
基于压缩感知理论的缺失数据集下线损预测模型
2019-03-18 02:57:18刘东升代盛国商学斌顾洁金之俭王颖琛李煜
广东电力 2019年2期
刘东升,代盛国,商学斌,顾洁,金之俭,王颖琛,李煜
(1.广州供电局有限公司,广东 广州 510620;2.云南电网有限责任公司西双版纳供电局,云南 景洪 666100;3.上海交通大学 电子信息与电气工程学院,上海 200240)
线损预测为找出电力系统结构和用电管理等方面所存在的问题提供依据,进而指导开展降损管理工作[1-2]。线损预测的准确性密切关系着降损措施实施的有效性。
现代电网中,智能电表采集得到的数据集成在信息平台上,构成电网运行实时数据集[3-4]。当智能电表出现各种软硬件问题、数据传输过程中采集信号突然中断以及量测补全的情况下所得到的电网运行实时数据集为不完备数据集[5]。
目前,电力系统中高频采集的线损数据面临的数据缺失情况较为严重,以96点采集为例,由于采集系统和数据处理系统本身问题导致某些数据不够,丢点数严重时会达40以上。
不完备数据集对于线损的预测精度会产生一定的影响。在缺失数据集下,常采用对原始数据集进行数据补全后再进行线损预测的方法[6],因而数据补全的恢复效果决定了线损预测的精度高低。
传统的缺失数据恢复方法一般有基于统计的简单数据补全和复杂的估算方法补全[7]。传统缺失数据恢复方法如差值法等运算机理较简单,运算量小,在处理少量数据缺失和较小数据集的数据补全方面用时短且恢复效果好;但在处理大量数据缺失和大数据集的数据补全时,由于其运算机理单一,无法对已有的数据进行分析后修补缺失数据,不能体现缺失数据集的变化趋势[8]。
当前,大数据技术已经在电力系统中得到了初步应用[9-11],压缩感知理论是近年来提出的可突破奈奎斯特采样频率的新型采样理论,该方法能高精度地恢复原始数据信息,实现数据补全与重建[12-14]。
目前电力系统中应用压缩感知理论进行处理的主要是电压等呈现明显周期性的电力信号。电网线损的特点是:每日整点线损时间序列呈现非平稳性;每日线损时间序列随着用电负荷的变化呈现一定的规律性。因此,对于压缩感知理论在线损处理方面的应用仍需要单独研究。
本文基于压缩感知理论对线损预测的缺失数据进行填补,利用改进的基于自适应噪声的完整集成经验模态分解[15-16](complete ensemble empirical mode decomposition with adaptive noise,CEEMDAN)建立线损预测模型,并应用算例对其可行性进行验证。
1 基于压缩感知理论的缺失数据恢复方法
1.1 压缩感知理论
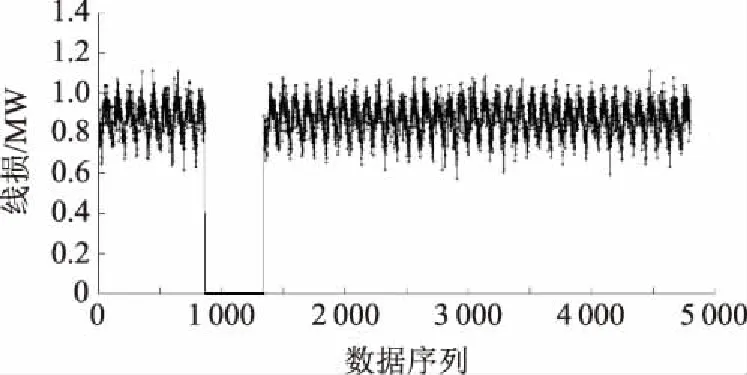
依据压缩感知原理,设原始信号为x∈RN(其中N为原始信号数据总数),选取某字典矩阵ψ将原始信号稀疏化,经过压缩可以得到观测信号y∈RM(M y=φx. (1) 设用于稀疏化的字典矩阵ψ∈RN×N,则稀疏化后的信号矩阵 θ=ψx. (2) 进而可得 y=φψ-1θ=Aθ. (3) 式中A为测量矩阵,且必须满足有限等距性质。 有限等距性质定义如下:对任意稀疏度为k的信号和常数δk∈(0,1),如果满足 则称矩阵满足有限等距性质。 此外,有限等距性质的等价条件为观测矩阵φ∈RM×N和字典矩阵ψ∈RN×N不相关。当两个矩阵互相表示所需的向量越少,就表明两者之间的相关性越强。数学表达式为: (1≤i≤M,1≤j≤N). (5) 式中:φi为矩阵φ的第i行;ψj为矩阵ψ的第j行;μ为相关性函数。 由压缩感知原理可知,数据补全效果与稀疏化字典矩阵的选取、矩阵重构算法的选取这两大因素有关[18-20]。稀疏化字典矩阵的选取原则为使得稀疏化后的原始矩阵在某个域上稀疏度最大化,矩阵重构算法的选取原则为重构效果稳定且高效。以下着重介绍具有代表性的矩阵稀疏变换方法和矩阵重构算法。 电网中所采集的电网运行数据一般为离散信号,线损数据所构成的时间序列为一维离散信号。常用的针对离散信号的稀疏变换有:离散正余弦变换(discrete cosine transform,DCT)、离散小波变换、快速傅里叶变换(fast Fourier transforma tion,FFT)、过完备原子分解等,其中FFT和DCT对于本文所涉及的线损时间序列信号的稀疏变换效果较好。 1.2.1 FFT FFT在离散傅里叶变换(discrete Fourier transform,DFT)的算法基础上进行了改进,优化了DFT运算量大和运算时间长的问题。对于一维离散信号x=(f(0),f(2),…,f(n),…,f(N-1)),其DFT为 (6) DFT的逆变换为 (7) 式中WN=e-j2π/N。 当f(k)含N个离散点时,需要N2次复数乘法和N(N-1)次复数加法。所以N越来越大时,DFT运算的复杂度也相应增大。FFT利用了WN的周期性和对称性,按时间抽取变换形式把N个点的DFT计算过程转变为一系列的迭代过程,降低了运算复杂度。 1.2.2 DCT 对于一维离散信号x=(f(0),f(2),…,f(n),…,f(N-1)),其DCT为 (8) DCT的逆变换为 (9) 式中u为测线方向的波数。当测线方向为x轴正方向时,设离散数据的采样间隔为dx,则有: (10) (11) 基于压缩感知理论的信号重构算法常见的有贪婪算法和凸松弛算法两大类。常用的贪婪算法有匹配追踪(matching pursuit,MP)算法、分段正交匹配追踪算法和正交匹配追踪(orthogonal matching pursuit,OMP)算法;常用的凸松弛算法有Dantzig选择器法和基追踪(basis pursuit,BP)算法。以下分别选取贪婪算法和凸松弛算法中两个具有代表性的信号重构算法予以介绍。 1.3.1 OMP算法 OMP算法是MP算法的一种,属于贪婪迭代算法大类。该方法运用了MP算法中的原子选择准则,通过递归方法对选中的原子集合进行正交化,以保证迭代最后得到最优解。OMP算法改进了MP算法为达到收敛可能需要的迭代次数过多且最后可能达到的是次优解的问题[21]。 OMP算法的输入有原始信号x∈RN、观测矩阵φ∈RM×N、观测信号y∈RM和原始信号稀疏度k,输出为重构信号x′∈RN。由于OMP算法的运用前提为输入的信号必须是k稀疏的,迭代次数n取决于输入信号的稀疏度k,所以若原始信号并非稀疏信号,则需要将原始信号转化为其他域的稀疏信号再作为输入信号输入。 1.3.2 BP算法 BP算法是常用的信号重构算法,属于凸松弛算法大类。该算法去除信号中的高斯白噪声,从而完成信号的重构。根据压缩感知原理,BP算法的目的是求出式(1)所示的欠定方程的解。求解的最直接方法为在0-范数下,求解如式(12)的最优解[16]: (12) 式(12)的求解问题涉及非确定性多项式难题,求解该类方程需要根据1-范数在一定条件下和最小0-范数的等价性求解,则式(12)可转化为 (13) 在有噪声存在的情况下,观测模型变为 Y=y+r=φx+r. (14) (15) 现有的线损预测方法多采用单一模型对线损序列总体进行预测,未能针对非平稳线损序列各分量特征进行细粒度分析,影响预测准确度。本文采用K-means聚类方法对历史数据进行聚类,对负荷进行分类,在各聚类内部进行数据恢复及线损预测,以提高计算精度。 线损预测的精度受训练数据集的完备程度影响较大,因此当线损数据出现缺失时,需要先完成数据的恢复与补全。传统的基于统计的数据补全方法在大数据集和数据大量缺失的情况下难以实现良好的数据补全效果。本文利用大数据理论中的压缩感知理论,选取适当的信号稀疏变换矩阵和重构算法,在完成历史数据聚类之后,对于各类历史数据分别进行数据恢复与补全,结合完备数据集下提出的预测模型,利用恢复后的历史数据进行线损预测。 综上,本文提出一种数据缺失条件下的线损预测模型,实现方法如下: a)根据电网历史数据中的总负荷、负荷率和峰谷差率3个特征量,采用K-means聚类方法对ND日历史负荷数据的各特征量按轮廓系数最大的原则进行聚类,将历史数据分为w类,含n1,n2,…,nw个相似日,且ND=n1+n2+…+nw。通过待预测日Di的3项特征量预测值确定待预测日所属类型。 b)将第t类别的历史线损数据按24个整点构成1条时间序列矩阵T=[t1[1],t1[2],…,t1[24],t2[1],t2[2],…,t2[24],…,tnw[1],tnw[2],…,tnw[24]],通过CEEMDAN将此线损时间序列分解为p个本征模态分量FIM1,FIM2,…,FIMp以及余量R。 c)选取适当的字典矩阵,将分解好的p个固有模态函数(intrinsic mode function,IMF)分量FIM1,FIM2,…,FIMp以及余量R分别进行稀疏化变换。字典矩阵的选取原则为使稀疏化变换后的矩阵稀疏度最大。 d)选取适当的重构算法,对变换后的IMF分量稀疏矩阵进行基于压缩感知理论的数据补全。重构算法的选取原则为使数据恢复效果稳定且高效。 e)对修复完的IMF分量矩阵进行稀疏化变换的逆变换,使得其恢复时域上的完备IMF分量序列。 f)将时域上的各IMF分量序列按相似日各整点再分为24条IMF分量。整理后各整点j(j=1,2,…,24)的IMF分量FIM1[j],FIM2[j],…,FIMp[j]分别作为Elman神经网络输入训练样本,根据绝对误差最小的原则选取最佳的隐含层层数,建立预测Elman网络[17]。 g)各模态分量预测值FIM1[j]′,FIM2[j]′,…,FIMp[j]′累加后得到待预测日该整点的线损预测值,即待预测日第j时刻的线损预测值X[j]=FIM1[j]′+FIM2[j]′+…+FIMp[j]′+R[j]′.数据缺失下的线损预测建模流程如图1所示。 图1 数据缺失下的线损预测建模流程Fig. 1 Flow chart of prediction modeling for line loss under data-missing condition FFT能将有一定周期性的时间序列变换为频域上的稀疏信号,故本算例采用FFT作为矩阵的稀疏变换方法。OMP算法能以很高的概率将单个稀疏信号复原,并且相比于BP算法速度更快且易于实现,更适用于大数据集的数据修复,因此本算例选取OMP算法为压缩感知理论的重构算法。 以某10 kV配电网2017年1月1日至9月2日共计246日、每日24个整点的全网线损数据和节点负荷作为历史数据样本,此样本可看作大数据源。以配电网总负荷、负荷率和峰谷差率作为聚类样本特征输入,选择最大轮廓系数下的聚类数作为样本聚类数,将历史数据分为两大类。 该配电网每15 min采集一次线损数据,每日共96个数据点。选取其中已聚类完的50个相似日共4 800个点构成线损时间序列,如图2所示。 在实际应用中,一维信号数据量超过100时即可视为大数据,故50个相似日构成的线损时间序列可以验证本文提出的方法和模型在大数据情况下的适用性。 图2 50个相似日线损时间序列Fig. 2 Daily line loss time-sequence of 50 similar days 由图2可知,50个相似日线损时间序列以日为单位呈现一定的周期性,这与电网的线损一般随负荷波动而变化的性质有关。 模拟第10日到第14日共5日的线损数据缺失,即50个相似日线损时间序列的第865点至第1 344点缺失,共缺失480个数据点,数据缺失率为10%。将数据集中的缺失数据置0,则含缺失数据的50个相似日线损时间序列如图3所示。 图3 含缺失数据的50个相似日线损时间序列Fig.3 Daily line loss time-sequence of 50 similar days with missing data 采用4种不同的数据恢复方法,分别对第3.1节中含数据缺失的50个相似日线损时间序列进行数据补全,修复效果如图4所示。其中,三次多项式插值法、线性插值法和最小二乘搜索法为传统的缺失数据恢复方法。 线性插值及三次多项式差值两种数据修复方法在数据缺失较大时,修复效果很差,不仅误差很大,而且没有反映出缺失数据序列随时间的变化规律。 最小二乘搜索法可以在一定程度上还原原始数据的周期性,但是与原始数据有一定的误差,也无法体现线损随时间的变化规律。而且该方法需要依据经验设定初始的函数模型,受人为因素影响较大。 (a)线性插值法 (b)三次多项式插值法 (c)最小二乘搜索法 (d) 本文方法图4 4种数据恢复方法的数据修复效果Fig.4 Data repairing effect of four methods 本文选取FFT为原始矩阵的稀疏化变换方法,将原始信号变换至频域上。该原始信号为频域上的稀疏信号,经过测量可得该原始信号频域上的稀疏度k,即变换后信号在频域过零点的个数为1 911。选取OMP算法作为压缩感知恢复数据的重构算法,算法迭代次数设为2k,即3 822次。由图4(d)可知,用该方法恢复的数据虽然和原始数据也有一定的误差,但很好地还原了原始数据的变化趋势和周期性,比最小二乘搜索法的修复效果更接近原始数据。 数据修复平均绝对误差和数据缺失率的关系如图5所示。由图5可知,随着数据缺失率增大,平均绝对误差也随之增大。由于原始数据周期性较好,没有出现特别的突变点,故恢复后的效果较好,当数据缺失率在50%以下时,平均绝对误差稳定在3%~4%。 图5 数据修复平均绝对误差和数据缺失率的关系Fig.5 Relationship between MAE of data repairing and data missing rate 取50个相似日线损数据中的前4 799个数据,分别模拟数据缺失率在10%~90%的情形,并对数据采用压缩感知法、最小二乘搜索法及插值法进行数据修复后,结合完备数据集下的预测模型进行网络训练,输出第4 800点的线损预测值。采用3种数据恢复方法所得到的线损预测值相对误差绝对值见表1。 表1 3种数据恢复方法的线损预测值相对误差绝对值比较 数据缺失率/%线损预测值相对误差绝对值传统插值法最小二乘搜索法本文方法104.451.430.502011.133.550.153013.486.984.644015.638.347.195015.9510.908.106017.7911.549.527020.2512.679.648021.0113.8910.159027.9725.4423.60 由表1可知,在任何数据缺失率下,线损预测误差由大到小依次为:传统插值法、最小二乘搜索法、本文方法。当数据缺失率特别大或特别小时,3种方法的预测效果差别不大。当缺失率特别大时,从已有的数据中已经很难预测出缺失数据的变化规律,因此3种预测方法均误差较大;当数据缺失率特别小时,已有数据较全面,传统数据补全法也能较好地恢复数据,因此基于大数据理论的压缩感知方法优势不明显。 目前,对线损预测的精度要求一般为小于2.5%。采用传统插值法补全数据后预测线损时,数据缺失率在10%以下可能仍无法达到该精度要求。采用压缩感知法补全数据后预测线损时,数据缺失率在20%以下即可以达到该精度要求。 本文提出了一种基于压缩感知理论的缺失数据集下线损预测模型。压缩感知理论是近年来基于大数据理论的一种新型采样技术。相比于传统的数据恢复方法,基于压缩感知理论的数据修复方法在数据量较大或数据缺失情况较严重的情况下,仍能较好地修复原始数据,恢复原始数据的变化趋势。CEEMDAN能够以极高的精确度重构原信号,解决了集成经验模态分解(ensemble empirical mode decomposition,EEMD)在实验次数较少的情况下重构误差大的问题。某10 kV配电网算例的验证结果表明,在数据修复效果及线损预测精度方面,本文提出的方法较传统数据恢复方法更有优势。 本文算例仅考虑了连续缺失数据的情况,未考虑其他情况。本文所提出的线损预测模型在非连续缺失数据的情况下是否适用,可在今后的研究中进一步验证。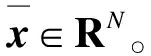
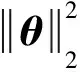
1.2 矩阵稀疏变换方法
1.3 重构算法

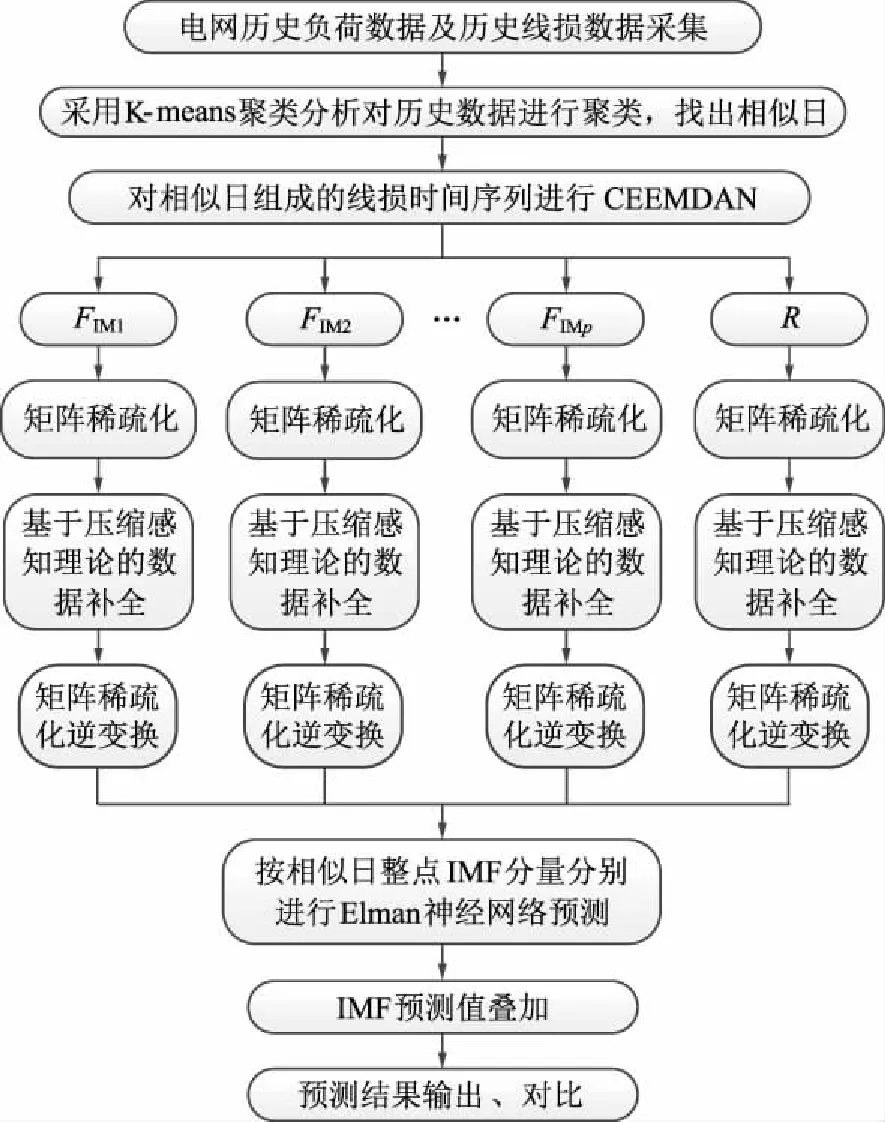
2 数据缺失条件下线损预测模型实现
3 算例分析
3.1 算例介绍

3.2 不同数据恢复方法的数据修复效果比较





3.3 基于不同数据恢复方法的线损预测结果比较
Tab.1 Comparison of relative error absolute values of prediction values of three data repairing methods
4 结束语
猜你喜欢
China Report Asean(2022年8期)2022-09-02 05:31:26
摄影世界(2022年1期)2022-01-21 10:50:14
物联网技术(2020年12期)2021-01-27 03:34:08
知识经济·中国直销(2018年12期)2018-12-29 12:22:14
电子测试(2017年15期)2017-12-18 07:19:27
商周刊(2017年6期)2017-08-22 03:42:36
汽车零部件(2017年4期)2017-07-12 17:05:53
山东大学法律评论(2016年0期)2016-08-16 03:24:12
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
