
智能驾驶-AI芯片的算力研究
2019-01-10 07:05于继成王强赵目龙焦育成
汽车文摘 2019年1期
于继成 王强 赵目龙 焦育成
(中国第一汽车集团有限公司智能网联研发院,长春 130011)
主题词:智能驾驶 算力单位 算力计算方法 算力对比分析
1 前言
在对驾驶汽车更便捷、更安全、更舒适的追求下,人类已经拉开了无人驾驶的幕布。纵观世界,奥迪A8搭载了L3级自动驾驶控制器,可在时速为60 km/h内的城市道路自动驾驶,是世界上首辆量产的L3级别自动驾驶车辆,这也开启了传统汽车厂商在智能汽车方面的开端,使得豪华车向智能豪华车转变。
智能驾驶汽车现已可配置激光雷达、毫米波雷达、超声波雷达、前视摄像头、环视摄像头、夜视红外摄像头等大量的传感器用以采集道路数据、感知驾驶环境,但是只有传感还不够,还要有一个足够强大的大脑对数据进行分析,并做出正确的规划和决策。这大脑部分就是由多个车规级的智能驾驶AI芯片搭建而成,包括GPU、FPGA、MCU及ASIC芯片等[1]。
2007年,一汽集团与国防科技大学合作,在红旗HQ3车型基础上完成高速公路自动驾驶样车,开启了中国一汽对自动驾驶探索之路。2011年7月,红旗HQ3无人车完成了从长沙到武汉286 km的高速全程无人驾驶实验,历时3小时22分钟,展示了一汽集团在自动驾驶上的探索成果;2015年4月,一汽集团正式发布了其“挚途”技术战略,标志着一汽集团的互联智能汽车技术战略规划正式形成。2015年4月19日,一汽在同济大学举行了“挚途”技术实车体验会,包含有“手机叫车、自主泊车、拥堵跟车、自主驾驶”等4项智能化技术[2]。2018年一汽集团徐留平董事长在北京鸟巢发布了红旗品牌战略,新红旗将突出“新高尚”、“新精致”、“新情怀”的理念,打造卓越产品和服务,发布了一汽红旗品牌自动驾驶发展规划。
中国第一汽车集团有限公司放眼世界造车趋势,集全集团之力誓将自主红旗品牌打造为中国第一、世界著名的汽车品牌。中国一汽将智能化、网联化作为新红旗汽车的核心魅点,匹配当前用户追求极致体验的需求。在2018年上市的红旗H5身上,消费者已经切身体验到行业领先的新红旗卓越智能驾驶系统。随后,中国一汽将不断推出更加智能化、高度自动化、完全自动化驾驶的新红旗产品。其中,2019年推出实现L3(SAE)级自动驾驶的量产车型,2020年推出实现L4(SAE)级自动驾驶的量产车型,2025年将实现L5(SAE)级自动驾驶量产车型,部分内容摘自一汽徐留平董事长红旗品牌战略发布会讲话。
作为从事硬件设计的工程师,为了提升对自动驾驶硬件方案的设计水平,缓解对供应商硬件方案的评估压力,建立对自动驾驶硬件方案的技术管控能力,需要对各个芯片厂家的AI芯片的功能和计算处理能力清楚掌握。
本文将从AI芯片最基础的算力资源及算力大小、计算的角度,揭开自动驾驶AI芯片的面纱。
2 自动驾驶AI芯片算力
2.1 算力研究的意义
自动驾驶域控制器的开发,OEM通常有两种方式,自主开发或者向供应商采购。如果自主开发,AI芯片厂家包括Xilinx、NXP、Renesas、Intel、NVIDIA、TI等所生产的不同AI芯片、不同硬件资源架构、不同计算能力,该如何取舍?如果向供应商采购,供应商如恒润、伟世通、地平线、东软、TTTech等所提供的硬件方案是否能够满足应用需求、实现应有的功能、规避项目失败的风险?这些问题使得我们不得不从硬件设计之初,芯片方案选型阶段就要充分论证AI芯片的算力资源。
以往,关于自动驾驶芯片算力的信息来自于AI芯片厂家提供及Tire1方案中的AI芯片对比数据,这种模式导致以下几点问题:
1)不能有效审核Tire1算力评估的准确性;2)无法对应AI芯片本身算力支持的硬件资源;3)不能根据需求进行算力匹配与AI芯片选型。所以,了解各厂家AI芯片的内部算力资源、了解算力的计算方法、统一算力单位成为自动驾驶硬件设计的重要工作内容。
2.2 算力基础概念
2.2.1 算力单位
OPS(Operations Per Second):每秒完成操作的数量,乘操作算一个OP,加操作算一个OP;
MACS:表示每秒可执行的定点乘累加操作次数,可借用于衡量自动驾驶计算平台定点数据运算处理能力,这个量之前用在那些大量定点乘法累加运算的科学运算中,记为MACS。1G MACS等同每秒10亿(=109)次的定点乘累加运算;
FLOPS(Floating-Point Operations Per Second):每秒可执行的浮点运算次数的字母缩写,它用于衡量计算机浮点运算处理能力。这个量经常用于需要大量浮点运算的科学运算中。在自动驾驶领域,由于NVIDIA SOC支持浮点运算,且是目前最强处理IC之一。浮点运算,实际上包括了所有涉及小数的运算。浮点运算比整数运算更复杂、更精确、更耗费时间。
DMIPIS(Dhrystone Million Instructions executed Per Second):Dhrystone:是测量处理器运算能力的最常见基准程序之一,常用于处理器的整型运算性能的测量。MIPS:每秒执行百万条指令,用来计算同一秒内系统的处理能力,即每秒执行了多少百万条指令。
2.2.2 基于INT8的深度学习架构
随着更精确的深度学习模型被开发出来,它们的复杂性也带来了高计算强度和高内存带宽方面的难题。能效正在推动着深度学习推断新模式开发方面的创新,这些模式需要的计算强度和内存带宽较低,但绝不能以牺牲准确性和吞吐量为代价。降低这一开销将最终提升能效,降低所需的总功耗。
INT8除了降低神经网络计算中数据传输带来的功耗,较低位宽的计算方式同时可以降低内存带宽带来的功耗费用,可理解为在相同内存事务的情况下传输的位数减少了,进而降低了总功耗[3]。
研究显示要保持同样的准确性,深度学习推断中无需浮点计算,而且图像分类等许多应用只需要INT8或更低定点计算精度来保持可接受的推断准确性。表1列出了精调网络以及卷积层和完全相连层的动态定点参数及输出。括号内的数字代表未精调的准确性。

表1 带定点精度的CNN模型精度对比分析[4]
通过上表可以看出,在自动驾驶图像处理应用中,在不同的参数神经网络下,INT8与32位浮点的定点精度高度相近,所以在降低功耗,减少数据传输带宽的优势下,INT8成为目前被广为看好的精度格式。
3 算力计算公式
3.1 单位换算
3.1.1 MACS与OPS单位转换
深度学习和神经网络使用相对数量较少的计算原语(Computational Primitives),而这些数量很少的计算原语却占用了大部分计算时间。矩阵乘法和转置是基本操作。矩阵乘法由乘法累加(MAC)操作组成。Ops/s(每秒完成的操作数量)指的是通过每秒可以完成多少个MAC(每次乘法和累加各被认为是1个operation,因此MAC实际上是2个OP)得到[5]。所以,可以得到MACS与OPS之间的换算关系如下:1MACS=2∙OPS。
3.1.2 ARM核算力DMIPS查询方法及算力计算
智能驾驶AI芯片内部均集成有多个内核,而目前各个AI芯片厂商尤其以集成ARM内核居多。ARM核多用于多图像处理(转化及提取)、目标识别和融合、具有功能安全定义的决策制定等功能。
这里先介绍一下ARM核的算力查询方法,ARM公司将其ARM核的算力信息更新在在维基百科上,可通过以下网址查询[6],如表2所示。

表2 ARM核工作主频及算力数据表[6]
例如某片SOC内部集成4个A53核,工作主频为1.2 GHZ,则该SOC内部ARM核部分的计算处理能力为4×(2.3 DMIPS/MHz)×1.2 GHz=11.04 K DMIPS。
当然有些AI公司会自己开发内核,如Infineon的Tricore MCU TC297内部集成的是其自己的内核,类似于这些非集成ARM内核的AI芯片的算力,在选型时需要与厂家进行仔细确认。
3.2 恩智浦S32V算力资源分析
3.2.1 芯片S32V234算力分析
恩智浦(NXP)下一代S32家族计算平台是一个完全可扩展的计算平台,基于公用架构,可以根据不同的应用,像雷达应用、网关应用、视觉的应用添加特有的功能IP,派生出针对功能安全和动力总成应用的S32S/P、雷达应用的S32R、下一代网关应用的S32G、视觉应用的S32V、自动驾驶应用的S32A和通用的S32K[7]。S32V234有2个专用的图形处理加速器APEX[8],如下图1所示。APEX由2个APEX-642 ICP核组成,每个ICP核由2组APU组成,每个APU包含32个CU(矢量计算单元-Computational Units)和1个ACP(标量计算及调度)。所以每个APEX有128个CU,4个ACP。其总计算能力为80 GMACs,即在400 MHz时钟内,每个时钟周期可以完成200次MAC运算,这得益于CU的SIMD处理特性。

图1 S32V234 Block Diagram[8]
3.2.2 下一代产品S32V3xx计算能力资源简介[8]
恩智浦下一代高算力产品S32V3xx的算力资源采用三个全新架构设计的APEX-D硬核图像处理加速器,总算力将比S32V2xx有大幅度提高。
S32V3xx性能的提高主要来源于以下因素:
(1)S32V3xx采用了全新设计的APEX-D加速处理器,架构上作了优化提升;
(2)时钟频率提升超过1倍;
(3)每个CU的处理能力大幅提升,每个时钟周期可以完成更多的MAC运算;
(4)整体功耗将控制在更低水平。
具体算力信息待NXP官方宣称,但可以肯定的是,这款芯片未来的应用场景非常可观,将会为自动驾驶技术的发展注入强劲力量。
3.3 瑞萨R-CAR算力资源分析
R-Car H3基于ARM® Cortex®-A57/A53核构建,采用ARM的最新64位CPU核架构,实现了40 000 DMIPS(Dhrystone百万指令/每秒)的处理性能。
IMP是瑞萨(Renesas)的AI芯片中的一个图像处理加速核,把许多图像处理相关的算子进行了硬件化。支持的一些预处理操作包括density-conversion、bit-inversion、normalization等,后处理包括Absolutevalue processing、normalization、density conversion等,像素转换、数学运算、逻辑运算、Convolution、Labeling、Histogram processing和Sobel-filter等。
R-CAR芯片核心是MAC计算,主要基于5X5卷积运算,每个5X5卷积运算是25 MACs/cc,5X5卷积运算在一个Clock cycle可以处理2个Pixel,每个Pixel是指一个8 bit的像素数据。
以R-CAR H3为例,H3有4个5X5卷积运算单元,工作频率533 MHz,算力也就是25 MACs/cc X 2 pixels/cc X 533 MHz X 4 IMP Cores=106 G MACS。
R-CAR H3[9]系统框图如图2所示:

图2 R-CAR H3系统框图[9]
3.4 德州仪器TDA2S算力分析
德州仪器(TI)的AI芯片内部包括ARM核、DSP和专为视觉处理设计的完全可编程的视觉加速器。
TDA2x SoC内部包含2个TI知识产权定浮点DSP内核C66x和4个专为视觉处理设计的视觉加速器EVE,完全可编程,工作主频可达到650 MHz。
TDA2S的DSP内核是TI自己开发的产品[10],可在其官网上对DSP算力进行查询,网址为:http://www.ti.com/processors/dsp/c6000-dsp/c66x/overview.html,查询结果如表3所示。
TI的EVE@650MHz视觉图像处理硬件加速器的算力为11.5 G OPS,DSP C66@750MHz的算力为4.6 G OPS,以TDA2s为例,其算力大小为2×DSP+4×EVE=55.2 G OPS=27.6 G MACS。
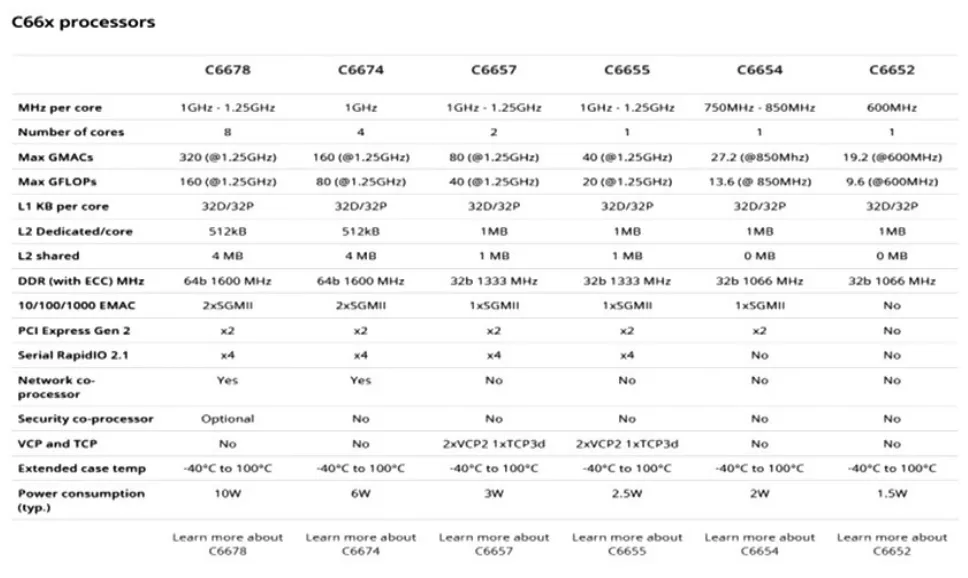
表3 TI官网DSP算力表[10]
3.5 赛灵思Ultra Scale ZU系列SOC算力分析
3.5.1 赛灵思(Xilinx)的FPGA在自动驾驶应用中的优势
作为GPU在算法加速上的强有力竞争者,FPGA在自动驾驶方案中越来越被看好,首先由于FPGA自身低能耗的特点,十分适合于传感器数据的(预)处理工作;同时FPGA具有硬件可升级、可迭代的优势,能够满足感知算法的不断更新;另外FPGA具有高性能及可编程特性,十分适合感知计算;最后,FPGA相比GPU价格便宜,相比于CPU与GPU有明显的性能与能耗优势。
3.5.2 FPGA算力计算分析
FPGA内部包括ARM内核、DSP Slices等算力资源。其中DSP Slices资源可以在Xilinx官网的选型指导手册查到[11],如下表4所示。

表4 赛灵思车规级FPGA硬件资源表[11]
DSP Slice的算例计算公式为:可以按这个公式来算GOPS:DSP数量×最高时钟×1.75×2,其中需要说明的是1个DSP平均可以做1.75次INT8运算、1个DSP是算2个运算。
以Xilinx的ZU5EV为例,其DSP Slice数量为1 248个,最高时钟为645 MHz,根据以上计算公式可得ZU5EV的算力大小为:DSP数量×最高时钟×2×1.75=1.248 K×645 MHz×2×1.75×G/1000=2817.36 G OPS=1408.68 G MACS=1.4 T MACS。
3.6 英伟达Tegra Parker SOC算例分析
3.6.1 基于GPU的计算解决方案
GPU在浮点运算、并行计算等部分的计算方面,能够提供数十倍甚至上百倍的CPU性能。利用GPU运行机器学习模型,在云端进行分类和检测,相对比CPU耗费的时间将大幅度缩短。凭借强大的计算能力,在机器学习快速发展的推进下,GPU目前在深度学习芯片市场非常受欢迎。
凭借具备识别、标记功能的图像处理器,英伟达(NVIDIA)在人工智能领域抢占先机。NVIDIA的PX2平台是目前领先的基于GPU的无人驾驶解决方案,分别为Tesla、百度和算法公司等提供全套的硬件解决方案。在Drive PX2中,Auto Chauffeur是一个定义面向L3的版本,其运算部分的配置是双Parker SoC(提供256个CUDA运算资源),外加双MXM3.1接口的Pascal架构独立运算图形处理单元GP106(GPU,提供1 280个CUDA运算单元)组成,片图形处理单元都有自己的专属内存以及专用的指令以完成深度神经网络的硬件加速。借助优化的I/O架构与深度神经网络的硬件加速,单台PX2 Auto Chauffeur能够执行每秒24兆次深度学习计算。
3.6.2 GPU的算力计算
GPU的浮点计算理论峰值能力测试跟CPU的计算方式基本一样:
理论峰值=GPU芯片数量×GPU Boost主频×核心数量×单个时钟周期内能处理的浮点计算次数,
只不过在GPU里单精度和双精度的浮点计算能力需要分开计算[12]。
双精度理论峰值=FP64 Cores×GPU Boost Clock×2=xxx T flops
单精度理论峰值=FP32 cores×GPU Boost Clock×2=xxx T flops
以Tegra Parker SOC为例,其内部有256个CUDA Cores,工作主频是1 275 MHz:其双精度理论算力峰值为FP64 Cores×GPU Boost Clock×2 = 0.65 T flops。
4 算力概括
通过以上对各个芯片厂家的AI芯片的算力分析,得到的是理论峰值,在方案阶段的对比选型数据,可以作为重要的参考要素,但是不能忽略有效算力这个概念,在硬件设计中如何协同合作发挥出AI芯片的有效算力是各位自动驾驶工程师需要共同面对和解决的重要问题。
本文最后根据上面所罗列的计算方法对各厂家AI芯片的算力进行总结比较,在这里需要声明的是各厂家对自动驾驶AI芯片的布局均有各自的策略和侧重点,对AI芯片的算力计算用以方案算力初始冗余量评估,本文的对比数据并无对不同AI芯片的优劣好坏的评比,而是在此建议设计师们根据需求、根据应用进行选型,选择最合适的而不是最贵的、性能最强大的。统计数据如表5所示。

表5 各芯片厂家部分AI芯片算力统计表
5 结束语
为促进一汽红旗智能驾驶汽车的发展,本文从最基础的AI芯片进行了论述,对AI芯片的计算处理能力进行了阐释说明。希望能够对未来的产品开发和芯片选型等提供参考依据。
高计算能力的AI芯片往往带来更多的功耗需求,汽车用AI芯片将在高计算能力和低功耗的平衡中不断发展突破,为实现L5级的完全自动驾驶需求,除算法上面的不断改进外,对AI芯片算力的需求也将朝着百TOPS级别发展。目前,在电动车及混动车型上更容易满足自动驾驶大功耗的计算平台需求,在提供大功率供电的同时,也可借助电池冷却液解决高功耗带来的散热难题。
致谢
感谢王强、赵目龙、焦育成等人对本文的形成给与的巨大支持与细致的校对,对本文的形成起了重要作用。他们是一汽从事智能驾驶硬件设计人员的先行者与开拓者,在面对并解决重重困难中,为一汽的自动驾驶事业保驾护航。
猜你喜欢
现代经济信息(2022年22期)2022-11-13
计算机应用(2022年6期)2022-07-05
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26
科学大观园(2022年6期)2022-04-21
汽车观察(2021年4期)2021-05-10
汽车观察(2021年4期)2021-05-10
汽车观察(2021年11期)2021-04-24
软件和集成电路(2019年9期)2019-11-29
学苑创造·B版(2019年4期)2019-05-09
中学生数理化·八年级数学人教版(2017年2期)2017-03-25
