
Apriori-KNN算法的警报过滤机制的入侵检测系统
2019-01-24 09:00翟继强马文亭肖亚军
小型微型计算机系统 2018年12期
翟继强,马文亭,肖亚军
(哈尔滨理工大学 计算机科学与技术学院,哈尔滨 150080)
1 引 言
基于特征的网络入侵检测系统(NIDS)在检测过程中可能会产生大量误报,增加了分析NIDS警报的难度,降低了NIDS系统的检测性能[1-3].误报源于NIDS检测方法的固有局限性.基于特征的检测很大程度上取决于一组检测入侵的规则,规则越严格,安全级别越高[4].这种情况下,误报的数量将会增加.放宽规则可以减少误报的数量,但安全级别将同时下降.因此,我们必须权衡考虑低误报率与检测精度之间的关系.
本文提出了利用Apriori-KNN算法的警报过滤器来降低基于特征的NIDS的警报误报率的过滤方法.主要研究在不牺牲安全性情况下基于特征的NIDS如何实现降低误报率.基于特征的NIDS(如Snort)产生的警报,直接输出作为警报过滤器的输入,利用数据挖掘技术对已经输出的警报进行二次处理[5].利用无攻击情况下的“正常”警报对基于特征的NIDS的正常警报模式进行建模,利用基于Apriori-KNN算法对警报进行过滤,误报则直接忽略将真正的警报输出进行处理.
2 相关工作
2.1 KNN算法
KNN算法是数据挖掘技术中的一种分类算法,其中心思想类似于“物以类聚,人以群分”[6,7].KNN依据距离度量从训练集中找出其最近的k个数据点,将k个数据点中的主导标签分配给新数据.若k=1,则新数据点由其最近的数据点确定.由于该算法实现简单和分类有效性,KNN通常被用作标准分类器[8].
2.2 Apriori算法
Apriori算法是一种可以有效地解决频繁项集任务,挖掘关联规则的算法[9].该算法主要利用关联规则的方法进行分类,计算频繁项集与规则.关联规则可以用X→Y表示(X,Y表示相互独立的项集,即X∩Y≠Φ),支持度(sup)和置信度(conf)用于度量其规则的关联强度.
2.3 Apriori-KNN算法

Apriori-KNN算法将关联规则转化为可量化的,然后与KNN算法结合.将是否含有频繁项集Xi(Xi=0或者Xi=1)作为一个属性,作为KNN算法的距离计算公式的变量.bool(Xi)表示是否存在频繁项集Xi,其对每一类的均值为conf(Xi→Yi).结合KNN的距离公式得到新的欧几里得的距离测试样例与训练样例(x,yi)的距离d如公式(1)所示:
(1)
设参数α为向量x词频的均值.X(1)表示为1-项集,X(2)表示2-项集,依此类推.在分类方面,项数多的项集会明显高于项数少的项集,因此设定ki=i的参数对项集 X(k)进行修正.修改距离公式如公式(2)所示:
(2)
在上述阐述的基础上,该Apriori-KNN算法的具体步骤如下:
1)首先对数据集进行预处理.
2)通过步骤1),得到bool模型和vsm模型.
依据信息增益方法对数据进行降维,根据其公式(3)选取前j个特征作为新的bool模型.
(3)
3)根据步骤2)的bool模型进行关联规则挖掘,利用Apriori算法产生频繁项集与规则,计算频繁项集的置信度和其对任意分类的置信度.
4)根据 tf-idf公式计算 vsm 模型关键字权值:
(4)
排序取前K个特征.
5)根据上述更改的KNN距离公式(2)计算测试样例与训练数据集的相似度.
6)通过KNN的分类规则进行分类,为了提高其分类的准确度,该算法使用距离加权表决公式:
(5)
公式(5)中wi=1/i.
KNN算法中取 k 个特征词构成特征词库,而Apriori 算法取 j 个词构成特征项集.根据以上的准备工作,Apriori-KNN算法的分类过程图如图1所示.
Apriori-KNN算法是利用Apriori算法对传统的KNN算法进行优化,解决由文章长短影响的语义关联和词频等问题,从而提高KNN算法分类的准确率.相比于KNN算法,Apriori-KNN算法在分类的准确率和召回率方面均有明显的提高.
3 基于Apriori-KNN算法的警报过滤机制
基于Apriori-KNN算法的入侵检测系统警报过滤机制结构,除了通用 NIDS 结构的部分外,还包括警报过滤模块.如图2所示.

图1 Apriori-KNN算法的分类过程图Fig.1 Classification process of Apriori-KNN algorithm
许多NIDS都是基于规则的,不仅编码实现困难,而且也无法检测到新的入侵行为[11-14].针对NIDS的弊端提出了依赖于数据挖掘的分类方法,利用基于Apriori-KNN算法的警报过滤机制降低误报率.当网络环境受到攻击时,基于特征的NIDS会产生不同于正常安全情况下的警报.而且在某些攻击情况下,可能发出正常情况下不存在的警报类型.该方法用于判断输入的警报序列是否偏离正常情况.如果出现偏离正常情况的现象,判断为可能存在攻击行为,需要做进一步调查.如果产生的警报与无攻击的情况非常相似,判断被攻击的风险很低.

图2 基于Apriori-KNN的算法入侵检测系统结构Fig.2 Based on Apriori-KNN algorithm intrusion detection system structure
下面将介绍如何模拟正常警报模式以及检测偏离状态与正常模式的偏差.在无攻击的情况下,N是由NIDS产生的不同的警报类型,采用N维空间建立正常的警报模式.空间中的数据点P的属性(A1,A2,A3,…,An)表示在时间段为T时不同类型的警报数量.将没有经历任何攻击产生的警报定义为“正常”点,这些警报被认为是“安全的”并被视为误报.如图3(a)表示数据集点表示无入侵行为情况下正常的点.用上述方法为新警报创建新数据点并判断新警报是否为误报.新点(白点)与正常点(黑点)的距离相当于该警报与正常模式的偏离.即新点接近正常点,则被认为是正常的,且认为在这段时间内产生的警报是误报.图3(a)表示是一个正常点的模型示例.如果满足以下任何一种情况,认为新点是异常的:远离正常点(图3(b))或者由正常点不存在的新警报类型组成,此时产生的警报是真正警报.
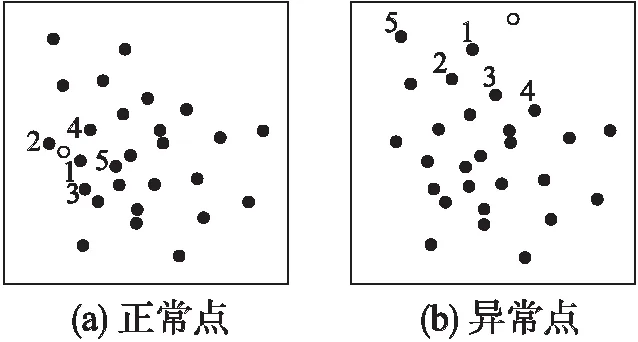
图3 误报模型中的正常点与异常点示例-标号的数据点(黑点)是离新数据点(白点)最近的5个点Fig.3 Example of normal and abnormal points in the false alarm model-Numbered points are the 5 nearest normal(black)points from the new(white)point
根据以上对于新警报的判断原理,采用Apriori-KNN算法作为分类算法判断新的数据点是否正常.根据Apriori-KNN算法中的距离d判断点与点之间的相似性,距离d越小表示相似性越大.被分类的数据点的最终相似性得分是其距离最接近的k个正常点的距离的平均值.相似性数值高于阈值T,则该点被认为是异常的.反之说明属于误报,应该被过滤掉.
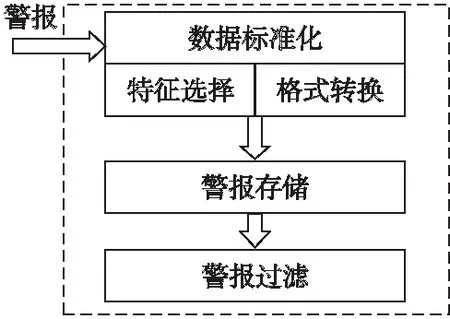
图4 基于Apriori-KNN算法的警报过滤机制的详细结构Fig.4 Detailed structure of alarm filtering mechanism based on Apriori-KNN algorithm
图4介绍基于Apriori-KNN算法的警报过滤层的内部构造.基于Apriori-KNN算法的警报过滤机制主要由数据标准化,警报存储和警报过滤三部分组成.数据标准化包含两个部分:特征选择和格式转换.特征选择是对输入警报进行预处理,格式转换是根据预处理特征集将基于特征的NIDS警报转换为标准警报(数据标准化的输出警报).具体的特征选择取决于NIDS的具体类型.以Snort为例,从Snort警报中提取8个特征,如描述,分类、优先级、报文类型、源IP地址、源端口号、目的IP地址和目的端口号,然而对于测试Apriori-KNN算法以上特征均不适合直接使用,需将这些特征进行标准化.所有警报将使用其在数据集中发生的概率来表示.在警报存储的组件中,所有传入的标准警报将被存储到数据库中,警报过滤组件将执行过滤误报.为了更好的测试降低误报率的算法,可通过对一些现有数据集(例如DARPA数据集)来标记标准警报,并对基于Apriori-KNN的警报过滤机制进行周期性测试.
该方法提出过滤警报的模型均独立于网络入侵检测系统(如图5),无需对现有检测配置进行更改.警报数据集是利用“正常”警报来构建误报模型.警报过滤过程是对从基于特征的NIDS连续不断输出的警报进行过滤,只需将过滤过程中被留下的警报进行二次检测.整个减少误报率的过程可看作是基于特征的NIDS的插件.简而言之,NIDS输出的警报流通过过滤器,将真正的警报输出并进行处理,误报则忽略.

图5 NIDS与降低误报率过程之间的关系Fig.5 Relationship between IDS and the proposed false alarm reduction processes
4 测试与分析
算法测试通过对基于特征的NIDS(即Snort)在不同情况下的性能进行比较,通过两个不同数据集(DARPA数据集和真实数据集)在Snort进行两次独立实验,并获取和分析实验结果.
4.1 使用DARPA数据集进行测试
DARPA是唯一经过深入研究,具有文献记录和公开可用的用于测试入侵检测系统的标记的数据.在实验中,使用1999年DARPA数据集来测试基于Apriori-KNN算法的警报过滤机制的性能.在DARPA 1999数据集中,误报可以通过从第1周和第3周重播到Snort来获得,在这两个星期内数据包不受任何攻击,因此,该时间段内的任何警报都可以被认为是误报.利用数据包生成器(Colasoft Packet Builder)向Snort发送恶意数据包来模拟一些攻击,从而获得了真实警报.DARPA数据集测试产生的警报数如表1所示.
表1 Snort生成的警报数
Table 1 Number of alarms generated by Snort

产生警报第2周第4周第5周 误报1448241057767 真正警报971723982172 警报总数2419965039939
为了测试Apriori-KNN算法的性能,利用DARPA数据集分别对本文算法的过滤机制和KNN分类器在Snort进行测试.DARPA数据集在Apriori-KNN算法和KNN算法产生的误报数量如表2所示.
在第2周、第4周和第5周DARPA数据集在Apriori-KNN、KNN与Snort的识别率见表3,Apriori-KNN警报过滤机制能够在KNN分类器的基础上再次提高Snort的识别率,降低了误报率.
如表1所示,由Snort在DARPA数据集上生成的标记警报(真实警报和误报),第2周误报数量为14482.表2、表3分别呈现了使用基于Apriori-KNN算法的警报过滤机制后的剩余警报(误报)数量与识别率,识别率用来衡量识别误报和真实警报的准确性.实验结果表明,基于Apriori-KNN算法的警报过滤机制具有较高的识别精度,减少误报数量.
表2 DARPA数据集在Apriori-KNN、KNN、Snort误报数量
Table 2 Number of false alarm for DARPA datasets in Apriori-KNN,KNN,Snort

时间误报数量Apriori-KNNKNNSnort第2周2047241214482第4周7929264105第5周115713287767
表3 DARPA数据集在Apriori-KNN算法的警报过滤器Snort降低误报
Table 3 Snort alarms reduced by based on the Apriori-KNN false alarm filter on the DARPA data set

时间识别率(%)Apriori-KNNKNNSnort第2周91.5490.0340.15第4周87.8285.7536.88第5周88.3586.6321.85
4.2 使用真实数据集进行测试
为了进一步测试基于Apriori-KNN算法的警报过滤器Snort的性能,使用真正的网络流量跟踪产生的数据集对该机制进行第二次实验.真实数据集是由部署在CSLab中具有公共IP域(这个IP地址不同于教育领域)的蜜罐提供.它由两台服务器组成:Honeywall和一台用于模拟服务列表的虚拟机(如HTTP,FTP).外部用户可以通过网络连接访问蜜罐,攻击者还可以对其发起恶意攻击或进行随机扫描.这种情况下,蜜罐可以看作是通过记录正常数据包和恶意数据包的所有传入流量来收集真实网络数据.将真实数据集分三部分,分别表示为DAY1,DAY2和DAY3.
表4给出了使用基于Apriori-KNN算法的警报过滤器进行降低误报率实验结果,其中警报过滤机制可以实现警报大约85%的识别率(识别精度在很大程度上取决于算法的训练.例如,通过测试更多的数据集,Apriori-KNN算法甚至可以达到90%以上的识别精度).
表4 基于Apriori-KNN算法的警报过滤器测试真实数据的性能
Table 4 Performance of the Apriori-KNN-based false alarm filter on the real data set

警报DAY1DAY2DAY3减少警报前568988297341减少警报后85410772172识别率(%)84.9987.8085.96
实验结果显示使用DARPA数据集测试时,识别率可以高达91.54%,相对于snort误报率而言明显减少.在使用收集的真实数据集进行测试时,识别率可以达到87.80%.使用基于Apriori-KNN算法的警报过滤器前后的警报差最多有7752个,明显减少了误报的数量,降低了误报率.
5 结 语
本文针对于基于特征的NIDS存在的高误报率问题,提出了一种利用Apriori-KNN算法的警报过滤机制的入侵检测系统.用N维空间对正常的警报模式进行建模,其中每个维度对应于一种警报类型.模型中的数据点表示某个时间段的警报分布,而其每个属性值是该时间段内特定类型的警报数.在研究中,根据Apriori-KNN算法中改进的欧氏距离d将新数据点分类为正常或异常.通过对DARPA数据集和收集真实数据集的测试与分析,证明本方法可以在不牺牲NIDS的安全性能前提下,有效地减少NIDS误报率,提高系统性能.
猜你喜欢
辽宁大学学报(自然科学版)(2022年1期)2022-04-26
煤气与热力(2021年6期)2021-07-28
计算机技术与发展(2019年7期)2019-07-23
计算机与数字工程(2018年10期)2018-10-23
中国水运(2016年3期)2017-05-13
中国高新技术企业(2017年5期)2017-05-05
中国科技纵横(2017年3期)2017-03-29
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
