
增强上下文的错误定位技术∗
2019-03-05 03:45:22谭庆平毛晓光薛建新
软件学报 2019年2期
张 卓,谭庆平,毛晓光,雷 晏,常 曦,薛建新,
1(国防科技大学 计算机学院,湖南 长沙 410072)
2(重庆大学 大数据与软件学院,重庆 400044)
3(信息物理社会可信服务计算教育部重点实验室(重庆大学),重庆 400044)
4(上海第二工业大学 计算机与信息工程学院,上海 200127)
软件调试是软件开发过程中非常耗时的活动.为了提升软件调试的性能,研究人员提出了许多错误定位方法(例如文献[1-6]).其中,基于频谱的错误定位方法(spectrum-based fault localization,简称SFL)[2]是被广泛研究和使用的错误定位方法,展示了其在减少检测到错误代码的百分比方面的有效性[1,5,7,8].SFL尝试通过度量每个错误语句的可疑值来识别错误语句.首先,SFL利用插桩工具来对程序进行插桩,自动收集语句在测试用例执行中的覆盖数据,以此构建程序谱;然后,基于程序谱,SFL利用不同的度量公式来评估语句为错误的可疑性;最后,SFL输出以可疑性为排名的语句列表.
然而,SFL关注语句选择和排名,却忽略调试工程师所需要关心的上下文信息和可疑语句之间的传播关系,这些关系可以方便其理解和分析失效原因.研究[9,10]表明,缺乏上下文信息可能会降低错误定位性能.因此,有必要构建上下文信息来优化错误定位.
为了构建上下文信息,本文发现,程序切片技术[11,12]可能成为解决这个问题的候选者.程序切片技术提取程序语句的数据与控制依赖关系,以选出影响程序输出的语句子集.它将这个语句子集命名为切片.可以发现,切片可以显示切片中语句之间的数据与控制依赖关系,以及如何传播到输出的过程.也就是说,切片显示影响程序输出的相关语句相互作用的上下文信息.这意味着错误定位可以利用切片来提供上下文信息.现有的程序切片技术大致可分为静态切片和动态切片两大类:静态切片根据数据和控制依赖关系分析程序,而不运行程序;动态切片沿着执行路径的依赖关系进行分析.在实际应用中,静态切片具有更高的时间复杂度,切片体积较大,可能会包含过多与具体错误行为无关的语句;动态切片则具有较高的空间复杂度,切片体积较小,可能会出现切片丢失错误语句的情况[3,13].由于动态切片体积较小且与具体执行相关联,与静态切片相比,动态切片使用更为广泛.因此,本文将动态切片纳入研究.
虽然程序切片提供了上下文信息,但是它对切片内的语句赋予相同的可疑度.换言之,即使与原始程序大小相比,在切片体积明显变小的情况下,它也不能区分切片中的哪个语句更可疑.然而,切片仍然包含许多语句,特别是当程序规模较大时,需要进行大量的人工查找.因此,衡量一个片段中的语句的可疑性至关重要.
基于上述分析,本文试图将程序切片融入错误定位中,自动获取调试工程师所需的上下文信息,并进一步将可疑性度量引入其中.因此,在前期研究[10]的基础上,本文提出了Context-FL,通过使用动态切片来构建上下文信息,以及基于SFL的可疑性度量来评估上下文中语句的可疑性.本文在14个开源程序的大量错误版本上展开了实验,与8种个典型错误定位方法进行了对比.实验结果表明,与8种典型错误方法相比,Context-FL的检查代码的平均成本降低最多可达52.79%.
本文第 1节介绍基于频谱的错误定位和动态切片.第 2节具体描述本文方法 Context-FL.第 3节给出Context-FL的实现.第4节描述实验以及结果分析.第5节介绍相关工作.第6节总结本文.
1 相关背景
1.1 基于频谱的错误定位
基于频谱的错误定位技术(spectrum-based fault localization,简称SFL)意在构建程序谱,并使用可疑评估公式来衡量每个语句的可疑值.程序谱是数据的集合,包括语句执行覆盖信息以及测试用例是否通过的信息,是程序动态行为的一种具体视图[5].
SFL基于程序谱定义了 4个参数,并以此构建可疑评估公式.4个参数anp、anf、aep、aef与具体语句绑定,分别表示执行或者未执行该语句的通过或者失败测试用例数.下标的第 1部分表示该语句是否被测试用例所执行(e)或者未被执行(n),而第2部分则表示测试用例结果是通过(p)或失败(f).
表1给出了5个测试用例{T1,T2,...,T5}的示例,以表明如何计算每个语句的4个参数.如表1所示,前3行表示3个程序语句,最后一行为结果(0表示通过,1表示失败).左5列表示5个测试用例,每个单元格表示语句在对应测试用例的执行情况(1为执行,0为未执行).例如,语句 1中的T1值为 1表示测试用例T1运行时执行了Statement 1.对于语句1,aep的值为2表示执行了Statement 1的通过测试用例有2个,aef的值为1表示执行了Statement 1的失败测试用例有1个,anp的值为0表示结果通过但未执行Statement 1的测试用例不存在.

Table 1 An example illustrating program spectra表1 程序谱示例
假设程序P={s1,s2,...,sn},这表明P包含n个语句.该程序被测试套件T={T1,T2,...,Tm}执行,T包含m个不同测试用例且至少包含1个失败测试用例(参见图1).如图1所示,测试用例运行完毕后,语句覆盖情况与测试结果组成M×(N+1)的矩阵.左边M×N矩阵表示语句执行情况.如果语句sj由测试用例ti执行,则xij为 1;否则为 0.矩阵最右侧的结果向量e表示测试结果.如果ti是失败测试用例,则ei为1;否则为0.

Fig.1 Coverage ofMtest cases after executed图1M个测试用例执行后的覆盖信息
基于图1矩阵,SFL计算出每个语句的4个参数anp、anf、aep、aef,然后使用可疑性度量公式来计算每个语句的可疑值.SFL构建可疑性度量公式的基本思想:希望错误语句具有相对较高的aef值、较低的aep值.其理想情况是错误语句的aef值为最大,而aep值为最小.这意味着错误语句在所有失败测试用例中被执行得最多,而通过的测试用例中被执行得最少.可疑性度量公式会赋予错误语句最大可疑值.一般来说,不同度量公式赋予通过和失败测试用例的不同权值,从而产生不同的排名.研究人员对他们提出的方法进行了实证调查,其中,Xie等人[2,14]理论分析了大量SFL度量公式,总结出了5种较优公式.除了这5种公式,Ochiai、Barinel和D*是最新错误定位评价研究[4]中排名前3的错误定位方法.表2给出了这8种方法的可疑性度量公式.需要说明的是,D*公式中的*通常被赋值为2[4],这也是本文实验所采取的赋值.
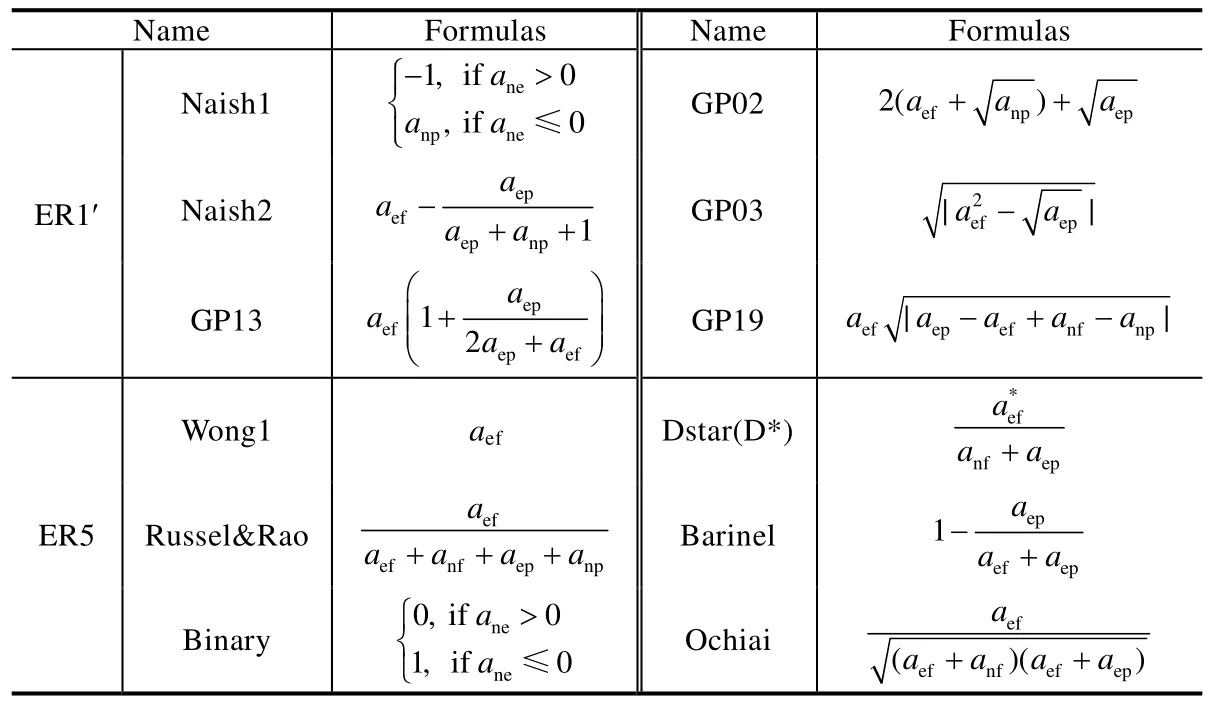
Table 2 Maximal formulas of SFL表2 最优SFL公式
SFL信息收集和工作原理比较简单,并能准确定位错误语句,因而得到了广泛的研究和应用.然而它并没有给出执行程序的上下文信息,也没有考虑到语句之间的依赖关系.其产生的语句排名列表没有显示语句之间依赖关系,有不少可疑性较高的语句与程序错误输出并没有关联.这种语句孤立与割裂,加重了开发人员理解和搜索问题的难度.当程序规模大时,不相关的语句将迅速增加,这可能对软件调试有很大的干扰.因此,需要构建与错误输出相关联的可疑上下文,以便更好地了解错误问题,并进一步减少手动查找范围.
1.2 动态切片
程序切片技术通过提取程序语句的数据和控制依赖关系,选择影响错误输出的语句的子集来构建上下文信息.程序切片技术首先由Weiser引入[11],已经在程序测试、程序理解和软件维护方面得到广泛应用.给定一个程序P和输入I,当P根据I执行时(例如文献[15-17]),切片技术切出直接或间接地影响一些变量出现的值的语句集合.静态程序切片由程序P中可能会影响变量v在某个点p[11,18]的值的所有语句组成,但它涉及所有可能的程序执行.然而,调试常处理特定的错误执行,以此查找导致该执行不正确的原因.因此,本文使用保留特定程序输入的程序行为切片,而不是针对所有输入的集合的静态切片.这种切片被称为动态切片[12].动态切片沿着执行路径收集运行时的信息,与静态切片相比可以显著地减少切片的大小[19,20].静态切片基于静态数据相关性计算,其切片中的语句数量很多,且通常根据对象在程序中的存在和指针进行保护.相对而言,动态切片针对具体执行捕获动态数据和控制依赖关系,更有针对性且精度较高,有助于调试人员理解和缩小其搜索范围.因此,本文采用动态切片技术来构建上下文.
动态切片标准可以表示为元组C=(Sk,V,I),其中,Sk表示语句变量为V的输入I上的语句S的k次出现.如图2所示,标准(n=91,v,2),其中,91表示第1次出现的语句9.由于输入n=2,这表明该循环执行了2次,即v=5和v=6分别执行1次.因为通过在第2个循环中分配5到v而使第1个循环中的变量v的赋值发生位移,所以可以从动态切片中省略if语句的else分支.而标准(9,v)下的程序的静态切片包括了整个程序.显然,动态切片更有利于缩小查找范围,且与具体执行相关,更具有针对性.
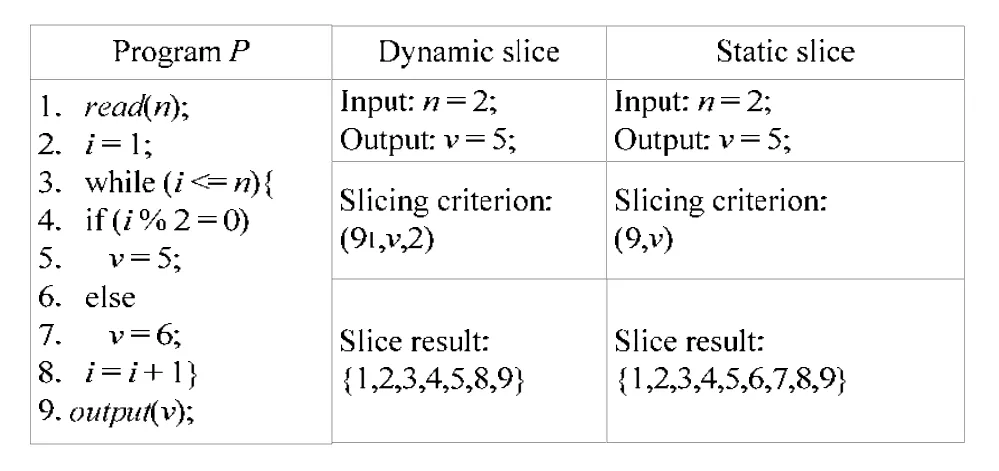
Fig.2 Examples of dynamic slice and static slice图2 动态切片与静态切片的例子
2 CONTEXT-FL算法设计
2.1 算法设计
Context-FL的基本思想是:将动态切片技术应用于 SFL,构建可疑上下文及其元素.Context-FL首先构建上下文,显示语句在程序执行过程中如何影响和被影响;然后,利用SFL评估上下文中元素的可疑值.
算法1和算法2描述了Context-FL方法的关键部分.
算法1.Get suspicious context.


算法2.Get statements suspiciousness in the context.

首先对算法1和算法2进行解释.本节采用第1节定义的程序P和测试用例套件T.即程序P由一组表示为{s1,s2,...,sm}的语句组成,相应的测试套件T={T1,T2,...,Tn}.Context{s1,s2,...,sn}表示与错误输出相关的语句的集合.EnhancedContext{s1,s2,...,sn}表示带可疑值标记的上下文语句的集合.接下来,将讨论 Context-FL算法中的每个步骤.
· 步骤1:构建可疑片段和他们的元素.
如算法1所示,该步骤迭代地构造可疑上下文,直到遍历完所有失败测试用例为止.第2行~第4行表示算法1所需要的输入变量,E表示输出错误结果的输出语句,V是语句中变量之一或变量集合,T表示测试用例套件.第5行是算法1的输出,即上下文,由一组至少影响1个错误输出的语句集合组成.由于上下文由导致程序错误输出的执行轨迹构成,它包含了导致失败的测试用例的错误语句.在第7行中,上下文初始化为空集.第8行和第9行表示循环依次遍历完每个失败测试用例.第10行获取可疑上下文片段,即每个失败测试用例错误输出的切片并集.最后,算法1返回可疑上下文片段Context.
· 步骤2:计算可疑片段中每个元素的可疑值.
如算法2所示,第2行和第3行显示输入变量,S(S={s1,s2,...,sn})表示由算法1生成的可疑上下文片段.M是可用于SFL公式计算的输入矩阵,结构如图1所示.第4行是输出,并且包含由标记着可疑值的增强型可疑上下文.在第 6行中,增强的上下文初始化为空.第 7行搜索上下文S中的每个元素.在第 8行和第 9行中,函数SearchElementInfo(si,M)分析测试用例T的语句覆盖信息和测试结果,函数GetSuspiciousness(si,ElementInfo(si))采用SFL公式计算S中每个语句的可疑值.语句覆盖信息的格式和测试用例的测试结果是一个矩阵,如图1所示.由于一些语句的可疑值可能相同,所以Order(EnhancedContext)函数按照它们的降序对语句进行排序.在本研究中,SFL以源代码中的行号降序排列具有相同可疑值的语句.
· 步骤3:输出错误定位结果.
此步骤将定制本地化结果输出.该定位包含一个增强的上下文,其语句以SFL给出的可疑值降序排列.定位结果可以帮助开发人员了解和定位错误,将一些信息附加到每个语句上,如可疑值和行号.
2.2 例子演示
如图3所示,本节通过包含错误语句s3的程序P,以此说明如何应用Context-FL.这个例子选择GP02来计算16个语句的可疑值.每个语句之下的单元格表示该语句是否被测试用例执行(1表示执行,0表示未执行),而最右侧的单元格表示测试用例的执行是否失败(1表示失败,0为通过).由GP02根据覆盖信息和测试用例结果得出排序:{s7,s8,s9,s12,s14,s10,s11,s2,s3,s1,s13,s4,s6,s5,s15,s16}.这个集合不能表示可疑语句之间的关系,也不能区分影响错误输出的语句.例如,s3和s8都被全部失败测试用例所执行,s3是错误的语句而s8不是.然而与s8相比,s3被更多地通过测试用例执行.因此,s3的可疑值要比s8低.但事实是,s8并不在导致错误输出的执行序列当中.这就解释为什么s3排名第9,并且可疑值比一些与错误输出无关语句的可疑值低.
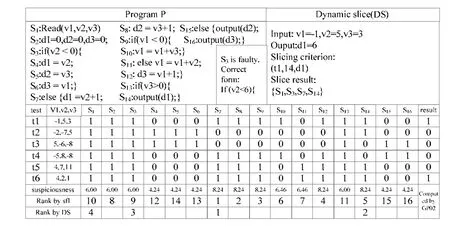
Fig.3 An example illustrating Context-FL图3 Context-FL例子说明
为了解决这个问题,Context-FL通过使用切片标准(t1,s14,d1)来构建错误输出的动态切片.该切片包括与失败测试用例t1的输出有直接关系的语句{s1,s3,s7,s14}.最后,GP02生成新的排名列表:{s7,s14,s3,s1},其中,s3被排在第3且{s8,s9,s12,s10,s11,s2,s13,s4,s6,s5,s15,s16}不包括在上下文中,因为它们与失败测试用例t1和t6的错误输出没有关系.因此,Context-FL比原来的GP02更有效.
3 CONTEXT-FL实现框架
3.1 实现框架
本节将详细介绍错误定位方法Context-FL的实现框架.如图4所示,Context-FL主要架构由3个主要功能模块组成,分别是程序信息提取模块、可疑上下文生成模块、可疑计算模块.
程序信息提取模块的主要功能是在执行测试用例后提取程序覆盖信息.第 1个不可或缺的步骤是程序插桩,其目的是捕获程序的运行信息.插桩点的选择由错误定位方法确定.因为收集足够的和非冗余的信息非常重要,所以需要采用适当的插桩技术,以此控制插桩的代码量,并且不会产生大量的冗余信息引起干扰.第2步是收集数据.因为在插桩之后,程序会产生大量的运行信息,必须以适当的方式收集数据进行抽象和恢复,以便于下一步的分析和计算工作.由于数据量相对较大,需要对数据进行简化.接下来是对每个测试用例生成的数据进行分类,使得所需数据以统一的方式存储.最后生成SFL计算的矩阵信息文件.由于软件的复杂性和规模日益增加,程序的运行数据显著增加.虽然采取了各种措施来压缩或减少在收集阶段收集的数据量,但需要分析的数据量仍然很大.因此,有效的数据分析方法是绝对必要的.程序切片信息、状态信息和统计信息是分析的 3个主要数据表现形式.Context-FL使用统计信息来查找与错误相关联的位置,这种类型的信息是通过分析程序的统计数据和提取特定模型来生成的.该方法通常使用语句、分支、预测信息、基本块和功能等程序覆盖信息,比较失败测试用例和成功测试用例并分析其差异性.最后,在不同要素之间的联系的基础上,产生了可疑值.

Fig.4 Architecture of Context-FL图4 Context-FL框架结构
可疑上下文生成模块的主要功能是找到与错误语句相关联的一组语句片段,该片段包含了错误语句且又大幅小于源代码量.其目的是通过缩小搜索范围来提高错误定位的效率.程序切片技术是一种分解技术,根据具体计算提取相关语句.它可以分析元素之间的依赖关系并缩小搜索范围.与其他可疑上下文提取技术相比,程序切片提供了一种有效的方法来了解程序执行是否影响输出.根据第 1.2节切片技术的分析,本框架采用动态切片技术提取可疑片段.虽然切片技术在语句关联分析中具有很强的能力,但是由于程序切片生成的可疑上下文中的语句不能区分,因此这些语句的可疑值是相同的.由于目前软件的规模不断扩大,所以片段的规模将会大为增加.如果只从片段中找出错误的位置,效率会很低,效果也会大为降低.可疑计算模块的主要功能是根据可疑环境,按照可疑值的大小顺序对片段中的语句进行排序.
受SFL技术的启发,当语句的执行影响了失败的测试用例的输出时,语句的可疑值会增加.另一方面,如果程序语句的执行影响成功测试用例的输出,则其可疑值会降低.因此,可疑计算模块定义了新的统计变量.
3.2 Context-FL使用的工具
首先介绍 EMMA[21]和 JSlice[22].EMMA是用于测量和报告 Java代码覆盖率的开源工具包.它是 100%纯Java且没有依赖外部库,可以在任何Java 2 JVM中工作.它支持4种不同的覆盖类型:类、方法、行和基本块.此外,它可以检测单个源代码行何时被部分覆盖.EMMA的输出报告类型包括纯文本、HTML和XML.特别地,HTML报告支持源代码链接.本文Context-FL主要使用行覆盖类型和HTML输出类型,如图5所示.
如图5所示,88行的深色表示在执行测试用例时没有执行该行,83行和92行的浅色表示该行只有一部分被执行,其余标深色的行完全被执行.本文过滤覆盖信息并摆脱其他不相关的信息.由于大型程序的文件数量众多,因此需要根据测试用例的顺序对覆盖信息文件进行重新编号、分类和存储.在运行所有测试用例之后,覆盖信息文件以矩阵的形式进行存储,如图1所示.
JSlice是Java程序的动态切片工具.给定一个程序P,切片工具执行一个切片标准(I,L,V),其中,I是一个输入,L表示在程序P执行期间根据输入I执行的一些语句的集合,V是由L引用的一组变量[22,23].由切片工具生成切片的目的是:在执行P期间找到影响语句L中的变量V的一组语句的集合,这些语句与L及其变量V是动态相关的.首先,将Java程序的执行路径转换为与执行跟踪相关联的字节流,并以简洁的形式进行压缩.Jslice使用的动态切片算法是直接在压缩程序跟踪上运行的算法,可以找到被忽略的错误语句.一般动态切片算法只给出 1组影响语句L中变量执行的语句,而Jslice除了发现通用算法发现的语句之外,还可能会发现一些影响语句L中的变量V的隐藏语句.本文在Context-FL中使用的JSlice的版本是JSlice v1.0,支持本文实验的程序都是顺序程序.JSlice可以使用的是Fedora Core 3/4或类似的系统.下一节的实验是在Fedora Core 3上运行的.
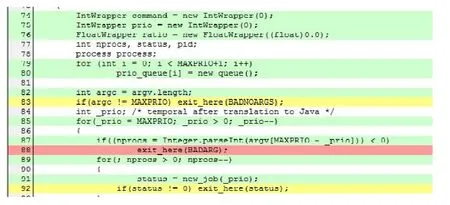
Fig.5 EMMA coverage report图5 EMMA覆盖报告
4 实 验
4.1 实验设计
实验将表2中的8种错误定位方法与Context-FL对比.对比基准程序集为14组Java程序.表3描述了这些实验程序,依次为简要描述(第2列)、实验使用的错误版本数量(第3列)、语句行数(第4列)和测试用例数(第5列).这些从SIR[24]和Defect4J[25]获取的程序被广泛使用.
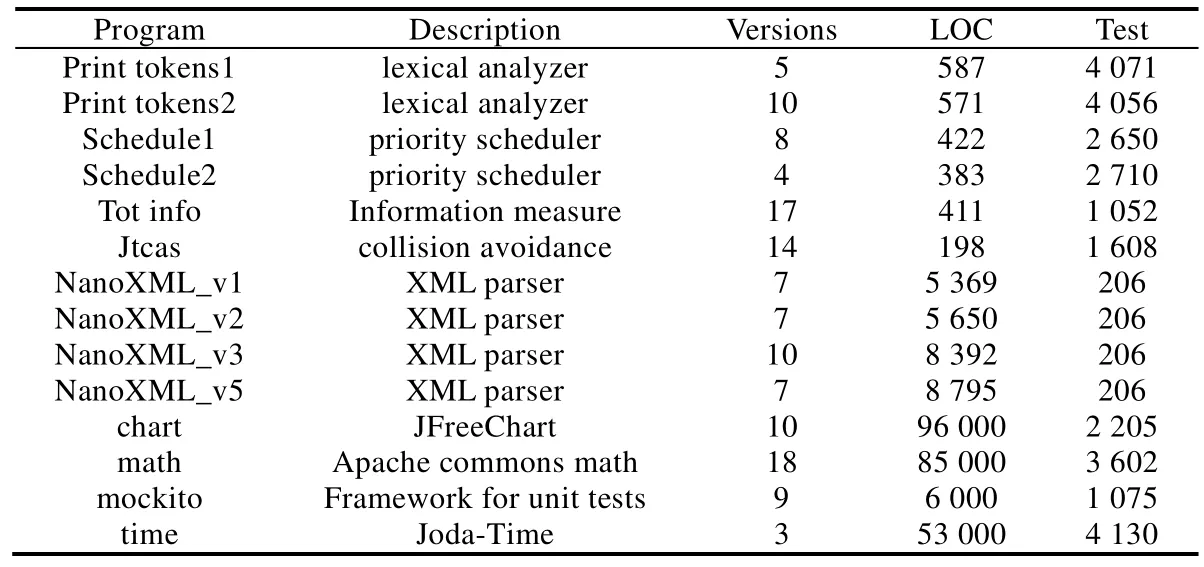
Table 3 Subject programs表3 实验对象
表中前10个程序[24]原本包含102个错误版本.实验没有采用schedule 1的版本1、schedule 2的版本2、版本4、版本9、版本10、版本12、版本14和Tot_info的版本4、版本10、版本12、版本14.因为它们没有失败的测试用例,至少有 1个失败的测试用例是执行动态切片所必需的.实验还排除了执行动态切片失败的Tot_ info的版本11,以及错误语句在依赖库中的版本19.对于Jtcas,实验使用了14个代表性的错误.后3个程序选自Defect4J[25],Defect4J是一个真实错误的数据集.在Defect4J中,实验选取了chart的版本1、版本3、版本6、版本7、版本12、版本13、版本17、版本20、版本23和版本24,mockito的版本1、版本5、版本7、版本8、版本26、版本28、版本29、版本34和版本38,time的版本4、版本16和版本19,math的35个单错误版本的18个.其他错误版本没有被采用的原因:一是本文研究主要是针对单错误,而其他版本为多错误;二是没有编译运行成功.因此如表3所示,实验最终采用了129个错误版本.
4.2 结果分析
为了评估本文提出的错误定位方法的有效性,实验采用错误定位精度(称为Acc)和相对改进值(称为RImp)作为评价标准[26].Acc被定义为在找到真正的错误语句之前要检查的可执行语句的百分比.RImp是使用Context-FL找到所有错误需要检查的语句总数除以使用对比方法需要检查的语句总数.Rimp的值越低,代表定位效果越好[27].
由于对比方法较多,图6将以分组的方式来更好地显示 Context-FL和对比方法的 Acc值.对于每个子图——图6(a)和图6(b),横坐标表示在所有程序中检查的可执行语句的百分比.纵坐标表示定位方法找出错误的比例.图6中的每一个点表示在检查可执行语句的百分比时,定位到的错误的百分比.

Fig.6 Acc comparison between SFL and Context-FL图6 SFL和Context-FL的Acc对比
从图6(a)和图6(b)可以看出,除了 ER5和 GP19之外,检查可执行语句到 5%时则出现了明显的效果提升.即使是ER5和GP19,在横坐标百分比分别为15%和10%时也出现了明显的效果提升.因此,Context-FL方法提高了8种定位方法的有效性.
由于对比方法较多,图7也分为图7(a)和图7(b)两个子图,显示了Context-FL在每个程序上的 RImp值.采用Context-FL方法后,需要检查的语句数明显减少,从Nanoxml_v3的GP03的20.22%(最优值)到chart的D*的88.63%(最差值).这意味着Context-FL只需要检查SFL所需检查的执行语句数的20.22%~88.63%,就能定位到错误.从图7(a)和图7(b)可以发现,Context-FL更加有效和稳定,特别是当程序规模大时效果则更为显著.
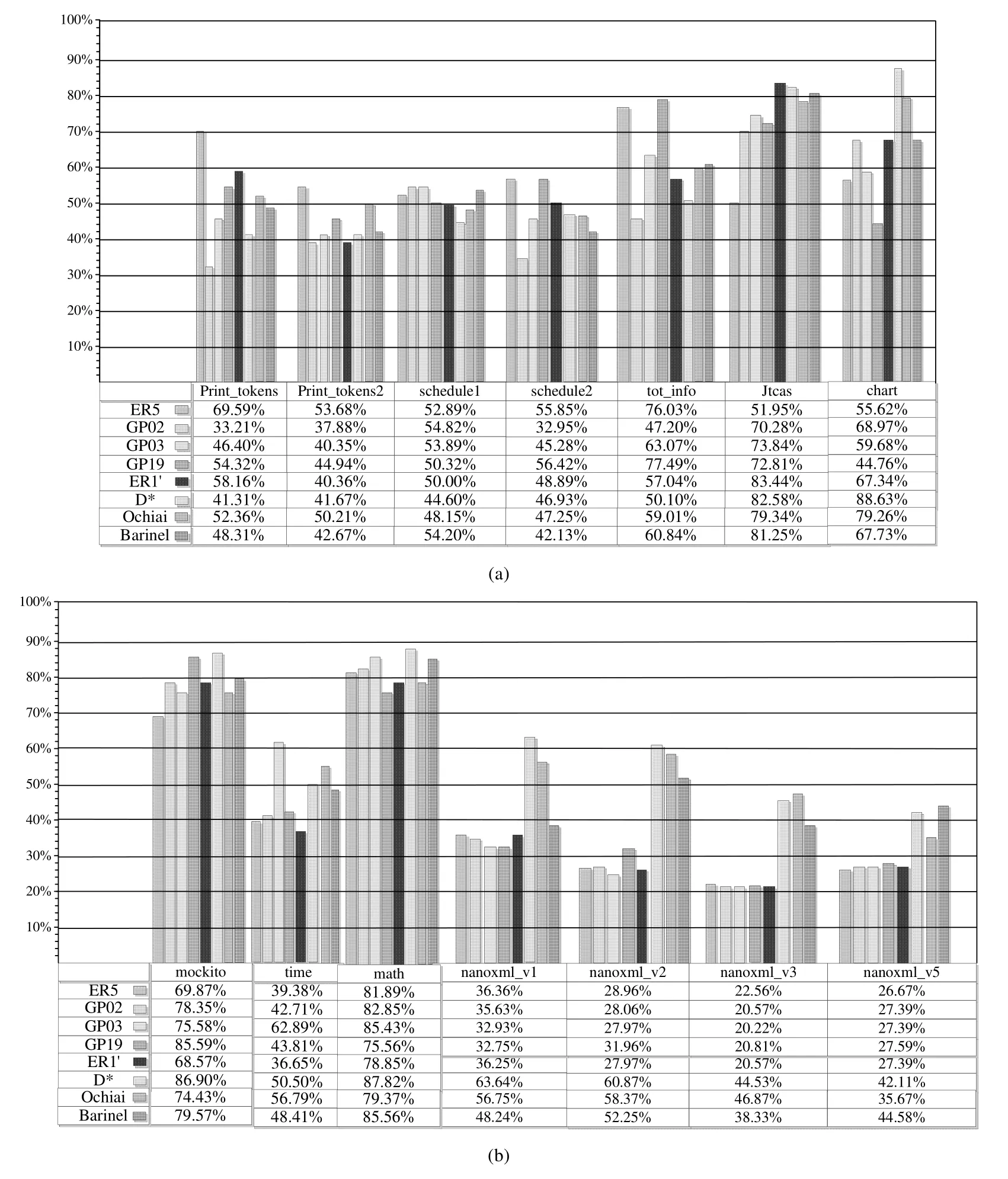
Fig.7 RImp of our approach图7 本文方法的RImp
为了对改进效果进行更详细的描述,图8显示了 RImp的分布,分别为 0~20%,20%~40%,40%~60%,60%~80%和 80%~100%.每个间隔代表分布在此区间的 RImp值的百分比.例如,GP02在 20%~40%区间的值为50.00%.这意味着在 50%的错误版本中,使用本文的方法定位到错误,它所需检查的语句数为使用 GP02所需检查的语句数的20%~40%.从图8可以看出,RImp值主要分布在40%和60%之间,其次是20%~40%.这表明,本文的方法对于提高定位效果还是非常明显的.
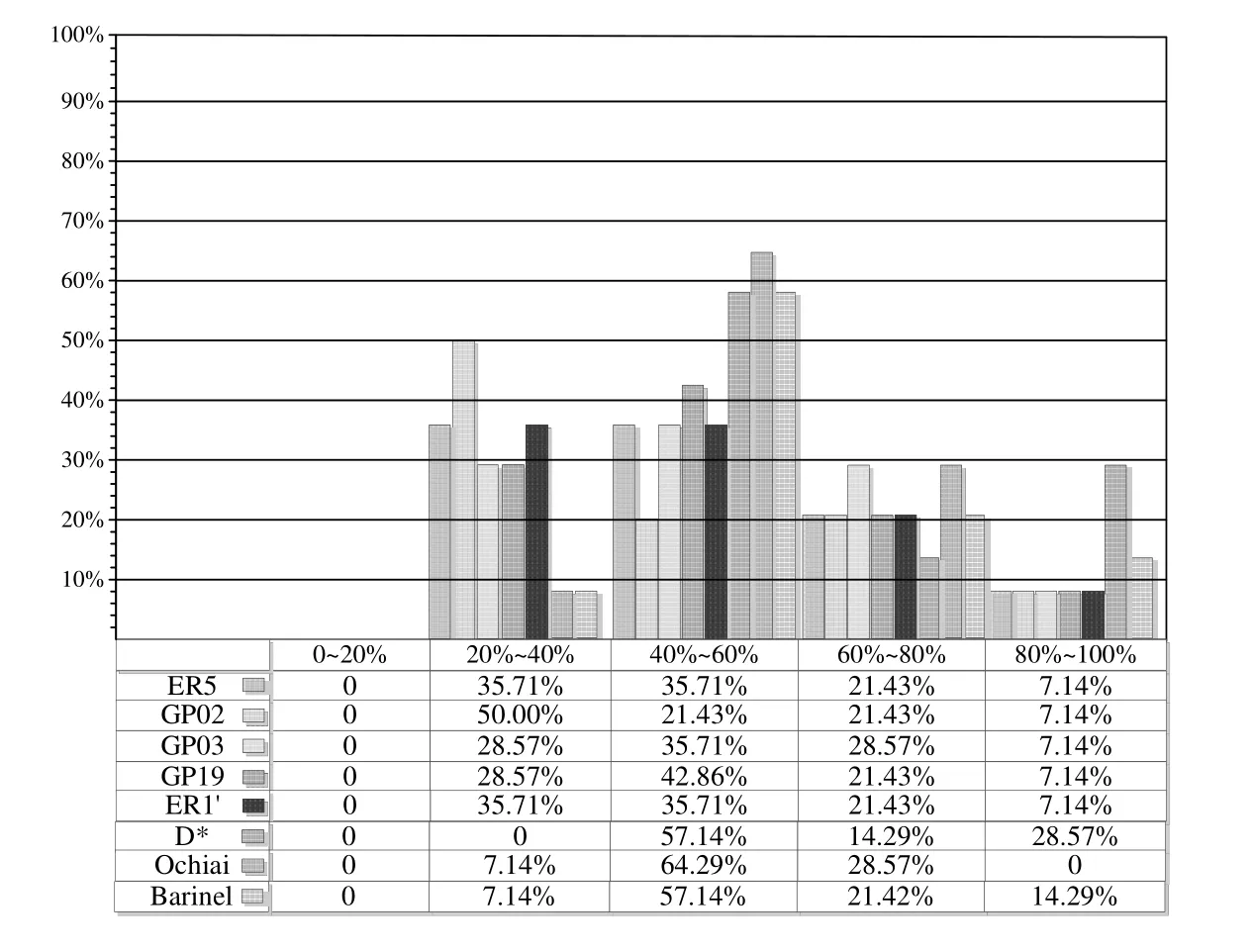
Fig.8 RImp distribution of our approach图8 本文方法的RImp分布
如图9所示,最大节约量(Saving=100%-RImp)为GP03的79.78%,最低节约量为D*的11.37%,平均节约范围为40.56%~52.79%.这意味着在使用Context-FL检查语句的数量时,可以减少11.37%~79.78%.总而言之,与实验中的8种定位方法相比,Context-FL明显减少了语句的检查数量.因此,Context-FL定位能力更强.

Fig.9 Saving of our approach over SFL图9 本文方法和SFL的Saving对比
Lei等人[27,28]以静态反向切片和执行切片的交集构建信息矩阵,并基于该矩阵提出重新定义语句怀疑度计算公式的方法(本文简称Lei-FL).为了进一步说明Context-FL的有效性,实验将Context-FL和Lei-FL进行了比较.Lei-FL使用的程序集为C程序,与实验所使用JAVA版本的Print tokens 1、Print tokens 2、Schedule 1、Schedule 2、Tot info和 Jtcas为一组程序,错误版本也相同.因此,实验选取在这些程序上效力较好的 5种公式(即 ER5,Barinel,GP02,GP19和 D*),分别应用 Context-FL和 Lei-FL,并对比它们的效力.如图10所示,在所有 5种公式上,Context-FL曲线一直高于Lei-FL曲线.这说明Context-FL的定位效力高于Lei-FL.
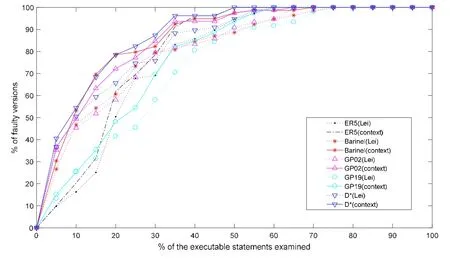
Fig.10 Acc comparison between Context-FL and Lei-FL图10 Context-FL和Lei-FL的Acc对比
表4描述了这些实验程序的时间开销的对比情况.表中数据的分子为使用Context-FL时的时间开销情况,分母为未使用 Context-FL的时间开销情况.可以看出,随着程序规模的扩大,由于采用动态切片的原因,使用Context-FL的时间成本会有所增加.

Table 4 Comparison of experimental time cost (s)表4 实验时间开销对比 (秒)
4.3 有效性威胁
本文实验有如下有效性威胁.
· 实验采用了JSlice的动态切片工具.然而,由于切片技术与JSlice工具局限性,与系统库相关的依赖无法提取.这时,错误语句很有可能不包含在切片结果中,如Tot_info的版本11.动态切片技术的另一个缺点是对某些类型的错误无法实施切片,例如,遗漏类型的错误语句无法产生执行信息,动态切片无法切到该类型的错误语句.这些缺点是由动态切片技术自身特点所引起的.
· 实验有一个潜在假设:当一个失败的测试用例运行时,错误的语句应该被执行.这个假设通常成立,实验结果也证实了假设的合理性.然而在某些情况下,如程序中出现多重错误时,则假设可能不成立.但是对于单一错误进行研究是必要的,因为它们是对多个错误进行定位的研究基础.这就是为什么大多数现有的研究集中在单一错误情景的原因.
· 实验对象也是有效性威胁之一.实验选择广泛应用于错误定位领域的代表性程序.然而现实调试中存在许多未知因素,说明它们不能覆盖并适用于现实中的所有情况.因此,未来工作使用更多的真实大型程序将会是本文研究的重点.
5 相关工作
有许多研究人员根据覆盖信息或切片信息研究错误定位技术.本节简要介绍这些研究.更多的错误定位工作可参考Wong等人近期发表的综述[1].
基于覆盖的错误定位技术将程序谱数据从测试执行转换为程序实体的可疑值,并使用诸如基于程序谱的错误定位(SFL)等统计公式对其进行排序.当使用这些技术时,本文不需要知道程序的详细信息,只需运行通过和失败的测试用例.Chen等人[29]提出了Jaccard技术,这是一种统计错误定位算法.Jones等人[30]提出了Tarantula技术,计算每个语句的可疑值,并根据他们的可疑值进行排名.Tarantula在后续研究中是广泛使用和比较的技术.Abreu等人[31]应用Ochiai定位单一错误.他们指出:他们的技术Ochiai一直优于Tarantula,并且在EXAM得分方面平均提高了5%.Abreu等人[32]在后来的研究中评估了Tarantula的有效性以及其他技术,并指出,Ochiai对测试用例进行了最佳的评估.Wong等人[33]利用数据和控制流程,并提出了几个指标,如Wong1-3,Wong3′.它们都是计算具有失败测试用例的程序实体的可疑值的统计公式.虽然Wong等人[8]提出了一种基于代码覆盖的方法,可以通过测试执行自动调整可疑语句的权重,还提供了一些减少搜索域的方法.Wong等人[34,35]还提出了一种基于交叉表的方法,利用语句的覆盖和执行信息,并提出了一种名为 DStar(D*)的技术.该方法计算了修改语句的可疑值.最近,Xie等人[14]在理论上研究了GP进化公式.
程序切片算法(静态和动态)的应用也被许多研究人员广泛研究用于程序调试.Lei等人[27,28]采用静态切片对每个测试用例的输出进行切片,以此构建输入矩阵,并基于这个矩阵重新定义可疑值计算方法.本文方法仅对失败测试用例的输出进行动态切片,其针对性强,避免了成功测试用例可能带来的不确定影响.同时,动态切片体积小于静态切片体积,搜索范围更小.本文实验结果也表明,Context-FL优于 Lei等人的方法.Zhang等人[36,37]研究了动态切片在定位错误中的有效性,并开发了一种采用动态切片的策略,通过计算从0到1的置信度值,来识别可能影响输出以产生不正确值的语句的子集.Zhang等人[38]还提出了一种类似切片的技术,以便从许多事件中剪除不相关的事件.Jones等人[30]使用动态切片和执行切片来减少搜索域.Alves等人[39]将变化影响分析纳入动态切片,以进一步优化动态切片.Wen等人[40]提出了利用混合切片谱的统计方法,以提高错误定位的有效性.与这些方法不同,本文方法使用的是动态切片,对程序的动态执行轨迹进行了分析,显示了如何捕获动态数据和控制依赖关系.Wong等人[41]提出了一种基于执行切片和块之间的数据依赖关系,在小范围代码内实现高效准确的错误定位的方法.我们的方法与它不同.我们利用动态切片来构建语句的上下文关系.
偶然正确性(coincidental correctness)问题是错误定位研究的一个热点.当测试用例执行了错误语句,却并没有导致程序失效时,就产生了偶然正确性问题.偶然正确性问题存在于成功测试用例中,对错误定位性能有负效应.为了解决偶然正确性问题,如何识别存在偶然正确性问题的成功测试用例成是关键.Wang等人[42]提出了上下文模型(context pattern),通过是否匹配上下文模型来识别存在偶然正确性问题的成功测试用例,并以此优化覆盖矩阵,从而提升错误定位性能.Masri等人[43]定义了基于缺陷的失效,以此描述具有偶然正确性问题的成功测试用例,从而更有利于缓解偶然正确性问题.随后,Masri等人[44]对偶然正确性问题进一步研究,采用Euclidean标准度量出成功测试用例与失败测试用例之间的相似度,以此移除具有偶然正确性问题的成功测试用例.Miao等人[45]基于偶然正确性的成功测试用例与失败测试用例有相似行为的思想,采用聚类方法对测试用例进行分类.当成功测试用例被划分到包含失败测试用例的类别时,该成功测试用例存在偶然正确性问题的可能性较大.Bandyopadhyay[46]基于成功测试用例与失败测试用例之间执行语句的相似度来定义权重,并以此预测可能具有偶然正确性问题的成功测试用例,最后,根据预测来优化错误定位性能.Lei等人[47]系统分析和总结了测试用例集的错误定位效能,从理论和实验证明了偶然正确性问题是成功测试用例对错误定位效能影响最大的因素.他们的研究还明确失败测试用例对错误定位效能具有正效应作用.与成功测试用例的偶然正确性问题相比,失败测试用例的信息更加直接有效.因此,本文方法关注于失败测试用例,通过动态切片提取更精确信息,大幅度缩小错误搜索范围,以此为基础来实现错误定位性能提升,也印证了 Lei等人[47]对失败测试用例的结论.虽然本文方法不关注优化具有偶然正确性问题的成功测试用例,且采用的动态切片不能根除偶然正确性,但是通过动态切片对失败测试用例的优化,大幅度缩小错误搜索范围,抑制了具有偶然正确性问题的成功测试用例发挥负效应的空间,间接地缓解了偶然正确性问题.
6 结 论
本文提出了一种基于上下文的错误定位方法 Context-FL.该方法结合动态切片和可疑性度量方法,构建可疑值标记的上下文.实验结果表明,与5种典型定位方法对比,Context-FL显著优于这些方法,有效缩减了代码检查的范围,大幅度提升了错误定位性能.未来的工作包括方法优化,以提高其准确性.此外,我们还会研究将Context-FL扩展到多错误场景下的定位.
猜你喜欢
铁道通信信号(2020年6期)2020-09-21 09:23:22
新世纪智能(语文备考)(2020年4期)2020-07-25 02:28:50
传感器与微系统(2018年7期)2018-08-29 00:44:18
作文评点报·低幼版(2017年44期)2017-11-16 08:24:58
电信科学(2016年11期)2016-11-23 05:07:58
中国组织化学与细胞化学杂志(2016年3期)2016-02-27 11:15:40
浙江理工大学学报(自然科学版)(2015年7期)2015-03-01 02:54:29
中国当代医药(2015年17期)2015-03-01 02:03:38
语文知识(2014年4期)2014-02-28 21:59:52
空间控制技术与应用(2010年3期)2010-12-23 08:04:57
