
基于元数据的流程模型相似性度量方法
2019-01-19 08:26:06何克清
计算机技术与发展 2019年1期
吴 军,李 昭,陈 鹏,何克清
(1.三峡大学 计算机与信息学院,湖北 宜昌 443002;2.武汉大学 计算机学院,湖北 武汉 430072)
0 引 言
全球化、虚拟化、网络化组织(包括企业)的业务流程管理变得日益复杂,给业务流程的柔性建模、高效调度、智能分析、合规控制等方面提出了一系列新的挑战[1]。业务流程管理技术(business process management,BPM)致力于为流程的分析、定义、执行、监视和管理提供支持,其目标在于改进产品质量,提升服务水平。
BPM是现代众多信息系统的共性基础技术,并在学术和工业领域发展迅速。例如,SAP公司拥有超过600种业务流程模型,其收集了荷兰地方政府大量的流程模型[2],这些业务流程模型通常用于描述组织提供和实现某些服务的内部过程。随着企业业务流程模型集的增大,愈发需要符合特定标准的业务流程模型管理方法和工具。
文中重点阐述了基于元数据的流程模型相似性度量方法。由于流程注册元模型框架(MFI-5)[3]忽略了业务流程的顺序特征,导致缺少用于描述不同流程元素间执行顺序的特征。为了解决该问题并在实际应用中有效实现流程建模的目标,对MFI-5中位于抽象元类(abstract metaclass)层的元素进行适当裁剪,同时对在实际应用中不直接参与流程构建的元素进行删减,并添加用于描述流程执行顺序的有向关联特征(association),构建出流程模型描述框架(process model description framework,PMDF)。然后依据PMDF定义流程模型相似性特征集(similarity feature set,SFS),同时采用业界广泛使用的业务流程建模标注语言[4](business process modeling and notation,BPMN)对实际流程进行建模,得到BPMN模型。再利用SFS对BPMN模型进行标识与量化,得到模型在多个特征中的向量,最后通过基于距离的相似性算法计算任意两个模型在某一特征中向量的相似性,进而综合依据两个模型在7个特征中向量的相似性获取两个流程模型的相似性。
1 相关工作
流程模型相似性度量的研究越来越受学术界和产业界的广泛关注。两个流程模型间的相似性度量通常涉及三个方面:文本概念相似性、结构相似性、行为相似性[5]。
对于文本概念相似性,Akkiraju等[6]从流程文本概念的角度来评估相似性;Dijkman等[7]综合度量流程每个节点文本概念的相似性,并将其作为度量两个流程模型相似性的一个重要指标。
对于结构相似性,Yan等[9]选择特定特征来描述业务流程模型,然后通过两个流程模型间匹配的特征个数来评估其相似性;曹斌等[9]提出用最大公共图代替图编辑距离,以便在查询响应时间方面达到更好的性能;黄子乘等[10]提出了一种基于流程相似性的自动服务发现框架。
对于行为相似性,除了文本标签相似性和结构相似性,基于行为相似性的流程模型搜索也引起了学术界的关注。Zha等[11]提出基于转换邻接关系集(TAR)的流程相似性度量方法;Jin等[12]从流程模型中提取四类行为特征:存在性、因果关系、冲突关系和并发关系,然后基于这些特征计算两个流程模型的行为相似性。同时,Jin等[13]也度量了基于行为的流程模型之间的相似性,并使用索引进行查询处理。Grigori等[14]利用两个流程模型间相似性的思想来发现满足用户需求的服务。
除上述三类工作外,还存在建模语言、查询方法、聚类等其他工作。标准的业务流程建模符号对于流程的描述具有重要意义,其提供了广泛的建模方式。Cheikhrouhou等[15]描述了BPMN在时间约束下的局限性。Geiger等[16]对基于BPMN2.0的支持和实施进行了研究和分析。Syukriilah等[17]对基于Petri网的业务流程模型的结构相似性进行了分析。BPMN可根据参与者在业务流程中扮演的角色来分配相应的流程资源,这种分配方式是一致且结构化的[18]。薛智山等[19]对基于BPMN的工作流程执行过程进行了适应性方法研究。为了研究个人和相关因素对流程模型的可理解性造成的影响,Qiao等[20]在统计语言建模技术和结构匹配的基础上,提出了一种聚类并检索业务流程的方法。
文中同时关注流程模型的结构相似性和行为相似性,且精简并补充了元数据(MFI-5),提出了基于元数据的流程模型相似性度量方法,为流程推荐提供决策支持。
2 流程模型描述框架与相似性特征集的构建
文中所提方法基于作者前期研究中研发的ISO国际标准:流程注册元模型框架[3](meta-model for process model registration,MFI-5)。采用一种具体的建模语言来描述特定的流程模型,然后从该模型中选择出相关的元数据,并利用MFI-5对所选的元数据进行注册与管理,这是MFI-5的主要功用。
基于MFI-5构建流程模型描述框架(PMDF)。通过经验主义研究,对MFI-5中位于抽象元类层的元素进行适当裁剪,同时对在实际应用中不直接参与流程模型构建的元素进行删减,根据流程建模的目标构建出PMDF,如图1所示。
PMDF由6个类特征(Class)和1个关联特征(Association)共7个相似性特征组成。其中类特征为:Process、Resource、Event、Sequence_Dependency、Split_Dependency、Join_Dependency,分别用于指出流程模型执行过程中涉及的各种流程模型元素,关联特征是指任意两个类特征间的关联关系,用于指出流程模型元素的执行顺序。
在PMDF中须均等考虑上述7个相似性特征,表1阐述了各个特征描述的范畴。
阐明7个相似性特征后,为了便于对流程模型进行准确描述并获取模型在每个特征中的向量,文中后续内容采用表1阐述的7个相似性特征。

图1 流程模型描述框架

NOFEATURESCOPE1Process用于特定目标的架构化活动(activities)或任务(tasks)2Resource流程利用、创建、消耗的实体或虚拟资源3Event特定情况的发生4Sequence_Dependency流程间的控制约束,指明流程按顺序执行5Split_Dependency流程间的控制约束,指明若一个前驱流程执行完毕,一个或多个后继流程将并行执行6Join_Dependency流程间的控制约束,指明若前驱的多个流程执行完毕,后继的一个流程将开始执行7Association指明流程间有向的关联关系
相似性特征构成流程模型相似性特征集SFS,定义SFS的内容如下:
SFS={Process,Sequence_Dependency,Resource,Split_Dependency,Event,Join_Dependency,Association}
(1)
相似性特征集的成功定义为流程模型的描述提供了元数据支持,并为基于距离的向量相似性计算奠定基础。
3 流程模型相似性度量
3.1 流程模型的标识与向量化
在业务流程相似性度量和流程挖掘领域,业务流程建模标注语言(BPMN)已成为一种通用的图形化描述语言,广泛应用于流程建模[18]。BPMN由于其具有图形化特征,且其抽象级别位于实际流程与MFI-5之间,尤其能描述多方参与的复杂应用场景,因此适合进行流程的描述。为了度量流程模型间的相似性,采用SFS对BPMN模型进行标识与量化,得到模型在多个特征中的向量,为基于距离的特征向量相似性计算奠定基础。以图2中的3个在线售货服务BPMN模型为例(Model1、Model2、Model3分别记为M1、M2、M3),通过7个相似性特征中的向量来标识并量化BPMN模型。
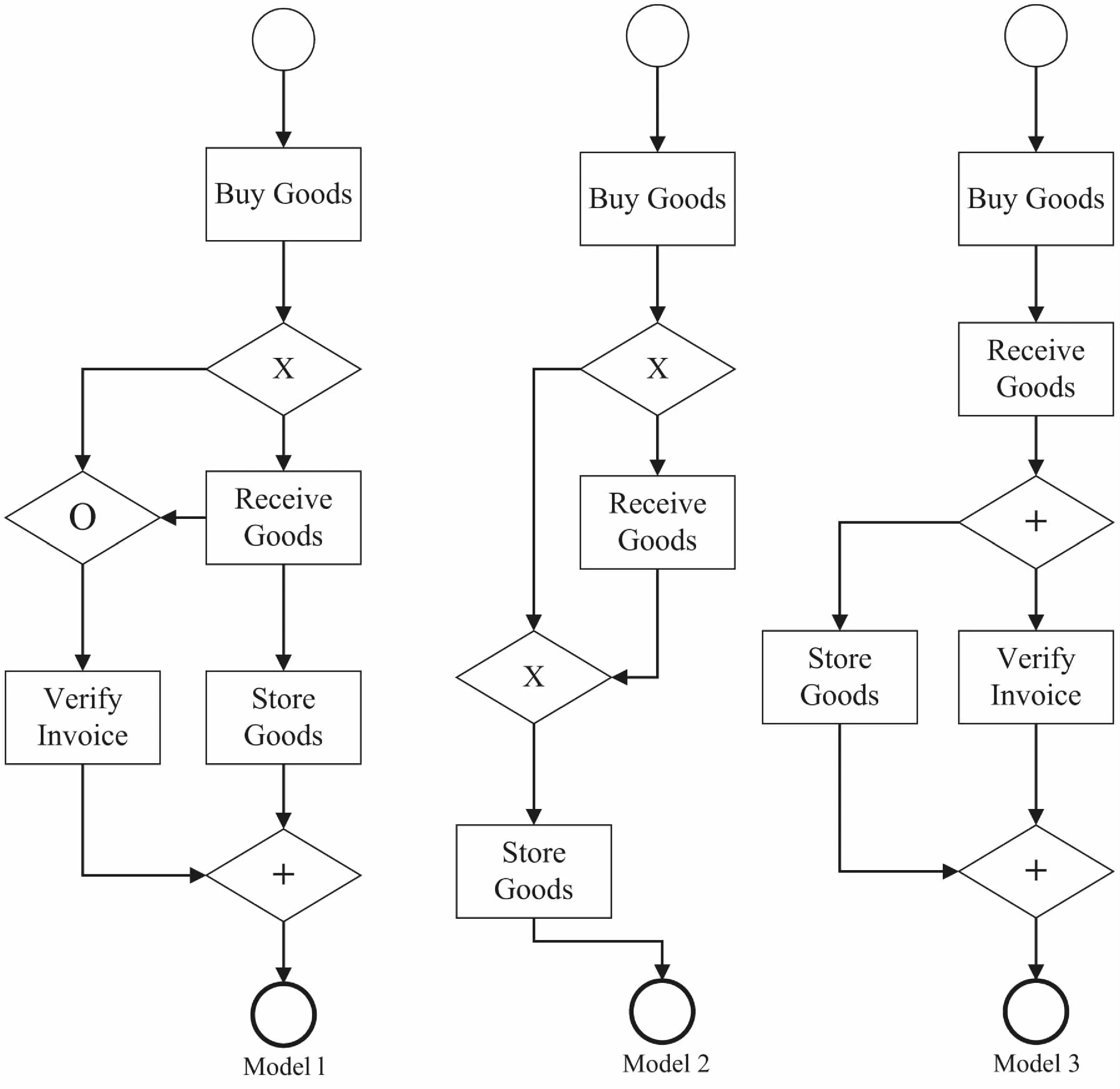
图2 在线售货服务BPMN模型
相似性特征1(Process)。
图2中的BPMN模型包含4种不同类型的流程(矩形框):购买商品(BG)、获得商品(RG)、验证发票(VI)、储存商品(SG)。在Process特征中,采用具有4个特征值的向量对3个模型分别进行描述,每个特征值对应于一种类型的流程,4个特征值分别为BG、RG、VI、SG,每个特征值用数字标识了一个模型包含该特征值的数量。3个模型在Process特征中的向量表示如下:

Model IdBGRGVISG111112110131111
相似性特征2(Resource)。
M1的直接参与者为Jack、Brook、Lily,因此M1的Resource为Jack、Brook、Lily。同理可知,M2的Resource为Jack、Brook;M3的Resource为Jack。所以,图2中的BPMN模型包含3种不同类型的资源:Jack、Brook、Lily。在Resource特征中,采用具有3个特征值的向量对3个模型分别进行描述,每个特征值对应于一种类型的资源,3个特征值分别为Jack、Brook、Lily,每个特征值用数字标识了一个模型包含该特征值的数量。3个模型在Resource特征中的向量表示如下:
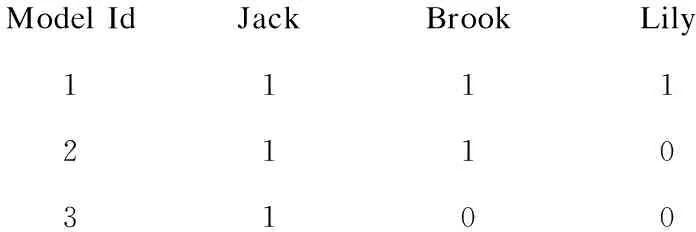
Model IdJackBrookLily111121103100
相似性特征3(Event)。
图2中的BPMN模型包含2种不同类型的事件(圆形框):启动(start)、结束(end)。在Event特征中,采用具有2个特征值的向量对3个模型分别进行描述,每个特征值对应于一种类型的事件,2个特征值分别为start、end,每个特征值用数字标识了一个模型包含该特征值的数量。3个模型分别在Event特征中的向量表示如下:

Model IdStartEnd111211311
相似性特征4(Sequence_Dependency)。
图2中BPMN模型包含顺序依赖。在Sequence_Dependency特征中,采用具有2个特征值的向量对3个模型分别进行描述,每一个特征值对应于顺序依赖特征在3个模型实例中分别出现的次数。2个特征值分别为Sequence_Dependency、Substitution,每个特征值用数字标识了一个模型包含该特征值的数量。3个模型分别在Sequence_Dependency特征中的向量表示如下:

Model IdSequence_DependencySubstitution100200310
(注:特征值Substitution为补充值,以使其符合向量的形式化定义,后文同理。)
相似性特征5(Split_Dependency)。
图2中的BPMN模型包含分支依赖。在Split_Dependency特征中,采用具有2个特征值的向量对3个模型分别进行描述,每一个特征值对应于分支依赖特征在3个模型实例中分别出现的次数。2个特征值分别为Split_Dependency、Substitution,每个特征值用数字标识了一个模型包含该特征值的数量。3个模型分别在Split_Dependency特征中的向量表示如下:

Model IdSplit_DependencySubstitution120210310
相似性特征6(Join_Dependency)。
图2中的BPMN模型包含联结依赖。在Join_Dependency特征中,采用具有2个特征值的向量对3个模型分别进行描述,每一个特征值对应于联结依赖特征在3个模型实例中分别出现的次数。2个特征值分别为Join_Dependency、Substitution,每个特征值用数字标识了一个模型包含该特征值的数量。3个模型分别在Join_Dependency特征中的向量表示如下:

Model IdJoin_DependencySubstitution120210310
相似性特征7(Association)。
图2中的BPMN模型包含5种不同类型的关联:购买商品→获得商品(BG→RG)、购买商品→验证发票(BG→VI)、获得商品→储存商品(RG→SG)、购买商品→储存商品(BG→SG)、获得商品→验证发票(RG→VI)。在Association特征中,采用5个特定值的向量对3个模型分别进行描述,每个特征值对应于一种类型关联,5个特征值分别为(BG→RG)、(BG→VI)、(RG→SG)、(BG→SG)、(RG→VI),每个特征值用数字标识了一个模型包含该特征值的数量。3个模型分别在Association特征中的向量表示如下:

Model IdBG→RGBG→VIRG→SGBG→SGRG→VI111101210110310101
3.2 基于距离的流程模型向量相似性计算
文中将BPMN模型间的相似性计算过程转换为计算两个模型在7个特征中向量间的距离(相似性)[21],即依据7个特征中向量的相似性值,计算出两个流程模型间的相似性。依据PMDF定义流程模型相似性特征集,以通过每个特征中向量的相似性确保BPMN模型的相似性。
PMDF由6个类特征(Class feature)和1个关联特征(Association feature)共7个特征组成。在PMDF中须均等考虑上述7个相似性特征:Process、Resource、Event、Sequence_Dependency、Split_Dependency、Join_Dependency、Association,这些特征构成SFS,如式1所示。基于SFS对BPMN模型进行标识和量化,得到模型在7个特征中的向量,然后通过基于距离的算法计算任意两个模型在某一特征中向量的相似性。文中采用谷本系数(Tanimoto Coefficient)[22]计算两个模型在某一特征中向量的相似性。
依据图2阐述的在线售货服务BPMN模型可知,BPMN模型集(MS)包含3个BPMN模型,定义MS的内容如下:
MS={M1,M2,M3}
(2)
定义式3对MS中任意两个BPMN模型在某一特征中向量的相似性进行计算,其中,MA和MB分别代表MS中任意两个模型。
Sim(MAi,MBi)=Tanimoto(MAi,MBi)=
MA,MB∈MS,i=1,2,…,7
(3)
其中,MAi和MBi分别表示MS中任意两个模型在第i个特征中的向量,且i的取值为1至7间的整数(包含整数1和7);Sim(MAi,MBi)指向量MAi与MBi间的相似性,其值等于Tanimoto(MAi,MBi),即向量MAi与MBi间的距离,向量间的相似性计算结果处于[0,1]范围内。通过式3计算得到MS中任意两个BPMN模型在7个特征中向量的相似性,如表2所示。

表2 BPMN模型在7个特征中向量的相似性
依据表2可知,BPMN模型M1与M2在Process特征中向量的相似性为0.75,在Resource特征中向量的相似性为0.67,在Event特征中向量的相似性为1,在Sequence_Dependency特征中向量的相似性为1,在Split_Dependency特征中向量的相似性为0.67,在Join_Dependency特征中向量的相似性为0.67,在Association特征中向量的相似性为0.40。其他模型在各特征中向量的相似性依此类推。
根据表2的计算结果进而获取两个BPMN模型的相似性,定义式4对MS中任意两个模型的相似性进行计算。
MA,MB∈MS
(4)
其中,Sim(MA,MB)是指BPMN模型MA与MB间的相似性。
依据计算结果构建出以上3个在线售货服务BPMN模型的相似性矩阵(SM):
依据相似性矩阵SM可知,M1与M1的相似性为1,M1与M2的相似性为0.73,M1与M3的相似性为0.63,M2与M3间的相似性为0.68。
为了给流程模型推荐提供决策支持,将模型相似性度量结果的值域进行划分。即将值域[0,1]划分为3个级别:[0,0.4),[0.4,0.7)和[0.7,1],即如果相似性属于[0,0.4),则将其视为较低的相似性(第三级),[0.4,0.7)视为中等相似性(第二级),[0.7,1]视为较高的相似性(第一级)。流程模型间的相似性所处级别越高,一方面能够更加有效地进行流程间相似性组件的替换与集成,为流程的变更提供支持;另一方面,能够在当前业务流程失效或异常的情况下,优先作为替代流程。
4 结束语
业务流程相似性的研究仍然存在诸多挑战与困难。文中提出一种基于元数据的流程模型相似性度量方法以度量流程模型间的相似性。构建了基于MFI-5的流程模型描述框架及流程模型相似性特征集;从相似性特征集的7个特征维度对BPMN模型进行向量化,得到流程模型在7个特征中的向量,为相似性计算奠定基础;使用基于距离的算法分别计算两个模型在7个特征中向量的相似性;均等权衡7个特征中向量的相似性,计算出两个流程模型间的相似性,依据任意两个流程模型间的相似性,构建流程模型相似性矩阵;利用所提方法对典型的在线售货服务流程间的相似性开展度量实验,分析讨论实验结果,为流程的变更和推荐提供决策支持。
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
数学物理学报(2022年5期)2022-10-09 08:56:44
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
加油站服务指南(2021年4期)2021-07-21 02:29:24
河北画报(2020年8期)2020-10-27 02:54:20
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
电子测试(2018年23期)2018-12-29 11:11:28
现代营销(创富信息版)(2018年10期)2018-10-12 03:01:32
中国商论(2016年34期)2017-01-15 14:24:22
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
