
基于自监督学习的番茄植株图像深度估计方法
2019-03-05 04:05周云成许童羽邓寒冰
农业工程学报 2019年24期
周云成,许童羽,邓寒冰,苗 腾,吴 琼
基于自监督学习的番茄植株图像深度估计方法
周云成,许童羽,邓寒冰,苗 腾,吴 琼
(沈阳农业大学信息与电气工程学院,沈阳 110866)
深度估计是智能农机视觉系统实现三维场景重建和目标定位的关键。该文提出一种基于自监督学习的番茄植株图像深度估计网络模型,该模型直接应用双目图像作为输入来估计每个像素的深度。设计了3种面向通道分组卷积模块,并利用其构建卷积自编码器作为深度估计网络的主体结构。针对手工特征衡量2幅图像相似度不足的问题,引入卷积特征近似性损失作为损失函数的组成部分。结果表明:基于分组卷积模块的卷积自编码器能够有效提高深度估计网络的视差图精度;卷积特征近似性损失函数对提高番茄植株图像深度估计的精度具有显著作用,精度随着参与损失函数计算的卷积模块层数的增加而升高,但超过4层后,其对精度的进一步提升作用不再明显;当双目图像采样距离在9.0 m以内时,该文方法所估计的棋盘格角点距离均方根误差和平均绝对误差分别小于2.5和1.8 cm,在3.0 m以内时,则分别小于0.7和0.5 cm,模型计算速度为28.0帧/s,与已有研究相比,2种误差分别降低了33.1%和35.6%,计算速度提高了52.2%。该研究可为智能农机视觉系统设计提供参考。
图像处理;卷积神经网络;算法;自监督学习;深度估计;视差;深度学习;番茄
0 引 言
视觉系统是智能农机进行环境感知的重要部件[1]。在日光温室或田间环境下,采用自主工作模式的智能农机需要规划行进路线[2],规避障碍物[3],同时在果实采摘[4]、对靶施药[5]等自动化生产过程中则需要识别并定位作业目标,这些都要求视觉系统具有目标定位、三维场景重建等功能,而深度信息的获取是实现这些功能的关键。
基于图像特征的立体视觉匹配法和以激光雷达(light detection and ranging,LiDAR)、Kinect为代表的深度传感器等常被用于植株的深度信息获取。立体视觉匹配算法用各像素点局部区域特征,在能量函数的约束下进行双目图像特征点匹配,实现深度信息恢复。翟志强等[6]以灰度图像的Rank变换结果作为立体匹配基元来实现农田场景的三维重建,其算法的平均误匹配率为15.45%。朱镕杰等[7]对棉株双目图像进行背景分割,通过尺度不变特征转换算子提取棉花特征点,并通过最优节点优先算法进行匹配,获取棉花点云三维坐标。由于田间植株图像颜色、纹理均一,传统算子提取的特征可区分性差,特征点误匹配现象严重。Hämmerle等[8]使用LiDAR获取作物表面深度信息进行作物表面建模。程曼等[9]用LiDAR扫描花生冠层,获取三维点云数据,通过多项式曲线拟合算法获取冠层高度特性。LiDAR可快速获取高精度深度信息,但设备价格昂贵[3],且无法直接获取RGB(红绿蓝)图像进行目标识别。肖珂等[2]利用Kinect提供的RGB图像识别叶墙区域,并与设备的深度图进行匹配,测算叶墙区域平均距离,用于规划行进路线。Kinect可同时获取RGB图像和像素对齐的深度图,但该传感器基于光飞行技术,易受日光干扰、噪声大、视野小,难以在田间复杂工况下稳定工作。数码相机技术成熟、稳定性高、价格低廉,如果能够在基于图像的深度估计方法上取得进展,其将是理想的智能农机视觉感知部件。近几年,卷积神经网络(convolutional neural network,CNN)在目标识别[10]、语义分割[11]等多个计算机视觉领域取得了突破,在深度估计方面也逐渐得到应用[12]。Mayer等[13]通过监督学习的CNN模型实现图像每个像素的深度预测。但监督学习方法存在的主要问题是对图像样本进行逐像素的深度标注十分困难[14],虽然Kinect等深度传感器能够同时获得RGB图像和深度,但深度数据中存在噪声干扰,影响模型训练效果[15]。Godard等[16]提出一种基于左右目一致性约束的自监督深度估计模型,在KITTI(Karlsruhe institute of technology and Toyota technological institute at Chicago,卡尔斯鲁厄理工学院和芝加哥丰田技术研究院)数据集[17]上取得了良好的效果,该方法是目前精度最高的自监督深度估计方法[18]。与KITTI等数据集相比,田间植株图像变异性小,CNN用于该类图像深度估计的方法及适用性有待进一步探讨。
鉴于此,本文针对智能农机视觉系统对深度信息获取的实际需求及问题,以番茄植株图像深度估计为例,借鉴已有研究成果,提出一种基于自监督学习的番茄植株图像深度估计网络模型,该模型直接应用双目图像作为输入来估计每个像素的深度。利用卷积自编码器为模型设计网络主体结构。针对现有损失函数存在的不足,提出引入卷积特征近似性损失作为网络损失函数的一部分。以重构图像相似度和棋盘格角点估计距离误差等为判据,验证本文方法在番茄植株图像深度估计上的有效性,以期为智能农机视觉系统设计提供参考。
1 番茄植株双目图像数据集构建
1.1 图像采集设备及双目相机标定
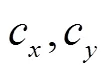
1.2 试验条件及数据集构建
番茄植株双目图像数据于2018年5月采集自沈阳农业大学试验基地某辽沈IV型节能日光温室(长60 m,宽10 m),番茄品种为“瑞特粉娜”,基质栽培、吊蔓生长,株距0.3 m,行距1.0 m,此时番茄处于结果期,株高约2.7 m。分别在晴朗、多云、阴天天气的上午9:00-12:00进行图像采集。首先在番茄行间采集两侧植株图像,受行距约束,相机离株行的水平距离在0.5~1.0 m之间。同时在行间沿株行方向对相机目视前方场景进行采样。共采集番茄植株双目图像12 000对。基于相机内、外参数,采用Bouguet法[20],通过OpenCV编程对采集的番茄植株图像进行极线校正,使双目图像的光轴平行、同一空间点在双目图像上的像素点行对齐。校正后的双目图像构成番茄植株双目图像数据集,其中随机选择80%的图像作为下文深度估计网络的训练集样本,其余20%作为测试集样本,每个深度估计网络重复试验5次。采用相同的图像采集与校正方法构建含棋盘格标定板的植株双目图像数据集,图像采集时在场景中放置单元格大小已知的棋盘格标定板,分别在相机镜头距离标定板支架0.5~3.0、3.0~6.0、6.0~9.0 m范围内对场景成像,并保证标定板均完整出现在双目图像中,共采集含标定板的双目图像1 500对,其中不同天气条件和采样距离下采集的图像数量均等。
2 自监督植株图像深度估计方法
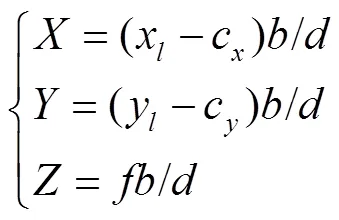
2.1 双目图像视差估计网络模型
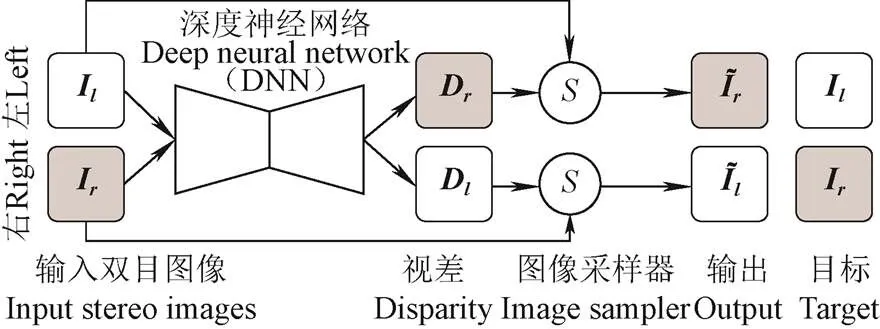
注:Il、Ir分别表示左、右目图像;Dl、Dr分别表示左、右目视差图;分别表示左、右目重构图像;S表示图像采样器。下同。
2.2 网络主体结构设计
本文采用卷积自编码器(convolutional auto-encoder,CAE)作为DNN的结构。CAE常被用于语义分割[11]、深度恢复[12-15]等任务,在这些研究中,CAE由常规卷积层、池化层等堆叠而成,网络参数多、计算量大。近期研究[21-22]多采用模块化设计的卷积块来构建CNN网络。周云成等[23]设计了一种称为面向通道分组卷积(channel wise group convolutional,CWGC)模块的结构,基于该结构的CNN网络在番茄器官分类和识别任务上都取得了较高的精度,与常规卷积相比,在宽度和深度相同的前提下,该结构可有效降低网络参数的数量。本文针对深度恢复任务,在现有CWGC模块基础上引入上采样和下采样功能(图2)。
图2a中的CWGC模块主要由4组相同的卷积组(convolution group)构成,各卷积组分别对输入进行特征提取,生成特征图,然后在通道方向上合并特征图,经批标准化(batch normalization,BN)层和ELU(exponential linear unit,指数线性单元)[24]处理后作为CWGC模块的输出。卷积组的卷积层只和组内的前后层连接,并使用1×1卷积(conv1×1)作为瓶颈层,以降低参数数量、加深网络深度、提高语义特征提取能力。为CWGC模块设计了3种类型的卷积组,图2b为空间尺度不变卷积组,该卷积组在卷积操作时通过边缘填充保持输出与输入的空间尺度(宽×高)相同;图2c为下采样卷积组,其中conv3×1和conv1×3在卷积过程中使用非等距滑动步长,使输出特征图的宽、高分别降为输入的一半;图2d为上采样卷积组,在conv1×1后设置一个步长为2的转置卷积层(deconv3×3),使输出特征图的空间尺度与输入相比扩大1倍。分别使用3种类型的卷积组,可使CWGC的输入、输出在空间尺度不变、缩小和放大之间转换。

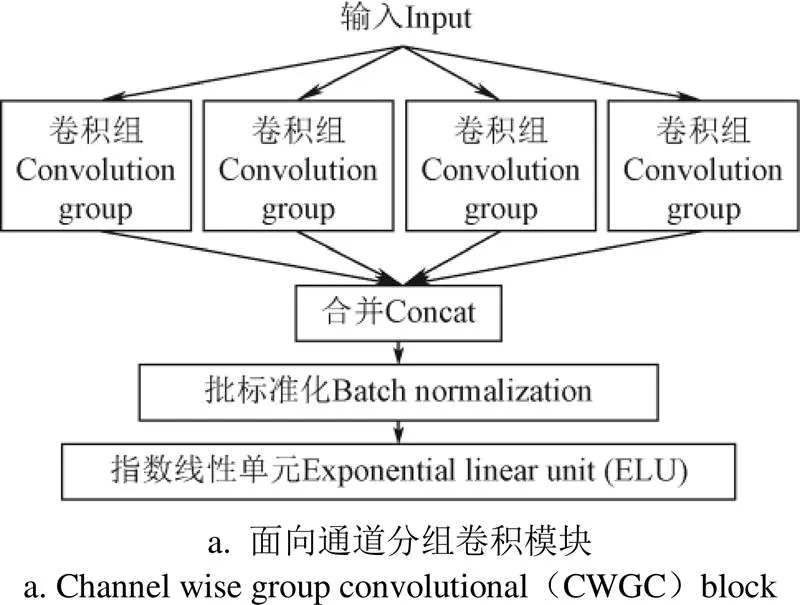
注:conv1×1,等表示卷积核大小为1×1、通道数为的卷积层;s2,1等表示水平和垂直滑动步长分别为2和1;deconv表示转置卷积。下同。
Note: conv1×1,and so on denote convolution with kernel size of 1×1 and channel number of; s2,1 indicates that the horizontal and vertical strides are 2 and 1 respectively; deconv means transpose convolution. Same as below.
图2 卷积模块
Fig.2 Convolutional block
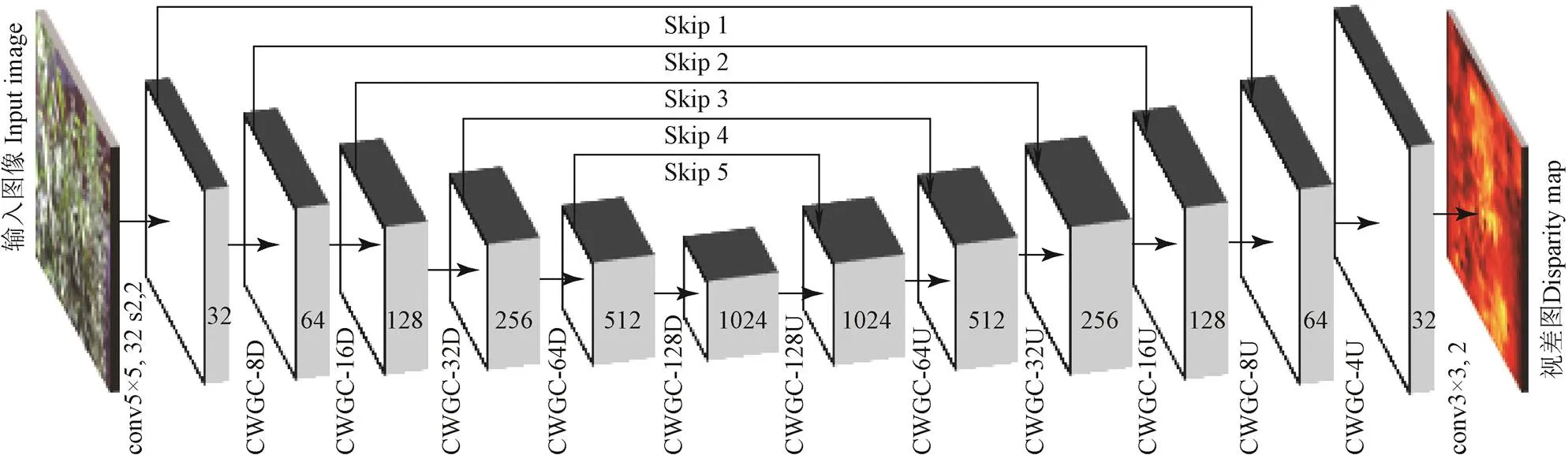
注:CWGC-8D等表示CWGC模块采用h=8的下采样卷积组;CWGC-128U等表示CWGC模块采用h=128的上采样卷积组;Skip 1等表示跨越连接。下同。 Note: CWGC-8D, etc. denotes that CWGC block usesdown-sampling convolution group with h=8; CWGC-128U, etc. denotes that CWGC block adopts up-sampling convolution group with h=128; Skip 1, etc. denotes skip connection. Same as below.
2.3 深度估计网络损失函数定义
损失函数的定义是实现自监督图像深度估计网络优化训练的关键,本文的损失函数定义如下
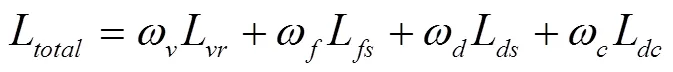
2.3.1 图像重构损失
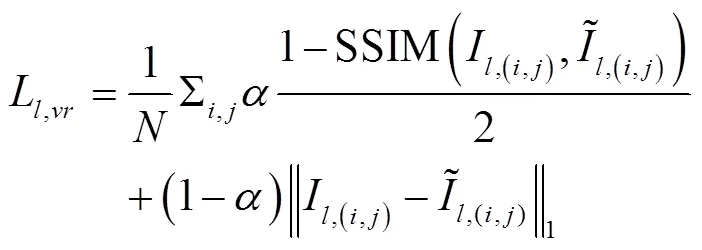
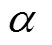
2.3.2 图像卷积特征近似性损失
1形式的图像重构损失,误差梯度仅由对应像素的光度差决定。SSIM指数由光度、对比度和结构相似程度构成。植株器官并非理想的朗伯体,其蜡质化层会在一定程度上产生镜面效应。且由于左、右目相机的位置、姿态及自身物理特性的差异,同一空间点在双目相机成像的光度值可能不同。即使DNN预测的视差图是准确的,从一目图像采样重建的另一目图像与原图像也会有差异。因此仅采用式(3)的人工特征来衡量两幅图像的近似性是不足的。Zeiler等[25]研究表明,经过训练的分类CNN网络的低层卷积学习到的是颜色、边缘、纹理等低级图像特征。相比人工特征,CNN的卷积特征是通过大量样本训练得到的,由于卷积核数量多,所提取的特征更为复杂多样,且具有语义性,受环境差异影响小。因此,本文进一步采用经良好训练的分类CNN网络的低层卷积输出特征的近似性来度量图像的近似性。
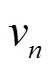
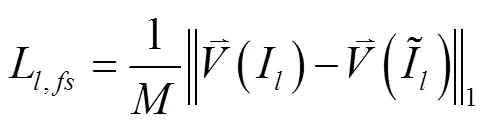
为计算图像的卷积特征张量,同样采用CWGC模块构建一个分类CNN网络,命名为CWGCNet,结构如图 4,该网络由常规卷积层、CWGC模块、最大池化(max-pool)、丢弃(dropout)层、全局平均池化(global average pooling)和Softmax函数构成,整个网络具有35层卷积操作。
2.3.3 视差平滑损失
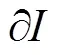
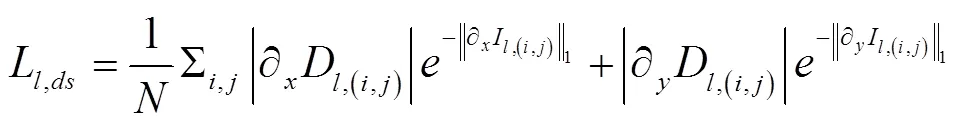

注:CWGC-16等表示CWGC模块采用h=16的空间尺度不变卷积组;max-pool2×2表示池化窗口为2×2的最大池化层。
2.3.4 左右目视差一致性损失

2.4 可微分图像采样器
以最小化损失函数L为目标,通过梯度下降来调整深度估计网络的权重参数,实现模型的优化。这要求构成神经网络的每个模块必须是可微分的,其中包括图像采样器。由于经极线校正后同一空间点在双目图像上对应像素行对齐,因此线性插值采样可满足图像和视差图的采样重建,过程如图5。
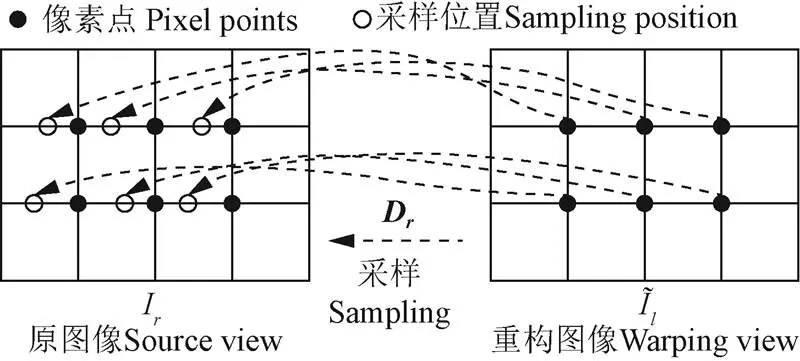
图5 可微分图像采样过程示意
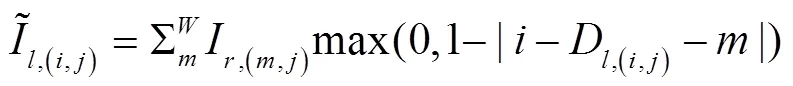
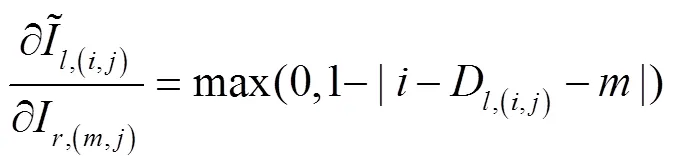
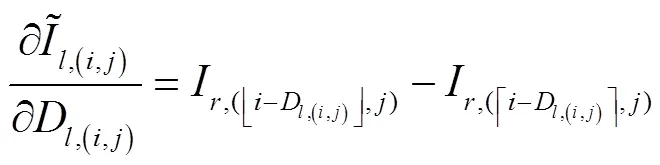
2.5 视差估计精度判据
DNN估计的视差图越精确,由图像采样器基于视差图采样重建的图像与目标图像的相似度越高。因此本文首先采用与主观评价法具有高度一致性的3种图像相似度评价指标FSIM(feature similarity index,特征相似性指数)[27]、IW-SSIM(information content weighted SSIM,信息内容加权结构相似性指数)[28]和GSIM(gradient similarity index,梯度相似性指数)[29]作为视差图精度的间接评判指标,3种指标值均越大说明图像相似度越高,视差图越精确。
3 深度估计网络模型训练与测试
3.1 深度估计网络总体结构及实现
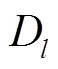
3.2 CWGCNet的训练
采用ImageNet1000[31]的训练集训练CWGCNet分类网络,训练方法同文献[32],采用小批量梯度下降法进行训练,通过图像随机裁剪法进行样本增广。在ImageNet1000的测试集上进行分类测试,并与AlexNet[33]和VGG-16[32]2种典型分类CNN网络进行top-1、top-5错误率(指网络输出的1个或5个最高概率类型不包括实际类型的样本数占测试样本总数的比例)及权重参数数量(由网络中所有卷积核和全连接层的权重参数的数量累加得到,与具体网络结构有关,下同)比较,结果如表1。
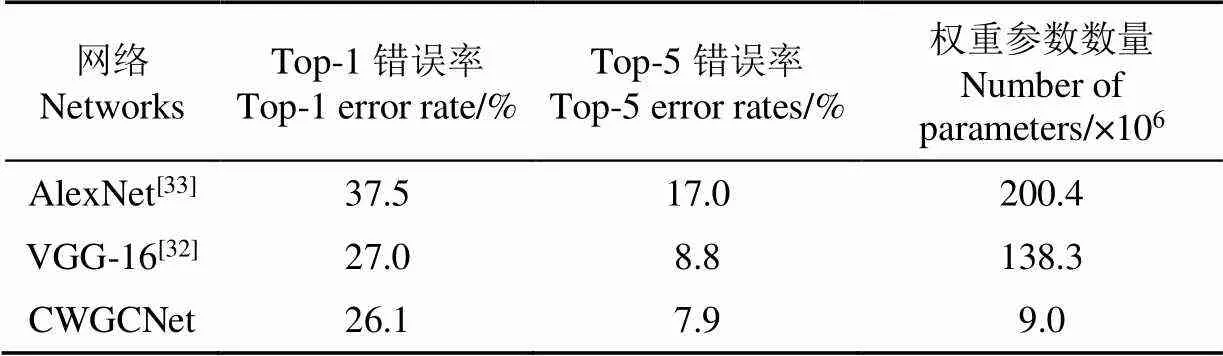
表1 CWGCNet与2种典型CNN网络分类性能比较
由表1可知,CWGCNet在ImageNet1000上的top-1错误率比AlexNet和VGG-16分别降低30.4%和3.3%,且权重参数数量只有后两者的4.5%和6.5%,说明其具有更强的图像特征提取能力,卷积核参数更加高效,参数冗余更少。将1幅番茄植株图像输入CWGCNet,并对其前2层卷积模块输出的部分特征图进行可视化(图6)。
从图6可以看出,CWGCNet的前2层卷积模块输出了表观各异的特征图,说明其学习出了能够提取图像多种类型特征的卷积核,其中第1层特征图主要体现了图像的颜色特征,第2层特征图主要突出了图像的边缘和纹理特征。因此,在式(3)中包含的2幅图像的光度、对比度、结构和光度差的比较基础上,采用卷积特征图构建的式(4)能够进一步为深度估计网络的训练引入多样化的图像特征比较。

图6 输入图像及对应的部分卷积特征图
3.3 深度估计网络的训练
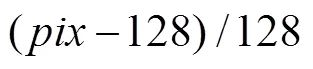
网络的训练方法同文献[16],用Adam(adaptive moment,自适应矩)优化器对深度估计网络进行训练,其中Adam的1阶矩指数衰减率1=0.9、2阶矩指数衰减率2=0.999,每一小批样本量为8,初始学习率为10-3,经过10代迭代训练后调整为10-4,此后每经过20代迭代,学习率下降10倍。经过60代迭代训练,网络损失收敛到稳定值。
3.4 深度估计网络的测试与分析
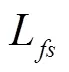
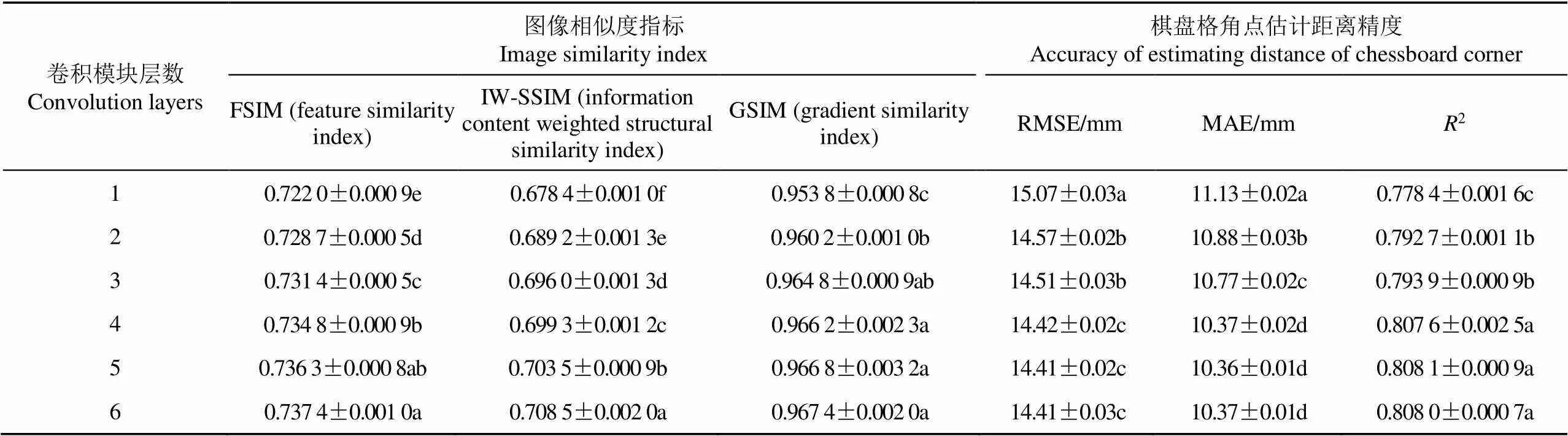
表2 卷积模块层数对视差估计精度的影响
注:数据为平均值±标准误。同列不同小写字母表示各处理在5%水平上差异显著。下同。
Note: Data is mean±SE. Values followed by a different letter within a column for treatments are significantly different at 0.05level. Same as below.
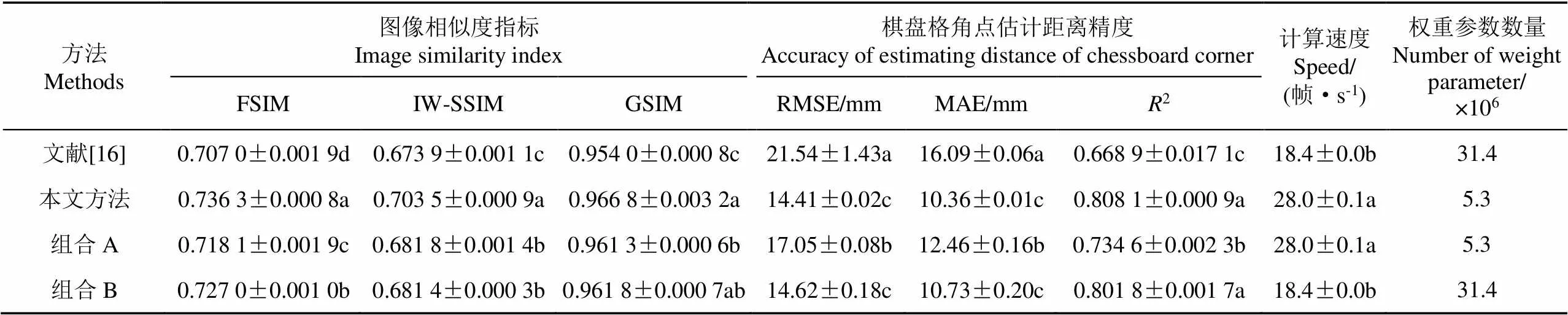
表3 深度估计方法性能比较
注:组合A表示模型由本文网络结构和文献[16]的损失函数构成;组合B表示模型由文献[16]的网络结构和本文损失函数构成。
Note: Combination A indicates that the model consists of our network structure and the loss function in [16]; Combination B indicates that the model is composed of the network structure of [16] and the loss function of this paper.
由表3可知,与Godard等人的方法相比,本文方法在FSIM等3种图像相似度指标上都显著高于前者,棋盘格角点估计距离误差也显著低于前者,RMSE降低了33.1%,MAE降低了35.6%,2显著提高,说明本文方法估计的视差图具有更高的精度。以CWGC-CAE为主体结构的深度估计网络的计算速度达28.0帧/s,与Godard等人的网络相比提高了52.2%。对比Godard等人的方法和组合A表明,CWGC-CAE无论在图像相似度指标,还是在棋盘格角点估计距离的精度上,其性能都显著高于前者的网络结构,且权重参数数量只有前者的16.9%,表明CWGC-CAE在番茄植株图像深度估计上更具有优势。对比Godard等人的方法和组合B表明,组合B在FSIM、IW-SSIM指标上有显著提高,棋盘格角点估计距离RMSE和MAE分别降低32.1%和33.3%,说明本文引入的图像卷积特征近似性损失函数对提高植株图像深度估计的精度是有显著作用的。
同样用最终深度估计模型,来估计番茄植株双目图像测试集中的部分图像的视差图,效果如图7。同时用该模型在含棋盘格标定板的植株双目图像数据集上测试光照条件和采样距离对棋盘格角点距离估计精度的影响,结果如表4。
由表4可知,光照对棋盘格角点估计距离误差无明显影响,说明本文的植株图像深度估计模型对光照变化具有一定的鲁棒性。棋盘格标定板的采样距离对角点间相互距离的估计精度具有显著影响,误差随着采样距离的增加而增大,当采样距离为0.5~3.0 m时,RMSE为6.49 mm,MAE为4.36 mm,分别小于0.7和0.5 cm;当距离为6.0~9.0 m时,RMSE为24.63 mm,MAE为17.90 mm,分别小于2.5和1.8 cm。
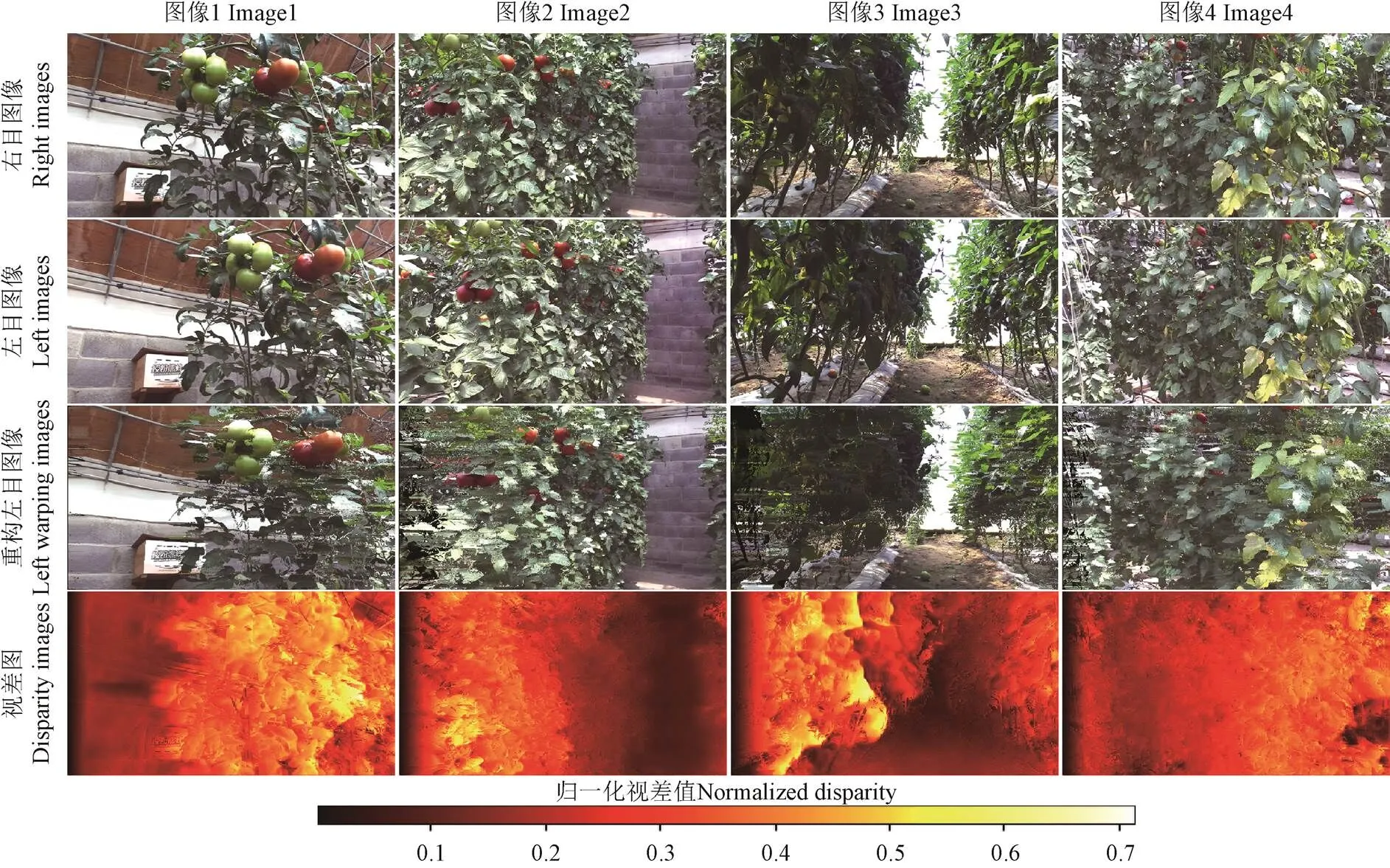
图7 深度估计效果

表4 光照条件与采样距离对棋盘格角点估计距离精度的影响
注:同行不同小写字母表示各处理在5%水平上差异显著。
Note: Values followed by a different letter within a row for treatments are significantly different at 0.05 level.
4 结 论
本文提出一种基于自监督学习的番茄植株图像深度估计网络模型,构建了卷积自编码器作为模型的主体结构,提出引入图像卷积特征近似性损失作为损失函数的一部分,以图像相似度、棋盘格角点估计距离误差等为判据,用番茄植株双目图像对模型进行训练和测试,结果表明:1)基于面向通道分组卷积模块设计的分类网络的浅层卷积能够提取番茄植株的低层图像特征,与未采用图像卷积特征近似性损失函数的模型相比,采用该函数的模型的棋盘格角点估计距离均方根误差RMSE和平均绝对误差MAE分别降低了32.1%和33.3%,该函数对提高番茄植株图像深度估计的精度具有显著作用,且精度随着参与近似性损失计算的卷积模块层数的增加而升高,但超过4层后,进一步增加层数对精度的提升作用不再明显。2)图像采样距离影响深度估计的精度,当采样距离在9.0 m以内时,所估计的棋盘格角点距离RMSE和MAE分别小于2.5 和1.8 cm,当采样距离在3.0 m以内时,则分别小于0.7 和0.5 cm,模型计算速度为28.0帧/s。3)与已有研究结果相比,本文模型的RMSE和MAE分别降低33.1%和35.6%,计算速度提高52.2%,深度估计精度和计算速度均显著提高。
[1]项荣,应义斌,蒋焕煜. 田间环境下果蔬采摘快速识别与定位方法研究进展[J]. 农业机械学报,2013,44(11):208-223. Xiang Rong, Ying Yibin, Jiang Huanyu. Development of real-time recognition and localization methods for fruits and vegetables in field[J]. Transactions of the Chinese Society for Agricultural Machinery, 2013, 44(11): 208-223. (in Chinese with English abstract)
[2]肖珂,高冠东,马跃进. 基于Kinect视频技术的葡萄园农药喷施路径规划算法[J]. 农业工程学报,2017,33(24):192-199. Xiao Ke, Gao Guandong, Ma Yuejin. Pesticide spraying route planning algorithm for grapery based on Kinect video technique[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2017, 33(24): 192-199. (in Chinese with English abstract)
[3]何勇,蒋浩,方慧,等. 车辆智能障碍物检测方法及其农业应用研究进展[J]. 农业工程学报,2018,34(9):21-32. He Yong, Jiang Hao, Fang Hui, et al. Research progress of intelligent obstacle detection methods of vehicles and their application on agriculture[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 34(9): 21-32. (in Chinese with English abstract)
[4]莫宇达,邹湘军,叶敏,等. 基于Sylvester方程变形的荔枝采摘机器人手眼标定方法[J]. 农业工程学报,2017,33(4):47-54. Mo Yuda, Zou Xiangjun, Ye Min, et al. Hand-eye calibration method based on Sylvester equation deformation for lychee harvesting robot[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2017, 33(4): 47-54. (in Chinese with English abstract)
[5]翟长远,赵春江,Ning Wang,等. 果园风送喷雾精准控制方法研究进展[J]. 农业工程学报,2018,34(10):1-15. Zhai Changyuan, Zhao Chunjiang, Ning Wang, et al. Research progress on precision control methods of air-assisted spraying in orchards[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 34(10): 1-15. (in Chinese with English abstract)
[6]翟志强,杜岳峰,朱忠祥,等. 基于Rank变换的农田场景三维重建方法[J]. 农业工程学报,2015,31(20):157-164. Zhai Zhiqiang, Du Yuefeng, Zhu Zhongxiang, et al. Three-dimensional reconstruction method of farmland scene based on Rank transformation[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2015, 31(20): 157-164. (in Chinese with English abstract)
[7]朱镕杰,朱颖汇,王玲,等. 基于尺度不变特征转换算法的棉花双目视觉定位技术[J]. 农业工程学报,2016,32(6):182-188. Zhu Rongjie, Zhu Yinghui, Wang Ling, et al. Cotton positioning technique based on binocular vision with implementation of scale-invariant feature transform algorithm[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2016, 32(6): 182-188. (in Chinese with English abstract)
[8]Hämmerle M, Höfle B. Effects of reduced terrestrial LiDAR point density on high-resolution grain crop surface models in precision agriculture[J]. Sensors, 2014, 14(12): 24212-24230.
[9]程曼,蔡振江,Ning Wang,等. 基于地面激光雷达的田间花生冠层高度测量系统研制[J]. 农业工程学报,2019,35(1):180-187. Cheng Man, Cai Zhenjiang, Ning Wang, et al. System design for peanut canopy height information acquisition based on LiDAR[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2019, 35(1): 180-187. (in Chinese with English abstract)
[10]Ren S, He K, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137-1149.
[11]Chen L C, Zhu Y, Papandreou G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//European Conference on Computer Vision. Springer, Cham, 2018: 833-851.
[12]Liu F, Shen C, Lin G, et al. Learning depth from single monocular images using deep convolutional neural fields[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2016, 38(10): 2024-2039.
[13]Mayer N, Ilg E, Häusser P, et al. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation[C]//Computer Vision and Pattern Recognition. IEEE, 2016: 4040-4048.
[14]Garg R, Vijay K B G, Carneiro G, et al. Unsupervised CNN for single view depth estimation: geometry to the rescue[C]// European Conference on Computer Vision. Springer, Cham, 2016: 740-756.
[15]Kundu J N, Uppala P K, Pahuja A, et al. AdaDepth: Unsupervised content congruent adaptation for depth estimation[EB/OL]. [2018-06-07] https: //arxiv. org/pdf/1803. 01599. pdf.
[16]Godard C, Aodha O M, Brostow G J. Unsupervised monocular depth estimation with left-right consistency[C]// Computer Vision and Pattern Recognition. IEEE, 2017: 6602-6611.
[17]Geiger A, Lenz P, Stiller C, et al. Vision meets robotics: The KITTI dataset[J]. International Journal of Robotics Research, 2013, 32(11): 1231-1237.
[18]Poggi M, Tosi F, Mattoccia S. Learning monocular depth estimation with unsupervised trinocular assumptions[C]// International Conference on 3D Vision (3DV). IEEE, 2018: 324-333.
[19]Zhang Z. A flexible new technique for camera calibration[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22(11): 1330-1334.
[20]Bouguet J Y, Perona P. Closed-form camera calibration in dual-space geometry[C]//European Conference on Computer Vision, 1998.
[21]Zhang T, Qi G J, Xiao B, et al. Interleaved group convolutions for deep neural networks[C]//International Conference on Computer Vision (ICCV), 2017.
[22]Szegedy C, Ioffe S, Vanhoucke V, et al. Inception-v4, Inception-ResNet and the impact of residual connections on learning[C]//Proceedings of Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17), 2017.
[23]周云成,许童羽,邓寒冰,等. 基于面向通道分组卷积网络的番茄主要器官实时识别方法[J]. 农业工程学报,2018,34(10):153-162. Zhou Yuncheng, Xu Tongyu, Deng Hanbing, et al. Real-time recognition of main organs in tomato based on channel wise group convolutional network[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 34(10): 153-162. (in Chinese with English abstract)
[24]Shah A, Kadam E, Shah H, et al. Deep residual networks with exponential linear unit[C]//International Symposium on Computer Vision and the Internet. ACM, 2016: 59-65.
[25]Zeiler M D, Fergus R. Visualizing and understanding convolutional networks[C]//Computer Vision and Pattern Recognition. IEEE, 2014.
[26]Heise P, Klose S, Jensen B, et al. PM-Huber: PatchMatch with huber regularization for stereo matching[C]//IEEE International Conference on Computer Vision. IEEE, 2014: 2360-2367.
[27]Zhang L, Zhang L, Mou X, et al. FSIM: A feature similarity index for image quality assessment[J]. IEEE Transactions on Image Processing, 2011, 20(8): 2378-2386.
[28]Wang Z, Li Q. Information content weighting for perceptual image quality assessment[J]. IEEE Transactions on Image Processing, 2011, 20(5): 1185-1198.
[29]Liu A, Lin W, Narwaria M. Image quality assessment based on gradient similarity[J]. IEEE Transactions on Image Processing, 2012, 21(4): 1500-1512.
[30]Agarwal A, Akchurin E, Basoglu C, et al. The Microsoft cognitive toolkit[EB/OL]. [2018-06-01] https: //docs. microsoft. com/en-us/cognitive-toolkit/.
[31]Deng J, Dong W, Socher R, et al. ImageNet: A large-scale hierarchical image database[C]//Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on. IEEE, 2009: 248-255.
[32]Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[C]//In ICLR, 2015.
[33]Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]// International Conference on Neural Information Processing Systems. Curran Associates Inc. 2012: 1097-1105.
[34]Yang Y, Zhong Z, Shen T, et al. Convolutional neural networks with alternately updated clique[C]//Computer Vision and Pattern Recognition. IEEE, 2018.
Method for estimating the image depth of tomato plant based on self-supervised learning
Zhou Yuncheng, Xu Tongyu, Deng Hanbing, Miao Teng, Wu Qiong
(,,110866,)
Depth estimation is critical to 3D reconstruction and object location in intelligent agricultural machinery vision system, and a common method in it is stereo matching. Traditional stereo matching method used low-quality image extracted manually. Because the color and texture in the image of field plant is nonuniform, the artificial features in the image are poorly distinguishable and mismatching could occur as a result. This would compromise the accuracy of the depth of the map. While the supervised learning-based convolution neural network (CNN) is able to estimate the depth of each pixel in plant image directly, it is expensive to annotate the depth data. In this paper, we present a depth estimation model based on the self-supervised learning to phenotype tomato canopy. The tasks of the depth estimation method were to reconstruct the image. The dense disparity maps were estimated indirectly using the rectified stereo pair of images as the network input, from which a bilinear interpolation was used to sample the input images to reconstruct the warping images. We developed three channel wise group convolutional (CWGC) modules, including the dimension invariable convolution module, the down-sampling convolution module and the up-sampling convolution module, and used them to construct the convolutional auto-encoder - a key infrastructure in the depth estimation method. Considering the shortage of manual features for comparing image similarity, we used the loss in image convolutional feature similarity as one objective of the network training. A CWGC-based CNN classification network (CWGCNet) was developed to extract the low-level features automatically. In addition to the loss in image convolutional feature similarity, we also considered the whole training loss, which include the image appearance matching loss, disparity smoothness loss and left-right disparity consistency loss. A stereo pair of images of tomato was sampled using a binocular camera in a greenhouse. After epipolar rectification, the pair of images was constructed for training and testing of the depth estimation model. Using the Microsoft Cognitive Toolkit (CNTK), the CWGCNet and the depth estimation network of the tomato images were calculated using Python. Both training and testing experiments were conducted in a computer with a Tesla K40c GPU (graphics processing unit). The results showed that the shallow convolutional layer of the CWGCNet successfully extracted the low-level multiformity image features to calculate the loss in image convolutional feature similarity. The convolutional auto-encoder developed in this paper was able to significantly improve the disparity map estimated by the depth estimation model. The loss function in image convolutional feature similarity had a remarkable effect on accuracy of the image depth. The accuracy of the disparity map estimated by the model increased with the number of convolution modules for calculating the loss in convolutional feature similarity. When sampled within 9.0 m, the root means square error (RMSE) and the mean absolute error (MAE) of the corner distance estimated by the model were less than 2.5 cm and 1.8 cm, respectively, while when sampled within 3.0m, the associated errors were less than 0.7cm and 0.5cm, respectively. The coefficient of determination (2) of the proposed model was 0.8081, and the test speed was 28 fps (frames per second). Compared with the existing models, the proposed model reduced the RMSE and MAE by 33.1% and 35.6% respectively, while increased calculation speed by 52.2%.
image processing; convolution neural network; algorithms; self-supervised learning; depth estimation; disparity; deep learning; tomato
周云成,许童羽,邓寒冰,苗 腾,吴 琼. 基于自监督学习的番茄植株图像深度估计方法[J]. 农业工程学报,2019,35(24):173-182. doi:10.11975/j.issn.1002-6819.2019.24.021 http://www.tcsae.org
Zhou Yuncheng, Xu Tongyu, Deng Hanbing, Miao Teng, Wu Qiong. Method for estimating the image depth of tomato plant based on self-supervised learning[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2019, 35(24): 173-182. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2019.24.021 http://www.tcsae.org
2018-11-01
2019-12-01
辽宁省自然科学基金(20180551102);国家自然科学基金(31601218)
周云成,副教授,博士,主要从事机器学习在农业信息处理中的应用研究。Email:zhouyc2002@163.com
10.11975/j.issn.1002-6819.2019.24.021
TP183
A
1002-6819(2019)-24-0173-10
猜你喜欢
青年文学家(2022年10期)2022-04-25
江苏农业科学(2022年6期)2022-04-15
今日农业(2021年21期)2022-01-12
北京航空航天大学学报(2021年9期)2021-11-02
今日农业(2020年23期)2020-12-15
电子制作(2019年13期)2020-01-14
电子制作(2019年20期)2019-12-04
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
作文大王·笑话大王(2018年12期)2018-03-23
