
基于PCA人脸识别原理
2019-01-18 01:15姚艳松
网络安全技术与应用 2019年1期
◆邵 岚 姚艳松 尚 福
基于PCA人脸识别原理
◆邵 岚 姚艳松 尚 福
(CLO 北京 100054)
文章主要讨论了人脸识别灰度化、生物特征的几种方法和原现,以及如何实现灰度化。同时分析了一种常见却并不妥当的灰度化实现,以及证明了opencv的灰度化是使用“加权灰度化”法,能从整体上反映人脸图像的灰度相关性具有一定的实用价值。
人脸识别;灰度化;人脸特征;识别技术
0 引言
人脸识别人是基于人的面部特征信息进行身份识别的一种生物识别技术。使用摄像头或者摄像机采集含有人脸的图像或视频,自动检测图像信息和跟踪人脸,对检测到的人脸进行脸部的一系列相关分析技术。
人脸检测是指从复杂的背景当中提取我们感兴趣的人脸图像。脸部毛发、化妆品、光照、噪声、人脸倾斜和大小变化及各种遮挡等因素都会导致人脸检测问题变得更为复杂。人脸识别技术主要目的在于在输入的整幅图像上寻找特定人脸区域,从而为后续的人脸识别做准备。
在计算机领域中,灰度(Gray scale)数字图像是每个像素只有一个采样颜色的图像。这类图像通常显示为从最暗黑色到最亮的白色的灰度,尽管理论上这个采样可以表现任何颜色的不同深浅,甚至可以是不同亮度上的不同颜色。灰度图像与黑白图像不同,在计算机图像领域中黑白图像只有黑白两种颜色,灰度图像在黑色与白色之间还有许多级的颜色深度。但是,在数字图像领域之外,“黑白图像”也表示“灰度图像”,例如灰度的照片通常叫做“黑白照片”。
“特征脸”方法中所有人共有一个人脸子空间,而我们的方法则为每一个体人脸建立一个该个体对象所私有的人脸子空间,从而不但能够更好的描述不同个体人脸之间的差异性,而且最大可能地摈弃了对识别不利的类内差异性和噪声,因而比传统的“特征脸算法”具有更好的判别能力。另外,针对每个待识别个体只有单一训练样本的人脸识别问题,我们提出了一种基于单一样本生成多个训练样本的技术,从而使得需要多个训练样本的个体人脸子空间方法可以适用于单训练样本人脸识别问题。人脸库对比实验也表明我们提出的方法比传统的特征脸方法、模板匹配方法对表情、光照、和一定范围内的姿态变化具有更优的识别性能。
1 PCA方法
近期发展起来的用于人脸或者一般性刚体识别以及其它涉及到人脸处理的一种方法。首先把一批人脸图像转换成一个特征向量集,称为“Eigenfaces”,即“特征脸”,它们是最初训练图像集的基本组件。识别的过程是把一副新的图像投影到特征脸子空间,并通过它的投影点在子空间的位置以及投影线的长度来进行判定和识别。
将图像变换到另一个空间后,同一个类别的图像会聚到一起,不同类别的图像会聚力比较远,在原像素空间中不同类别的图像在分布上很难用简单的线或者面切分,变换到另一个空间,就可以很好的把他们分开了。Eigenfaces选择的空间变换方法是PCA(主成分分析),利用PCA得到人脸分布的主要成分,具体实现是对训练集中所有人脸图像的协方差矩阵进行本征值分解,得到对应的本征向量,这些本征向量就是“特征脸”。每个特征向量或者特征脸相当于捕捉或者描述人脸之间的一种变化或者特性。这就意味着每个人脸都可以表示为这些特征脸的线性组合。
原始图像投影到该特征空间中。特别说明,此时的原始图像x存成大小是n维的向量,即:
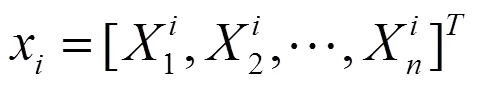
训练集为形成矩阵X[n][p],其中行代表像元,列代表每幅人脸图像[2]。
将训练样本集中的人脸图像减去平均人脸图像,计算离散差值,将训练图像中心化。中心化之后图像组成一个大小为n×p的矩阵。

将中心化后的图像组成的矩阵X乘以它的转置矩阵得到协方差矩阵Ω。
求解协方差矩阵Ω的k个非零特征值,以及所对应的特征向量,一般来说,训练图像数量p远远小于一幅图像的像素值n,所以协方差矩阵Ω最多有对应于非零特征值的p个特征向量,所以k≤p.按照特征值的从大到小的顺序排列特征向量,对应于最大特征值的特征向量反应了训练图像间的最大差异,而对应的特征值越小的特征向量,反应的图像间的差异越小。所有的非零特征值对应的特征向量,组成特征空间,也就是所谓的“特征脸”空间。
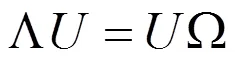
计算特征值和特征向量,其中U为对应于特征值的特征向集。排列特征向量:按照非零特征值,从大到小的顺序,将对应的特征向量排列。所组成的特征向量矩阵即为特征空间U,U的每一列为一个特征向量。
每一幅人脸图像都可以投影到由张成的子空间中。因此每一幅人脸图像对应于子空间中的一个点,同样,子空间中的每个点对应于一幅图像,下图显示的是所对应的图像,由于这些图像很像人脸,所以它们被称为“特征脸”[5]。

图1 特征脸
特征脸训练图像投影得到特征脸子空间 有了这样一个由“特征脸”组成的降维特征子空间,任何一幅中心化后的人脸图像都可以通过下面的式子投影到特征脸子空间并获得一组坐标系数。
2 灰度化
将彩色图像转化成为灰度图像的过程称为图像的灰度化处理。
灰度化,在RGB模型中,如果R=G=B时,则彩色表示一种灰度颜色,其中R=G=B的值叫灰度值,因此,灰度图像每个像素只需一个字节存放灰度值(又称强度值、亮度值),灰度范围为0-255。
彩色图像中的每个像素的颜色有R、G、B三个分量决定,而每个分量有255个值可取,这样一个像素点可以有1600多万(255*255*255)的颜色的变化范围。而灰度图像一个像素点的变化范围为255种,所以在数字图像处理种一般先将各种格式的图像转变成灰度图像以使后续的图像的计算量变得少一些。灰度图像的描述与彩色图像一样仍然反映了整幅图像的整体和局部的色度和亮度等级的分布和特征[3]。
一般有四种方法对彩色图像进行灰度化处理:分量法、最大值法、平均值法、加权平均法。
图像灰度化处理有以下几种方式:
(1)分量法
将彩色图像中的三分量的亮度作为三个灰度图像的灰度值,可根据应用需要选取一种灰度图像。
f1(i,j)=R(i,j)
f2(i,j)=G(i,j)
f3(i,j)=B(i,j)
其中fk(i,j)(k=1,2,3)为转换后的灰度图像在(i,j)处的灰度值。
(2)最大值法
将彩色图像中的三分量亮度的最大值作为灰度图的灰度值。
f(i,j)=max(R(i,j),G(i,j),B(i,j))
(3)平均值法
将彩色图像中的三分量亮度求平均得到一个灰度值。
f(i,j)=(R(i,j)+G(i,j)+B(i,j)) /3
(4)加权平均法
根据重要性及其它指标,将三个分量以不同的权值进行加权平均。由于人眼对绿色的敏感最高,对蓝色敏感最低,因此,按下式对RGB三分量进行加权平均能得到较合理的灰度图像。[3]
f(i,j)=0.30R(i,j)+0.59G(i,j)+0.11B(i,j))
在Opencv中可以通过以上几种方法的数值计算来得到灰度图像也可以通过opencv提供的颜色空间转换函数来得到。Opencv封装灰度法将彩色图转为灰度图[3]。
cv::cvtColor(rgbMat, greyMat, CV_BGR2GRAY);
3 利用PCA进行人脸识别
完整的PCA人脸识别的应用包括几个步骤:人脸图像预处理;读入人脸库,训练形成特征子空间;把训练图像和测试图像投影到上一步骤中得到的子空间上;选择一定的距离函数进行识别。
PCA算法依赖于一个基本假设:一类图像具有某些相似的特征(如人脸),在整个图像空间中呈现出聚类性,因而形成一个子空间,即所谓特征子空间,PCA变换是最佳正交变换,利用变换基的线性组合可以描述、表达和逼近这一类图像,因此可以进行图像识别,PCA包含训练和识别两个阶段。
本文采用matlab作为工具平台, 实现了一个人脸自动识别的系统原型。人脸库中有40个人,各随机取出其10张图像中的7张用作训练集,剩余3张用作后续的测试。将280张train_imgs都拉伸成列向量并将所有列拼在一起,由于每张图像的总像素数都为10304,这样就得到了10304*280的矩阵X,X的每列再减去均值向量,从而中心化,求出X的转置和X的矩阵乘积,并求出乘积40*40矩阵的特征向量[1],是matlab的eig函数。滤出前K大的特征值对应的特征向量W,再将X乘上W映射得到V,将V的每一列向量作为后续映射关系的一组基向量,共有K个基向量,也可以称为K个特征脸。将X每一列都通过基向量矩阵V映射到对应的特征空间中。这样相当于将每张图像train_imgs都在新的空间中找到了对应的位置。对于每个测试图像,也进行类似上述的变换:转成列向量,减去均值向量而中心化,然后用基向量矩阵映射到特征空间中。要判断测试图像和40张train_imgs的哪张最匹配,只需对比测试图像在特征空间的新坐标和40张train_imgs在特征空间的坐标直接的欧几里得距离(或二范数)的大小,找到二范数最小的对应的train_img,就找到了最匹配训练图像了。
这种算法的主要思想就是,去除部分无关的或者关系较小的向量,保留影响较大的向量作基,这样即减少了基向量的数目从而减少了运算量,同时又减少了图像细节,能避免无关的向量和测试图像主人公的表情、脸朝向和配饰等变化对测试准确性产生不良干扰。
Matlab代码实现函数Training用来随机读取40*7张图像并分别作平均产生训练集
function [ imgs ] = Get_Training_Set( input_path, index, height, width, output_path )
imgs = zeros(length(index), height, width);
for i = 1 : length(index)
imgs(i, :, :) = uint8(imread([input_path '/' num2str(index(i)) '.pgm']));
end
end
函数Test_Case用来测试单张图像,循环调用即可测试所有的测试集图像
function [ found ] = Test_Case( V, eigenfaces, indexes, i, j, mean_img )
f = imread(['Faces/S' num2str(i) '/' num2str(indexes(i, j)) '.pgm']);
[height, width] = size(f);
f = double(reshape(f, [height * width, 1])) - mean_img;
f = V' * f;
[~, N] = size(eigenfaces);
distance = Inf;
found = 0;
for k = 1 : N
d = norm(double(f) - eigenfaces(:, k), 2);
if distance > d
found = k;
distance = d;
end
end
end
测试性能表格,Test_Case函数返回1-280之间的整数,表示这一列最能匹配当前测试图片。但还需要转成1-40之间的整
数才能表示出匹配到了的是哪一个人。
found = Test_Case(V, eigenfaces, indexes, i, j, mean_img);
found = floor((found - 1) / 7) + 1;
修改代码为初始不求40张平均脸,而用280张人脸直接训练后再对每个K值测试10次,得到的测试折线图如下,可以看到,测试准确度随着K从50到100取值,大约在93%到95%间波动,并且大约在K取83的附近得到较稳定的最大值[4]。
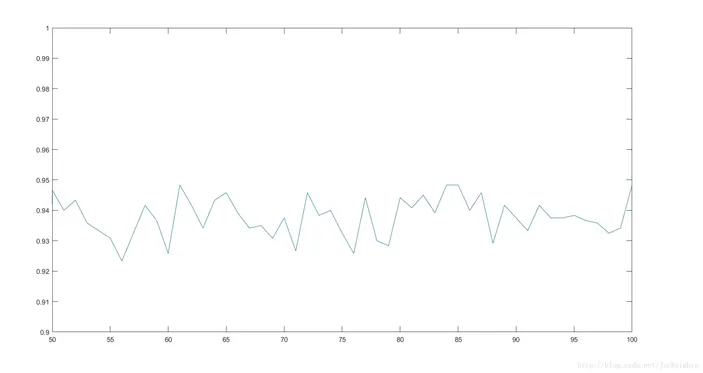
图2 测试折线图
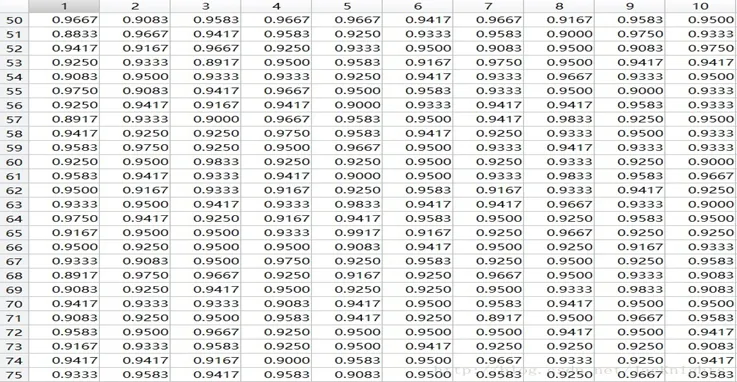
图3 测试结果表
4 结论与展望
人脸识别是目前较活跃的研究领域, 本文详细给出了基于主成分分析的人脸特征提取的原理与方法。并使用matlab 作为工具平台, 实现了一个人脸自动识别的系统原型。实验结果表明, 该系统识别率为85%, 达到预期的效果。如果想进一步提高人脸识别率, 可以考虑与其他方法结合。
人脸识别的技术得到突破,准确率得到提升并普及用户习惯后,其商业化应用前景是十分广阔的,且有助于线下生物识别格局的改变,很有可能会成为下一个科技时代的商业爆发点。随着人脸识别技术的革新,人脸识别效果的提升将打开前期受效果制约的应用场景。
总之,以人脸识别为代表的新一代技术驱动的产业革命已经兴起,学习研究人脸识别的组识会越来越多。但在实际应用中仍然面临困难,不仅要达到准确、快速的检测并分割出人脸部分,而且要有效的变化补偿、特征描述、准确的分类效果及如何与其它技术相结合,提高识别率和识别速度、减少计算量。
[1] 杨琼,丁晓青.鉴别局部特征分析及其在人脸识别中的应用[J].清华大学学报:自然科学版,2004.
[2]罗韵.用Matlab进行PCA人脸识别[N/OL].http://blog. 163.com/luoyun_dreamer/blog/static/215529070201331281538309/?suggestedreading.
[3]文尹习习.图像处理:灰度化,二值化,反色[EB/OL]. https: //blog.csdn.net/liu1152239/article/details/73088182
[4]JacKnights.基于PCA的人脸识别[EB/OL].https: //blog. csdn.net/JacKnights/article/details/79439180?utm_source=blogxgwz6.
[5]xiaoshengforever.PCA的具体实现(Eigenfaces特征脸) [EB/OL].https://blog.csdn.net/xiaoshengforever/article/details/13041753.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
北京航空航天大学学报(2022年6期)2022-07-02
保定学院学报(2022年2期)2022-04-07
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
奥秘(2021年5期)2021-06-15
集装箱化(2021年1期)2021-04-12
天津医科大学学报(2021年1期)2021-01-26
中国信息技术教育(2020年2期)2020-02-02
数学学习与研究(2018年15期)2018-11-12
