
VANET中流调度与路径选择联合优化的传输策略∗
2019-03-05 03:45:34陈晓江尹小燕贾茹昭汤战勇房鼎益
软件学报 2019年2期
强 敏,陈晓江,尹小燕,贾茹昭,徐 丹,汤战勇,房鼎益
(西北大学 信息科学与技术学院,陕西 西安 710069)
目前,车载自组网(vehicular ad-hoc network,简称 VANET)已经获得世界各国研究机构与科研工作者的关注.VANET中,车辆节点与路边设施的强大存储与计算能力、良好的无线通信能力以及不间断的能量供应,因而可以检测车辆行驶环境的变化,评测危险路况并预警,如前方事故现场预警、交叉路口防碰撞预警等,预估司机的反应时间,为安全驾驶及驾驶体验提供技术支持[1-3].车辆节点配备的传感器负责采集环境数据与交通状况数据,借助路边设施或其他车辆节点,采集的数据被实时地传输到云计算中心.云计算中心经过数据挖掘、大数据处理等计算技术对信息进行综合分析、处理,从而实现智能化的交通信息管理,为智能交通系统的发展提供保障[4-6].VANET中动态产生的数据量与车辆的密集程度息息相关.众所周知,数据乃 VANET各类应用的前提与基础,数据应在尽可能短的时间内可靠地传输到控制中心.因此,数据传输成为 VANET中亟待研究的重要问题之一.
VANET是移动自组织网络在道路上的应用,具有高密度节点分布、车辆节点高速移动等特点,因而VANET中数据传输面临无线信道质量不稳定、网络拓扑瞬息万变、无线链路寿命短、带宽受限、通信负载量大等多重挑战.同时,VANET中异质数据有不同的传输需求.研究结果表明,若在发生碰撞前的 0.5s内对驾驶者发出警告,则60%的交通事故可以避免[7].该类数据对时延敏感,需要在严格的时间限制内被传输到云计算中心,本文称其为强实时数据;另一方面,为提升驾驶体验的PM2.5,CO2含量数据与音频视频数据[8-11]对时延不敏感,对可靠性要求高,本文称其为弱实时数据.利用 VANET的有限资源,在满足其传输需求的前提下将两类数据传输到云计算中心,是本文的研究重点.
VANET中,强实时数据和弱实时数据共存,形成了混合数据.本文为强实时数据和弱实时数据设置了不同的优先级别,在传输时提供区分服务.现存的 VANET传输协议,如专用短距离通信(dedicated short range communications,简称 DSRC)协议,能够提供基于优先级的数据服务.DSRC中,高优先级的强实时数据流侵占了全部网络带宽,能够将高优先级的数据尽快传输到云计算中心,但低优先级的弱实时数据流则被阻塞,致使驾驶体验降低[12-14].因此,受经济学理论的启发,考虑存储成本、丢包惩罚与传输奖励,本文首先提出了面向 VANET的混合流调度策略,为不同优先级的数据流分配传输资源,最大化车辆节点的收益;结合链路状况,随后提出了VANET中混合流调度与路径选择联合优化的数据传输策略,满足强实时数据流对传输时延的需求,同时提高弱实时数据流的传输可靠性.
1 混合流调度及研究现状
迄今,面向VANET的混合流调度策略均基于传统网络的传输协议,如专用短距离通信协议DSRC.DSRC为VANET中车与车(vehicle to vehicle,简称V2V)、车与路边单元(vehicle to roadside unit,简称V2R)间的通信提供支持[15],基于增强的分布式信道访问(enhanced distributed channel access,简称EDCA)机制,为VANET应用中的混合流提供调度策略,为 VANET的数据传输提供服务质量(quality of service,简称 QoS)保障[12].EDCA为VANET数据赋予不同的优先级,并设计相应的混合流调度策略.对于车辆发生碰撞时产生的危急预警、车辆的实时速度、方向等强实时数据,EDCA赋予其最高优先级别,使其可抢占信道而优先发送;对于环境信息、娱乐信息等弱实时数据,EDCA赋予其较低优先级别,将其暂存在车辆缓冲区,在高优先级数据全部成功传输之后,再对其进行发送.DSRC中,EDCA采用8种不同的优先级别,对应4种不同的访问类别.优先级别与访问类别间的对应关系见表1[16].
表1中的每个访问类别(access categories,简称AC)对应一个队列,不同的EDCA参数对应不同的优先级别.除了用户的优先级别和访问类别外,EDCA再引入虚拟竞争机制,以解决AC队列的冲突问题.根据表1的对应关系,AC队列将来自应用层不同用户优先级的数据转发到相应的AC队列中,高优先级的AC队列和低优先级的AC队列发送时机取决于各自的退避计数器.当两个AC队列的退避计数器数值都减到0时,两个AC队列同时发送数据,引发冲突.冲突发生时,虚拟竞争机制先发送高优先级别的数据,缓存低优先级数据,高优先级别的数据成功发送之后,再发送低优先级别的数据.但是 VANET中,强实时数据的通信负载量大且不可预期,实施调度时易导致弱实时数据流“饿死”,从而导致驾驶体验降低.

Table 1 Relationship between priority levels and access categories表1 EDCA中优先级别与访问类别的对应关系
面向队列的调度方案中,基于轮询的调度算法尤为经典.其基本思想是:首先调度具有最高优先级别的非空队列中的分组,然后转向次优先级别的非空队列,直到对每个非空队列都调度一遍之后,再次调度最高优先级别的非空队列.如此循环往复.常用的基于轮询的调度算法有轮询(round robin,简称RR)、加权轮询(weighted round robin,简称 WRR)等.基于既定规则,RR[17]调度算法首先将到达服务器的数据分组分配至相应队列,然后对每个非空队列依次进行访问,直到所有队列都被访问一遍后再次循环进行.RR算法每次仅服务1个分组,如此能够保证带宽资源的共享.但 RR算法的调度单位为分组,数据分组的大小不同将导致带宽资源分配不均,且不能预测传输时延,无法为强实时数据提供时延保障.WRR[18]是RR算法的扩展,遵循一定的分配比例.WRR为不同权值的队列提供相应服务.WRR可以有效地避免“饥饿”现象的出现,但可变尺寸的分组将导致不公平的资源分配.
基于GPS(general processing sharing)的调度算法[19]立足于协商,即数据流提前向GPS预约资源,一旦预约成功,用户则获得事先协商的业务保证.基于GPS的调度算法中,比特为最小的调度单元.基于GPS的调度算法规定,所有的调度队列优先级别相同,因而能够确保所有队列分配到相同的服务资源,在保证公平性的同时,端到端的时延也能得到保障.但基于GPS的调度算法目前是相对理想化的模型,不能投入使用[20].
基于优先级的调度算法 PQ(priority queuing)[21,22]中,每个队列的调度与其优先级别密切相关.调度算法先对高优先级队列中的分组进行服务,直到全部高优先级别的数据分组均被处理后,相对较低优先级队列中的分组才能得到调度.同一队列遵循先来先服务的准则.因此,PQ能够为高优先级别的数据提供QoS保障.PQ在对低优先级队列中的分组进行调度时,若有高优先级队列中的分组到达,PQ则立即转去服务高优先级队列中新到达的分组,导致低优先级队列中的分组得不到处理而被“饿死”.本文基于主流队列调度算法,考虑存储成本、丢包惩罚与传输奖励,结合链路状况对 VANET中的混合流进行实时调度,为强实时数据流与弱实时数据流分配传输资源,防止弱实时数据流被“饿死”.
2 路径选择及研究现状
目前,面向移动自组网的路径选择算法主要包括平面数据传输协议、基于位置的数据传输协议以及层次传输协议这3类.
基于位置的传输协议,其前提是网络中每个节点的位置已知,节点选择最近的邻居节点作为转发节点.VANET中,由于车辆节点携带全球定位系统,易于获取位置信息,因此,基于位置的传输协议为 VANET的主流路由协议;层次数据传输协议按照不同归类基准,将节点划分为不同大小的簇,由簇头对簇内节点进行统一管理,数据包分簇发送;平面数据传输协议则由每个节点采取主动或者被动的方式建立路由表,实施数据传输.GPSR(greedy perimeter stateless routing)[23]是一种典型的基于位置的数据传输协议,其选择转发节点的依据为边界转发和贪婪转发.GPSR的优点在于节点仅需维护邻居节点的状态信息,对于动态变化的拓扑结构具有更好的适应性.原因在于,当节点需要路由时,以距离为基准,GPSR探测其邻居节点的状态,选择距目的节点最近的邻居节点作为下一跳节点,实现数据转发.鉴于车辆节点的位置已知,GPSR在VANET中有明显优势.但VANET中车辆节点分布不均,源节点与目的节点的最短路径上不一定存在可用车辆节点.由于缺少中心设备的支持,GPSR难以避免将数据传输至车辆稀疏区域,从而使数据仅能通过车辆携带的方式传递至下一跳,甚至是目的节点,将导致数据包的传播时延成倍增加.
DSDV(destination sequenced distance vector routing)[24]为典型的平面数据传输协议,网络中的每个节点均可与其他节点建立一条传输路径,节点定期地广播自己的状态,邻居节点获取广播消息,以此更新路由表.路由表中包含所有可到达的节点以及跳步数,节点在发送/转发数据时,优先选择最小跳步数的路径.DSDV适用于节点数较少且移动不频繁的情形,可快速检测出异常链路并有效避免.但当网络中的节点数目增加且移动速度较快时,DSDV的路由表建立时间增加,周期性的全网链路状态广播也将给网络负载带来巨大压力.
CGS(cluster-gateway selection)[25]为典型的层次数据传输协议,采用分簇思想,簇头管理簇内移动节点,普通节点一跳将信息传递至簇头,然后,簇头再利用网关将信息传递到目的节点所在的簇.网关指多个簇共同拥有的节点,即网关同属多个簇,其主要作用是在簇之间传递信息.与 DSDV相比,CGS的优点在于路由表的简化,路由表更新带来的开销也随之降低.但VANET中网络拓扑结构动态变化,无线链路寿命短,簇的维系异常困难,簇头的失效将引起CGS算法的失效.
鉴于VANET中无线信道质量不稳定、网络拓扑瞬息万变、无线链路寿命短、带宽受限等特点,移动自组网中现行的路径选择算法不能直接适用于 VANET.因此,本文提出了混合流调度与路径选择联合优化的思想,为强实时数据流提供时延保证,为弱实时数据流提供可靠性保证.
3 面向VANET的混合流调度
VANET中,车辆节点采集环境数据、路况信息等多模态数据,基于数据对传输 QoS的不同需求,分为强实时数据流与弱实时数据流,强实时数据流具有更高的优先级别.本文关注如何利用 VANET受限的带宽资源将强实时数据流实时地传输到云计算中心,同时保证弱实时数据流的可靠传输.
3.1 问题描述
我们假设VANET中:(1)所有车辆节点均安装有车载单元(on board unit,简称OBU)模块;(2)车辆在进行数据传输时,数据包不会丢失;(3)数据包在传输过程中不会发生损耗;(4)路边单元(road side unit,简称RSU)与基础设备间数据交换的时间可忽略不计;(5)链路带宽相同,用B表示.
VANET中,车辆节点被称为目标车辆,RSU规则部署于道路边,RSU都通过大容量电缆被直连到云计算中心.目标车辆的 OBU 模块采集车辆本身移动参数,比如速度和移动方向以及位置信息等,采集到的此类信息被统称为 Traffic数据包.同时,OBU模块也采集车辆所处周围环境的 CO2含量、PM2.5值等,此类信息被称为Environment数据包.OBU模块中配备的无线收发器充当VANET中发送者以及接收者的角色,既能将目标车辆缓冲区中的数据包发送出去,同时也能接收发送给目标车辆的数据包.
目标车辆首先将采集到的所有Traffic数据包和Environment数据包存放在自己的缓冲区,力求将其发送至云计算中心.车辆节点首先搜索离它最近的 RSU,若搜索到可用的 RSU,则将缓冲区的数据直接传给 RSU,RSU再将其转发给云计算中心;若车辆节点的通信半径内无可用 RSU,则借助于邻近的车辆节点,采用多跳的方式,将数据发至RSU,最终将数据发送至云计算中心,如图1所示.
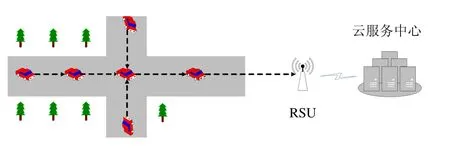
Fig.1 System architecture of a VANET图1 VANET系统架构图
本文中,我们只讨论数据从车辆节点流向云计算中心的情形.云计算中心对接收到的海量数据进行处理、分析,实现各种个性化VANET服务.
所有车辆持续地收集Traffic数据和Environment数据,相对于Environment数据,Traffic数据具有较高优先级别,数据产生后立即进入相应的缓冲区队列.而缓冲区队列长度亦有限制.为了避免队列溢出,应尽快将队列中的数据发送出去,但受限的VANET带宽不可能为所有数据提供实时服务.因此,需权衡VANET的通信资源与数据的传输需求,为两种数据流分配合理的通信资源,最大化系统性能.
3.2 系统建模
在时刻t0,目标车辆VA收集到的实时路况数据和道路环境数据分别对应Traffic和Environment数据,设产生Traffic数据包的数目为Af,Environment 数据包的数目为Ae.车辆节点的Traffic队列中已存在数据包的数目为Souf,目标车辆Environment队列中已存在的数据包数目为Soue.VA将收集到的两种数据包分别存放至相应缓冲区队列,Traffic缓冲区的队列长度为Qf,Environment队列的缓冲区队列长度为Qe.VA每发送一个Traffic包就得到奖励βf,Traffic包属强实时数据,每个Traffic包都携带deadline信息,除给予每个Traffic包基准奖励外,系统还根据实际完成时间与deadline的关系,给予额外奖励.VA每发送一个Environment包将得到奖励βe,鉴于Traffic包的优先级高于Environment包,设βf>βe.VA将尽力将所有Traffic包和Environment包发送至云计算中心.同时,缓冲区大小有一定限制,若缓冲区溢出,则溢出的包视为被丢弃.引入惩罚函数,计算缓冲区溢出带来的危害,Traffic包的惩罚因子为γf,Environment数据包的惩罚因子为γe,惩罚因子的设置如公式(1)所示.

为了最大化自己的收益,VA应尽快将数据包发送出去,应优先发送 Traffic包.数据包在缓冲区队列中存放,将占用存储空间,导致相应的存储成本.Traffic包的大小为af,Environment包的大小为ae,单位数据的存储成本记为c.xf表示VA在特定时间段内发送的Traffic包数量,xe表示VA发送的Environment包数量,t为Traffic数据包发送时刻.于是,VA的收益可如下计算.
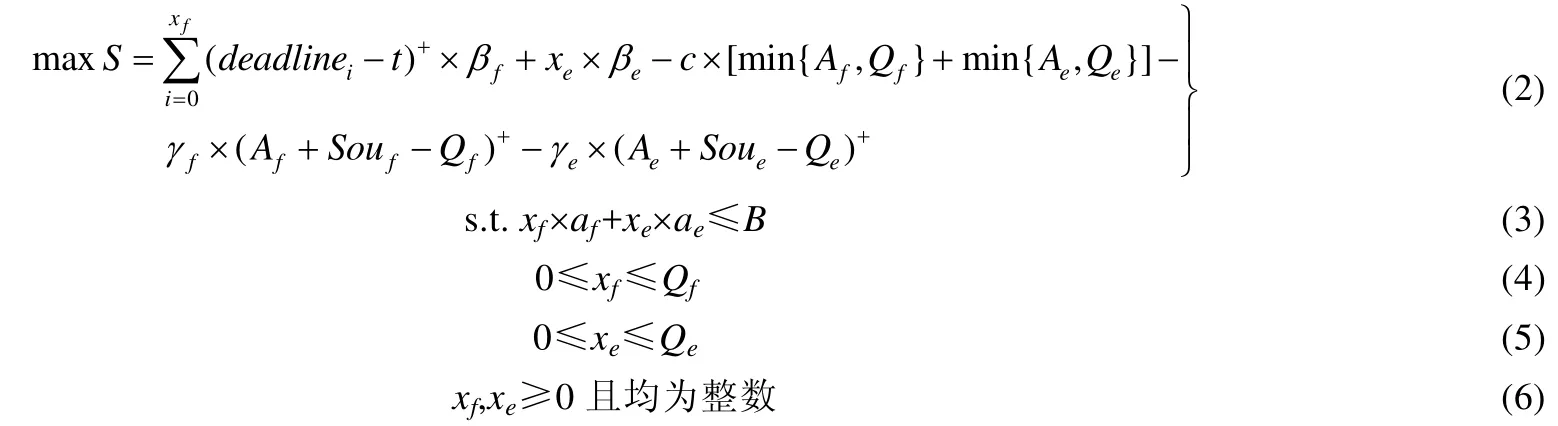
该目标函数记为 V_MFS模型.其中,公式(2)表示目标函数,公式(3)为带宽约束,公式(4)为 Traffic包的缓冲区约束,公式(5)为 Environment包的缓冲区约束,公式(6)为决策变量约束.系统给予VA的奖励,包括发送 Traffic包奖励与Environment奖励之和.因此,VA获得的总奖励为

VA缓冲区中的每一个Traffic或Environment包都会占据相应的缓存空间,因此,这两类数据包对应的存储成本为

缓冲区溢出而引发的惩罚为

若VA中采集的数据包个数超过相应的缓冲区大小时,惩罚则会启动,(Af+Souf-Qf)+表示若前者大于后者时,则溢出的包数目为Af+Souf-Qf;若相反,则值为0,即前者小于后者,意味着缓冲区未溢出,则惩罚为0.Environment包的惩罚机制与Traffic包类似.
3.3 问题证明
V_MFS模型所描述的问题是典型的NP-hard问题.
证明:V_MFS模型中主要包括两部分:第1部分为目标函数S的表达式,第2部分为其约束条件,共有4个线性约束条件,xf与xe为该模型的决策变量,xf表示的是在最大化目标车辆收益时应发送的Traffic包数目,xe则为应发送的Environment包数目.显而易见,xf与xe的取值均为自然数,即决策变量的取值只能是整数.因此,本文的V_MFS模型与整数规划问题(integer programming,简称IP)一一对应.整数规划的规范形式为

V_MFS模型可表示为
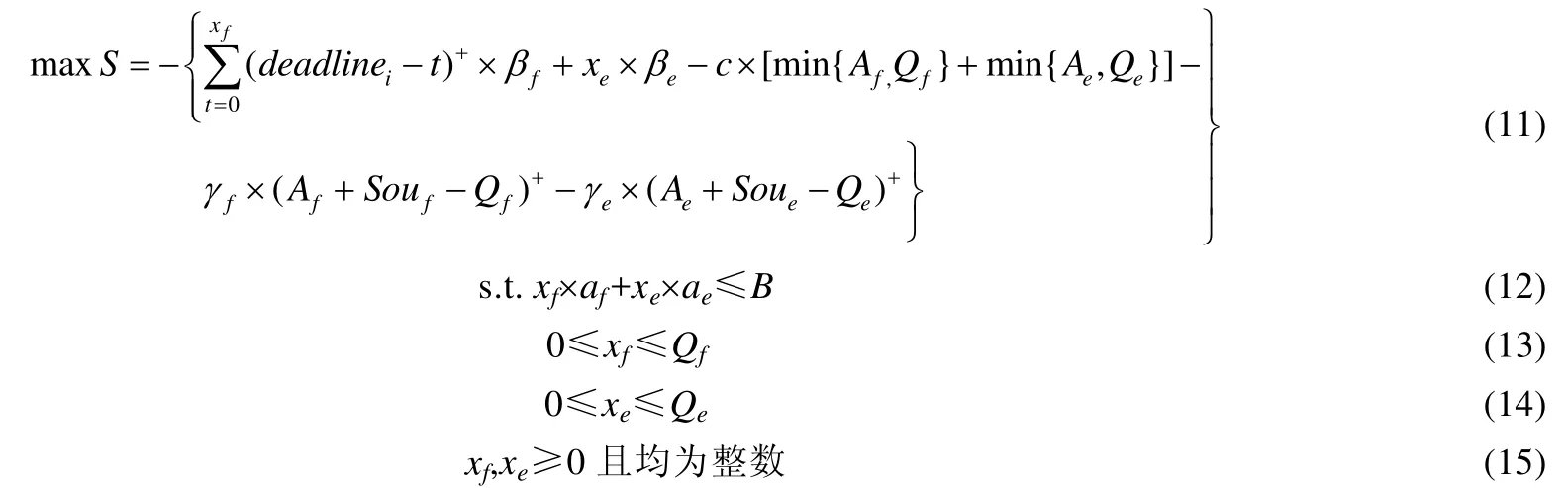
因此,本文的V_MFS模型属于典型的整数规划问题.
整数规划问题已被证明为NP-hard问题[24],因而本文的V_MFS模型也是NP-hard问题. □
3.4 算法设计
目标车辆VA的缓冲区中分别存放Af个Traffic包以及Ae个Environment包,其缓冲区大小分别为Qf和Qe.目标车辆VA每发送一个Traffic包i,则收到奖励(deadlinei-t)+×βf,每发送一个Environment包,则会收到奖励βe.数据包在缓冲区的存放,对应存储成本,若目标车辆收集到的数据包个数大于缓冲区能够接受的最大长度时,惩罚将被启动.目标车辆的收益见公式(2),为了最大化目标车辆VA的收益,即S取最大值.问题的求解思路是:充分利用有限的通信资源,为Traffic数据流与Environment数据流分配最佳带宽,最大化车辆节点的收益.
借鉴 0-1背包问题的思路,对目标函数求解.0-1背包问题描述如下:现有一组物品,每个物品的价值和重量均已知,对于给定的背包,背包重量有限制,在背包容量限定的范围内选择物品,使得背包的总价值最大.对于每个物品,只能选或不选,物品被选择用1表示,而不被选择则用0表示,将这类问题称为0-1背包问题.将目标车辆对Traffic包和Environment包的发送问题进行转化,确定两种数据包在某段时间内t′内的发送速率,即确定哪些包被成功发送,哪些包未被发送,统计发送成功的数据包数目即为求解结果.因此,目标函数的求解,被转化为求解目标车辆缓冲区中每个Traffic包与每个Environment包是否发送,设置中间向量X和Y,X代表Traffic包的发送向量,Y代表Environment包的发送向量,X和Y向量的取值只能是0或者1,0代表不发送该包,1则代表发送该数据包,同一时间段内发送的两类数据包不能超过带宽B.考虑所有约束,最大化目标车辆的收益,确定应发送的Traffic包和Environment包,即X向量和Y向量为目标函数的解,统计X以及Y向量中1的数目,得到xf与xe的值,此时对应的S即为最优目标值.因此,Traffic包和Environment包的调度与0-1背包问题对应,带宽B对应于0-1背包问题中的限定重量,车辆节点的总收益对应于0-1背包问题中的总价值,最终的求解目标均为最大化总价值.V_MFS模型与0-1背包的差别在于:0-1背包问题仅针对1类物品,而本文的模型中则有2种类型的数据包,0-1背包问题中的限定条件只是针对1类物品的重量限定,而本文所提出的V_MFS模型面向2类数据包,带宽B为2类包的共同限定条件.综上,本文的V_MFS模型可映射到0-1背包问题,但又有所区别.对于缓冲区中的两类数据包,并不直接求其需要发送的数据包数目,转而为缓冲区中的所有数据包进行状态求解,0为不放入待发送序列,1则表示放入待发送序列.最后,统计状态为1的数据包数目即为求解结果.
3.5 模拟退火算法原理
模拟退火算法(simulate anneal,简称 SA)在求解大规模的组合优化问题方面效果颇佳.SA算法是一种通用概率算法,其思想借鉴于金属处理工艺中的退火过程,首先将金属的温度加热到充分高,然后再让其徐徐冷却,在冷却过程中,金属内部的粒子运动逐渐趋于稳定,并且能够在每个温度下都达到平衡状态,最后,金属内部粒子会达到基态,此时它的内能也逐渐减到最少[26].
应用模拟退火时,首先为控制参数T(对应上述金属初始温度)设置初始值,目标函数f(对应于上述金属的内能)的表达式给定,Markov链长度L也给定.在解空间内随机选择一个作为初始解,然后根据相应的邻域函数随机产生新解,计算目标函数的差值,根据Metropolis准则确定是否接受新解.持续进行上述过程,即随机产生新解→计算目标函数f差值→确定是否接受新解,迭代次数等于Markov链长时,再继续对控制参数T进行降温.继续迭代执行上述过程,随着控制参数T的减小,系统状态也将越来越趋于稳定,最终求得最优解.SA算法性能的关键是冷却参数表的选取,冷却参数表包括控制参数T、退火率α、每个温度下的迭代次数Markov链长度L以及终止条件s.
Metropolis准则是模拟退火算法的精髓,模拟退火与贪心算法相比,差别在于在搜索过程加入了随机因素,对于比当前解要差的解,并不直接丢弃,而是以一定的概率来接受新解,所以有极大的可能找到全局最优解.而贪心算法仅接受比当前解更优的解,贪心算法因而很容易陷入局部最优而不能达到全局最优.模拟退火算法中接受新解的过程就是Metropolis准则,即
· 如果目标函数的差值Δf小于0,则接受新解;
· 如果Δf大于0,则首先生成一个0-1之间的随机数,判断exp(-f′/kT)>Random是否成立:若成立,则接受新解;否则不接受新解.
对于恶化解,不直接丢弃,而是以一定的概率接受.模拟退火算法的流程图如图2所示.
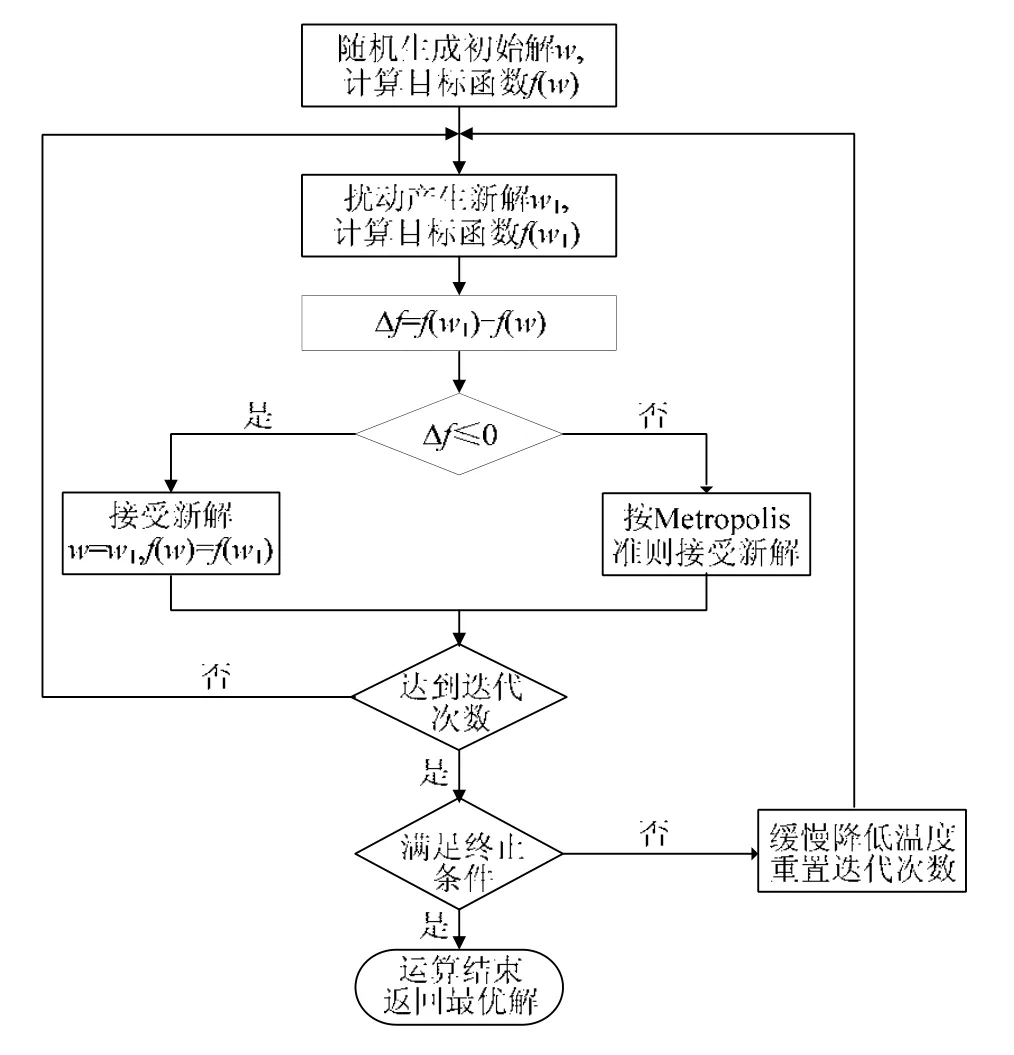
Fig.2 Workflow of the simulated annealing algorithm图2 模拟退火算法流程
3.6 面向VANET的混合流调度策略实现——TESA算法
基于V_MFS模型的分析讨论,结合0-1背包的思想,将模型中某段时间内求解的两种数据流发送速率问题转化为求解每个数据包是否被发送的问题.不同于贪心算法,模拟退火算法以一定的概率来接受可能会使问题变糟的恶化解.因此,模拟退火算法有更大的概率跳出局部最优,从而找到全局最优解.结合模拟退火算法的思想,本文提出启发式的TESA算法对目标函数进行求解.TESA算法包括数学模型、问题解空间、初始解、目标函数、新解的产生规则、价值差、Metropolis接受准则,工作流程如下.
1)本文将混合流的调度问题建模为典型的组合优化问题,即为V_MFS模型.
2)问题的解空间即由该问题的所有可行解组成:
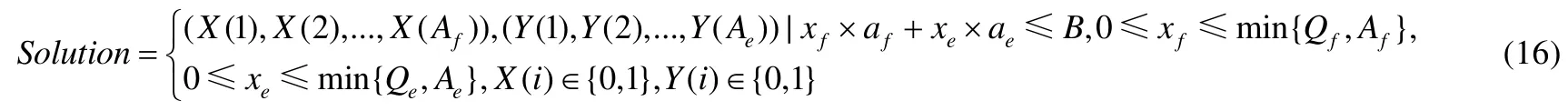
3)初始解,可任选解空间中的任一向量为初始解,简单起见,选择零向量作为初始解和.
4)目标函数,V_MFS模型的目标函数如公式(2)所示.
5)新解的产生规则,随机选取两类数据包中的任意一个数据包i,若i不在待发送序列,则直接将其放入待发送序列,或者将i放入待发送序列的同时再取出另一数据包j;若数据包i已经在待发送序列,则取出i,并随机放入数据包j.
6)价值差,根据上述产生新解的3种可能情况,对应的价值差为

S(i)表示将数据包i直接放入待发送序列;S(i)-S(j)表示将数据包i放入且将j取出;S(j)-S(i)表示选取的数据包i已经在待发送序列,则将i取出并放入j.
7)借鉴Metropolis准则,接受准则为
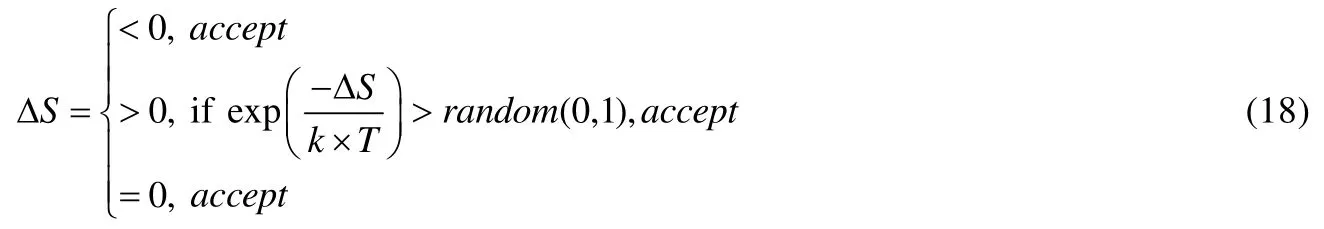
本文首先将该问题转化为与类0-1背包问题,结合模拟退火算法,设计TESA算法,对目标函数求解.模拟退火算法的性能取决于冷却参数表,冷却参数表包括一组用来控制算法进程的参数,即(T,L,α,s).
·T表示控制参数,即退火的初始温度;
·L表示Markov链长度;
·α为退火率;
·s为算法的终止条件.
一般地,将退火温度下降为 0作为算法的终止条件.只有选取了合理的退火参数才能保证模拟退火算法在有限的时间内达到全局收敛性,从而找到全局最优解.
1)控制参数T的选取
控制参数T为初始的退火温度.T值应设置足够大,算法的搜索范围也将随之增大,最终求得全局最优解的概率也将增加.但若T值过大,则会导致算法的迭代次数增加,使得程序的CPU运行时间明显增加.因此,T值的选取应与其他参数进行折中考虑,综合选取.
2)Markov链长的选取
Markov链长L对于模拟退火算法至关重要.TESA算法中,每个Markov链长迭代结束后,问题的解也会趋于稳定.链长L的选择,应使每个控制参数T对应的解都能趋于稳定,对应于金属退火中的粒子状态趋于稳定.链长L若选取得当,将大幅度提高程序的运行效率与结果.
3)退火率的选取
α为衰减函数的退火率,α用于对控制参数T降温,降温的方式有多种,本文选取指数降温,即
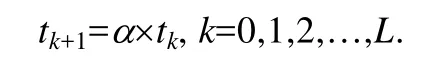
若α过小,则将导致控制参数T快速衰减,致使算法无法访问更多邻域,无法搜索更大解空间,最终导致与最优解擦肩而过.因此,退火率α应尽可能地大,使得控制参数T缓慢衰减,从而找到更高质量的解.
4)程序终止条件的确定
算法终止条件为控制参数T小于某个正数值,即当控制参数T<1的时候程序将终止.目标车辆收集到的所有Traffic包的deadline信息被表示为deadline数组.增加两个待发送序列Traffic和Environment序列,基于算法1,目标车辆选择需要发送的数据包到待发送序列.
算法1.面向VANET的低时延混合流调度策略——TESA算法.


4 VAENT中混合流调度与路径选择的联合优化
Traffic包和Environment包为VAENT中两种典型的数据包.Traffic包属强实时数据,其实时性必须得以保障.数据包的有效调度能够确保数据被正确发送,路径选择则可以提高数据发送的成功率.对混合流调度与路径选择进行联合优化,VANET的数据传输成功率将大为提高,Traffic包和Environment包的QoS需求得以保障.
4.1 问题描述
面向VANET的混合流调度策略有效地解决了VANET中优先级不同的数据流共存时的资源与速率分配问题,满足了两种数据流的传输需求,提高了数据流的传输效率.Traffic包和 Environment包为不同优先级的数据,Traffic包所携带的信息主要包括车辆的实时位置信息、行驶速度以及方向等,而Environment包携带的信息为CO2、PM2.5值等环境参数.Traffic包属强实时数据,为了确保信息的时效性,Traffic包应尽快被发送到云计算中心.为了将 Traffic数据包快速传输到云计算中心,路径选择尤为必要.同时,弱实时数据流的传输可靠性也能随之提高.
由于具有节点高速移动、节点密度过高、无线链路寿命短等特点,VANET的传输控制协议更具有挑战性和独创性.如车辆同向行驶时,车辆节点间的链路相对稳定,网络拓扑也相对稳定;但车辆相向而行时,无线链路转瞬即逝,网络拓扑变化快.因此,静态路由选择不适于 VANET,需为 VANET设计动态自适应的路由选择算法.并且应结合车辆节点的行驶方向、车速和道路信息,对链路进行预测,为车辆节点选择最佳下一跳.
4.2 模型建立
在指定时间内,VA需将待发送序列中的Traffic包和Environment包传输到云计算中心,VA到云计算中心有多条可选路径,每一条候选路径由若干链路组成.
· 若数据流k通过了路径j,即;
· 若链路l属于该路径,即.
而且Traffic数据流和Environment数据流可能分享同一条传输链路.因此,链路l的带宽应满足:
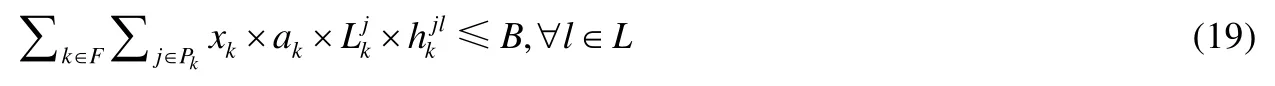
其中,
·F代表Traffic和Environment两条数据流的集合;
·j代表任一条数据流的任一候选路径;
·Pk代表Traffic或Environment数据流的所有候选路径集合;
·L表示该车载自组网中所有链路的集合;
·xk即xf或者xe,ak即af或者ae.
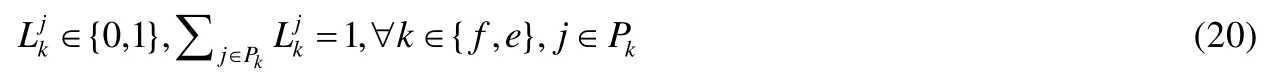
其中,f代表的是Traffic数据流,e代表的是Environment数据流,Pk表示k数据流的所有候选路径.假如任一条数据流选择了路径j,则简记为;如果恰好链路l在被选择的路径j上,则记为,链路容量记为cl.
综上,V_MFSPS数学模型如下:
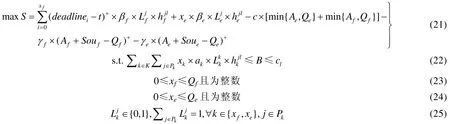
其中,公式(21)为目标函数,公式(22)为带宽约束,公式(23)和(24)为决策变量约束,公式(25)为路径约束.相较于V_MFS,对混合流调度与路径选择采取联合优化的模型V_MFSPS可大幅提高数据流的传输效率.目标车辆VA采集到的Traffic包数目表示为Af,Environment包数目表示为Ae,Traffic包的缓冲区大小表示为Qf,Environment包的缓冲区大小表示为Qe以及代价因子c,惩罚因子γf和γe已知.S代表链路的总收益.结合路径选择,V_MFSPS模型可转换为
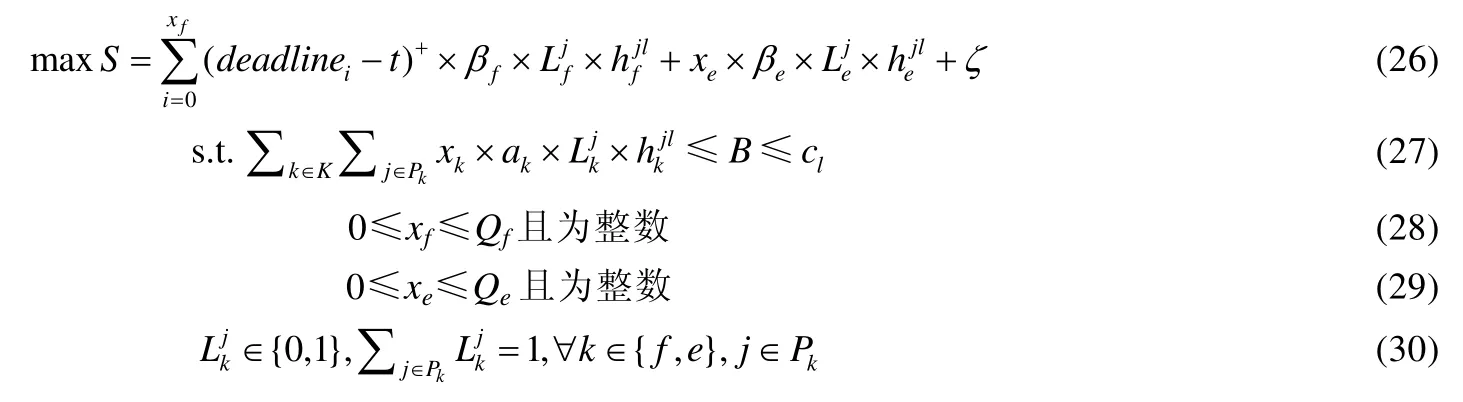
4.3 理论分析
V_MFSPS有4个约束条件,ζ为已知常数,要使目标函数值S取最大值,只需讨论除ζ之外的部分.于是,对最大化目标函数的问题进行转换,得到公式(26).
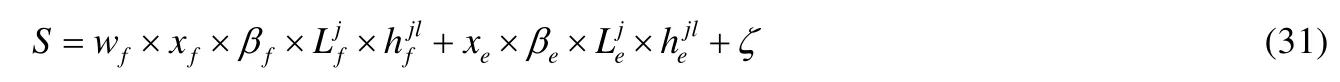
为了获得S的最大值,对公式(31)进行放松处理,于是可得:
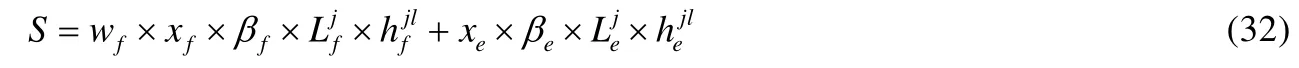
设每条链路容量为cl(B≤cl),βf表示 Traffic包的单位基准价值,wf×βf实质仍代表βf,令wf×βf=βf,公式(32)可转换为
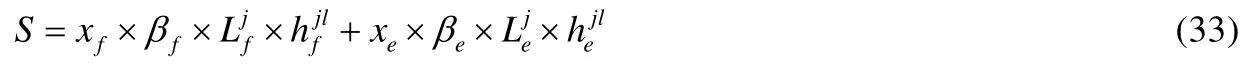
对于 Traffic和 Environment数据包来说,数据包容量越大,说明其携带的信息量越大,因此价值也越大.Traffic 数据包的单位价值βf与af成正比,af越大,βf也将会越大;同理,βe与ae也成正比,即

由此可得:

结合约束条件公式(22),可得:

求解的目标是使S达到最优值,即maxl∈LS=μ×cl.S与cl成正比,cl越大,S就越大.因此,在混合流调度与路径选择的联合优化策略中,最佳策略是为Traffic数据流和Environment数据流选取链路容量最大的链路所组成的路径.
4.4 PS&TESA算法设计
加入路径选择后,决策变量变成3个,分别为目标车辆应发送的Traffic包的数目、Environment包的数目以及链路的选择.xf与xe的取值为整数,对于任意链路来说,只有选或不选,故取值为 0或 1.在模型 V_MFSPS中,3个决策变量的取值都为整数,对应的PS&TESA算法也属整数规划问题,也是一个NP-hard问题[24].
将路径选择因素作为决策变量,链路容量越大,则目标函数值S越大.当目标车辆发送这两类数据流时,从目标车辆可用的所有链路中选择链路容量最大的一条作为数据流的当前路径,并对已选择过的路径进行标记.当目标车辆移动时,根据前述规则动态进行链路选取,直到到达目的地,即云计算中心.
此启发式算法命名为PS&TESA算法.算法伪代码如算法2所示.
算法2.面向VANET的混合流调度与路径选择联合优化的数据传输策略.


5 实验结果与性能分析
为了满足 VANET中两种不同优先级的混合数据流的传输需求,同时最大化目标车辆的收益,本文提出了TESA与PS&TESA算法.仿真实验结果可证实该算法的有效性.
5.1 VANET中混合流调度与路径选择的联合优化策略性能分析
基于传输时延,评价本文所提出的算法的性能.仿真实验证实在不同的问题规模下,本文所提出的PS&TESA算法在时延方面具有明显优势.
本文采用OMNET++平台仿真各移动车辆节点数据通信情况,最后采用MATLAB仿真对算法进行性能分析.仿真环境设置为一条双向通行的城市道路,车辆在两条车道上均匀分布,车间距为20m,RSU在道路两侧随机分布,在道路尽头设置云计算中心.道路两侧均匀分布10辆车,车辆在时间段t内接收Traffic和Environment数据包的数目分别设置为50、100、150和300.设Traffic数据包长度为5KB,Environment数据包长度为3KB.
基于Traffic数据包的传输时延,对未进行路径选择的TESA算法与加入路径选择后的PS&TESA算法进行比较,仿真结果如图3 所示.Af、Qf、Ae、Qe分别取值为(50,50,40,40)、(100,100,80,80)、(150,150,130,130)、(300,300,270,270),图3给出了实验结果.每个问题规模分别进行100次仿真求平均.实验仅统计Traffic数据流的传输时延,取最后一个Traffic包传输完成的时间为整条数据流的传输时延.由图3可知,PS&TESA的Traffic传输时延明显低于TESA.即使规模增加,传输时延依然呈现出相同的规律,相对于TESA,PS&TESA的Traffic传输时延显著提高.原因在于,与路径选择联合优化的优势显而易见,PS&TESA将从所有可用路径中选择链路容量最大的路径.链路容量越大,丢包率越低,重传次数减少,传输时延减少.PS&TESA 对于强实时数据尤为有效,能够保证Traffic数据包的传输时延.
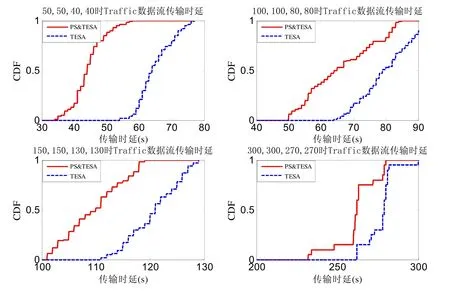
Fig.3 Comparison of transmission delay between PS&TESA and TESA in different scales图3 不同规模下PS&TESA与TESA的传输时延对比
5.2 PS&TESA与DSRC算法的性能比较
基于传输时延,结合不同类型数据包的速率和缓存区占用比,对PS&TESA与DSRC算法进行比较.仿真实验结果表明,相对于DSRC算法优先发送强实时数据流,本文提出的PS&TESA有效地提高了弱实时数据流的发送速率,并降低了缓存区占用比.由于路径优化的关系,PS&TESA算法的时延与DSRC算法相比并无明显差距.由图4可知,PS&TESA算法不仅能够有效地减小Traffic包的传输时延,而且能够提高弱实时数据流的发送速率,降低弱实时数据流缓存占用比.
由图4(a)可知,不同的数据包产生速率下,DSRC算法优先发送强实时数据流,导致弱实时数据流“饿死”.而PS&TESA算法有效地提高了弱实时数据流的发送速率.图4(b)表明,本文所提出的算法不仅提高了弱实时数据流的发送速率,而且未对强实时数据流产生任何不良影响,与优先发送强实时数据流的DSRC算法相比,两者的传输时延近似.图4(c)给出了不同的数据包产生速率时两类数据流占用缓存空间的情况,由图4(c)可知,PS&TESA算法有效地降低了弱实时数据流的缓存占用比例,降低了缓冲区超负荷溢出概率.

Fig.4 Performance comparison of PS&TESA and TESA under different packet generating rates图4 不同数据包产生速率下PS&TESA与TESA性能对比
6 总结与展望
车载自组网具有广阔的应用前景,可在道路上建立一个自组织、结构开放的车辆实时通信网络,实现交通预警、车辆的自动化驾驶、提升驾驶舒适度与实时路况查询.VANET中强实时数据与弱实时数据共存,数据动态产生且不可预期.同时,VANET通信带宽受限,面临无线信道质量不稳定、网络拓扑瞬息万变、无线链路寿命短、带宽受限、通信负载量大等多重挑战.本文提出了VANET中混合流调度与路径选择联合优化的数据传输策略,以满足强实时数据流对传输时延的需求,同时提高弱实时数据流的传输可靠性.仿真实验与性能分析结果表明,本文提出的联合优化策略 PS&TESA不仅能够减小强实时数据流的时延,而且能够提高弱实时数据流的发送速率,降低弱实时数据流的缓存占用比.
猜你喜欢
北京工业职业技术学院学报(2024年1期)2024-01-14 06:35:14
汽车维修与保养(2020年11期)2020-06-09 05:42:22
小学生学习指导(低年级)(2020年4期)2020-06-02 09:09:26
软件(2020年3期)2020-04-20 00:58:44
军营文化天地(2018年2期)2018-12-15 17:39:08
电脑与电信(2018年12期)2018-03-23 02:37:36
产品可靠性报告(2017年7期)2017-09-05 09:49:12
西北工业大学学报(2015年3期)2015-12-14 13:08:48
项目管理技术(2015年3期)2015-04-23 08:44:29
中国卫生(2014年7期)2014-11-10 02:32:54
