
基于Logistic模型的我国房地产企业信用风险度量研究
2019-01-21 11:02雷欢欢胡华强
中国软科学 2018年12期
胡 胜,雷欢欢,胡华强
(1.九江学院,江西 九江 332005;2.郑州航空工业管理学院,河南 郑州 450000 )
一、引言
近十年来,我国房地产行业快速发展,其投资及其投机性质已经成为社会关注的热点问题。十九大报告中指出“坚持房子是用来住的、不是用来炒的”,我们将要加快保障房供给,减弱房地产的投机属性,加强住宅的消费品属性,推进房地产税立法和实施,建立以法律控制手段为支撑的房地产市场长效调控机制。出台的一系列限购和限贷调控政策虽然抑制了发展过热的房地产市场,但也使房地产企业信用风险开始慢慢暴露和显现。
房地产企业的信用风险主要体现在房地产借款企业是否有能力偿还所借款项、是否有主动承担还款义务的责任感等相关方面。一般来说,房地产企业融资具有资金规模大、使用周期较长等特性[1],且房地产经济体量大、振幅宽。一旦房地产企业出现危机,就影响金融稳定,甚至会不利于社会经济的健康发展。
在美国、日本等一些国家及香港地区,已经出现了因房地产泡沫破裂导致房地产投资者损失惨重、国家经济危机发生。其中2007年的美国次贷危机就是因为房地产次级抵押贷款市场出现信用风险,大量借款者不能按期偿还住房抵押贷款而引起,美国十几家次级抵押贷款银行一时间纷纷被迫申请破产保护,且从次贷领域迅速转向优质房贷按揭、公司信贷、消费信贷等,蔓延至全球金融市场及实体经济领域,导致2008年全球金融危机开始全面爆发[2];到2008年11月,美国就业率急剧下降,新增失业人数超过75万人;2009年3月2日,道琼斯指数已经从危机前的14000多点跌到6800点,跌幅超过50%。20 世纪 80 年代末日本也发生了因房地产价格泡沫问题重创日本经济。日本的房地产价格1986-1991 年平均地价增长 207.1%,商业地价更是增长3倍,日本房地产价格泡沫急剧膨胀;日本政府通过提高政府贴现率、停止房地产企业贷款等系列“电击疗法”措施遏制房地产价格的飞速上涨,到1997年名义平均地价比 1991年下降 21.8%,商业地价下降 34.1%,全国土地市值缩水30%[3]。日本房地产泡沫的破裂使日本需求下降、产业抑制、经济萎缩等,日本经济此10年间没有发展,史称“失去的日本十年”。
国内外学者不断应用Logistic 模型于信用风险度量研究。Martin(1977)依据投资主体的风险偏好,基于Logistic 模型探讨公司的违约率、风险警戒线及破产等[4]。Ohlson(1980)通过增加财务变量及虚拟变量构建Logistic回归模型,判别准确率高达96.12%[5]。Sjur W (2001)通过Logit回归分析认为企业规模、资本结构、资产收益率、短期流动性等因素能有效识别公司财务风险度及破产率[6]。国内乔卓(2002)等运用 Logistic 模型分析我国上市公司的违约风险,验证Logistic 模型有较好的应用性[7];庞素琳(2006)通过精选相关变量及样本数量,建立的Logistic回归信用评价模型的判别准确率高达了99.06%[8];张春伟(2012)选取116家房地产企业及16个指标数据构建Logistic模型,模型拟合效果良好,对企业信用风险的判别准确率达到了96.2%[9];王俊籽等(2017)通过比较不同类型信贷风险度量模型在房地产信用风险的预警运用[10],显示Logistic模型相对准确率较高,企业提高股东权益、现金流量以及短期偿债能力等都能够有效降低房地产信贷风险。本文在借鉴国内外学者的研究基础上,结合我国实际情况建立Logistic模型探讨我国房地产企业信用风险。
二、样本选取及初始财务指标选取
Logistic模型使用最大似然估计法对参数进行估计,它对样本数据是否存在正态分布要求不高,所需的参数也较少。Logistic模型表达式形式为:
其中Z=β0+β1x1+β2x2+…+βnxn;β0表示常数项,β1,2…n表示回归系数,x1,2…n表示财务指标自变量,因变量P表示企业违约概率,当Z趋于-∞时,P趋近于0,定义为企业不存在信用风险;当Z趋近于+∞时,P趋近于1,定义为存在信用风险企业[11]。
本文样本选取我国2015年131家房地产上市企业,样本指标分为偿债能力指标、获利能力指标、营运能力指标、发展能力指标、宏观经济指标等五个方面共20个指标(见表1)。未上市企业的财务数据不对外公布,不易获得,而上市企业的财务报告比较齐全,数据经过审计比较真实可靠,容易获得[12]。财务指标数据主要来源wind数据库及中国统计年鉴。
把131家房地产企业分成两组,一组是公司经营业绩良好,没有被“ST”及“*ST”的企业,共126家,是正常组企业;一组是财务状况出现问题,被“ST”及“*ST”的企业,共5家企业,是非正常组企业。“ST”是指证监会宣布对连续两年亏损、出现财务状况异常的上市公司实行特别处理的简称,“*ST”是指证监会宣布对连续三年亏损,有退市风险的上市公司作出退市预警的简称[13]。被“ST”及“*ST”的上市公司一般来说因为连续亏损、公司业绩较差、财务问题严重等,违约概率大,被视作违约企业风向标。

表1 选取指标及分类
三、Logistic模型建立
(一)主成分分析
运用spss19.0软件对131家财务数据进行主成分分析,提取主成份因子。为了消除观测量纲和数量级差异的影响,需要对样本观测数据进行标准化处理。
(1)样本数据处理与检验
表2所示样本数据中并没有存在数据丢失的情况,有效样本数为131个。经过标准化处理的数据可以提高回归分析的准确性。数据标准化处理后还得检验数据是否适合进行因子分析以及来自于正态分布总体,为此选择使用KMO和Bartlett检验方法对数据进行检验。

表2 描述统计量
表3所示KMO度量值为0.618,大于0.5,sig值为0.000,小于显著性水平0.05,表示数据比较适合进行因子分析,符合正态分布性能较好[14]。
(2)公因子解释程度分析
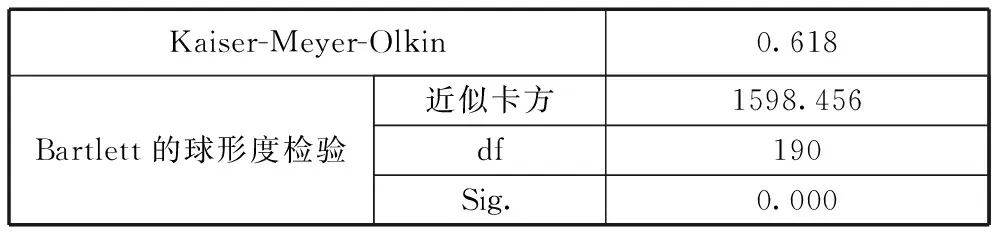
表3 KMO 和 Bartlett 的检验
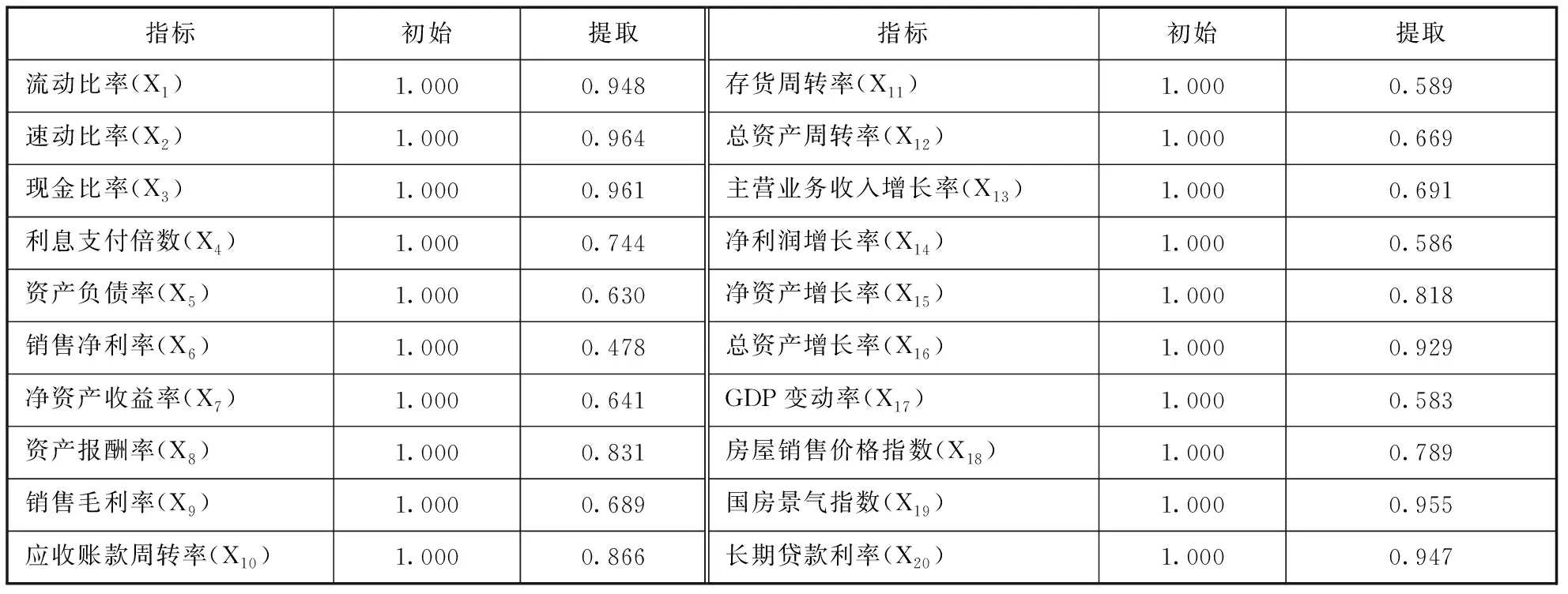
表4 公因子方差
由表4可以看出大部分初始因子的被反映解释程度都很高,只有销售净利率、存货周转率等解释程度相对较低,遗失信息相对多些,但不影响本文所建模型质量。
(3)主成分因子提取。为了降低所选20个财务指标的多重相关性,运用主成分分析法线性变换成少量的不相关综合变量。碎石图是反映各个因子的重要程度,因子越重要,特征值越大,直线也就越陡峭(见图1)。显而易见,前3个因子的特征值最高,作用最明显,从第10个因子开始作用力越来越小,且取值都小于1可以忽略不计。依据总方差及旋转成份矩阵综合计算分析,提取9个主成分因子分别定义为FAC1、FAC2、FAC3、FAC4、FAC5、FAC6、FAC7、FAC8、FAC9,这9个因子共同解释了总方差的76.553%,总的来说因子信息比较完整,9个因子基本上包含了所有指标的信息[15]。这9个因子分别定义:

图1 碎石图
FAC1主要表达了流动比率、速动比率、现金比率等指标,反映了企业的偿债能力;FAC2主要表达了主营业务收入增长率、净资产增长率、总资产增长率等指标,反映了企业的发展能力;FAC3主要表达了资产报酬率、净资产收益率、销售净利率等指标,反映了企业的获利能力;FAC4主要表达了存货周转率等指标,反映了公司的营运能力;FAC5主要表达了房屋销售价格指数,反映了宏观经济指标中的房价因素;FAC6主要表达了应收账款周转率指标,反映了公司的营运能力;FAC7主要表达了利息保障倍数和GDP变动率指标,反映了企业的偿债能力和所处的宏观环境;FAC8主要表达了国房景气指数,反映了企业宏观经济指标中的发展因素;FAC9主要表达了长期贷款利率,反映了企业宏观经济指标中的利率因素。经过标准化处理后,各因子表达式如下(见表5):
FAC1=0.309X1+0.303X2+0.301X3+0.005X4-0.121X5+0.028X6-0.006X7-0.002X8-0.076X9+0.025X10-0.063X11-0.071X12+0.051X13-0.063X14+0.042X15+0.01X16-0.026X18-0.009X19-0.006X20
FAC2=0.018X1+0.018X2+0.017X3-0.036X4-0.004X5-0.044X6-0.022X7-0.04X8-0.001X9+0.01X10+0.011X11+0.069X12+0.285X13+0.208X14+0.312X15+0.325X16+0.049X17-0.041X18+0.00X19-0.003X20
FAC3=-0.017X1+0.017X2+0.018X3+0.117X4+0.031X5+0.315X6+0.348X7+0.358X8+0.051X9+0.007X10-0.043X11+0.255X12-0.071X13+0.067X14-0.053X15-0.049X16-0.113X17-0.014X18+0.048X19-0.016X20
FAC4=-0.095X1-0.045X2-0.032X3-0.23X4-0.405X5-0.133X6-0.071X7+0.141X8+0.253X9-0.144X10+0.610X11-0.052X12-0.042X13+0.074X14+0.037X15-0.003X16+0.217X17+0.132X18-0.007X19+0.066X20
FAC5=0.00X1-0.002X2-0.013X3+0.017X4+0.014X5-0.03X6-0.081X7+0.035X8-0.357X9+0.112X10+0.106X11+0.29X12-0.069X13+0.043X14-0.083X15-0.026X16+0.066X17+0.793X18+0.003X19-0.019X20
FAC6=0.025X1-0.016X2-0.004X3-0.128X4-0.057X5+0.008X6+0.015X7-0.011X8+0.293X9+0.87X10-0.174X11-0.076X12+0.008X13-0.007X14+0.042X15+0.011X16+0.089X17+0.148X18-0.008X19+0.044X20
FAC7=0.00X1+0.011X2+0.015X3+0.707X4+0.041X5-0.026X6+0.099X7-0.055X8+0.111X9-0.034X10+0.007X11-0.124X12+0.025X13-0.018X14+0.03X15+0.013X16+0.619X17+0.097X18+0.005X19-0.001X20
FAC8=-0.005X1-0.003X2+0.003X3-0.132X4+0.044X5+0.117X6-0.003X7-0.01X8-0.034X9-0.006X10+0.009X11-0.076X12+0.00X13+0.021X14+0.001X15+0.009X16+0.13X17+0.002X18+0.965X19+0.019X20
FAC9=-0.003X1-0.001X2-0.003X3+0.163X4-0.005X5-0.016X6+0.016X7-0.014X8-0.075X9+0.056X10+0.08X11+0.015X12-0.006X13+0.009X14-0.014X15+0.001X16-0.154X17-0.043X18+0.018X19+0.961X20
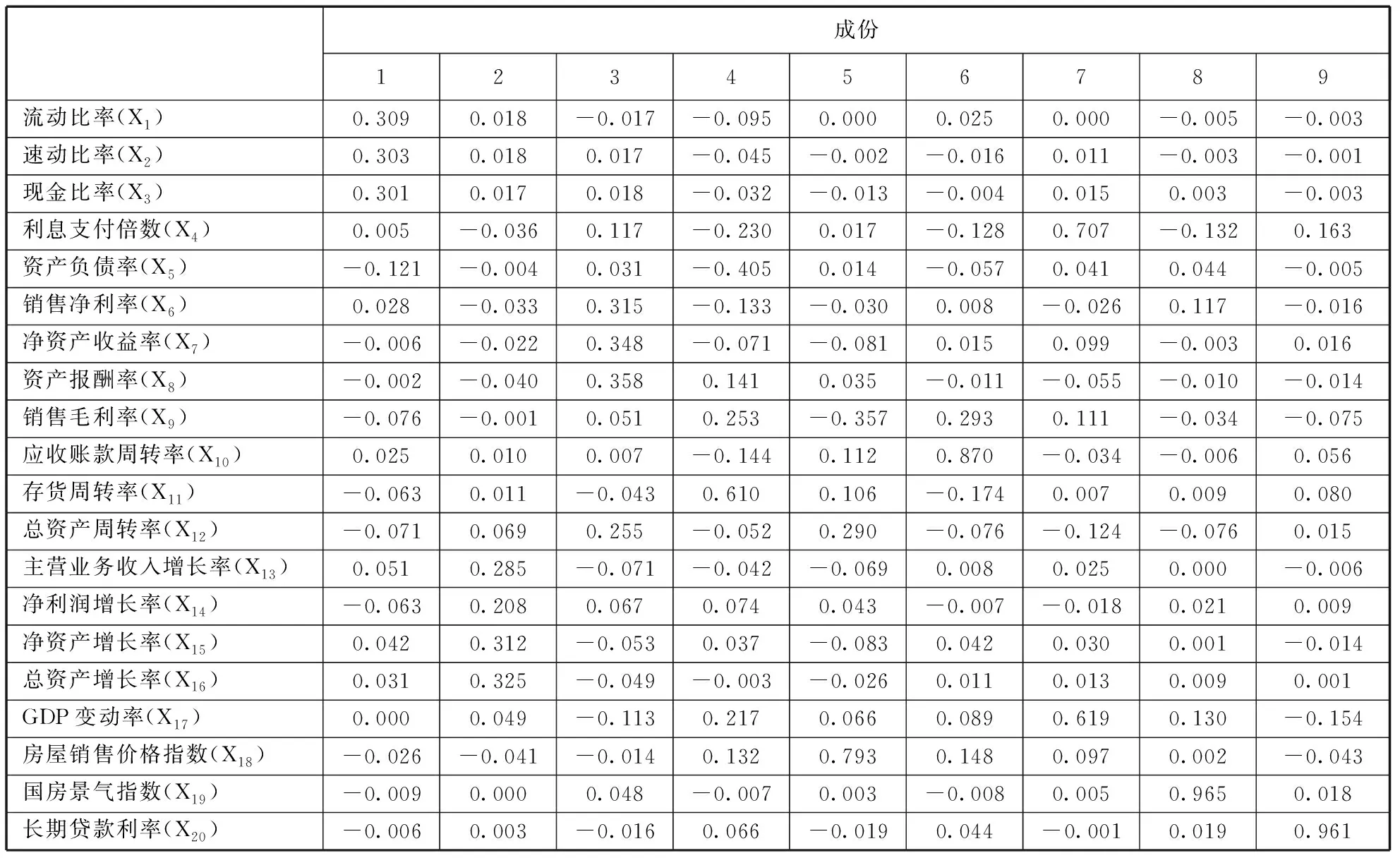
表5 主成分子得分系数矩阵
(二)Logistic模型建立
以上述提取的9个主成分因子作为协变量,企业违约概率作为因变量建立二元logistic回归模型。因研究实际问题需要该模型以P=0.5为分割点,即P>0.5,则该企业为ST企业,为非正常组企业,信用风险大;P<0.5,则该企业为非ST企业,为正常组企业,没有违约风险。样本总数是131家,缺失样本数为0,并且将被ST的企业定义值为1,非ST企业定义值为0(见表6及表7)。

表6 案例处理汇总

表7 因变量编码

表8 Hosmer-Lemeshow 检验
Hosmer-Lem show检验的卡方值为21.423,df(自由度)为8,P值为0.467,说明模型整体拟合度较高(见表8)。
FAC4、FAC5、FAC6、FAC7、FAC9这五个变量的系数显著性都不高,应该剔除后再进行分析(见表9)。FAC1、FAC2、FAC3、FAC8为较影响显著因子,结合本文实际问题研究需要,可引入本文模型协变量(见表10),变量 P表示企业的违约概率,建立Logistic回归模型:

表 9 方程式中的变量
a.在步骤 1 中输入的变量:FAC1,FAC2,FAC3,FAC4,FAC5,FAC6,FAC7,FAC8,FAC9。
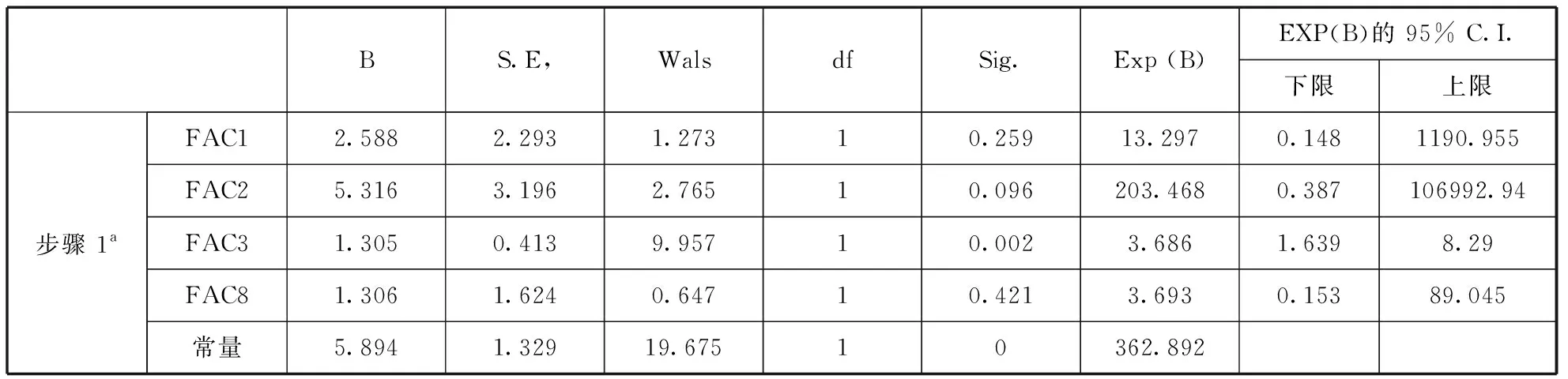
表10 方程式中的变量
a.在步骤1中输入的变量:FAC1,FAC2,FAC3,FAC8。
(三)模型预测正确率
Logistic模型检验出两种情况,第一种情况是将没有存在违约情况的公司误判成存在违约;第二种是将实际存在违约情况的公司误判成不存在违约。第一种情况会高估企业的信用风险,第二种情况刚好相反,会低估企业的信用风险。由表11可以看出,总体预测的正确率达到98.5%,其中ST公司被预测正确的概率只有60%,非ST公司被预测正确的概率达到100%,也就是说在这次实验中出现第一种情况的概率是0,出现第二种情况的概率是40%(见表11)[16]。该模型对ST企业预测效果不是很好,这可能跟ST企业样本量较少及本文假设有关,且我国实际上有的ST企业财务状况到了第三年在政府帮助下转化盈利可能性很大,“ST”及“*ST”的上市公司并非都是一定违约,符合国内实际情况。
总体而言,Logistic模型对于企业信用风险预测的准确度还是很高的,比较适用于我国房地产企业信用风险的判别、度量及预警。

表11 Logistic模型检验结果a
a.切割值为 0.500。
四、结论及建议
本文运用主成分分析法筛选主要影响因子指标,基于Logistic模型原理构建我国上市房地产企业信用风险度量模型,该模型总体预测的正确率为98.5%,这表明Logistic模型能够适用于我国房地产企业信用风险度量及预警。通过该模型对我国2017年房地产上市企业信用风险进行判别分析,除了三家*ST企业有较大违约可能外,其余房地产上市企业都不会有违约风险,房地产上市企业是我国房地产市场的主力军,说明我国目前整体房地产企业市场信用风险状态还是良好。
依据所建模型回归结果显示,判别我国房地产企业信用风险的主要因子是企业获利能力因子FAC3、企业发展能力因子FAC2、企业偿债能力因子FAC1及宏观经济的发展因素FAC8,其主要具体对应相关财务指标分别是流动比率、现金比率、销售净利率、资产报酬率、主营业务收入增长率、净资产增长率、总资产增长率、国房景气指数等。
一般来说,房地产企业产生信用风险的原因可以分为企业内部经营和外部环境两个方面,企业内部经营原因是房地产投资负债规模过大、房地产销售不景气、企业之间的担保违约连锁反应、企业还款责任意识强度等;外部环境原因主要是世界经济危机、房地产严厉调控政策、利率与汇率不利于房地产企业的变化等。2017年3月份我国已有十几个大、中城市实施限购,2018年中美发生贸易关税战,美国方面将可能对中国几千亿美元商品的加征关税。中美贸易战可能导致汇率和货币政策的调整,会使房地产和楼市的流动性出现紧缺,房地产开发商融资难度加大,房价可能加速下跌,使房地产市场萎靡[17],导致房地产企业信用风险加剧。
为了防止我国房地产企业信用风险的出现,结合本文模型分析,提出如下政策建议:
(1)大力提高房地产企业自身盈利能力。房地产企业要在新环境背景下加强内部经营与内部控制能力,提高企业盈利能力,企业就有足够利润偿还债务,企业违约风险就越小。树立优良产品理念,加强房地产企业内部管理与监督,积极通过多种途径提升员工技术专业水平、创新能力、道德水平,形成优秀企业文化,创立优质企业品牌,不断提升房地产企业竞争力,使企业盈利能力与偿债能力不断加强。
(2)积极推广不动产登记制度,在不动产登记系统增设信用档案等级栏目,完善房地产企业信用管理制度,增强企业还款意愿强度。不动产登记制度能使归属产权明确清晰,有利于权利人的财产保护,有利于房地产市场的交易安全。构建一个全国互联网的不动产登记系统,保证房地产市场信息准确与透明,在不动产登记系统增设信用等级档案栏目,一旦发现存在失信行为,就纳入信用档案。消费者在进行消费前可以先查询该公司在信用档案中是否有不良记录,有利于完善房地产企业信用管理制度,保护消费者权益[18]。不断提高不动产统一登记质量,就可以逐步抑制房地产市场圈房、炒房等行为,提升房地产市场的规范性与秩序性,迫使房地产企业自觉维护信用等级。
(3)测算我国小康水平的基本人均必需居住面积及商品房基本价格,实施“平均空间,超住多交,不超不交,少住多补”房产税征收与补贴政策,促进房地产市场健康发展。本文模型分析指出宏观经济发展环境是房地产企业信用能力的重要影响因素之一,国家要基于人均国内生产总值发展轨迹、人均房地产需求量及社会主义商品市场体系,发挥计划经济与市场调节功能,依据中国社会发展长期趋势及房地产市场的短期特点[19],测算我国小康水平基本人均居住面积,测算社会主义生产关系下的商品住房基本价格。进而制定各种相关政策,加强宏观调控,迎接中美贸易战,不断深化改革与顶层设计,完善房地产市场社会主义分配机制,实施“平均空间,超住多交,不超不交,少住多补”房产税征收与补贴政策,增强广大普通人民的住房购买能力,促进房地产销售,提升国房景气指数,提高广大人们的生活水平,落实“房子是用来住不是用来炒的”,减少国有资源在房地产市场上过度大量的不合理浪费,加强房地产信贷风险监控与预警能力,防范房地产企业信贷违约发生,促进房地产企业及我国经济稳定发展,促进社会主义小康水平全面实现。
猜你喜欢
化工管理(2022年13期)2022-12-02
数学物理学报(2022年5期)2022-10-09
中国信用(2022年4期)2022-09-28
数学物理学报(2021年4期)2021-08-30
中等数学(2020年1期)2020-08-24
文化创新比较研究(2020年8期)2020-01-02
计算机应用(2018年12期)2019-01-08
商周刊(2018年26期)2018-12-29
特别健康(2018年3期)2018-07-04
当代经济(2016年26期)2016-06-15
