
基于自适应萤火虫算法的BP神经网络股价预测
2019-01-22 11:33刘园园贺兴时
渭南师范学院学报 2019年2期
刘园园,贺兴时
(西安工程大学 理学院,西安 710048)
0 引言
中国证券市场于20世纪末逐渐形成,经过20多年的发展,已成为国民经济发展的重要组成部分。[1]随着国民经济的发展以及人们对投资理财的重视,股票投资受到越来越多的关注,因其收益比较高,并且股票的投资门槛较低,对于投资者来说是一个不错的投资渠道,故逐渐成为大多数人的投资理财方式之一。然而国内股市发展时间较短,各类规章制度尚不够完善。加之股市是一个极其复杂的非线性时变动态系统,股票价格受各种宏观、微观因素以及突发事件的影响[2],股价的走势往往呈现出较强的非线性特征。为了降低投资风险,保证稳定的投资收益,人们迫切需要一种合理的、有效的方法来掌握股价的变化规律,并预测其走势[3],因此研究股票市场,构建一种高效的股价预测模型,具有十分重要的现实意义。
股票预测即以股市信息及统计资料为依据,运用数学方法预测未来的股票价格。虽然学术界提出了多种方法来预测股价,如多元回归、时间序列法、混沌理论、证券投资分析法等[4-7],但由于诸多内部、外部因素的影响,致使股票预测时存在很多难点[8],如存在高噪声数据、股价波动呈非线性特点及投资者意向的不确定性,因此传统的线性分析方法在解决此类非线性问题时有一定的局限性,预测结果难以令人满意。人工神经网络的非线性关系映射能力极强[9-10],不需要构建非线性系统的数学模型或显示数学解析式,便能够实现任意维数向量之间的映射关系,非常适用于对股市等非线性系统的预测,其中BP(Back Propagation)神经网络在此方面表现出了极其强大的能力。它不仅能够将有关经济活动类的知识从历史数据中自动提取出来,还能够克服传统的定量预测方法中存在的诸多局限及困难,同时也能够避免人为因素的影响。BP神经网络的优势虽然明显,但也存在着诸多不足,如BP调整其权、阈值采用的是梯度下降法,这样会导致网络收敛速度慢且易陷入局部极小值点。因此,学者为了弥补算法自身的缺陷,将两种以上的算法结合到一起,规避算法缺陷,凸显算法优势。目前主要研究成果有以下几个方面:许晓兵等人[11]提出将小波变换和BP神经网络结合的股价预测算法,对股票价格先去干扰再预测,能够提高预测精度,但去干扰的参数选择对于股价的预测影响较大。尹璐[12]提出了一种利用遗传算法优化BP网络初始权值和阈值,从而实现股价预测和发掘。但大量实验表明,随着时间的推移,该算法模型易使算法的绝对误差呈上升趋势变化。刘媛媛等人[13]提出了一种将遗传算法与BP网络相结合的算法,能够提高收敛速度、改善寻优精度,从而提高预测精度。Huang Fu-Yuan等人[14]提出了一种利用蜂群算法来优化模糊神经网络的股价预测算法,该算法提高了BP神经网络的预测性能。
智能算法近年来受到诸多学者的关注,如遗传算法、蚁群算法、布谷鸟算法、萤火虫算法等,其中萤火虫算法(Firefly Algorithm,FA)[15]概念简单,流程清晰,需要调整的参数较少,收敛速度较快,同时搜索精度较高,更加容易实现。本文在详细研究了标准BP算法和标准FA算法原理的基础上,针对FA算法存在的缺陷,通过将混沌优化方法应用到萤火虫算法中,并对萤火虫算法中的步长因子进行自适应调整,提出了一种自适应萤火虫优化算法(SFA);针对BP算法的不足,提出了利用自适应的萤火虫算法优化BP神经网络的方法,改善股票的预测精度、提高BP算法的收敛速度,据此对4种股票指数走势进行预测。通过与传统BP神经网络、基于FA算法的BP网络模型(FA-BP)对比,发现基于SFA算法的BP网络模型(SFA-BP)明显优于另外两种模型,能有效预测股票价格。
1 FA-BP神经网络
1.1 萤火虫算法
萤火虫算法(FA)的核心思想是通过亮度比较来调整位置、更新数据,即亮度大的萤火虫吸引亮度小的萤火虫向其移动,同时两者均更新自身位置。故亮度、吸引度、位置更新公式为萤火虫算法中的几个要素。 当萤火虫i的亮度大于萤火虫j的亮度时,萤火虫j向i移动。故有如下定义:
(1)萤火虫i对j的相对亮度为:
(1)
其中:Ii为萤火虫i的最大荧光亮度;γ为光强吸收系数,通常设为常数;rij为萤火虫i到j的空间距离。
(2)萤火虫i对j的吸引力为:
(2)
其中:β0为在光源(r=0)处的吸引力,是最大吸引力。
(3)萤火虫j向i移动并进行位置更新,萤火虫j的位置更新公式如下:
Xj(t+1)=Xj(t)+βij(Xi(t)-Xj(t))+α(rand-1/2)。
(3)
其中:t为迭代次数;Xi、Xj表示萤火虫i与j的空间位置;步长因子α为[0,1]上的常数;rand是[0,1]上的随机因子,且服从均匀分布。 由于其他萤火虫无法吸引最亮的萤火虫,故最亮的萤火虫位置更新公式不能按式(3)执行。
下面给出最亮萤火虫位置更新公式:
XB(t+1)=XB(t)+α(rand-1/2)。
(4)
基本萤火虫算法步骤如下:
Step 1:设置相关参数,随机初始化n个候选解作为萤火虫的初始种群。
Step 2:计算适应度值,更新空间位置,重新计算各萤火虫的亮度、吸引度,计算移动到的新位置。
Step 3:评估新解,更新萤火虫荧光亮度,排列各萤火虫,并且找出当前最优解。
Step 4:移动最亮萤火虫。
Step 5:判断是否满足迭代结束条件:若满足,转至Step 6;若不满足,转至Step 2。
Step 6:输出结果。
1.2 BP神经网络
BP神经网络作为目前应用最为广泛的一项人工神经网络[16-18],是基于反向传播的多层前馈式网络,其特点是信号正向传播、误差反向传播。BP网络一般为三层结构的网络,即输入层、输出层和隐含层,隐含层可为单层或多层。各层间的神经元仅和相邻层神经元之间通过权值传递信息,同层神经元之间无连接。假设网络的输入层神经元个数、隐含层神经元个数、输出层神经元个数分别为n、m、s,则BP神经网络结构即为:n-m-s。
BP神经网络算法步骤如下:
Step 1:初始化各层之间的连接权值、阈值,ωij为输入层和隐含层间的连接权值,ωki为隐含层和输出层间的连接权值,θi为隐含层阈值,αk为输出层阈值,均取[0,1]区间内的随机值。
Step 2:选择一个样本作为输入样本xj进行训练,则隐含层第i个节点的输入变量zi、输出变量yi如下:
(5)
(6)
Step 3:通过确定隐含层输出变量yi,则输出层第k个节点处的输入变量mk、输出变量nk、输出变量与实际输出值Ok的均方差E如下:
(7)
nk=ψ(mk),
(8)
(9)
Step 4:比较E的值与训练目标误差值的大小:若小于误差值,则返回Step 2,选择下一个样本;反之进行误差反向传播,修正各层连接权值、阈值,直至满足误差要求。其中应用梯度下降法获得权值的学习率η的修正公式如下:
(10)
其中:
(11)
(12)
则输出层的权值修正公式如下:
Δωkj=-∂(Ek-nk)ψ′(mk)yi。
(13)
同理,可得阈值的修正公式。隐含层的权值、阈值修正公式亦可得。
Step 5:选择下一个样本,返回Step 2继续训练,直至将所有样本训练完。
1.3 FA-BP神经网络
传统的BP神经网络是基于梯度下降法获得的权值和阈值,是随机的,且收敛速度较慢,易陷入局部极小值点。而通过BP神经网络和萤火虫算法相结合的方法(FA-BP)可以在一定程度上改善BP算法的不足。其基本思想是:首先由输入和输出的参数将BP神经网络的结构加以确定,这样也就能够将萤火虫算法内每个萤火虫个体的编码长度加以确定。每个萤火虫个体都包含了BP网络的所有权值、阈值,且萤火虫个体的维度与BP网络中起作用的权值和阈值的总个数相对应。再根据适应度函数计算每个萤火虫个体的适应度值,并且进行迭代,更新亮度、吸引度、位置等信息,找到最优个体,然后将得到的萤火虫个体信息给BP网络赋值,作为其初始权值和阈值,最后通过BP算法进行股价预测,从而得到精确度较高的预测结果。
但是,传统的萤火虫算法存在对初始解较为依赖、迭代后期收敛速度较慢、搜索精度不高等缺陷。为解决这些问题,提高算法的全局搜索效率,本文提出了一种利用自适应的萤火虫算法来优化BP神经网络的方法,并构建了模型(SFA-BP),从而获得最优的初始权值和阈值,提高预测精度。
2 自适应萤火虫算法(SFA)
2.1 混沌映射
混沌是一种复杂的非线性系统动态行为,因其具有对初值敏感依赖性、遍历性、随机性等优点,近些年得到广泛关注,还被广大学者应用到启发式算法中,将其与启发式算法相结合,提高算法的寻优性能。基本思想是把优化变量空间通过混沌映射线性地映射到混沌变量中,再根据混沌变量的遍历性、随机性进行优化搜索,最后将得到的解线性地转化到优化变量空间。
Tent映射混沌序列分布均匀,并且搜索效率较高,有更快的收敛速度,其数学表达式为:
(14)
该映射经贝努力移位变换后数学表达式为:
xn+1=(2xn)mod 1。
(15)
2.2 Tent混沌优化
利用混沌序列优化萤火虫算法已经受到众多学者的研究,本节利用Tent映射具有更好的遍历均匀性及更快的搜索速度的特点,优化萤火虫算法,其基本思想如下:
(1)利用Tent映射初始化种群。利用Tent映射随机产生分布均匀的初始种群,这样既能保证初始种群个体的随机性,又能使种群多样性得以提升,从而提高算法的收敛速度。
(2)自适应动态调整较优解混沌搜索。本文假设算法第i只萤火虫在寻优时出现停滞。对当前进化第t代的所有萤火虫按适应值从大到小排序,取前百分之p个个体n(其中p=5),分别求出这n只萤火虫第d维的最小值Xdmin和最大值Xdmax作为混沌搜索空间。并从这n只萤火虫中随机选择1个萤火虫位置XB作为基础解,产生Tent混沌序列,进而用产生的混沌序列中的最优解更新萤火虫位置,使算法跳出局部最优。
利用Tent映射对种群中较优解进行局部搜索的主要步骤如下:
Step 1:在萤火虫种群Xi(i=1,2,…,n)中,从前百分之p个个体当中随机选择一个萤火虫位置XB作为基础解。
Step 2:利用式(16)将XB映射到(0,1),其中i=1,2,…,n;d=1,2,…,D。
(16)
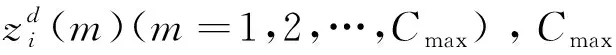
(17)
Step 5:计算XC的适应度值,并与XB的适应度值作比较,保留最好的解。
Step 6:如果达到最大混沌迭代次数,运行结束,否则转至Step 3。
2.3 选择策略
锦标赛选择策略是一种基于局部竞争机制的方法,即从种群当中随机选出q个个体进行比较,并且将适应度大的个体作为最优个体。本文中萤火虫采用锦标赛选择策略进行群体位置更新,并且取q=2,给适应度大的个体加1分,所有萤火虫进行此过程,最终得分最高的萤火虫个体其权重也最大。因为该选择策略仅将适应度值的相对值当作选择的标准,而对适应度值的正负不作要求,故能避免超级个体对萤火虫算法的影响。适应度选择概率为:
(18)
其中:ci为每个个体的得分。
2.4 自适应步长
基本FA算法中步长因子α为常数,采用的是[0,1]间的固定值,且在迭代过程中值不变。较大的α在进化初期有利于算法的全局搜索,但进化后期会降低搜索精度,容易出现震荡现象,不易找到全局最优解;较小的α在进化后期有利于算法的局部搜索,搜索精度较高,但将导致算法收敛速度过慢等问题。本文采用随着迭代次数而递减的 α,从而使算法具有更快的搜索速度和搜索精度,α计算公式如下:
αt+1=αtδ,0.5<δ<1。
(19)
其中:δ为冷却系数,通过式(19)迭代计算得到的α,每次会得到一个更小的值,从而能更好地平衡萤火虫算法的全局搜索能力和局部开发能力。
2.5 SFA算法
SFA算法采用Tent混沌优化、锦标赛选择策略和自适应步长参数优化方法,避免算法早熟收敛及陷入局部极值,具体算法流程如下:
Step 1:设置相关参数:萤火虫种群规模n、最大迭代次数T抑或求解精度σ、步长因子α初始值、最大吸引度β0、光强吸收系数γ、位置维数D、混沌搜索最大迭代次数Cmax。
Step 2:设置迭代次数初始值t=0,在可行域中利用Tent映射初始化种群,随机初始化n个D维候选解作为萤火虫的初始种群Xi(i=1,2,…,n)。
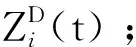
(20)
Step 3:根据适应值函数f(Xi)计算各萤火虫的亮度I(Xi)。初始标志向w(i)=0,记录最亮萤火虫为同一萤火虫的次数。
Step 4:每只萤火虫都会向着比自身亮的萤火虫移动,更新萤火虫之间距离,更新吸引度值,根据式(19)更新步长因子,根据式(3)或(4)进行位置更新,计算亮度。
Step 5:如果f(Xj)>f(Xi),则Xi=Xj,w(i)=0;反之保持原解Xi不变,w(i)=w(i)+1。
Step 6:利用锦标赛选择策略,通过式(18)计算选择概率Pi(t)。
Step 7:萤火虫根据概率Pi(t)选择最亮萤火虫,从而确定自身位置更新,计算适应度值,转至Step 5。
Step 8:若w(i)>Limit,则第i只萤火虫为停滞解,根据第2.2节的自适应混沌搜索产生一个新解替换停滞解。
Step 9:记录当前所有萤火虫自身的最优解,保存种群当前最优解。
Step 10:更新t=t+1,判断是否达到求解精度σ要求或满足最大迭代次数T。若满足,则输出当前最优解;反之返回Step 4。
3 SFA-BP神经网络
3.1 个体编码
本文采用实数编码的形式,将BP神经网络的连接权值和阈值表示为萤火虫个体。该个体被映射为4部分,即输入层到隐含层间的连接权值ωij、隐含层的阈值θi、隐含层到输出层间的连接权值ωki、输出层的阈值αk。由于输入层节点个数为n、隐含层节点个数为m、输出层节点个数为s,因此,萤火虫个体的字符串长度为:L=n×m+m+m×s+s。
各连接层之间的权值和阈值表示如下:
(21)
θi=[θ1,θ2,…,θm]Τ,
(22)
(23)
αk=[α1,α2,…,αs]Τ。
(24)
则萤火虫个体的编码形式为:
X= [ω11,ω12,…,ω1m,ω21,ω22,…,ωnm,θ1,θ2,…,θm,
ω11,ω12,…,ω1s,ω21,ω22,…,ωms,α1,α2,…,αs]。
(25)
3.2 评价标准
本文将网络的实际输出值和真实值之间的均方误差作为BP网络的评价标准,因此在萤火虫算法中可将适应度函数设置为:
(26)
其中:N为输入的样本总数,yi为预测的股票价格,xi为真实的股票价格。fitness的值越小,表示网络的性能越好。
3.3 算法实现的基本步骤
根据传统BP神经网络的实现步骤及自适应萤火虫算法的实现步骤,得到基于自适应萤火虫算法优化的BP神经网络(SFA-BP)的算法实现步骤如下:
Step 1:初始化参数:初始化SFA算法以及BP算法的参数,并设置最大迭代次数。
Step 2:编码:采用实数编码方法,依照式(25)将BP的权值和阈值统一编码,并对应到萤火虫个体中,使得每个萤火虫个体代表一个BP网络结构。
Step 3:根据2.5节自适应萤火虫算法步骤,找出当前最优解。
Step 4:解码:将萤火虫个体解码,得到相应BP网络的权值和阈值。并以此作为BP的初始权、阈值,进而训练BP神经网络。
Step 5:判断是否达到BP网络停止条件:若满足,得到最优的神经网络结构;反之,继续训练。
4 仿真实验与结果分析
4.1 FA与SFA性能对比分析
由上文可知,载有BP神经网络初值信息的萤火虫个体进行寻优,然后将输出的最优值解码为神经网络的权值、阈值,因此FA-BP、SFA-BP算法性能的好坏在一定程度上依赖于FA、SFA算法的性能。为了评估FA、SFA算法的优化性能,本文选取4个标准测试函数来进行仿真实验,这4个测试函数表达式、搜索区间和最优值如表1所示。

表 1 4个基准测试函数
这些测试函数均为国际通用的全局优化问题常用的测试函数,分别具有不同的特性,可用来充分考察算法的寻优能力。其中,Rosenbrock和Sphere是单峰函数,这些函数可以用来测试算法的寻优精度、收敛速度和执行效率;Rastrigin 和Ackley为多峰多极值函数,这些函数的特点是有许多局部极值,可以用来考察算法的全局寻优能力、跳出局部极值点和避免算法早熟收敛的能力。将标准FA算法和SFA算法进行对比实验。所有实验均在硬件环境为Intel Core I5-7200,CPU 2.70 GHz,内存4 GB;软件环境为Windows 10操作系统的计算机上进行,所有算法在Matlab R2016a下进行仿真。
在实验中,算法的相关参数设置为:萤火虫种群个数为100个,最大迭代次数为2 000次,最大吸引度β0=1,步长因子初值α=0.05,光强吸收系数γ=1.0,函数维数设置为30。相比FA算法,SFA算法又引入了3个参数,参数值的设定分别为混沌搜索次数为30次、δ=0.97、Limit=100。为了避免算法偶然性带来的误差,每个测试函数分别独立运行30次,并统计其结果。规定当求解精度达到10-20时假定结果为0,通过记录FA算法和SFA算法在迭代后的平均值、最优值、最差值、平均运行时间等来评价各算法的优化性能,平均值、最优值、最差值反映的是解的质量,平均值反映的是算法所能达到的精度,平均运行时间反映的是算法的寻优速度。测试结果比较如表2所示。
由表2可知,SFA算法的寻优精度明显优于FA算法,无论是对于单峰函数还是对于多峰函数,SFA算法的收敛速度均明显优于FA算法。

表2 FA算法和SFA算法测试结果比较
对于单峰函数Sphere,SFA算法在寻优精度、寻优率及收敛速度方面均明显优于FA算法,能够持续有效地搜索函数全局最小值。对于非凸病态单峰函数Rosenbrock而言,因其在取值范围内走势较平坦,可收敛至全局最优点的机会很少,但SFA算法依然表现出了强大的全局寻优能力;对于多峰函数Rastrigin和Ackley函数,SFA算法的求解精度及收敛速度均高于FA算法,主要由于SFA采用自适应Tent混沌搜索和自适应步长因子,不仅能动态调整混沌搜索空间,还能动态调整步长,因而既能保证种群多样性、提高求解精度和收敛速度,也能使算法跳出局部最优。故初步推断SFA-BP预测精度优于FA-BP。
4.2 样本数据准备
BP网络进行预测时,若样本个数太少,会导致网络的泛化能力较弱;反之,样本个数太多,又会出现过拟合现象。因此,样本个数的选取应当适中。本节选取了4种股票指数从2015年1月5日—11月12日的历史收盘价数据,分别是中证1000指数、深证1000指数、上证商业指数及香港恒生指数。中证1000指数能够整体反映沪深证券市场内小市值公司的综合状况,深证1000指数,旨在反映深圳证券市场内大中小市值企业的整体状况。上证商业指数能总体反映多种行业的景气情况及其股价的波动情况,香港恒生指数在反映香港整体股市价幅趋势中是最具权威影响的股价指数。
4.3 网络结构的设计
(1)网络层数的确定。Cybenko等人[19]已经用理论证明,三层的BP网络能够以任何精度逼近任意非线性函数。因此本文选择三层BP网络进行研究,即只含一个隐含层的BP神经网络。
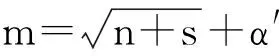
(3)其他参数的确定。利用随机函数设置初始权值,通常为(-1,1)之间的随机数,学习步长取0.2,期望误差取0.000 1,萤火虫种群个数取100个,最大迭代次数取2 000次,步长因子初值α=0.05,最大吸引度β0=1,光强吸收系数γ=1.0。相比FA算法,SFA算法又引入了3个参数,参数值的设定分别为混沌搜索次数为30次,δ=0.97,Limit=100。
4.4 预测结果及分析
本文通过已选取的股票数据,对BP网络模型、FA-BP网络模型和SFA-BP网络模型进行股价预测精度的仿真对比分析。表3为3种算法对4种股票指数预测的平均误差数据对比。
由表3的统计结果可以看出,对于4种股票指数数据而言,SFA-BP网络模型的预测精度最高,明显优于BP网络模型及FA-BP网络模型的预测精度,具有一定的实际应用价值。
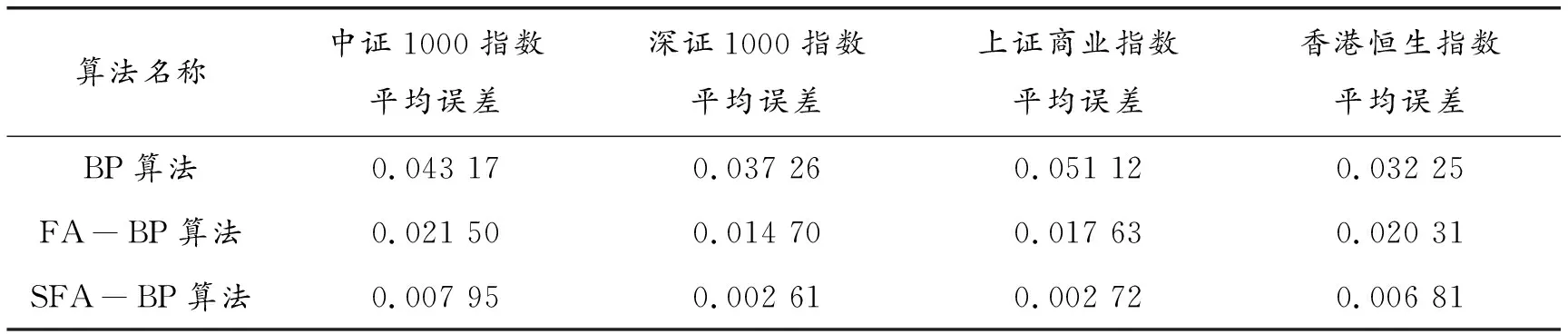
表3 BP算法、FA-BP算法和SFA-BP算法误差对比
5 结语
为了克服传统BP网络收敛速度慢、容易陷入局部极值点等不足,提出了利用自适应的萤火虫算法(SFA)来优化BP网络的方法,构建了BP优化模型(SFA-BP),并将其用于股价预测,构建了股票价格的预测系统模型,通过仿真实验可以看出,该预测系统取得了较为理想的预测效果,在实际生活与工作中,具有一定的实用价值。但股票价格预测作为一个长期的工作,若能扩大其样本规模,将开盘价数据、最高最低价数据、成交量数据等引入,将进一步提高预测精度,进行更为精确的预测,将有更好的应用前景。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
娃娃乐园·综合智能(2022年6期)2022-06-17
福建师范大学学报(自然科学版)(2022年2期)2022-03-16
成都信息工程大学学报(2021年5期)2021-12-30
西安邮电大学学报(2021年1期)2021-04-19
邮电设计技术(2021年2期)2021-03-13
计算机与数字工程(2019年11期)2019-11-29
无线电通信技术(2019年4期)2019-06-25
小天使·一年级语数英综合(2018年7期)2018-09-12
计算机测量与控制(2018年3期)2018-03-27
