
视觉注意力检测综述∗
2019-03-05 03:45:50王文冠沈建冰贾云得
软件学报 2019年2期
王文冠,沈建冰,贾云得
(智能信息技术北京市重点实验室(北京理工大学),北京 100081)
人类的视觉系统(human visual system)具有极强的感知和数据处理能力,有研究显示[1,2],每秒约有 108~109字节的数据进入人眼.认知科学领域的研究表明[3,4],视觉注意力机制(visual attention mechanism)是人类视觉系统具备如此惊人数据处理能力的重要基础:在处理视觉数据的初期,人类视觉系统会迅速将注意力集中在场景中的重要区域上,这一选择性感知机制极大地减少了人类视觉系统处理数据的数量,从而使人类在处理复杂的视觉信息时,能够抑制不重要的刺激,将有限的神经计算资源分配给场景中的关键部分,为更高层次的感知推理和更复杂的视觉处理任务(如物体识别[5]、场景分类[6]、视频理解[7]等),提供更易于处理且更相关的信息.从人类生理机理的角度而言,人类的视觉注意力机制基于视网膜的特殊生理结构:高分辨率的视网膜中央凹(central fovea)和较低分辨率的边缘视网膜(periphery).视网膜的中央凹区域集中了绝大多数的视锥细胞(cone cells),负责视力的高清成像.当人类关注某一物体时,通过转动眼球,将光线集中到中央凹,从而获取显著区域的更多细节而忽略其他不相关区域的信息.可见,人类视觉注意力机制引导视网膜的生理结构,完成对场景信息的选择性收集任务.而在计算机视觉领域,主要的研究问题在于怎样建立合适的计算模型来解释这种人类视觉注意力机制的潜在机理.在计算机视觉信息处理过程中引入注意力机制,不仅可以将有限的计算资源分配给重要的目标,而且能够产生出符合人类视觉认知要求的结果.因此,视觉注意力检测已经成为计算机视觉领域的研究热点,得到学界的大力关注.
人类视觉注意力机制研究起源于认知心理学(cognitive psychology)和神经科学(neuroscience),早期的代表工作可以追溯到Koch和Ullman的著作[8].Itti等人[9]利用认知心理学中的经典理论——特征整合理论(feature integration theory,简称FIT)[10]和指向搜索模型(guided search model)[11]提出了早期的人类视觉注意力机制的计算模型,并将人类视觉显著性检测研究引入了计算机视觉领域,该任务也被称为人眼关注点检测(human eye fixation prediction).在 Itti等人的工作后,学界提出了大量的视觉显著性计算模型,这些模型对人眼在场景中某一个位置停留的可能性进行预测.随着计算机视觉的进一步发展,针对目标物体级别的理解显得尤为重要,在此背景下,视觉显著性检测出现了另一个重要的分支——显著物体检测(salient object detection).这一分支的早期研究有Liu等人[12]和Achanta等人[13]的工作,强调对场景中显著目标整体的准确预测并且获取清晰的显著物体边界,为物体级别的视觉任务(如目标检测[14]、目标备选提取[15]、视频摘要[16]、基于内容感知的图像裁剪[17,18]、目标跟踪[19]等)提供更直接更有效的信息.
与同类文献相比,本文的主要贡献如下.
(1)对视觉注意力检测在近年来的代表性方法进行了系统和全面的研究,并根据输入数据的不同,将上述模型进一步划分为动态视频和静态图像的视觉显著性检测模型.
(2)对近年来基于深度学习的视觉注意力计算模型进行了研究和分析,对它们的典型网络结构进行了阐述和分类.
(3)对人眼关注点检测以及显著物体检测领域的代表性实验数据集、算法的性能评估指标进行了讨论和总结.
(4)对经典的人眼关注点检测和显著物体检测模型,在静态及动态场景下的性能进行了定量分析,并探讨了视觉注意力检测领域未来的发展趋势.
本文第1节对人眼关注点检测模型进行综述.第2节介绍显著物体检测领域的代表性工作、主要假设以及基于深度学习的算法.第 3节介绍人眼关注点检测和显著物体检测领域常用的数据集.第 4节介绍人眼关注点检测和显著物体检测领域用于算法性能评估的指标.第 5节针对当前经典的人眼关注点检测模型以及显著物体检测模型,在静态及动态场景下的性能进行定量评估.第 6节对视觉注意力检测这一研究领域未来的发展趋势进行展望.
1 人眼关注点检测模型
人眼关注点检测是指通过数学建模的方式模拟人类视觉注意系统的机能,对图像或视频中不同位置受到视觉关注的概率进行计算,通过与真实的人类眼动数据相比对,能够对模型预测的视觉显著性结果进行量化评估.设有K个观测对象注视了N张图像为观测对象在观测第n张图像时的眼动数据(人眼关注点位置),人眼关注点检测任务可以定义为:找到一个刺激-注意力变换函数(stimuli-saliency mapping function)f∈F.该函数通过最小化人眼关注点预测误差得到,如式(1)所示.

这里,m∈M被定义为一种人眼关注点真值与显著性预测的距离度量(参见第4.1节).
这一领域早期的代表性工作是Koch等人[8]于1985年提出的视觉选择性注意理论.他们在对灵长类动物和人类视觉系统进行研究的基础上,提出了视觉注意力分配过程中的3个要素.
(1)图像中的一些基本底层特征:颜色、朝向、运动方向和差异;
(2)视觉选择性注意机制的一个重要功能,是使不同图像之间的信息变成一个连贯的整体;
(3)WTA 机制,即赢者取全(winner-take-all)的竞争机制,在视觉注意过程中,先选择最明显的目标,然后选择次明显目标.
1998年,Itti等人[9]基于Koch等人的理论以及认知心理学经典的特征整合理论[10]、指向搜索模型[11],提出了首个视觉显著性的计算模型,其算法流程主要含有3个步骤:提取颜色、亮度和朝向这3种初级视觉特征;在多尺度下使用中央-周围对比度(center-surrounding contrast)计算3种体现显著性的特征图(显著特征提取);对特征图进行归一化处理,然后进行特征图的合成(特征融合),运用WTA机制标注出图像中的显著目标.该算法对后来计算机视觉领域中视觉显著性计算模型的研究产生了重要影响,尤其是在深度学习技术得到大规模运用之前,主流的显著性检测算法都采用了类似的框架.
1.1 静态场景中的人眼关注点检测模型
在Itti的工作之后,计算机视觉领域出现了大量关于人眼注意点检测的工作,这些工作主要关注静态图像中的视觉显著性检测.根据这些模型所采用的人类视觉注意力机制的作用机理,可以将其划分为两种:自底向上(bottom-up)的模型和自顶向下(top-down)的模型.
自底向上的模型[20-25]受数据的驱动,典型的例子是人类在自由观看(free-viewing)模式下分配视觉注意力的情形.这类模型主要利用图像中的颜色、亮度、边缘等特征,考虑像素与周围领域在特征上的差异,计算该像素的显著性.Itti等人在 1998年的工作[9]就是这一类模型的典型代表.中央-周围(center-surround)原理是自底向上模型使用最多的理论,相关研究结果表明,视觉神经元往往只针对一个较小的中心区域敏感,如果在中心的周围区域也产生刺激,那么这个刺激会抑制中心区域对视觉神经元的刺激,这意味着视觉神经元对局部空间的不连续性较为敏感,容易注意到那些与局部周围邻域对比较为明显的位置,这也是视网膜、外侧膝状体和底层视觉皮层的工作原理.为了检测局部中心与周围邻域间的对比度(contrast),相关工作往往在不同的尺度上采用不同的特征进行计算,得到的差异度被作为估计最终显著性结果的依据.
自顶向下的模型[26-28]主要受任务驱动,受到人类主观意识的影响,包括先验性知识、当前的目标或对未来的预期.例如在等待客人时,人的注意力会集中在门的位置;或者在监控场景下,场景中的人往往更能引起监控者的注意.自顶向下的模型需要考虑高层的先验信息,例如人脸、车辆等,因此在基于特定任务数据上使用机器学习算法进行建模的方式,成为这类工作的主流.由于在自顶向下的注意力机制中,人类个体的情感、意志等主观因素难以控制,绝大部分人眼关注点检测算法都属于自底向上的模型.自底向上和自顶向下模型是基于不同的视觉注意力机制,根本机理不同.从人类认知学角度而言,自底向上模型主要是研究人类注意力机制的早期机制,数据驱动和任务、人的主观情感无关;而自顶向下的模型综合人类复杂推理和认知过程,和人类的心理活动、当下的主观情感相关.而自底向上的注意力机制是人在放松状态下,不加思考地自由观看场景时的视觉选择性特性,和人的主观个人因素关联较少,因此在计算机视觉领域,主要研究重点在自底向上的注意力机制,因为外部变量可控,内部变量影响少,而自顶向下模型主要在认知心理学相关领域有较多研究.
从Itti等人的工作[9]开始,传统的人眼关注点检测模型的计算框架主要是基于Treisman和Gelade的经典特征融合理论[10].该理论通过对人类视觉系统的研究,描述了不同视觉特征的融合,能够对人类的视觉注意力机制产生引导作用.基于这一理论,传统的人眼关注点检测模型主要包含 3个步骤:(1)显著性特征提取;(2)基于显著特征的显著性图推断;(3)不同特征的显著性图融合.在显著性特征提取阶段,首先检测不同的底层显著性特征,如颜色、纹理等.在显著性推断阶段,根据中央-周围理论,计算中央区域与不同尺度上的周围区域的差异,如考虑局部邻域[9,23,27],或更大范围的全局邻域[20,22,24].由于上述过程同时使用不同的特征对显著性进行推断,因此在最后一步,需要融合不同特征得到的显著性图,这一融合过程可以基于不同的计算方式,如通过手工定义的线性组合权重[9],或通过支持向量机(support vector machine,简称SVM)训练得到组合权重[25].
近年来,随着深度学习技术在计算机视觉领域的兴起,基于深度神经网络的显著性检测模型[29-36]已经成为主流.这些模型利用大规模的眼动数据集[37]以及深度学习技术的强大学习能力,达到了远好于传统模型的性能.在著名的公共人眼关注点检测数据集MIT300[38]上,排名前10的显著性检测模型均使用了深度学习技术,其中,eDN模型[29]是利用深度神经网络来对视觉注意机制进行建模的早期代表性工作,此后相继提出了 DeepFix模型[30]、SALICON 模型[31]、Mr-CNN 模型[32]、Shallow and Deep模型[33]、attentive LSTM 模型[34]、DVA 模型[35].这些工作的研究思路主要是探讨更复杂更有效的网络结构.Jetle等人[36]测试了多个损失函数,这些损失函数主要基于概率理论的距离测度,实验结果表明,基于Bhattacharyya距离测度的损失函数能够给出最好的训练效果.
1.2 动态场景中的人眼关注点检测模型
在显著性检测领域中,有很多工作研究了如何模拟人类在观看图像时的视觉注意力机制,但关于动态场景下人类如何分配视觉注意力的研究相对较少,动态视觉注意力机制在人类日常行为中却更为普遍且更为重要.与静态的视觉注意力检测相比,动态视频中的运动信息为人眼关注点检测提供了很强的引导,然而,背景区域中的运动同样也会产生强烈的干扰,此外,光流模型计算运动信息时产生的计算误差也会给动态显著性检测带来很大的负面影响.
早期的动态人眼关注点检测的研究工作[39-46]主要为自底向上的模型,这些模型通过将静态显著性特征和时间域信息(如光流场、时域差分等)相结合,检测动态场景下的视觉注意力,其中大部分工作[39-41]都可被看作是已有静态显著性模型的基础上考虑运动信息后的扩展.例如,Gao等人[39]通过在图像显著性检测模型[47]中添加额外的运动信息,来计算视频上的显著性.类似的,Mahadevan等人[40]利用文献[47]中的模型,将中心-周围对比度显著性与动态纹理特征相结合;Guo等人[48]采用傅里叶变换的相位谱(phase spectrum of the Fourier transform)计算动态显著性;Seo等人[41]利用局部回归算子(local regression kernel)计算视频中像素或超体素和周围区域的相似性;Rahtu等人[49]利用统计模型和局部特征(如光照、颜色和运动信息)上的对比度来计算视频显著性.这些模型严重依赖于特征工程,因而模型的性能受到了手工设计特征的限制.
目前,基于深度学习的人眼关注点检测模型非常少[50-52],主要原因是动态场景的眼动数据集的数量较少且规模普遍较小.其中,
· Bak等人[50]使用了经典的双流网络架构(two-stream network),将提取静态表观特征的网络与提取运动特征的网络相结合.
· Jiang等人[51]使用两层长短期记忆神经网络(long-short-term memory network),与用于检测似物性(objectness)、光流和静态表观特征的网络相结合.
· Wang等人[52]提出了基于卷积长短期记忆神经网络(convolutional long short-term memory network)的动态人眼关注点检测模型.该模型通过加入静态注意力模块(attentive module),将动态和静态显著性特征的提取进一步解耦合,并充分利用现有的大规模静态眼动数据,对整个网络结构进行充分的训练;同时,该网络设计还避免了之前动态显著模型需要进行耗时的光流计算的缺陷,进一步提升了检测速度.
相对于之前基于手工特征的动态显著性计算模型而言,这些基于深度学习的工作取得了更好的性能,同时也证明了将神经网络用于解决该问题的潜在优势.
2 显著物体检测模型
与人眼关注点检测任务相比,显著物体检测任务的研究历史相对较短,且该任务是一个纯计算机视觉任务,Liu等人[12]和Achanta等人[13]的研究是该领域的早期代表性工作.2007年,Liu等人[12]正式提出了显著物体检测任务,可以视为视觉注意力机制在物体分割任务上的延拓,提出的背景是计算机视觉领域从底层视觉处理任务向高层视觉理解方向的深入,对物体级别的感知和描述成为相关研究的关键.Liu等人使用了不同尺度下的对比度(multi-scale contrast)、中心-周围直方统计(center-surround histogram)以及颜色空间分布(color spatialdistribution)这 3种显著性度量方式,之后,使用条件随机场(conditional random field)对这些显著性特征进行整合,同时也提出了第1个显著物体检测数据集,并引入了查准率(precision)、查全率(recall)、F-值(F-measure)这3个重要的评估指标.2009年,Achanta等人[13]在Liu等人工作的基础上,提出了在频率域(frequency domain)上对显著物体进行快速检测的方法,该工作给出了查准率-查全率曲线(precision-recall curve),并进一步优化了F-值的定义,这两种评估指标成为日后显著物体检测领域最常用的评估指标.Liu等人[12]和Achanta等人[13]的研究为显著物体检测这一方向上的后续工作奠定了基础.
设有N张图像和相应的显著物体真值标定,这里为第n张图像的显著性二值化标定,基于以上定义,显著物体检测任务可以定义为:找到一个图像-显著物体预测函数f∈F,该函数可以通过最小化显著物体预测误差得到,如式(2)所示.

这里,m∈M被定义为一种显著物体真值标定与显著物体预测的距离度量(参见第 4.2节).显著物体真值可以通过观测对象的眼动数据进行标定,这表示显著物体检测和人眼关注点检测两者间存在着密切的相关性.
2.1 图像显著物体检测模型
早期的图像显著物体检测模型[53-57]主要基于自底向上的方法,使用了不同的底层视觉特征,如颜色、边缘等,由于显著物体检测与人眼关注点检测任务关系密切,都是对人类视觉注意力机制的建模,因此早期的显著物体检测模型也借鉴了人类视觉注意力机制的一些基本理论,包括经典的对比度假设、中心-周围假设.比如,Liu等人[12]和 Achanta等人[13]都使用了这两种假设,Cheng等人[53]也使用了类似的假设,他们考虑了局部和全局范围上的颜色对比度信息,算法简洁明了,得到了学界的广泛关注.此外,Yan等人[55]提出通过对图像进行不同尺度的过分割,完成在不同尺度上表观一致的图像表达,并在不同尺度上对显著性特征进行提取和融合优化,来得到最终显著物体检测结果.视觉中心偏移(center bias)也是一个常用的基于人类注意力机制的假设[55].该假设基于这样的现象:人类在观测场景时,视觉系统具有向场景中央分配较高注意力权重的倾向.之后,流行的假设是背景先验假设(background prior),该假设在2012年由Wei等人[54]提出.与中心-周围假设和视觉中心偏移假设尝试定义“什么更有可能是显著区域”不同,该假设尝试定义“什么更有可能是背景”.该假设基于这样的观察:在大部分场景中,图像四周边缘的部分属于背景的概率较大.该假设可视为对视觉中心偏移假设的进一步发展,在深度学习技术得到大规模应用之前,背景先验假设是显著性检测领域最有效的假设,绝大多数性能优异的模型[58-62]都基于这一假设,这些工作主要关注如何进一步提高背景先验假设的准确度以及如何应用更先进的单分类器(one-class classifier).通过背景先验假设,相当于获取了一类(背景)样本,那么该问题可被视为只给出1类样本的单类分类(one-class classification)问题.例如,Jiang等人[59]的工作可被视为基于可吸收随机游走算法的单分类器,Wei等人[54]和Zhang等人[61]的工作则是通过不同的距离度量方式对样本进行分类.
随着深度学习技术在图像分类问题上取得巨大的成功,显著物体检测领域的研究重心也逐渐向基于深度学习的模型偏移.稍早期的工作(2015年~2016年)使用了深度学习特征作为更有效的显著性表达,并使用全卷积神经网络进行训练.例如,Zhao等人[63]的工作使用深度神经网络预测图像超像素(superpixel)或目标物体备选(object proposal)的显著性值,从而将显著物体检测任务转换为对图像超像素或目标物体备选的分类问题(显著/不显著);Wang等人[64]使用两个深度网络分别用于预测局部超像素和全局目标物体备选的显著性值;Li等人[65]利用每个超像素在不同尺度上的深度学习特征,提取上下文信息(contextual information),然后,通过分类网络来对每个超像素是否显著进行分类;Lee等人[66]将深度特征作为高层信息,将Gabor滤波响应、颜色直方统计等作为底层特征,融合不同层次的显著性信息后进行显著性预测.这类模型取得了较好的性能,但存在一些缺陷,比如,由于使用了基于全连层(fully connected layer)的分类网络,这类模型的参数量较大且损失了空间信息;同时,由于需要对每一个超像素或目标物体备选进行显著/不显著分类,这类算法的计算代价较大.
随着全卷积神经网络(fully convolutional neural network)的兴起,近年来(2016年~2018年),基于深度学习的显著物体检测工作都使用或改造了全卷积神经网络,进行像素级别的显著性预测.例如,Wang等人[67]将深度学习技术与之前的显著性先验相结合,利用显著性先验获取初始的显著性估计,然后,使用循环神经网络(recurrent neural network)来对初始的显著性先验进行优化.有一些工作[68-72]受到像素级语义分割任务的启发,提出将不同神经网络层的特征相融合来进行显著物体检测.由于深度神经网络的较浅层网络能够保留较多较细粒度的底层视觉特征,而较深层的网络能够提取更高层的、语义级的特征,因而,融合不同神经网络层的特征既能保留原有的底层空间信息,又能获得高层语义信息.目前,基于深度学习技术的显著物体检测工作的主要研究重心是探索更有效、能保留更多空间细节的网络结构.例如,Zhang等人[68]利用不同尺度输入得到了深度信息,Hou等人[69]将每一层的深度神经网络特征都进行互连.除此之外,2018年,Wang等人[70]提出了通过视觉注意力先验来检测视觉显著物体的 ASNet模型.该模型将视觉注意力作为对整个场景的高层次理解,通过较高层的神经网络层进行学习,显著物体检测任务则被视为更细粒度的、物体层面的显著性检测,由视觉注意力提供自顶向下地引导.ASNet模型基于堆栈卷积长短期记忆神经网络,该网络特有的循环结构能够迭代地优化显著性检测结果.该工作为视觉注意力机制提供了更深层次的解读,揭示了显著物体检测和人眼关注点检测二者之间的关联性.就整体而言,基于深度学习的显著物体检测模型取得了远超传统模型的性能.
2.2 视频显著物体检测模型
早期的动态视觉显著性模型主要关注动态场景下的人眼关注点检测任务,针对视频显著物体检测的研究,可以追溯到 Liu等人[73]和 Wang[74]等人的工作.2014年,Liu等人[73]提出在超像素级别上,利用运动和表观信息来检测视频中的显著物体整体.Wang等人[74]提出了梯度流场(gradient flow field)和全局显著物体连续性假设,首先,利用目标的表观和运动的不连续性,计算光流梯度幅值和颜色梯度幅值,建立梯度流场来确定显著物体的初始位置,结合局部和全局显著性线索进一步优化;然后,利用视频显著物体在时空域上连续的假设,建立全局显著性优化方程,得到最终的时空域平滑的显著物体估计结果.该工作同时提出了第 1个专门用于显著物体检测的数据集ViSal,并将查准率-查全率曲线和MAE值这两个评估指标用于视频显著物体检测任务.
关于视频显著物体检测的工作逐年增多.2015年,Wang等人[75,76]进一步提出了基于测地距(geodesic distance)的视频显著物体检测算法,并将显著物体检测用于无监督的视频分割.该算法通过建立帧内和帧间图模型对视频帧内和帧间信息进行建模,并使用测地距在帧内和帧间图模型上对每个超像素的显著性进行度量,因为测地距能够较好地获取相应的结构化信息.Kim 等人[77]提出了基于重启动随机游走(random walk with restart,简称RWR)的视频显著物体检测算法.该算法将空间域的显著性作为随机游走的重启动分布,利用空间特征建立随机游走的转移概率矩阵,将达到稳定状态时相应的概率分布作为最终的时空显著物体估计.2017年,Liu等人[78]通过对显著性检测结果在时间域上的迭代更新,进一步发展了他们之前的工作[73].此外,还有Guo等人[79]提出的基于目标物体备选(object proposal)的频显著物体检测模型;文献[80]提出的基于低秩相关性(low-rank coherency)的模型;文献[81]提出的利用时空显著性线索、局部约束以及似物性指标的算法;Li等人[82]提出的基于栈式自动编码器(stacked autoencoder)的视频显著物体检测模型;Alshawi等人[83]通过计算每个像素的不确定性(uncertainty)来提高视频显著物体的检测结果.
2017年,Wang等人[84]提出了基于全卷积神经网络的视频显著性物检测模型,这也是第1个基于深度学习的视频显著物体检测模型.该工作主要解决了两个关键问题:(1)在缺乏充分训练样本的条件下,如何对深度学习模型进行训练;(2)如何建立快速且准确的视频显著性检测模型.该模型包含了两个模块,分别用于学习空间域和时间域上的显著性信息.其中,动态显著性检测模块,显式地利用了静态显著性检测模块的静态显著性估计,直接生成时空显著性检测结果,并且避免了耗时的光流计算.同时,该工作中提出了一个重要的数据扩充技术,能够利用已有的标定好的图像数据集来合成大量的视频数据,从而使深度视频显著物体检测模型能够学习到丰富的显著性信息,并避免了在原来少量视频样本上的过拟合.通过利用合成的视频数据和真实的视频数据,该视频显著物体检测模型能够成功地学习到时间域和空间域的显著性信息,从而产生更准确的显著性检测结果和达到更快的检测速度.
3 视觉显著性检测数据集
本节主要介绍图像人眼关注点检测、视频人眼关注点检测、图像显著物体检测以及视频显著物体检测领域的代表性数据集.
3.1 图像眼动数据集
常用的静态眼动数据集有 MIT300[38]、MIT1003[25]、TORONTO[22]、PASCAL-S[85]、SALICON[37]以及 DUTOMRON[58].
(1)MIT300数据集
2012年,麻省理工的Judd等人建立了MIT300数据集[38].该数据集包含了300张自然图像以及39名观测者的眼动数据,是图像人眼关注点检测领域影响力最大、使用最广泛的数据集.该数据集得以广泛应用的原因是:数据分布较为合理且具有一定的难度;建立较早,影响力较大;人眼关注点的真值标定不公开,从而防止了模型在该数据集上的过拟合;发布了相关评估实验的代码,且评估结果详实充分.
(2)MIT1003数据集
MIT1003数据集[25]也是由麻省理工的Judd等人建立的.该数据集包含了从Flikr和 LabelMe网站得到的1 003张图像,其中779张为风景像,228张为肖像,并公开了15名观测者的眼动数据.同时,眼动数据的记录过程还考虑了记忆机制:每个观测者被要求在 100张图像中指出哪一张是先前看到的.MIT1003数据集可以作为MIT300数据集的补充,即在MIT1003数据集上训练基于机器学习的注意力模型,然后,以MIT300数据集作为测试集进行性能评估.
(3)TORONTO数据集
TORONTO数据集[22]于2006年由约克大学的Bruce等人建立,是计算机视觉领域提出最早、使用最广的数据集之一.它包括了120张分辨率为511×681的彩色图像.这些图像属于室内和室外场景,一共记录了20名观测者的眼动数据.在每名观测者眼动数据的采集过程中,每张图像呈现3s,图像之间插入为时2s的灰度图像作为间隔.
(4)PASCAL-S数据集
PASCAL-S数据集[85]于2014年由乔治亚理工学院的Li等人建立.该数据集使用了PASCAL VOC 2010[86]数据集验证集的850张图像,并公布了8名观测者在2s内、自由观看模式下观测图像得到的眼动数据.
(5)SALICON数据集
SALICON数据集[37]是 2015年由新加坡国立大学的 Jiang等人建立的.该数据集包含了 20 000张选自Microsoft COCO数据集[87]的图像,是迄今为止图像人眼关注点检测领域规模最大的数据集.但是该数据集没有使用眼动仪录制眼动数据,而是利用了亚马逊众筹标记平台(Amazon Mechanical Turk,简称 AMT),让标注者用鼠标点击自己关注的位置.Jiang等人强调了用鼠标记录的眼动数据与眼动仪记录的实际数据高度接近,但是Tavakoli等人[9]指出,眼动仪记录的真实眼动数据和鼠标记录的眼动数据之间仍然存在着较大的区别,当分别利用不同方式记录的眼动数据作为训练样本训练模型时,不同的训练样本会对模型的最终性能产生不同的影响;同时,利用鼠标记录的眼动数据对模型的性能进行评估时,产生的评估结果以及模型性能的相对好坏也与在真实眼动数据上的测试结果不符.尽管如此,鉴于 SALICON数据集的较大规模,还是被当前主流的基于深度学习技术的显著性检测模型广泛使用.SALICON数据集公开了训练集(10 000张)和验证集(5 000张)的眼动数据,但保留了测试集(5 000张)的眼动数据.
(6)DUT-OMRON数据集
DUT-OMRON数据集[58]由大连理工大学的Yang等人于2013年建立.该数据集包含5 168张图像,每张图像提供了 5名观测者的眼动数据.该数据集主要关注显著物体检测,因而在物体之外的视觉注意点在后处理过程中被移除.
我们将上述常用的静态场景的眼动数据集的相关信息进行了总结,见表1.
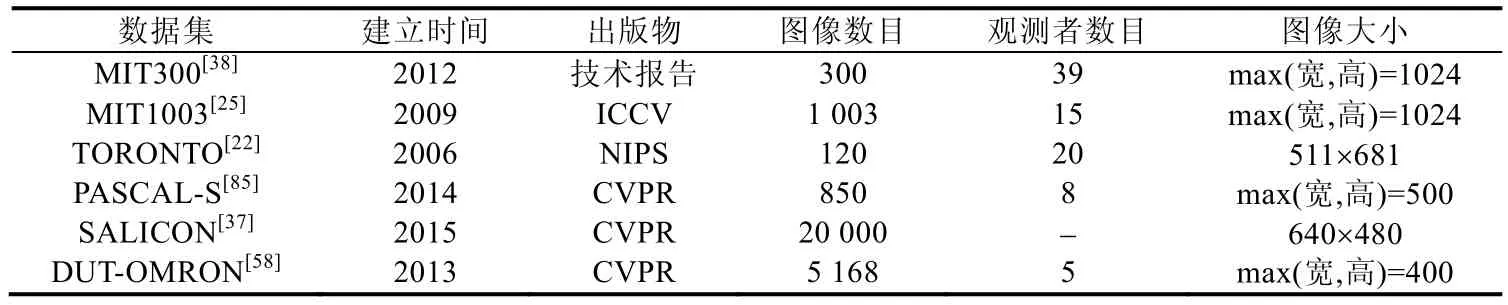
Table 1 Information of eye-tracking datasets collected in static scenes表1 关于静态场景下眼动数据集的相关信息
3.2 视频眼动数据集
与图像眼动数据集相比,动态场景下的眼动数据集较少.这主要是由于收集人类在观测动态视频时的眼动数据更为困难,对眼动仪器的要求更高,并且需要的工作量也更多.目前,代表性的动态眼动数据集主要有 4个:Hollywood-2[88]、UCF-sports[88]、DIEM[89]以及最新提出的 DHF1K[52].
(1)Hollywood-2数据集
Hollywood-2眼动数据集[88]由多伦多大学的Mathe等人在2012年建立,包括了Hollywood-2动作识别数据集[90]中的所有1 770个视频.这些视频是从69个电影中收集的,并按照12个动作类别进行了标注,例如吃饭、接吻和跑步等.眼动数据的收集过程共有19个观测对象参与完成,这些观测对象被分为3组:自由观看组(3个观测对象)、人类动作标注组(12个观测对象)和视频内容标注组(4个观测对象).虽然Hollywood-2数据集的视频数量较大,但这些视频的内容仅限于常见的人类动作行为和电影场景,并且该数据集主要关注在任务驱动(动作识别)的观看模式下,由于人类视觉系统的显著性机制,自由观看模式下的人眼关注点数据仅占所有数据的很小一部分比例.Wang等人的研究[52]指出,当从 Hollywood-2数据集中随机抽取 1 000个视频帧后,统计结果显示,84.5%的人眼注视点都位于场景中的人脸位置附近.
(2)UCF-sports数据集
UCF-sports眼动数据集[88]也是由Mathe等人在2012年建立的.该数据集包含了UCF sports action数据集[91]中的150个视频,这些视频涵盖了9种常见的体育运动类别,如潜水、游泳和跑步等.与Hollywood-2数据集相类似,该数据集偏向于任务驱动的观看方式,即观测对象在观看过程中被指示“识别在视频序列中发生的动作”,因此,观测对象在观看时具有偏向于动作识别的目的性.Wang等人的研究[52]指出,当从UCF sports数据集上随机选择1 000个视频帧进行统计后,结果表明,有82.3%的人眼注视点位于运动人物的身体区域内.
(3)DIEM数据集
DIEM数据集[89]是伦敦大学的Mital等人于2011年建立的.该数据集包含了从公共网络中收集到的84个视频,包括广告、纪录片、体育赛事和电影预告片等.数据集中的每段视频都有人眼关注点的标注,这些标注来自约50名观测对象在自由观看模式下的眼动数据.但该数据集包含的场景内容较为有限,并且数据规模较小.
(4)DHF1K数据集
DHF1K数据集[52]是由北京理工大学的Wang等人于2018年建立的,是学术领域迄今为止规模最大的、用于动态场景自由观看模式下的眼动数据集.整个数据集的收集、标定过程耗时近半年.Wang等人通过 Youtube搜索引擎搜索了大约200个关键字(如狗、行人、汽车等),并忽略了返回结果中包含较大图标、文字或分辨率较低的视频,最终从检索结果中选择了1 000个视频序列,这些视频被统一地转换为30fps的Xvid MPEG-4视频格式,并统一地缩放到640×360的分辨率.DHF1K数据集一共包含了1 000个视频序列和582 605个视频帧,总持续时间达19 420s.同时,DHF1K数据集还提供了更丰富的标定,每个视频都被人工标记了一个场景子类别(共有150类),这些子类别进一步被聚类为7种主要类别,即动物、景物、人造物以及4种人类活动(日常活动、运动、群体行为、艺术表演),这些场景的语义标注帮助人们更深入地理解引导动态注意力机制的高层信息,对将来的研究很有帮助.此外,DHF1K还提供了运动模式、场景明暗、物体数量等标定.共有 17位志愿者作为观测对象参与了眼动数据收集,这些观测对象包括 10名男性和 7名女性,年龄范围在 20岁~28岁之间,得到共计51 038 600组眼动数据.DHF1K数据集的1 000个视频被分为3部分,包括:600个视频作为训练集、100个视频作为验证集和300个视频的测试集.Wang等人公开发布了训练集和验证集的眼动数据,用于模型的训练和验证,测试集作为对各方法进行统一评估的标准,保留了标注数据.此外,Wang等人还在 DHF1K、Hollywood-2和UCF-sports这3个数据集上对16个视觉注意力模型进行了评估,这也是当前动态视觉注意力检测领域规模最大的一次测评.
(5)其他数据集
除了以上数据集之外,还有Itti等人在2004年建立的CRCNS数据集[92]以及Hadizadeh等人在2012年建立的SFU数据集[93],但是这些数据集的规模和影响力都相对较小.
我们在表2中对上述静态场景的眼动数据集的相关信息进行了总结.

Table 2 Information of eye-tracking datasets collected in dynamic scenes表2 关于动态场景下眼动数据集的相关信息
3.3 图像显著物体检测数据集
常用的图像显著物体检测数据集有 MSRA10K[12,53]、ASD[12,13]、ECSSD[55]、PASCAL-S[85]、DUT-OMRON[58]和HKU-IS[65].
(1)MSRA10K数据集
2007年,西安交通大学与微软亚洲研究院的Liu等人[12]提出了第1篇显著物体检测的论文,同时也提出了第 1个显著物体检测数据集,但是该数据集只提供了物体边界框这一级别的显著性真值标定.之后,Cheng等人[53]对该数据集[12]中的10 000张数据进行了像素级的标定,这一重标定的数据集被称为MSRA10K数据集,是目前显著物体检测领域最常用的数据集之一(主要作为深度显著物体检测模型的训练样本).
(2)ASD数据集
ASD数据集是最早使用的显著物体检测数据集之一,由洛桑联邦理工学院的Achanta等人[13]在2009年建立.该数据集包含了Liu等人[12]建立的数据集中的1 000张图像,Achanta等人对这1 000张图像进行了像素级的显著物体真值标定,该数据集也常被称为MSRA1000.
(3)ECSSD数据集
ECSSD数据集[55]由香港中文大学的Yan等人于2013年建立,包含了1 000张图像,这些图像由互联网得到.该数据集中的显著物体包含较复杂的结构,且背景具备一定的复杂性.
(4)PSCAL-S数据集
PASCAL-S数据集[85]于2014年由乔治亚理工学院的Li等人建立.该数据集使用了PASCAL VOC 2010[86]数据集的验证集的850张图像.Li等人根据该数据集上的眼动数据(参见第3.1节),对该数据集中每张图像的显著物体进行了标定.该数据集与其他显著物体检测数据集区别较大,没有非常明显的、较少的显著物体,并主要根据人类的眼动数据集进行标注,因此该数据集的难度较大.
(5)DUT-OMRON数据集
DUT-OMRON数据集[58]由大连理工的Yang等人于2013年建立,包含了5 168张图像,每张图像提供了5名观测者的眼动数据.该数据集的主要任务是显著物体检测,但也提供了眼动数据集(参见第3.1节),同时也包括了物体的标定框.该数据集每张图像由5人标注完成.
(6)HKU-IS数据集
HKU-IS数据集[65]由香港大学的Li等人于2015年建立,包含了4 447张图像和相应的像素级显著物体真值标定.该数据集的每张图像至少满足以下的3个标准之一:(1)含有多个分散的显著物体;(2)至少有1个显著物体在图像边界;(3)显著物体与背景表观相似.
我们在表3中对上述常用的图像显著物体检测数据集的相关信息进行了总结.
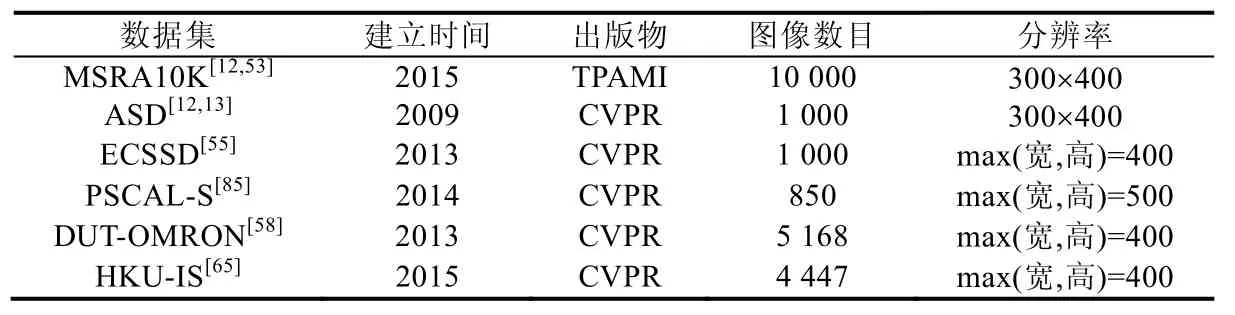
Table 3 Information of image salient object detection datasets表3 关于图像显著物体检测数据集的相关信息
3.4 视频显著物体检测数据集
在视频显著物体检测领域常用的数据集有 ViSal[74]、MCL[77]、UVSD[78]、VOS[82]、SegTrack[94,95]、FBMS[96,97]和DAVIS[98],其中,ViSal、MCL、UVSD、VOS是专门用于视频显著物体检测任务的数据集,SegTrack、FBMS和DAVIS则在视频物体分割领域有较多的应用.
(1)ViSal数据集
ViSal数据集[74]由北京理工大学的Wang等人于2015年建立,是第1个明确提出用于视频显著物体检测的数据集.该数据集包含了17个从Youtube上收集的视频序列,包含了多种类别的显著物体,如人类、动物等,视频的分辨率多为320×240,长度为30帧~500帧.该数据集每间隔5帧提供像素级的显著物体真值标定.该数据集涵盖了丰富的场景内容、不同的目标运动模式、较为复杂的背景、快速物体形状变化以及相机移动.
(2)MCL数据集
2015年,高丽大学的Kim等人建立了MCL数据集[77].该数据集包含了9个分辨率为480×270的视频序列,每个视频序列包含约100帧~400帧视频图像,涉及室内和室外场景,包含了多个快速运动的目标以及相机运动.该数据集每隔8帧视频图像给出了视频显著物体的像素级真值标定.
(3)UVSD数据集
UVSD数据集[78]由上海大学的Liu等人于2017年建立.该数据集含有18个视频序列,每一帧视频图像均进行了像素级的显著性标注.该数据集的视频分辨率以320×240为主,长度为70帧~300帧.该数据集的难度主要在于显著的物体相对较小,且显著物体与背景具有一定的相似性.
(4)VOS数据集
VOS数据集[82]由北京航空航天大学的Li等人于2018年建立,该数据集包含了200个室内/室外场景下的视频序列,时长共64min,包含116 103帧视频图像,帧率统一为30fps.该数据集对7 650个关键帧进行了像素级的标定;同时,该数据集还收集了23名观测者的眼动数据,以此作为确定显著物体的依据.
(5)SegTrack数据集
SegTrack数据集的初始版本(V1)于2010年由佐治亚理工学院的Tsai等人[94]建立.该数据集建立的初始目标是用于视频跟踪分割,在视频分割领域曾经极为流行.之后,在2015年被Wang等人[74]引入视频显著物体检测,SegTrack-V1数据集包含了6个视频,共224帧,其中,penguin这一视频中不包含显著的前景物体,故这一视频在无监督的视频物体分割和视频显著物体检测任务上不予以采用.之后,在2014年,Li等人[95]建立了SegTrack的扩充版本(V2),增添了8个视频,并提供了多个目标的标定,SegTrack-V2数据集因而共包含了14个视频序列以及1 065帧像素级的标定.
(6)FBMS数据集
FBMS数据集[96]的早期版本由加州大学伯克利分校的 Brox等人在 2010年建立,包含了 26个视频.之后,Ochs等人[97]在 2014年对其进行了扩展,最终版本共包含了 59个视频.该数据集最早是用来进行运动分割(motion segmentation)的.该任务主要是在无监督条件下对视频中的运动物体进行分割.之后,由Wang等人[74]引入到视频显著物体检测任务中.该数据集的标定较为稀疏,13 860帧视频中共有720帧的真值标定;并且,该数据集的标定较为简单,且并不完全符合视频显著物体的定义.
(7)DAVIS数据集[98]
DAVIS数据集于2016年由苏黎世联邦理工学院的Perazzi等人建立,主要用于视频物体分割.该数据集经过精心设计,因此一经提出就在视频分割领域获得了极大的影响力.该数据集包含了 50个高质量的视频序列,含有480p和1 080p两个版本,视频长度约为2s~4s,且提供了对每帧视频图像的像素级真值标注.该数据集包含了多种挑战,如遮挡、运动模糊、表观变化等,因而有较高的难度.由于该数据集有明显的前景目标,在标注时主要考虑单一的前景目标或相连的两个明显前景目标,较为符合视频显著物体的定义,Wang等人于 2018年[84]将其引入视频显著物体检测任务.
我们对上述常用的视频显著物体检测数据集的相关信息进行了总结,见表4.
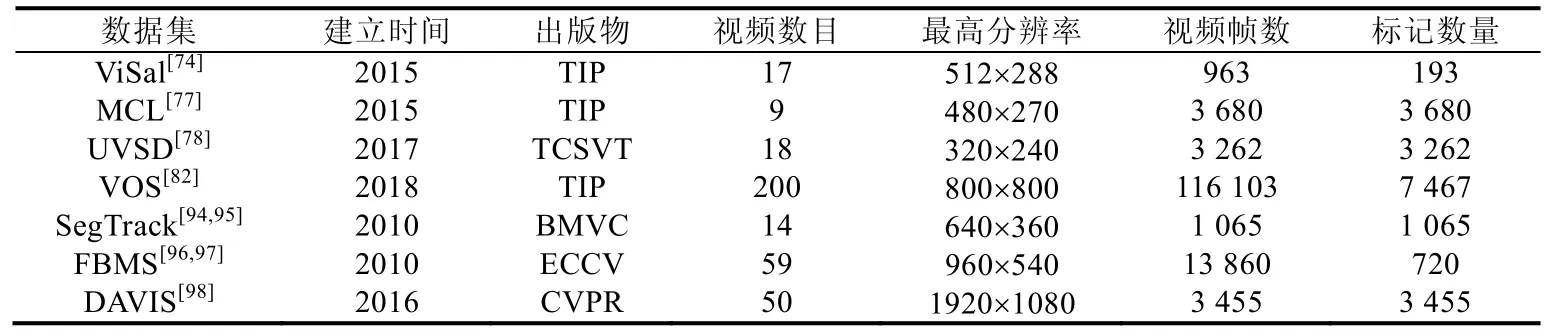
Table 4 Information of video salient object detection datasets表4 关于视频显著物体检测数据集的相关信息
4 视觉显著性检测评估指标
本节主要介绍视觉显著性检测任务中常用的评估指标.
4.1 人眼关注点检测评估指标
在人眼关注点检测任务中,研究者们提出了较多的评估指标,其中较为典型的包括EMD距离(earth movers distance)、交叉熵(kullback-leibler divergence)、标准化扫描路径显著性(normalized scanpath saliency,简称NSS)、相似性测度(similarity metric,简称SIM)、线性相关系数(linear correlation coefficient,简称CC)、AUC指标(the area under the receiver operating characteristic(ROC)curve).
这些指标遵循了不同的设计原则,如,交叉熵指标将显著性预测结果与真实的人眼注意力标定视为概率分布;AUC指标将显著性预测结果视为二分类结果,并使用信号检测理论,从分析分类器分类性能的角度进行评估;或将显著性预测结果与真实的人眼注意力标定二者都视为随机变量,从而可以采用线性相关系数或标准化扫描路径显著性来度量二者相关性.本质上,这些评估指标为显著性检测结果和真实的人眼注意力分布之间的一致性提供了不同维度上的评估,从实际效果而言,综合采取多种评估方式对模型进行评估的做法更可取.
当给定显著性预测结果P=[0,1]W×H时,真实的二值人眼注意点记录R={0,1}W×H以及连续的视觉注意力真值分布Q=[0,1]W×H.这里,连续的视觉注意力真值分布Q是通过对二值的人眼注意点分布图使用较小的高斯核卷积得到的,高斯核的参数主要根据不同眼动数据集上人眼大小和眼动设备的情况来进行设定.下面我们详细介绍人眼关注点检测任务中常用的评估指标:
(1)EMD距离
EMD距离(earth movers distance)衡量的是显著性预测结果P与连续的人眼注意力真值分布Q之间的相似性,该度量方式被定义为:从显著性预测结果P上的概率分布转移到连续的人眼注意力真值分布Q上的最小代价.因而,EMD距离越小,表示估计结果越准确.
(2)交叉熵
交叉熵(kullback-leibler divergence)主要基于信息理论,经常被用于衡量两个概率分布之间的距离.在人眼关注点检测中,该指标被定义为:通过显著性预测结果P来近似连续的人眼注意力真值分布Q时产生的信息损失,可通过式(3)来计算.

其中,ε表示很小的正则化系数,i表示第i个像素.交叉熵指标是非对称的度量指标,交叉熵越小,表示显著性估计结果越准确.交叉熵这一指标对零值非常敏感,会对稀疏的人眼关注点预测产生非常大的惩罚.
(3)标准化扫描路径显著性
标准化扫描路径显著性(normalized scanpath saliency,简称NSS)是专门为显著性检测设计的评估指标.该指标被定义为:对在人眼关注点位置归一化的显著性(均值为0和归一化标准差)求平均,可通过式(4)来计算.
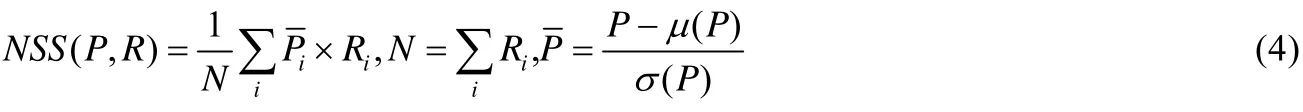
其中,N表示所有的人眼关注点数目;μ(·)表示均值;σ(·)表示标准差,该指标越小,表示显著估计结果越准确.
(4)线性相关系数
线性相关系数(linear correlation coefficient,简称 CC)是一种用于衡量两个变量之间相关性的统计指标.在使用该度量时,将显著性预测结果P和连续的人眼注意力真值分布Q视为随机变量.然后,统计它们之间的线性相关性,如式(5)所示.

其中,cov(·,·)表示表示协方差,该统计指标的取值范围是[-1,+1].当该指标的值接近-1或+1时,代表显著性预测结果与真值标定高度相似.
(5)相似性测度
相似性测度(similarity metric,简称SIM)指标将显著性预测结果P和连续的人眼注意力真值分布Q视为概率分布,将二者归一化后,通过计算每一个像素上的最小值,最后加和得到,如式(6)所示.
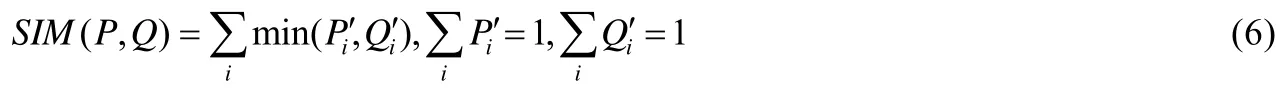
当相似性测度为1时,表示两个概率分布一致;为0时,表示二者完全不同.
(6)AUC指标
AUC指标(the area under the receiver operating characteristic curve,简称ROC曲线),即受试者工作特性曲线下面积.ROC曲线是以假阳性概率(false positive rate,简称 FPR)为横轴,以真阳性概率(true positive rate,简称TPR)为纵轴所画出的曲线,如式(7)所示.

其中,TN表示二值显著性图中的背景区域且对应于显著性真值图中的背景区域的像素个数.ROC曲线越趋近于左上方,说明算法的性能越好.AUC即为ROC曲线下的面积,通过在[0,1]上滑动的阈值,能够将显著性检测结果P进行二值化,从而得到ROC曲线.当采用较小的阈值时,可以视为计算两个概率分布的整体相似度;当取较大的阈值时,进而计算两个分布在峰值处的相似度,通过ROC曲线可以计算AUC指标,AUC数值越大,说明算法性能越好.当接近1时,代表着显著性估计与真值标定完全一致.根据ROC曲线的定义,AUC指标主要受高阈值的影响.此外,AUC指标对人眼关注点的中心偏向较为敏感,根据对FPR以及TPR定义的不同,AUC指标也产生了许多变体,典型的包括:Judd等人[25]提出的AUC-Judd,真阳性概率是所有真值关注点上预测准确的像素比率,假阳性概率为非关注点上被预测为显著的像素比率;Borji等人[99]提出了AUC-Borji指标,该指标在计算假阳性时,在非关注点上采用了均一的随机采样,而不是直接选取所有的非关注点,但由于采取了随机采样,AUC-Borji指标容易出现多次对同一个模型评估但结果不一致的现象;shuffled AUC(简称sAUC)[100]也是一个常用的AUC变体,该指标降低了原AUC指标对中心偏移的敏感性,sAUC指标对非显著性点进行采样时,是从其他多张图像上的关注点分布中进行采样,而不是根据在原来图像上的非显著点上进行随机采样,这一采样方法能够导致符合高斯分布的采样,如果在一个模型的检测结果上人为地加入了中心偏向,那么 sAUC指标在图像中心位置的密集采样会导致这个模型的评估结果下降.
我们对以上人眼关注点评估指标进行了统计和归类,见表5.根据这些评估指标对视觉显著性做出的不同假设[101],可以将其分为基于位置的评估指标和基于概率分布的评估指标:基于位置的评估指标将显著性视为随机变量,基于概率分布的评估指标将显著性视为概率分布.根据不同评估指标的度量方式,可以分为相似性度量指标和非相似性度量指标:相似性指标越大,表示模型表现越好;非相似性指标越小,表示模型表现越好.根据不同评估指标采用的真值形式,可以将其分为使用连续显著性真值Q的评估指标和使用二值离散人眼注意点真值R的评估指标.
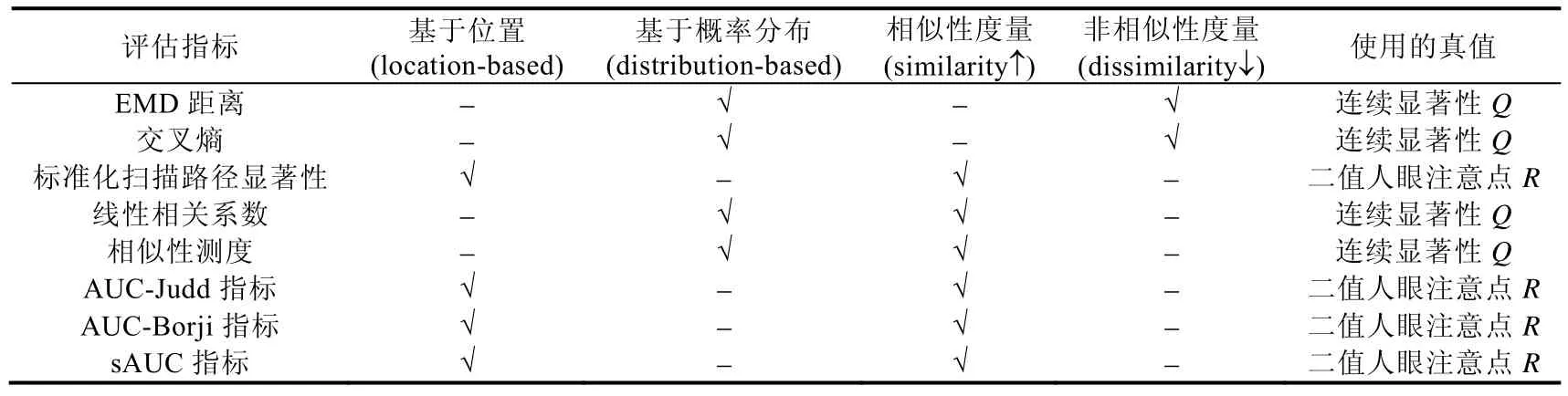
Table 5 Information of evaluation metrics used in eye fixation prediction表5 关于人眼关注点检测评估指标的相关信息
4.2 显著物体检测评估指标
在显著物体检测任务中,查准率-查全率曲线(precision-recall curve)、F值(F-measure)以及平均绝对误差MAE值(mean absolute error)是3个最常见的评估指标.
(1)查准率-查全率曲线
给定显著性估计结果,取值范围在[0,255]之间,通过使用从0到255依次变化的阈值,能够生成一组二值化的显著性结果图(小于阈值的像素标记为 0,大于阈值的像素标记为 1).将每张二值化显著性结果图与显著性真值标定的结果进行比较,可以得到相应的查准率和查全率,如式(8)所示.

其中,TP表示二值显著性结果中显著区域与真值显著性标定中一致的像素个数;FP表示二值显著性结果中被错误划分为显著的像素的个数;FN表示二值显著性结果中被错误划分为背景的像素的个数.即查准率是指在算法生成的所有前景像素中被正确标定的像素的比率,查全率是指在实际真值标定的前景像素中被算法正确标定的像素的比率.查准率较高,说明有较多的显著区域被正确地检测到,而这往往意味着被误检为显著的像素也较多,从而查全率可能较低;查全率较高,代表检测到的显著区域中检测正确的概率很高,但这也往往意味着有较多的显著区域没有被正确检出,从而精确度可能较低.通过不断变化的阈值,能够得到一组相应的查准率和查全率结果.以查全率为横轴,查准率为纵轴,可以绘得查准率-查全率曲线(precision-recall curve,简称PR-curve).曲线越靠近右上方,说明算法性能越好.
(2)F-值
由于查准率和查全率相互制约,且查准率-查全率曲线包含了两个维度的评估指标,不易比较,因而需要就二者进行综合考量.Achanta等人[13]提出了F-值指标(F-measure).该指标同时考虑了查准率和查全率,能够较为全面、直观地反映出算法的性能.其定义如式(9)所示.

其中,β2=0.3,以此强调查全率更高的重要性.F-值指标的数值越大,说明算法性能越好.在实际中,有算法使用F-值曲线,而有的则直接给出F-值曲线上的最大值.
(3)MAE值
MAE值(mean absolute error,简称MAE)是指平均每个像素估计的显著性概率与相应的真值显著性标定之间的绝对误差.由于查准率-查全率曲线和F-值这两个评估指标都只考虑了显著像素的划分结果,而没有考虑对背景划分正确的情况(真阴性),因此,MAE指标经常作为查准率-查全率曲线和F-值这两个评估指标的补充.其定义如式(10)所示.
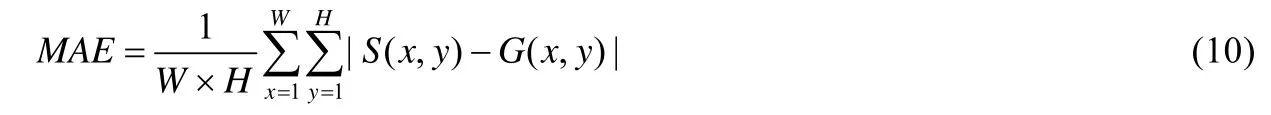
其中,S表示归一化到[0,1]之间的显著性估计结果,G表示显著性真值标定,W和H对应图像的宽和高.作为相似性度量指标,MAE值越小,代表算法性能越好.MAE指标较为直观,对评估显著性检测模型的实际应用能力(如物体分割)十分重要.
5 视觉显著性检测模型性能评估
本节针对静态及动态场景下的人眼关注点检测模型以及显著物体检测模型的性能进行定量评估.
5.1 人眼关注点检测模型在静态场景下的性能评估
本节针对 14个经典的静态人眼关注点检测模型(DeepFix[30]、SALICON[31]、DVA[35]、Mr-CNN[32]、SalNet[33]、Deep Gaze I[102]、BMS[103]、eDN[29]、CAS[104]、AIM[105]、Judd Model[25]、GBVS[23]、ITTI[9]、SU[106])的性能进行定量测试,使用了3个静态人眼关注点检测数据集,分别为MIT300[38]、MIT1003[25]和PASCAL-S[85].实验使用了AUC-Judd、SIM、s-AUC、CC和NSS这5种评估指标,相关定量评估结果分别见表6~表8.在MIT300数据集上的定量评估结果是根据该数据集的公开结果(http://saliency.mit.edu/)得到的,在MIT1003及PASCAL-S数据集上的定量评估结果是通过运行这些模型的代码或论文中公布的数据得到的.
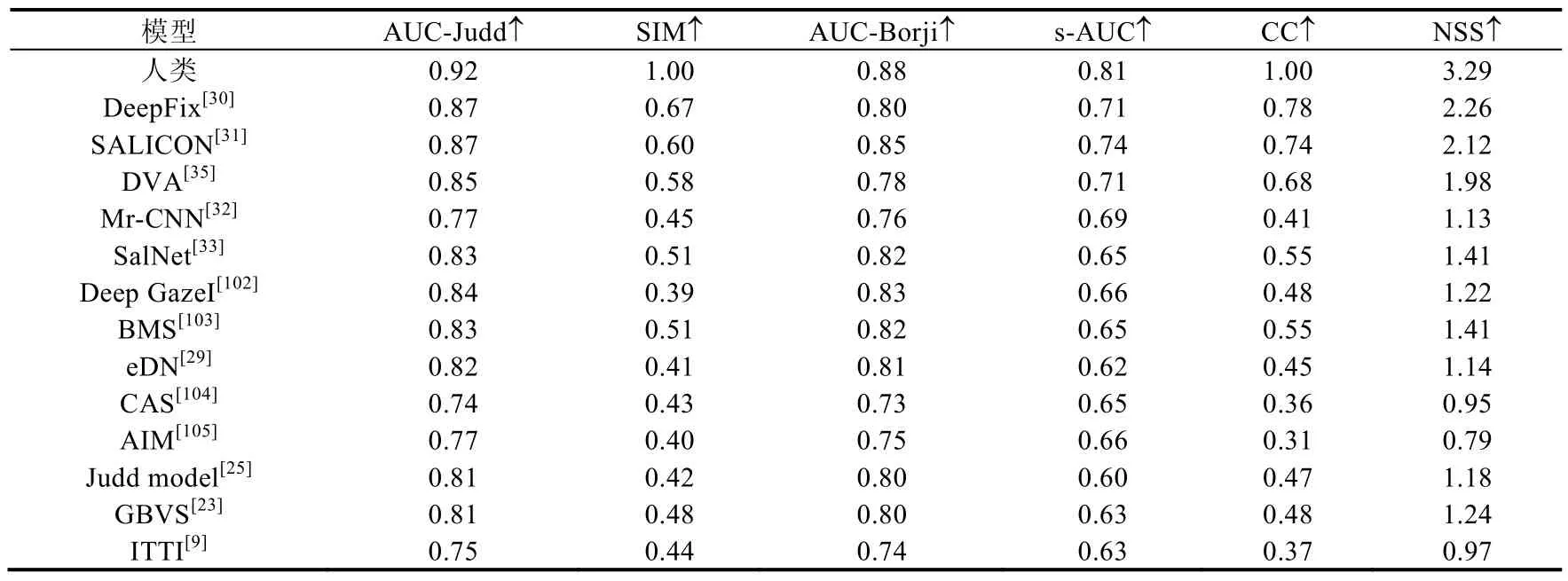
Table 6 Quantitative evaluation of different static visual fixation prediction models on MIT300 dataset[38]表6 对不同的静态人眼关注点检测模型在MIT300数据集[38]上性能的定量评估
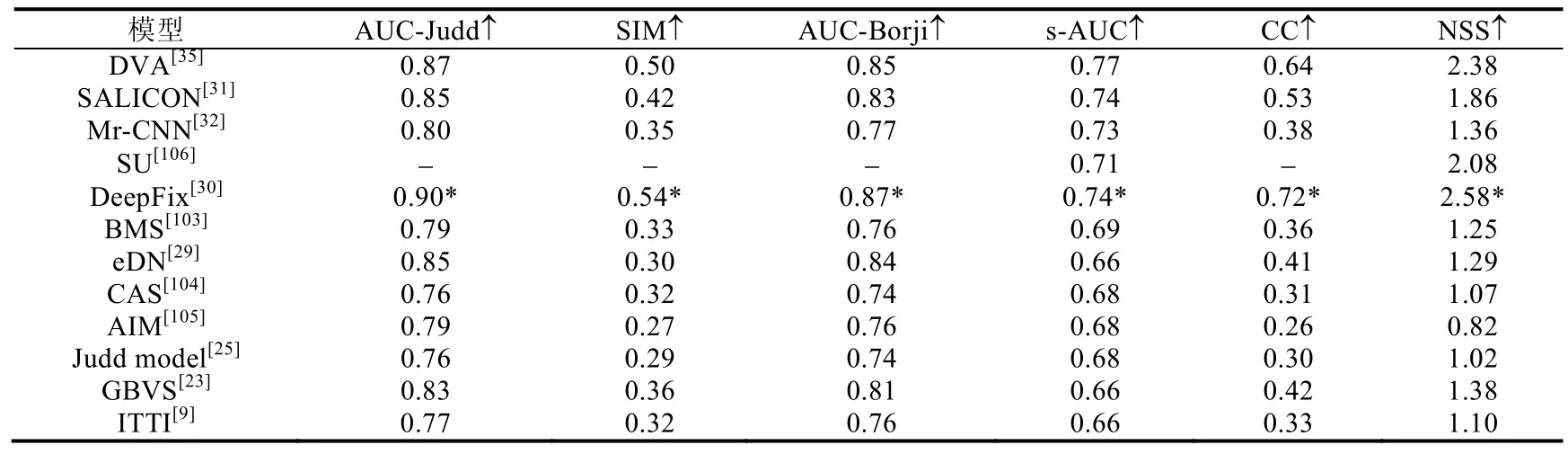
Table 7 Quantitative evaluation of different static visual fixation prediction models on MIT1003 dataset[25]表7 对不同的静态人眼关注点检测模型在MIT1003数据集[25]上性能的定量评估
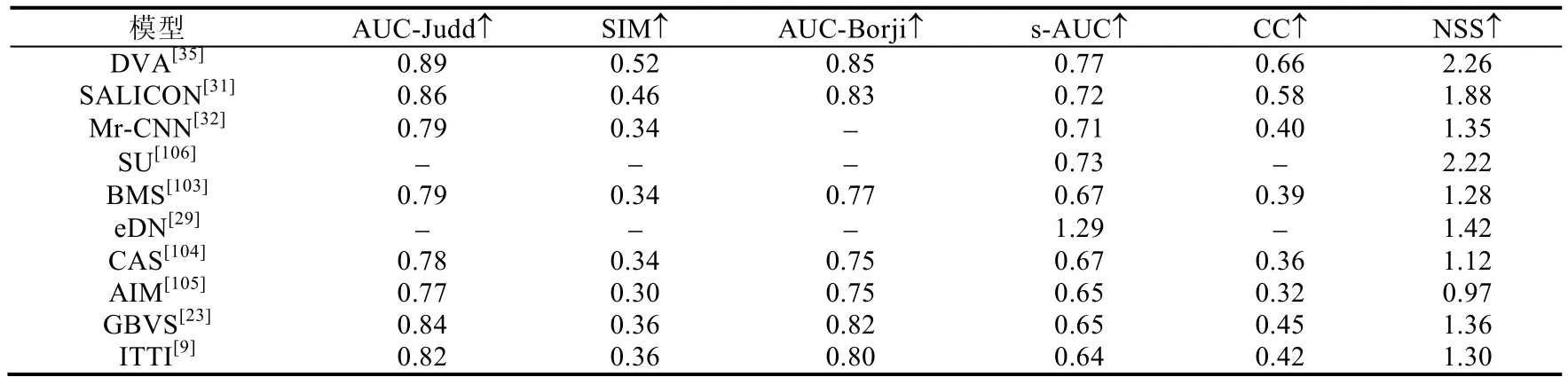
Table 8 Quantitative evaluation of different static visual fixation prediction models on PASCAL-S dataset[85]表8 对不同的静态人眼关注点检测模型在PASCAL-S数据集[85]上性能的定量评估
5.2 人眼关注点检测模型在动态场景下的性能评估
本节针对16个经典的人眼关注点检测模型在动态场景下的性能进行定量测试,其中包括6个静态人眼关注点检测模型(ITTI[9]、GBVS[23]、SALICON[31]、Shallow-Net[33]、Deep-Net[33]、DVA[35])以及 10 个动态人眼关注点检测模型(PQFT[107]、SEO[41]、RUDOY[43]、HOU[44]、FANG[108]、OBDL[45]、AWS-D[46]、OM-CMM[51]、Two-stream[50]和 ACLNet[52]),使用了 3个动态人眼关注点检测数据集,分别为 DHF1K[52]、Hollywood-2[88]和UCF-sports[88].实验使用了AUC-Judd、SIM、s-AUC、CC和NSS这5种评估指标,相关定量评估结果分别见表9~表11.评估结果主要根据DHF1K数据集的公开结果(https://github.com/wenguanwang/DHF1K)得到.
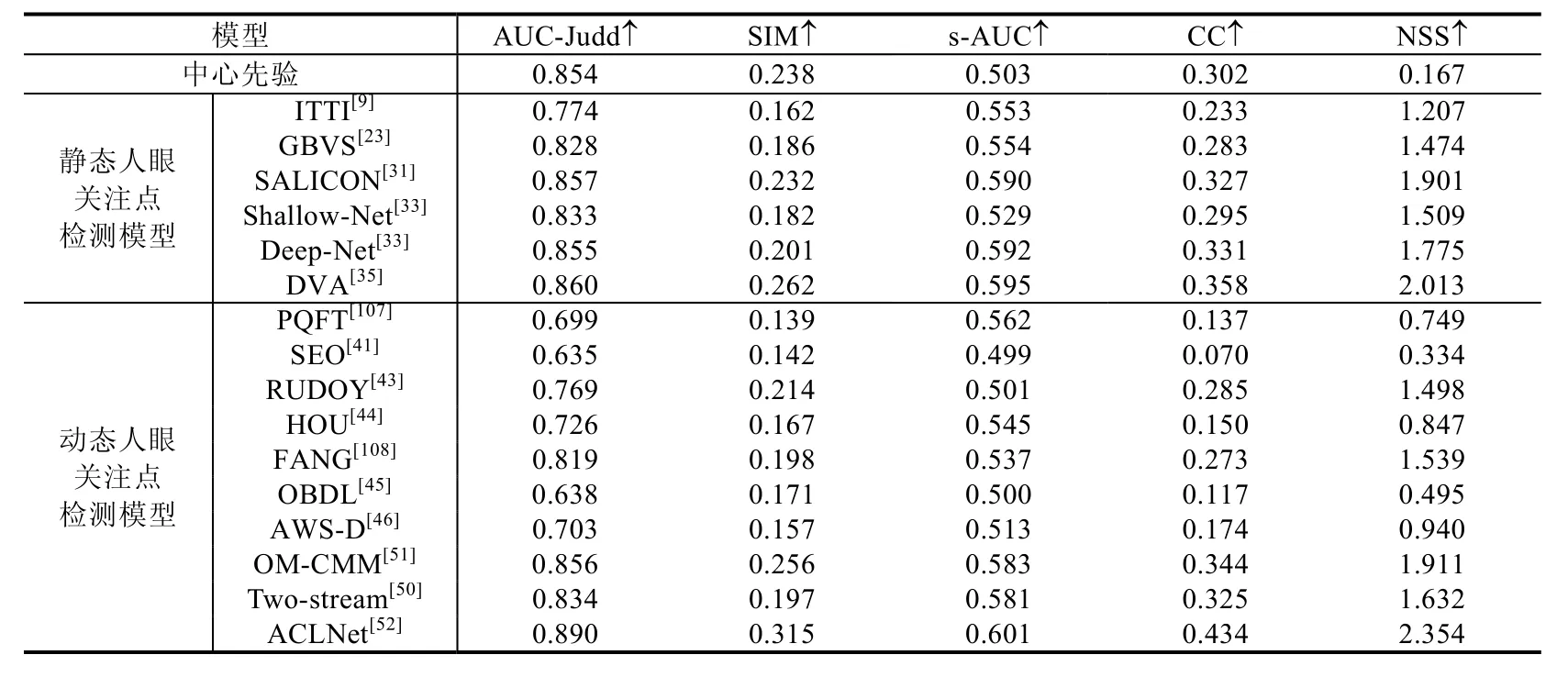
Table 9 Evaluation of visual fixation prediction models in dynamic scenes using DHF1K dataset[52]表9 DHF1K数据集[52]上,对不同的人眼关注点检测模型在动态场景下的性能评估
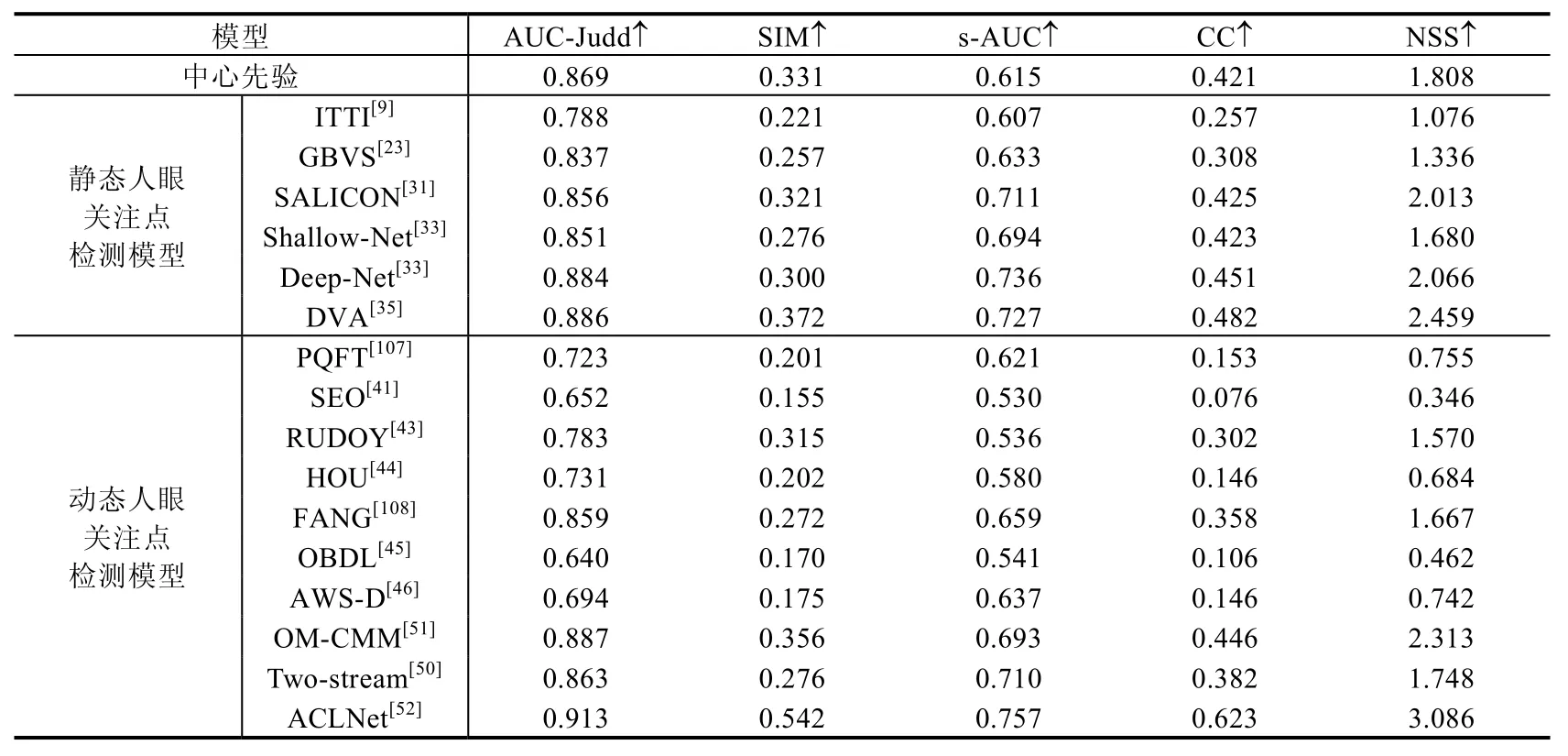
Table 10 Evaluation of visual fixation prediction models in dynamic scenes using Hollywood-2 dataset[88]表10 Hollywood-2数据集[88]上,对不同的人眼关注点检测模型在动态场景下的性能评估
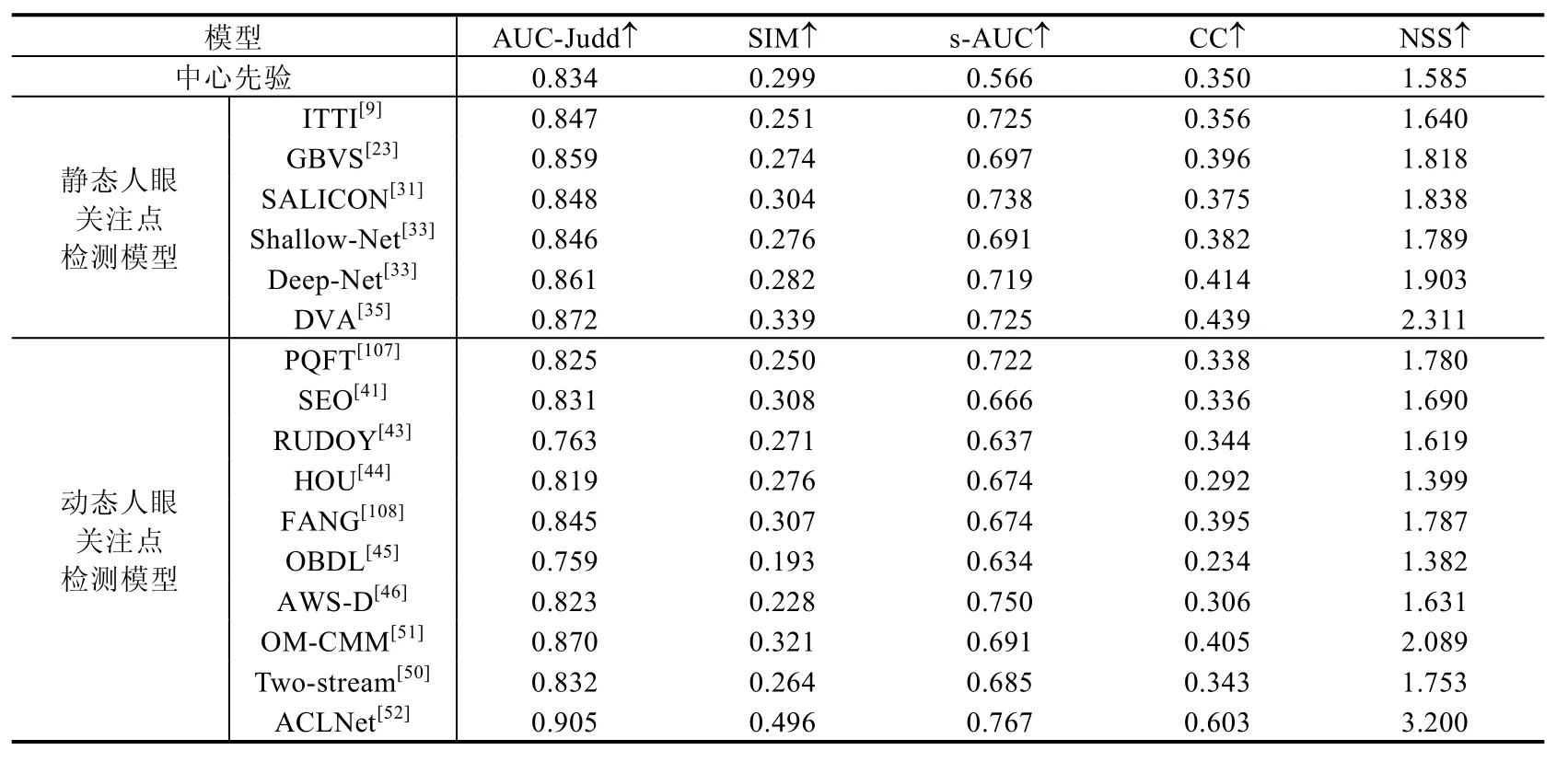
Table 11 Evaluation of visual fixation prediction models in dynamic scenes using UCF-sports dataset[88]表11 UCF-sports数据集[88]上,对不同的人眼关注点检测模型在动态场景下的性能评估
5.3 显著物体检测模型在静态场景下的性能评估
本节针对20个经典的静态人眼关注点检测模型,包括4个传统的、非深度学习的模型(HS[55]、DRFI[56]、wCtr[57]、CST[109])以及 16 个基于深度学习的模型(MDF[65]、LEG[64]、MDS[110]、DCL[111]、ELD[66]、SU[106]、RFCN[67]、DHS[72]、HEDS[69]、NLDF[112]、DLS[71]、AMU[68]、UCF[113]、SRM[114]、FSN[115]、ASNet[70]),在 ECCSD[55]、HKU-IS[65]和PASCAL-S[85]这3个数据集上的性能进行了定量测试.表12总结了使用F-score和MAE作为评估指标的定量结果.
图1中以查准率-查全率曲线作为评估指标的定量结果.这些结果是通过运行以上模型的代码或论文中公布的数据得到的,图1中没有提供SU模型的结果,因为该模型的实现源码和相关查准率-查全率结果都未给出.
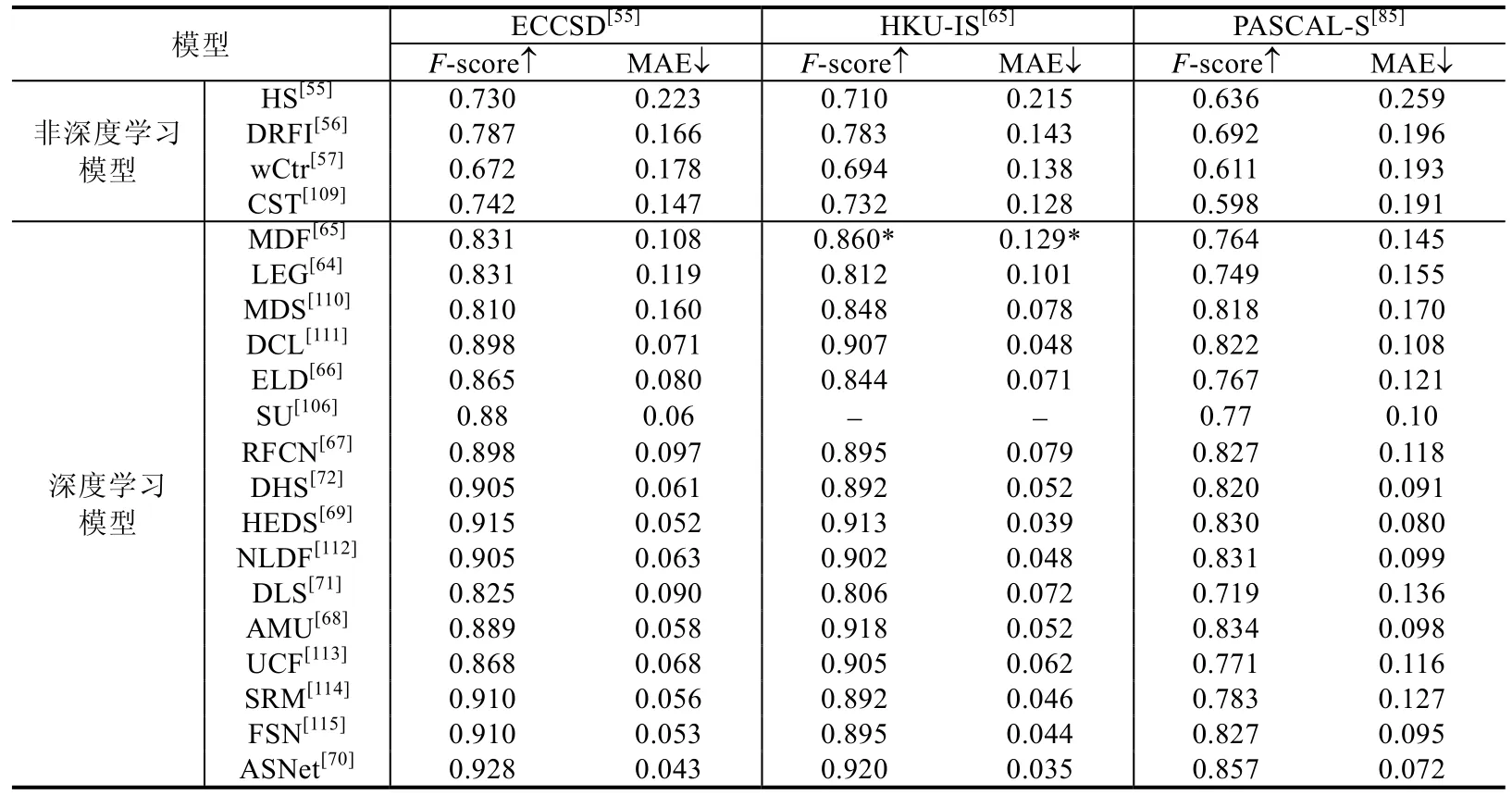
Table 12 Quantitative evaluation of different static salient object detection models on ECCSD[55],HKU-IS[65],and PASCAL-S[85] datasets usingF-score and MAE表12 对不同的静态显著物体检测模型在ECCSD[55]、HKU-IS[65]和PASCAL-S[85]数据集上性能的定量评估,使用F-score和MAE作为评估指标
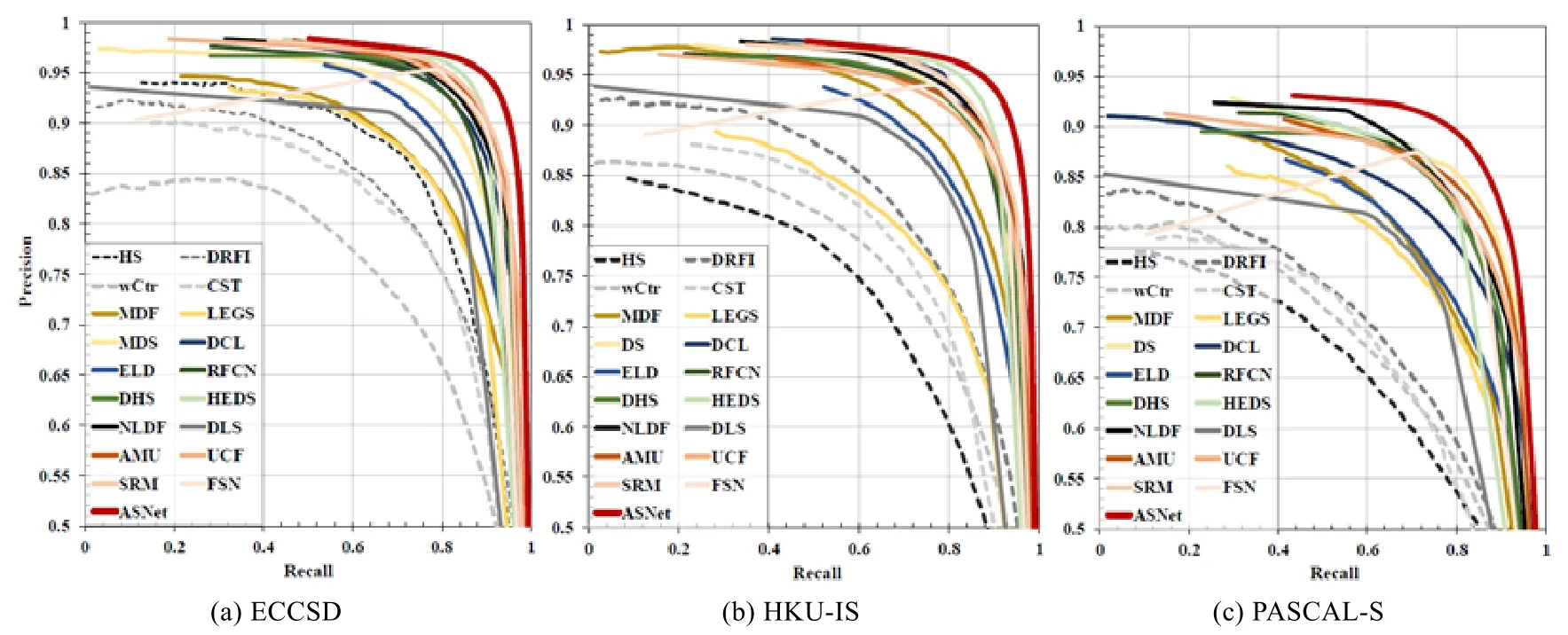
Fig.1 Quantitative evaluation of different static salient object detection models on ECCSD[55],HKU-IS[65],and PASCAL-S[85] datasets using precision-recall curve图1 对不同的静态显著物体检测模型在ECCSD[55],HKU-IS[65]和PASCAL-S[85]数据集上性能的定量评估,使用查准率-查全率曲线作为评估指标
5.4 显著物体检测模型在动态场景下的性能评估
本节针对17个经典的显著物体检测模型在动态场景下的性能进行定量测试,其中包括10个静态显著物体检测模型(AMU[68]、SRM[114]、UCF[113]、HEDS[69]、NLDF[112]、DCL[111]、DHS[72]、ELD[66]、KSR[116]和 RFCN[67])以及 7 个动态显著物体检测模型(FCNS[84]、SGSP[78]、GAFL[74]、SAGE[75]、STUW[42]、SP[73]和 PDB[117]),使用了 3个动态视频显著物体检测数据集,分别为 DAVIS[98]、FBMS[97]和 ViSal[74].SGSP、GAFL、SAGE、STUW和SP为非深度学习模型,其余算法均为深度学习模型.表13总结了使用F-score和MAE作为评估指标的定量结果,图2中为查准率-查全率曲线作为评估指标的定量结果.这些结果是通过运行以上模型的代码或论文中公布的数据得到的.
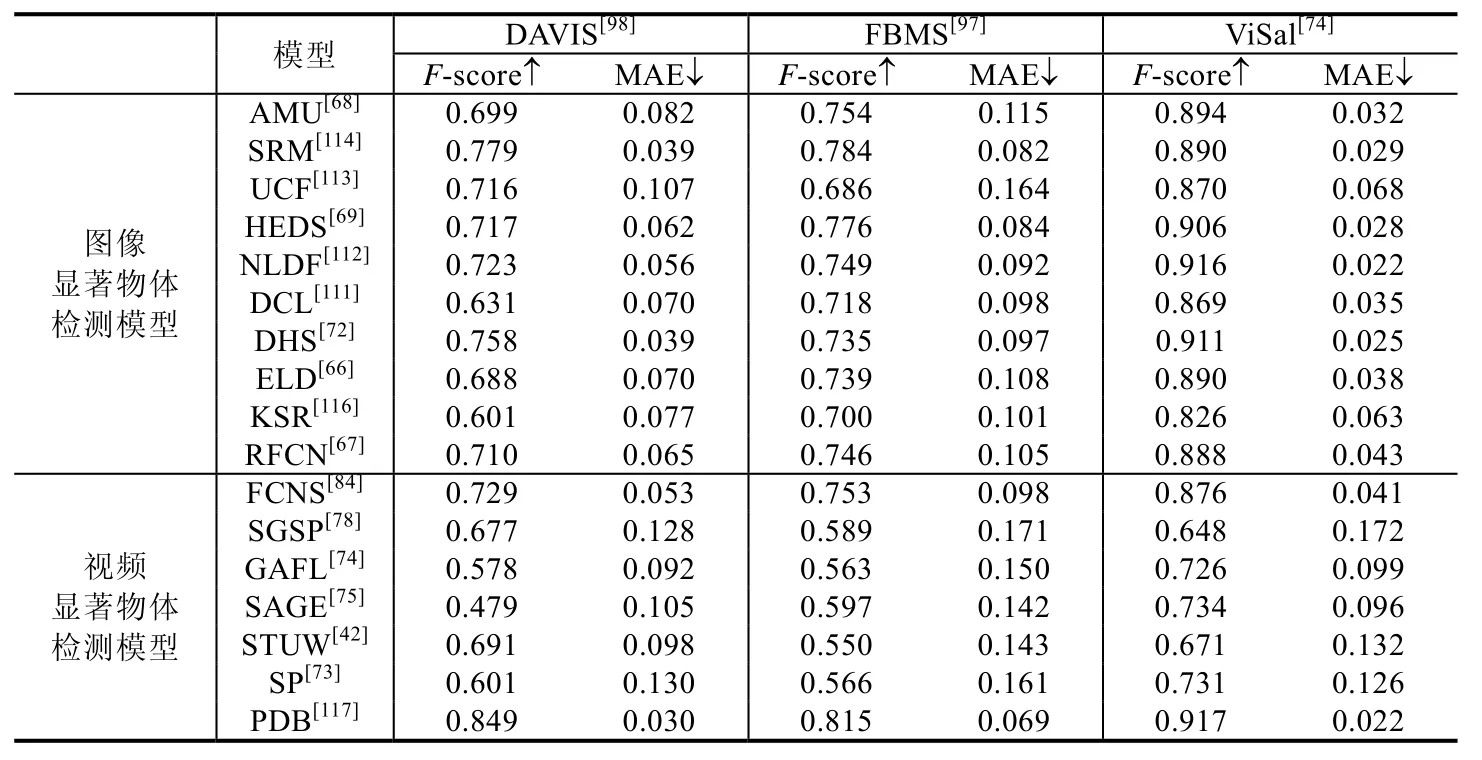
Table 13 Evaluation of salient object detection models in dynamic scenes using DAVIS[98],FBMS[97],and ViSal[74] datasets,measured byF-score and MAE表13 在DAVIS[98]、FBMS[97]以及ViSal[74]数据集上,对不同的显著物体检测模型在动态场景下的性能评估,使用F-score和MAE作为评估指标
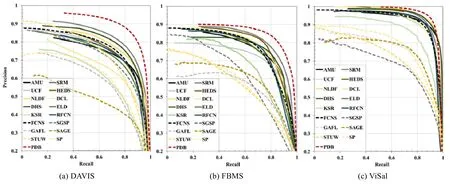
Fig.2 Evaluation of salient object detection models in dynamic scenes using DAVIS[98],FBMS[97],and ViSal[74] datasets,measured by precision-recall curve图2 在DAVIS[98]、FBMS[97]以及ViSal[74]数据集上,对不同的显著物体检测模型在动态场景下的性能评估,使用查准率-查全率曲线作为评估指标
6 总结与展望
随着深度学习技术在计算机视觉领域取得广泛的成功,深度神经网络成为当前视觉注意力机制计算和建模的首选工具,基于深度学习的视觉显著性模型在人眼关注点检测和显著物体检测领域都取得了极佳的效果.我们认为,视觉注意力检测领域未来可能的研究工作主要包括以下几个方面.
(1)在人眼关注点检测方向,进一步将经典的认知理论与深度学习技术相融合.
传统的认知领域通过对人类和其他灵长类动的观测和研究,积累了很多经典的关于视觉注意力机制的理论和模型,这些理论更符合生物学原理,如1985年Koch等人[8]提出的WTA理论、1991年Leventhal提出的中央周边差[118]、Treisman的特征整合(FIT)理论[10]、Wolfe等人提出的指向搜索模型[11]等.但是,现在计算机视觉领域中,对视觉注意力机制的计算建模主要基于深度学习技术,很少与之前经典的认知理论相结合,虽然基于深度学习技术的计算模型具有较好的性能,但是对研究界理解视觉注意力机制背后更深层次的机理,难以提供更多更有价值的实验支持.因而,有必要将基于深度学习技术的计算模型与经典认知理论相结合,进一步发展新理论和新模型.此外,经典的视觉注意力机制理论指出,人眼注意力的分配是由自底向上与自顶向下两个过程协同完成的,但是当前的基于深度学习技术的显著性检测模型主要通过融合不同网络层抽取的不同层次的特征来得到显著性检测结果,而缺乏有效地、显式地融合自底向上和自顶向下信息的过程,这与之前针对视觉注意力机制的研究成果不符,因此,有必要进一步发掘现有的深度学习技术,将自底向上和自顶向下的显著性检测过程融合到深度神经网络结构中,并能够通过端到端的方式进行学习.
(2)从注意力机制角度,研究深度神经网络的可解释性.
目前,深度神经网络受到注意力机制的启发,通过特殊的网络结构,能够“迫使”神经网络关注文本或图像中与任务最相关的部分.这种神经网络的注意力模块,可以被视为一种自顶向下、任务相关的注意力机制.这类带有注意力机制的深度神经网络在许多任务上表现出了较好的性能,但是这种通过隐式学习的、与任务相关的注意力是否真的与人类的注意力相一致?这一问题对通过注意力机制来研究深度神经网络的事后解释性(posthoc explanation)非常重要,但却很少有工作关注这一点.我们有必要在现有的公共数据集上收集人类在执行有关任务时的眼动数据,据此和深度神经网络的注意力机制进行比较;同时,利用人类实际的注意力机制来显式引导神经网络,即观察当神经网络利用有监督的注意力机制时其性能的变化,从而能够从注意力机制的角度,对深度神经网络的可解释性进行更深入的研究.
(3)通过借鉴认知科学的理论研究,进一步拓宽计算机视觉领域对视觉注意力研究的内涵和外延.
认知科学中,对人类的注意力机制进行了更深入、更广泛的研究,如:群体的注意力机制(group attention)、人类在社交场景中的注意力机制(co-attention in social scenes).因此,计算机视觉领域针对视觉注意力计算模型的研究,有必要充分吸收借鉴认知科学领域中对于人类注意力机制的理论成果,进一步研究挖掘人类视觉注意力机制以及更高层次的感知理解,如:研究第一人称视角下的人类注意力机制、研究人类在社交场景下的认知机制、研究人类的多轮注意力分配和转移机制,并基于人类的行为、动作、注意力进一步研究人类的行为意图(intention).
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
新体育(2022年2期)2022-02-09 07:04:32
甘肃教育(2020年14期)2020-09-11 07:58:44
今日农业(2019年12期)2019-08-13 00:50:12
中学生数理化·七年级数学人教版(2019年6期)2019-06-25 01:01:30
快乐语文(2019年9期)2019-06-22 10:00:38
中学生数理化·八年级物理人教版(2018年11期)2019-01-31 02:40:08
传媒评论(2017年3期)2017-06-13 09:18:10
优雅(2016年12期)2017-02-28 21:32:58
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
