
基于特征选择加权支持向量机的运动模式识别
2019-01-12 02:19
传感器世界 2018年9期
北京信息科技大学高动态导航技术北京市重点实验室,北京 100101
一、引言
人体运动模式识别是指对人体多种运动状态的感知过程,主要通过对传感器数据的分析,实现运动模式的识别[1]。在行人导航航位推算系统中,准确的运动模式认知,有助于准确获得行为轨迹,可应用于老弱病残等群体日常看护、行人导航、消防救援等领域[2]。
FederiaInderst等人[3]通过腰部穿戴IMU单元测量惯性数据,提取标准差、幅值范围和最值作为分类特征,采用两级分类方式,实现分类正确率为87.56%。Thomas Moder等人[4]提取行人运动的最大值、均值、标准差、均方差、四分位差和频率为分类特征,采用决策树进行运动分类与识别,识别率为89%。NatthaponPannurat等人[5]提取多种时域数据作为分类特征,对八种分类算法进行评估,SVM分类方法对运动模式识别率为91%。
但以往方法,均存在选取的特征向量信息重叠的情况,没有解决特征冗余的问题。基于这些研究,本文基于Relief-F算法对IMU提取的特征向量进行权重估计,根据Relief-F算法构造一个特征元素权重向量,增大不同类特征向量的差异性,作为输入进行支持向量机分类计算,识别站立、走、跑、跳、跌倒、上楼、下楼7种运动状态,提高了人体运动模式识别分类的精度和效率。

二、系统介绍
1、数据采集和处理
本文采用法国SBG Systems公司的MEMS惯性测量单元Ellipse-N进行测试,模块安装在测试人员腰部,如图1所示,依照右手笛卡尔坐标系,传感器的x轴与地面垂直,y轴与地面平行,z轴指向人体运动前进方向。

对传感器原始数据预处理以提取运动传感器的时域特征,采用3阶巴特沃斯低通滤波,截止频率fc=5Hz,如图2所示。可以看出,数据经过预处理后,消除了噪声,保留了加速度信号的特征,信号更加平滑,系统的分类准确度明显提高。
2、特征提取
特征提取对于多运动模式识别的精度有很大的影响。惯性测量单元Ellipse-N采集三轴加速度信号和三轴角速度信号,其中每轴数据都可以提取出不同的特征量。因为时域特征的提取计算复杂度低、耗时短[6],所以本文选取适用于实时性要求较高的系统的多种时域特征。用n来表示一个时间窗口的大小,即窗口内数据的行数,用i来表示第i行数据。
取三轴合加速度A为特征提取与分类的初始数据,ax、ay、az分别为加速度计的三轴数据。在确保精度的同时,要减少计算复杂性。合加速度公式为:

特征向量β由多个时域特征元素βi(i∈{1, 2, 3, 4,5, 6})构成,特征向量公式为:

式中,β1—方差;
β2—四分位间距;
β3—峰值;
β4—加速度均值;
β5—过均值点个数;
β6—幅值。
(1)方差
设x1,x2,…,xn是角速度传感器数据x的一个样本,特征元素方差β1公式如下式所示:
图3为多种模式下方差的分布。图中定义每50个数据点划分为一个窗口,模拟实时情况下的数据处理。
(2)四分位间距
取特征元素β2为四分位间距,把加速度计x轴的数据ax从小到大排列为ax1,ax2,...axn,并均分为四份,处于三个分割点位置的数值即为四分位数(Quartile)。第三个四分位数和第一个四分位数的差值即为四分位间距(InterQuartile Range,IQR),计算公式为:

式中:IQR—四分位间距;
Q1—第一个四分位数;
Q3—第三个四分位数。
四分位间距的分布情况如图4所示。


(3)均值
特征元素加速度均值β3,分布情况如图5所示,计算公式如下:

(4)最大值
特征元素加速度最大值β4,可反应加速度信号在一个周期内的变化强度,峰值绝对值越大,说明运动幅度越大,可用来区分运动和静止的状态模式。最大值的分布情况如图6所示,计算公式如下。

其中,A—特征元素幅值。
(5)过均值点个数
特征元素过均值点个数β4,计算公式为:



(6)幅值
特征元素幅值β6,定义为最大值和最小值之差,计算公式为:

三、算法描述[10]
1、Relief-F算法
Relief-F(Relevant Features)是Relief算法的扩展,由Kononenko[7]于1994年在Kira工作的基础上提出的一种处理多类别特征选择算法。这是一种过滤式特征选择方法,也叫特征权重算法,根据各个特征和类别的相关性赋予不同的权重,权重值小于某个阈值的特征将被剔除,仅能处理两类别数据。
设D={X1,X2,...,Xm}(i=1, 2…m)是待进行分类的对象全体,Xi为其中任意一个样本,xi=[xi1,xi2,…,xin]T(p=1, 2…n)表示Xi的n个特征值,λi=[ai1,ai2,…,ain]T(p=1, 2…n)表示Xi各维特征值的权值。从D中随机选择样本Xi以后,从和Xi同类的样本中寻找k个最近邻样本H={H1,H2,...,Hk}(j=1, 2…k) (特征值hj=[hj1,hj2,…,hn]Tp=1,2…n),称为Near Hit,从和Xi不同类的样本中寻找k个最近邻样本M={M1,M2,...,Mk}(j=1,2…k) (特征值mj=[mj1,mj2,…,mn]Tp=1,2…n),称为Near Misses。
设diff_hiti是n×1的矩阵,表示Xi和H在每个特征上的差异:

其中,max(xi) 、min(xi)—特征值中最大值和最小值。
设diff_missi是n×1的矩阵,表示Xi和M在每个特征上的差异:

其中,P(L)—待分类类别的概率,是第L类的样本数与数据集中样本的总数之比。
此过程重复m次进行迭代,权重值由下式更新:

由此,得到特征集中每一个特征的权重值向量λm。
2、SVM分类方法
支持向量机(Support Vector Machine,SVM)通过构造一个分类函数或分类器,把数据库中的数据项非线性映射到一个高维特征空间中,从而进行线性分类,然后在新特征空间中构造最优分类面,形成样本分类,可用于预测未知数据[8]。SVM算法简单,鲁棒性好,在过拟合、运算速度和分类精度等方面都比传统的分类算法具有明显的优势。
考虑线性可分的分类问题,设训练样本集合为:
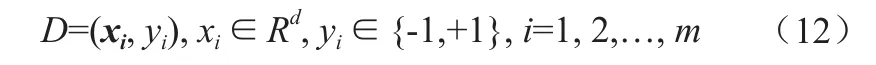
其中,每一个xi对应一个数据向量;yi是xi对应的类标签;d为空间维数。
设d维空间中线性判别函数的一般形式为:

其中,w—法向量;
b—偏移量,超平面与原点的距离;
(w*,b*) —最优解。
根据SVM的基本思想,如果超平面分类线性函数f(x)=sign(w*x+b*)可以将训练样本准确的区别开,并且使分类间隔最大即离超平面最近的距离其实是最远的,则这个超平面是最优超平面[9],其解(w*,b*)为最优解。
对于线性不可分的线性支持向量机的学习问题,变成如下凸二次规划问题:

其中,ξi—松弛变量;
C—惩罚参数,C〉0。
设问题(14)的解为(w*,b*),于是可以得到最优分离超平面w*x+b*=0及分类决策函数f(x)=sign(w*x+b*)。
对于非线性可分的运动模式分类问题要引入核函数,将训练样本映射到高维空间,问题可转变为线性可分。核函数的加入将分类模型转变为下列公式:

其中,K(xi,x)—核函数。
则式(14)中的优化问题变成如下形式:
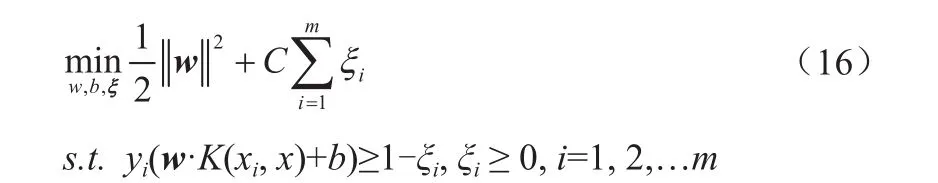
3、基于Relief-F的SVM运动模式分类算法
对于非线性可分的运动模式分类问题要引入核函数,把特征权向量和核函数二者结合起来,可以得到特征加权核函数,然后再应用到非线性SVM中,为得到较佳的实验效果,选择高斯核函数作为高斯径向基函数分类器的核函数。
(1)收集原始样本数据集D:

(2)根据Relief- F算法分别计算每个特征向量的权值(m=30,迭代30次),得出下式[7]:

剔除特征属性权重值最小的β5,从上述权重值可以看出,方差、均值、四分位间距等都是分类主要的影响因素,增大其权重值(按照踢出的权重值取平均,加在各个权值里),由此构造新的特征权重向量:

(3)选取高斯核函数K(x,xc):
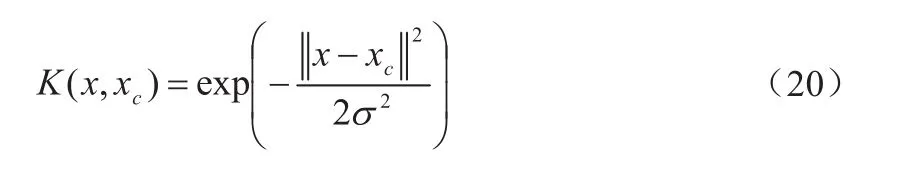
其中,xc—核函数中心;
σ—核函数的宽度参数,控制函数的径向作用范围。
选取适当的参数C,构造并求解最优化问题:

其中,α—拉格朗日乘子。
(4)选择α*的一个正分量计算:
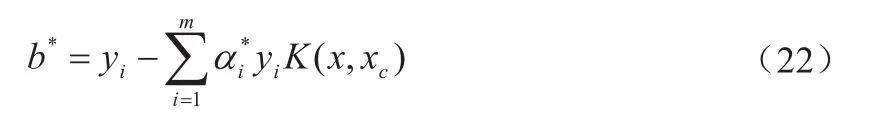
由此构造决策函数:
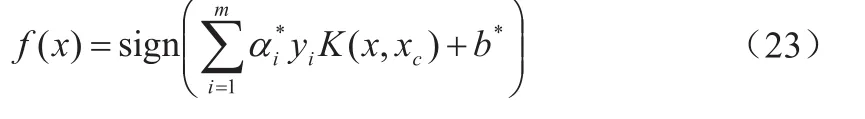
四、实验结果与分析
为了验证本文所提出方法的有效性,设计了测试实验。实验人数30(男性20名,女性10名),按要求完成站立、走、跑、跳、跌倒、上楼、下楼7种运动模式。在实验过程对测试人员的行为不作任何约束,跌倒实验在4m×1m×0.2m的海绵垫子上完成。
本文进行两组对比实验,分别采用多时域特征向量和基于Relief-F特征加权的多时域特征向量作为SVM运动模式识别的数据。数据分别在系统平台上实验验证,以分类准确度(一种运动模式被分类器判定为其所属类别的几率)作为评判标准。实验结果如表1~表4所示。
表1、表2为第一组实验数据,实验采用多时域特征向量作为SVM运动模式识别的数据。其中表1为7种运动模式的分类准确度。可以看出,由于与其它几种动作的区分度较大,站立的准确度达到100%;而坐、跳和跌倒、上楼和下楼区分度较小,准确度较低。表2列出了7种运动模式的混淆情况,跳、跌倒之间易错误识别,上楼、下楼易误识别为走。
表3和表4列出了第二组实验的结果,实验采用基于Relief-F特征加权的多时域特征向量作为SVM运动模式识别的数据。对于较难区分的上楼和下楼,识别精度提高了5%,跌倒的识别精度提高了7%。
由此可以看出,采用本文提出的方法在训练时间上好于传统的SVM分类器。采用相同服务器进行测试,传统SVM训练平均时间为3s,而本文平均为1.5s,仅为传统方法耗时的1/2,显示出其时间上的优势。

表1 第一组实验7种运动模式的分类准确度
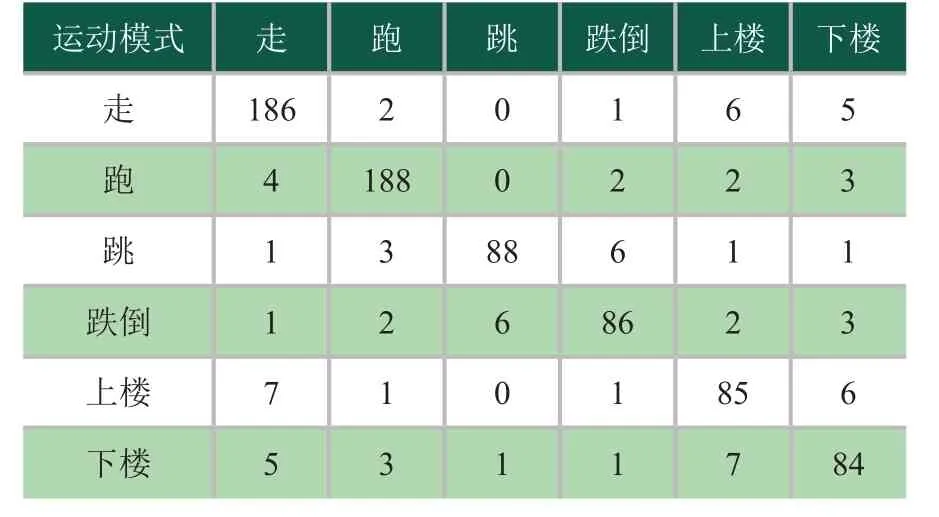
表2 第一组实验 7种运动模式的混淆矩阵

表3 第二组实验7种运动模式的分类准确度

表4 第二组实验中7种运动模式的混淆矩阵
五、结束语
基于对Relief-F特征加权SVM的人体运动模式识别算法的详细阐述,对多种运动状态样本集进行了分类。实验结果表明,这种方法在分类准确率上优于传统的SVM分类器,具有计算准确度高、高效、简单的特点。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
测控技术(2018年11期)2018-12-07
许昌学院学报(2018年4期)2018-05-02
中国港湾建设(2017年11期)2017-12-19
中成药(2017年10期)2017-11-16
中华建设(2017年1期)2017-06-07
智能系统学报(2017年5期)2017-01-22
系统工程与电子技术(2016年7期)2016-08-21
西北工业大学学报(2015年4期)2016-01-19
