
保精度-稀疏特性的最优上边界回归模型辨识
2019-02-06 10:56刘小雍张南庆阎昌国
重庆理工大学学报(自然科学) 2019年12期
刘小雍,张南庆,李 青,阎昌国
(遵义师范学院 工学院,贵州 遵义 563006)
近年来,众多复杂过程自动化概念的应用,如基于模型和数据的模型预测控制及故障诊断等,都需要实际被控系统或过程的静态以及动态行为的精确数学模型[1-2]。然而,大多数物理系统包含复杂的非线性及耦合关系等因素,导致很难建立准确的数学模型。此外,对来自控制系统中的过程参数变化、外部干扰或传感器失效也对控制系统的设计增加了诸多不确定性[3-4]。这些现象的存在更需要探索一种更有效的建模方法,能实现复杂的输入-输出映射及非线性函数逼近。因此,出现了基于数据或数据驱动的建模方法[5-6],即通过传感器或其他数据设备获取被控系统的输入-输出数据,采用神经网络(NN)[7-8]、T-S模糊模型[9]、支持向量机[10]以及相关向量机(RVM)[11]等方法建立复杂系统的数学模型。这些方法的共同特点是建立的数学模型一般从拟合精度角度出发来考虑,不受系统参数、测量噪声或其他不确定性等因素的影响,具有一定的局限性:①基于训练数据建立的数学模型结构复杂、泛化性能差;②确定的数学模型不能自适应系统的变化。
基于经验风险最小化的数据建模方法得到了广泛研究。例如在NN、TS模糊模型的参数辨识过程中,主要考虑如何最小化模型的预测输出与实际输出之间的偏差,其中L2-范数的经验风险最小化准则[12-14]以及基于卡尔曼滤波的参数的估计方法[15-16]用得较多。然而仅从建模精度来看,经验风险最小化准则确实可以以任意的精度逼近任意的非线性系统,但容易陷入局部最优,导致模型结构复杂[17]。因此,有必要引入对模型结构复杂性的控制。文献[18]从模型稀疏角度出发,在前馈NN中引入稀疏描述概念,对模型的初始结构进行优化,用于正确选取最小化输出残差的重要隐神经元,权值及偏差项的调整仍然采用最小二乘标准。为了解决模型精度以及泛化性能之间的平衡,文献[19]引入了结构风险最小化准则作为目标优化,极大提高了模型的泛化性能。
结构风险由经验风险和控制模型结构的Vapnik-Chervonenkis(VC)维组成,其中VC维对模型结构起着至关重要的影响。随着不敏感域损失函数的引入,支持向量机(SVM)被扩展到回归问题,即支持向量回归(SVR)[19],已成功应用于最优控制、TS模型的初始结构选取、时间序列预测以及非线性系统建模等。鉴于SVR中的结构风险最小化原理在各种应用中的优越性,文献[13]将Hammerstein系统的动态线性部分与静态非线性部分辨识构造为最小二乘-SVR(LSSVR)架构,并对动态部分采用LSSVR辨识。在TS模型的后件参数辨识中,为了克服传统的经验风险最小化所带来的缺陷,文献[20]基于LSSVR分解建立了一种新的代价函数求解后件参数。从上述基于数据的建模方法来看,主要集中在确定性建模方法的研究,即获取到的数学模型是确定的点输出,其模型结构保持不变,同时也不受系统参数变化、测量噪声以及其他不确定性因素的影响。然而,在众多的实际应用中,获取的信息往往呈现出不确定、不准确以及不完整等特征,若仍采用传统的确定性数学模型建模,显然不能更好地去捕捉这一类不确定性复杂系统的特征变化。因此,本文将基于SVR的结构风险最小化原理与逼近误差的L1范数相结合,建立了保模型精度-稀疏特性的最优上边界回归模型建模方法。首先,建立满足上边界回归模型的约束条件。其次,将结构风险的L2范数转化为简单的L1范数优化问题,并将回归模型与实际测量数据之间的逼近误差的L∞范数融合到结构风险的L1范数优化问题,再应用较简单的线性规划对双范数的优化问题进行求解并获取模型参数。所提出方法的最优性体现在:①上边界模型的建模精度通过逼近误差的L1范数得到保证;②模型结构复杂性在结构风险的L1范数优化条件下得到有效控制,进而提高其泛化性能。
1 支持向量回归的L1范数优化问题转化
支持向量回归[17,21](support vector regression,SVR)是将基于二范数的结构风险最小化作为优化目标,实现对回归模型结构复杂性的控制,从而提高模型的泛化性能;然而,在文献[22]中指出,SVR中的优化目标求解采用的是二次规划,会产生模型的冗余描述以及昂贵的计算成本;同时,L2范数的优化问题不能直接用于本文提出的最优下边界回归模型辨识的优化问题,需要进行L2范数到L1范数的转化。对于二次规划-SVR(QPSVR)的优化问题,

其中:φ(·)表示从输入空间到高维空间的非线性特征映射,即为松弛变量,分别对应超出正、负方向偏差值时的大小;常量γ大于0,反应非线性f与偏差大于ε时两者之间的平衡。对于式SVR模型f有,


其中β=(β1,β2,…,βN)T。对于式(2)的优化问题,范数的引入是为了控制模型的复杂度,根据范数的等价性可知[23],在结构风险中引入其他范数也可以同样对模型结构复杂性进行控制。因此,可考虑将QP-SVR的优化问题(1)变成

其中f(x)以式(2)形式描述,表示系数空间的L1-范数。因此,新的约束优化问题为[24]

从几何的角度来看,ξk和之间的关系在SVR中满足因此,在优化问题(5)中仅引入松弛变量ξk即可[22],即
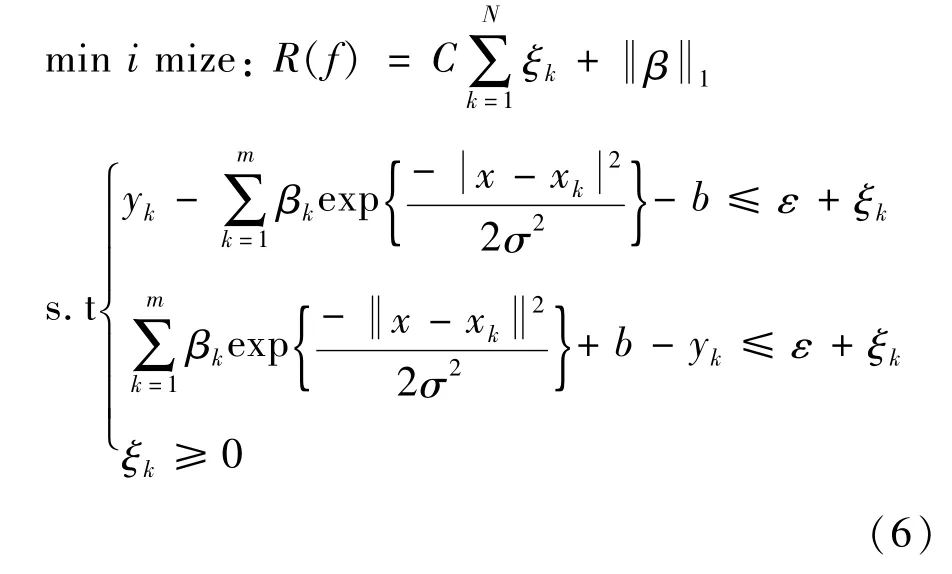
为了转化上述优化问题为线性规划问题,将βk和|βk|进行如下分解[25],

其中α+k,α-k≥0。考虑到α+k和α-k不能同时大于0,对应3种不同情况的解,即(α+k,0)、(0,α-k)、(0,0),因此式(7)的分解是唯一的。下面对线性规划问题(6)在式(7)的分解下,α+k和α-k不能同时大于0进行简单证明。采用反证法,假设在优化问题(6)的最优解中存在某一个k,使得α+k和α-k同时大于零,现取τ=min(α+k,α-k),将α+k和α-k分别换成α+k-τ和α-k-τ,仍然满足α+k-τ>0和α-k-τ>0,但是目标函数中的α+k+α-k将减少α+k+α-k-2τ,这显然与最优解的假设相矛盾。因此,α+k和α-k不能同时大于0,即α+k·α-k=0。
基于式(7),优化问题(6)进一步为
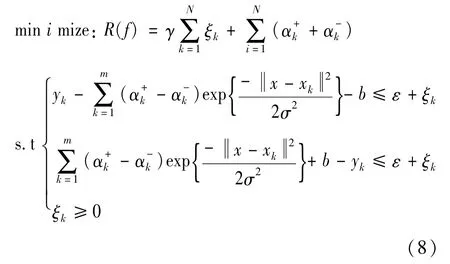
现定义向量

向量β的L1-范数表示为

α+=(α+1,α+2,…,α+N)T,α-=(α-1,α-2,…,α-N)T。以向量形式将优化问题(8)构造为标准的线性规划问题如下:

其中:ξ=(ξ1,ξ2,…,ξN)T;I为N×N的单位矩阵,y=(y1,y2,…,yN)T
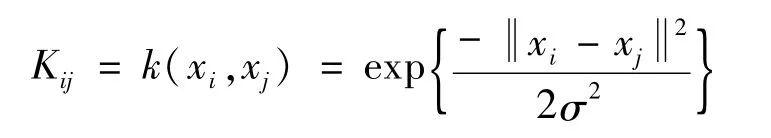
线性规划问题(9)可通过单纯型算法或原-对偶内点算法进行求解[26]。对于QP-SVR,在ε域之外的所有数据点将被选择为支持向量(SVs);而对于LP-SVR,即便ε域选择为0时,由于软约束在优化问题中的使用,LP-SVR仍然能够获取稀疏解。通常情况下,稀疏解往往通过设定非零的ε域来获取。
2 基于L1-L∞范数的最优上边界回归模型辨识
在完成SVR的优化问题从L2范数到L1范数转化之后,接下来将从保精度以及保稀疏特性的角度出发建立最优UBRM。如图1所示,提出的方法将从2个重要指标来辨识最优UBRM,其中保模型辨识精度通过引入最小化所有模型输出与实际输出之间的逼近误差最大值来实现,即逼近误差的L∞范数优化问题。另一方面,辨识精度太高会导致模型结构复杂,出现模型过拟合问题,因此引入结构风险最小化对模型结构复杂性进行控制,即保模型的稀疏特性。接下来,先从保模型辨识精度讨论逼近误差的L∞范数回归模型辨识问题。

图1 最优上边界回归模型辨识方法流程
2.1 逼近误差的L∞范数回归模型辨识
假设通过传感器或数据获取设备获取一组测量数据{(x1,y1),(x2,y2),…,(xN,yN)},其中{x1,x2,…,xN}描述输入测量数据,对应的输出定义为{y1,y2,…,yN}。设测量满足如下非线性系统模型
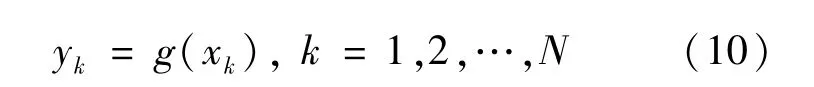
根据统计学理论可知[27],存在以式(2)描述的非线性回归模型f对测量模型g的任意逼近,当逼近精度越小时,需要的支持向量越少;反之,逼近精度越高,则支持向量越多。因此,对任意给定的实连续函数g及较小的正实数η>0,存在如下回归模型f满足

由于下边界回归模型是基于获取到的输入-输出数据来辨识的,其中集合S是指被建模对象的数据输入集。值得指出的是,较小的η值,对应式(2)较多的支持向量。现讨论回归模型中式(2)的另一种参数求解方法。在非线性系统模型的逼近情况下,定义实际输出与由式(2)定义的SVR模型输出之间的偏差ek,

为了估计SVR模型的最优参数,考虑如下最大建模误差的最小化:
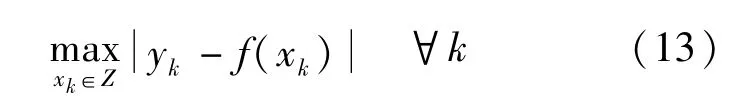
Z表示整个输入数据集。显然,这是一个最小-最大(min-max)优化问题。在式(2)描述的回归模型情况下,式(13)的最小化可通过2个阶段完成:①核函数中的核宽度σ的参数寻优,通常采用经典的交叉验证或其他方法来实现,其详细过程在本文中不再讨论;②式(2)的参数确定可通过min-max优化问题求解,即

定理1min-max优化问题中的参数可通过最小化λ,且满足如下不等式约束的线性规划求解,即

其中:β=(β1,β2,…,βN)T和b为被求解参数;λ表示最大逼近误差。

证明定义λ如下,

可直接得出如下不等式,
根据去绝对值运算,可知式(15)的约束条件成立。
2.2 基于L1-L∞范数的最优上边界回归模型辨识
假定不确定非线性函数或非线性系统属于函数簇Γ由名义函数gnom(x)和不确定性Δg(x)两部分组成,

其中不确定性Δg(x)满足R+。现考虑来自函数簇Γ的成员函数g,x∈Rd,对应输入x上的测量输出Y={y1,y1,…,yN},即yk=g(xk),g∈Γ,xk∈S,k=1,2,…,N。UBRM建模的思想是,在满足约束(11)的条件下,建模下界回归模型f(xk),

在式(19)约束的意义下,来自函数簇的任一成员函数总能在UBRM上方中找到。显然,这样的UBRM有无穷多个,提出方法的目的就是根据提出的约束(11),确定尽可能逼近成员函数的上界。本文是通过将L∞范数、结构风险最小化理论以及线性规划相结合,给出UBRM 更好的逼近。由式(3)给出UBRM的表达式,

UBRMf(x)可通过线性规划对如下优化问题进行求解:

定理2对于UBRMf(x)的参数β,b的求解,对应min-max优化问题(2.12)可通过最小化λ,且满足如下不等式约束的线性规划求解,即
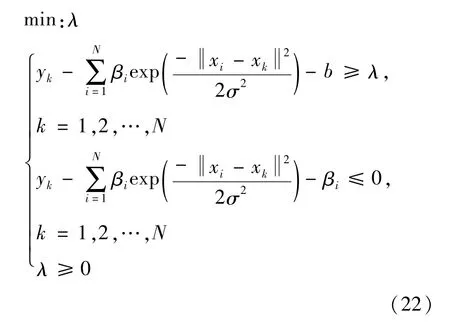
其中λ表示最大逼近误差。
证明定理2可直接通过定理1推出。
从上述回归模型辨识的思想来看,仅考虑上边模型输出与实际输出之间的逼近误差,而回归模型本身的结构复杂性却没有被考虑,这样一来,通过上述优化问题获取的参数解有可能出现不全为零的情况,不具有稀疏特性,对应N个样本数据可能都是支持向量,导致模型结构复杂。为了解决模型稀疏解的问题,在求解上边界回归模型的优化问题中,有必要将结构风险最小化的思想融合其中,在保证回归模型逼近精度的同时,尽可能让模型结构复杂性得到有效控制。基于此,将上边界回归模型优化问题(14)融合到基于结构风险最小化的优化问题(3)。因此,对于带有稀疏特性的下界回归模型f(x)的优化问题,有

其中:λ表示最大逼近误差;参数α+k、α-k、b、ε、ξk与第二节的定义一样。
从优化问题(23)可知,作为典型的线性规划问题,可用向量及矩阵形式表述如下:
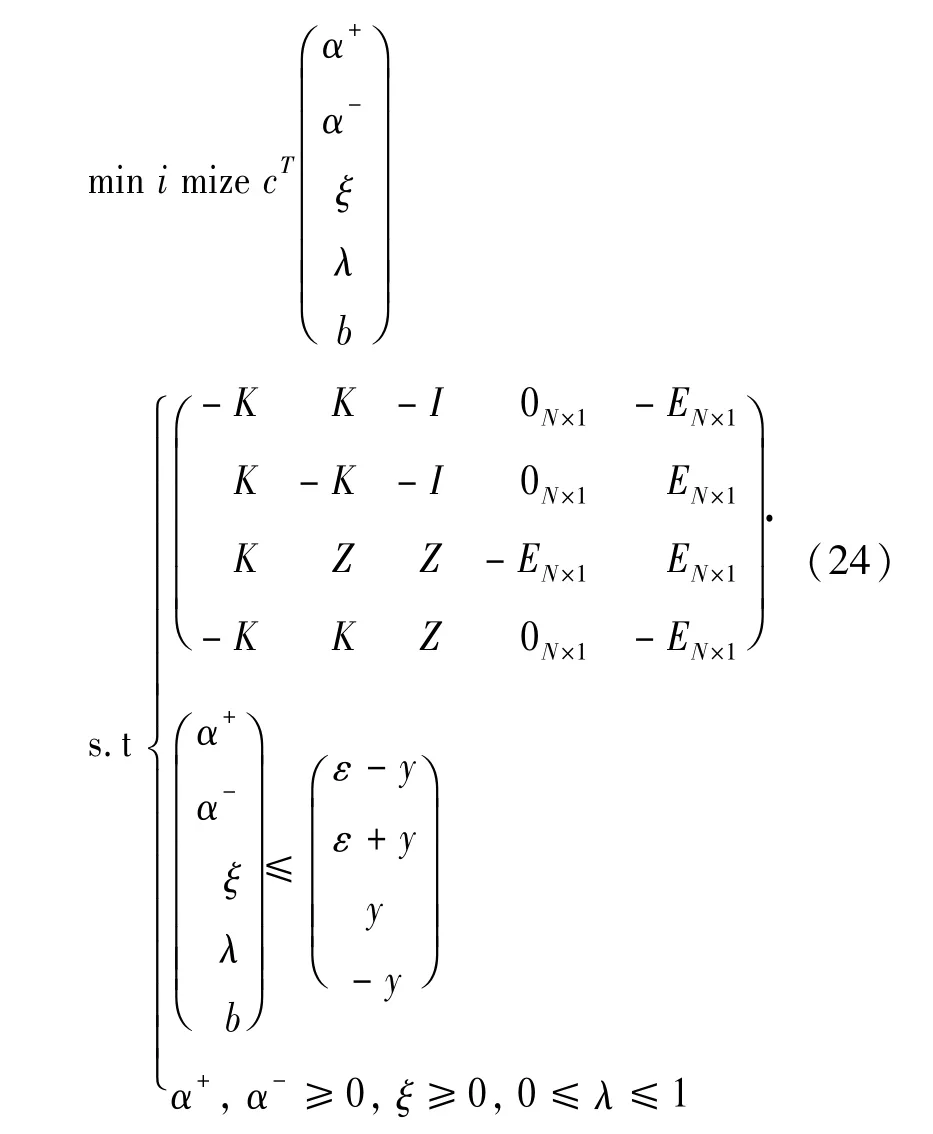
其中:
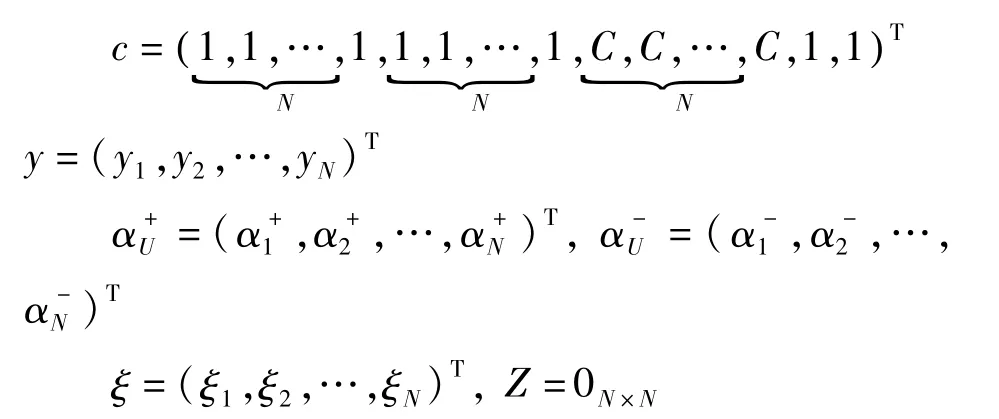
I为N×N的单位矩阵;E=1N×1;核矩阵K的元素定义为

σ为可调核参数。
显然,应用内点法或单纯性方法可以求解优化问题,进而得到下界回归模型f(x)。
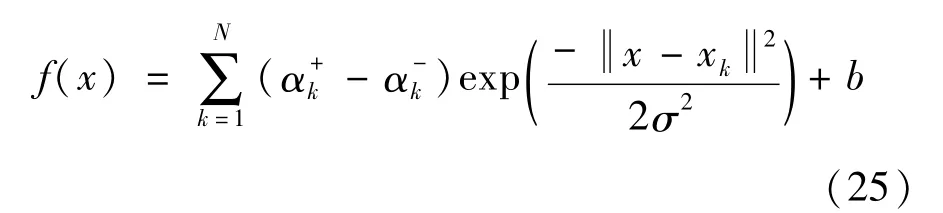
从应用提出方法来建立OLRMf(x)的整个过程来看,优化问题既包括了对模型结构复杂性控制的目标函数,又包括了如何获取较好的模型精度所对应的逼近误差作为目标函数,而且模型结构复杂性控制和模型精度之间的权衡可以通过规则化参数进行调整。总而言之,提出方法在保证获取下界模型建模精度的同时,而且还对模型结构复杂性进行有效控制,从而提高下界回归模型的泛化性能。
3 实验分析
为了论证提出方法的合理性与优越性,将从保精度和保模型稀疏特性两方面展开提出方法的实验论证,其中保精度是通过均方根误差(root mean squares error,RMSE)指标进行评估,定义如下:

其中:N表示所获取测量数据的总数;y(k)为第k个实际测量数据;f(xk)对应提出方法的上界模型预测输出,如式(25)定义。从提出的方法来看,对于UBRM,必满足f(xk)-y(k)≥0,但满足该条件的f(xk)有无穷多个。因此,在保证f(xk)-y(k)≥0恒成立的条件下,f(xk)与y(k)之间的偏差越小越好,即通过RMSE指标进行评估,若RMSE越小,UBRM建模精度越高,反之较低。
显然,较高的建模精度,通常情况下会引起UBRM的结构更复杂,丧失模型结构的稀疏特性,泛化性能变差。为了对模型结构的稀疏特性进行有效评估,将采用在所有N个测量数据中,对模型结构本质上起贡献作用的测量数据,即支持向量(support vector,SV)所占百分比,即SVs%,用于评估UBRM的稀疏特性,其定义如下:

其中Nk表示SV的个数,对应优化问题(24)的求解中,当被求解参数满足条件α+k-α-k≥δ时,则对应的k个输入数据xk为SV,δ为较小的正数,在实验仿真中,取δ=10-8。当SVs%越小时,用于建立UBRM的SV个数就越少,对应模型较好的稀疏特性,但模型的辨识精度会降低。因此,根据不同建模需要,应从既能保模型精度,又能保模型稀疏特性之间取其平衡。
下面将从来自模型参数不确定性和测量数据不确定性两个方面,应用提出的方法建立由不确定性所引起的UBRM。虽然基于数据的建模方法很多,包括T-S模糊模型、支持向量机、神经网络等,但这些方法主要是从模型逼近和拟合的角度进行建模,而本文提出的方法是建模所有不确定性参数以及不确定性测量数据的上边界模型f(x),且满足条件f(x)≥y(k),同时对UBRM的建模精度以及模型结构稀疏特性进行有效控制。先考虑来自参数不确定性的UBRM 辨识的试验分析。

其中被建模对象g(x)由名义函数fnorm(x)以及不确定性参数τ引起的不确定性两部分构成,设τ的取值范围[0,1],x的定义域[-1,1]。为了建立UBRM,基于式(28)~(30)获取样本数据,不妨取xk=0.021k,k=-47,…,47。图2给出了由不确定性参数τ引起的不确定性输出,对应τ={0,0.2,0.4,0.6,0.8}。应用提出的方法建立不确定性输出的UBRM如图3所示,其中超参数集(ε,γ,σ)选择为(0.004,100,40),建立的UBRM在满足f(xk)-y(k)≥0条件下,仅用了4个支持向量(SVs),即从95个测量数据中,真正对UBRM起决定性作用的只有4个数据,SVs%为4.21%,同时表明UBRM具有较好的稀疏特性,对应模型结构简单;然而UBRM 的建模精度变差,即RMSE为0.137 2,其建模误差如图4所示,红色实线表示零水平线,所有的逼近误差都在其上方,意味着f(xk)-y(k)≥0。当核参数σ为8.0时,如图5所示,红色实线表示提出方法建立的UBRM。
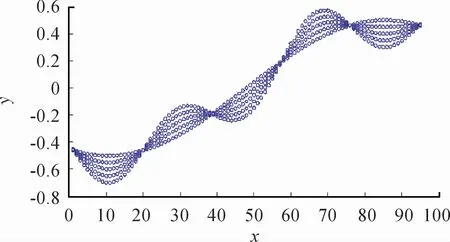
图2 由不确定性参数τ引起的输出
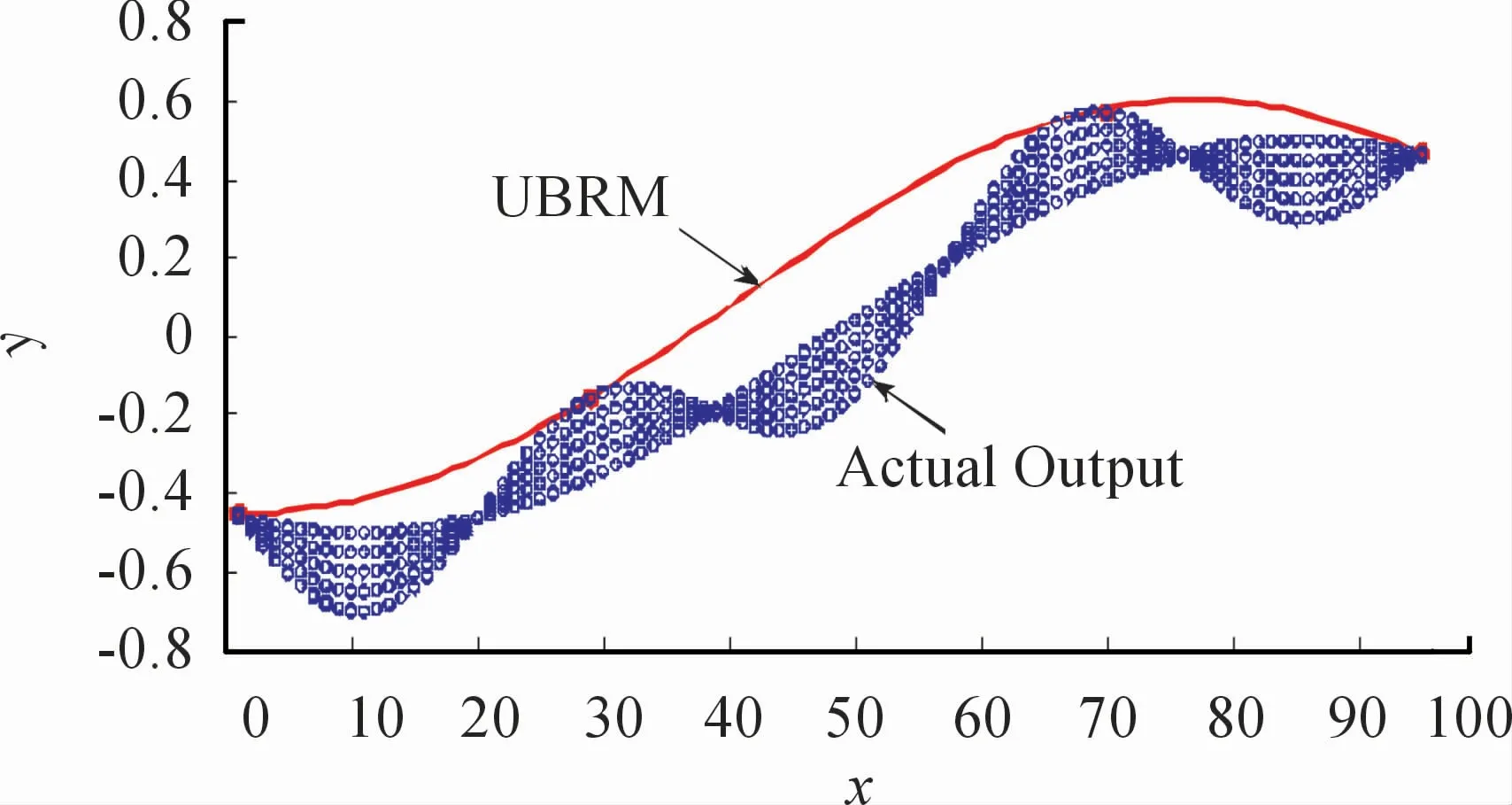
图3 所建立的UBRM,其中红色实心圆表示4个支持向量(SVs)
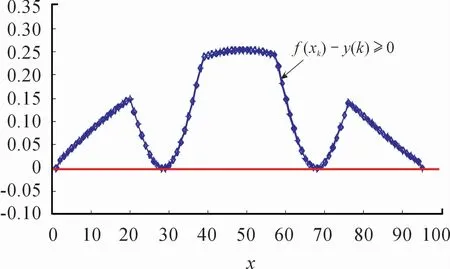
图4 核参数σ为40时的逼近误差
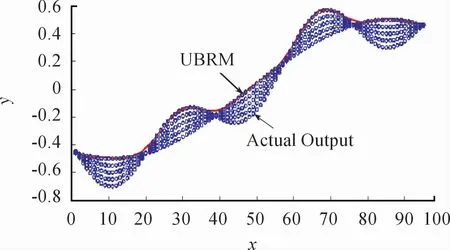
图5 所建立的UBRM,其中红色实心圆表示15个支持向量(SVs)
图5的红色实心圆描述的SV相比于图3建模精度有较大改进,对应的RMSE为0.008 8;从稀疏特性角度来看,对应SVs%为16.84%,从95个测量数据中用于建立UBRM只用了15个数据。因此,无论是建模精度还是模型稀疏特性,UBRM均得到保证,建模误差如图6所示。为获取UBRM保精度以及保稀疏特性之间的平衡,如图7给出了SVs%和RMSE在不同核参数下的变化曲线,显然,随核参数的增大,SVs%在减小,表明稀疏特性越好;但RMSE随核参数的增大而增大,σ越小,RMSE越小,表明建模精度越高,需要较大的SVs%来保证。因此,SVs%和RMSE之间互为矛盾体,可通过提出的方法可以对模型保精度-保稀疏特性之间取其平衡。
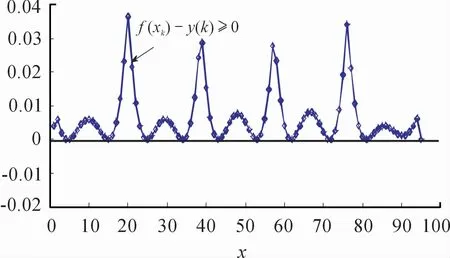
图6 核参数σ为8.0时的逼近误差

图7 RMSE与SVs%在不同核宽度下的比较结果
继上述来自参数不确定性所引起的不确定性输出的UBRM分析之后,接下来考虑如下的非线性动态系统,
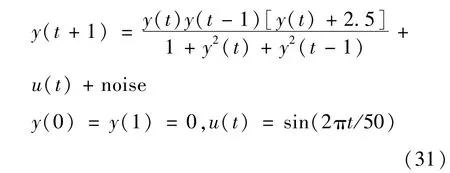
其中noise是均值为0,方差为0.25的高斯噪声。为了建立UBRM,从受噪声影响后的式(31)获取201个测量数据。当核参数超参数σ选择较大时,即σ=25,对应超参数集(ε,γ,σ)为(2.0,1 000,25),建立的UBRM 如图8所示,在满足f(xk)-y(k)≥0条件下,对应逼近误差如图9所示,描述建模精度的RMSE为0.950 5,稀疏特性指标SVs%为0.034 8,表明从201个测量数据仅用了6个数据建立UBRM,这6个数据也就是SV,对应201个测量数据的第k个数据的αk+-αk-≥10-8。

图8 所建立的UBRM,其中红色实心圆表示6个支持向量(SVs)
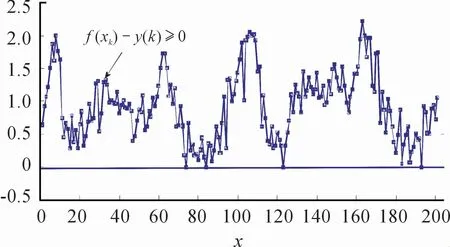
图9 核参数σ为25.0时的逼近误差
如图10所示,对UBRM起贡献作用的第k个数据以蓝色实心圆表示,其他的数据对应{α+k-α-k}≤10-8,对建立UBRM 的贡献可忽略不计,UBRM表达式如下:

既要提高建模精度,又要保证模型的稀疏特性,不妨取核参数σ=7.0,可得UBRM,如图11所示,建模精度相比于图7有较大改进,对应的RMSE为0.484 5;描述稀疏特性指标的SVs%为11.44%,从保精度-保稀疏特性来看,有着较好的输出结果。进一步,当核参数σ为0.6时,RMSE为1.360 4×10-4,具有较高的建模精度,然而描述模型结构复杂的稀疏特性指标SVs%达到了100%,说明在满足约束f(xk)-y(k)≥0条件下,建立UBRM的所有数据都在做贡献,如图12所示,完全丧失了模型的稀疏特性,出现了过拟合问题,逼近误差如图13所示。

图10 对应UBRM的第k个展开项系数≥10-8
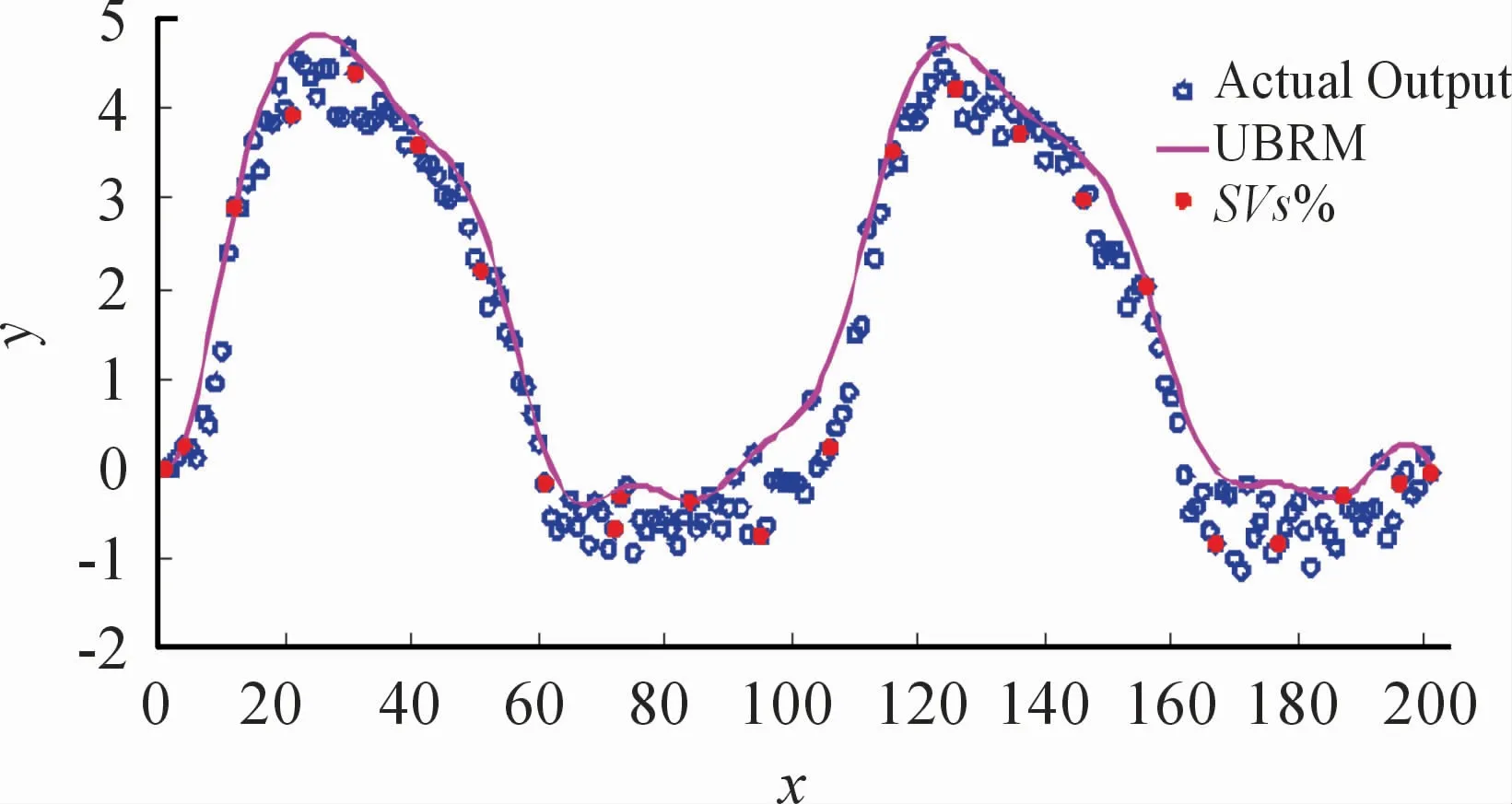
图11 所建立的UBRM,其中红色实心圆表示23个支持向量(SVs)

图12 所建立的UBRM,其中红色实心圆表示所有数据均为支持向量(SVs)

图13 核参数σ为0.6时的过拟合逼近误差
表1给出了在不同核宽度σ下的SVs%和RMSE,从中可以发现,UBRM随核宽度σ的增加,SVs%在逐渐减小,表明建立UBRM所用到的SVs个数减小,模型结构简单,对应较好的稀疏特性;相反,用于反映UBRM辨识精度的RMSE在增加,表明模型的辨识精度降低。因此,反映稀疏特性的SVs%和反映模型辨识精度的RMSE之间是一对矛盾体,在核宽度σ的选取上,应从建模的需要从两者之间取其平衡,不能一味地追求某个指标。事实上,稀疏特性反映的是UBRM的结构复杂性,模型对应的SVs%越小,构造UBRM所需要的参数越少,模型结构相对简单。因此,在保证模型精度的条件下,越稀疏的UBRM,则泛化性能越好。

表1 不同核宽度σ情况下的SVs%和RMSE(ε=0.000 1,γ=1 000)
接下来考虑用提出的方法对如下传递函数在前向通道恒增益参数发生异常时的故障检测:
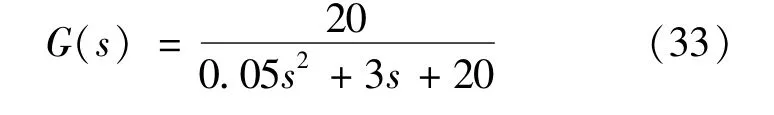
首先通过对系统的传递函数离散化,采样时间为0.01 s,仿真总次数为200,离散后的模型如下
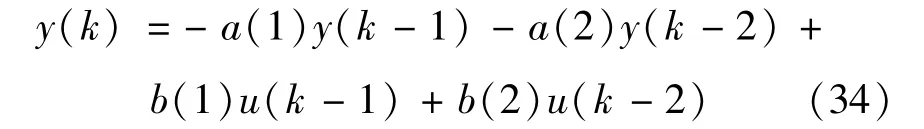
其中:a(1)、a(2)、b(1)、b(2)为离散化后的已知常数;u(k)为已知随机输入信号。基于式(33)构造UBRM的输入向量为
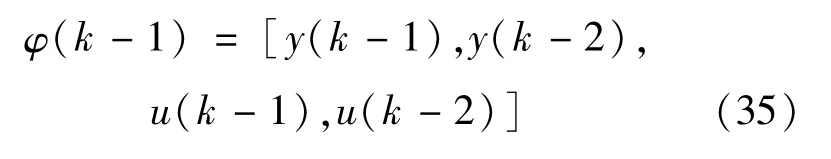
对应输出为y(k)。在系统无故障情况下,获取对应的输入/输出数据,选择参数集(ε,γ,σ)为(0.8,100,5.0),用于描述无故障上边模型(φ(k-1))的稀疏特性SVs%都为1.52%,意味着从输入输出数据建立(φ(k-1))仅用了3个数据(SV,支持向量),表现很好的稀疏特性;此外,从辨识精度来看,(φ(k-1))的RMSE为0.049 9,显然精度满足要求,可用于传递函数在前向通道恒增益参数下的故障检测。假设传递函数(33)没有发生故障,则对应的实际输出不会越过UBRM输出,或通过条件(φ(k-1))-y(k)≥0来判断。当系统(33)发生前向通道的恒增益参数在1.4~1.6 s范围发生异常,对应离散时间k为140≤k≤160,如图14所示,k=140时发生故障,k=141时检测到故障,对应实际输出越过UBRM输出,实际上也可以通过y(k)-(φ(k-1))≥0来判断故障是否发生,如图15所示。

图14 在k=140时发生故障,k=141时检测到故障,对应实际输出越过无故障的区间模型输出
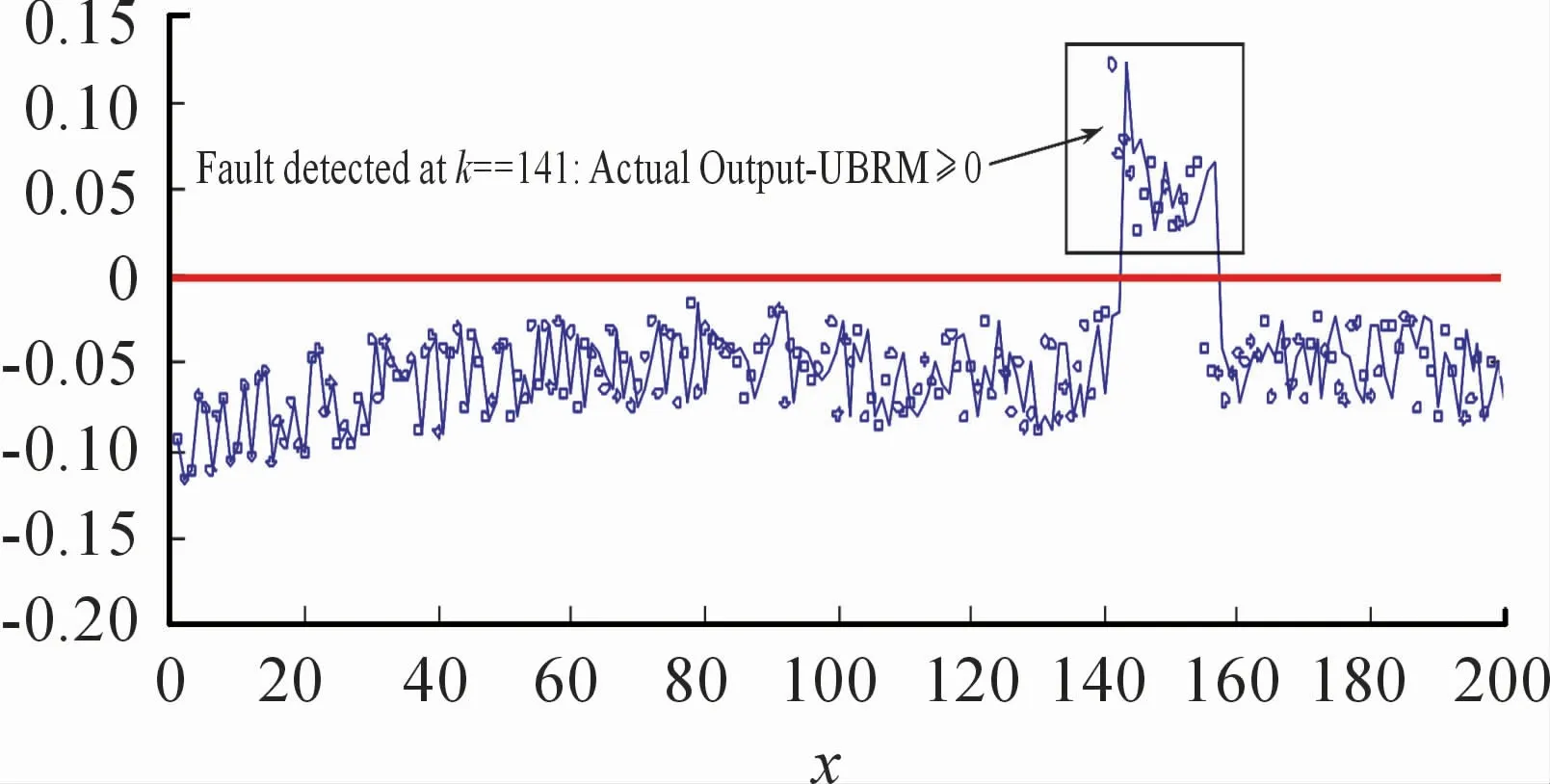
图15 通过条件f(φ(k-1))-y(k)≤0的故障检测
当前向通道恒增益参数无故障时,则UBRM如图16所示,实际输出在UBRM的下方,对应的逼近误差如图17所示,满足条件(φ(k-1))-y(k)≥0。
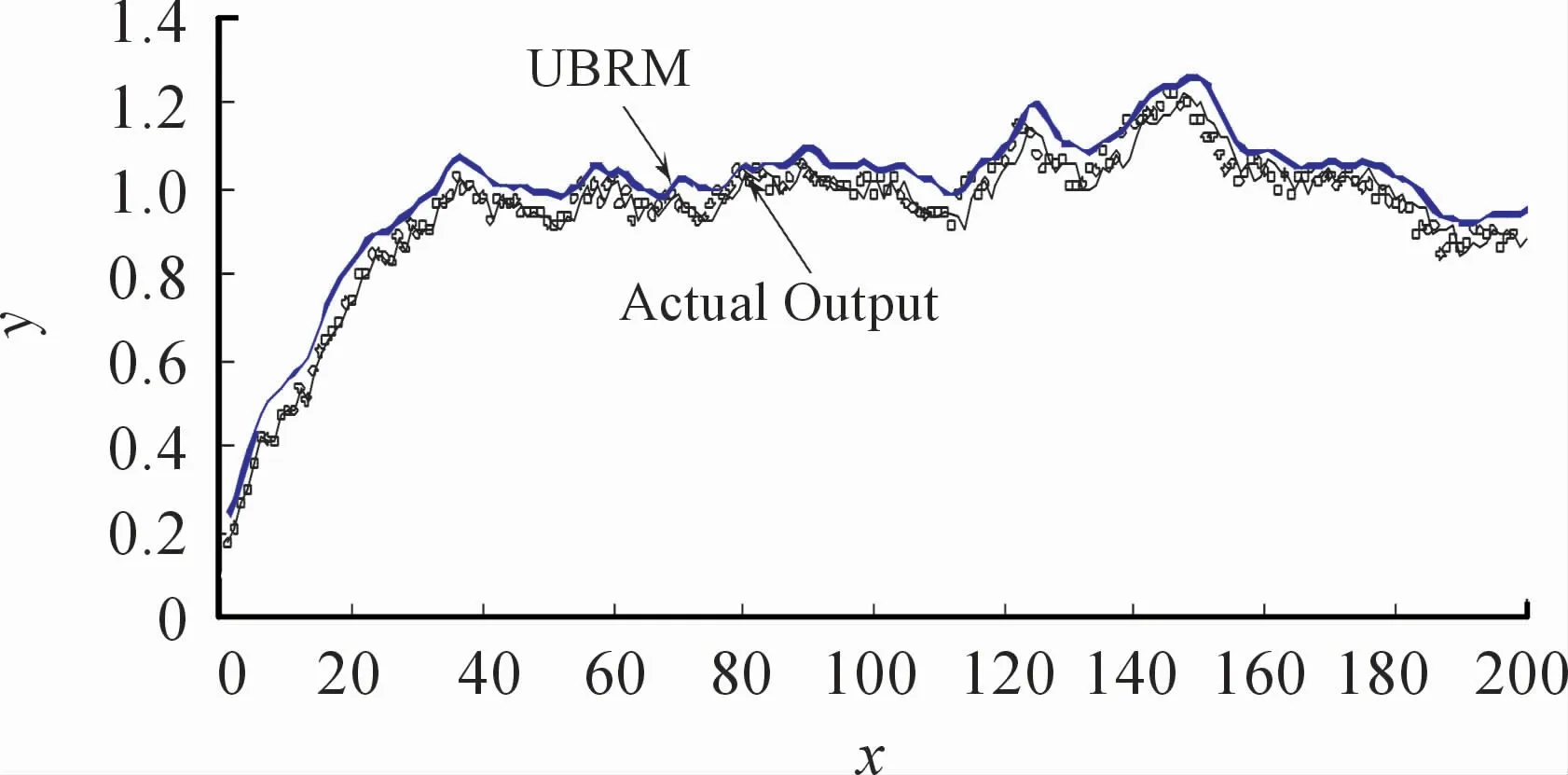
图16 系统正常运行时的故障检测,对应实际输出没有越过无故障的UBRM输出

图17 UBRM无故障的逼近误差,其中(φ(k-1))-y(k)≥0
4 结束语
针对来自模型结构参数以及传感器测量数据的不确定性等因素,建立由这些因素导致的上边界回归模型尤为重要。从保模型辨识精度以及稀疏特性出发,通过将结构风险最小化理论与逼近误差最小化思想相结合,提出了L1-L∞双范数的最优UBRM辨识方法,其中双范数中的L1范数是在结构风险最小化框架下对模型稀疏特性的控制。L∞范数的引入是基于模型逼近误差对模型辨识精度的控制,将两者融合到一个优化问题,可实现UBRM的保精度-保稀疏特性之间的平衡。最后,通过来自两个不确定性的实验分析,即测量数据的不确定性和模型参数的不确定性,从保精度-保稀疏特性两个指标论证了提出的方法。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
现代畜牧科技(2021年4期)2021-07-21
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
安阳工学院学报(2020年4期)2020-09-11
流行色(2020年9期)2020-07-16
家庭影院技术(2018年9期)2018-11-02
中国校外教育(下旬)(2017年8期)2017-10-30
CHIP新电脑(2017年6期)2017-06-19
自动化学报(2016年3期)2016-08-23
高中生学习·高三版(2016年9期)2016-05-14
