
仿视网膜采样的二进制描述子
2019-02-25 01:26袁庆升靳国庆张冬明包秀国
通信学报 2019年1期
袁庆升,靳国庆,张冬明,包秀国
(1. 国家计算机网络应急技术处理协调中心,北京 100029;2. 中国科学院计算技术研究所,北京 100190;3. 中国科学院大学网络空间安全学院,北京 100049;4. 中国科学院信息工程研究所,北京 100193)
1 引言
随着互联网图像数量迅速增长,对海量图像进行内容分析与检测的需求越来越大,基于内容的图像检索技术成为研究热点。这些技术通常使用局部特征作为图像内容的描述,这是由于局部特征具有良好的区分性,对图像的多种变换,如遮挡、模糊、噪声、剪切等,具有较高的稳定性。局部特征的提取主要分为2个步骤:1) 特征点的提取,提取的信息包括特征点位置、特征点主方向、特征点尺度信息等;2) 局部特征点描述子的计算,即依据特征点周围的像素信息,计算其对旋转、光照、尺度等变化顽健的特征,提取到的特征通常以向量表示,能有效描述特征点。
常见的局部特征点描述子主要分为2种:实数描述子和二进制描述子。实数描述子提取复杂,在内存和磁盘上以浮点数的形式存储,对存储要求高且不能满足实时性需求。二进制特征描述子使用二进制位进行编码,计算简单且占用的存储空间小,适合实时性要求高的应用场景。常用的二进制描述子主要有BRIEF(binary robust independent elementary features)[1]、ORB(oriented FAST and rotated BRIEF)[2]、BRISK(binary robust invariant scalable keypoint)[3]、FREAK(fast retina keypoint)[4]等。
BRIEF通过随机选择点对而得到二进制描述子,计算速度快[1],但是其对旋转和尺度变化敏感,在不同数据集下检索性能差异大。BRISK抛弃了随机采样模式,提出类似 Daisy[5]的采样方式,以特征点为圆心,在半径依次增大的同心圆上均匀采样候选点,同心圆上候选点采样密度从中心开始均匀下降,这在一定程度上增强了对噪声的顽健性。FREAK则模仿视网膜特性在BRISK技术上进一步引入了多尺度平滑[4]。李兵等对BRIEF进行改进,不同于ORB特征使用区域质心计算主方向,该方法通过在特征点邻域内均匀采样8对对称子区域,然后累加各子区域以其像素均值加权的梯度方向作为主方向,从而实现了描述子对旋转的不变性[6]。朱英宏等通过提取特征点邻域内33个像素点的二进制纹理特征,得到一个132 bit的二进制描述子[7]。卢鸿波等在特征点邻域内选取R个同心圆,每个圆上采样N个像素点,然后使用同心圆层内编码和层间编码的方式得到一个2RN bit的二进制描述子[8]。惠国保等研究了不同采样模式和不同高斯平滑半径对二进制描述子的影响,提出了一种内密外疏的采样模式[9]。
此外,近年来研究者们还提出了很多基于有监督学习的二进制特征生成方法。RFD(receptive fields selection)特征[10]对多个子区域的实值特征进行量化构建二进制特征,子区域的选择和量化阈值通过学习得到。BinBOOST[11]特征则是通过学习多个弱分类器组合成一个强分类器,用分类器来判断二进制位取值为0或1,采用的弱分类器形式是量化函数。RFD特征和BinBOOST特征在本质上都是通过有监督学习的方式对实值特征进行量化来得到二进制描述子。随着深度学习卷积神经网络(CNN,convolution neural network)[12]在图像分类上快速发展,也出现了许多基于深度学习提取二进制描述子的算法[13-15],这类方法不同于上述局部的二进制描述子,获得的是图像的全局二进制描述,缺少描述图像底层细节的有用信息,且计算复杂度高,提取描述子时需要占用大量内存,效率低。
本文综合考虑采样点选择和描述子生成,基于视网膜的视神经细胞分布和感知特性,研究二进制描述子生成方法。特别地,针对特征点对顽健性低的问题,提出了模仿视网膜特性的采样模式。对比同样模仿视网膜特性的 FREAK[4]描述子,本文方法二进制描述子的生成过程不同。本文所提出的采样模式混合使用多尺度光滑、视野重叠等模仿视网膜特性,且通过数据实验对关键参数进行优化,同时还提出了基于学习的方法,在典型数据集上对最终采样点对进行选择。所提方法具有计算快速、占用内存少、顽健性高的优点,且匹配正确率有明显提高。
2 基于RBS的二进制描述子
图像局部二进制特征提取包括特征点检测和描述子提取。特征点检测往往需要在多个尺度空间上进行极值点检测,以应对图像的尺度变化,保证特征点的可重复性。描述子提取是在特征点检测的基础上进行的,通常依据特征点周围的像素分布按照预设计算模型生成一串特征数值,而二进制描述子一般通过比较像素点之间亮度的大小来确定描述子取值,如式(1)所示。

其中,l为比较点对的数目,它决定二进制描述子的最终长度;点对 Pi由 2个像素点和定义;T(Pi)表示点对 的比较结果,定义如式(2)所示。

其中,I(⋅)表示对应点的灰度值。
由式(1)可以看出,二进制描述子完全取决于点对的选择,相应地,描述子的区分能力和顽健性完全依赖特征点周围的点对采样模式。选择好的采样模式,一方面可以减少描述子长度,即降低的取值,进而降低计算量和内存开销;另一方面由此产生的二进制描述子对各种常见的变化具有很好的顽健性,即不随图片尺度、方向及视角等变化而改变。本文根据视网膜的细胞分布特性,设计了相应的候选点选取方式和点对采样模式,从而获得高性能的RBS(retina-imitation based sampling)特征。下面详细介绍候选点选取方式、点对采样模式以及RBS特征的生成方式。
2.1 候选点选取
候选点选择方面,ORB和BRIEF采用随机采样,BRISK采用均匀采样,FREAK使用类视网膜采样,均取得了较大的性能提升。视网膜由3层神经元组成。第一层神经元是视细胞层,包括锥细胞和柱细胞,负责感光。第二层是双节细胞,数量为十至数百个,负责联络作用,视细胞通过双节细胞与一个神经节细胞相联系。第三层是神经节细胞层,将光信号转化为视觉信号,是实际的视觉神经,所以也称为视神经层。神经科学的最近研究结果表明视觉神经细胞的分布并非均匀分布,在视网膜中心视觉神经细胞密度并不是很高,而在中心周围密度急剧上升,再往外密度则快速下降,如图 1所示[16]。视网膜中心位置叫做视网膜小凹,其中只有很少的细胞,但在这个凹槽周围分布有大量的细胞,细胞数量与其到中心小凹的距离成反比。此外,视神经层还具有类似高斯差分机制的感知特性,抽取信息的神经节细胞位于视网膜外围,而形成高层视觉信息的细胞位于视网膜中心。
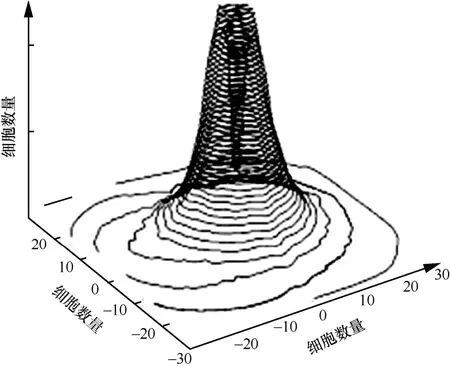
图1 人眼视网膜视神经细胞分布
本文模仿视网膜视神经层细胞的分布特性,设计了一种新型的候选点采样模式。模拟视神经层的细胞具有“低-高-低”的密度分布特性,通过实验选择,确定对特征点采用5层采样。具体地,以特征点为候选点中心,在中心外围第一层候选点的密度比较低,在第二层候选点的密度最高,第三层~第五层候选点的密度呈指数下降。如图2所示,中间点为特征点,从内向外每层采样点数分别为 4、24、12、8、4。本文将这种采样模式称为 RBS。FREAK采样点设置为6:6:6:6:6:6:6,共7层42个采样点;RBS采样点设置为4:24:12:8:4,共5层52个采样点。通过比较可知,RBS的特点如下:一方面采样点数增加了10个,增长率为23.8%;另一方面突出特征点周围像素点对描述子的作用,分布更贴合视网膜的细胞“低-高-低”的密度分布。

图2 候选点分布
由于二进制描述子是基于像素点之间的亮度比较,所以对噪声较为敏感,为了降低噪声的影响,对候选点进行高斯模糊已成为通行做法。对于不同候选点,BRIEF和ORB使用相同的高斯模糊半径;而BRISK和FREAK使用不同的模糊半径,更符合人眼视觉特性。本文模仿视神经的感知特性,采用不同大小的高斯模糊半径,中心模糊半径最小,外围候选点模糊半径逐渐增大。通过匹配正确率实验对比,本文设定初始模糊半径为2,层间相差为2。此外,本文还设计特殊的模糊范围来改善模糊效果,同一层的模糊范围保证一定的重叠,第二层和第三层的重叠面积最大,各层的重叠面积满足“少-多-少”的规律。经实验,选定比例为1:4:3:2:1,进一步提高平滑效果,多级高斯模糊如图3所示。

图3 多级高斯模糊示意
2.2 点对采样模式
接下来研究如何从潜在的大量候选点对中选出最佳的比较点对。假设有n个候选点,两两组合一共有个候选点对。为了提高特征顽健性,同时降低特征维数,必须进一步筛选以去除噪声影响,同时消除强相关的点对。为此,本文提出从训练集中学习筛选比较点对,从而确定最后的采样模式,具体方法如下。
1) 在训练集上提取r个特征点,每个特征点计算长度为的描述子。这样组成一个r行列的二进制矩阵。在本文的实验中取n=53,则这个矩阵一共有1 378列。
2) 在上述矩阵中,每一行表示一个特征点描述子,每一列表示一个候选点对的所有计算结果,点对之间可能存在较强的相关性,导致某些列可能全为0或全为1。而如果某个候选点对的区分性高,则该列的按位均值应接近 0.5。所以本文选取均值最接近 0.5的那一列记为c,把其所对应的候选点对加入最终的比较点对集合。
3) 对剩下的所有列按照其均值与0.5的接近程度排序,计算各列与列c的余弦距离,选择余弦距离大的列,把对应点对加入最终点对集合。重复此步骤,直到选出M组点对。
通过上述方法选出的M组点对区分性较强、相关性低。可以看出,本文方法和FREAK中方法类似,均采用构建特征矩阵、降维方式,来获取点对中对提升描述子区分力作用最显著的点对,本质上是一种统计学习方法。但RBS得益于本文设计的采样模式,可以消除更多的冗余点对,构建更短的二进制描述子,并构建了32、64、128、160 bit的描述子以适应不同应用场景,分别记为 RBS-32、RBS-64、RBS-128、RBS-160。图4中列出了当M设置为 32时选择的部分点对。结果显示点对选择并没有像FREAK那样呈现明显的对称规律,这一方面是由于 32组点对数量偏少,另一方面也表明FREAK的点对中可能存在较大冗余。
2.3 二进制描述子
为了使生成的二进制描述子具有旋转不变性,在提取特征点的二进制描述子之前,首先将特征点邻域旋转至特征点主方向上,这里使用特征点邻域的亮度质心来计算特征点主方向。特征点邻域的亮度质心C的具体计算如式(3)~式(6)所示,其中I(x,y)表示点(x,y)上像素亮度值。

图4 比较点对示意
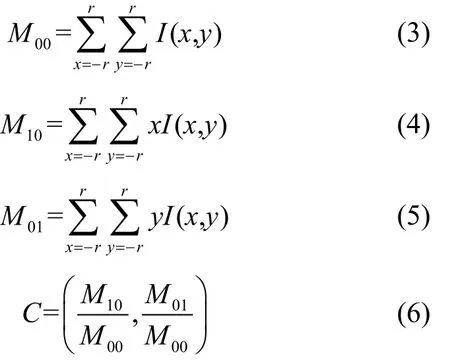
特征点中心O与质心C的连线方向即是特征点的主方向。
传统的描述子计算按照式(1)和式(2)进行计算,由于只是像素点灰度的比较,所以噪声对其影响比较大,为了提高顽健性,本文使用像素点及其周围8个邻域像素的信息作为比较信息量,即

其中,AI(⋅)表示9个像素点(8个邻域像素点以及自身)灰度的均值。按照2.2节中介绍的点对采样模式进行采样后,按照式(7)进行描述子计算,获取该像素点的二进制描述子,通过该方法可以进一步提高描述子对噪声的顽健性。
对比同样基于视网膜特性的 FREAK,本文方法取得两方面改进:1) 通过设计更符合视网膜特性的采集模式和典型数据的学习进行点对选择,大幅降低了点对数目,提高了二进制描述子的紧致性;2) 对模糊半径、模糊范围等关键参数进行优化,设计了更符合视网膜特性的参数模型,在生成二进制描述子时,使用区块均值代替单个像素点,顽健性更高。
3 实验结果与分析
3.1 数据集与测试环境
为了测试描述子RBS的顽健性,本文使用专用描述子测试集进行评测,该测试集由 Mikolajczyk等[17]提出。这个数据集由8张图片组成,每张图片有 5张变体,覆盖了视角变化(wall和 graffiti)、压缩退化(ubc)、光照变化(leuven)、旋转和焦距变化(boat和bark)、图像模糊(tree和bike)这些常见的图像变化,第一张变体变化最小,第五张变化最大。另外,这个数据集还提供了变体与原图之间的单应变化矩阵,方便计算匹配正确率。
进行测试的硬件平台为Dell台式机,其指标如下:CPU 为 Intel(R) Core(TM) i7-4770 @ 3.40 GHz,内存为8 GB,操作系统为Ubuntu 14.04。
实验中,提取二进制描述子前需要进行特征点检测。Rostenand等通过制定特征点规则并进行机器学习的方式得到了 FAST(feature from accelerated segment test)特征检测子[18],使用极大值抑止的方法筛选特征点。针对检测速度慢的问题,Mair等[19]提出了AGAST(adaptive and generic corner detection based on the accelerated segment test)检测子,BRISK进一步提出了一个多尺度的AGAST检测子,他们以fast得分为衡量指标在不同的尺度空间中寻找极大值,从而找到顽健的特征点。本文综合考虑稳定性和检测速度因素,使用AGAST检测子进行测试。
3.2 测试指标
本文使用2个指标来衡量不同方法的性能,即描述子平均计算时间和描述子正确匹配率。描述子平均计算时间是多次计算时长的平均。描述子正确匹配率按以下步骤计算。
1) 分别计算原图和变体的特征点和描述子。
2) 判断原图和变体的描述子是否匹配,得到总匹配数N。
3) 判断每个匹配是否正确,得到正确匹配数Nc。
3.3 实验结果
首先,测试了RBS描述子的距离分布,即匹配描述子之间的距离和不匹配描述子之间的距离分布。对数据集内每张图片及其变体图片使用 AGAST检测子提取1 000个特征点,并计算对应的RBS-128描述子,进而计算特征点之间的海明距离,图5列出了wall图与其他3个变体的特征点对的距离分布情况,其中,海明距离单位为bit,频率是指对应距离点所占比例。可以看出,匹配点的方差和均值都在不断增大。

图5 wall图片与其不同变体特征点距离分布情况
如图5可知,不匹配点之间的距离大致呈正态分布,均值约为64 bit。匹配点的距离分布也呈正态分布,对于不同的变体图片,匹配点的距离均值不同,第一张图变化和距离均值最小,最后一张图变化和距离均值最大。随着变化程度加剧,匹配点之间的海明距离变化范围逐渐增大,这符合实际情况。
接下来,对不同描述子匹配正确率进行比较,对比对象包括 SIFT(scale-invariant feature transform)[20]、ORB、BRISK、BRIEF、FREAK 这 4种描述子,其中SIFT是最流行的实数描述子,其余3个是主流的二进制描述子。程序采用了 OPENCV中的开源代码或者作者提供的代码,均使用默认参数。对数据集中 wall、graffiti、ubc、boat、tree、leuven的匹配正确率对比结果如图6所示,具体数据如表1所示。

图6 不同描述子正确率对比

表1 不同描述子的正确率对比
通过分析结果可以发现,SIFT平均正确率最高,尤其在有大视角变化和焦距变化的图片(graffiti和boat)下。4种二进制描述子中,随机采样模式(BRIEF和 ORB)性能低于特定模式采样(BRISK、FREAK 和 RBS)。RBS-128分别超过BRIEF和ORB 约8.6%和4.1%,RBS-64则分别超过约4.8%和1.3%,RBS-32优于BRIEF约0.7%,但比ORB低约2.7%。RBS优于512 bit的BRISK,与FREAK性能接近,RBS-32、RBS-64和RBS-128性能随着长度增加匹配正确率不断上升,RBS-128性能最高,其平均正确率超过FREAK约8.4%,超过BRISK约1.9%,正确率提升比例分别达到16.4%和5.3%。二进制描述子BRISK性能高于FREAK,分析可能是由于FREAK并没有很好地模拟视网膜分布,而被使用均匀采样的 BRISK超出。实验还显示,160 bit时匹配正确率相对128 bit已经开始下降,这表明随着点对选择方法能够有效地筛选出稳定点对,随着排序靠后点对数量的增加,描述子开始受到噪声点的负面影响。
最后,使用leuven原图对不同描述子的计算速度进行对比,结果如表2所示。

表2 描述子提取算法速度对比
由表2可以看出,RBS描述子在速度上有很大的优势,比SIFT快了近2个数量级,与其他二进制描述子(ORB、BRISK、BRIEF)相比,也有一定优势,RBS-32和RBS-64均快于其他二进制描述子,而 RBS-128仅慢于对比描述子中最快的FREAK。
4 结束语
本文模仿人眼视网膜细胞分布特性,实现了一种仿视网膜视神经分布和感知特性的采样学习方法,以生成更顽健、更紧致的二进制描述子。实验表明,描述子对光照、旋转、退化、模糊具有较高的顽健性,RBS-128匹配正确率超过512bitFREAK和BRISK二进制描述子,计算性能比SIFT描述子提高了近2个数量级,相比其他二进制描述子也有一定的优势。但是,由于本文的方法仍旧是像素点对之间的比较,对于大角度的视角变化顽健性较低,如图 6中 boat和graffiti,需要进一步研究如何提高二进制描述子对视角变化的顽健性。
猜你喜欢
医学食疗与健康(2022年3期)2022-04-23
合肥工业大学学报(自然科学版)(2021年11期)2021-12-10
中等数学(2021年8期)2021-11-22
现代电子技术(2021年1期)2021-01-17
中华养生保健(2020年7期)2020-11-16
数学大王·低年级(2019年10期)2019-11-25
中等数学(2019年4期)2019-08-30
微型电脑应用(2019年1期)2019-01-23
电脑知识与技术(2018年35期)2018-02-27
家教世界·创新阅读(2016年11期)2016-12-27
