
循环神经网络在语音识别模型中的训练加速方法
2019-01-24 08:26冯诗影韩文廷迟孟贤
小型微型计算机系统 2018年12期
冯诗影,韩文廷,金 旭,迟孟贤,安 虹
(中国科学技术大学 计算机科学与技术学院,合肥 230027)
1 引 言
作为对传统神经网络的一种改进,循环神经网络(RNN)引入反馈机制,在解决如自然语言处理等序列问题方面取得了巨大的成功,例如语音识别[1],语言模型[2],以及机器翻译[3]等.伴随问题更加复杂,以及对训练精度要求不断提高,模型中神经网络层数不断增多,规模越来越大.如今,大多数神经网络使用GPU或FPGA等加速卡进行训练.然而,随着神经网络规模的不断扩大,片上有限的存储空间逐渐成为训练大规模模型的瓶颈.目前已有许多工作用于加速神经网络训练,例如cuDNN——NVIDIA专用深度学习加速库[4],或分布式机器学习技术[5],但是如果没有有效利用计算资源,加速器的最佳性能同样不能被最大化发掘.
本文提出了一种基于循环神经网络的语音识别(ASR)模型加速训练方法.首先,从训练集中获取序列长度分布,根据可利用内存空间确定存储的不同大小模型数,并对每批次训练样本进行补零对齐.其次,平衡存储空间与训练时间,通过高效利用显存,达到在相同存储空间下一次训练更多样本,充分利用计算资源,提升计算效率.实验表明,该方法有效地提升了训练速度,且保证无精度损失.
2 相关工作
2.1 循环神经网络
循环神经网络(RNN)基于传统神经网络,在隐藏层之间增加了反馈连接.由于其反馈机制,RNN具有记忆过去状态的能力,因此在处理具有时间相关性的序列数据中有良好表现.一个简单的循环神经网络如图1所示.
xt是时刻t的输入(input),通常是具有特征维度的向量.st是时刻t的隐藏状态(hidden state),它由输入xt和前一隐藏状态st-1计算得到.ot为时刻t的输出,它是表示所有类别的概率向量.U,V和W分别是从输入,前一隐藏状态到下一隐藏状态,隐藏状态到输出的连接的权重矩阵.请注意,对于每一时刻,循环神经网络共享权重.网络输出计算公式如下所示.为激活函数,如sigmoid或tanh.Softmax是一种应用于多分类问题的算法.
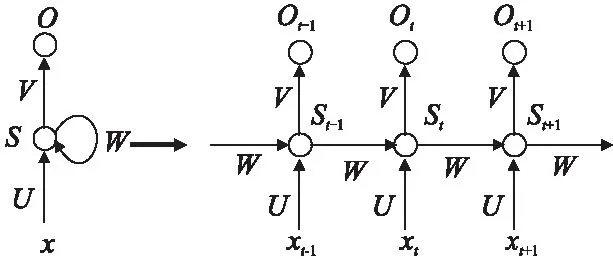
图1 循环神经网络Fig.1 Recurrent neural network
st=σ(Uxt+Wst-1)
(1)
ot=Softmax(Vst)
(2)
理论上,RNN能够在任意长的网络间传递信息,但是当涉及长时任务时,如对包含1000帧语音数据进行解码,其反馈能力会大大降低.为了增强记忆能力,长短时记忆模型(Long Short-term Memory,LSTM)[6]和门控循环单元(Gated Recurrent Unit,GRU)[7]网络应运而生,两种改进的循环神经网络结构添加门控机制,增强存储信息的能力,并成功地避免了梯度消失问题[8].目前,基于循环神经网络的大多数模型均使用LSTM[9]或GRU[10]进行构建.
如今,自动语音识别(ASR)模型使用RNN(LSTM或GRU)作为基本单元,通过对当前训练帧引入反馈机制,极大提高了训练的精确率.与其他神经网络相同,有效地增加模型层数将会获得更高的准确性,但同时将需要更多的计算时间和存储空间.
2.2 相关加速算法
与卷积神经网络(Convolution Neural Network,CNN)[11]和全连接网络(Fully Connected Network,FCN)[12]相比,循环神经网络不仅包含垂直方向上的深度信息,还包含水平方向的时间信息.当涉及序列学习任务时,对于长度不同的输入序列,使用RNN进行训练时,模型的水平方向长度将会变化.通常,神经网络以批处理(batch)方式进行训练,以达到更高计算效率[13].当同时训练多个序列时,较短的序列将在末尾填零补齐,从而使同一组训练数据具有相同长度.显然,填补零将带来额外计算开销,同时每一批不同长度的序列将使用不同大小的模型进行训练.由于存储限制,应该考虑如何选取合适的模型数量及大小进行存储.
截断反向传播时间(Back-propagation Through Time,BPTT)是一种将输入样本进行分段训练的方法,能够有效减少训练模型大小[14],但截断将会导致梯度信息丢失并影响性能[15].同时,对于训练较大模型,陈天奇小组提出了一种减少内存消耗的系统化方法,已被证明在卷积神经网络和固定长度的循环神经网络模型训练中有效[16].谷歌提出了一种前后向折中计算的方式来训练循环神经网络[17],解决了内存紧张时大规模模型训练的问题.这两个方法均在理论上以牺牲计算时间在有限存储下进行训练,未表现出加速性能.
本文提出一种更合理的方法来训练语音模型中的循环神经网络,通过对序列的合理组织以及高效的存储使用,来提升对输入序列的长度有显著变化的模型训练速度.
3 序列分组
序列分组(sequence bucketing)思想是指将输入序列按批(batch)训练大小进行划分,并放入对应组中,每个特定大小的组称为桶(bucket).序列分组有两个考虑因素:(a)应保留训练数据的随机性.(b)对于训练序列,分组应该是最佳的.序列分组主要分为三个步骤(见图2).
1)给定具有可用内存的块大小,将数据集拆分成具有索引的多个块;获取数据时,随机从磁盘中取出一个块到内存;
2)对所选块中的序列进行排序,并按批训练大小进行分组;再次对其编号进行随机化;
3)训练时取出一组样本,选择合适大小的桶对其进行处理,并使用对应大小模型进行训练.

图2 序列分组过程Fig.2 Process of sequence bucketing
该方法第一步一次将一整块数据放入内存中,减少硬盘访问次数来提高数据访问速度.此步由多线程生产者消费者模式进行操作,掩盖读取时间开销.第二步对该块序列排序,具有相似长度的序列将位于同一训练批次中.通过随机化,前两步保证了输入数据的训练随机性.第三步,批训练数据被置入合适大小的桶中,该桶为长度大于当前批次最长序列中最小的桶.显然,由于没有额外的计算,具有相同长度的序列的桶大小将达到最佳性能.直接利用已存储的模型将会减少模型构造时间,但由于参数,网络结构等设置,一个模型将占用200MB空间;对于最长序列长度为1000的数据集,若对每一步长的模型均进行存储,将占用近200GB的空间,这将给内存带来巨大的负担.如果动态构建模型,当计算与构建模型时间不能重叠时,整体训练时间也将大大增加.
此时考虑存储特定大小及数量的桶.桶的数量取决于内存大小和最长的序列长度.在可存储范围内,不同尺寸的模型将被保存和重复使用.本文提出两种设置桶大小的方法.
设L为最长的序列长度,N是桶的数量; Bm是第m个桶的大小,Bm和Bm+1之间的步长为Sm+1.注意对于任一步长,Sm>0,桶大小按升序排列.此时桶的大小表示为:
(3)
通常,简单采用固定步长可以满足基本训练需求,此时桶的大小如公式所示:
(4)
固定步长适用于序列长度均匀分布的数据集.但是,大部分数据集并不符合均匀分布.图3显示了一个语音识别数据集的序列长度的概率密度分布.可以看到,大多数序列倾向于在一定范围内分布,并且较短的序列比更长的序列分布更加密集.因此,具有较大尺寸的桶利用率较低,而在数据集的密集分布范围内桶的利用率更高.
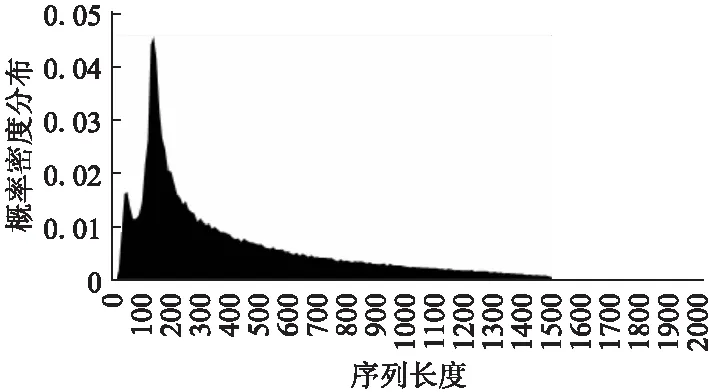
图3 语音识别数据集长度概率分布Fig.3 Probability distribution of sequence length for the speech recognition dataset
在这种情况下,根据数据集的分布设置变化步长的桶大小会取得更好的性能.取其概率分布函数F(x),桶大小可以设置为:
(5)
对于语音识别的数据集,概率分布函数类似平方根函数.与均匀步长相比,桶的大小变化较大,这可能对长序列有更差的影响.为平衡性能,最终选取如下公式对桶大小进行设置,即相邻两桶之间步长呈递增形式:
(6)
(7)
图4给出了取8个桶时,选择固定步长和变化步长方法下,每个桶覆盖数据集中不同长度序列范围的示例.最上为改进后的变化步长,中间为依靠概率分布所取步长,最下为固定步长.如图所示,序列长度较短范围内,选取变化步长时桶的数量明显多于固定步长,且改进后的变化步长方法在较长序列范围部分,桶的数量较原方法增多,从而使位于语音数据集中不同长度的序列均有大小合适的桶可供选择.
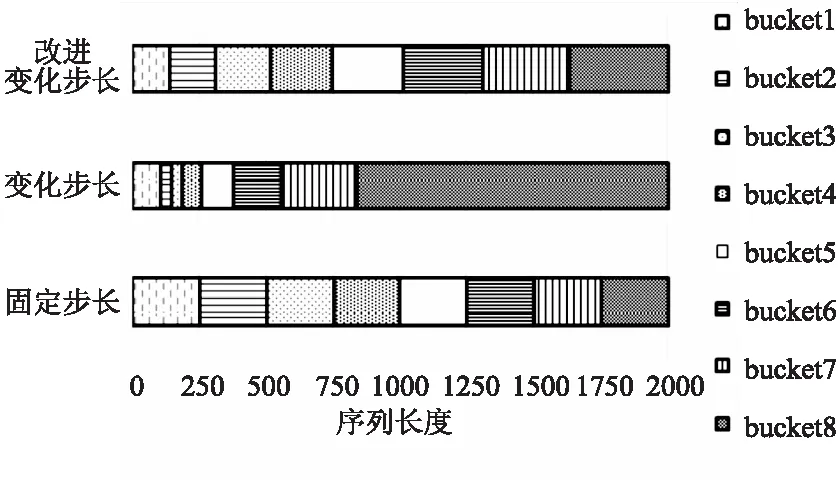
图4 不同步长设置下桶覆盖数据区域分布Fig.4 Buckets with different step setting
除此之外,批训练数据的形状被重新排列,以桶大小作为第一维度(如图2中的步骤3所示).通过此种排列,处于不同序列但在同时刻的输入数据将位于连续向量中,从而在计算过程中能够连续访存,获得较高访存性能.
4 高效利用显存
在循环神经网络中,由于水平方向实际为按时间顺序循环展开,因此每个单元结构相同,其输出不仅作下一层输入,还将传递给后一单元.随着序列长度和批样本数增加,模型逐渐变大,有限存储空间将无法存储模型,或仅可以在一次训练中训练几个序列,导致计算效率极低.因此,需要考虑在计算时间和存储空间之间进行平衡,从而提升训练性能.
为了解循环神经网络模型占用内存大小,需要深入了解其单元结构.以LSTM作为对象进行分析,LSTM网络与标准RNN相同,但隐藏层中的单元被更复杂的单元替代.在该单元内,细胞(cell)是LSTM的关键部分,它保存当前单元的状态信息; 输入门(input gate)、输出门(output gate)和遗忘门(forget gate),决定是否应将信息添加到单元中或从单元中移除.
LSTM核心公式如下.it,ft,ot表示输入门,遗忘门和输出门,输入数据xt,隐藏状态ht,单元状态ct分别为向量形式.Wmn表示从单元n到单元m的连接权重矩阵,大小为m×n.bi,bf,bo,bt分别为三个门和变换部分的偏置权重,为向量形式.t表示时刻t.σ为激活函数,g是单元和隐藏层的输出激活函数.
it=σ(Wixxt+Wihht-1+bi)
(8)
ft=σ(Wfxxt+Wfhht-1+bf)
(9)
ct=ftct-1+itg(Wcxxt+Wchht-1)
(10)
ot=σ(Woxxt+Wohht-1+bo)
(11)
ht=otg(ct)
(12)
从方程式可以看出,LSTM计算过程比基本RNN更加复杂,更多变量需要存储.图5显示了一个LSTM单元的计算过程.在图中,点状网格表示一个LSTM单元,其内部的每个方块表示中间结果或最终结果.
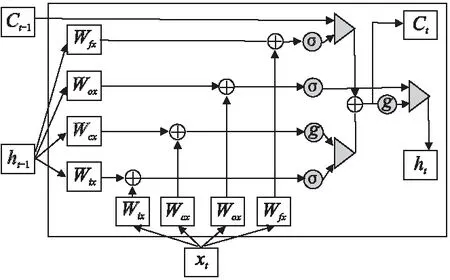
图5 LSTM单元结构图Fig.5 LSTM unit
首先,前一隐藏状态ht-1和输入xt通过全连接层被转换成四个矩阵.后续操作——矩阵加法,激活和矩阵点乘均基于这四个矩阵进行计算.假设批样本大小为B,一层中的神经元数量和输入维度均为H,则一个块中的内存使用总大小为2(19BH).例如,对于批量大小为8,隐藏大小为2048的浮点数据类型,一个单元占用2.5MB,那么对于步长(step)为1000的3层模型,除其他如softmax层外,已经需要7.5GB显存.反向传播过程使用链式法则来递归地计算每层参数梯度,中间结果将被再次使用进行误差计算.此时保存所有输出及中间结果,调整模型深度或一次训练更多样本将被显存限制.
通过分析后向计算过程中的导数公式[18],必须存储的中间结果是经过激活函数后的输出,其他梯度可通过该值进行求取.以这种方式,一个单元所需的保存结果的空间为7BH,矩阵参数大小为4H2+H.假设模型共L层,时间步长为N,网络中的参数在单元中共享,则训练时前后向计算所需内存成本的总大小为:
mem=2(7LNBH+4H2+H)
(13)
为减小单个样本存储空间,提升训练规模,此时考虑数据丢弃方法(data drop),即在前向计算中,丢弃中间结果,只保存最终输出,在反向传播阶段,丢弃的中间结果通过对最近的记录状态重新进行前向计算获得.该方法非常适用于循环神经网络,因为RNN中的每个单元成为一段,输出的隐藏状态作为记录状态,单元内的中间结果可以通过记录的隐藏状态重新计算.
仅保存每个单元的隐藏状态和单元状态时,为前向计算过程中需要计算的中间结果分配一个临时空间;在后向过程中,再次使用该空间来重新计算中间结果以获得误差值,从而节省原需要保存全部单元而占据的存储空间.单层RNN算法描述如下:
输入:训练样本序列X,长度为N
输出:本层输出S及梯度G
显存分配:
(1)中间结果temp
(2)输入X[N],输出 S[N],梯度G[N]
Step1.前向计算
For k=1 to N do
S[k]←rnn[k].forward(X[k],S[k-1],temp)
End for
Step2.后向计算
For k=N to 1 do
rnn[k].forward(X[k],S[k-1],temp)
G[k]←rnn[k].backward(G[k+1],temp)
End for
只存储每个块的隐藏状态和单元状态,参数和临时空间时,同样大小的训练模型的内存成本为:
mem=2(2LNBH+4H2+H)
(14)
与等式(13)相比,一个单元内所需的空间理论上将缩小至原空间大小的30%,并且模型包含单元越多,内存节省的将会越多.通过这种方式,在一次训练过程中,相同内存将可用来训练更多样本.尽管反向传播阶段的计算成本增加,但由于批处理规模增大,GPU硬件计算单元得到充分利用,计算效率提高,即同一时间并行计算的数据增多,从而为提升整体训练速度提供可能.
5 实 验
5.1 实验设置
实验针对语音识别模型进行评估,使用具有隐层大小为2048的3层LSTM模型,并且基于低秩方法[19],每个单元的输出维数减少到512以降低计算规模.输入数据集最长序列长度设置为2000,每帧向量输入维度为40维;输出损失函数使用Softmax,最终类别为8991类.
数据集来源于Switchboard Corpus,使用的训练样本包含332,576个序列.实验基于MXNet框架[20].此次试验基于NVIDIA Tesla M40,该GPU具有12GB显存.优化效果评测主要针对单GPU,当使用多GPU进行数据并行加速时,其速度基本与单卡速度成线性关系.
实验目标为如何在限定条件下在单GPU上获得最佳性能,主要基于三个因素的评估:不同的模型数量,不同步长的选择方式以及高效利用显存方法.首先对序列分组方法进行实验,然后使用数据丢弃方法查看实际内存减少比例,最终通过组合两种方法来测试基于相同内存下训练不同样本大小的计算性能.
5.2 序列分组加速结果
该部分实验设置批训练样本数设置为8,分别选取{1,2,4,8,16,32 }作为桶的数量.桶的数量为1时,代表所有序列都将在具有固定大小的单个模型中进行训练.同时,实验比较了分别使用固定步长(公式(4))和变化步长(公式(7))效果.

图6 基于不同桶数量时速度对比Fig.6 Speed of different bucket number
最终速度性能如图6所示.使用多个桶明显提高具有不同长度序列的训练性能;在变化步长的方式下,与只基于单一模型的训练相比,当桶的数量为32时,加速比达到4.2倍.比较固定步长和变化步长的结果,后者在相同条件下较前者有大约1.1倍加速比.后续实验中,均采用变化步长方法进行速度对比.
5.3 高效利用显存加速结果
实验首先对优化前后显存的实际使用情况进行验证.模型的展开步长设置为2000.优化前后方法均调用基于相同计算函数编写的内核,优化前内核保存中间结果,优化后内核在前向计算中丢弃中间结果,在后向计算时重新计算.由于cuDNN中的RNN函数只能应用于固定长度模型,对于变长模型无法使用,因此并没有将其用作对比目标.

图7 优化前后显存大小对比Fig.7 Memory usage comparison
图7显示了内存使用情况.批样本大小从1开始,考虑到CUDA内核的线程组织,批样本大小均设置为4的倍数.从实验中可以清楚地看出,使用优化显存方法减少内存使用,并且随着批样本数增加,计算性能随之提升.在单GPU上的12GB内存中,优化前模型能够训练的最大批样本大小为16,而优化后批训练样本数达到32.
其次,基于相同的桶数量,步长及显存优化方法,不同批样本大小下的训练速度对比如表1所示,速度单位为每秒训练序列数.随着批样本数增加,训练速度趋于线性加速,即批训练样本数增大,训练性能随之提高.
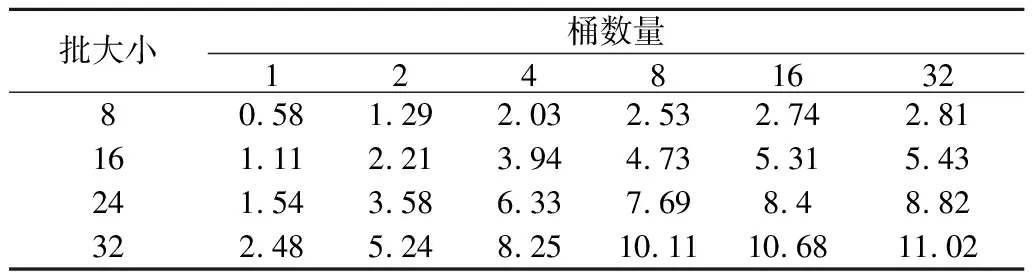
表1 不同批样本数下速度对比实验数据表Table 1 Speed comparison with different batch size
最后,实验基于相同显存下,对使用优化显存方法前后的性能进行对比.实验选取批样本大小分别为8,20和12,32两组实验进行对比.图8显示了两组实验基于不同数量桶下的速度.两组实验均从优化显存方法中获得了性能提升:第一组实验平均得到1.82倍的加速,第二组实验的加速为1.73倍.该结果表明,尽管数据丢弃方法在后向计算中需要更多的时间,但由于增大了批训练样本数,硬件计算利用效率得以提升,从而提高了整体训练速度.
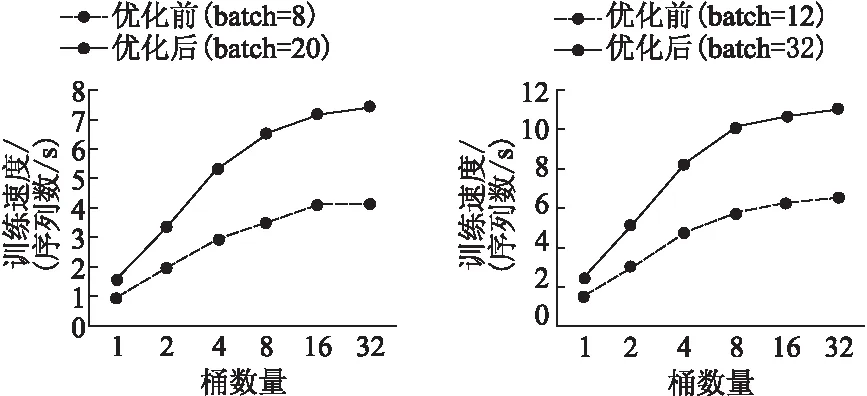
图8 相同显存下优化前后速度对比Fig.8 Speed comparison with same memory
基于完整的一次训练,当完成一个训练周期(批样本大小为8时需要10,343个epoch;批样本大小为32时需要41,375个epoch),未使用优化显存方法前,原模型一次只能训练8个样本,在单GPU上需要48小时;使用优化方法后,一次训练样本数达到32,单GPU只需19小时,使用4GPU进行数据并行训练时间缩短至5小时.
6 结 论
本文提出了一种有效的方法来加速基于变长输入序列的循环神经网络的训练速度.通过高效的序列分组和显存优化方法,循环神经网络模型训练速度得到显著提升.
实验主要基于语音识别模型进行评估,在相同的显存下,基于NVIDIA Tesla M40 GPU实现了1.7倍的加速.实验证明,该方法对于较长序列的循环神经网络效果更好.此外,随着每批训练样本数的增加,可以提高学习率来加速收敛.下一步工作将考虑在显存和计算之间进行更准确的量化分析,以及在其他模型上使用该方法进行加速,期望达到更优的训练性能.
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30
西安邮电大学学报(2021年1期)2021-04-19
小学生学习指导(低年级)(2020年10期)2020-11-26
无线互联科技(2020年12期)2020-09-03
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
无线电通信技术(2019年4期)2019-06-25
作文大王·低年级(2017年11期)2017-12-05
学苑创造·A版(2017年1期)2017-01-19
电脑爱好者(2015年21期)2015-09-10
