
基于机器学习LightGBM和异质集成学习方法的新闻分类
2019-03-15 01:29李安
电子制作 2019年4期
李安
(陕西省西安中学,陕西西安,710000)
1 概述
在机器学习领域,对分类模型的研究具有重要的意义。集成学习作为一种能够有效提高分类模型性能的方法也被广泛使用。集成学习分为两种类型,包括同质集成学习与异质集成学习,目前在实际应用中,大多数采用同质集成学习,包括sklearn等主流的机器学习框架,都实现了同质集成学习。因此,对于异质集成学习进行探索就有了重要意义。
娱乐文章按体裁能分成七类:资讯热点,电影电视剧报道评论,人物深扒,组图盘点,明星写真,行业报道,机场图。本文依据娱乐新闻分类这一具体问题,通过对不同模型的综合分析,探究异质集成学习的方法,将文章进行多分类。
1.1 数据集特征
娱乐新闻的数据集特征由分词和去停用词以及TF-IDF处理后的4700维构成。
1.2 数据集预处理
1.2.1 去停用词
由于并不是每一个词都能表征这篇文章的内容,如果保留,输入特征会很大,影响训练效果,因此有一些形如“这样”“1.2.3.4”的词就应该被删除掉,可以从网络上寻找一份中文的停用词表作为参考。将文章中的词与停用词表中的词作比较,如果在表中出现该词,就将其删除,如果没有出现,就跳过。
1.2.2 分词
文本分词是文档处理中的一个不可或缺的操作,因为之后的操作需要用文章中的词语来代表这篇文章的主要内容的概括。本文中对文章进行分词主要操作步骤如下:构造语料库词典和进行文章分词操作。
目前在nlp领域用来构造词典的主要方法是字典树。对于分词,主要采用的有正反双向最大匹配以及nlp语言模型和最短路径等相关的算法。
对于我们的问题而言,我们使用的是jieba分词库。
1.2.3 tf-IDF
tf-IDF指标是一种基于概率论的统计学方法,用于评估一篇文章中的某一字词的对于一个语料库中的文件集合中的其中一个文件的重要程度,词语的重要程度和其在一篇文章中出现的次数是正比关系,但是和其在文件集合中出现的次数成反比关系。通俗地说,就是一个词在某篇文章中出现的次数越高,而在这一堆文章中的其他文章中出现越少,它就更能表征这篇文章的内容。
词频(TF)指的是一个给定的词语在某篇文章中出现的次数,为了防止文章过长导致频率偏向长文章,这个指标一般会采用某种方式进行归一化操作(常常用出现的频数/文档总词数)。
Tf-IDF指标的计算方法是由语料库中文档的总数除上出现该词语的文档数,将结果再取对数,TF·IDF=TF*IDF。
为了简化计算,针对数据集,做出每4700词划分一次的调整,长度大于4700的进行切分,小于4700的进行填充。
1.3 数据集划分
将9000篇文章中,30%划分为训练集,70%划分为测试集。
2 构建传统机器学习模型
2.1 构建朴素贝叶斯模型
2.1.1 基本原理
朴素贝叶斯是经典的机器学习算法之一,通过考虑特征概率来预测分类,是为数不多的基于概率统计学的分类算法。
朴素贝叶斯的核心是贝叶斯定理,而贝叶斯定理的公式本质上是条件概率。
贝叶斯法则如下:
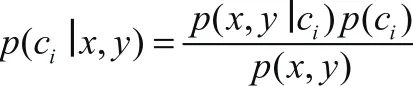
这里的C表示类别,输入待判断数据,式子给出要求解的某一类的概率。我们的最终目的是比较各类别的概率值大小,而上面式子的分母是不变的,因此只要计算分子即可。
2.1.2 算法效果
运用朴素贝叶斯模型进行预测,在训练集上达到了71.59%的准确率,在测试集上达到了69.89%的准确率,如图1所示。

图1
2.2 logistic模型
2.2.1 logistic原理
Logistic模型是人工智能中的一种被广泛使用的分类模型,对于一般的分类问题而言,具有良好的性能。Logistic模型使用S函数作为我们的预测函数,去估计概率P(y | x)的大小。如果P大于0.5,我们则认为属于“1”类别,否则属于“0”类别。在娱乐新闻分类问题中,S函数的输出就是属于每一类娱乐新闻的几率值,大小取值在0到1之间。Logistic模型在训练阶段,通过随机梯度下降法SGD去不断的最小化预测函数在训练集娱乐新闻上的误差,来提高模型的泛化能力。为了避免模型陷入过拟合,在代价函数上采用相应的正则化手段,可以缓解模型的过拟合程度。
2.2.2 logistic的假设函数
假设函数采用sigmoid函数,函数形式为如2-1式,取值范围为[0,1]。代表了测试样本新闻属于某一类的概率。其中z = θTxX,θ是模型需要学习的参数,X在该问题中对应每篇文章的特征向量。即z是一篇新闻所有特征的线性组合。

2.2.3 逻辑回归的loss function
Loss function又称为代价函数、损失函数,是我们将机器数学问题抽象成数学问题后所对应的优化目标,主要用来评价模型的好坏,在训练集上的预测误差越小,loss function就越小,在训练集上的误差越大,则loss funciton也就越大。机器学习的训练过程,本质上就是通过SGD等优化算法来不断的更新模型权重,从而不断的减小模型的预测误差。
机器学习中比较常见的loss funciton有均方误差和cross entropy误差。均方误差一般用于regression问题中,cross entropy一般用在classi fi caton问题中。对于娱乐新闻分类问题而言,其是一个分类问题,因此我们采用了cross entropyloss function。cross entropyloss function的公式如2.2式。公式中的g(θ)代表了逻辑回归函数的输出,log代表以10为底的对数,yi代表样本的真实分布。
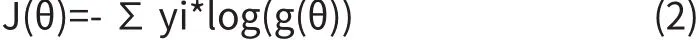
2.2.4 logistic模型存在的问题
从数学优化上来讲,模型每次更新权重时,loss function都可以有一定的降低,在降低到很小的某一个值后,在其附近波动。但是loss function过低的风险是模型会过拟合。模型过拟合后,虽然模型在训练集上的误差很小,但是在测试集上的误差将会非常大[2],无法得到良好的预测性能。
2.2.5 逻辑回归的正则化
为了解决上述提到的模型可能陷入过拟合的问题,需要采取一定的措施。在机器学习中,我们可以通过增加训练集样本的数目去缓解过拟合,但是通常增加训练集数目的成本过高,因此可以使用另外一种常见的手段-正则化。正则化一般有L1正则,L2正则。在我们的问题中采用L2正则化,加入正则化项的代价函数如2.3式,其中C为正则化参数。
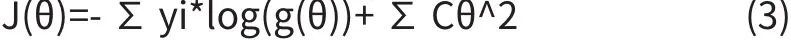
2.2.6 结果分析
通过在训练的过程中加入的L2正则化项,我们的模型基本没有发生过拟合,在训练集上达到了80.32%的准确率,在测试集上达到了74.31%的准确率,如图2所示。
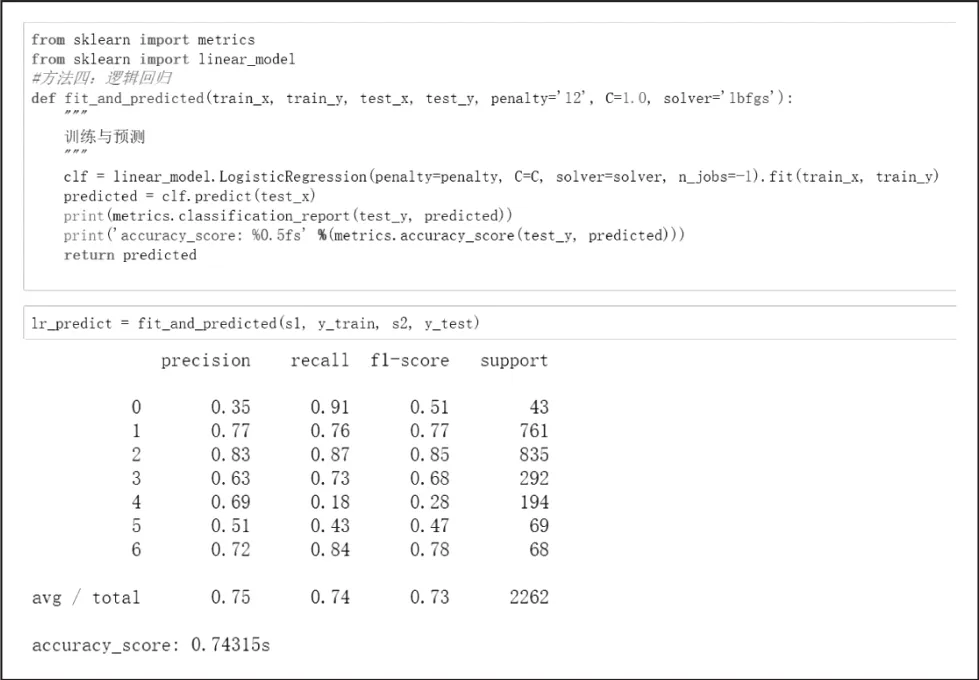
图2
逻辑回归的优点是在于简单,训练速度较快。但是其一般更适合用于线性可分的问题当中,而对于一些线性不可分的问题中,采用更复杂的非线性模型可能会取得更好的效果。
3 Ensemble learning
3.1 Ensemble learing基本原理
机器学习中的分类模型在训练结束后,我们希望训练出一个在各种指标下的表现都十分良好的模型,但是真实的情况往往不是如此,一个模型在某些评价指标上表现良好,在另外的评价指标上的表现可能就很差。通常我们只能得到在某几个指标下表现良好的多个单一的分类模型。Ensemble learing的主要思想就是将多个单一的分类模型的结果综合起来考虑,来获得最后的分类结果。在这种情况下,模型对某几个模型产生的错误就会具有一定的容错性。
因此,从Ensemble learing的学习思想我们可以把集成学习分为两个主要的步骤,第一步是获得多个在某些指标上表现良好的单一分类器,第二步是采用某种算法将这些单一分类器的预测结果综合起来考虑,获得最后的预测结果。
Ensemble learing通常包含两种方式,同质集成学习和异质集成学习。同质集成学习是指只使用一个模型,但是在该模型下选取不同的超参数,从而获得不同的个体分类器。异质集成学习是指使用不同的模型,把不同模型的结果综合起来,得到最后的预测结果,比如就一个基本分类问题而言,我们可以采用决策树模型、SVM模型、logistic模型获得不同的预测结果,再将结果综合起来,得到最终的预测模型。
在现在的人工智能领域,通常使用基于决策树的同质集成学习。一般情况下,在无特殊说明时,我们都是指的这种集成方式。在这种学习方式中,个体分类器通常使用决策树模型。不同的决策树模型即可以通过bagging的方式来并行得到,也可以通过boosting的方式来串行得到。bagging方式每种分类器之间相互独立,boosting方式每种分类器之间相互依赖。
在我们的娱乐新闻分类问题中,我们采用基于boosting的方式来实现我们的分类算法。
3.2 LGB模型
LightGBM是一个基于GBDT树的机器学习框架,Boosting算法通过使用一个叠加型的函数模型,选取某种函数作为优化目标,逐步优化,得到最后结果。
3.3 结果分析
运用lightGBM模型模型进行预测,在训练集上达到了78.50%的准确率,在测试集上达到了73.34%的准确率,如图3所示。
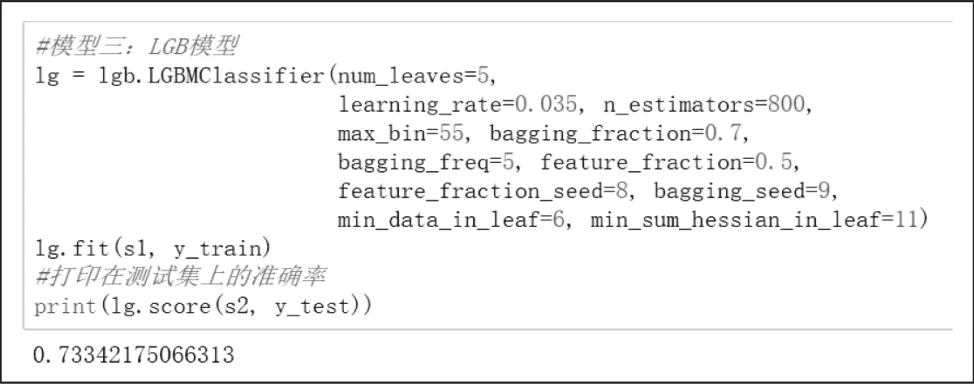
图3
4 应用异质集成学习方法综合各模型的预测结果
在上述三个模型的预测基础上采用投票的方法进行集成,在测试集上达到了75.19%的准确率,如图4所示。
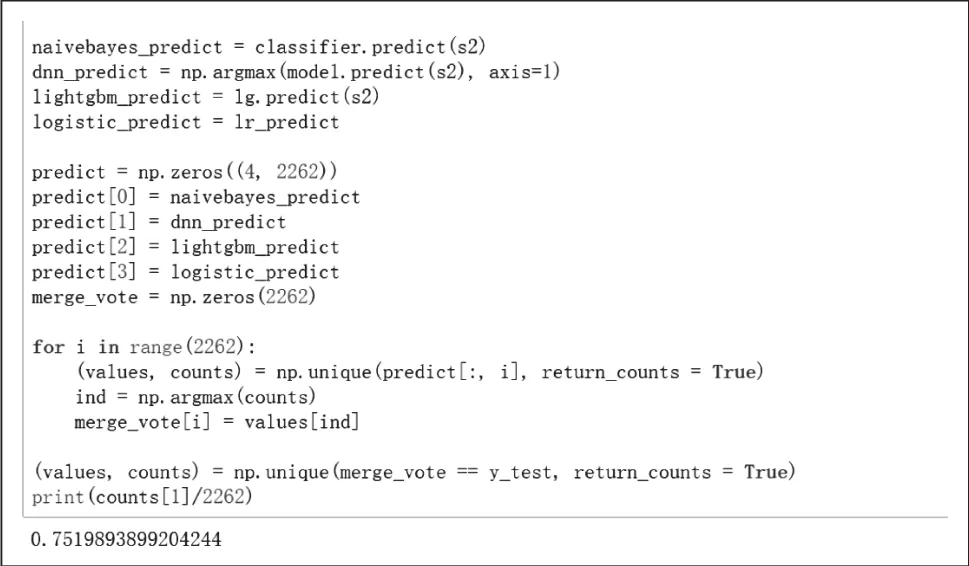
图4
5 结语
本项目根据具体的娱乐新闻分类数据,在该数据上分别采用了朴素贝叶斯算法,逻辑回归算法,LightGBM算法。在测试集上分别取得了69.89%,74.31%,73.34%的准确率。证明了在采用了基于boosting的集成后,提高了在测试集上的准确率,相比单独使用一个分类器而言,表现出了集成算法的优点。
猜你喜欢
计算机研究与发展(2022年1期)2022-01-19
华南师范大学学报(自然科学版)(2021年5期)2021-11-09
计算机应用(2020年12期)2020-12-31
中国航海(2019年2期)2019-07-24
上海师范大学学报·自然科学版(2018年3期)2018-05-14
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
神州·上旬刊(2017年9期)2017-10-15
数学学习与研究(2017年10期)2017-06-22
