
面向目标跟踪的主动式移动传感器长期调度方法∗
2019-03-26 09:14:42徐公国单甘霖段修生
传感技术学报 2019年2期
徐公国,单甘霖∗,段修生
(1.陆军工程大学石家庄校区,石家庄050003;2.石家庄铁道大学,石家庄050003)
现代战争呈现出网络化和信息化的特点,传感器管理的作用日益增大[1-3]。作为传感器管理的关键一环,移动传感器的调度问题越来越受到重视,其实质上是非线性最优化控制问题。通过对移动传感器平台的有效控制,可使传感器时刻保持对目标良好的观测性,从而获取更好的量测数据和目标跟踪精度。
现阶段,移动传感器调度问题的研究多集中在无线传感器网络(WSN)覆盖控制和无人机(UAV)路径规划上,针对目标跟踪下移动传感器控制问题的研究还比较少。一般情况下,目标的运动和状态变化规律可用马尔科夫决策过程来描述。如文献[4]利用部分可观马尔科夫决策过程(POMDP)对传感器控制问题进行建模分析,采用目标状态的先验和后验概率之间的信息散度作为代价函数,该模型能够有效解决传感器移动调度问题,但增加了问题的复杂度。文献[5]利用Fisher信息增益对被动式移动传感器的调度问题进行了研究,并利用网格搜索策略来寻找问题的最优解,但网格搜索速度较为缓慢。考虑目标数目的时变性,文献[6-7]基于随机集理论研究了多目标跟踪下的传感器调度问题。文献[8]则基于随机集理论进一步对机动目标跟踪下的传感器调度问题进行分析,并给出了信息理论下传感器调度的一般方法。但是基于随机集理论框架的控制方法对目标进行统一的探测与跟踪,不能很好地对目标进行区分,没有良好的针对性,容易造成传感器大范围的摇摆移动,能耗问题会偏大。
针对上述问题,考虑多目标跟踪需求以及传感器的运动能力,提出了一种面向目标跟踪的基于PCRLB和目标优先级的主动式移动传感器长期调度方法。仿真实验表明,本文所提模型能够有效控制传感器进行合理地移动,并能获得更多的目标跟踪收益。
1 问题描述
如图1所示,本文主要对面向目标跟踪的主动式移动传感器的调度问题进行研究,目标和传感器均设定在二维平面内运动,本节给出了二维坐标下的目标运动模型、传感器运动模型和量测模型。此外,依据贝叶斯滤波理论,给出了移动传感器的长期控制模型,下面进行具体分析。
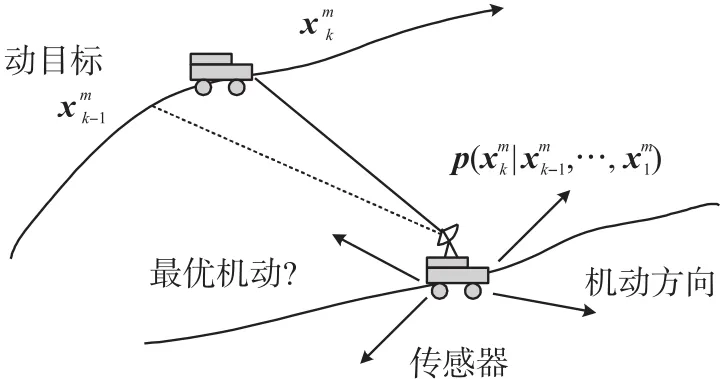
图1 移动传感器调度示意图
1.1 目标运动模型
假设在x-o-y侦察区域内,有N个主动式传感器资源,M个被探目标。假设目标运动模型为CV模型,则目标m(m=1,2,…,M)在 k时刻的状态方程可表示为:
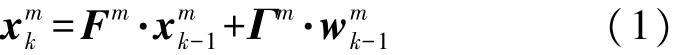
式中:Fm为目标的状态转移矩阵,Γm为噪声增益矩阵,wmk-1~N(0,Qm)是服从高斯分布的状态转移噪声。在二维CV模型下,状态xmk=[xmkẋmkymkẏmk]T,分别表示目标在x和y方向上的位置和速度信息。
1.2 传感器运动和量测模型
由于传感器机动能力的限制,定义每一时刻传感器的移动步长为L,传感器可移动的方向为λ个。如图2所示,传感器在每个时刻的位置变化矢量集合为 θΛ={a1,a2,…,aλ},其中 ai是在以传感器单步移动距离L为半径的圆上等分而来,在λ等分的情况下,位置变化矢量ai可由式(2)计算而来:
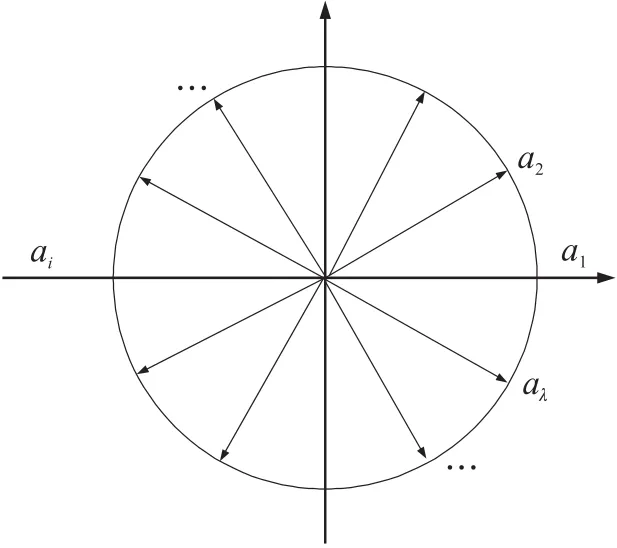
图2 传感器单步移动示意图
参数λ反映了对传感器运动模型刻画的精细程度,但当λ过大时,进行长期预测的计算复杂度会快速增加,为加快问题的优化速度,一般情况下λ取4或8。二维平面内,主动式传感器一般选取目标的斜距离、方位角作为量测信息,若传感器n在k-1时刻的调度动作为Ank-1∈θΛ,则传感器 n(n=1,2,…,N)在k时刻的对目标m的量测方程可表示为:
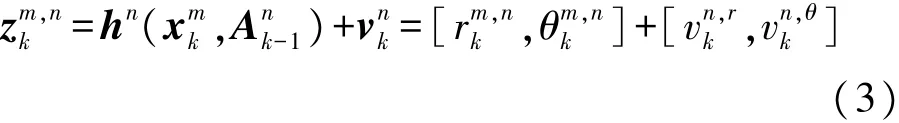
式中:hn(·)为非线性量测方程,vnk~N(0,Rn)是服从高斯分布的量测噪声,vnk,r、vnk,θ分别为斜距离、方位角的量测噪声,rmk,n、θmk,n分别为目标到传感器的斜距离和方位角,具体计算方法为:
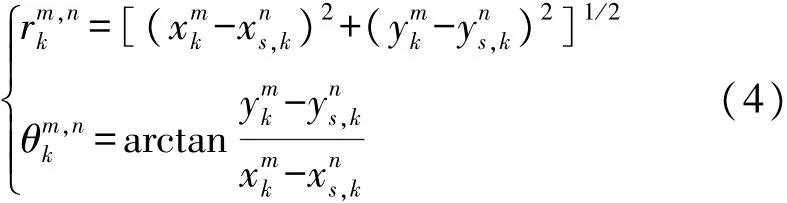
式中:xns,k和 yns,k为传感器n在k时刻的位置坐标,传感器位置坐标[xns,k,yns,k],且满足以下递推公式:

需要注意的是,传感器n的位置发生变化,相应的量测方程hn(·)在调度过程中也会变化。考虑到量测方程为非线性方程,容积卡尔曼滤波(CKF)算法对处理非线性系统有着良好的性能且比较成熟,故本文采用CKF对目标状态进行滤波更新,具体步骤参见文献[9],这里就不再展开分析。
1.3 移动传感器长期调度模型
传感器预测控制存在短期和长期之分,短期调度只以当前时刻的收益最大化为目标,而忽略当前动作对未来收益的影响。长期调度则考虑未来一段时域内的整体收益,该策略对未来状态进行预测,以求全时域内的收益最大化。
已知在k时刻内,传感器n的调度动作Ank,目标m的量测值zmk,n,目标m的状态xmk,满足以下关系:

式中:p(·|xmk-1),p(·|xmk,Ank-1)为状态转移函数和量测似然函数,π0为状态初始分布概率,则目标m在k时刻的状态分布满足以下贝叶斯递推公式:
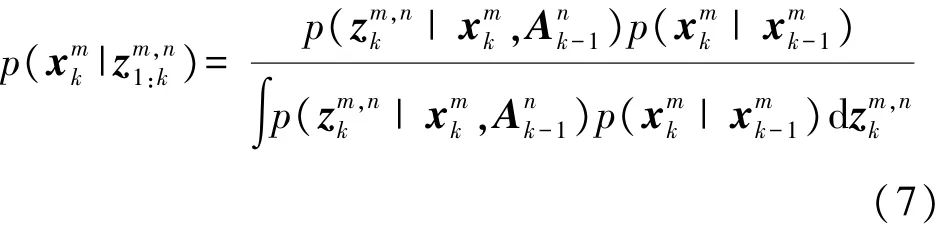
因此,可通过滤波预测对移动传感器的长期调度问题进行建模分析。移动传感器具体调度过程如图3所示。

图3 移动传感器调度过程示意图
定义传感器n在移动过程中跟踪目标m时的优化目标函数为Rk(xmk,Ank),即为优化过程中的收益函数,其依据具体任务需求来确定,可以为跟踪精度、能耗等。进一步,假设传感器n在时域T内的调度动作序列为 A1n:T= {An1,A2n,…,AnT}∈θΛ,令传感器在时域T上的长期收益为累积单步收益的期望值,此时传感器n的移动调度问题就转化为了以下最优化问题:
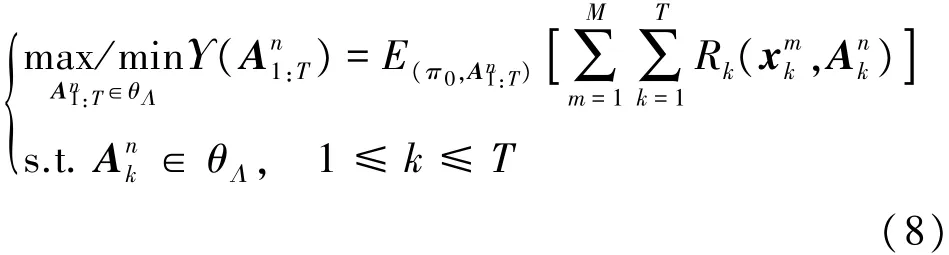
进而传感器最优调度指令的选择问题就可描述为:在 k时刻通过滤波预测,选择使目标函数Υ(An1:T)最优的传感器移动轨迹,最优调度动作序列可由式(9)计算得出。

获得最优调度动作序列An1:,∗T之后,在实际应用时,一般有两种执行策略:一种是执行完A1n,
:T∗动
作序列中的所有动作,称为开环控制;另一种,类似于滑窗的形式,只执行最优序列An1:,∗T中第一个动作,然后重新进行预测优化,获取新的An1,:T∗′,称为闭环控制。如图4所示,由于闭环控制能够实时从调度动作中获取新的反馈信息,对目标状态的估计也就更准确,故本文采用闭环方式进行传感器移动控制。

图4 控制指令执行策略
2 基于PCRLB和目标优先级的收益函数构建
2.1 PCRLB
传感器移动控制的目的是通过预测来事先进行传感器机动,进而减少目标状态的不确定性,提高目标跟踪的精度。后验克拉美-罗下界(PCRLB)给出了目标状态估计的预测误差的理论下界,适用于传感器资源的调度管理。例如,文献[10-11]基于PCRLB对多传感器资源的部署问题进行了研究,分析不同布站方式下对目标PCRLB的影响。文献[12-13]则基于PCRLB对无线传感器网络中的选择策略进行了研究,并取得了良好的跟踪效果。

已知,对于目标m的状态xmk+1,其均方误差下界满足:式中:^xmk为目标m的状态估计,Jk+1为Fisher信息矩阵,且满足以下递推公式:
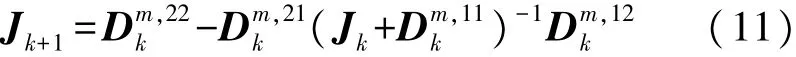
式中:
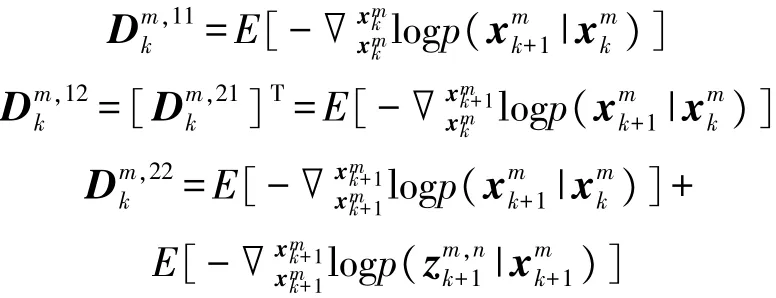
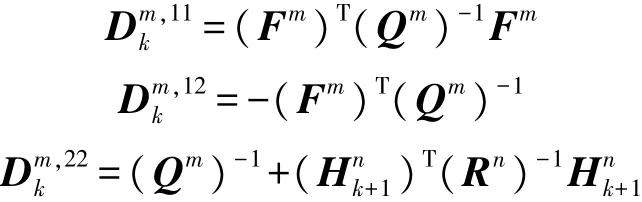
式中:Hnk+1非线性量测方程 hn(·)的雅可比矩阵,已知hn(·)随着传感器位置的变化会发生改变,相应的PCRLB也会发生变化。因此,可以通过优化PCRLB来选择传感器的最佳位置变化,从而获取最优的移动轨迹。此外,由于在目标跟踪过程中更重视目标的位置量,故本文选择目标位置分量的误差边界和作为优化目标函数,即有:

式中:J-k+11[1,1]和 J-k+1
1[3,3]分别为目标在 x 和 y 方向上的均方误差下界。PCRLB描述的目标位置误差的下界,应该越小越好,故此时式(8)中的最优化问题应为最小化问题。
2.2 目标优先级
多目标跟踪场景下,有限的传感器资源可能无法满足所有目标的跟踪需求,这就需要区分目标的重要程度,以便对重点目标优先跟踪。目标优先级的确定实质上是一个多属性决策问题,通常目标威胁程度越大,目标优先级越高。
进行目标威胁度判断,目标的移动速度、目标与我方阵地的距离以及目标的类型往往是重点考虑的目标属性。故定义目标m的优先级函数为Prm(Vm,Lm,Tym),其中Vm是目标速度,Lm是目标距离,Tym是目标类型。目标优先级的具体计算方法参见文献[14],当求出多个目标的优先级函数值后,按照式(13)的归一化方法求出目标m的重要程度:

式中:Pri为目标i的优先级函数值,1≤i≤M。
综上,当考虑目标跟踪误差下界和目标优先级时,传感器n在时域T内的优化目标函数应为:

最优调度动作序列 An,∗1:T则由以下公式计算得出:
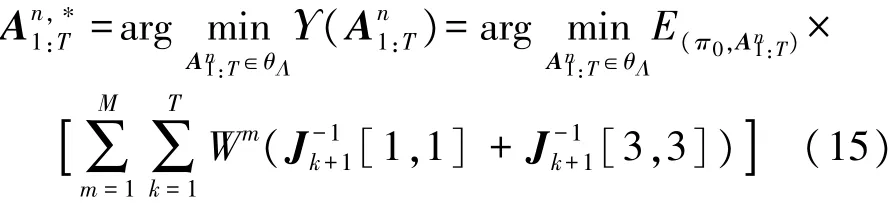
3 优化求解算法
如图5所示,当移动传感器的预测优化步长T>1时,由于传感器在每一时刻都有λ个移动选择,该问题可抽象为深度为T、分支为λ的决策树问题。决策树中各分支的权重为该移动方向所对应的Υ(An1:T),获取最佳的传感器组合也就转化为搜索决策树中Υ(An1:T)(目标函数)最小的分支路径。
当步长T较大时,搜索空间会呈现指数型增长,问题求解速度会变缓。为加快求解速度,这里引入分支剔除技术来减少搜索空间。常用的分支剔除技术有平滑窗法和阈值法,本文针对移动传感器移动控制问题的特点,在标准代价搜索的基础上,利用阈值剔除搜索技术来寻找问题的次优解。其中,阈值δ≤1为分支取舍参数,当某一节点所对应的目标函数值大于最优目标函数值的1/(1+δ)倍时,则将该节点剔除,其后的节点也不再打开。通过剔除分支可有效达到减少搜索空间的目的,从而加快问题解的搜索速度。利用决策树来进行问题求解,主要具有两个方面的优势:一是可减少内存开销,降低硬件成本;二是不用进行重复滤波预算,节点的滤波值可被后面所有的节点用来进行滤波。

图5 决策树
基于阈值δ分支剔除的传感器移动控制求解算法的具体步骤如算法1所示。

算法1 基于阈值δ剔除的传感器移动控制算法
4 仿真实验分析
4.1 场景1
在该场景中,面向单个运动目标,对移动传感器的调度问题进行研究,分析优化时域步长T对传感器调度序列和跟踪性能的影响,验证所提长期调度方法的有效性。
实验参数设置:采样间隔 t=1 s,采样时间Simtime=50 s。目标运动模型为CV模型,目标初始状态为 x0=[2000,50,4500,-50]Tm,噪声协方差矩阵 Q=diag[20,5,20,5]m,状态转移和噪声增益矩阵分别为:

传感器可运动方向为4,即λ=4,移动步长为60 m,则移动指令有:a1=[0,60], a2=[0,-60], a3=[60,0],a2=[-60,0]。 此外,传感器初始位置为[500,500]m,量测噪声协方差矩阵为 R=diag[1002,0.52]m。
此外,为对比分析本文所提调度模型的有效性,实验过程中同时采用传感器位置固定策略SP(Stationary Policy)和恒定速度移动策略CVP(Constant Velocity Policy)进行跟踪实验。不失一般性,SP策略中传感器位置位于[500,500]m,CVP策略中传感器初始位置为[500,500]m,并按速度矢量为[60/2,60/2]m/s方向移动。对于本文所提基于PCRLB的长期调度策略,分别取优化时域步长T为1(又称为短期调度)、2、3进行实验,实验结果分别如图6~图8所示。

图6 不同调度策略下的目标位置RMSE
图6 为不同调度策略下目标估计位置的均方根误差(RMSE)。由图可见,相较于SP和CVP两种调度策略,本文所提方法能较好控制传感器的跟踪误差,跟踪性能也更加优越。且随着优化时域T的增加,传感器对目标的估计误差越来越小。原因在于优化时域T越长,预测时间也就越长,就可使移动传感器能够提前运动到更好的位置,以至获得更为准确的目标信息,目标的跟踪精度也就会变高。
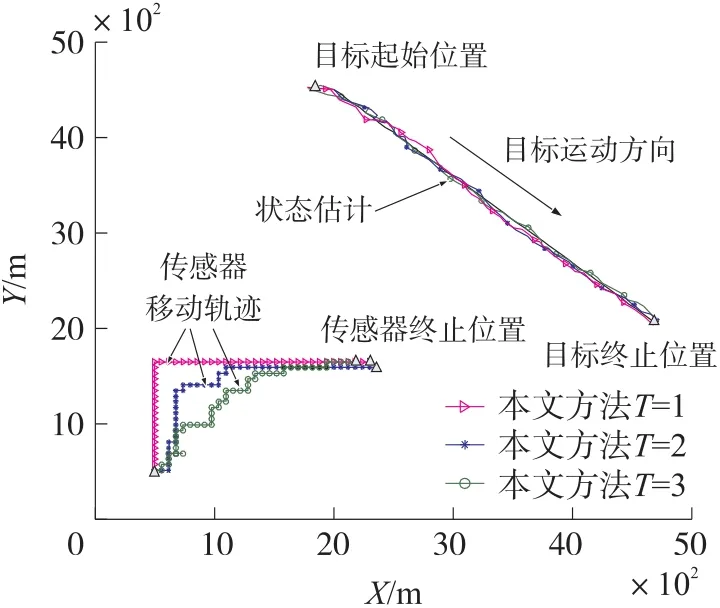
图7 传感器优化轨迹对比图
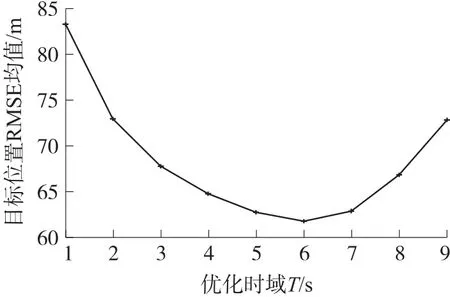
图8 不同时域T下的RMSE均值
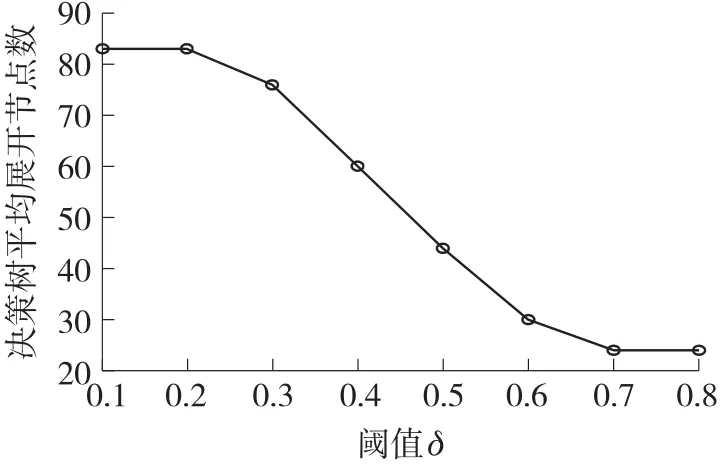
图9 不同阈值下的决策树平均展开节点数
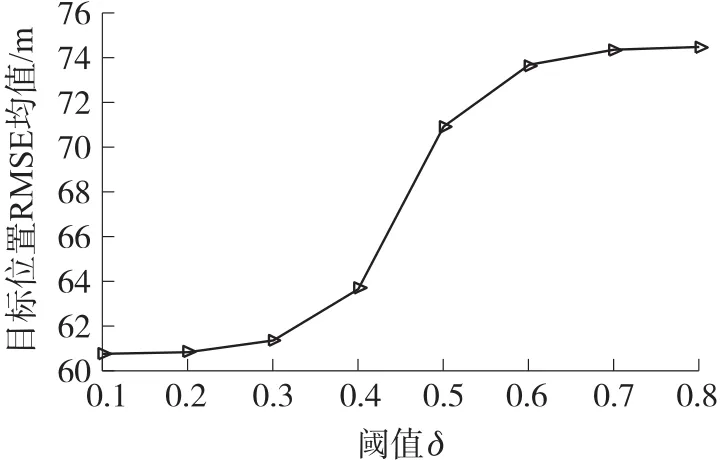
图10 不同阈值下的目标位置RMSE平均值
图7 为本文方法在时域T=1、2、3时的传感器移动轨迹对比图。可见,相较于短期调度,长期调度能够更为准确地把握目标的运动趋势,从而获取更为合理的传感器移动轨迹。
在前面的实验中我们发现,在长期调度策略中,预测优化时域T较长时,移动传感器的跟踪效果较好。那是否预测时域步长T越长,传感器对目标的跟踪效果越好,对此我们做了大量的实验,分析预测优化时域T对跟踪精度的影响。图8为不同优化时域T下,重复运行20次时的跟踪误差RMSE的平均值。
由图8可见,跟踪误差RMSE并不是随着T的增加而不断减小。而是在T=6时出现了拐点,跟踪误差RMSE又开始增加。通过分析,原因在于进行跟踪收益预测时,是根据假设的传感器运动模型来推理的。但目标的实际运动情况与假设的模型会有所差异,且随着预测时间的增加这种差异会越来越大。定义RMSE均值下降区间为正收益区间,在正收益区间内,随着预测优化时域T的增加,目标跟踪误差会减小。因此,在针对具体问题时,要先确定正收益区间,以便选择合适的预测优化时域T,在保证跟踪收益的同时还要减少问题的计算复杂度。以本问题为例,取T=3比较好,因为此时问题的计算复杂度不高且能获得较高的目标跟踪精度。
此外,为寻找合适的阈值δ来有效减少搜索空间,保持时域步长T=3不变,在[0,1]内取δ为不同值进行实验,分析决策树列表展开节点数和目标估计位置的RMSE全局平均值的变化情况,实验结果如图9和图10所示。图9为不同阈值δ下决策树优化时展开计算的节点个数,可见随着阈值δ的增加,展开节点数呈现不断减少的趋势,且在δ=0.4时,展开节点数有了大幅度的减少。图10为不同阈值δ下目标估计位置RMSE全局平均值,可见随着阈值δ的增加,RMSE平均值也在不断增加,原因在于控制参数δ的控制范围太小,使得优胜解被剔除掉。且在δ=0.5时,RMSE平均值大幅增加。综上所述,为有效减少搜索空间并保持较高的跟踪精度,在本文实验中取δ=0.4进行实验。
4.2 场景2
在该场景中,面向多个运动目标,对移动传感器的调度问题进行研究,验证所提长期调度方法在多目标跟踪场景下的适用性。
实验参数设置:采样间隔 t=1 s,采样时间Simtime=50 s。目标数目为2,运动模型均为CV模型,目标 1 的初始状态为 x10=[3000,30,4200,-30]Tm,目标 2 的初始状态为 x20=[400,30,2400,35]Tm,传感器初始位置调整为[2000,500]m,其他传感器和目标参数与场景1保持一致。此外,分别取目标权重矩阵[W1,W2]为[0.5,0.5]、[0.8,0.2]、[0.2,0.8]进行实验。实验结果如表1、图11~图13所示。
表1为三种权重场景下不同优化时域T时的目标跟踪估计位置的 RMSE平均值,由表 1中的RMSE平均值的综合值来看。当面对多目标跟踪场景,在正收益区间内,长期调度的收益也高于短期调度收益,进一步证明了所提方法的有效性性。
图11~图13分别为三种权重场景下传感器移动优化轨迹图。可见,当移动传感器对多目标进行跟踪时,本文所提方法能够根据目标权重的不同,优先对高权重目标进行跟踪处理,从而获取更多的目标跟踪收益,体现了本文所提传感器调度模型在多目标跟踪场景下的适用性。

表1 不同权重下的目标位置RMSE平均值
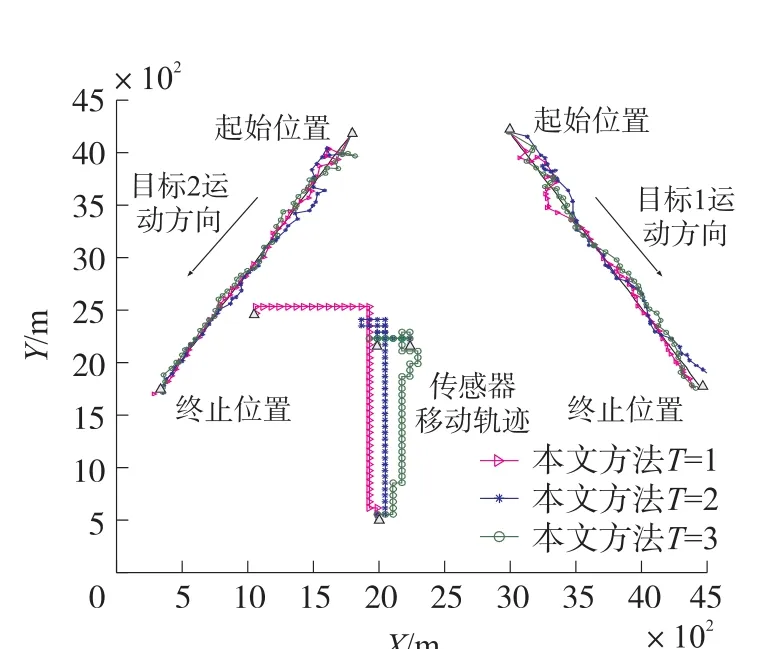
图11 权重[0.5,0.5]下的传感器优化轨迹图

图12 权重[0.8,0.2]下的传感器优化轨迹图

图13 权重[0.2,0.8]下的传感器优化轨迹图
5 结论
面向多目标跟踪需求,提出了一种基于PCRLB和目标优先级的主动式移动传感器长期调度方法。该方法以目标跟踪精度下界为调度目标,并采用目标优先级来区分目标的重要程度,实现了传感器的合理调度,并且能够获得更多的目标跟踪收益。同时,为快速求解最佳的传感器调度方案,在标准代价搜索的基础上,利用阈值剔除技术来搜索问题的解,可有效减少搜索空间,加快求解速度。
后期,将考虑传感器能耗问题,进一步完善传感器运动模型,在跟踪收益与能耗之间进行平衡,并实现多运动传感器的协同跟踪,使其更加贴近实际应用环境。
猜你喜欢
铁道通信信号(2020年10期)2020-02-07 01:01:32
成都信息工程大学学报(2019年3期)2019-09-25 08:31:10
制造技术与机床(2019年9期)2019-09-10 07:36:54
三门峡职业技术学院学报(2019年1期)2019-06-27 07:32:58
西南交通大学学报(2018年6期)2018-12-18 02:22:28
测控技术(2018年11期)2018-12-07 05:49:02
河北遥感(2017年2期)2017-08-07 14:49:00
系统工程与电子技术(2016年7期)2016-08-21 13:59:14
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
西北工业大学学报(2015年4期)2016-01-19 03:31:55
