
基于权重的SVM预测模型的设计与实现
2019-03-15 01:29李开阳
电子制作 2019年4期
李开阳
(河南大学附属中学,河南开封,475000)
0 前言
随着人们生活水平的不断提高和消费意识的不断改进,菜品的需求等级越来越高。为了便利人们并满足其需求,本文利用数据仓库和数据挖掘技术分析存放在数据库中大量的菜谱信息并以此预测世界各地的菜品及其分属的菜系。论文的研究在于通过对分属不同菜系的菜品进行以支持向量机(SVM)为主,以Python为辅的有效方法,并基于TFIDF加权技术进行数据分析。从多方面构建数据挖掘模型,直观有效地反映出数据挖掘的分析结果。基于已有的数据分析模型,并根据最终的详细分析数据,把菜品的成分与其分属的菜系进行有机结合。
这些被挖掘并整理过后的数据和模型,不仅可以为餐厅或餐饮APP等餐饮机构提供有效信息,还可以增进人们对餐饮文化的了解,丰富人们的知识。
1 国内外研究现状
1.1 国内研究现状
近年来,大数据一度成为网络热词,人工智能也不断发展,二者的重要技术—数据挖掘,受到了更多人的关注。数据挖掘,就是从大量的,随机的数据库中,提取隐含在其中人们事先不知道,但又有潜在有用信息的过程。数据挖掘,它是一种多学科相互综合、相互渗透的技术,它以传统的数据库技术为基础,运用多种手段分析数据,对海量数据进行知识发现,并进行恰当的可视化表示,是一种高效的预测决策系统解决方案。基于数据挖掘技术的预测决策系统,利用挖掘技术,通过构建预测决策模型,对生产和计划的完成情况及相关环境数据进行多角度、多层次的分析,帮助决策者及时掌握计划的运行情况和发展趋势。
1.2 国外研究现状
1.2.1 TF-IDF(特征向量分类)
IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。
1.2.2 SVM(支持向量机)
原始SVM算法由Vladimir N. Vapnik和Alexey Ya发明。当时这方面的研究尚不十分完善,且数学上比较艰涩,大多数人难以理解和接受。近年来,许多关于SVM方法的研究,包括算法本身的改进和算法的实际应用,都陆续被提了出来。随着支持向量机的不断发展,人们对支持向量机的研究也越来越细化,其要研究方向大致可分为:求解支持向量机问题,支持向量机多类分类问题,参数的选择和优化问题等。
2 数据来源与处理和模型假设
本研究选取了kaggle数据挖掘竞赛网下载的世界各地的不同菜系所包含的主要成分,并赋予每个菜系不同的编号。
研究中所有的菜系成分和可能影响因素皆来自Kaggle网站。这些数据均以微软Excel表格形式存储。
面对66万的训练数据和15万测试数据,数据较为庞杂,但内容较为全面。不同菜系已经用”id”编号。于是,我们对数据经行了细致的检查,并未发现数据有缺失或遗漏现象,且系统较为完备。我们参考了关于SVM的一些论文,建立了SVM模型。
3 TF-IDF
3.1 概念
TF-IDF 的概念被公认为信息检索中最重要的发明。在搜索、文献分类和其他相关领域有广泛的应用。
词频又叫TF-IDF,可以给重要的词加上一个权重。我们经常需要一个词来概括并代表一篇文章的写作意图,而TF-IDF就可以对此进行统计,用以找出对于一份文件较为重要的词汇。TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力适合用来分类。它能够反映这篇文章的特性,某个词对文章的重要性越高,它的TF-IDF值就越大。所以需要用TF-IDF来进行信息检索。
3.2 算法介绍
现在有一个给定的文件,如果用词数来度量该文件中一个词的重要程度,这显然是不合理的,因为在一个较长的文件里相同的一个词语很有可能比在短文件中出现的次数高,但这个词本身可能对该文件并不重要。用这个给定的词语在文件中出现的频率,也就是词频,来进行对词数的归一化,就可以防止它偏向长的文件。如图1所示。
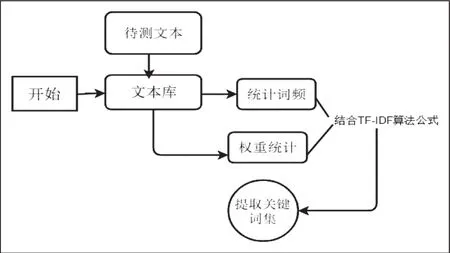
图 1 TF—IDF 流程图
在向量空间模型中,它经常会和余弦相似度一同使用,用来判断两份文件之间是否相似。每种成分对该菜系的贡献值由向量中每一个维度的大小来决定。根据余弦定理,可以求出特征向量之间的夹角(夹角在0度到90度之间)如图2所示。
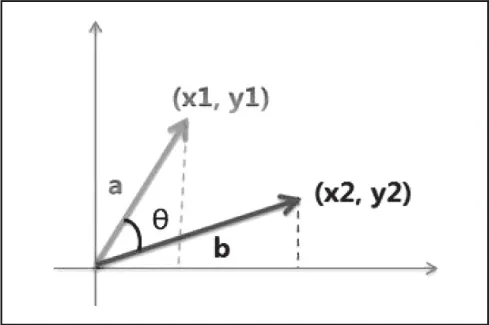
图2 特征向量的计算
两向量夹角的余弦等于1时,也就是夹角为0,说明这两种菜系的成分完全相同;当夹角的余弦接近1时,这两种菜系的成分基本相同,也有可能完全一致,目标菜系与该菜系基本相似,从而可以归成一类;夹角的余弦越小,说明他们之间的成分差距越大。
3.3 优点与缺点
优点:一是解决了分类器不好处理离散数据的问题;二是在一定程度上也起到了扩充特征的作用。
缺点:在文本特征表示上有些缺点就非常突出了。首先,它是一个词袋模型,不考虑词与词之间的顺序;其次,它假设词与词相互独立(在大多数情况下,词与词是相互影响的);再次,它的独立性不强;最后,它得到的特征是离散稀疏的。
4 利用支持向量机模型来推测菜系
4.1 支持向量机(SVM)
支持向量机简称SVM,是20世纪末期发明的一种分类算法。其原理类似于种西瓜,切西瓜,即对低维的数据升维,将数据映射到高维特征空间,之后对生成的多维物体在特征空间内用超平面切割从而再获得分类后的低维数据,达到分类的效果。
4.2 升维与降维
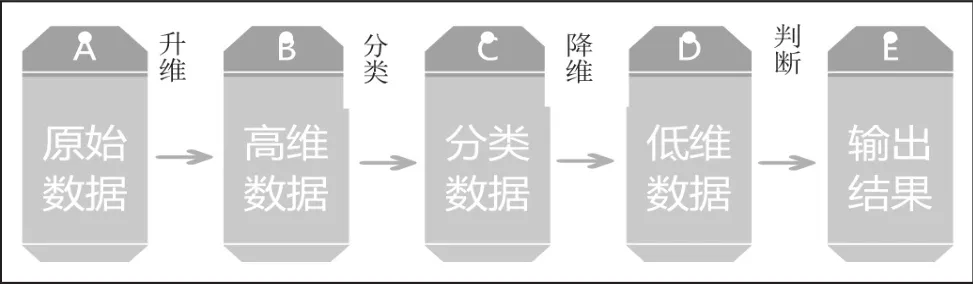
图3 SVM流程图
升维是针对在低维不容易分类的元素,将其转化成高维,再进行分类。升维的效果有两种,一是针对低维的数据可以直接用升维后的本质差别将其分离。如图4所示。二是可以拉大低维数据间的差距使之容易分类例如10与9低维差距并不大,可是假如升维成(10,100)和(9,81)差距值增大且差值所占比例也增大了,这也更容易分出类别。
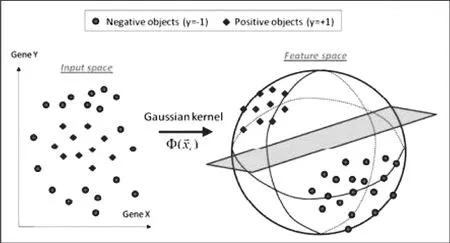
图4 低维数据映射分类
4.3 超平面
支持向量机的重点是高维分类,而高维分类的核心就是超平面。经过升维后,计算机通过计算点间的距离,确定两类间相邻最近的两点,在两点间算出超平面使之与两点间距离相等,作其中垂线并进行适当升维,产生超平面。于是,数据就被轻松地分为了两类。然而,有时由于存在异常数据,SVM的精准度会大打折扣,容易导致其过拟合。我们引入了松弛变量,将超平面模糊化,使其变为一个允许计算机出错的范围。为了提高精度,我们又引入了惩罚参数,赋予每个结果一定权重,降低超平面附近结果以及异常数据的权重,从而提高精度。这个过程就叫做正则化。
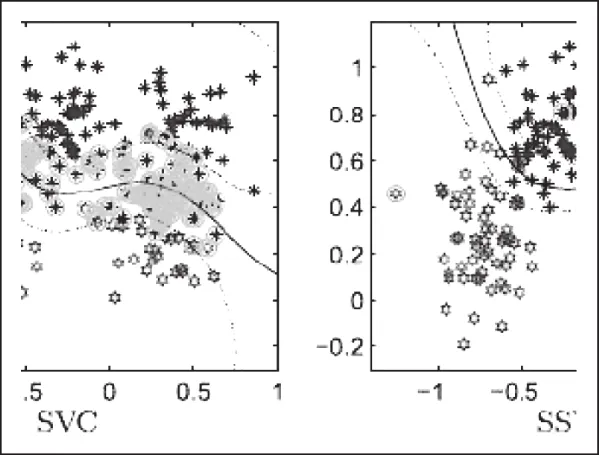
图5 超平面模糊化
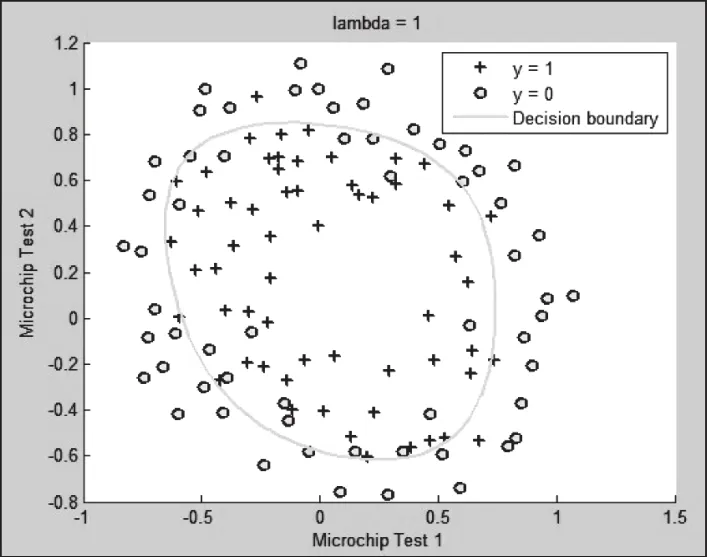
图6 正则化
4.4 优点与缺点
优点:支持向量机对于大部分数据具有极高的应用价值,针对界限规则的数据它可以巧妙地运用维度的改变,快速建立起较为规范的模型,运用规范的超平面,快速分类。
缺点:大多只用于二分类,多类会造成结果的不精确,因此较之于决策树不具有普适性。且超平面的建立较为机械,无法进行自动规避,受异常数据干扰较大,鲁棒性不强。
5 循环语句
循环语句出现较早,是一种类似于决策树的推测方法。在漫长的筛选中,像离心机一样,元素间差异会不断被扩大,进而筛选出最相似的元素,排除噪声元素,并输出结果,达到精确导入,精确分类,精确输出的效果。
6 世界各地菜系推测与最常见的十种成分预测
我们建立了三种模型,用测数据进行了实验,表1是部分结果。
通过基于python语言的循环语句,我们整理出了世界各地菜系中最常见的十种成分。经过可视化处理后整理如图8所示。
由图8可看出,十种成分由多到少分别是盐、洋葱、橄榄油、大蒜、糖、蒜瓣、黄油、黑胡椒粉、面粉。这与世界范围内不同菜品的受欢迎程度是有很大关系的。
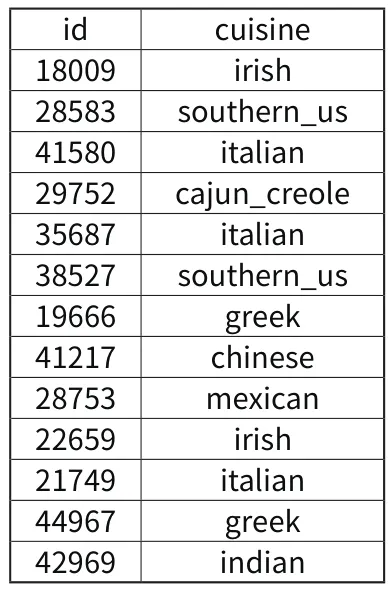
表1 部分预测结果
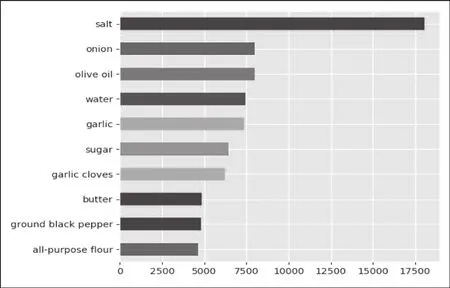
图8 十种常见成分
7 结论与展望
本文使用了Kaggle网站的数据,利用多个维度的数据对菜品的菜系进行预测。
通过这一系列操作,我们发现在世界各地的诸多菜品之中,最常见的成分有十种,按常见程度从高到低排列为盐,洋葱,橄榄油,水,大蒜,糖,蒜瓣儿,黄油,黑胡椒,面粉。根据成分的含量多少,国别,地区,将世界各地的菜品大致分成了十几种菜系。

图9 预测流程图
一般的 TF-IDF 算法常常可能屏蔽这些出现次数较少的文字。因此我们探索了一些改进措施,例如 Mingmin Xu 等提出了一种基于 TF-IDF 的 改进算法,命名为信道分配信息,该方法通过原始数据的统计特征来识别核心词。罗欣等则基于 TF 改进原始算法,该算法以词频差异为基础,用信息量来重新计算TF 值。
上述两种改进措施虽然能够找到文本一些出现频率较低的重要词汇,并获取该文本的特征向量,但它同时也增长了计算时间,使其变得复杂。再次查阅相关资料,我们还可以根据数据自身的特点,然后将行业专有词典运用到原始的TF-IDF特性选择的过程中,从而在获取出现频率较低的关键词的同时避免了较大的时间复杂度,通过该算法获取的特征空间结构稳定,能够使其准确性提高。
模型预计改进方案:
经过查阅资料,分析并对比,发现了一个较为有效的新模型—关联规则分析模型。Apriori 算法是一种挖掘关联规则的频繁项集算法,其核心思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集。其主要操作流程如图10所示。
本文的研究工作有以下亮点:
(1)基于TF-IDF加权技术构建相对稳定的支持向量机算法模型以达到比较准确的预测菜品所分属的菜系的目的。
(2)使用构架好的数据模型分析了诸多菜品中最常出现的十种元素。但本文的研究尚存在一些不足,以后的研究中可以加入以下几种方法:
①可以同时选取支持向量机算法模型、随机森林算法模型以及逻辑斯蒂多元回归预测法进行多次预测,分别得出结论后投票决定最佳分类;
②在本文中,由于篇幅原因尚未对比三种模型的预测结果。在未来的工作中,可以把三种模型的预测结果整合并对比和分析其优劣。留给人们更多的操作空间。
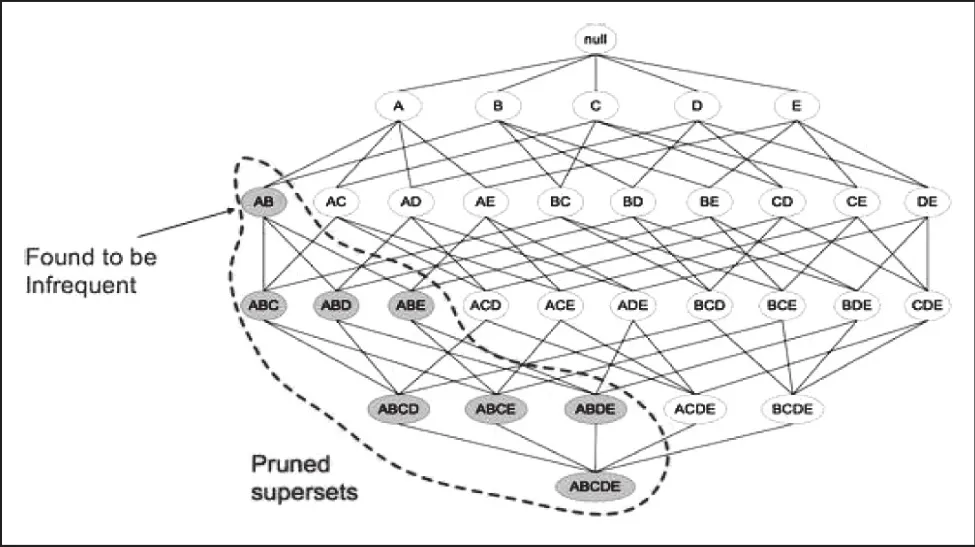
图10 Apriori模型流程图
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
国际商业技术(2021年9期)2021-05-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
意林·少年版(2020年20期)2020-11-06
烹调知识(2018年7期)2018-06-28
意林·少年版(2017年11期)2017-07-07
烹调知识(2017年6期)2017-06-16
美食(2016年10期)2016-08-22
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
