
营销活动问题标签分类语料库的构建与分类研究
2019-04-01 09:28:02徐俊利赵江江
计算机应用与软件 2019年3期
徐俊利 赵江江 赵 宁 薛 超
(中移在线服务有限公司 河南 郑州 450000)
0 引 言
营销活动问题投诉工单是指客服人员面向客户描述与投诉营销活动有关的记录。营销活动问题标签是专门针对营销活动问题投诉工单进行更细粒度地划分形成的标签。营销活动问题标签分类是指判断营销活动问题投诉工单所属的问题标签。挖掘营销活动问题投诉工单中潜在的价值信息,开展移动客服领域营销活动问题标签的分类研究,对于捕捉客户投诉意图、开展营销活动专题分析具有重要意义。语料库是研究营销活动问题投诉工单分类的基础,然而目前尚没有移动客服领域营销活动问题标签分类语料库,这严重阻碍了营销活动问题标签分类研究的发展。因此,构建营销活动问题标签分类语料库是十分必要的。
近年来,语料库构建受到广泛关注[1-5]。目前在对话[6]、微博[7-9]、语言[10,11]、医学[12]等领域已出现公开构建的语料库。Lowe等[6]基于Ubuntu社区的对话内容,构建了包含一百万个对话的Ubuntu对话语料库,该语料既有Dialog State Tracking Challenge数据集的多次序对话特性,也有类似微博服务(如Twitter)上的人类自然对话特点,已成为对话系统的公开评测数据集。Quan和Ren[13]基于微博内容,构建了包含期望、喜悦、爱、惊讶、焦虑、悲伤,愤怒和憎恨8种情感类别的语料库。Chen和Nie[14]基于爬取技术,爬取双语平行的网页内容,构建了包含117.2 MB中文文本、136.5 MB英文文本的跨语言中英平行语料库。冯冠军等[15]提出维吾尔语情感语料库的构建规范,利用条件随机场(CRFs)自动识别维吾尔语情感词汇,构建了维吾尔语情感词语语料库。杨锦锋等[16]收集医学领域的中文电子病历数据,结合中文病历特点,制定了命名实体和实体关系标注体系,并构建了包含992份病历文本的中文电子病历命名实体和实体关系语料库。由于这些语料库独有的领域特性,导致很难移植应用于移动客服领域。而且目前尚没有公开的移动客服领域营销活动问题标签分类语料库,也没有基于深度学习的移动客服领域营销活动问题标签分类研究。因此本文构建了营销活动问题标签分类语料库,表1是营销活动问题标签分类的投诉工单示例。
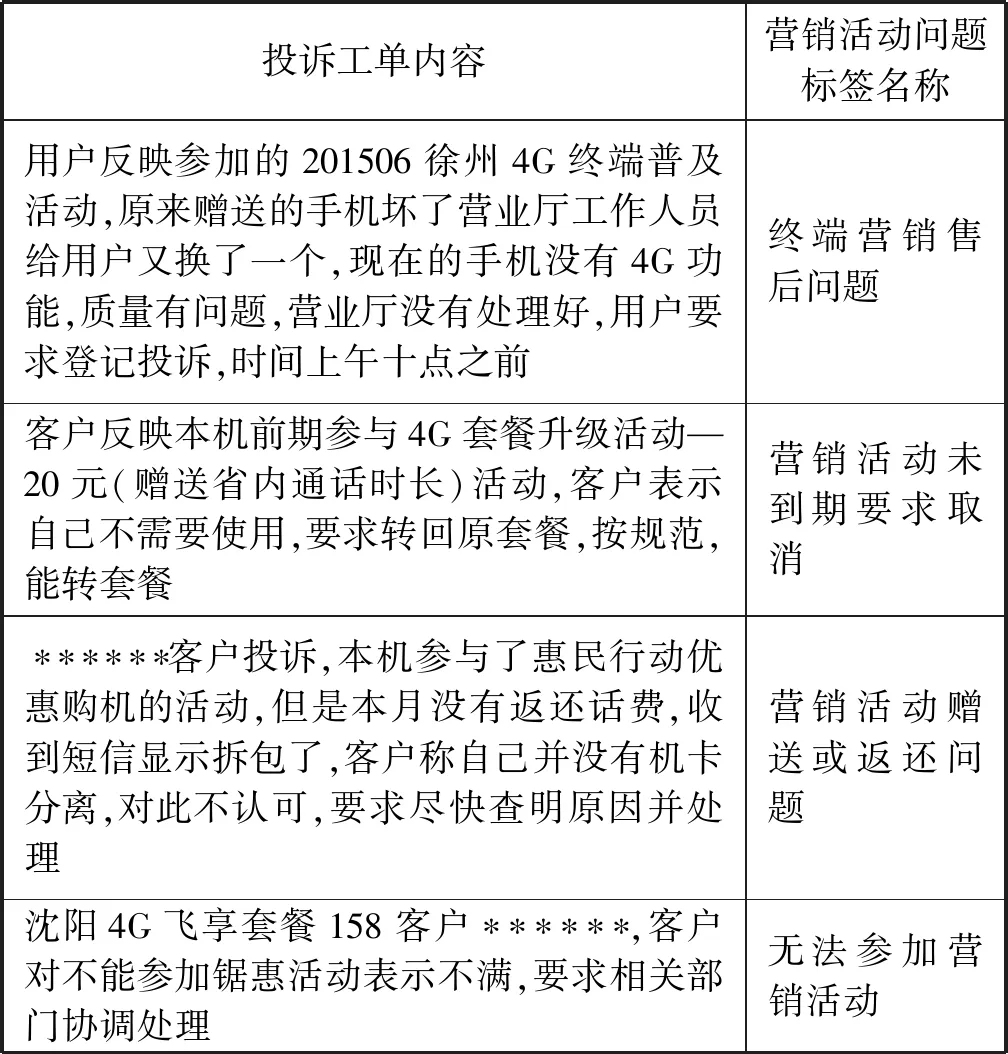
表1 营销活动问题标签投诉工单示例
营销活动问题标签分类是一个典型的多标签分类问题,目前分类方法有基于规则、基于传统机器学习、基于深度学习三种,然而目前尚未有营销活动问题标签分类的相关研究。基于规则的方法是通过分析各个标签的特性,编制规则或制定模板,进行分类。基于规则的方法简单有效、准确率较高,但是规则灵活性、扩展性较差。基于机器学习的方法是通过特征提取的方法,使用核函数的方法进行分类,效果较好。基于机器学习的方法虽能够取得较好的效果,但是仅能捕捉浅层的语义特征,并不能捕捉到深层的语义信息。基于深度学习的方法通过构建数据的深层抽象特征表示来捕捉输入序列的深层语义信息。基于神经网络的方法有卷积神经网络CNN(Convolutional Neural Network)[17]、长短时记忆递归神经网络LSTM(Long Short Term Memory)[18]两种。基于神经网络的方法可以避免繁琐的特征工程设计,能够将语言学信息表示为低维、连续的实值向量,在语义信息表达上,比传统机器学习方法更具优势。基于深度学习的方法已取得较好成果,然而在移动客服领域尚没有相关分类应用的研究。因此,本文基于深度学习方法挖掘移动客服领域营销活动问题投诉工单内部深层的语义信息,开展营销活动问题标签的分类研究。
本文首先基于K-means算法,对31省800万条营销活动问题投诉工单数据进行聚类分析,结合业务知识,将营销活动问题标签划归为否认参加营销活动、营销活动规则不满、无法参加营销活动、营销活动赠送或返还问题、优惠到期未自动取消、营销宣传与实际不符、终端营销物流配送不及时、终端营销缺货、终端营销售后问题、其他营销问题、反悔定制、营销活动未到期要求取消等12种标签。然后制定标注规则,并构建了营销活动问题标签分类语料库。最后在本文构建的语料数据集上,基于深度学习方法进行营销活动问题标签的分类研究。
本文的创新之处在于:(1)本语料库是移动客服领域目前为止首个公开且规模较大的数据集,能够为移动客服领域营销活动问题标签的分类研究提供较好的资源支持,并有效推动营销活动问题标签分类研究的发展。(2)本文制定的详细的标注规范和分类体系,能够为其他客服领域数据集的标注提供借鉴,具有适用性。(3)本文采用深度学习单一模型及融合的方法能够有效挖掘营销活动问题投诉工单内部的深层语义信息,提升分类效果。
1 营销活动问题标签分类语料库的构建
1.1 基于K-means算法确定问题标签
由于数据量大,采用人工方法确定问题标签个数代价较大。因此,我们采用K-means聚类算法进行聚类分析,结合专业知识,确定营销活动问题标签的数目为12, 具体过程如下:
1) 预处理。首先,将投诉工单中客户的手机号、地址等信息用“******”替换进行脱敏处理;然后,使用分词工具包LTP对工单进行分词。
2) 特征抽取。统计和分析语料,抽取n-gram特征(unigram,bigram,trigram),使用Tfidf作为句子特征表示。
3) 基于K-means聚类进行聚类,利用K-means算法(5≤K≤16),分别基于unigram、bigram、trigram进行聚类。分析聚类结果发现:(1) 基于unigram特征聚类效果不理想,这可能是由于unigram特征没有利用上下文信息导致的;(2) 无论K取何值,基于trigram特征的聚类效果均不理想,分析原因发现,trigram容易产生数据稀疏导致概率失真。因此,本文最终基于bigram特征,K分别取5到16之间的整数进行12组聚类实验。
4) 确定分类标签数目。采用手肘法的误差平方和确定投诉工单分类标签数为12。手肘法的核心是误差平方和SSE(Sum of the Squared Errors),其计算如下:
(1)
式中:Ci是第i个簇,p是Ci中的样本点,mi是Ci的质心(Ci是所有样本的均值),SSE是所有样本的聚类误差,代表了聚类效果的好坏。
手肘法的基本思想是随着聚类数K的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,那么SSE自然会逐渐变小。并且当K小于真实聚类数时,由于K的增大会大幅增加每个簇的聚合程度,故SSE的下降幅度会很大。而当K到达真实聚类数时,再增加K所得到的聚合程度回报会迅速变小,所以SSE的下降幅度会骤减,然后随着K值的继续增大而趋于平缓。也就是说SSE和K的关系图是一个手肘的形状,而这个肘部对应的K值就是数据的真实聚类数。图1是基于手肘法确定的最佳聚类数示意图。
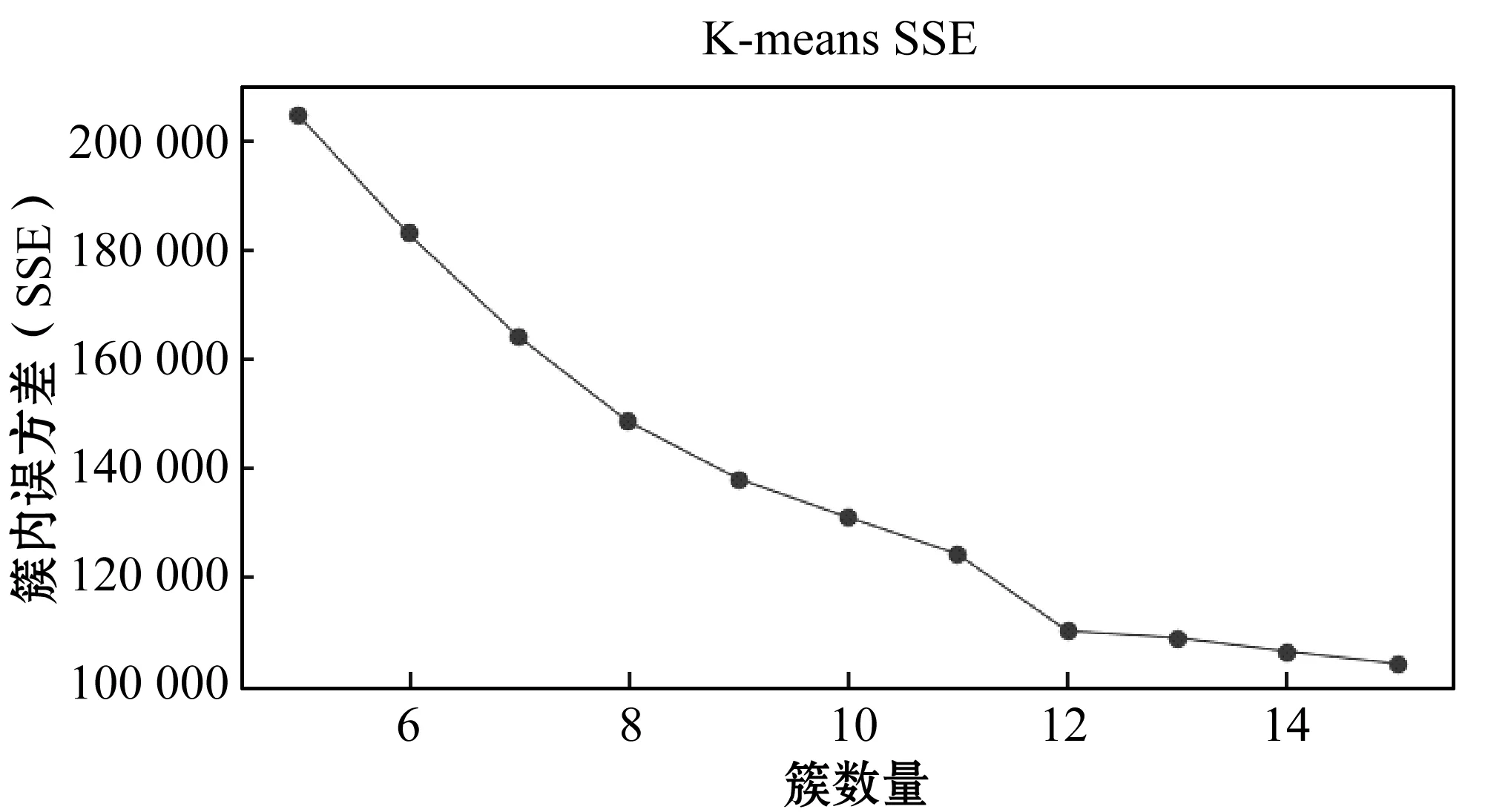
图1 基于手肘法确定的最佳聚类数示意图
5) 确定分类标签名称,分析基于2-gram特征,K取12时,每类随机抽取500条投诉工单交给业务专家进行分析,并确定分类标签名称。
1.2 标注过程
营销活动问题标签分类语料标注规范的制定难度较大,不仅数据量大,涉及专业知识,而且涉及到对专业业务的定义和分类。因此,本文基于K-means算法和专业知识确定营销活动问题标签分类体系,并进行标注。标注过程如图2所示。首先,根据K-means算法和专业知识确定的营销活动问题标签分类体系,规则制定者制定标注规则;然后,对每条投诉工单,由两名标注人员进行独立标注。最后,由规则制定者审核标注结果,并与标注人员、非参与标注的业务专家进行讨论和修订,统一两份标注语料中不一致的标注结果,形成最终的营销活动问题标签分类语料库。

图2 语料标注过程
1.3 问题标签标注规则
1.3.1 营销活动问题
营销活动问题指的是客户对网站、10086人工、短信等渠道为客户推荐优惠活动的内容、相关规则等产生争议,引起客户不满。客户投诉工单的对象为营销活动,例如客户对营销活动参与或退订、对营销活动规则不满、宣传与实际不符、营销活动赠品(含话费/流量)未按时收到、质量问题(含话费金额有误)等情况的投诉。
1.3.2 标签的定义
(1) 否认参加营销活动 客户在不知情情况下公司统一开通、变更、取消业务或优惠、免费体验活动,必须是客户明确拒绝办理仍然被开通才属于“否认参加营销活动”。
(2) 营销活动规则不满 该问题标签包括活动规则限定捆绑业务(用户参与营销活动,不知情/不想捆绑新业务,或对捆绑业务无法取消不满)、基础套餐无法转出或者变更(活动到期前基础套餐/流量套餐不能转出或变更)、话费分摊不合理(对已参加的营销活动返还月份/金额不满意)、最低消费不合理(客户对营销活动月底补收最低消费不满意、话费清零不满)、其他营销活动规则不满(如限制办理停机、销号、过户,分合户等;客户表示有其他用户参加相同活动不同待遇;没有解释清楚或者该提醒业务点未提醒的)几种情况。
(3) 无法参加营销活动 该问题标签包括客户自己是非目标客户(客户来电表达对自己不能参与某营销活动,不是目标客户表示不满)、营销活动参与渠道少(客户对营销活动限定办理渠道不满意)、因互斥业务无法办理(客户现有业务与开通营销活动的捆绑业务互斥导致无法参与营销活动)、其他无法参加营销活动问题(客户同意参加活动但是未及时给客户办理;客户表示办理了未显示成功;宽带活动已缴费或已变更业务但是因安装问题导致客户无法参加;活动页面无法打开或刷新不出来等)几种情况。
(4) 营销活动赠送或返还问题 该问题标签包括未按时收到活动返还(客户仅表示未在活动指定时间内收到赠送,无提及最低消费问题,因人为问题导致活动期承诺的赠送未按时返还)、返还/赠送金额有误(参与活动返还金额不准确)、赠送礼品质量问题(用户参与活动赠送的礼品、电子券、优惠码等出现的各类质量及使用方面问题)、其他返还类问题(其他营销活动赠送或返还问题)几种情况。
(5) 优惠到期未自动取消 该标签的判定依据是:活动到期后业务未自动取消的套餐或业务。
(6) 营销宣传与实际不符 该标签的判定标准是:客户明确表示活动宣传与实际体验不符(有对比),包括公司的一些宣传册页及短信中有关活动内容的文字信息、客户明确表示有人告知或承诺的内容与实际发生的活动情况不一致、要取消活动(包括活动到期变更已下线业务、客户参加活动或接到电话推荐业务,实际办理和宣传不一致)等情况。
(7) 终端营销物流配送不及时 终端营销物流配送不及时包括手机收到但是发票未及时配送、物流配送将客户订购产品丢失两种情况。
(8) 终端营销缺货 终端营销缺货包括:承诺赠送机顶盒后一直未送;宣传有免费赠送但是免费机型无货,但是有收费机型的情况。
(9) 终端营销售后问题 该问题标签包括:终端维修、换机等售后问题、客户对终端品质产生质疑(例如手机质量差)。
(10) 其他营销问题 该问题标签包括客户反映因参加活动宽带未及时安装但是产生扣费、客户办理终端类活动要修改地址或信息填写错误要求修改等情况。
(11) 反悔定制 该问题标签主要包括用户接到电话推荐活动表示同意办理,之后反悔、客户表示没听清或误操作或非本人办理活动要求取消的情况。
(12) 营销活动未到期要求取消 该问题标签包括活动未到期用户要求取消活动、客户明确表示只要求取消活动,无其他需求、客户表示有活动要求取消(客服人员前期有承诺客户会帮助取消,但是还未执行,客户的要求仍然是取消业务)的情况。
1.4 问题标签的基本规则
出现以下“重单”、“模板工单”、“无效工单”三种情况,在构建语料库时直接舍弃。
(1) 重单 如果工单内容中没有具体的投诉内容,只有之前投诉工单的一个编号,直接标注为“重单”。
(2) 模板工单 如果是用工单模板建单的情况,此类工单内容没有客户描述的自由文本信息,看不出客户投诉的任何信息,标注为“模板工单”。
(3) 无效工单 客户描述不清,看不出客户投诉点的工单,标注为“无效工单”。
标注语料的前提是能够看懂客户投诉的营销活动问题,以客户的投诉意图为主。为确保标注出来的问题标签分类语料库准确、有效,标注人员在标注过程中需严格遵循以下标注原则:
(1) 以客户需求为准 标注时,需要从客户的角度出发,填写客户的需求,无论需求是否合理、是否可以实现,只要客户表达出来了,均需按照客户投诉营销活动问题的意图进行标注。
(2) 摒弃业务经验 标注的目的是让系统从大量的数据中学习判别客户投诉营销活动问题标签的规则,由于系统并不具备移动业务知识和推理能力,所以在标注过程中不能将业务经验加入考虑,基于推理得到标注结果。
(3) 避免臆断推测 标注客户投诉意图时,必须从文字内容出发,不能加入标注人员自己的主观猜测,不能在文字内容表达出来的意图之外推测出客户的投诉意图。
(4) 纯凭文字内容 为确保训练数据的有效性,保障系统学习准确率,标注人员进行标注时仅通过文字判定标签,不可做文字内容以外的联想和经验判断。
1.5 标注特殊情况说明
虽制定了详细的标注规则,但由于营销活动投诉工单的灵活性,导致很难判别,如下是标注特殊情况:
(1) 如果客户表示未经许可、不知情办理了***活动,统一归为:否认参加营销活动。
(2) 对活动有最低承诺消费不满、没有机卡绑定或手机坏了等导致的双倍扣费,属于营销活动规则不满;如果客户明确了业务规则,之后表示办理时没有提示,对宣传与实际不符不满,此类归为:营销宣传与实际不符;对不能参加某一档位的营销活动,归为:营销活动规则不满;参与活动但话费没有返还属于营销活动赠送或返还问题。客户表示参与活动但不成功,属于:无法参加营销活动;客户参与活动,如明确表示当时参与时介绍的与现在成功参与后的内容不一致,则为:营销宣传与实际不符;营销活动到期后未取消产生扣费的情况,归为:优惠到期未自动取消。
(3) 参与终端活动后,终端出现质量类问题,归为:终端营销售后问题;参与需要好友协助类活动,但数据不更新,归为:无法参加营销活动。
2 基于深度学习的营销活动问题标签分类研究
传统基于机器学习的分类方法需要人工设计特征,并且特征表示均采用独热(one-hot)的高维稀疏表示形式,难以捕捉投诉工单内部的深层语义信息。相对于传统的机器学习,基于深度学习的方法不需要繁琐的特征工程设计,通过多层的神经网络自动构建数据的深层抽象特征表示,学习深层次的语义信息。基于深度学习的方法能够将语言学信息表示为低维、连续的实值向量,可以减小特征选择不全面对实验结果造成的影响。目前比较具有代表性的神经网络模型有CNN和LSTM。
CNN本质上是学习大量输入信号到输出目标的映射关系,通过多隐层堆叠、每一层对上一层的输出进行处理的机制对输入信号进行逐层加工,从而把能够将初始的“低层”特征表示自动转化成“高层”的特征表示,该方式既可以避免显式的特征抽取,也能够减少训练代价。由于其采用局部感受野和权值共享的方式,能够有效降低反馈神经网络的复杂性,所以在语音识别、图像分析等领域得到广泛应用。
LSTM通过独特的“门”机制控制信息的记忆和更新,能够自动学习整个输入序列的深层语义信息,并且可以解决传统循环神经网络RNN(Recurrent Neural Network)[19]的梯度消失问题。LSTM的“门”机制包含一个sigmoid激活函数和一个pointwise乘法来控制信息的加入与丢弃。sigmoid函数的输出值在0到1之间,输出值表示容许信息的通过量是多少,值为0表示“任何信息都不允许通过”,值为1代表“允许所有的信息通过”。LSTM模型通过输入门、输出门、忘记门控制信息的记忆和更新,从而在学习过程挖掘营销活动投诉工单内部的深层语义信息。
为挖掘营销活动问题投诉工单内部的深层语义信息,本文采用深度学习的方法进行营销活动问题标签的分类研究。图3是基于深度学习的营销活动问题标签分类框架图,包括预处理、构建句子向量表示、基于深度学习训练模型、输出分类结果四个阶段。在预处理阶段,对营销活动问题数据,进行分词、去停用词、训练词向量等处理。在构建句子向量表示阶段,通过映射操作,将训练数据、测试数据中的工单词序列转换成低维、连续的实值表示形式,得到工单的句子向量表示。在基于深度学习训练模型阶段,分别基于CNN、LSTM、Bidirectional Long Short Term Memory(BiLSTM)模型及三种模型融合的方法,训练营销活动问题标签分类模型。在输出分类结果阶段,预测并输出待测试营销活动投诉工单的问题标签分类结果。
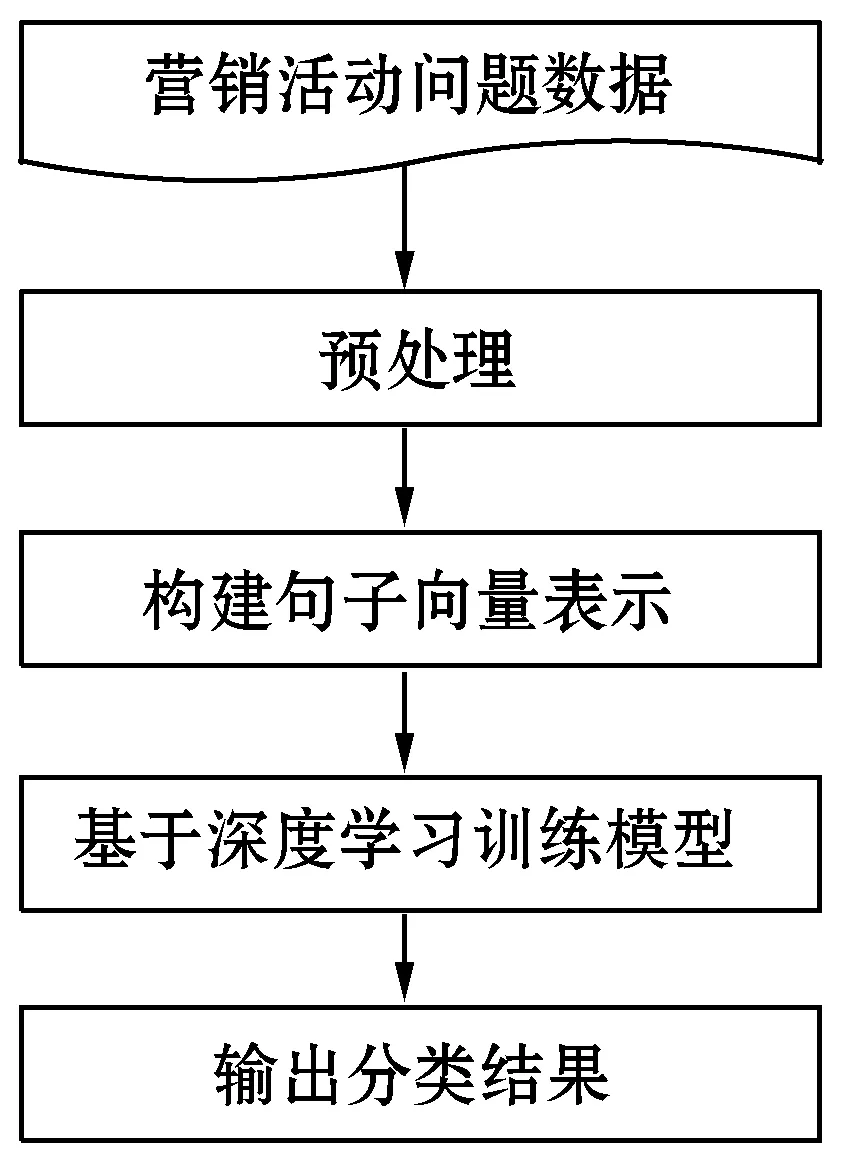
图3 基于深度学习的营销活动问题标签分类框架图
3 语料库统计及分类研究实验
3.1 语料库的统计及一致性分析
本语料数据来源于移动客服领域,31省800万条客户投诉营销活动问题的真实工单记录,共计标注数据24 957条投诉工单。其中训练集有19 960条,测试集4 997条,每条标注数据包括工单内容和问题标签,其中工单内容、问题标签之间用制表符隔开。表2是营销活动问题标签分类语料库的统计信息。
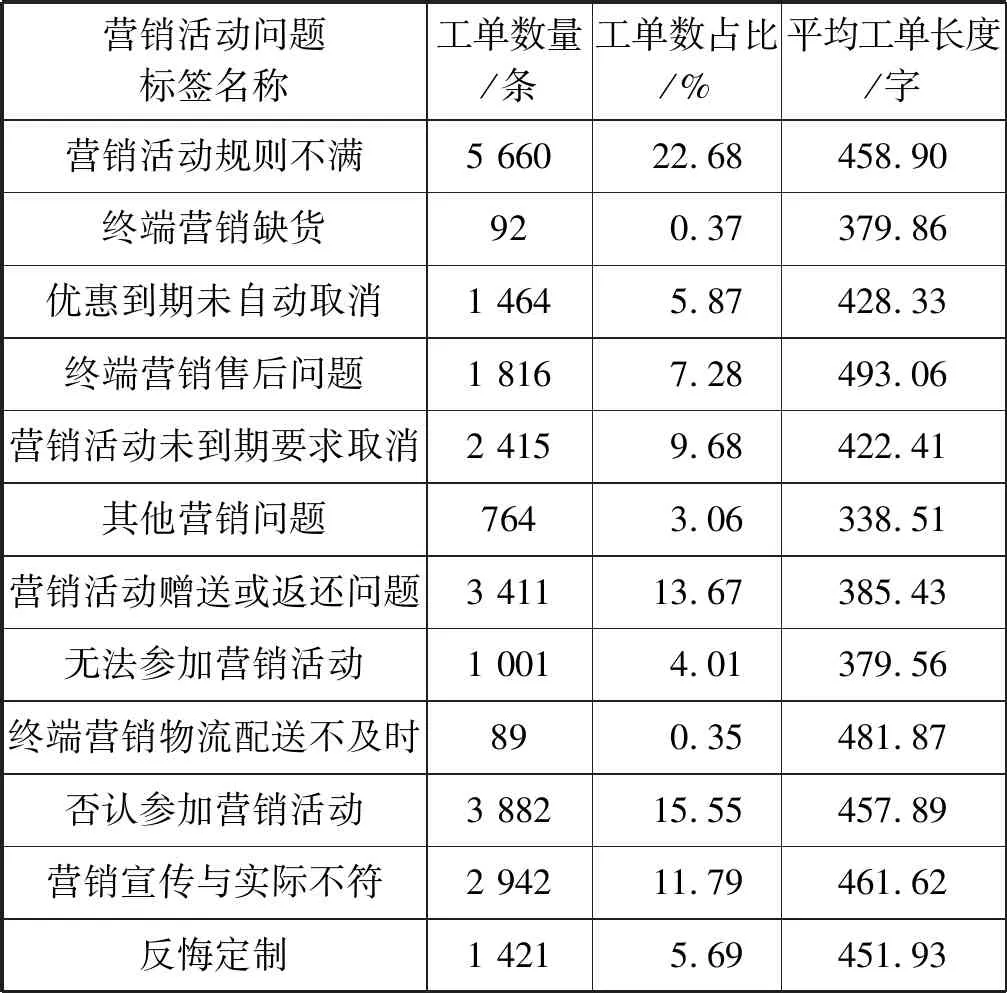
表2 营销活动问题标签分类语料库的统计信息
(1) 营销活动问题投诉工单数占比最高的三种问题标签分别是营销活动规则不满、否认参加营销活动和营销活动赠送或返还问题。而终端营销物流配送不及时的投诉工单仅有89条。说明不同营销活动问题标签的投诉热度不同,客户关注的焦点不同。从投诉工单的数量和占比,可以发现客户投诉的Top3核心问题,对于快速定位客户投诉的问题标签类别,提升服务质量具有重要意义。
(2) 12种问题标签投诉工单的平均长度均在338字到493字之间,不同问题标签的工单长度分布较均匀。这可能是由于营销活动问题的工单模板比较相似导致的。
由于本文对每条营销活动问题投诉工单都标记了唯一的标记,所以召回率为100%。采用准确率作为一致率(即两组标注结果完全一样的投诉工单数目/总的投诉工单数目×100%)来分析标注一致性。营销活动问题标签分类语料库的一致性分析结果如表3所示。Result1_2为标注结果1和标注结果2之间的一致率,Result1_final为标注结果1和最终语料标注结果之间的一致率,Result2_final为标注结果2和最终语料标注结果之间的一致率。
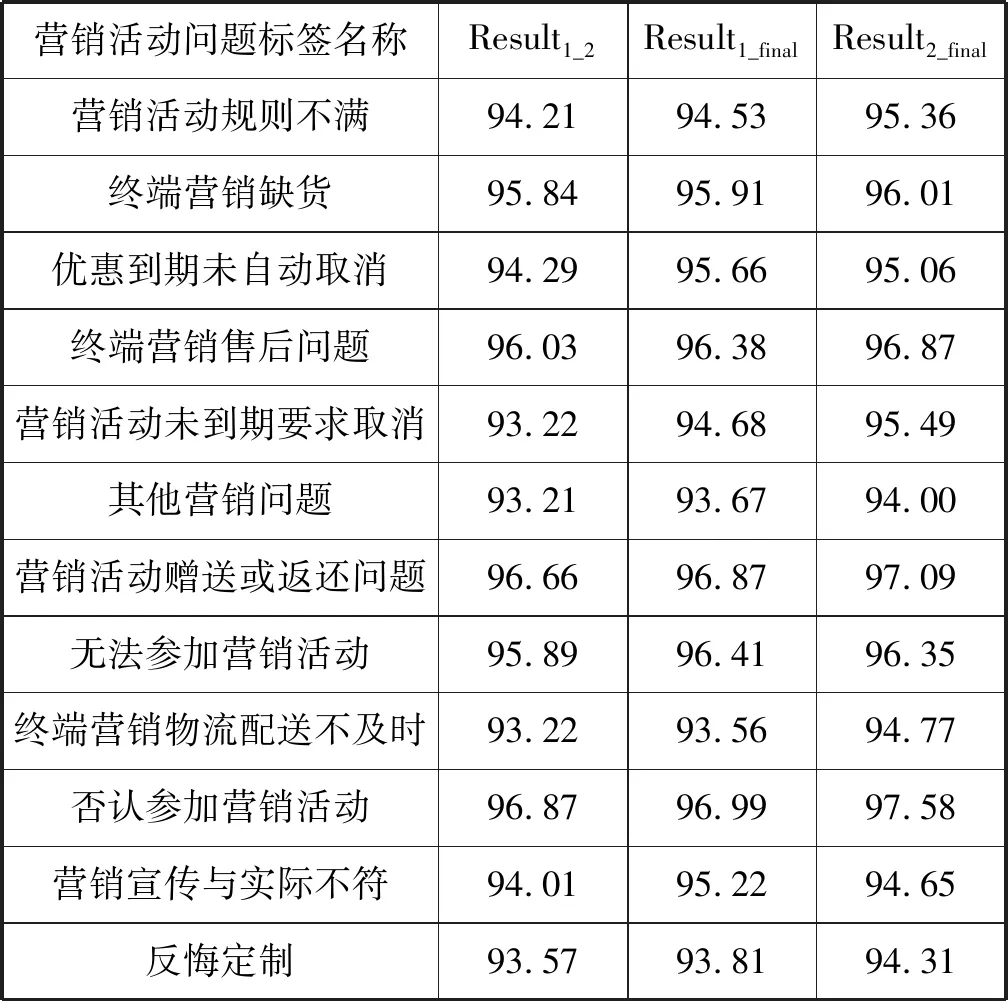
表3 投诉工单分类语料库的一致率统计 %
从表3可以看出:
(1) 12种问题标签的标注一致率结果均在93%以上。Artstein和Poesio[20]指出,当标注一致性达到80%时,即可认为语料的一致性是可信赖的。从最终一致性结果可以看出,我们构建的语料库在一致性上是可靠的。
(2) 第一列的一致率普遍比第二列、第三列的一致率低。这是因为:标注结果会受人主观因素的影响,而最终问题类语料是由标注结果1和标注结果2不同之处统一之后得到的。所以第二列、第三列的一致率普遍高于第一列的一致率。
(3) 营销活动未到期要求取消、其他营销问题的一致率相对较低;否认参加营销活动、营销活动赠送或返还问题、终端营销售后问题的一致率相对较高。这可能是因为:各个问题标签的特点、区分度不同造成的,例如否认参加营销活动必须有明确的客户否定的说法;营销宣传与实际不符必须有对比等。此外,还可以看出相对于其他问题标签,营销活动未到期要求取消、其他营销问题的标注更加复杂,因为涉及到更多复杂和多变的投诉情况。
3.2 分类实验分析
本文首先基于移动客服领域营销活动问题800万条投诉工单语料,使用Word2Vec工具包[21]进行预训练,得到100维的词向量。然后,分析表2营销活动问题标签分类语料库的统计信息结果,发现数据存在不平衡现象,这样会对分类器的结果造成影响。因此我们借鉴非均衡问题调节分类器的方法(即对分类器的训练数据进行改造),通过欠抽样和过抽样的方法来处理不平衡的问题,最终构建并得到新的平衡数据集。过抽样就是对终端营销缺货、终端营销物流配送不及时、其他营销问题等标签数量少的数据进行复制操作,欠抽样就是对营销活动规则不满、否认参加营销活动等标签数量多的样例的方式进行随机删除操作,这样就可以保证数据集分布大致保持在平衡的状态。最后,分别基于CNN、LSTM、BiLSTM模型及三种模型融合的方法,在本文构建的语料数据集上进行营销活动问题标签分类的实验。在CNN实验中,滤波器的数目为292,学习率为0.01,设置一个批度的样本数(batch-size)为128,卷积窗口大小为3,采用最大池化方式,实验迭代500次。在LSTM和BiLSTM实验中,设置一个批度的样本数(batch-size)为800,迭代次数为500,其他均采用默认参数。在三种模型融合实验中,为综合利用三个模型的优势,采用规则进行融合,构建基于融合的营销活动问题标签分类模型(CNN+LSTM+BiLSTM),得到分类结果。本文以每条工单为单位进行评测,采用准确率(P)、召回率(R)和F1值的评测指标衡量分类效果。本文采用的融合规则如下:
(1) 如果两个分类器输出的问题标签一致,一个分类器输出的问题标签和另外两个分类器的标签不同,按照多数投票原则确定最终的问题标签。
(2) 如果三个分类器输出的问题标签各不相同,则依据概率最大的原则确定最终的问题标签结果。
本文基于上述规则,得到的基于深度学习模型的营销活动问题标签分类实验结果如表4所示。
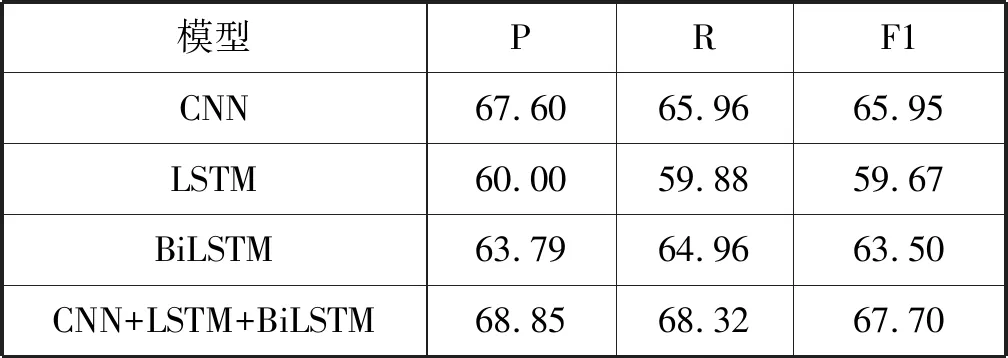
表4 基于深度学习的营销活动问题标签分类实验结果%
(1) 基于CNN模型的营销活动问题标签分类结果比基于LSTM模型的结果好,F1值达到65.95%。可能是因为:工单句子的模板性较强,会包括较多的无用(噪音)信息,这样,LSTM模型会将噪音信息传递到下一时刻,从而影响分类效果,而CNN模型能够捕捉到局部最有效的信息,所以分类效果相对较好。
(2) BiLSTM模型的F1值比LSTM模型高3.83%,说明历史信息和未来信息对于营销活动问题标签的分类都是有用的。这可能是因为:BiLSTM模型能够捕捉到工单序列的历史信息和未来信息,而LSTM模型仅能够捕捉到工单序列的历史信息。
(3) CNN、LSTM、BiLSTM模型的分类结果F1值在59.67%和65.95%之间,说明基于深度学习方法的分类结果还有很大的提升空间。这主要是因为:本文数据来源于真实的客户投诉工单内容,工单的灵活性和口语化特征加大了问题标签分类的难度和复杂性。
(4) CNN+LSTM+BiLSTM模型分类性能最好,F1值达到67.70%,比CNN、LSTM、BiLSTM模型的F1值分别高1.75%、8.03%、4.20%。说明本文提出的融合分类方法是有效的,能够综合利用各种模型的优势,挖掘更深层的语义信息,从而显著提高营销活动问题标签的分类效果。
4 结 语
本文主要总结了在移动客服领域营销活动问题标签分类语料库构建和分类研究方面的工作。首先,基于K-means算法和专业业务知识确定分类标签体系,依据专业知识制定详细的标注规则并进行标注。最终构建了目前规模较大、业务覆盖面最广、分类最完备的移动客服领域营销活动问题标签分类语料库,共计标注投诉工单24 957条。然后,统计和分析营销活动问题标签分类语料库标注结果的一致性,并在构建的语料库上,采用单一深度学习模型及三种模型融合的方法进行营销活动问题标签分类实验。实验结果F1值最高达到67.70%,表明本文提出的基于深度学习的营销活动问题标签分类方法是有效的。最后,对未来工作进行展望。详尽的标注规则和严格的标注过程,使得语料标注取得了较高的一致率,分类结果较好,可见本文构建的语料规模足以用于后续研究。如前所述,语料库的构建目的是为了研究营销活动问题标签的分类,从而帮助服务决策人员进行营销活动问题专题分析。未来工作的重点是根据使用者的反馈意见,继续完善标注规范,改进标注质量,扩大语料规模,改进营销活动问题标签的分类方法,提高分类效果,从而实现移动客服领域营销活动问题信息的抽取和整合。
猜你喜欢
电子测试(2022年7期)2022-04-22 00:13:16
高技术通讯(2021年6期)2021-07-28 07:39:20
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
中国核电(2017年1期)2017-05-17 06:09:55
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
中国科技信息(2015年23期)2015-11-07 08:26:17
语言与翻译(2015年4期)2015-07-18 11:07:45
民族古籍研究(2014年0期)2014-10-27 08:24:34
