
针对层次化名字路由的聚合机制∗
2019-03-05 03:45:42许志伟张玉军
软件学报 2019年2期
许志伟,陈 波,张玉军
1(中国科学院大学,北京 100049)
2(中国科学院 计算技术研究所,北京 100190)
3(Department of Computer Science,University of Memphis,Memphis,TN 38152,USA)
现有的互联网在可扩展性、移动性和安全性等方面面临严峻的挑战[1-3].互联网的主流应用形式已经从基本的端到端通信转变为大规模内容传输,现有互联网端到端的设计原则无法适应这些新兴的内容密集型应用形式,加剧了互联网的内容传输压力.同时,随着移动互联网的发展,由移动终端产生的流量占总体网络流量的比重日益增加,而 TCP/IP体系结构面向常连接设计,IP地址被赋予身份和位置双重功能,无法有效支撑移动性应用的要求.
为了从根本上解决互联网面临的这些问题,需要采用clean-slate方式设计并建设全新的未来互联网[3-5].命名数据网络(named data networking,简称NDN)[6,7]根据信息名字请求和传输数据,不再依赖固定的IP地址传输数据,保证了互联网的可扩展性和移动性;同时,采用网内数据泛在缓存和多路传输,有效地保障了这种基于内容名字的传输机制的效率.鉴于 NDN网络的这些优点,命名数据网络的设计思想已经得到了广泛的重视和研究,将会应用于包括5G在内的新兴网络体系[8,9].
NDN网络基于内容名字进行路由,内容名字由不定数量的任意字符串组成.与 IP地址相比,内容名字的结构更为复杂,因此,现有的互联网路由机制无法直接应用于NDN网络.同时,当前互联网拥有海量的在线内容,相应的内容名字数量也极其庞大.综合考虑NDN网络路由内容名字的复杂性及其庞大的数量,基于名字的路由技术将是影响NDN网络效率的最为关键的问题,将直接影响NDN网络的效率和可用性[1].名字是内容的标识,目前常见的内容名字可以分为两类.
· 一类是以 NDN为代表的层次化名字,采用可读的文本方式组织,一般由多个“/”隔开的名字段(字符串)组成,名字段的数量和长度都是任意的,类似于现行互联网中的URL(uniform resource locator)[7].
· 另一类是以数字签名为代表的扁平化名字.这类名字是经过散列(hash)得到的散列值,具有很好的安全性[2].各类扁平化名字具有其专门的编码方式,与IP地址类似,配备有完整的命名和路由规则.
当前,关于层次化名字路由的研究还不成熟,尤其是如何优化层次化名字路由,还没有完善的解决方案.
目前,关于层次化名字路由传输的研究主要集中在提升路由表的名字前缀(名字前缀由多个名字段构成)查找速度方面[10-14],例如,通过前缀树压缩和GPU并行加速等方法来提高路由查表速度.现有的NDN路由机制为了获取特定内容,需要针对该内容的名字添加相应的路由表项,利用内容名字标识路由,并关联可以用于转发的接口信息(不唯一),因此,NDN的路由表规模与现有 TCP/IP网络的路由表规模相比将出现巨大的增长.另一方面,NDN网络中内容来源多样,信息可以来自多信息源,或者移动信息源,甚至以存储在网内缓存中的信息副本作为信息来源,导致网络内容版本变化更加频繁,进一步加剧了层次化名字路由器的负载.因此,仅靠提升单节点查表速度难以保证海量在线内容的高效路由转发.针对这些问题,我们需要约减 NDN 网络整体路由规模,实现层次化路由的聚合和聚合更新,保证高效、准确地转发内容请求包及相应的内容包,提升NDN网络整体效率.
路由聚合是降低路由表规模、提升查表效率和优化路由转发效率的主要措施.路由聚合用一条聚合路由代替大量原始路由,从而减小路由表规模[15].NDN网络各节点路由聚合过程如图1所示,聚合前,路由表中存在各个内容对应的表项;聚合后,具有公共前缀和相同转发接口的表项被聚合为一条聚合路由.不同于现有无类域间路由利用子网号(IP前缀)作为聚合路由标识,NDN网络聚合路由的标识应包括两部分:首先是内容名字前缀,其次还需要利用后缀聚合标识区分这一前缀下发往不同接口内容名字.这一聚合路由标识上的差异实际上反映了IP路由和层次化名字路由的本质差异.IP地址路由标识了路由转发的目的地址,特定子网内IP地址有限,可以用子网号代表这些地址,作为聚合路由标识.NDN网络中,拥有同一名字前缀的路由的指向不确定,仅利用名字前缀无法代表所有被聚合的路由,形成的聚合路由也无法作为路由转发的真正依据,需要引入名字后缀的压缩表示来共同标识被聚合的路由.
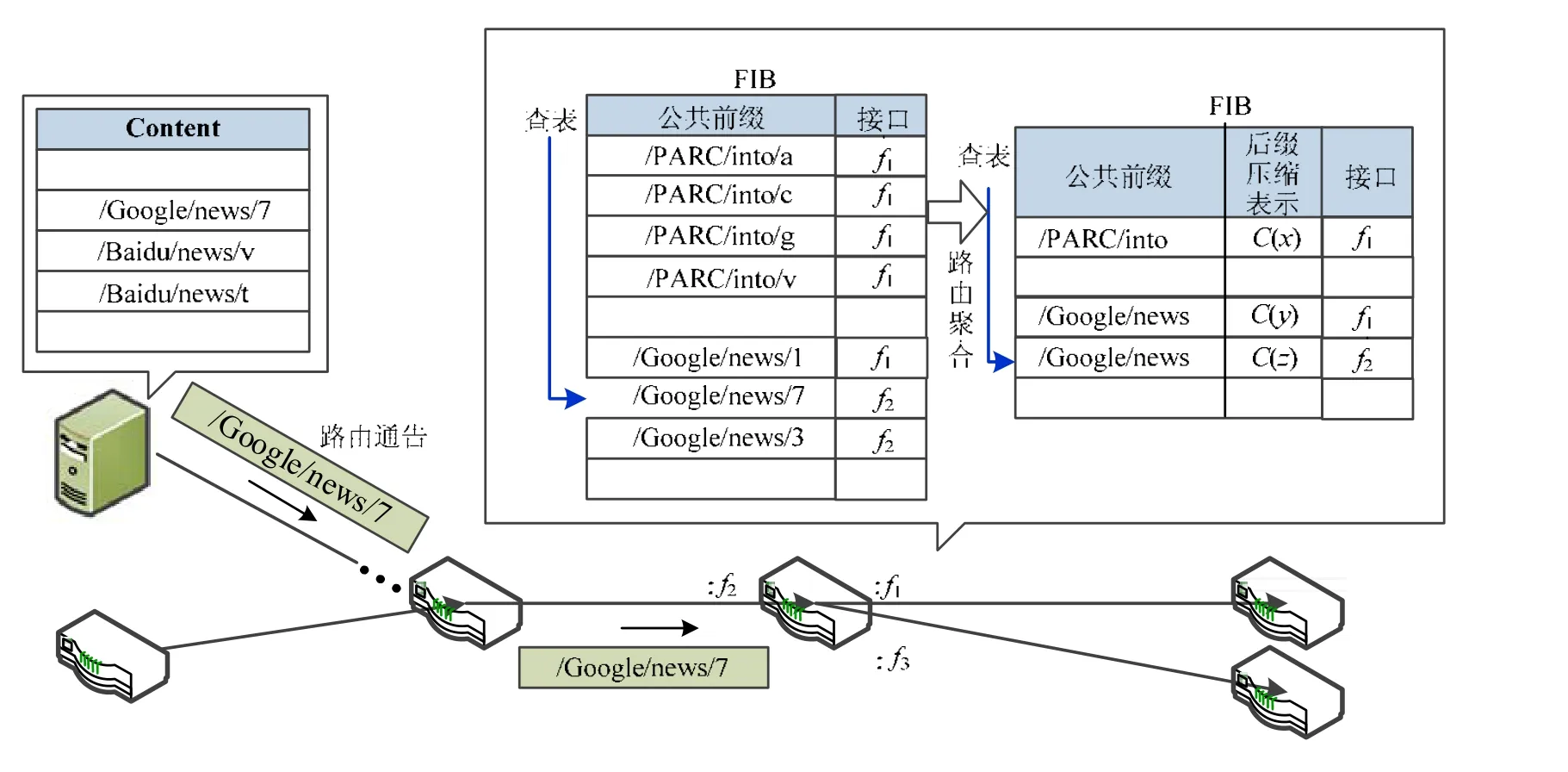
Fig.1 An example for hierarchical name-based route aggregation图1 层次化名字路由的聚合实例
为了实现全网路由聚合,最大程度地减少名字路由条目数量,在完成特定前缀的名字路由聚合后,需要将被聚合路由通告给其他网络节点,以便这些节点进一步进行路由聚合,与本地路由表压缩的效果对比,路由聚合能够在网络层面真正大幅度缩减路由规模.
为了约减全网路由规模,提升层次化名字路由查表及转发效率,本文对层次化名字路由聚合问题进行了系统的分析,采用名字前缀和后缀压缩表示共同标识路由,提出了支持聚合的后缀压缩表示机制,并以路由可用性为依据构建了高可用的路由聚合机制,为NDN网络投入实际部署提供了前提.主要包括如下工作.
(1)对层次化名字路由聚合问题进行了研究,明确了将名字后缀纳入聚合后的路由标识的必要性.
(2)为了支持聚合路由在节点间的交换及进一步的聚合,本文提出了一种支持更新及合并操作的后缀压缩表示机制,堆叠计数布隆过滤器.
(3)为了限制后缀压缩表示引起的冗余转发,我们依据聚合路由的可用性构建了一套动态名字路由聚合机制,在保证路由转发正确性的前提下,最大程度地聚合名字路由,约减全面路由规模,提升了路由转发效率,保证了海量在线内容的高效路由转发.
本文首先在第1节对问题背景和相关研究进行系统分析.第2节分析层次化名字路由问题.第3节提出一种可合并计数布隆过滤器,用于名字后缀的压缩表示,和名字前缀一同标识聚合路由,以便进行本地路由聚合和全网聚合路由通告.在此基础上,本文给出一套高可用的动态路由聚合机制.最后,本文在真实网络拓扑的基础上构建仿真平台,验证所提出的层次化名字路由聚合机制.
1 背景及研究现状
1.1 NDN网络
NDN根据层次化的名字而不是IP地址路由和转发数据包.为了从NDN网络中获取需要的内容,一个请求节点 Consumer首先发送请求包(interest),其中包括被请求内容的层次化名字.网络中的路由节点收到该请求包后,分3步进行处理.
(1)首先查找PIT表(pending interest table).PIT表记录了之前转发过的所有未被响应的请求包信息,包括被请求内容的名字、收到该请求的时间、接口及转发接口.如果在 PIT表中找到了特定名字的请求信息,则意味着已经转发过该请求,将新的请求到达端口加入该表项的接口列表,收到内容后一并处理;如果没有找到,则建立新的PIT表项.
(2)查找该节点的内容缓存CS(content store),如果缓存了该内容,则直接构建相应的内容包(content),并从收到请求的接口返回内容包.
(3)如果本地未缓存所请求内容,则查找转发表FIB(forwarding information base),从指定接口将该请求转发给下一跳的各个邻居.如果传输路径上的节点都没有缓存被请求内容,则请求包最终将被转发到内容发布者 Producer,由内容发布者构建内容包.内容包中将包括内容名字、内容、内容包签名及签名信息(发布者公钥等).然后,同样由内容发布者从收到请求包的接口返回该内容包.内容包由转发请求包的路由节点按照其对应 PIT表项中的记录沿请求到达接口原路径返回,最终达到内容请求者Consumer.
各节点 FIB中记录全网所有在线内容的转发信息,路由条目数量巨大,为了保证正常的基于层次化名字的路由转发,必须有效地约减路由条目数量,提升路由查表及转发效率.
1.2 相关研究分析
针对现有的TCP/IP网络规模不断增长的问题,大量工作试图通过IP路由聚合和压缩加以解决[15,16].其中,基于无类域间路由的TCP/IP网络路由聚合机制利用子网号(IP前缀)代表被聚合的子网IP地址,有效地约简了全网路由规模[15],保证了现有 TCP/IP网络体系结构的互联网的可用性.其后,为了进一步缩短路由查表时间,提升路由转发效率,出现了大量本地路由表压缩方面的研究.Degermark等人通过一种全新的 hash机制实现了路由IP前缀的压缩[16].文献[17]首次使用基本的Bloom过滤器实现了路由表查表过程的优化.针对IPv4和IPv6路由查表过程,文献[18]提出了一种编码机制,在保证查找效率的同时,降低了查找过程中的误判率.然而,由于名字路由不再基于 IP实现路由,而是以内容名字为路由标识进行路由,路由标识的数量不可控,且结构更为复杂,这些研究都无法直接应用于层次化名字路由.
在 NDN路由转发方面,张丽霞等人[7]进行了大量基础性研究.首先,在文献[19]中提出了 NDN网络的自适应多路转发机制,在转发路径选择方面优化了网络传输效率;其次,文献[20,21]分别提出了 NDN网络中基于内容名字的最短路径优先协议OSPFN和链路状态协议NLSR,实现了基本的层次化名字路由.在所提出的这些关键问题的引导下,层次化名字路由机制得到了更为广泛的研究[22-24],包括分层路由和路由可达性评估等机制被先后引入层次化名字路由过程.为了进一步提升路由查表效率,文献[10,13,14,25]通过哈希表、名字前缀的前缀树索引和前缀树压缩等方式优化了NDN路由节点路由查表(内容名字查找)效率.文献[11]通过GPU提升了前缀树查找效率.为了实现板卡级别的包过滤,进而优化NDN网络内容获取效率,文献[12]利用布隆过滤器实现了网络节点本地FIB表、PIT表和CS缓存的表项板卡级缓存,提升了转发效率.然而,当今互联网已经得到了全方位的应用,在可以预期的互联网扩大应用的大背景下,网络信息数量将进一步急剧增长[3],仅仅通过改进本地路由查表过程、提升查表效率,并不能从根本上解决未来层次化名字路由在应用中的路由规模问题,需要通过研究包括路由聚合在内的全网路由规模约减机制来保证正常的路由查表及转发.
2 针对层次化名字路由的聚合过程分析
构建在现有互联网层次化网络拓扑之上的TCP/IP路由聚合机制,通过无类域间路由将子网IP地址聚合成对应的子网网络号以约减路由表规模,并将聚合后的路由通告给其他网络节点,以便进行进一步的聚合,最终形成高度聚合的聚合路由,在全网范围内约减路由规模.NDN的层次化名字路由根据路由名决定从哪几个接口转发内容请求.下面通过一个例子分析名字路由聚合过程.注意,为了简化分析,假设各节点路由的转发接口均一致,不再特别说明.参照IP地址聚合机制,层次化名字聚合过程如图2(a)所示.
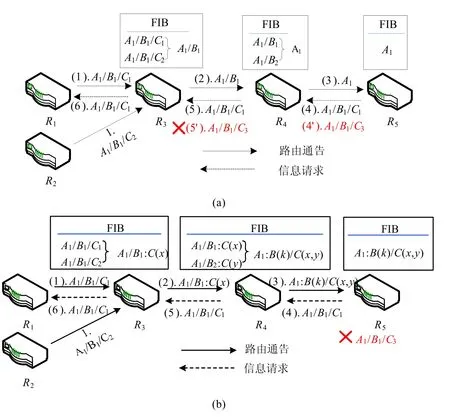
Fig.2 Potential problems in hierarchical name-based route aggregation图2 针对层次化名字的路由聚合过程的潜在问题
(1)在路由建立过程中,路由器R1和R2分别向路由器R3发送了针对名字A1/B1/C1和A1/B1/C2的路由通告.
(2)路由器R3收到这两条路由通告后,聚合成路由表项A1/B1并添入其FIB(fowarding information base)表.
(3)路由器R3继续向周边路由器通告聚合后的路由表项,最终路由器R4将收到的路由通告A1/B1与其本地路由A1/B2进一步聚合,得到路由A1并通告给R5.
(4)在数据请求阶段,路由器R5向R4发送请求包,请求名字为A1/B1/C1的内容.
(5)路由器R4会根据路由表项A1/B1将请求包转发给路由器R3.
(6)最终由路由器R3转发给路由器R1,路由器R1返回相应的数据内容给请求者.
从上述过程可知,采用层次化名字聚合能够缩小全网路由表规模,进而提升路由查找效率.然而,如果仅仅采取与IP地址类似的聚合方式,那么当请求没有聚合过的内容时,这种聚合方式将会出现问题.还是在上述例子中,如果在步骤(4′)中,R5请求名字为A1/B1/C3的数据,那么在步骤(5′)中,R4同样会基于聚合后的路由表项将请求包转发给路由器R3,但因为路由器R3中并没有聚合名字为A1/B1/C3的路由信息,将导致数据请求失败.
从上述实例可以看出,名字聚合不能完全采用IP路由聚合的方式.原因在于,IP路由地址是一种具有固定长度的由0和1组成的比特串,当聚合后的IP地址前缀长度为k时,其可能包含的被聚合后缀的取值最多只有232-k种,IP地址聚合时考虑到了所有可能的后缀取值,聚合后通过IP前缀信息标识路由;与IP地址不同,内容名字的取值可以是任意字符串.层次化名字的一个名字段在理论上有无穷多种取值,如图2(a)中,名字前缀“A1/B1/”后面可以添加各种字符串(名字后缀),因此,以名字前缀为标识的聚合结果无法囊括所有可能的名字后缀,即使请求名字同路由名字的前缀吻合,也无法保证可以根据该路由转发请求并获得对应的内容.因此,在名字路由聚合过程中,不仅需要抽离出待聚合路由的公共前缀来作为新的聚合路由前缀,同时为了准确地将多条路由聚合为一条聚合路由,也需要生成这些待聚合路由名字后缀的压缩表示,和聚合路由前缀一起标识聚合路由,如图2(b)所示.为了便于节点间交换聚合路由并进一步聚合这些路由,实现全网路由聚合,后缀压缩表示不仅需要能够准确地压缩表示被聚合路由的名字后缀,还需要支持多个后缀压缩表示的合并,以便构建新的聚合路由.如图2(b)中,R3完成对路由A1/B1/C1和A1/B1/C2的聚合后,会将聚合路由A1/B1:C(x)通告周边节点R4,其中,C(x)为名字后缀C1和C2的压缩表示,R4可以将收到的聚合路由A1/B1:C(x)和本地路由A1/B2:C(y)进一步聚合,压缩表示B1,B2的同时,合并C(x),C(y),形成新的聚合路由A1:B(k)/C(x,y),聚合路由标识由名字前缀A1和名字后缀压缩表示B(k)/C(x,y)共同构成.
考虑到全网海量内容名字聚合后的巨大熵空间,过度的聚合必将带来路由查表过程中的误判,因此在名字聚合过程中,需要保证聚合后路由的可用性.在此基础上,最大程度地聚合路由,缩减全网路由的规模.如何构建准确的后缀压缩表示机制,并以聚合路由可用性为依据完善层次化名字路由的聚合机制,以更少的路由条目表征正确的路由转发路径,这将是一个极具挑战性的问题,也是层次化名字路由聚合过程中必须解决的一个关键问题.
3 针对层次化名字路由的聚合机制
根据上一节的分析,为了构建针对层次化名字路由的聚合机制,主要需要解决两个问题.
(1)聚合路由标识问题,具体来说就是名字后缀的压缩表示问题;
(2)以路由可用性为基准的路由聚合问题.
为了解决这些问题,本节首先对聚合过程中的核心问题——名字后缀压缩表示问题进行分析,并按照分析结论设计支持路由名字后缀压缩表示的计数布隆过滤器——堆叠计数布隆过滤器,和名字前缀一起构成聚合路由标识;最后,在对NDN路由可达性分析的基础上构建一套高可用动态路由聚合机制.
3.1 后缀压缩表示问题分析
网络内容不断发生变化,存在内容源失效、内容过期和内容版本更新等情况,为了能够动态地添加并更新指向相关内容的聚合路由,后缀压缩表示机制不仅要表示特定内容后缀的存在性,同时还要支持特定内容后缀的删除和更新.经过多年的发展,布隆过滤器(Bloom filter,简称BF)已经成为应用最为广泛的压缩表示机制,衍生出了多种不同类型的布隆过滤器,其中,计数布隆过滤器(counting Bloom filter,简称 CBF)被设计用来同时支持添加操作和删除操作[26].CBF通过将 BF的单比特位单元扩展为用于计数的固定长度的多比特位单元,记录各单元被重复设置为1的次数(所添加名字段的哈希值命中这一单元的次数),以便哈希到这些单元上的已添加元素需要被删除时,通过减小这些单元上的计数器值来实现元素删除.除了用l比特的计数器替代基本布隆过滤器的单比特单元外,CBF完全等同于 BF,可以按照基本布隆过滤器的配置方法配置,包括配置过滤器单元(计数器)数、哈希函数数量等.CBF的哈希函数命中特定单元的最大次数c大于特定整数i的概率具有上界[27],可以根据这一上界配置CBF各单元计数器大小(比特位串长度l).通常情况下,4比特长的计数器即可满足构建CBF的需要,以极大的概率保证任一单元的计数器都不会超出其最大计数范围.CBF可以满足路由聚合过程中路由更新引起的动态添加、删除名字后缀的需要.为了优化CBF的性能,在支持添加操作和删除操作的同时,降低存储开销和假阳性率,多种新型计数布隆过滤器先后被提出来.其中,Cohen等人提出了 Spectral Bloom Filter(SBF)[28],可以确保其任一单元的计数器都不会超出其最大计数值,但是与 CBF相比增加了的存储开销.文献[29]基于d-left哈希提出dlCBF,与CBF相比,在同样的假阳性率下优化了存储开销.MPCBF[30]利用多级比特数组在保证查询效率的基础上实现了CBF的功能,其存储开销和假阳性率与CBF相比都有所改善.
但是,如果利用现有各类计数布隆过滤器压缩表示路由名字后缀,在全网路由聚合过程中,来自不同节点的相关路由后缀的压缩表示将被进一步聚合,这就需要将后缀压缩表示(计数布隆过滤器)合并,而现有的各类计数布隆过滤器[27-30]都不支持多个计数布隆过滤器的合并操作.现有计数布隆过滤器都通过类似计数器的机制来记录哈希函数重复命中各个单元的情况,多个计数布隆过滤器合并时可以选择的合并算子包括加运算、或运算和异或运算.首先,逐个单元进行计数器值的按位或运算和异或的运算结果不能代表不同元素命中各单元的计数总和,因此无法用来支持计数布隆过滤器的合并.而对应单元的计数器相加同样也存在问题.例如,
(1)将计数布隆过滤器的计数器长度设为4比特,最大计数值为15.
(2)当一个节点R周边的16个节点中的一个Rj压缩表示一个后缀名字段nsgx后,nsgx的k个哈希结果指向的计数布隆过滤器CBFj的计数器的值c1j,…,ckj均加 1,得到∀cij≥1,i∈{1,2,…,k},j∈{1,2,…,16}.
(3)假设R周边的16个节点都压缩表示了nsgx,当R需要进一步聚合这条路由时,需要合并来自16个邻居的计数布隆过滤器CBF1,…,CBF16.如果采用相加的方式合并这些CBF,则需要将这些计数布隆过滤器各单元计数器的值相加,即ci=ci1+…+ci16.由于∀cij≥1,故ci≥16,超出了计数器的最大计数范围.
注意,这与上述计数器最大值的概率上界并不冲突.文献[27]中上界的证明条件是计数布隆过滤器用于压缩表示不重复元素,如果不同路由存在相同的名字后缀,计数布隆过滤器的计数器很快就会溢出.究其原因,现有计数布隆过滤器在压缩表示被添加的元素的过程中,没有保留足够的信息,无法发现两个压缩表示结果中相同的元素,合并后压缩表示结果中会出现重复元素.综上所述,由于现有计数布隆过滤器不能有效地排除不同路由节点上记录的相同名字后缀的影响,因此不能支持来自不同路由节点的名字路由的聚合操作.为了实现支持路由聚合的名字后缀压缩表示机制,并和路由名字前缀一同标识聚合路由,需要构建一种全新的压缩表示机制,该机制需要同时支持:(1)后缀名字段的动态添加和删除;(2)多个压缩表示结果的合并.针对这两个需求,我们在第3.2节中设计了一种全新的计数布隆过滤器——堆叠计数布隆过滤器(compounded counting Bloom filter,简称CCBF),用于被聚合路由名字后缀的压缩表示.
3.2 堆叠计数布隆过滤器
为了支持名字后缀的动态添加和删除,同时支持多个压缩表示的合并,我们在现有计数布隆过滤器思想的基础上构建的新的后缀压缩表示机制需要:
(1)归并重复后缀名字段的添加,支持多个压缩表示的合并;
(2)记录后缀名字段哈希结果命中过滤器各个单元的次数,支持后缀名字段的动态添加和删除.
通过加运算合并现有计数布隆过滤器时,由于无法排除记录在多个计数布隆过滤器中的重复后缀名字段,造成合并结果中会出现计数器计数溢出的情况.我们注意到,基本布隆过滤器可以通过按位或归并重复名字段.这是由于在基本布隆过滤器中重复添加和合并重复名字段时,重复的名字段的所有哈希结果都将命中过滤器中同一个单元,即使重复置1,也不会改变BF比特数组的取值,从而屏蔽了重复名字段的影响.例如,将一个布隆过滤器BF1同另外一个布隆过滤器BF2合并的过程中,如果BF1和BF2中都添加了后缀名字段nsgx,nsgx的k个哈希结果分别指向的这两个布隆过滤器的k个单元(位),b11,…,bk1和b12,…,bk2,全部被置 1.注意到,合并BF1和BF2后,仍有:

合并结果中同样是这k个单元被置1,可以有效地归并记录在不同布隆过滤器中的重复名字段.根据这一观察,我们利用基本布隆过滤器可以归并重复元素的特点,通过堆叠多个相同的基本布隆过滤器来构建支持合并的计数布隆过滤器.多个基本布隆过滤器的特定位置的单元可以共同记录该位置被所添加的后缀名字段的哈希结果命中的次数(每次将其中一个基本布隆过滤器的相应单元置 1),从而构建了一种全新的支持合并的计数布隆过滤器——堆叠计数布隆过滤器.CCBF通过伪随机发生器使用多个基本布隆过滤器,在有效使用所包含的过滤器的同时,保留了各单元被重复置1时过滤器的使用顺序.
CCBF的数据结构如图3所示.
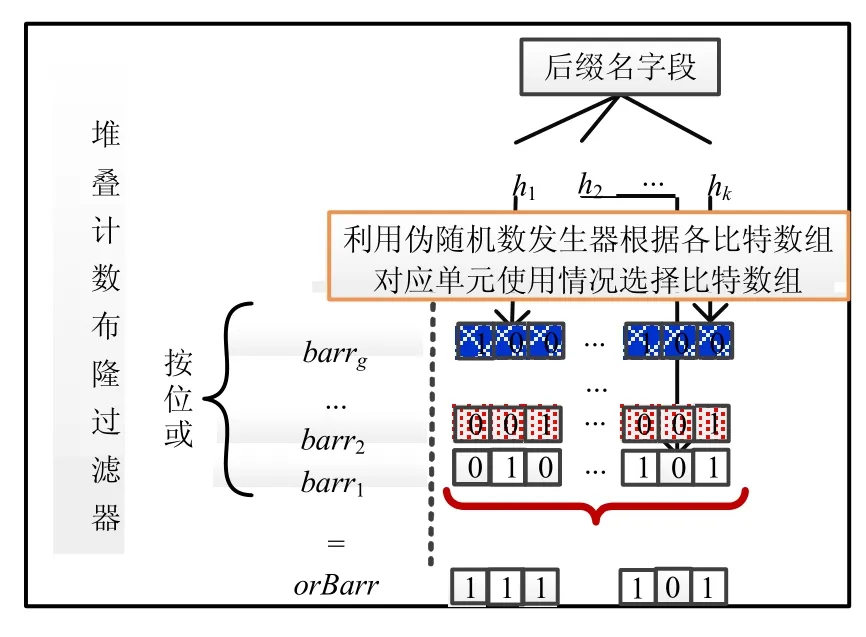
Fig.3 Framework of compounded counting Bloom flitter图3 堆叠计数布隆过滤器的结构
CCBF由g个比特数组(长度为m)和它们按位或的结果数组orBarr构成.其中,g的大小以能够满足计数需要为基准,本节后续将具体说明.orBarr是 CCBF的g个比特数组按位或的结果,用于提升 CCBF的查询效率.CCBF除了支持名字段的添加、删除和查询外,还支持多个CCBF的合并.下面对这些操作逐一加以说明.
(1)添加、删除和查询后缀名字段
CCBF在添加一个名字段nsg的过程中,针对k次哈希操作中的第j次哈希操作,利用伪随机数生成器,根据哈希结果对应位置单元(下标为hashj(nsg)的单元)已经被置1的比特数组的数量,随机选中g个比特数组中的一个比特数组barri(CCBF的第i个比特数组),将其下标为hashj(nsg)的单元置1.同时,如果为名字段nsg的k个哈希结果选择的比特数组满足:

则说明该名字段已经添加过,放弃本次添加.注意,本文采用的伪随机数发生器根据第hashj(nsg)个单元已经被置 1的比特数组的数量来选择下一个要使用的比特数组,具体操作就是针对各个单元随机生成一个数组标号的排列,并以这些排列为列构建矩阵,在产生伪随机数的过程中,以特定单元已经被置1的数组的数量加1为行号,查找特定单元对应的列上相应行中记录的数组标号,返回该标号代表的数组.因此,选中的比特数组对应的单元必然还没有被置 1.这样既避免了名字段的重复添加,又高效地实现了特定单元被置 1次数的计数,为删除名字段提供了前提.具体添加操作的计算过程如算法1所示.算法1中,利用伪随机数发生器随机选择比特数组,针对一个特定的哈希结果指向的单元,总能在g个比特数组中找到一个数组,其对应单元为0(证明见定理1),可以持续支持新数据的插入.
算法1.CCBF.add(nsg).
输入:nsg.//待压缩表示的后缀名字段


定理1.CCBF过滤器中包含g个比特数组,令这些比特数组第pj个单元被置为1的个数为cj,则cj大于等于g的概率可控,具有概率上界.
证明:令 CCBF能够插入的名字段的最大值为n,其相应的比特数组长度为m,哈希函数个数为k,比特数组数量为g,则g个比特数组的第pj个单元被置为1的数量cj大于等于g的概率为

根据斯特林公式化简可得:
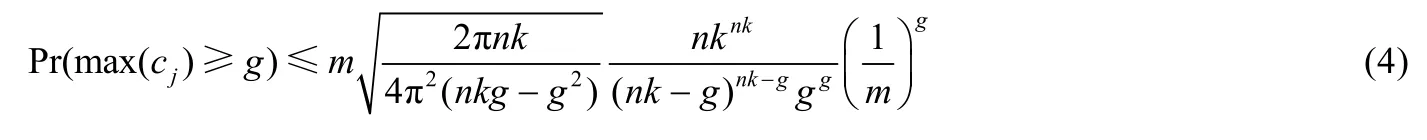
由文献[26]中的公式:

可知,在布隆过滤器的最优配置中,n×k与m成线性关系,因此,n×k远大于g,公式(4)中根号内的值小于 1.同时,对第2项放大,得到公式(3)的一个松弛上界:

将公式(5)代入可得:

为g个比特数组特定位pj被置为1的次数cj,得到g的概率上界. □
根据公式(7),当g为16时,CCBF任意一位全部被置1的概率为1.37×10-15×m,在通常网络应用中,这种情况不会出现,即当向包括16个比特数组的CCBF添加名字段时,总可以为k个哈希结果找到对应单元为0的比特数组,完成添加操作.
下面对添加操作的计算复杂度进行分析和比较.算法1共进行了k次哈希、k次随机数组选择及k次数组读写操作,最后将g个比特数组按位或得到更新后的orBarr,计算复杂度为O(k×H1+k×H2+k+m×g),其中,H1为布隆过滤器哈希过程的时间开销,H2为伪随机数生成器选择数组的时间开销,伪随机数生成器实际上就是在针对各单元的随机数组标号排列中查找一个元素,其计算复杂度远低于布隆过滤器的哈希函数,而比特数组按位或操作的复杂度m×g同样小于布隆过滤器的哈希函数的复杂度,因此,本算法的计算复杂度规约为O(k×H1).现有的计算布隆过滤器,包括CBF、SBF、dlCBF和MPCBF,添加新元素时直接查找并更新对应的计数单元,而本算法还要通过额外的伪随机生成器选择计数单元对应的比特数组,虽然计算复杂度均为O(k×H1),但算法1的计算开销将近似 2倍于上述 4类计数布隆过滤器的添加操作的计算开销.当然,鉴于现有布隆过滤器哈希函数的高效性[26],CCBF添加操作的总体计算开销仍较小,不会影响CCBF的应用.
布隆过滤器作为一种压缩表示机制,除了可以节省存储空间外,最关键的是可以提升后缀名字段存在性查询的效率.与添加和删除操作相比,后缀名字段(路由)查询是路由聚合机制中最常见的操作,为了优化聚合路由(CCBF的名字段)查询效率,我们在 CCBF中添加了一个记录 CCBF中g个比特数组按位或的结果的数组orBarr,在进行查询的过程中,无需逐一查看g个比特数组,判断哈希结果对应单元是否为 1,而是直接查看orBarr的对应单元是否为 1即可,具体查询操作如算法 2所示,查询操作的复杂度完全等价于基本布隆过滤器查询操作的复杂度,与CBF和MPCBF的查询过程类似,可以直接定位各个哈希函数对应的单元并进行查询,具有相同的计算复杂度.由于 SBF在查询过程中在通过哈希函数定位计数单元后仍需要通过索引最终找到这些计数单元,以完成查找,dlCBF需要在d个分区中逐一定位并查找各个哈希对应的单元,存在重复操作.因此,SBF、dlCBF查询效率低于CBF、MPCBF以及算法2.
算法2.CCBF.query(nsg).
输入:nsg.//待查询的后缀名字段

CCBF删除操作的计算过程类似于添加操作的计算过程,这里不再赘述,仅就其中的关键操作步骤进行说明.首先确认该名字段可以删除(类似算法 2的查找过程);然后,通过伪随机数生成器定位上一次添加操作中各个哈希函数操作的单元所在的比特数组,将这些比特数组对应单元清零,并更新orBarr,完成名字段删除操作.因此,CCBF删除操作的计算复杂度与添加操作类似,为O(k×H1).与其他计数布隆过滤器相比,CCBF的删除过程需要通过伪随机数发生器找到需要进行单元清零操作的比特数组,因此,删除操作的计算开销近似 2倍于其他计数布隆过滤器的删除操作的开销.
(2)合并操作
不同于其他现有计数布隆过滤器,CCBF支持合并操作,即将多个配置完全相同的CCBF合并为1个,以便应用于类似路由聚合这样需要归并已有名字段的场景.多个CCBF的合并操作相当于将这些CCBF压缩表示的名字段(添加的元素)合并,即等同于在一个CCBF中添加其他CCBF中压缩表示过的名字段.CCBF中的伪随机数发生器可以确保哈希结果对应单元置 1时选择的比特数组有固定的顺序,CCBF中添加后缀名字段(元素)的顺序不会影响各个比特数组的取值,详见定理2.因此,按照不同CCBF比特数组的标号,可以按顺序合并各个比特数组(按位或,与BF的合并操作相同),实现多个CCBF的合并.
当然,多个CCBF合并后压缩表示的名字段数量仍然受到其比特数组数量g和长度m的限制.以两个CCBF的合并过程为例,合并过程主要是将两个CCBF中的g个比特数组两两按位进行或操作,同时将两者的orBarr也按位或.具体如算法3所示.
算法3.CCBF.combine(other).
输入:other.//待合并的另外一个CCBF过滤器,两个CCBF的配置完全相同,且合并后的后缀数没用超过CCBF的容量n


其中,为了保证合并后不会超过CCBF的配置容量n,CCBF利用estSize函数估计当前已添加的名字段的数量(已添加名字段数量).CCBF每次添加1个名字段时会有k位被置1,因此可以利用g个比特数组中1的总数除以k,得到已经添加的名字段的数量,estSize函数的计算过程如公式(8)所示。

其中,g和k为CCBF配置的比特数组数量和哈希函数数量,比特数组的sum4ones函数可以计算它其中被置1的单元的数量.算法3的计算过程包括估计已添加名字段总数和合并比特数组两部分,其中,
· 估计已添加名字段的复杂度为Ο(m×g),其中,m为比特数组长度,g为比特数组数量(最大计数范围);
· 合并比特数组的复杂度也是Ο(m×g).
因此,算法3总的计算复杂度为Ο(m×g).注意,现有其他计数布隆过滤器均无法支持合并操作.
定理2.CCBF中添加元素的顺序不会影响CCBF中各个比特数组的取值.
证明:对于一组元素nsg1,…nsgi,…,nsgn,将其按顺序添加到一个 CCBF中.不失一般性,假设有两个名字段——nsgx和nsgy,其哈希结果命中了 CCBF的第j个单元,CCBF中的伪随机数发生器以确定顺序在barr1,…,barrg中选中两个比特数组,将其第j个单元置1.这一过程中,随机数发生器选中的下一个比特数组的依据是当前第j个单元被置1的比特数组的个数.因此,如果首先添加nsgx,第j个单元被置1的比特数组的个数为0,随机数发生器选中barr(1),将barr(1)[j]置 1.当添加nsgy时,选中barr(2),将barr(2)[j]置 1.同样,如果先添加nsgy,将对barr(1)[j]置1,然后添加nsgx时,将对barr(2)[j]置1.无论nsgx和nsgy的添加顺序如何,添加结果都是barr(1)[j]和barr(2)[j]被置1.对特定单元的多次加1操作的顺序不影响该单元使用,因此,CCBF中添加名字段的顺序不会影响CCBF中各个比特数组的取值. □
综上所述,堆叠计数布隆过滤器可以高效地完成名字段的添加、删除和查询,其计算复杂度基本与现有计数布隆过滤器等同,其中,路由过程中最为频繁的查询操作的效率优于或等同于其他计数布隆过滤器.同时,堆叠计数布隆过滤器 CCBF支持高效的多过滤器合并,为聚合路由后缀合并(及其他需要合并多个压缩表示的场景)奠定了基础.CCBF空间复杂度为Ο(m×g),与CBF的空间复杂度Ο(m×log2g)相比,使用的存储空间更多.同样地,与 dlCBF和 MPCBF相比也需要更多的存储空间(除 SBF使用的存储空间随添加元素增长外,dlCBF和MPCBF都在CBF的基础上优化了存储空间开销[29,30]),但是根据定理1,g的取值在实际应用中具有上界(通常情况下为 16),因此,CCBF空间复杂度可控,在当前网络设备存储空间不断扩大的背景下,完全可以应用于各类互联网应用场景.在假阳性率方面,CCBF中哈希函数定位数组单元的方式与BF和CBF相同,函数个数k和数组长度m的配置也与BF和CBF相同[26],因此,CCBF中添加一个元素时,k个哈希结果均发生碰撞的概率(假阳性率)与BF和CBF完全相同.虽然CCBF的假阳性率高于优化了假阳性率的SBF、dlCBF和MPCBF,但是路由聚合过程中,假阳性的出现只会增加冗余转发数量,不会引起转发错误,并非路由聚合过程中的首要因素,不会影响CCBF在聚合路由后缀压缩表示中的应用.
综上所述,CCBF的主要设计目标是实现多个CCBF的合并,以便支持路由聚合操作.在此基础上,CCBF优化了其查询效率,为构建高效的路由聚合机制提供了前提.在基于CCBF的后缀压缩表示的基础上,可以将指向同一接口的多条具有公共名字前缀的路由聚合为 1条聚合路由,用公共名字前缀和后缀压缩表示共同标识聚合路由(如图1所示),有效地避免了第2节中指出的仅采用路由名字前缀来标识路由时出现的路由错误,构建了准确、高效的路由标识.
3.3 基于路由可达性的动态名字路由聚合机制
在上述层次化名字聚合路由标识的基础上,本文利用路由可达性度量聚合路由可用性,并作为路由聚合条件,将多条稳定可达的具有公共名字前缀的路由(包括其他节点通告的路由)聚合为一条聚合路由;当可达性下降后,进行解聚合,还原被聚合路由,降低聚合程度,提升路由可达性;聚合和解聚合都需要通告周边邻居节点.按照这一动态聚合方式,本文构建了一套基于路由可达性的动态名字路由聚合机制.
本文之所以将路由可达性作为路由聚合的条件,其原因是聚合路由压缩表示了被聚合路由的名字后缀(或后缀压缩表示),将不可避免地在路由查找过程中引入假阳性,将没有聚合过的路由纳入聚合路由查找结果,进而在NDN网络中带来冗余的转发.由于NDN网络采用多路转发机制,因此假阳性引起的冗余转发不会影响正常的内容获取,仅仅会加大网络负载.当然,过大的网络负载同样会影响网络效率,甚至会抵消路由聚合后路由规模缩减带来的效率提升.如果假阳性问题引起的网络负载过大,将会进一步引起网络拥塞等问题,因此,我们需要最大程度地保证转发的正确性,同时,通过路由聚合减小路由规模,提升网络效率.其中,为了回滚聚合路由,需要在低速存储中备份被聚合路由,在减小路由节点高速内存空间的同时,实现了基于路由可达性的动态聚合过程.本文名字路由聚合记录如图4所示.
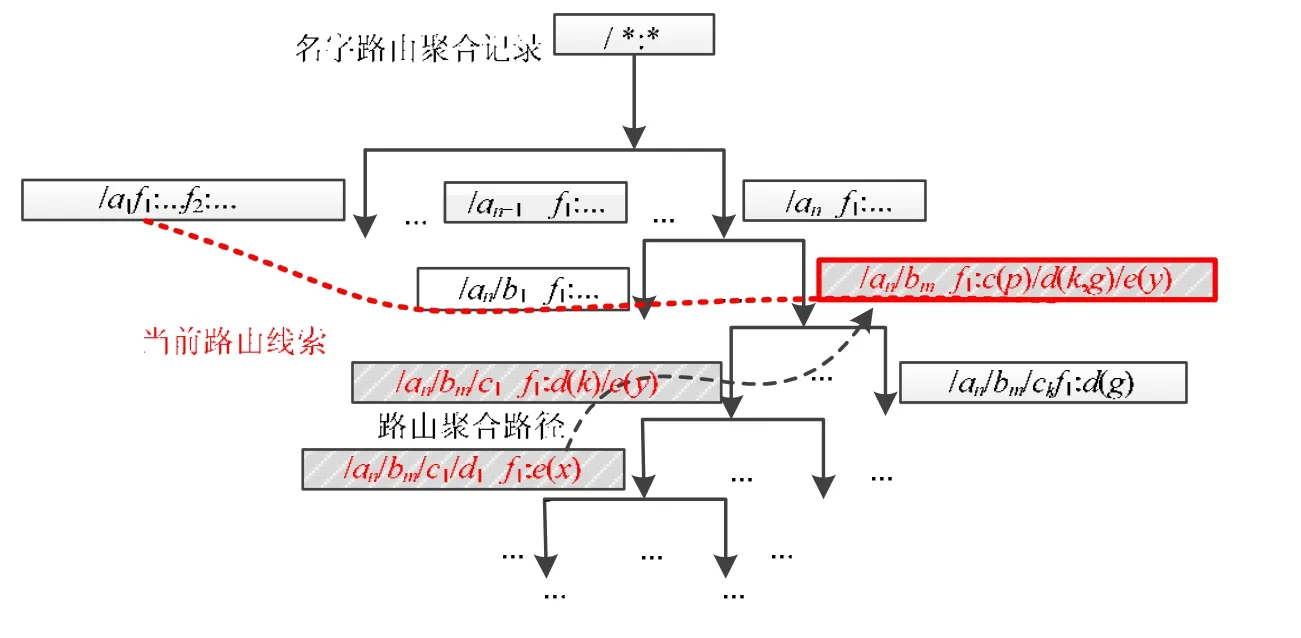
Fig.4 An example for dynamic route aggregation图4 动态路由聚合过程实例
NDN网络节点的不同接口可以获取不同内容,因此,本文的聚合机制在聚合相关路由的同时,保留了各个接口的独立记录.为每条聚合路由针对不同接口设置独立的后缀压缩表示单元和相应的可达性统计单元,形成聚合路由的标识二元组结构:〈路由前缀;转发接口信息〉,其中,转发接口信息中记录了接口ID、路由后缀压缩表示、转发延迟统计和可达性统计等状态信息(如图4所示).可达性统计为RP(faceID),其中,faceID为相应的接口ID.可达性统计值为最近转发出去的请求的响应比,代表路由可用性的统计结果,如公式(9)所示.

其中,n(t-1)为t-1时刻总共发出的内容请求包数量,ns(t)为t时刻收到的内容响应包数量.其中,通过卷积运算淘汰旧的统计信息,提升当前请求响应情况在统计结果中的比重.针对接口faceID,RP(faceID)准确地反映了依据聚合路由从该接口转发请求、获取内容的可能性,可以作为评估聚合路由可用性的标准.根据文献[31]中的相关定理,当节点间连通概率大于等于lg(N)/N时(N为网络节点数),网络为强连通网络.因此,我们可以将这一条件作为判断路由可达性的阈值,如果所有RP(faceID)都大于lg(N)/N,则可以获取分布在任意网络节点上的内容.
当一组具有公共前缀的聚合路由在所有接口上的可达性都达到了阈值,且持续了从某个时刻t起的两个时刻时,则这些路由被认为是稳定的路由,可以和其他具有公共前缀的稳定路由一同进一步聚合新的聚合路由.这种延迟决策机制可以避免聚合过程中的抖动现象(频繁重复聚合和解聚合的循环).同样地,聚合路由两个时刻内持续不可用,则需要将其分解为之前被聚合的路由,以提升路由准确性,改善路由可达情况.为了支撑聚合路由回滚,需要在各个节点保留如图4所示的线索树结构,在聚合路由的同时保留被聚合路由信息,以便更新和回滚聚合路由.其中,当前路由线索是当前使用的聚合路由的线索,当需要更新和回滚路由时,可以快速找到相应的聚合路由,并回滚或更新相关被聚合路由.本文的动态聚合机制可以在保证路由可用性的前提下最大程度地聚合路由,缩小全网路由规模,提升层次化名字路由效率.
4 实验评估
4.1 方案部署与实现
我们在NDN网络的仿真平台ndnSIM[32]的基础上实现了本文针对层次化名字路由的聚合机制.
· 首先,我们对ndnSIM的FIB模块进行了修改.现有的ndnSIM中,每条路由包含路由名字前缀和转发接口信息.基于本文动态路由聚合机制,我们在转发接口信息中添加了后缀压缩表示 C和可达性统计RP(见公式(9)).RP中的统计值n(t-1)是在查表转发请求时计数,而nr(t)是下一个时刻收到的内容包的数量.根据不同的预定容量n,用于压缩表示后缀名字段的CCBF按布隆过滤器最优配置设置比特数组长度m及哈希函数个数k[26],同时,根据本文第3.2节的分析,比特数组数量被设置为16.在此基础上,FIB模块周期性更新 RP,根据更新过的 RP分析现有路由的可用性,将持续可用的路由进行进一步聚合,得到新的聚合路由,并周期性地通告周边节点.同时更新在低速外部存储中的记录路由聚合过程的数据结构(如图4所示),以备聚合路由回滚时还原其中备份的路由信息.
· 其次,我们修改了转发模块ndn-forwarding-strategy.实现了基于名字前缀和后缀压缩表示的转发机制.
仿真平台在本地计算机上部署,其配置如下:Ubuntu 13.04,内核版本 3.8.8,Intel Core i7 3.4G CPU,DDR3 1866 16G内存,1TB硬盘.为了保证仿真结果真实、可靠,我们采用了一个真实的网络拓扑——欧洲EBONE网络拓扑[33],包括279个节点、731条边,其中包括65个边界网关节点、45个网关节点和169个边缘路由节点.在边缘节点中,我们随机选择了10个节点作为内容发布节点producer,实验中请求的各类内容全部由这10个节点发布.另外,选择了 30个节点作为内容请求方 consumer,内容请求服从参数α为 0.6的 Zipf-Mandelbrot分布,即被请求的多数内容为热门内容,其他内容很少被请求.为了全面验证本文路由聚合机制的有效性,实验中使用了多个不同规模的数量集,这些数据集的具体信息见表1.

Table 1 Datasets表1 数据集
在此基础上,通过对这些数据进行组合,我们可以得到各种规模的名字数据集.在其基础上,我们对本文路由聚合机制的有效性进行了全面的评估.首先比较了路由聚合前后的路由表规模;其次,通过与 NDN原生路由查表机制以及利用CBF压缩路由表的对比方案比较,给出了路由聚合前后的路由查表效率的比较;最后,通过对比分析了本文路由聚合机制带来的假阳性问题.
4.2 聚合前后路由表规模对比分析
路由聚合的目标是减少路由条目数量,从而提升路由查表效率,进而优化网络传输效率.同时,路由条目的减少还会减少路由设备内存的使用,降低 NDN网络部署成本.为了验证本文路由聚合机制的聚合效果,我们在数据集Alexa top 1M上比较了各个路由节点在同一时刻采用聚合后的路由条目数量和不采用聚合的情况下路由条目数量的比值R,在2 000s内对279个路由器每隔6s记录一次R值,仿真结果如图5所示.
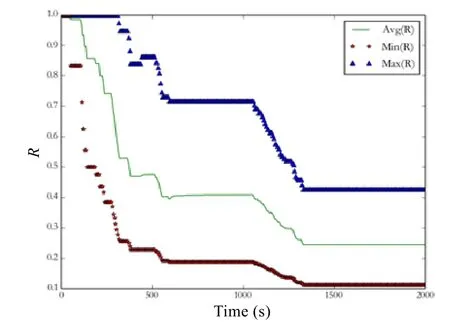
Fig.5 Effection on FIB size reduction of route aggregation图5 路由聚合对路由表规模的影响
仿真过程中,随着时间Time的推移,路由聚合程度不断提升,路由规模不断缩小,在1 400s附近,全网路由聚合达到稳定状态.全部 279个节点中,在全网路由聚合完成后,路由条目数量至少压缩了 60%,平均压缩了75.47%,路由聚合对路由规模的缩减效果明显.注意,由于现有数据集中多数名字(URL)只有 2级,如果应用于实际部署的NDN网络中,路由名字层次变化更多,路由聚合效果也会更为显著.
4.3 聚合路由效率分析
作为影响网络传输效果的关键因素,路由查表效率直接影响网络数据包转发延时.路由聚合主要通过减少路由条目数量(路由表规模)来提升路由查表效率,进而缩小网络数据包转发延时.利用本文路由聚合机制,可以将多条具有公共前缀的层次化名字路由聚合为单条聚合路由,并利用这些路由的公共名字前缀和后缀压缩表示来共同标识该聚合路由.因此,与未进行聚合的层次化名字路由相比,本文的路由聚合机制在缩短名字前缀查找时间的同时,也引入了路由后缀的查找过程.为了验证本文聚合过程对路由查表时间的影响,我们首先针对不同规模Ns的名字路由(1万、10万和100万)进行路由聚合,并比较聚合前后各路由的查表时间总和LTime.实验结果如图6(a)所示,圆形点线代表未聚合路由查表时间总和,方形点线为本文聚合路由查表时间总和.可以看出,未被聚合的路由的查表时间与路由规模成正比例关系,随着路由规模Ns的增长线性增加;而聚合后路由查找基本不受路由规模增长的影响,仅表现出1s的差异,如图6(a)所示.究其原因,主要是由于聚合后减小了前缀数量及前缀查找时间;同时,本文在后缀压缩表示查询方面的优化(为CCBF添加16个比特数组按位或得到的归并结果orBarr)也避免了大量后缀查询时延的引入.
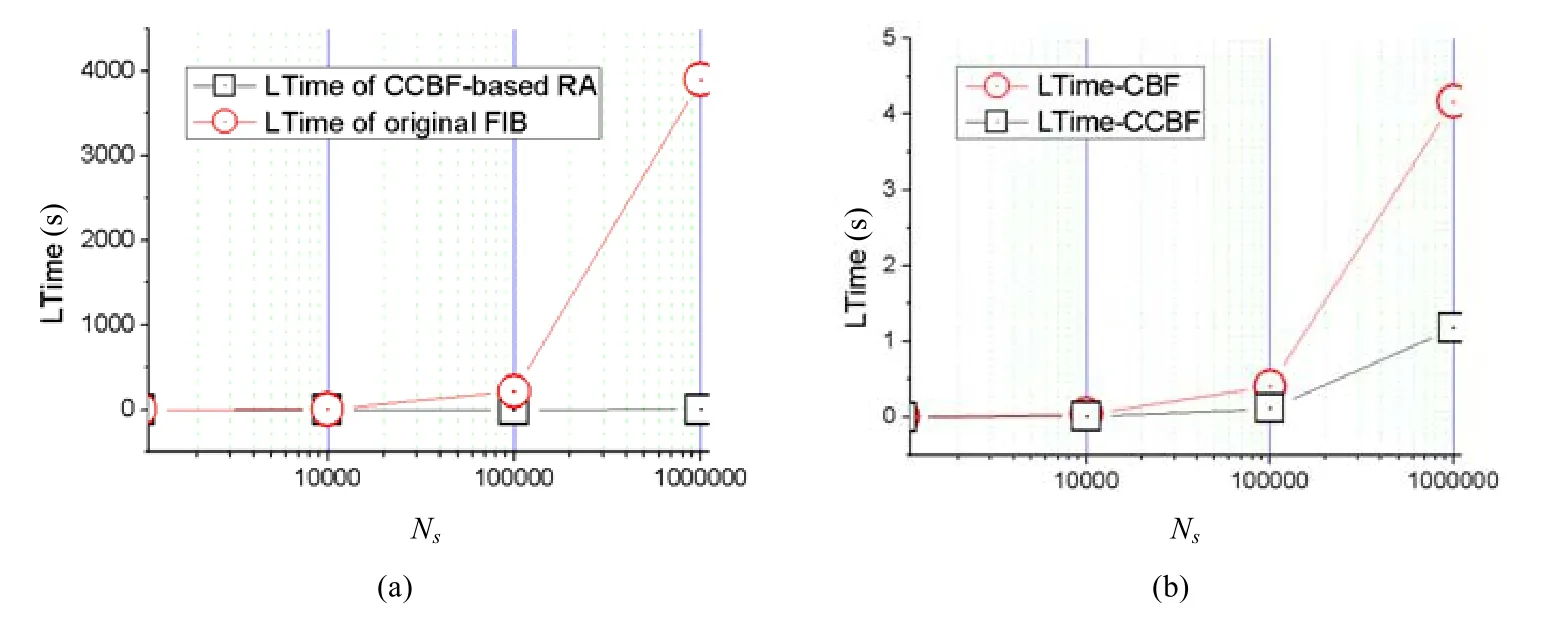
Fig.6 Comparison of route lookup time图6 路由查找效率对比
为了进一步验证本文路由聚合机制的查表效率,我们在 CBF的基础上构建了一套路由压缩机制作为对比方案,采用与本文的聚合路由相同的前缀和CBF压缩表示的路由后缀共同标识压缩后的路由.压缩后的路由规模与本文路由聚合后的路由规模相同,通过这一方式对比验证本文聚合路由查表效率.如图6(b)所示,方形点线为CBF的查询时间LTime-CBF,圆形点线为本文CCBF的查询时间LTime-CCBF.在不同规模的路由表上,本文方案的查表时间始终只有对比方案的一半,本文建立在orBarr上的查询过程的效率要优于CBF的查询效率.
同时,我们对比了聚合前后路由更新效率(如图7所示),路由更新时间等于所有路由的查找、删除和添加操作的总和,用UpTime代表.图7(a)中,圆形点线为未聚合路由总更新时间,方形点线为本文方案路由总更新时间.未聚合路由的整体更新时间都随路由规模Ns的增长呈线性增长,本文路由聚合机制的更新时间增加较慢,路由规模对路由更新效率的影响同样存在.为了进一步评估本文机制的路由更新效率,图7(b)中,我们对比了本文机制的路由更新时间和基于CBF的对比方案的路由更新时间.圆形点线为本文机制的总路由更新时间,方形点线为对比方案的总路由更新时间.两个方案的总路由更新时间都随路由规模Ns的增长呈线性增长,本文路由更新时间略小于对比方案路由更新时间的 2倍,虽然与路由查表时间相比,本文的路由聚合机制的路由更新时间较长,但路由更新不是网络路由转发过程中最关键的操作,操作频率较低,且独立处理,基本不影响路由查表过程.
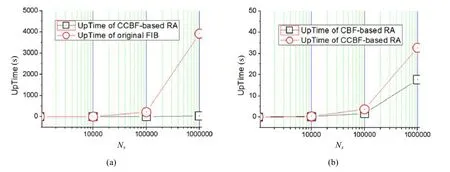
Fig.7 Comparison of route updating time图7 路由更新时间对比
4.4 假阳性分析
本文的聚合标识在使用路由名字前缀的同时,还引入了基于CCBF的后缀压缩表示.CCBF本身可能会在查询过程中引入假阳性,即查询到未被压缩表示过的名字段.假阳性在路由聚合问题的背景下,将会引发路由查询的假阳性误判,将数据包发往没有通告过相关路由的接口.注意,假阳性不会影响数据包从通告过该路由的接口正常转发,仅仅是增加了冗余的路由转发.本节实验验证了本文后缀压缩表示所采用的 CCBF布隆过滤器的假阳性情况,并与基于CBF的对比方案的假阳性进行了对比.在布隆过滤器的配置过程中,本文为各个过滤器设定的最大假阳性率均为0.01.图8中,菱形点线为CCBF在不同规模数据集下的查询假阳性数Fp-CCBF,方形点线为对比方案在不同规模数据集下的查询假阳性数 FP-CBF.两种布隆过滤器在不同规模的数据集上的假阳性值相同.
为了进一步分析假阳性的出现情况,分析两种方案在不同的添加比例Rfill下的假阳性变化情况,本文针对3种不同规模的数据集(1万、10万和100万)进行了实验.其中,Rfill=nc/n,n为布隆过滤器容量(分别取1万、10万和100万),nc为添加到布隆过滤器的名字段数量.如图9所示,在不同规模的数据集下,两种方案的假阳性查询数量在Rfill达到0.85后出现了假阳性查询,并在Rfill到达1时达到最大值,两种方案的假阳性查询数量始终保持相同.本文方案在查询假阳性方面等同于基于计数布隆过滤器CBF的对比方案,没有带来额外的假阳性查询.
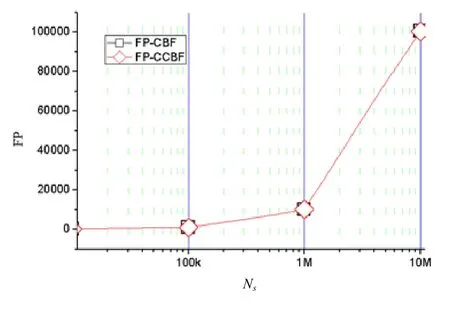
Fig.8 False positive under datasets with different size图8 不同规模数据集下的假阳性
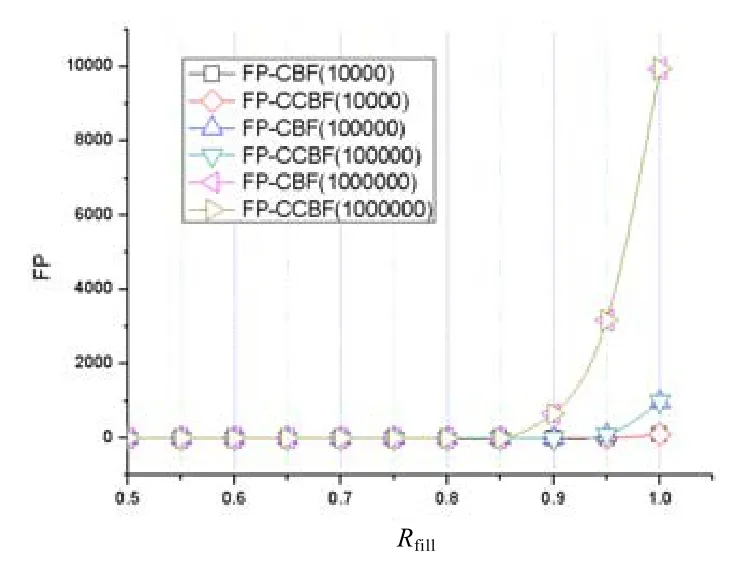
Fig.9 False positive with differentRfill图9 不同Rfill下的假阳性
5 结 论
为了实现针对层次化名字路由的聚合机制,进而优化NDN等信息中心网络的传输效率,本文首先分析了层次化名字路由的聚合问题,明确了路由聚合过程中需要同时利用路由名字前缀和后缀压缩表示来共同标识聚合后的路由.为了实现对名字后缀的压缩标识,同时在路由聚合过程中通告和进一步聚合(合并)这些后缀压缩标识,本文提出了一种全新的计数布隆过滤器 CCBF.CCBF在支持多过滤器合并的同时,还优化了查询效率.在此基础上,本文进一步提出了面向路由可达性的动态路由聚合机制,在保证路由可达性的前提下最大化聚合路由.我们在真实网络拓扑及数据集上构建了实验环境,验证了本文路由聚合机制的有效性,本文路由聚合机制通过有效聚合路由,以较小的冗余路由转发(假阳性路由查询)为代价,减小了路由规模,优化了网络传输效率,为NDN等信息中心网络投入实际应用提供了前提.
本文的路由聚合程度由路由可达性动态决定.作为影响可达性的关键因素,如果能够有效地降低 CCBF的假阳性查询结果,则不但可以避免过多的冗余转发,而且可以提升路由可达性,进一步提升路由聚合程度,减少路由条目数量.为此,在下一步的研究工作中,应该将综合分析现有计数布隆过滤器的优化思路,降低堆叠计数布隆过滤器的查询假阳性,进一步改进路由后缀压缩表示机制及相应的路由聚合过程.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:57:30
文萃报·周二版(2020年32期)2020-09-02 07:25:38
铁道通信信号(2016年1期)2016-06-01 12:10:17
现代语文(2016年21期)2016-05-25 13:13:35
意林(绘英语)(2016年5期)2016-04-09 10:55:20
辽金历史与考古(2016年0期)2016-02-02 01:34:10
电子与信息学报(2015年2期)2015-07-18 12:04:47
中国舰船研究(2015年2期)2015-02-10 06:45:44
航天返回与遥感(2014年5期)2014-07-31 17:57:09
