
基于卷积神经网络的宫颈癌细胞图像识别的改进算法
2019-01-18 12:26:28夏为为夏哲雷
中国计量大学学报 2018年4期
夏为为,夏哲雷
(中国计量大学 信息工程学院,浙江 杭州 310018)
宫颈癌细胞的准确识别对临床诊断具有重大研究意义,现阶段对宫颈癌细胞的诊断主要依靠医生的肉眼判断,仅凭借临床经验判定可能会出现较高的误差:其一,宫颈癌细胞之间存在复杂性和差异性并且癌变细胞的形状是不规则的;其二,宫颈癌细胞图像数据具有高阶统计的特性,导致宫颈癌细胞之间存在大量的冗余信息[1].然而利用卷积神经网络对图像进行处理则可以提取图像较深层次的特征,使得提取的特征具有更精确的表达能力.
卷积神经网络在图像处理等方面的研究和发展具有重要的作用,利用卷积神经网络可以模拟人脑视觉中枢的功能对信息进行更深层次的提取,避免了人工提取特征不精确的问题.周凯龙等[2]使用卷积神经网络实现对手写字体的分类,陶源等[3]提出了卷积神经网络在特征提取时具有鲁棒性的观点,肖志鹏[4]等利用卷积神经网络提高了对绘画图像的分类效率,特征征提取的精确度对卷积神经网络的学习性能研究具有至关重要的作用,因此,有必要对卷积神经网络的卷积层和池化层进行优化来达到提高算法识别率的目的[5],赵显达等[6]使用了基于卷积神经网络的平均池化模型实现了人脸识别并取得了较好的结果,时增林等[7]使用基于卷积神经网络的最大池化模型提高了对人群计数方法的识别率.文献[6]在池化过程中将池化域中所有元素都分配相同的权值,文献[7]将池化域中非最大元素的权值全部舍弃.针对文献[6]和文献[7]在池化过程中存在容易损失大量有用信息导致识别率不高的问题,本文提出了一种改进的算法.该算法基于卷积神经网络的框架,对下采样过程中的池化模型进行改进.这种改进的池化模型是给池化域中的数值分配合适的权值,进而提高了特征提取的准确性.基于卷积神经网络的改进算法降低了宫颈癌细胞图像的识别错误率.
1 卷积神经网络
输入层、隐层和输出层构成了卷积神经网络的一般结构[8],其中隐层主要包含卷积层和池化层,卷积神经网络的隐层可以避免在特征提取的过程中出现人工提取特征的主观性和不定性,使输出层的表达更接近于真实值.
1.1 卷积神经网络的结构
卷积神经网络的结构如图1.
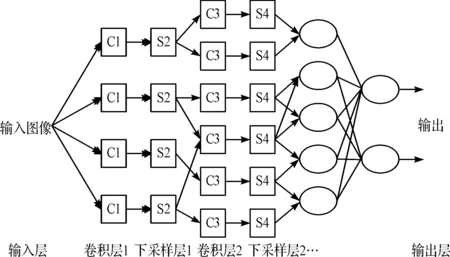
图1 卷积神经网络结构图Figure 1 Structure of convolution neural network
图1中将未经处理的图像作为卷积神经网络的输入,C1是通过将卷积核和输入层的图像进行卷积运算生成对应的卷积特征图,由于有4个卷积核所以C1中包含4个卷积特征图,由C1至S2是下采样过程,具体实现是将C1中的连续4个像素点进行求平均或者求最大值运算,然后加权值和偏重,将其映射到S2的一个点上.由于C1到S2是单独下采样过程,所以S2也包含4个不同的下采样特征图,如此重复卷积层与下采样层,最后将得到的特征图作用于输出.
1.2 卷积层
卷积层的输入单元与输出单元之间采用了稀疏连接和参数共享,稀疏连接是指网络中的神经元并不是全连接的,而是每个神经元只连接上一层的一个小区域,假如某个神经元有i个输入和j个输出,所以根据矩阵乘法原理传统神经网络需要i×j个参数,相应算法的时间复杂度是O(i×j),假设每个输出单元的连接数量是k,那么稀疏连接的方式仅需要k×j个参数以及O(i×j)的时间复杂度.在卷积神经网络中,只要k比i小几个数量级就可以达到比较好的识别效果.参数共享的实质是同一个参数作用于同一个模型中的多个函数,在一般的人工神经网络中,权重矩阵的每个参数只使用一次,然而在卷积神经网络当中,使用卷积核的每一个参数作用于输入单元的每一个位置上,这就明显地减少了模型的存储需求个数.因此,在卷积层中采用稀疏连接和参数共享的方法明显地减少了网络的参数和复杂度.卷积过程如图2所示,用一个可训练的卷积核分别与输入层中与卷积核相同大小的矩阵卷积,设卷积核的大小为n×n的矩阵C,输入图像是m×m的矩阵M,激活函数S()为Sigmoid函数,然后加一个偏置bx,设卷积核的移动步长是1,得到(m-n+1)×(m-n+1)的卷积特征图F,计算公式为
(1)
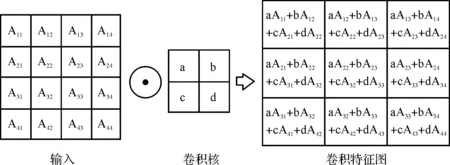
图2 偏置为0的卷积过程示意图Figure 2 Convolution process with the bias of zero
1.3 下采样层
下采样层是对特征的再一次提取,其中最重要的步骤就是池化.为了更方便地对某个区域的特征值进行统计与分析,往往需要得到能代表该区域总体特征的新特征,该区域称为池化域,在该区域提取新特征的过程就是池化.经过池化后得到的下采样特征图不仅能抗形变而且还能够防止过拟合,在池化过程中设池化域的大小c×c,移动步长为c,池化过程如图3所示.设经过卷积运算后得到的卷积特征图是8×8的矩阵,如图3(a),其中用4×4灰色填充的部分表示池化域,设移动步长c等于4,经过池化后得到的下采样特征图如图3(b).
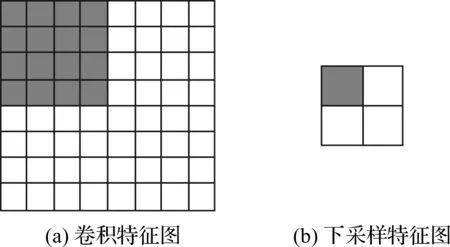
图3 池化过程示意图Figure 3 Schematic diagram of pooling process
图3(b)中灰色填充的部分表示对卷积特征图中对应灰色填充区域池化的结果,其本质就是池化函数P与池化域相作用的结果,设矩阵F为卷积运算后得出的卷积特征图,池化函数是P,然后再加上偏置bx,得出下采样特征图S,计算公式如式(2)所示:
S=P(F)+bx.
(2)
文献[6]使用的平均池化模型和文献[7]使用的最大池化模型是经典池化模型中最常用的两种.平均池化模型是指在池化的过程中,求出池化域内所有元素的平均值作为下采样的特征值[9],平均池化可以降低由于在特征提取过程中领域大小限制导致的估计值方差增大的误差,更大程度上保存图像的背景信息;最大池化模型是指采用池化域中所有元素的最大值作为下采样的特征值[10],最大池化可以降低由于卷积层参数误差导致估计值偏移的误差,更大程度上保存图像的纹理信息.
设矩阵F为图2得到的卷积特征图,池化域大小是c×c,偏置是bx,移动步长是c,则平均池化和最大池化的算法表达式分别如式(3)和式(4)所示:
(3)
(4)
式(4)中:i∈[2l-1,2l+c-2],j∈[2k-1,2k+c-2].Fij是卷积特征图F中大小为c×c的池化域中对应的元素,Slk是根据大小为c×c的池化域使用平均池化和最大池化算法得到的下采样特征值.图4是最大池化和平均池化的池化过程示意图,设池化域的大小是2×2,移动步长是2,最大池化分别将池化域为2×2的所有特征值求出最大值作为下采样特征图中的对应特征值,平均池化分别将池化域大小为2×2的所有特征值求出平均值作为下采样特征图中的对应特征值,得到两种池化模型的下采样特征图如图4.
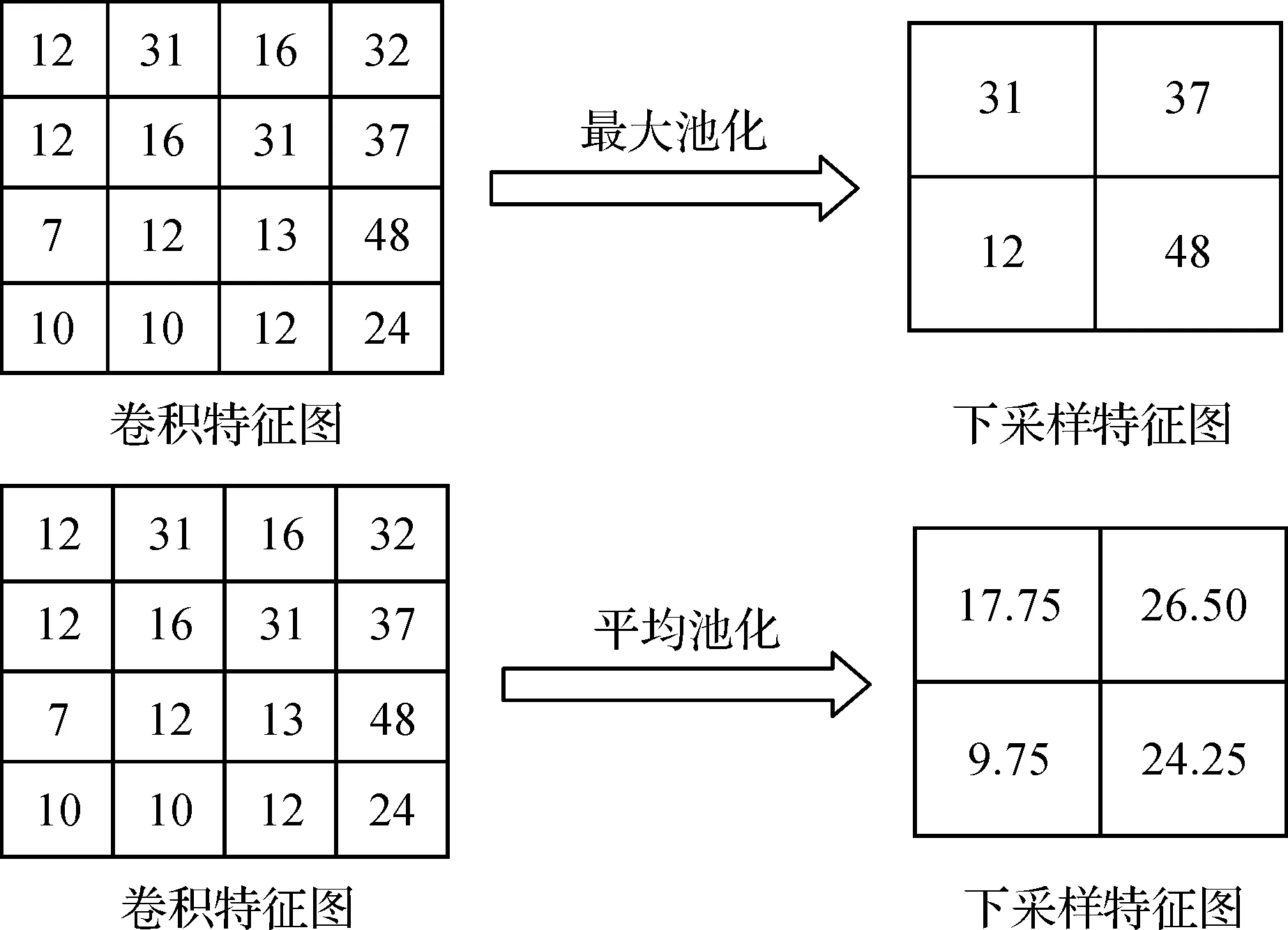
图4 两种池化模型的池化示意图Figure 4 Schematic diagram of two pooling models
2 改进算法
2.1 改进算法的措施
平均池化和最大池化在下采样过程中提取的特征值不能很好地反映出全局特征,平均池化是给每个池化域内的元素赋予一样的权值系数,然而,图像的每个区域的重要性并不是同等的,会导致信息的冗余;最大池化是将池化域内的非最大元素全部舍弃会导致信息有所丢失.本文基于卷积神经网络提出了一种改进的算法.该算法对下采样过程中的特征提取阶段的池化模型进行改进,这种模型对池化域的不同元素分配合适的池化权值,使提取的特征值更好地表达全局特征.改进池化模型的算法表达式如下:
(5)
式(5)的实质是利用池化因子μij对平均池化算法进行优化处理,使得优化后的特征提取更加精确,其中池化因子的表达式为
(6)
式(6)中c表示池化域的边长,Fij是卷积特征图F中大小为c×c的池化域中对应的元素,a是池化域中所有元素的总和,σ是标准差,池化域中所有元素的值决定了池化因子的值,从而克服了平均池化和最大池化特征表达具有片面性的问题,有效避免最大池化方法造成的关键特征丢失问题和平均池化造成的较大特征值被弱化的问题,进而使不同池化域都可以提取更准确的特征.本文提出的基于卷积神经网络的改进算法降低了对宫颈癌细胞图像的识别错误率.
2.2 改进算法的实现
改进池化后得到的下采样特征图如图5,设池化域的大小是2×2,池化的移动步长是2,偏置为0,首先池化域中各项元素的值Fij是已知的,再根据式(6)求出池化域中各元素的池化因子,将得到的池化因子带入式(5),即得出改进池化后的下采样特征图中对应元素的下采样特征值.改进的池化算法对池化域中不同的元素加入不同的池化因子,对于池化域内较大的元素加大其对应的因子,对于较小的元素减少其池化因子,使得提取的特征对全局特征的表达更加准确,进而降低了对宫颈细胞图像识别错误率.
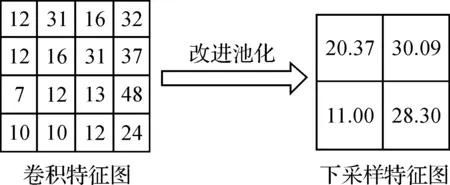
图5 改进池化过程示意图Figure 5 Schematic diagram of improved pooling process
3 实验结果与分析
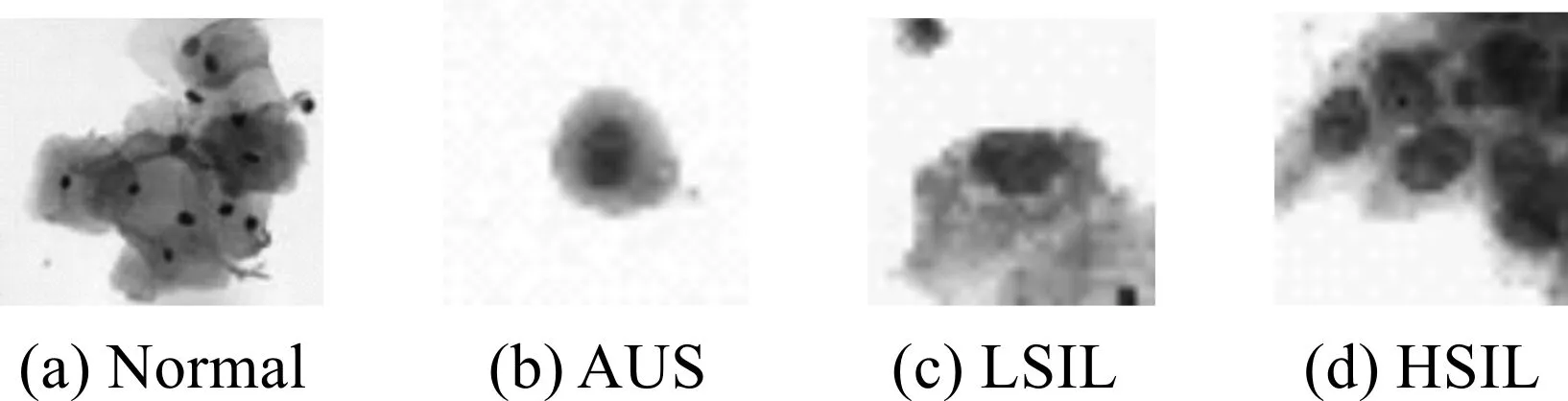
图6 四类宫颈细胞图像Figure 6 Four types of cervical cell images
本实验在宫颈细胞图像数据集上分别对文献[6]、文献[7]和改进算法在识别错误率上进行对比和分析研究.实验是在CNTK的搭建平台下使用8核CPU,8G内存实现的,网络结构在经典VGG16[11]模型的基础上改进的,输入层是32×32×3的图像,卷积层是3×3,移动步长是为1,池化层是采用了本文提出的改进池化,池化域大小是2×2,移动步长为1,全连接层的特征输出层Fc1是512,分类层Fc2是4,其他的实验平台有可能对实验结果造成一定的影响.本实验在每个卷积层和激活层之间使用了批量正则化,使用mini-batch为128的随机梯度下降算法来优化模型参数,使用常数项为0.9的动量,权重衰减参数为0.000 1,学习速率初始化为0.01,被训练的宫颈细胞图像分为4类,如图6,分别是正常细胞图像(Normal)、不能确定为低度病变或者高度病变细胞图像(AUS)、低度病变细胞图像(LSIL)以及高度病变细胞图像(HSIL).实验设置14 112条宫颈细胞图像作为训练数据,5 000条宫颈细胞图像作为测试数据,识别的结果分为两类,一类是假阳性(即把HSIL、LSIL或者AUS识别成Normal),另一类是假阴性(即把Normal识别成HSIL、LSIL、或者AUS),这两类的识别错误率之和称为总的识别错误率.实验分为三组进行训练,分别是将文献[6]、文献[7]和改进算法对宫颈细胞图像进行识别分类.
3.1 实验结果
分别使用文献[6]、文献[7]和改进算法应用于宫颈癌细胞图像的识别中,不同迭代次数下的识别错误率曲线如图7.由图7可以看出宫颈癌细胞图像的识别错误率前期具有较快的下降速度,随着迭代次数的增加,识别错误率下降速度逐渐降低,当迭代到120次左右时,识别错误率趋于稳定,其中文献[6]、文献[7]和改进的池化算法对宫颈细胞图像的识别错误率分别稳定在5.25%、4.74%和4.38%左右.可见改进的算法比文献[6]和文献[7]的算法对宫颈癌细胞图像的识别具有更低的错误率.
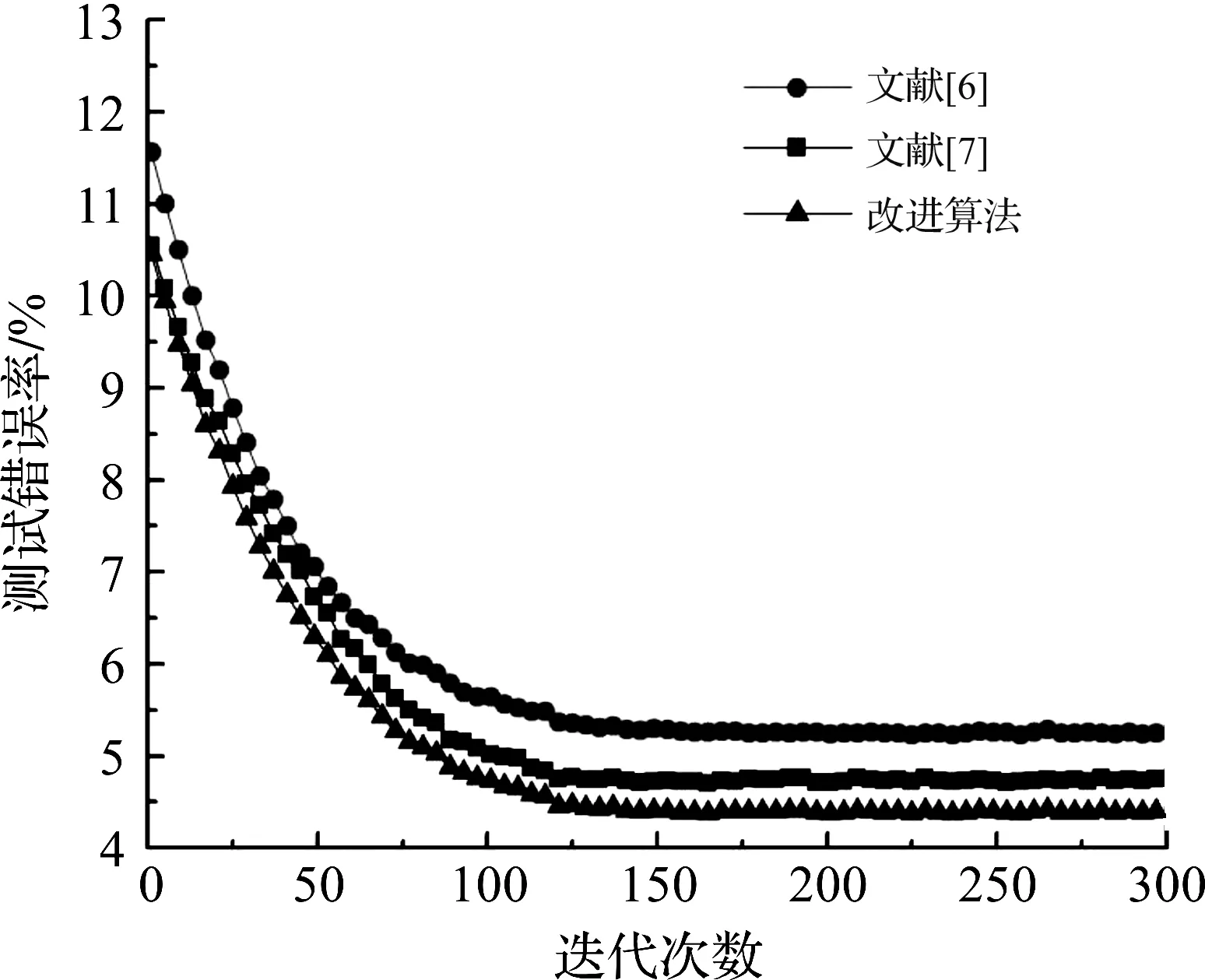
图7 不同算法的识别错误率曲线Figure 7 Recognition error rate curve of different algorithms
3.2 实验分析
文献[6]、文献[7]和改进算法随着迭代次数的增加对宫颈癌细胞图像的识别错误率逐渐降低,表1是改进算法相对文献[6]和文献[7]算法的降低效果.由表1可知改进算法对宫颈细胞图像的识别错误率相对另外两种算法都有不同程度的降低,其中相对文献[6]的算法降低最高可以达到17.04%,相对文献[7]的算法降低最高达到7.23%.
通过以上实验结果可以看出,改进算法相对于文献[6]和文献[7]的算法对宫颈细胞图像的特征提取更加准确,因此,降低了卷积神经网络对宫颈癌细胞图像的识别错误率.

表1 改进算法对识别错误率的降低Table 1 Reduction of recognition error rates by the improved algorithm
4 结语
通过对卷积神经网络的池化阶段使用了不同池化模型进行特征提取,分析了不同池化模型的特征提取方式以及对识别错误率的影响,提出了一种基于卷积神经网络的改进算法.该算法的实质是对特征提取阶段的池化模型进行改进,使得特征提取方式更加合理,并将该算法应用于宫颈癌细胞图像的识别中.实验结果表明,基于卷积神经网络提出的改进算法降低了宫颈癌细胞图像的识别错误率,这种方法也可以应用到其他的图像识别中.
猜你喜欢
中国卫生统计(2023年5期)2023-11-30 01:40:14
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
软件导刊(2022年3期)2022-03-25 04:45:04
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
计算机技术与发展(2019年1期)2019-01-21 00:56:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
教师·中(2017年3期)2017-04-20 21:49:49
试题与研究·教学论坛(2016年27期)2016-08-11 14:57:08
