
基于YOLov2模型的道路目标检测改进算法
2019-02-07 05:32宋建国吴岳
软件导刊 2019年12期
宋建国 吴岳

摘要:针对传统道路目标检测算法推荐窗口冗余、鲁棒性差、复杂度较高的问题,提出基于YOLOv2模型的道路目標检测改进算法。相较于传统的HOG+SVM目标检测算法,YOLO模型优势在于提升了检测速度及准确度,更适用于实时目标检测。比较YOLO V3与YOLO V2算法,前者在构造神经网络模型时复杂度较高,故最终选择YOLO V2算法。针对原算法中选取AnchorBoxes时所采用的K-MEANS算法造成的目标物体框冗余问题,以及原算法对于不规则物体以及遮挡物体检测效果较差等问题,提出基于YOLO V2模型的一种改进方法,将K-MEANS算法改进为一种DA-DBSCAN算法,通过动态调整参数的方式大大减少了锚点框冗余问题。实验表明,改进后的模型准确率达到96.76%,召回率达到96.73%,检测帧数达到37帧/s,能够满足实时性要求。
关键词:目标检测算法;鲁棒性;深度学习;不规则;DA-DBSCAN;锚点框
DOI:10.11907/rjd k.191279
中图分类号:TP312 文献标识码:A 文章编号:1672-7800(2019)012-0126-04
0引言
传统的目标检测算法大多基于计算机视觉对已经形成的图像进行多步分析,在卷积网络问世之前DPM(De-formable Parts Model)是一个可行的目标检测算法。该算法采用SVM(支持向量机)加HOG(梯度直方图)对经过处理的图像提取特征进行分类,但在整个目标检测过程中,对于区域选择阶段的目标窗口推荐容易造成推荐窗口冗余现象,大多推荐的目标窗口不能利用。后来卷积神经网络问世,在深度学习领域结合计算机图像图形学等多项技术,在目标图像的复杂特征提取方面有了巨大进步,使得目标检测的精确率和召回率得到极大提升。
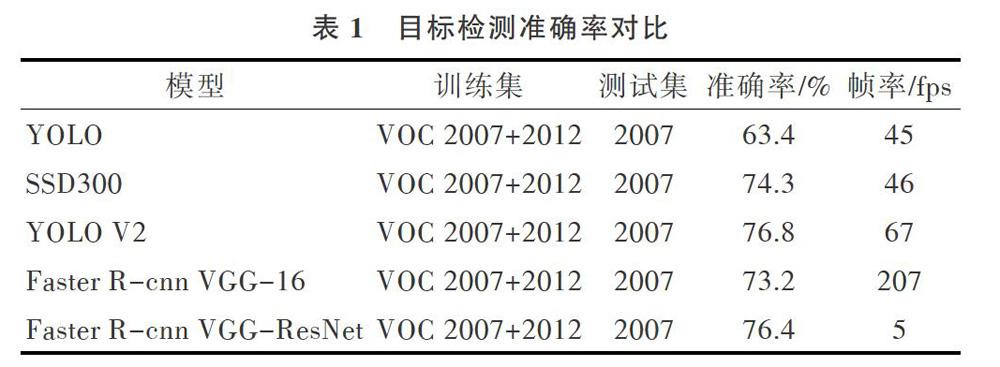
之后产生了一系列目标检测算法:在CVPR大会上提出的RCNN(Reigions with CNN),通过探索性选择滑动目标窗口形式,生成有可能包含被检测物体的目标窗口,并且逐一采取分类器识别方式对所有窗口进行识别,然后通过对候选滑动窗口的处理去除冗余窗口;Fast-Rcnn以及Faster-Rcnn逐渐将提取特征图的部分与分类部分合二为一,前者将特征图输人到一个全连接层中,从而得到相应的回归判定,后者则将提取特征图部分融合到神经网络中,实现了一体化操作。这两种算法将VOC 2007上的MAP分别提升至70%、73.2%。多模型在相同数据集上的对比表现如表1所示。
DIVVALA等学者提出将回归思想融合到常规目标检测过程中,从而形成了YOLO模型。但是YOLO算法同传统目标检测算法SSD:一样具有定位不准确问题。之后在YOLO算法基础上改进,提出了YOLO V2算法。与传统的多分类尺度候选框选择方式不同,YOLO V2使用聚类算法K-means作为Anchor Boxes选择规则,进一步提升了速度,并且在VOC 2007上的MAP表现达到了前所未有的78.6%。
笔者在利用YOLO V2模型进行目标检测时发现,其对不规则目标的识别准确度不高,并且在出现物体半遮挡情况下并不能正确识别目标物。为此,提出用DA-DB-SCAN算法替代K-means进行候选框筛选,并对神经网络结构进行调整,使其更适合道路目标实时检测。
1YoLo V2算法
1.1算法结构
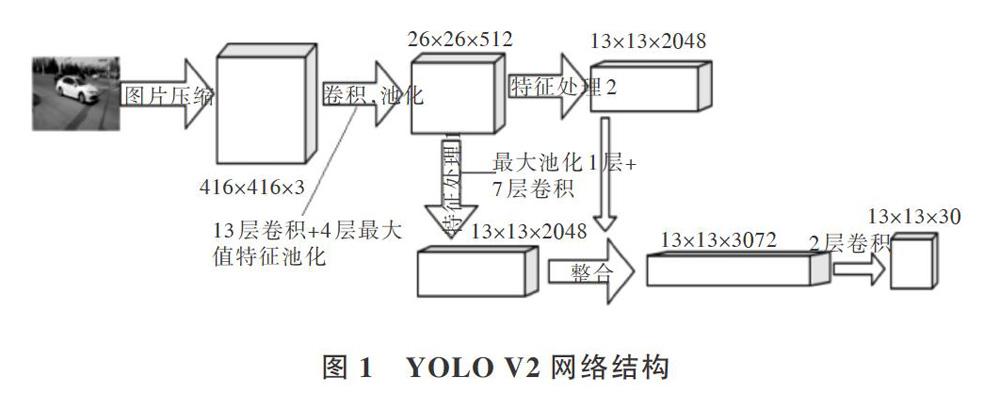
相较于Faster-Rcnn以及YOLO V1,YOLO V2采取了一系列调优算法。从整个网络训练速度看,YOLO V2采用了Batch Normalization(批量归一化)处理,在每次完成网络卷积后,将特征数据进行归一化处理,这样一是提高了整体网络的训练速度,二是去除了一部分的离群数据。为了获取更准确的目标框信息,在YOLO V2模型的末尾全连接层替换为锚点框对检测目标进行预测。
本文实验网络结构如图1所示。首先将图片通过Normalization统一到YOLO V2网络模型中,统一图片输入大小。经过模型中定义好的13层卷积并采用Maxpool池化策略进行4次池化,然后将提取出来的特征图再次进行卷积与池化,最终对经过处理后的整合结果进行卷积操作,生成13"13*3072的特征图。
1.2模型评价方法
物体检测主要判断是否检测到物体以及检测到的物体是否被正确分类,所以可划分为一个广义的二分类问题,最终达到以较高的准确率检测出目标物体并能够正确对检测出来的目标进行分类的目的。在此采取观察模型训练时的召回率与准确率判定模型优劣,做出以下定义:①正确检测出物体且正确分类:TrueObject;②正确检测出物体但分类错误TrueFObject;③不是正确目标物体但被检测出为目标并分类:FalseObject;④目标是具体目标物但并没有被检测出来:FalseFObject,以此定义评价模型优劣的准确率以及召回率计算表达式见式(1)、式(2)。
2DA-DBSCAN算法
2.1算法分析
在YOLO V2模型中将原有YOLO模型和Faster-Rcnn中的候选框选择策略,由传统的人工定制多尺度候选框选择策略改良为使用K-Means算法,该方法在去除无关候选框时效果显著,能将同一张特征图上的同类目标以更加准确的效果聚为一类,但同时也带来算法自身的弊端:首先对不同特征图的超参数K值选择计算量较大,其次由算法本身带来的不规则物体识别效果较差,并且在目标前存在遮挡物时无法正确识别目标。
传统DBSCAN算法虽然能够解决不规则物体识别和聚类数量超参数选择问题,但是随之而来的超参数调节问题增加了模型复杂度,对此提出改进算法:Mimarogli提出基于位向量的分类切割方法,缩短原有算法的执行时间;Zhou分析了算法中两个超参数(Eps,MinPts)的手动设置问题,发现两者的排列符合数学中数理特征,能通过某种算法自适应地确定全局变量;Liu提出一种依据维度的相对排序坐标,将核心对象外的邻域点作为种子拓展聚类,从而减少同一特征的查询次数,提高聚类精度,降低对特征环境以及阈值的依赖性;Kellner提出了一种基于网点的DBSCAN算法,解决了输人参数问题。
综上所述,本文提出的DA-DBSCAN(Dynamic Adjust-ment-DBSCAN,动态调整-DBSCAN)算法在目标聚类上避免了K-Means算法带来的不规则物体无法正确识别问题,并能动态依据特征数据调整超参数Eps和MinPts,从而节省大量人工调参的时间消耗,在存在遮挡物时识别效果较原有算法有小幅提升,提升了目标检测的召回率和准确率。
2.2算法实现
由于特征密度测量数据单一,本聚类中主要是聚类密度差异较小的目标物,故定义距离公式如下:
式(3)中Distrbutionn×n是一个对称阵,内部是每个目标元素i与目标元素j之间的距離。根据矩阵中的距离数据绘制K-DIST分布图,从而反映本特征图中目标之间的距离变化。本文实验的K-DIST图如图2所示。
从图2可以看出,大部分数据落在相对集中的距离分组中,可通过数理统计中的方法识别出距离急剧下降位置的数值大小,帮助判定出半径参数Eps。随后对特征数据进行高斯曲线拟合,同时使用SSE和RMSE作为曲线拟合的评价参数,经过多次试验将RMSE调整至1附近,这时对数据的拟合更加准确。多项式拟合曲线如下:
2.3算法分析
通过高斯函数曲线拟合的方式可以更好地去除离群的特征值,更大程度上排除一些不包含实际目标物的An-chor Boxes,并通过将密度积累算法DBSCAN与统计学中的曲线模型相结合的方式,基于数理统计通过动态调节方式计算出最适合每一张特征图的全局最优超参数Eps和Mint'ts。
3模型实验
为验证相关模型的可行性,本文使用多种不同算法模型进行召回率与准确率比对,最终展示模型效果。
3.1实验数据与结果
本文采用标准数据集加实况道路视频采集的1583张图片自制数据集库,随机选取其中1215张作为训练集,剩下的368张作为测试集,经过缩放输入,对改进后的YO-LO V2模型进行效果监测,人工数据集参数如表2所示,实验效果如图3所示。
3.2实验分析
将训练集中的数据导人到改良后的YOLO V2模型中进行训练,在大约经过25h的训练下,迭代110000次后得到最终的目标检测模型,采用验证集的368张实时图片进行验证,同时对于两种传统目标检测算法在相同的硬件情况下进行训练,使用相同的验证集进行验证,最终对3种算法模型进行评价对比,结果如表3所示。
Faster-RCNN算法是在R-CNN算法之后经一系列优化算法改进后形成的,是目前效果较好且经典的目标检测算法,具有极强的代表性。本文将改良后的YOLO V2算法与原算法以及Faster R-CNN进行效果对比,如图4、图5所示。从图4、图5可以看出,3种算法准确率都在一个较高数值上,但是在召回率方面,改良后的YOLO V2算法体现出DA-DBSCAN算法的优势,对遮挡物体以及不规则物体的召回率较高,达到了96.73%。在实时性方面,改良后的算法模型在每秒检测帧数上比Faster R-CNN效果好,并且远高于传统的DPM算法效果,达到了37帧,s,足以满足实时性要求。从图3(d)、图3(e)中可以看出,经过改良后的YOLO V2算法对不规则目标如车内的人以及遮挡目标的检测效果方面有所上升,与原模型相比在目标召回率上有所提升,且在执行速度上略有提高。
4结语
本文针对原YOLO V2模型对小物体、不规则物体、遮挡物体检测效率低的问题,对原有算法进行改良,通过更改原模型中的目标特征图锚点框选择策略,提升目标物检测的准确度和召回率,对特殊物体做到不漏检。后续将应用到无人设备,与多种传感器组合,进一步提升现有物体检测设备的准确度,开发出更加快速、精准的目标识别算法并应用于实际。
猜你喜欢
科技研究·理论版(2021年22期)2021-04-18
农业机械学报(2020年2期)2020-03-09
中华建设(2019年7期)2019-08-27
系统管理学报(2018年2期)2018-08-13
江苏教育·中学教学版(2016年11期)2016-12-21
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
项目管理技术(2016年12期)2016-06-15
西南交通大学学报(2016年6期)2016-05-04
