万篇文章中寻找已获取授权的内容,然后基于编辑所定义的部分内容自动编辑剩余内容,继而对接亚马逊等图书电商平台,并将所编辑的内容输出到各个数字出版分发渠道”[7]。
世界顶级互联网公司在人工智能方面的积极作为给“人工智能+”模式提供了技术支持;中国知网、龙源数字传媒等文献数据库和出版实体或平台与人工智能的积极融合,则为“人工智能+出版行业”模式提供了宝贵的实践经验。他们的尝试与努力共同为人工智能与期刊发展的深度融合奠定了技术基础,提供了行业示范。
2 人工智能与期刊发展融合的挑战
2.1 技术挑战
2.1.1 数据依赖与“人工愚蠢”
现代人认知方式的改变可能是导致“人工愚蠢”的一个非常重要的原因。以前人们获得的认知主要来自于个体对知识的学习与实践、理解与体悟、内化与外显,即来自于人类智慧,而“智慧是上万年来人类心性、智性和灵性在多方因素下的积累和沉淀,是感觉、意识、品位、兴趣、品质、信仰、情谊等的有机复杂体”[14]。人工智能的便利使得人们能够跨过知识积累,直接利用互联网、大数据、云计算、图像识别等技术,通过搜索、筛选、概率、判断来完成认知,但是“人们借助智能机器而实现的认知延展实际上超越了人的判断能力,超越了整个社会总体的理解和掌控能力”[15]。这时,人类便会面临如何在个体知识谱系一片空白的情况下进行合理决策的问题,也就是说海量数据—智能搜索—判断决策这个行为模式很可能是在无知状态下做出的选择。有学者对此表示担心:“令人玩味的是,智能化时代人类最需要的可能不再是知识论而是无知学,即人们迫切需要了解的是怎样在无知的情况下做出恰当的决策”[15]。在知识爆炸的时代,因人工智能带来的认知方式改变以及这种改变的便捷,反而有可能导致人类不再依赖知识的长期积累,而依赖智能平台与大数据,追求短、平、快的即时认知,造成“人工愚蠢”。
这种“人工愚蠢”若出现在期刊出版领域就可能会遭遇以下尴尬:期刊同质化严重、期刊创新性匮乏、期刊自我评价与定位困难等。以选题策划、内容采集、内容写作、内容分发、效果反馈等相关出版生产环节为例,人工智能基于相关数据设计算法,通过一系列的量化指标进行筛选,可能会出现以下状况。(1)在选题上可能会过多地关注既有热词,从而缺乏前瞻性。而前瞻性才是科学研究改变世界、推动社会进步的重要支点。一窝蜂地追逐所谓的热点,只会造成期刊的同质化。(2)在内容采集上,计算机科学“重相关而轻因果”的数据搜集特征可能会造成内容采集数据的偏狭,影响信息收集的精准。(3)在内容写作上,有可能过于模式化、平面化、碎片化,缺乏创造性、因果关联性和深度复杂性。而在写作中,后者才是区别、评议作品的重要因素。著名作家韩少功曾在《当机器人成立作家协会》一文中探讨了人工智能与文学的关系问题,他认为机器人能胜任一些“类型化”写作,但在本质上,机器人写作只是“一种高效的仿造手段,一种基于数据库和样本量的寄生性繁殖,机器人相对于文学的前沿探索而言,总是有慢一步、低一档的性质,总是有只能作为‘二梯队’里跟踪者和复制者的性质……文学之所以区别于下棋和揪魔方等一般娱乐,就在于文学长于传导价值观。好作家之所以区别于一般‘文匠’,就在于前者总是能突破常规俗见,创造性地发现真善美,守护人间的情与义”[16]。因此,在内容写作上,树立嵌入伦理责任的技术观是在人工智能技术发展中应当思考的问题。(4)在内容分发上,这种依赖于数据的个性化和针对性的分发,很可能会导致不符合数据筛选条件、甚至是不在数据库范围内的潜在读者的隐形;或者因为滥用数据与数据推送,导致既有读者的反感,从而造成既有读者的流失。(5)在效果反馈阶段,利用算法搜集、分析、处理相关反馈数据,涉及数据占有量的问题。人工智能平台占有的数据越多,其得出结果的有效性越高;反之,其结果可能会与实际情况存在巨大偏差。而在实际工作中,仅以期刊为例,其发行渠道、发行量和读者定位等因素都决定了其受众有限,也必然会导致其反馈数据的有限。在有限的数据下进行相关分析所得出结论的可信度较低,而这会造成期刊自我评价与定位的困难。
2.1.2 人工智能生成物版权归属和责任认定的法理争议
假设有一天,就像微软小冰创作了100%人工智能诗集《阳光失了玻璃窗》[17],人工智能论文写作机器人完成了一篇100%人工智能科技论文(综述性论文也许会成为此领域的突破口),其知识版权是属于人工智能论文写作机器人这个人工智能生成物,还是论文写作机器人的制造商?又或者是机器人的购买者或使用者?抑或根本无所谓版权?此外,如果这些人工智能生成物创作的产品出了问题,其责任认定也是个问题。如《锦绣未央》剽窃案牵出了幕后“神器”——网文写作软件,该软件可一秒成文,37个小时能写1亿字,但其剽窃行为的责任归属该如何划定?《中华人民共和国著作权法》第十一条规定:“著作权属于作者,本法另有规定的除外。创作作品的公民是作者。由法人或者其他组织主持,代表法人或者其他组织意志创作,并由法人或者其他组织承担责任的作品,法人或者其他组织视为作者。”因此,从某种意义来说,此类事件版权归属和责任认定的根本争议是在法律上将人工智能定性为“工具”还是“虚拟人”,是“一个把伦理学、本体论和认识论高度纠缠在一起的问题”[18],而这种法理上的争议还有待界定与厘清。
2.1.3 大数据≠全数据
大数据不等于全数据。或囿于数据搜集条件、或囿于搜集者的认知、或囿于被调查者信息的隐私保护,相关大数据很可能只是碎片而非整体,这使得人工智能用以决策的数据依据先天不足,从而导致决策结果失准。比如在期刊发展中涉及的基础作者储备、审稿专家筛选就可能因为涉及个人隐私而影响数据收集和分析;又如在期刊精准推送中,可能囿于读者阅读习惯等相关数据的攫取规范与界限而影响数据占有与结果决策。
2.2 伦理挑战
2.2.1 信息裸奔下的数据安全
期刊运作的各个环节都会涉及到大量信息数据,比如期刊信息、作者信息、评价信息、读者信息、销量信息、用户行为信息等,这些信息往往涉及隐私。在人工智能时代,信息近乎裸奔,如何从法理上重新界定和保护隐私?期刊社如何占有数据但不侵权?如何运用数据但不控制数据以及数据背后的群体?数据提供者如作者、审稿专家、读者等如何破除“透明人”的思想顾虑并实现法理上的自我保护?这需要从人工智能技术、行业发展、法律、伦理等方面进行研究和探索。
2.2.2 算法不透明、不可解释性和不可追责
人工智能的“算法歧视”案例时有出现,比如App“大数据杀熟”。人工智能算法的不透明、不可解释性主要来源于以下3个方面:(1)人工智能算法的设计目的、数据运用、结果表征等受制于开发者、设计者的主观价值选择;(2)算法的占有数据可能受到既往的片面与偏颇数据的影响;(3)“深度学习”的开发使得算法越来越不透明。“深度学习”被业内人士戏称为“当代炼金术”:处理数据的神经网络,通常由数十个或者上百个(或者更多)神经元组成,并利用数层逻辑结构组织起来,运算过程极其复杂,智能程序给自己设定算法和权重,而最后为什么输出了某个决策,人类并不能完全理解[19]。
算法的不透明、不可解释性导致了算法的不可追责性。“人工智能造成的歧视和不公,在很大程度上是对监管、异议、上诉等‘免疫’的,因为它非常不透明。”[19]正如某些学者所言,代码的不透明加上算法本身的自我学习和适应能力,使得“将算法歧视归责于开发者”变得很困难[20]。在人工智能与期刊发展融合的过程中,题材的策划、稿件的选择、读者的定位、信息的反馈等要注意3个问题:(1)避免人工智能相关软件受制于既往的片面和偏颇数据,比如既往稿件的选择往往带有期刊选择倾向,那么以这个数据为基础进行的算法,当然会自带算法歧视;(2)避免人工智能相关软件受制于开发者与使用者的使用目标和评估体系,比如责任编辑既往的用稿倾向、对题材的好恶等;(3)避免人工智能相关软件因为自主学习、自我设定算法和权重,作出令人费解的决定,比如题材上因为追逐热点而忽略了前瞻性,又如因强调条件符合甚至在既有条件上作相应引申而放弃潜在优秀作者。
2.2.3 算法权力的边界不明
人工智能时代的一个显著特征就是数据具有话语权。“让数据说话”成为占据人们思维、解决所遇问题、甚至进行社会管理的重要决策方法,并最终形成了“让数据说话”的算法权力。这种算法权力因其对人的身份、认知、行为、倾向、情感乃至意志具有精准的认知与操控力而在政治、经济、文化领域时有越界。比如“剑桥分析”软件通过测验手段暗中获取用户私人信息并将其用于有针对性地投放政治广告等目的[21];又如某互联网企业的首席科学家曾坦承,大公司的产品常常不是为了收入而做,而是为了用户的数据而做,在某一个产品上收集的数据,会用于另一个产品并获利[22];至于文化领域,某些“抄袭神器”对创作的干扰、版权的侵犯,程式化写作机器对读者阅读品味的固化,个性化信息推送对读者阅读选择权的干扰甚至侵权也时有发生。于是,算法权力的边界问题日益成为学界关注的焦点。
要警惕“大数据的获得者和控制者把大数据作为一种不正当操控手段”[23],“机器需要给自己‘划线’,要让人工智能的制造者给自己的智能‘划线’”[19]。从伦理学角度来说,在人机混合系统发生的问题,往往不是人工智能技术本身的问题,而是人的问题。如何避免少数精英或大公司操控数据、控制他人?如何避免期刊在用稿、审稿、文章推送阅读等方面的越界干扰?如何使得占有大量数据的文献数据库与期刊实现双赢而非互相控制?这些问题都有待商讨。
3 人工智能与期刊发展融合的实践路径
人工智能与期刊发展的融合是涉及问题认识、经验总结、解决思路与实践范式的跨学科综合探索,是技术与伦理的双重共振与重构,其融合实践路径见图1。
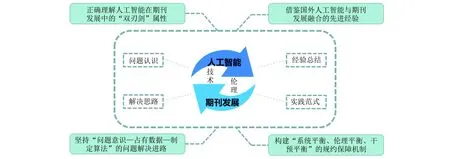
图1 人工智能与期刊发展融合的实践路径
3.1 正确理解人工智能在期刊发展中的“双刃剑”属性
正确理解人工智能在期刊发展中的“双刃剑”属性,对其可能提供的机遇和遭遇的困境从技术、心态、法律、伦理上做好积极的准备。比如人工智能对生产效率的提升与人类就业权的倾轧、数据带来的决策便利与数据依赖导致的“人工愚蠢”、人工智能生成物的创作与追责法律的空白、算法权力的权威与边界等。只有明白了人工智能在期刊发展中的“双刃剑”属性,才能为二者的高质量融合、人机系统的和谐存在、工具理性与价值理性的平衡创造条件。
3.2 借鉴国外人工智能与期刊发展融合的先进经验
他山之石,可以攻玉。我们应该主动借鉴美国等人工智能研究前沿国家在人工智能与期刊发展融合方面的典型案例、经验教训与发展启示,为解决本土问题拓展思路。这种经验探索往往立足技术,兼顾伦理,指向社会,惠及行业,大致可分为宏观层面的经验启示和微观层面的经验启示。
3.2.1 宏观层面的经验启示
(1)人工智能安全法理方面的经验。欧盟率先在数据和算法安全领域进行立法尝试,2016年4月27日欧洲议会通过、2018年5月生效的《一般数据保护条例》对个人数据的收集和存储使用规定了更高的透明度与更严格的管控。它规定商业公司有责任公开“影响个人的重大决策”是否由机器自动做出,且做出的决策必须“可以解释”(explainable)[19]。根据这项“史上最严的隐私条例”,最高违规罚金可达公司全球总收益的4%或2000万欧元[22]。在老牌科技出版巨头Elsevier、学术出版领域的内容分销商英捷特(Ingenta)等纷纷表现出对数据与信息的浓烈兴趣并加速占有时,这项条例的执行会有利于在期刊领域嵌入人工智能技术后,对作者、读者、审稿专家、科研成果等隐私或信息的保护,其在信息收集上的“最少必须”原则也会对大型学术出版集团形成的数字利维坦主义起到防范作用。(2)人工智能政策制定与规划执行方面的经验。在人工智能研究领域有着超级话语权的美国,对人工智能领域采取轻干预、重投资政策[24]。2016 年10 月,其发布的《国家人工智能研究与发展战略规划》专门论述了人工智能安全,提出人工智能服务于国家安全战略,以及对人工智能系统自身的安全和系统行为的可解释性等方面的保障措施[12]。人工智能期刊出版领域,比如Elsevier也是通过“不断收购(比如Mendeley、Plum)来为数据分析铺路,其中也包括一些强大的内容源定位系统(比如bePress、SSRN)”[25]。(3)人机系统出现问题后的法律追责。为应对人工智能的普遍应用可能对社会运行产生的冲击,美国立法机构已经着手考虑,对人工智能技术可能在刑事司法等领域的滥用予以必要规制[26],而这将对期刊出版领域的人工智能生成物创作作品的版权归属和责任认定提供法律依据。(4)对人机劳动关系的界定。德国政府在推行“改善劳动条件计划”中,规定有危险的岗位由机器人代替[24]。这对于人工智能嵌入期刊出版领域后,人机交互协作系统的分工与平衡具有参考价值。
3.2.2 微观层面的经验启示
微观层面的经验启示主要表现为人工智能最新技术在期刊出版领域的应用。(1)在期刊审稿领域的经验。2016年年底,Aries系统公司宣布将元文献计量智能(Meta Bibliometric Intelligence)集成到其学术刊物稿件和同行评审跟踪系统Editorial Manager中,以帮助科技出版商和编辑在同行评审期间利用人工智能估算一篇稿件的未来被引频次和影响。多项测试结果表明,该项技术在新稿件影响力评估的速度、准确性和一致性方面远远超过了人类的能力,尤其是在识别 “超级明星文章”——Top1%的高影响力论文时,它的准确性比同组编辑高2.2倍,这可以帮助编辑做出更加准确的论文出版决策[27]。(2)在期刊信息采集与搜索领域的经验。随着人工智能时代的到来,Elsevier已经将其发展战略有意识地从内容许可转向预印本、分析、工作流和决策支持,将自己描述为一个“信息和分析”公司,这些努力使其成为开放获取市场的重要角色[28],其所有的期刊和图书资源都支持文本与数据挖掘(Text and Data Mining)。(3)在期刊内容分发领域的经验。学术出版商泰勒-弗朗西斯(Taylor & Francis)与丹麦人工智能创业公司UNSILO合作,“目标是基于在线用户已经阅读的内容向他们推荐其他内容,最终实现让任何内容都能通过机器学习与知识网络建立语义联系”[29]。这些具有行业领先地位的科技出版单位对人工智能技术极具前瞻的选择、应用、反馈和调整,为中国期刊在发展过程中嵌入人工智能技术提供了极具参考价值的借鉴样本。
3.3 坚持“问题意识—占有数据—制定算法”的问题解决进路
问题作先行,数据是基础,算法是关键。在人工智能与期刊发展融合过程中,须进一步普及“计算思维”。我们应坚持问题导向,搜集、分析数据,设计合理算法,从而解决问题。人工智能与期刊发展融合过程中遇到的各种技术、法律、伦理问题都可以尝试按照这种问题解决进路予以解决。
3.4 构建“系统平衡、伦理平衡、干预平衡”的规约保障机制
要正确处理人工智能与期刊发展融合过程中的3个平衡:(1)人机交互协作的系统平衡;(2)工具理性与价值理性之间的伦理平衡;(3)涵盖“干预原则、干预程度、干预路径”[30]3项内容的干预平衡。
3.4.1 人机交互协作的系统平衡
人工智能在期刊领域的嵌入重新定义了劳动主体,人机交互协作系统成为新的劳动主体登上历史舞台。随着人工智能在期刊用户系统、内容生产系统、分发推送系统等领域的覆盖,人工智能与智人从分工到权责、从认知到行为、从决策到后果,都相互渗透、交织、粘连,人们越来越难以厘清某种认知、行为、权利、责任应该归属于某一智人或是某一人工智能,而更易于见到上述因素背后的人机交互协作系统,因此人机交互协作系统的平衡实现对期刊的智能化具有重要意义。
3.4.2 工具理性与价值理性之间的伦理平衡
技术的颠覆往往引发伦理的共振。人工智能对期刊出版领域的强势介入,在显示技术力量的同时也对伦理提出了新要求。比如数据收集与数据共享之间的平衡,占据大量期刊数据资源的内容分发商对学术成果传播和商业利益攫取的平衡等。2012年,学术界掀起了对Elsevier的大型抵制运动,16000余名科学家在名为“知识的代价”(The Cost of Knowledge)的网站上签署了不给Elsevier旗下期刊投稿、审稿和担任编辑的承诺书,以期推动科研成果变得更透明化和更易获取。“知识的代价”到底该由谁决定?又该如何定价?工具理性与价值理性之间的伦理平衡该如何实现?这都值得我们认真思考。
3.4.3 涵盖干预原则、干预程度、干预路径3项内容的干预平衡
就干预原则而言,至少应该包括开放包容、公平正义、安全稳定、合理引导4项内容。人工智能技术嵌入期刊领域方兴未艾,技术上的无限可能、伦理上的公平正义、社会意义上的安全稳定、策略上的合理引导是生成这一干预原则的重要原因。
就干预程度而言,宏观调控、可控监管、保持活力是其努力方向,而对干预程度的合理把握是人工智能与期刊融合成败的关键。它以对人工智能技术介入期刊的科学理性认识为基础,以对人工智能技术介入期刊的行业监管、法律规约、伦理构建为抓手,以对人工智能技术介入期刊的合理期待为依归,宏观调控、可控监管、保持活力是合理把握干预程度的3个重要旨归。
就干预路径而言,主要有技术路径、法律路径和伦理路径。技术先行、法律保障、伦理规约,只有三管齐下,齐头并进,才能保证人工智能与期刊融合健康发展。
4 结语
人工智能与期刊发展的深度融合,是期刊行业因为技术进步做出的主动选择,是行业发展的大势所趋,其融合过程也是技术与伦理的双重共振与重构过程。探讨人工智能技术与期刊融合过程中出现的机遇与挑战,其目的不是为了禁止使用该技术,而是为了更好地控制该技术;不是为了在工具理性和价值理性之间站队,而是促使二者互补平衡;不是为了终结,而是为了更好的解放。正如学者所言,“人工智能是一场开放性的人类科技—伦理试验,其价值反省与伦理追问具有未完成性”[15]。面对这一进行时态,开放的心态、审慎的态度、主动的介入、乐观的期待应该是我们迎接人工智能时代到来的最合适姿态。
猜你喜欢
军事运筹与系统工程(2022年1期)2022-11-15
质量安全与检验检测(2022年2期)2022-11-13
今日农业(2021年19期)2022-01-12
中老年保健(2021年11期)2021-08-22
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
现代出版(2020年3期)2020-06-20
中国现代医药杂志(2020年10期)2020-01-08
商界(2019年12期)2019-01-03
IT经理世界(2018年20期)2018-10-24
小康(2017年16期)2017-06-07
