
基于机器视觉的水下河蟹识别方法
2019-04-01 12:28赵德安刘晓洋孙月平吴任迪洪剑青阮承治
农业机械学报 2019年3期
赵德安 刘晓洋 孙月平 吴任迪 洪剑青 阮承治
(江苏大学电气信息工程学院, 镇江 212013)
0 引言
我国河蟹养殖业增长迅速,养殖面积约47万hm2,年产量约80万t,总产值超过500亿元,现已成为中国渔业生产中最具潜力的支柱产业[1]。但是相关河蟹养殖技术以及自动化养殖机械方面仍然比较落后,不能满足工业化、规模化的养殖需求[2]。其中河蟹的自动化投饵是工业化养殖的重要发展方向。
目前国内外有关水下河蟹识别研究较少,但是机器视觉在渔业生产中的应用研究已经得到部分学者的关注。JIANG等[3]采用粒子滤波算法实现了实验室环境下河蟹的自动视频跟踪,但并未涉及河蟹的识别。王勇平等[4]和胡利永等[5]采用摄像头对鱼群进食的水面进行监控,通过分析鱼群抢食时造成的水花和波浪确定进食面积变化,从而实现精确投饵。马国强等[6]采用K-均值聚类算法识别海中水箱养殖的石斑鱼,在图像清晰、干扰较小的情况下能够达到较高的识别率。
河蟹主要在池塘底部活动,且水质条件较差,水中存在气泡和悬浮物等杂质。因此水体会对光线产生较大的衰减作用,对采集图像的质量有较大影响。此外河蟹的形状与姿态存在较大差异,这给河蟹识别带来了难度,传统目标识别方法难以满足河蟹的识别需求。近年来深度卷积神经网络的迅猛发展,为水下河蟹的识别提供了新的方向[7-8]。现已有学者将此类基于卷积神经网络的目标检测框架应用于农业和渔业生产中,并取得了较好的效果[9-11]。傅隆生等[12]采用1998年提出的经典卷积神经网络LeNet成功地实现了猕猴桃的识别。熊俊涛等[13]采用更快速卷积神经网络(Faster regions with convolutional neural networks,Faster RCNN)实现了自然环境下绿色柑橘的识别。薛月菊等[14]采用YOLO V2实现了绿色芒果的识别。
为实现自动投饵船的精确投饵,本文提出基于机器视觉的水下河蟹识别方法。针对水下环境采用优化的Retinex算法对水下图像进行增强,以提高图像对比度,增强河蟹在图像中的细节表现,然后采用最新的YOLO V3深度学习模型对河蟹进行识别。为科学确定投饵量以及根据河蟹分布进行精确投饵提供可靠的反馈信息。
1 图像采集与增强
1.1 图像采集
实验样本图像采集于江苏省常州市长荡湖河蟹养殖基地。图像采集装置是广州海豹光电公司研发的游弋式浑浊水下监控系统,型号为HB-HZSJC-AK。该系统由船体和控制箱两部分组成。船体如图1a所示,在船体下方安装有可伸缩水下摄像头以及LED辅助照明光源。摄像头采集的图像和视频通过无线网络传输至控制箱,如图1b所示。在傍晚河蟹觅食时进行图像采集,如图1c所示。所采集图像格式为jpg,图像分辨率为960像素×576像素。

图1 图像采集系统Fig.1 Image acquisition system
1.2 图像增强
水下摄像头采集的图像如图2a所示。由于水中光线衰减较大造成图像对比度低,同时由于受到水中杂质等影响使得图像较为模糊。因此,首先需要对图像进行必要的增强,以便于在后续识别中提取河蟹特征。水下图像增强方法主要分为3类:①基于空间域的图像增强算法,如对比度拉伸、直方图均衡等。②基于频域的图像增强方法,如同态滤波[15-16]、小波变换等。③基于颜色恒常性理论的增强方法,如自动白平衡、Retinex算法[17-18]等。
实验分别采用全局直方图均衡、自适应直方图均衡、同态滤波和Retinex算法对水下图像进行增强。因河蟹与背景并没有显著的颜色差异,因此将拍摄的彩色图像转换为灰度图像,并针对灰度图像进行增强。全局直方图均衡的增强效果如图2b所示,从图中可以看出该方法对光照不均图像的增强效果较差,易造成局部过亮从而丢失部分图像信息。自适应直方图均衡的增强效果如图2c所示,自适应直方图均衡通过改变图像局部对比度增强了图像细节同时也克服了全局直方图均衡的缺陷,但是增强效果并不显著。图2d是同态滤波的效果图,增强后的图像虽然在视觉上更加纯净,但是其对比度弱于图2c。相对于图2c,Retinex算法的增强效果(图2e)更差,且图像整体偏亮。因此,上述4种图像增强方法均未达到预期的增强效果。

图2 不同方法增强效果对比Fig.2 Comparisons of different image enhancement methods
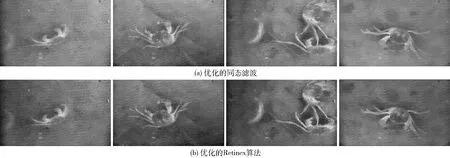
图3 优化算法的增强效果对比Fig.3 Comparisons of optimized image enhancement methods
为了达到理想的图像增强效果,结合上述结果,采用自适应直方图均衡分别对同态滤波和Retinex算法进行优化。优化后的图像增强效果如图3所示。对比图3a和图3b可以看出,经优化的同态滤波算法增强后,图像中的暗区域都得到了相应增强;而优化的Retinex算法对细节不显著的区域增强效果较优化的同态滤波算法差。河蟹作为图像检测对象,自身具有大量的细节特征。两种方法对检测对象河蟹的增强效果是相当的,优化的Retinex算法对细节不显著区域的增强效果较差,能够减少后续识别的干扰,因此选择优化的Retinex算法作为水下图像的增强算法。
Retinex算法将图像理解为入射图像和反射图像的乘积,即
T(x,y)=G(x,y)H(x,y)
(1)
式中T——给定图像
G——反射图像
H——入射图像
x、y——图像中像素的横、纵坐标值
入射图像对应图像的低频部分,而反射图像对应图像的高频部分。优化的Retinex算法对水下图像进行增强的流程如图4所示。首先将原图转换为灰度图像,然后通过频域低通滤波估算出入射图像,接着将灰度图像和入射图像转换到对数域相减,从而得到反射图像,最后采用自适应直方图均衡再次对反射图像进行增强。其中,对数变换是为了实现式(1)中入射图像和反射图像的分离,以便于通过减法操作得到反射图像。

图4 Retinex算法增强图像流程图Fig.4 Flow chart of image enhancement by Retinex
2 水下河蟹识别
YOLO是近年来被广泛应用的目标检测深度学习框架[19],本文采用最新提出的YOLO V3对河蟹进行识别定位。
2.1 建立数据集
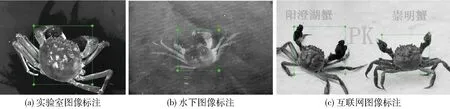
图5 数据集样本标注Fig.5 Labelled images in dataset
深度学习对于训练样本的数量要求较大,数据量的多少会直接影响河蟹的识别精度。为建立可供YOLO V3训练和测试的数据集,实验通过多渠道采集实验图像。在长荡湖河蟹养殖基地采集的水下河蟹图像共计1 731幅,抽取其中1 500幅(图5b)进行图像增强,然后用于YOLO V3模型的训练和性能测试,剩余图像用于后续的对比实验。为了进一步丰富数据集并提高网络泛化能力,在实验室环境下采集河蟹图像1 000幅(图5a),此外在互联网上下载河蟹图像1 000幅(图5c)。共计3 500幅河蟹图像用于YOLO V3模型的训练和测试,其中70%用于训练,30%用于测试。但是仍然达不到模型训练的数量要求,因此需要对数据集进行扩增。通过沿纵向和横向翻转图像、平移图像、缩放图像、添加高斯噪声、旋转图像以及裁剪图像等方法,对图像数据集进行扩增。
完善的数据集除了包括大量的样本图像,还需要对图像中的检测目标进行标注。实验采用矩形框对河蟹进行标注,但是河蟹具有1对蟹螯和4对蟹腿,若将其全部框选进行标注则会使得标注区域包含大量背景。背景中存在的无用特征会干扰模型的训练和性能表现。因此,人工标注河蟹时只关注河蟹的主要特征,主要对河蟹的身体和1对蟹螯进行框选。具体标注情况如图5所示,标注框包含了河蟹的身体和大部分蟹螯以及小部分蟹腿。图像标注信息采用PASCAL VOC数据集的格式进行保存,具体包含所标注图像在硬盘中的地址、矩形标注框左上角在图像中的坐标、标注框的长和宽以及标注的类别。因为河蟹的颜色并不是其显著的特征,为了减少数据量并提高YOLO V3的训练和识别效率,实验室采集的图像和网络下载的图像均转换为灰度图像。
2.2 YOLO网络结构
YOLO深度卷积神经网络一直以其识别的快速性受到广泛关注,但是其目标检测的准确性还相对欠佳。近几年,YOLO模型通过自身不断优化并吸收单次多类检测器(Single shot multibox detector,SSD)、Faster RCNN等其他目标检测模型的优点已经经历了3个版本的迭代。最新的YOLO V3在识别速度和准确性上都有了显著改善,并被应用于多个领域。不同于Faster RCNN、区域全卷积神经网络(Region-based fully convolutional network, R-FCN)等采用区域建议和分类器相结合的算法思想,YOLO将图像分为S×S个网格,通过回归方法一次性预测所有网格所含目标的包围框、置信度以及类别概率。因此,YOLO能够在识别速度上远超其他目标检测网络,其识别速度能够满足实际应用场景对实时性的要求。
YOLO V3网络结构如图6a所示,其采用类残差网络构造[20]的DarkNet-53作为基础网络对目标特征进行学习。残差网络的基本结构单元如图6b所示,该结构使得网络能够不断加深且不会造成梯度消失或梯度爆炸,从而加强对图像特征的学习,提高识别的精确度。从图6中可以看出,YOLO V3抽取3个不同尺度的图像特征进行回归预测,提高了对不同尺度目标的检测能力。该网络已经在COCO等数据集上进行了相应的训练,但为了提高其对水下河蟹的识别速率和准确性,实验对网络结构进行了必要的调整。原网络输入是尺寸为416像素×416像素×3通道的彩色图像,这使得YOLO V3的首个卷积层必须采用3维卷积核,以适应对彩色图像的识别。因为所有图像为灰度图像,因此采用2维卷积核替代3维卷积核,从而可以将首个卷积层的权值数量减少到原来的1/3,从而提高网络训练和识别的效率。此外,水下河蟹的识别中需要检测的目标只有河蟹1个类别,因此通过修改YOLO V3的输出类别数量,可以极大地减少网络所预测张量的维度,使得每个尺度所预测张量的长度仅为18,从而减少不必要的运算量。
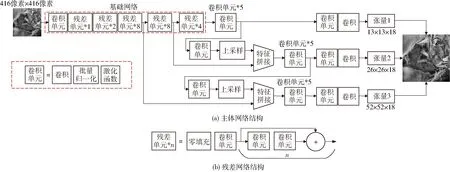
图6 YOLO V3网络结构Fig.6 YOLO V3 network structure
2.3 河蟹检测网络的训练
首先将数据集中的图像样本全部转换为416像素×416像素,以便于输入网络进行训练。训练时以128幅图像为一个批次进行小批量训练,每训练一批图像,权值进行一次更新。权值的衰减速率设为0.000 5,动量设置为0.9,初始学习率设为0.001。模型训练的硬件平台配置为2个Intel E5-2683处理器,4个显存为11 GB的 Nvidia GTX1080Ti 显卡和2根32 GB内存条。共对YOLO V3模型进行了6 000次迭代,网络损失函数L的输出如图7所示。为了清晰地展示损失值的变化,将纵坐标设置为lg(L+1)。从图7中可以看出,在前250次的迭代中损失值迅速下降,在250次到2 000次迭代中损失值缓慢减小,而2 000次后损失值保持稳定没有显著变化。在训练过程中每迭代1 000次输出一个模型,因此本次训练共输出6个模型,依次为模型1~6。

图7 损失函数的输出结果Fig.7 Output result of loss function
为选取合适的模型,需要采用多种指标对模型的性能进行评判。常用的评价标准包括交并比I,即人工标记框与网络预测框的交集与并集的比例, 准确率P、召回率R、F1分数与平均精度均值Q的计算公式为
(2)
(3)
(4)
(5)
式中U——真正,即网络预测的正样本中包含正样本的数量
V——假正,即网络预测的正样本中包含负样本的数量
W——假负,即未被网络预测的正样本数量
J——精度均值函数,即准确率P与召回率R所构成P-R曲线与横纵坐标所围成的面积
C——所检测目标类别的数量
k——类别序号
实验只需要检测河蟹这一类目标,因此,本文C取1。其中,交并比的阈值选择是直接影响准确率和召回率的重要因素。该阈值越大,准确率越大,召回率反之。实验目的为检测河蟹的数量和分布,因此对交并比的要求不高,但为了保证检测的准确率,交并比也不能过低,因此选择交并比I>50%作为判断目标是否被正确检测的标准。表1列出了每个模型相应的性能参数。从表中可以看出,模型1性能最差,而模型3~6性能较好且没有显著差异,因此,只在后4个模型中选择合适的模型进行河蟹识别。为了对4个模型的性能进行恰当的排序,需要明确性能参数的优先级。实验采用的性能参数优先级由大到小为Q、F1、R、P、I。Q是对模型性能衡量最为全面的参数,排在首位。按照此优先级进行排序,模型5的性能最佳,只在准确率和交并比上略差于其他模型。因此选择模型5对水下河蟹进行检测。

表1 输出网络模型的性能参数Tab.1 Performance parameters of output network model %
3 实验与讨论
3.1 不同类型河蟹的识别
为了进一步测试所选取的网络模型对河蟹的识别能力,对实验室和水下采集的河蟹图像以及水下不同尺寸河蟹的图像分别进行识别。实验室环境下采集的河蟹图像背景简单,干扰少,河蟹特征清晰。通过对比所选模型对水下河蟹与实验室环境下河蟹的识别效果,可以看出水下环境对河蟹识别的影响。此外,由于池塘底部的起伏造成拍摄的河蟹图像尺寸存在较大差异,且YOLO V3模型对不同尺寸的目标识别能力存在一定的差异,因此对水下河蟹按尺寸进行分类,验证所选取模型对不同尺寸河蟹的识别能力。河蟹尺寸按照河蟹占图像总面积的百分比进行分类,百分比为5%及以下的河蟹为小尺寸河蟹(图8a),百分比5%~20%的河蟹为中尺寸河蟹(图8b),百分比20%及以上的河蟹为大尺寸河蟹(图8c)。
表2列出了所选取模型对不同类型河蟹识别结果的相关统计参数,表中“数量”表示测试图像中人工统计的河蟹数量。从表中可以看出,所选模型对实验室采集的河蟹图像的识别准确率100%,既没有误识别也不存在漏识别,并且交并比也同样很高。这说明所选模型在简单背景下能够保证超高的识别准确率。从所选模型对水下图像的识别统计参数可以看出,水下环境对河蟹的检测产生了较大的干扰,使得各项参数都有所下降,而其中小尺寸河蟹的识别效果最差。一方面是因为小尺寸河蟹与摄像头和光源距离较远且光线在水中衰减过快,使得小尺寸河蟹图像较为模糊,特征不明显,另一方面是因为YOLO V3模型自身对小尺寸目标的检测效果稍有欠缺。中尺寸河蟹的识别效果较为理想,识别准确率能够达到较高水平。而大尺寸河蟹图像中河蟹的特征清晰,其识别效果近似于实验室环境下的识别效果,水下环境对所选模型的识别并未产生显著影响。

图8 不同尺寸的河蟹图像Fig.8 Crab images in different sizes

类型数量I/%UVWP/%R/%F1/%实验室图像9693.869600100100100水下图像 25381.2623182296.6591.3093.90小尺寸河蟹6873.825341592.9877.9484.80中尺寸河蟹13384.621263797.6794.7496.18大尺寸河蟹5285.34521098.1110099.05
图9展示了部分识别错误的河蟹图像,图9a和图9c是因为网络所预测的目标位置与实际目标位置偏差较大被判断为识别错误。图9b存在漏识别,下方的河蟹没有被成功检测,而图9d则存在误识别。
3.2 不同方法的检测效果对比
为进一步验证YOLO V3对于水下河蟹识别的可靠性,分别与基于区域建议机制的Faster RCNN[21]和传统的梯度方向直方图(Histogram of oriented gradient,HOG)+支持向量机(Support vector machine,SVM)[22]的方法进行比较。Faster RCNN经历了从RCNN、Fast RCNN等多个版本的迭代,通过加入区域建议网络(Region proposal net, RPN)实现了端到端的目标检测,使得识别速率和准确率都得到了较大的提高。HOG+SVM最早用于行人检测,该方法通过多尺度滑窗提取图像的HOG形状特征并采用SVM对特征向量进行分类,对于不规则形状物体的检测具有较好的效果。这两种方法与YOLO V3在相同的数据集上进行训练并在同一硬件平台上运行,该硬件平台配置为i5-7400 处理器,主频3 GHz,8 GB内存。

图9 部分存在错误识别的图像Fig.9 Examples of falsely detected crabs
表3列出了3种方法对于水下河蟹识别效果的统计参数。从表中可以看出,Faster RCNN的识别效果与YOLO V3相当,且略优于YOLO V3的识别效果,但是其识别速率与YOLO V3相差较大。HOG+SVM对于河蟹的识别效果最差,存在较多的漏识别和误识别且识别速率也最慢。通过具体分析错误识别的图像可知,HOG+SVM对于较为模糊的图像识别能力较差,从而产生较多的漏识别。此外,不同于行人在图像中的方向具有一致性,河蟹在图像中的姿态和朝向存在较大差异,这使得HOG特征分布离散,SVM难以分类,因此造成较多的误识别。综合识别效果和运行速率来看,YOLO V3是3种方法中最适合用于搭载在河蟹自动投饵船上对水下河蟹进行识别的算法。

表3 不同方法识别统计参数Tab.3 Statistical parameters of different methods
4 结论
(1)针对水下环境采集图像质量差的特点,提出了有效的水下图像增强方法。通过对比多种图像增强方法,最终选择优化的Retinex算法对水下河蟹图像进行增强,使得水下河蟹特征更加明显,为后续模型训练和特征学习提供了基础。
(2)基于深度卷积神经网络的YOLO V3模型目标检测框架,通过修改网络的输入输出构建适合河蟹识别的网络结构,并构建数据集对模型进行训练和性能测试,最终输出模型的平均精度均值达86.42%,对水下河蟹识别准确率为96.65%,召回率为91.30%。
(3)对比了所选训练模型对不同环境下河蟹的识别效果,表明YOLO V3模型在河蟹特征清晰、环境干扰小的情况下能够实现接近100%的识别精度,对水下小尺寸河蟹这类特征模糊、干扰较多的情况识别率较低。
(4)通过与Faster RCNN、HOG+SVM进行河蟹识别效果对比,只有YOLO V3能够在保证识别效果的同时确保识别速率。在同一硬件平台上YOLO V3识别速率达10.67 f/s。
猜你喜欢
当代水产(2022年8期)2022-09-20
当代水产(2022年3期)2022-04-26
China’s foreign Trade(2021年6期)2021-12-26
北京航空航天大学学报(2021年9期)2021-11-02
今日农业(2021年1期)2021-03-19
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
汽车与新动力(2017年3期)2017-06-29
中华奇石(2015年7期)2015-07-09
