
基于SA-SVM的中文文本分类研究
2019-04-01 09:28郭超磊陈军华
计算机应用与软件 2019年3期
郭超磊 陈军华
(上海师范大学信息与机电工程学院 上海 201400)
0 引 言
文本分类,就是利用计算机相关技术将具有相同特征的文本信息根据文本内容自动划分到预先设定好的文本类别体系中的过程[1]。众多学者在研究文本分类的过程中,提供了许多优秀的分类算法,钟将等[2]提出一种改进的KNN文本分类算法,介绍KNN文本分类算法,并基于LSA降维和样本密度对KNN进行改进;Shathi等[3]将贝叶斯算法应用于文本分类中;Bahassine等[4]使用决策树算法对文本进行分类;Goudjil等[5]采用SVM算法对文本分类进行技术研究。经过大量实验表明,在中文文本分类上,SVM具有较强的泛化能力。基于SVM的文本分类性能与其惩罚因子C和核函数参数σ等密切相关,直接影响文本分类精度[6-7]。
选择SVM的参数是一个优化问题,近年来,国内外学者提出了很多优化SVM参数的方法。庄严等[8]提出了基于蚁群优化算法(ACO)的支持向量机选取参数算法;陈晋音等[9]提出了基于粒子群算法(PSO)的支持向量机的参数优化;王克奇等[10]采用遗传算法(GA)优化支持向量机参数。ACO算法的收敛速度较慢易陷入局部最优,PSO算法易早熟收敛且局部寻优能力较差,GA算法实现比较复杂,需先对问题进行编码,然后再对最优解进行解码,搜索速度较慢。模拟退火算法(SA)也是一种启发式算法[11],能较强地跳出局部最优,提高全局寻优能力。
本文提出一种基于模拟退火算法优化SVM参数的方法,并应用于中文文本分类中。利用SA良好的寻优性能构建的SVM中文文本分类器,与朴素贝叶斯、KNN算法、决策树算法、逻辑回归算法构建的分类器相比,该分类器能达到更好的分类效果,具有更强的鲁棒性。
1 相关理论
1.1 模拟退火算法
模拟退火算法[12]来源于材料统计力学的研究成果,它引入固体退火过程的自然机理并适当引入随机因素,在整个解邻域范围内随机性地取值,提高全局寻优能力,有效地解决众多组合优化问题。
引入Metropolis准则到优化过程,以最大化目标函数为例,对于某一温度Ti和优化问题的一个解x(k),可以生成x′。接受x′作为下一个新解x(k+1)的概率为:
(1)
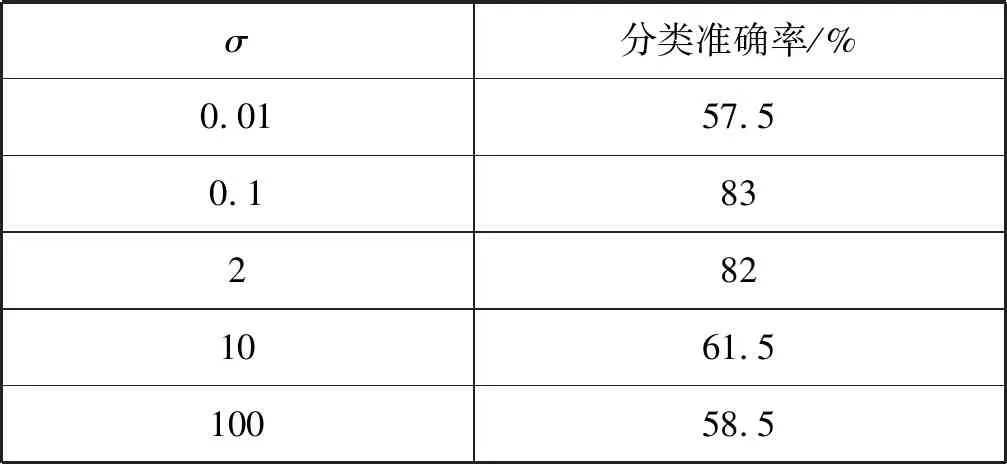
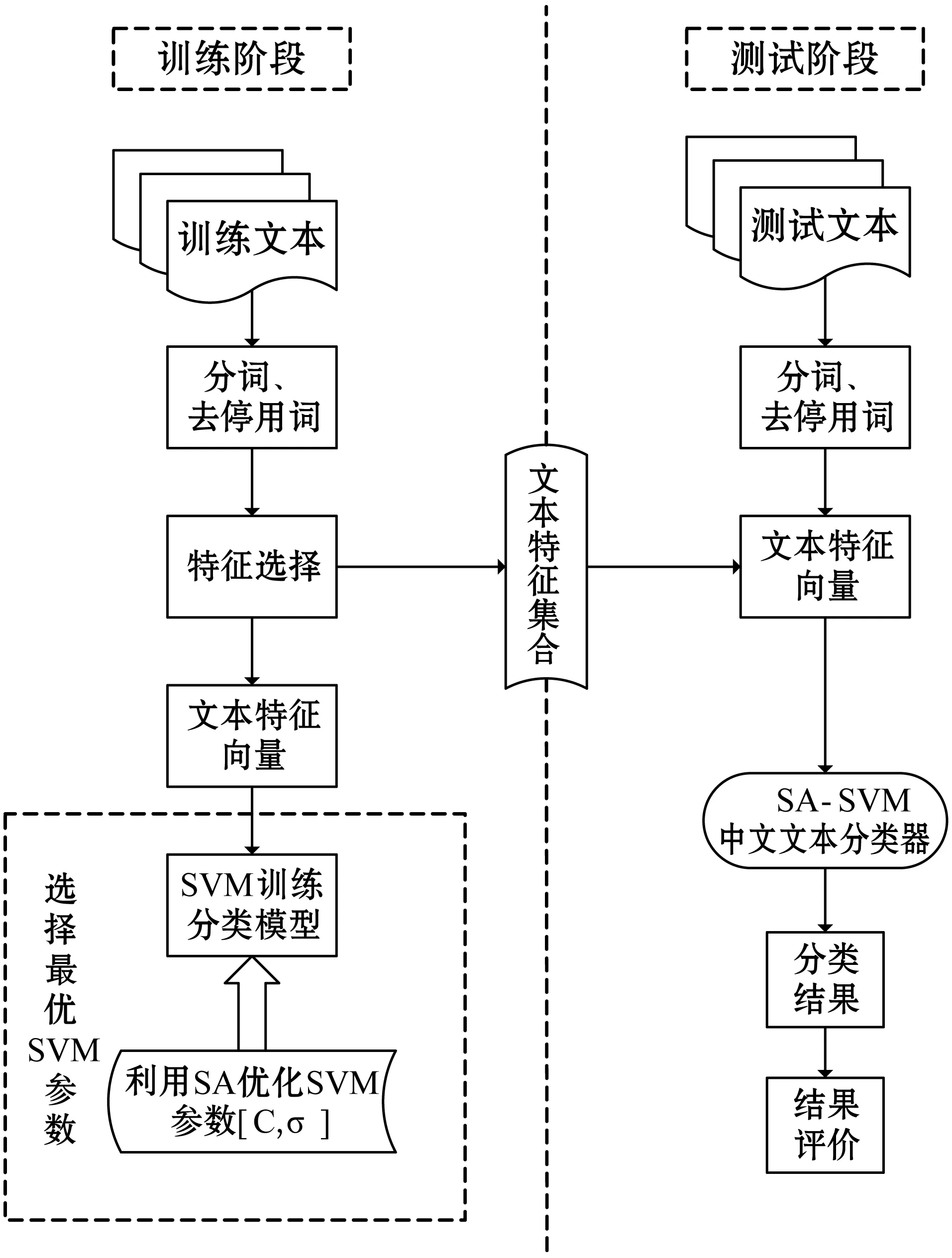
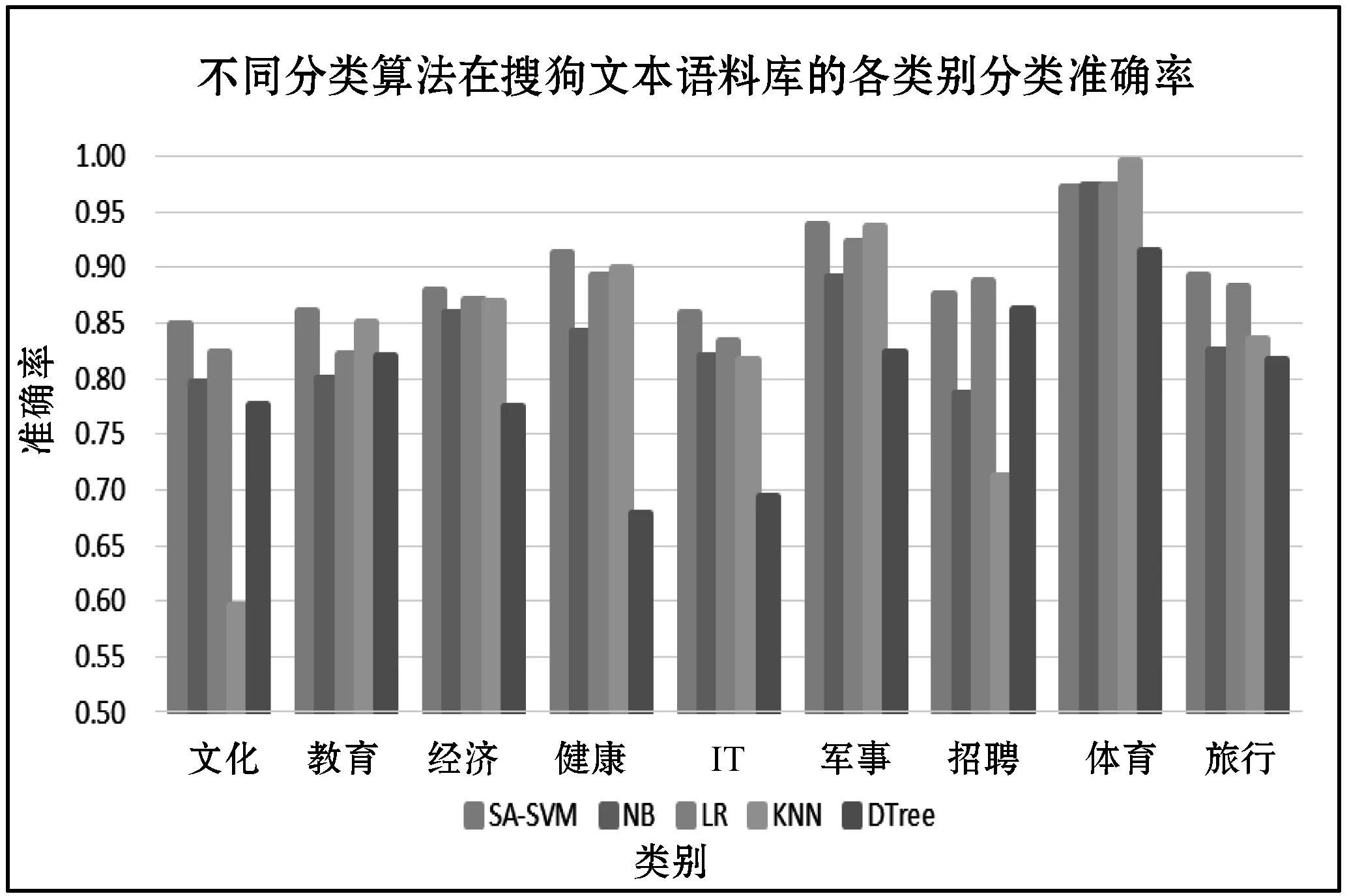
在温度Ti下,经过很多次的转移之后,降低温度Ti,得到Ti+1 对于数据集D={(x1,y1),(x2,y2),…,(xn,yn)},其中xi∈Rn,并表示输入,yi表示对应输出,n为输入样本的维数。SVM分类目标是找到一个超平面,这个超平面能将所有样本分开,并使样本之间的距离尽可能最大。即有: y=ωTΦ(x)+b (2) 式中:Φ(x)为标准正态分布函数,ω表示权值向量,b表示偏移向量。 求解最优超平面,就是针对所给定的数据集样本,找到权值向量ω和偏移向量b的最优值,使得权值代价函数最小化,且正例和反例之间的间隔最大。对于式(2)而言,难以对超平面参数ω和b直接求解,因此利用增加非负的松弛因子将式(2)转变成二次优化问题: (3) s.t.yi(ωΦ(xi)+b)≥1-ξiξ≥0,i=1,2,…,n 式中:C为惩罚因子,C>0;ξi表示松弛因子。将最少错分样本和最大分类间隔折衷考虑,就能得到广义上的最优分类面。 通过引入拉格朗日乘子将式(3)转化为对偶问题,以便于更好地求解,公式如下: (4) 式中:αi为拉格朗日乘子。 对式(4)进行求解得到αi值,那么ω为: ω=∑αiyiΦ(xi)·Φ(x) (5) 最终,SVM相应的分类决策函数为: f(x)=sgn(αiyiΦ(xi)·Φ(x)+b) (6) RBF函数具有收敛域宽、参数少、通用性好等优点,是一个很理想的分类依据函数,因此采用RBF函数建立SVM,公式如下: (7) 式中:σ为RBF核函数参数。 SVM进行分类的基本流程可归纳为:首先将输入的SVM向量映射到一个特征空间,紧接着在这个特征空间中寻找优化的线性分界线,于是就构建出了一个可分离类别的超平面,使不同的类别正确分开。SVM的训练过程实质上就是寻找全局最优解。 为了验证惩罚因子C和核函数参数σ对SVM分类性能的影响,随机选择四类3 306个文本作为训练集。建立分类SVM模型,并选取适当数目的文本作为测试集,分析不同C和σ对SVM分类精度的影响,具体结果如表1、表2所示。 表1 C=1时的分类结果 表2 σ=1时的分类结果 从表1和表2的结果可知,在相同的训练集、测试集下,惩罚因子和核函数参数不同,SVM分类准确率不同,这表明C和σ的取值影响基于SVM的文本分类结果,要获得最优的SVM文本分类模型,找到最优的C和σ值是关键。 SA优化SVM的惩罚因子C和核函数参数σ的主要判定是取得更高的文本分类准确率,在最优参数[C,σ]处能取得最高的分类准确率,故最大化目标函数为F=Vprecision(C,σ)。 相关设置如下: (1) 设置温度T的初始值:SA算法的全局搜索性能受温度初始值的影响,若初始值高,则全局搜索能力强,但需大量时间进行计算;反之,虽可减少时间,但会影响全局搜索性能。在具体操作时,T的初始值可根据实验结果进行灵活调整。 (2) 设置退火速度(内循环每个温度的迭代次数):SA算法的全局搜索性能同时也受退火速度的影响,若在某个温度下充分搜索,需要时间代价,在具体执行时,要根据实际问题设置合理的退火速度。 (3) 设置温度管理:权衡计算复杂度,通常的降温方式为T(k+1)=αT(k),k为降温次数,α一般取较接近1的正常数。 (4) 设置初始解和解的搜索范围:SA算法具有优良的健壮性,求得的最优解不受初始解的影响,可在解空间内随机设置初始解。不同的数据集的最优参数[C,σ]范围不同,实际应用中可根据实验结果进行灵活调整。 (5) 设置记忆存储器:在搜索过程中,SA算法由于执行概率接受环节,有可能遗漏当前取得的最优解,增加记忆存储器,存储搜索过程的中间最优解,并及时更新。 (6) 设置终止条件: ① 内循环终止条件:当前状态下连续若干个新解都未被接受或达到迭代次数。 ② 外循环终止条件:连续若干次降温所获得的最优解均不变或T SA优化SVM参数的过程具体操作描述如下: (1) 初始化温度T,设置终止温度Tmin,设置降温系数α。 (2) 产生随机初始解[C0,σ0](是算法迭代起点),并以此作为当前最优解[Cbest,σbest]=[C0,σ0],计算目标函数值F(Cbest,σbest)。 (3) 设置每个T值的迭代次数L;对l=1,2,…,L做第4至第6步。 (4) 在可行解空间内,对当前最优解作一次随机扰动,利用状态产生函数生成一个新解[Cnew,σnew],并计算其目标函数值F(Cnew,σnew)以及目标函数值增量Δf=F(Cnew,σnew)-F(Cbest,σbest),其中F(C,σ)为优化目标。 (5) 采用状态接受函数,判断是否接受新解:若Δf>0,则接受[Cnew,σnew]作为新的当前解;否则按式(1)中Metropolis准则判决,以概率p接受[Cnew,σnew]为当前最优解。若接受,设置当前状态为[Cnew,σnew],存入记忆存储器;反之,当前状态为[Cbest,σbest]。 (6) 判断是否满足内循环终止条件,若是,输出当前解为最优解并结束此次迭代,转入(7);否则转入(4)。 (7) 降温。根据设置的降温系数α进行降温,取新的温度T=αT(其中T为上一步迭代的温度)。 (8) 判断满足外循环终止条件,退火过程终止,转入(9);否则转入(3); (9) 输出当前最优解与记忆存储器的中间最优解比较,找到最优解[Cfinal,σfinal],算法结束。 基于SA-SVM的中文文本分类过程如图1所示。 图1 基于SA-SVM的中文文本分类过程 采用Python的第三方库jieba分词对数据集进行分词处理,然后去除停用词。 利用TFIDF进行权重计算,TF指的是特征词在文本中出现的绝对频率,而IDF指的是特征词在文本中的文本内频率。常用的TFIDF公式如下: (8) 利用DF进行特征选择,文档频率计算训练集中包含特征项t的文本数目。设|D|为训练集中的文本总数,di为其中的一个训练文本,于是有: (9) 若t∈di,则p(t,di)=1;若t∉di,则p(t,di)=0。 DF值低于某个设定阈值的特征词属于低频词,它们可能不含或者含有很少的文本分类信息,可以在原始特征空间剔除这样的特征项,既能降低特征空间的维度,还有可能提高文本分类的准确率。 采用分类常用的评价指标:准确率P、召回率R和F1度量,具体表示如下: (10) (11) (12) 为验证SA-SVM中文文本分类的有效性和可行性,采用SA-SVM对中文文本进行分类实验。实验的硬件平台:操作系统为Windows 10专业版,处理器为Inter(R) Core(TM) i5-3210M CPU @2.50 GHz,内存为10 GB,硬盘为256 GB;软件平台:Python 2.7。为保证实验具有全面性和代表性,使用复旦大学中文文本分类库和搜狗文本语料库进行对比实验。 复旦大学中文文本分类库共有9 804篇训练文本,9 833篇测试文本,分为20个类别,每一个文本只属于一个类别。去除重复和损坏的文本以及文本数小于100篇的稀有类别,共有9个类别,其中训练文本9 318篇,测试文本9 331篇。经过SA优化的SVM参数[Cfinal,σfinal]=[100,0.05],将其代入分类模型重新训练学习,与常用的文本算法比较,实验结果如表3和图2所示。 表3 不同分类算法在复旦大学中文文本 分类库的分类结果 % 图2 不同分类算法在复旦大学中文文本分类库 各类别分类精度 搜狗文本语料库共有9个类别,每个类别1 990篇文本,随机将每个类别的1 400篇文本分为训练文本,590篇文本分为测试文本。经过SA优化的SVM参数[Cfinal,σfinal]=[10,0.5],将其代入分类模型重新训练学习,与常用的文本算法比较,实验结果如表4和图3所示。 表4 不同分类算法在搜狗文本语料库的分类结果 % 图3 不同分类算法在搜狗文本语料库的各类别分类准确率 实验表明,不同数据集的最优参数[Cfinal,σfinal]不同,两组数据集通过SA全局寻优能力搜索到最优的SVM参数。经过SA优化参数的SVM分类模型,相比其他中文文本分类算法,在准确率、召回率和F1度量各个方面有明显的优势,具有较强的泛化能力,展现了较为显著的分类性能。 基于SVM的文本分类模型的泛化能力与其参数选择紧密相关,为解决优化SVM参数难题,本文提出了一个基于SA优化SVM参数的方法,以最大化文本分类准确率为目标全局搜索SVM的最优参数[Cfinal,σfinal]。在设计算法流程时,合理灵活地设置模拟退火的关键参数,并引入记忆存储器以防止因执行概率接受环节遗漏中间最优解,使得模拟退火算法更为智能。在设置内外循环终止条件时充分考虑实际情况,在保证最优性的基础上尽可能减少不必要的计算量。实验结果比较表明,基于SA-SVM中文文本分类模型具有良好的使用价值,展现出了非常显著的分类性能,为今后的文本分类建模提供了一种可行的思路。由于在综合考虑分类性能时未能做到充分的特征降维,使得分类过程时间较长,因此下一步的工作将在文本分类的特征降维方法上进行改进,进一步提高模型的计算效率。1.2 支持向量机
2 SA-SVM文本分类方法
2.1 参数对SVM分类性能的影响

2.2 基于SA的SVM参数选择设计方案
3 基于SA-SVM的中文文本分类
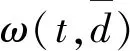



4 实验例证



5 结 语
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18少先队活动(2021年4期)2021-07-23健康之家(2021年19期)2021-05-23医学食疗与健康(2021年27期)2021-05-13农业科技与信息(2021年2期)2021-03-27健康体检与管理(2021年10期)2021-01-03水上消防(2020年5期)2020-12-14中国金属通报(2020年2期)2020-06-30摄影之友(影像视觉)(2019年3期)2019-03-30软件(2017年7期)2018-01-24
