
在线社交应用中隐私驱动的访问控制研究
2019-01-07 05:21张梦娇曹彦尹小花陶灵灵
计算技术与自动化 2018年4期
张梦娇,曹彦,尹小花,陶灵灵
(南京航空航天大学 计算机科学与技术学院,江苏南京 211100)
伴随着互联网的兴起,社交应用对人们的交流方式产生了巨大的影响。而随着智能手机、平板电脑等移动终端的普及,社交应用也变得更加灵活多样,在线社交应用迅速发展起来[1]。用户信息的可靠性是社交应用的基础,发布消息跟其他用户进行分享是社交应用的前提,但由此带来的隐私泄露问题也给社交应用的发展带来了很大的挑战。当用户在在线社交应用中发布了一条消息,消息中涉及到自身的一些隐私,而用户在发布完消息之后并不知道自己的信息将会被什么人看到,被谁以何种方式使用,这就很容易造成隐私泄露。人们利用移动在线社交应用(微信、QQ、微博等)这些平台互相交流,建立和维护自己的社交圈。而且用户还可以在自己发布的消息下面进行定位,这样自己的好友就会知道自己所在的位置[2]。但是,用户发布的消息经常会涉及到个人的隐私,而目前的在线社交应用基本上都是只有简单的粗粒度的访问控制,这就对用户隐私信息的泄露造成了极大的威胁。如果被第三方用来谋取利益甚至被不法人员拿来诈骗或者做其它危害社会安全的事情都将带来很大的困扰[3]。
由于分享的信息存在潜在的私密性,所以需要对用户的隐私进行保护[4]。为了保护用户的隐私信息,访问控制策略帮助控制对用户信息的访问,它描述了一些规则,即,谁可以访问用户的信息,在什么条件下可以访问用户的信息[5]。工业界提出的访问控制策略语言,例如,可扩展访问控制标记语言(XACML)和企业隐私授权语言(EPAL),这些语言把义务处理成抽象的符号而不是具体的元素,因此它们并不能直接将隐私法律法规转换成访问控制策略[6]。传统的基于身份的访问控制模型不支持隐私需求而且是不灵活的[7]。基于角色的访问控制(RBAC)的中心思想就是用户不可以直接访问目标信息,而是被分成不同的角色,对应不同的访问权限水平,访问权限水平越高,权限越大,可访问到的信息就越详细[8]。提出对不同的用户进行分类,根据分类不同在访问其他用户发布的消息时会得到不同的结果也是受基于角色的访问控制的启发。
基于上述问题,提出了一个隐私驱动的细粒度的访问控制机制。首先,根据不同类型信息的粒度与访问该信息的用户的类型(陌生人、朋友、家人)对用户的隐私需求进行定义。当用户在社交应用上发布消息以后,社交应用自动的对用户发布的内容进行分析,找出可能泄露用户隐私的敏感词进行标注。然后根据访问该内容的用户的类型对可能泄露用户隐私的敏感词进行不同程度的模糊化,最终不同类型的用户看到的是跟原来用户发布的内容语义一致的不同消息。
本文第1节介绍国内外的相关工作;第2节提出了隐私驱动的细粒度的访问控制机制,并对该机制的不同的组成部分进行详细的描述;第3节通过一个例子来证明该访问控制机制的可行性;最后,在第4节对全文进行总结并提出了一些未来的研究方向。
1 相关工作
目前,国内外很多学者都在隐私保护的问题上做出了贡献。Shih-Chien Chou等人通过一个扩展的XACML模型即EXACML模型来确保Web服务中信息访问的安全性,这个模型主要是运用信息流控制来实现隐私保护[9]。这篇文章虽然实现了细粒度的访问控制,但是仅仅对请求者和Web服务的信息进行保护,没有对信息拥有者的隐私进行有效地保护。
Dinh Tien Tuan Anh等人设计并评估了一款运行在Google App Engine上的中间件,叫做Mosco,能有效地管理分享的移动信息,保护用户的隐私[10]。这篇文章给我们在细粒度的访问控制上一些启发,当需要访问信息的时候,如果请求者不是信息拥有者的朋友,或者亲密程度不够的话,文章中的处理方式是拒绝访问,太过生硬,可能违背用户最初分享信息的初衷。
Linke Guo等人为在线社交网络提出了一种基于信任度的隐私保护的好友推荐的方法,用户根据自己的隐私偏好找到匹配的好友并与之建立社交关系[11]。文章通过为用户选择信任度高的好友进行社交来避免用户隐私泄露,但是不能灵活的控制用户发布消息的暴露程度。
Yuan Cheng等人针对在线社交网络中用户之间的关系进行访问控制建模,提出了利用正则表达式符号来对隐私策略进行描述的方法,用户和资源的访问控制策略由访问请求、多种关系类型、评估的出发点和路径中的跳数组成,并提出了两种路径检测方法来确认用户之间是否存在访问关系路径[12]。文章主要还是关注于用户是否有访问权限,而并不能对信息的暴露程度进行灵活的控制。
Leila Bahri等人提出了一个基于标签的访问控制方法,用户可以给他的朋友自定义访问水平标签,给自己发布的不同类型的信息自定义敏感度标签,当用户需要请求访问信息的时候需要对他的访问水平和所要请求的信息的敏感度进行评估,只有访问水平高于信息的敏感度时才能访问该信息[13]。
而本文提出的方法是对用户发布的消息中的敏感信息进行模糊化,相比于现有的访问控制机制要么可以访问要么完全不能访问的情况,本文中用户的所有好友都可以访问到消息,但是他们所得到的消息的敏感程度是不一样的,在保证好友都可以访问到消息的前提下有效地保护了用户的隐私。
2 隐私驱动的访问控制机制
图1是用户通过在线社交应用发布消息的系统。整个系统分为三个部分:消息发布者、消息请求者和在线社交应用。整个处理过程在在线社交应用内部处理,对用户是透明的,社交应用通过两个步骤控制整个过程:(1)对消息发布者提交的内容进行语义标注(2)根据请求者的隐私权限,将发布者提交的内容中涉及隐私的词汇进行模糊化,产生与消息发布者提交的内容语义一致的消息发送给请求者。为了实现这两个功能,在线社交应用需要两个模块:标注模块和访问控制模块。
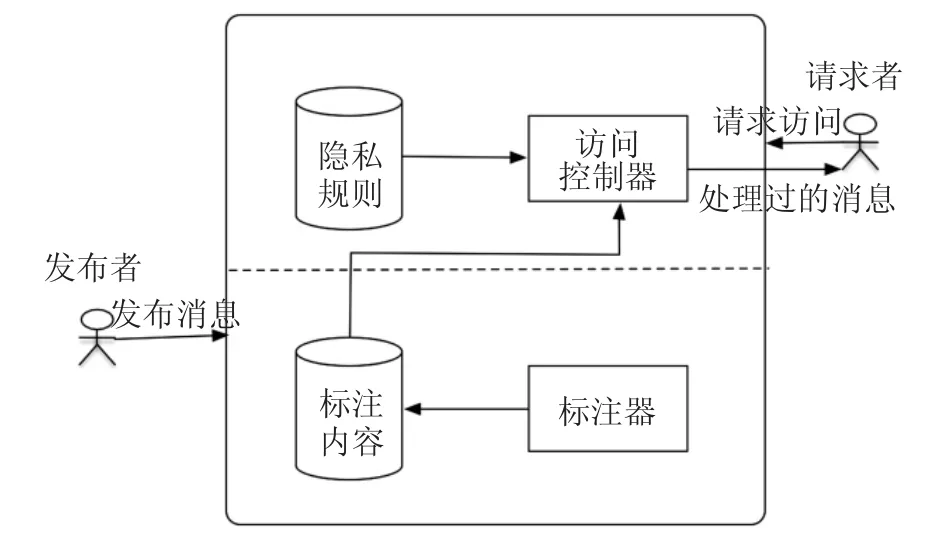
图1 系统架构图
在开始使用在线社交应用时,用户需要先向在线社交应用提交自己的隐私需求,即,对不同类型的请求者,他们最后看到的隐私信息的详细程度。这些不同的需求以隐私规则的方式存储在数据库中,由在线社交应用进行管理。用户只要定义好自己的隐私需求,在以后的使用过程中系统会将他的需求应用到他所有发布的消息中,不需要用户自身来管理各种权限的请求者可以得到什么样的内容,简化了用户的工作。
当User1发布一条消息m,m会发送到标注模块进行词性标注和语义分析得到m0,并存储在在线社交应用中。然后,User2向访问控制模块提交访问m的请求,访问控制模块对该请求进行评估,并评定经过词性标注的消息m0的敏感度。最后,根据User2亲密程度的不同运用相应的隐私规则得到新的消息m1,发送给User2。
2.1 消息标注
当用户通过在线社交应用发布消息时,应用会调用标注模块。消息的内容经过标注模块的处理,标注过的内容将用于评估隐私敏感度。
名词作为用户发布的消息的一部分含有丰富的语义,通常会带有一些隐私敏感信息[14]。所以,我们的系统中标注模块自动的从发布的内容中找出名词,并对这些名词进行标注,然后将这些名词与它们的概念联系起来。因为一个名词可能会有不同的意思,例如,苹果可能指的是我们平常吃的水果,也可能指的是苹果公司的产品,所以在处理一个名词的时候要根据发布的信息中真实的语义来消除歧义,选择最合适的词义。标注模块的工作流程如图2所示。

图2 标注模块工作流
把可能泄露用户隐私的名词分成两大类:一类是专有名词,比如,名字、地点等,一类是普通名词,比如,一些隐私敏感的疾病、职业等。 ICTCLAS 2016[15]可以自动的对消息中的名词进行标注,然后利用CN-Dbpedia[16](提供开放API)的资源,把标注的名词的概念跟 CN-Dbpedia中的资源进行关联,借助SPARQL查询语言[17]和语义Web[18]来实现标注名词的语义分析。
经过之前的语义分析,每个名词的分类范畴和可能的概念都被找出。然后需要根据发布的消息来确定最合适的词义,这个过程叫做词义消歧[19]。在经过词义消歧以后的结果存储在标注模块的数据库里,下面就对得到的结果进行隐私敏感度分析并执行隐私访问控制。
2.2 消息访问控制
在这一部分,提出了一个访问控制机制,对用户发布到在线社交应用上的消息进行处理。隐私策略和请求访问消息的用户等级由消息发布者自己定义。用户对自己社交应用中好友的分类类似于基于角色访问控制中角色的分类,不同类型的好友对发布的消息有不同的访问权限。
访问控制机制对可以发布消息的社交应用都是可行的,依赖于现有的社交应用,帮助控制隐私消息的访问。在线社交应用需要开发一个控制模块对请求访问的用户进行隐私访问授权,访问控制模块在处理访问请求时需要三类资源:请求访问的消息;访问请求者的类型;消息发布者的隐私需求。在处理访问请求时,访问控制模块从标注模块的数据库中调出经过标注的消息,消息由三个标签标注:消息发布者、消息的合作发布者,即,消息发布者在自己的消息里提到的其他人,语义标注。
2.2.1 访问控制规则
系统根据用户的需求定义了一系列的访问控制规则,下面我们就详细阐述一下访问控制规则。访问控制规则包括三个元素:敏感话题(ST)、请求者的类型(RC)、访问水平(AL)。用户可以根据自己的隐私偏好选择他想保护的敏感话题,敏感话题列表由在线社交应用提供,用户在使用前对自己想要保护的话题进行选择就可以。用户还需要将自己社交应用上的好友根据亲密程度或者信任程度进行分类,然后根据好友的亲密程度将每个敏感话题的访问水平与请求者类型进行对应。通过这种方式,用户就可以对自己的隐私信息进行控制,不同类型的请求者访问到的隐私消息的水平不同。下面的三元组就是一个访问控制规则:
rulei=
rulei∈Rules(访问规则)有三个组成元素:敏感话题(sti)、请求者类型(rci),访问水平(ali)。
定义1(敏感话题(ST))系统提供的可能涉及到个人隐私的话题,这些内容是关于用户个人信息的,当被他人得到将有可能会滥用并影响到用户。
例如,涉及用户个人信息的敏感话题有职业、收入、健康状况、信仰、家庭住址等等。
定义2(请求者的类型(RC))用户根据自己与消息请求访问者的亲密程度来对请求者进行分类,在社交应用中可以把请求者分成家人、朋友、陌生人等。
定义3(访问水平(AL))用户根据自己隐私偏好对自己发布的敏感话题定义不同的暴露程度,并与不同类型的请求者进行匹配。
例1用户Alice的其中一个隐私敏感话题是职业,定义的访问水平是AL=(社会角色,教育工作者,教师),对社交应用的请求访问者的分类是RC=(陌生人,朋友,家人),所以,当Alice发布了一条消息中含有“教师”这两个字的时候,陌生人看到的是“社会角色”,她的朋友看到的是“教育工作者”,而她的家人看到的是“教师”。下面是隐私规则:
rule1=<职业,陌生人,社会角色>
rule2=<职业,朋友,教育工作者>
rule3=<职业,家人,职业名称>
接下来介绍隐私规则的定义过程和系统是如何执行的。
rule4=<定位,陌生人,空>
rule5=<定位,朋友,区属>
rule6=<定位,家人,具体地点>
rule7=<人名,陌生人,空>
rule8=<人名,朋友,姓名>
rule4禁止陌生人得到用户定位信息,rule5允许用户的朋友看到用户的定位在某个区但是更详细的位置看不到,rule6允许用户的家人看到用户定位的具体地点。rule7禁止陌生人看到用户发布的消息中的人名,rule8允许朋友得到消息中的人名。
rule9=<健康状况,陌生人,空>
rule10=<健康状况,朋友,生病>
rule11=<健康状况,家人,病名>
在rule中用户给陌生人设定的访问水平是“空”,这就意味着陌生人不会得到任何有关该用户健康状况的信息。rule10中我们可以看到用户给自己的朋友设定的访问水平是“生病”,但是除了这个,朋友并不知道更详细的信息。rule11中用户的家人可以看到用户是感冒了或者胃炎等具体的病名,因为给家人的访问水平是“病名”。
定义4(概念语义树)用层次化的树状结构来表达概念之间的逻辑关系。
(1)N={n1,n2,…,nn}为概念树的节点,表示不同的敏感词。
(2)若一个节点含有子节点,则这个节点称为其子节点的父节点,父节点的词汇敏感度低于子节点。
(3)一个节点含有的子树的根节点称为该节点的子节点,子节点的词汇敏感度高于父节点。
(4)当nj节点是ni节点的下层节点时,表示nj节点中的词汇敏感度高于ni节点中的词汇。
系统通过比较访问者的访问水平和经过语义处理的消息来度量消息中词汇的敏感度。在语义描述中,本体[20,21]作为知识库角色,利用它描述客观事物的概念和关系。本体作为知识库的特点在实现信息检索,智能搜索方面提供了一种完善的解决方案[22]。本文本体构建采取的是 Protégé[23,24],Protege是生成和编辑本体与知识库的可扩展、跨平台且开放源码的开发环境,目前已经在30多个国家得到广泛的推广和使用。我们利用本体从CN-DBpedia中得到与不同访问水平对应的概念语义树,树中一个节点对应一个访问水平,对于此节点下层的所有节点对这个访问水平都是敏感的,即,这个访问水平不能访问到下面的节点。如图3所示,是一棵概念语义树。
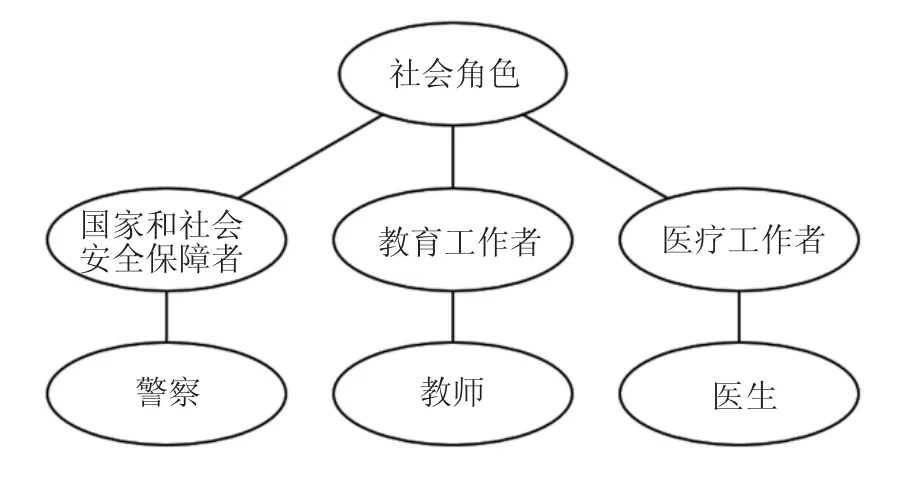
图3 概念语义树
例2Alice在社交应用上发布了一条消息,消息中有“教师”这个词汇,她的朋友Bob(在Alice的社交应用中属于“朋友”这一访问者类型)要访问这条消息。首先,社交应用中的访问控制模块会对Bob的请求进行拦截,然后检查分配给“朋友”这一访问者类型的隐私规则,以确定Bob的访问水平(教育工作者),然后调出含有“教育工作者”的这一支(图3),“教师”节点在“教育工作者”节点下面,最终,访问控制模块将消息中的“教师”替换成“教育工作者”(Bob的访问水平)发送给Bob。
2.2.2 处理策略冲突
在对敏感信息进行处理时,访问控制模块也需要处理潜在的策略冲突。当用户在发布一条消息时提到了他的一个朋友,或者这条消息跟他的朋友相关,这时他的这个朋友就属于间接消息发布者,而他们两个人的隐私需求一般来说是不一样的,这个时候就可能产生隐私策略冲突。为了满足这两个人(或更多人)的隐私需求,访问控制模块需要处理隐私策略冲突,对两个(或多个)访问水平进行比较,在语义树上选择靠根节点近的节点,因为越靠近根节点词义越广,可以很好地保护隐私信息。
例3Alice在社交应用发布了一条消息,里面提到了Tom,Tom就是这条消息的间接发布者,下面是描述Alice和Tom隐私需求的访问规则。
rule1-Alice=<职业,陌生人,社会角色>
rule2-Alice=<职业,朋友,教育工作者>
rule3-Tom=<职业,朋友,职业名称>
我们分两种情况来讨论隐私策略冲突问题:
(1)Bob在Alice社交应用中被分在“陌生人”一组,在在Tom的应用中是“朋友”这一组,根据Alice和Tom各自的隐私访问规则,Bob得到的信息分别是“社会角色”和“职业名称”,这时候就产生了隐私策略冲突,社交应用中的访问控制模块对“社会角色”和“职业名称”这两个访问水平进行比较,选择词义更广的“社会角色”返回给Bob,最终Bob在Alice发布的消息中看到的是“社会角色”。
(2)Bob在Alice社交应用中被分在“朋友”一组,在Tom的应用中也是“朋友”这一组,但是Alice和Bob给自己朋友定义的隐私访问水平是不同的。根据Alice和Tom各自的隐私访问规则,Bob得到的信息分别是“教育工作者”和“职业名称”,这时候就产生了隐私策略冲突,社交应用中的访问控制模块对“教育工作者”和“职业名称”这两个访问水平进行比较,选择词义更广的“教育工作者”返回给Bob,最终Bob在Alice发布的消息中看到的是“教育工作者”。
2.2.3 执行访问控制
用户根据好友亲密程度的不同,分配给其不同的隐私访问水平。为了满足不同的访问者执行对应的访问水平,当用户发布一条消息后,需要根据访问者的不同类型对该消息进行敏感度评估。敏感度根据下述几个元素来定义:访问者的类型、访问者对应的访问水平、访问水平对应的词,消息中的语义标注。设用户b请求访问用户a发布的消息,首先我们要判断用户b的类型rcb,然后根据b的类型从社交应用的库中调出相应的隐私规则ruleb,然后分配给b相应的隐私访问水平alb,得到相应访问水平对应的词,最后,b得到跟自己访问水平一致的消息mb。
定义5(访问请求(IR))用户a和用户b是好友,用户b请求访问用户a发布的消息,我们用如下三元组来表示:irba=(b,m,a)。
下述算法定义了系统中访问控制是如何执行的:
1.Input:An IR,irba=(b,m,a,),T;
//输入一个访问请求和概念语义树
2.Output:al;//输出访问水平对应的敏感词汇
3.request(b,m);//用户 b 请求访问用户 a发布的消息;
4.rcba=JudgeUserType(b);//判断用户 b 在 a中的类型;
5.rr1=GetRules(rcba);//b在 a中对应的隐私规则;
6.alba=GetUserAL(rr1);//b 在 a中所对应的访问水平;
7.al1=DFS(T,alba);
//对概念语义树进行深度优先遍历,找到b在a中的访问水平对应的敏感词汇;
8.judge=Co-publisher(m);
//判断用户a发布的消息是否有间接发布者c,如果有,返回true,如果没有,返回false;
9.if judge=false;
10.return al=al1;
11.else
12.rcbc=JudgeUserType(b);//判断用户 b 的类型;
13.rr2=GetRule(rcbc);//得到 b 对应的隐私规则;
14.albc=GetUserAL(rr2);//得到 b 的访问水平;
15.al2=DFS(T,albc);//对概念语义树进行深度优先遍历,找到b在c中的访问水平对应的敏感词汇;
16.al=Choose(al1,al2);//从 al1和al2中选择更靠近根节点的一个;
17.return al;//返回用户b访问水平对应的敏感词汇;
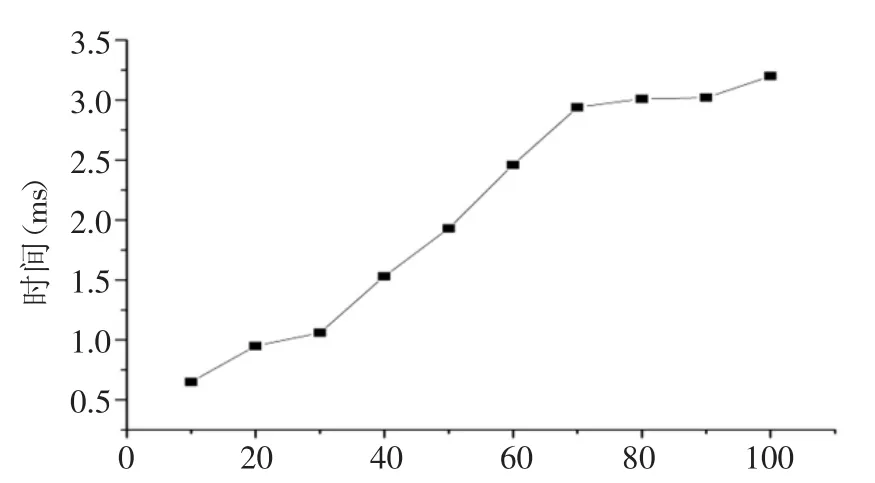
图4 算法运行时间
上述算法的时间复杂度为O(n2),空间复杂度为O(n),n为概念语义树的节点个数。如图4,随着概念语义树节点个数的增加,运行时间也在增加,虽然本文的访问控制方法需要一定的时间开销,但是运行时间是很短的,当节点个数增加到100个的时候,运行时间也只有3.2毫秒,完全在我们接受的等待时间的范围内。
3 案例分析
考虑在线社交应用的一个用户Alice发布了一条消息如下:今天天气很好,我跟我的好朋友Bob一起去了幼儿园看望小朋友,因为Bob是一个教师,所以他跟孩子们相处的很融洽。消息最后有一个定位是南京航空航天大学。
如图5所示,是Alice发布的消息,当Alice将这条消息发布到自己的社交应用上之后,社交应用开始对这条消息进行处理,首先,对发布的消息进行名词标注,结果如下图6所示。

图5 Alice在移动社交应用上发布的消息

图6 经过词性标注的消息
图6对消息中的名词进行了标注,后面有/n、/nr、/ns、/ng的都是名词,已经被标注出来,nr是人名,ns是地名,ng是名词性语素。
Alice设置的敏感话题(ST)中包括职业和具体位置,所以经过语义分析和消歧之后,筛选出教师和南京航空航天大学属于敏感话题,接下来需要对它们进行处理。
首先,我们先来看Alice给她的不同类型的访问者定义的隐私规则,
rule1-Alice=<职业,陌生人,社会角色>
rule2-Alice=<职业,朋友,教育工作者>
rule3-Alice=<职业,家人,职业名称>
rule4-Alice=<定位,陌生人,定位>
rule5-Alice=<定位,朋友,区属>
rule6-Alice=<定位,家人,具体位置>
由于Alice在自己发布的消息中提到了Bob,所以Bob就是这条消息的间接发布者,他的隐私也需要保护,Bob给他的不同的请求访问者定义的隐私规则如下,
rule7-Bob=<职业,陌生人,社会角色>
rule8-Bob=<职业,朋友,教育工作者>
rule9-Bob=<职业,家人,职业名称>
rule10-Bob=<定位,陌生人,市属>
rule11-Bob=<定位,朋友,区属>
rule12-Bob=<定位,家人,具体位置>
当Alice的朋友Ted想要访问她发布的这条消息时,Ted向移动在线社交应用发出请求,社交应用对Ted的访问水平进行评估,在这里,Ted是Alice的朋友,但是对Bob来说,他是一个陌生人,如图7、图8所示,是Alice和Bob对不同的敏感词的隐私访问水平。

图7 Alice和Bob的访问水平

图8 Alice和Bob的访问水平
我们可以看到Alice和Bob的隐私策略是冲突的,根据之前策略冲突的处理方法,最终Ted得到的消息中,“教师”由“社会角色”代替,定位中的“江宁区”由“南京”代替,所以最后Ted在他自己的移动在线社交应用上看到的Alice发布的消息内容是这样的:今天天气很好,我跟我的好朋友Bob一起去了幼儿园看望小朋友,因为Bob是社会角色,所以他跟孩子们相处的很融洽。消息最后有一个定位是南京。这样就很好的保护了Alice跟Bob的隐私。
4 总结和展望
提出了一个隐私驱动的细粒度的访问控制机制,可以对在线社交应用中的隐私泄露问题进行有效地保护。相比之前的相关工作,本文的主要贡献在于在线社交应用可以自动的对用户发布的消息进行语义分析,把涉及到的敏感话题进行标注,然后根据访问者的不同对该敏感词进行处理,最后不同的访问者得到的消息是不同的,而且该访问控制机制对用户是透明的,用户在使用起来简单便捷。并相应的进行了案例分析,证明了该访问控制机制的可行性。本文的下一步工作是,将该访问控制机制应用到现有的在线社交应用中同时提出一种根据不同用户隐私偏好自动生成用户的隐私规则的方法。
猜你喜欢
电子元器件与信息技术(2022年7期)2022-09-07
北京航空航天大学学报(2022年8期)2022-08-31
通信产业报(2020年43期)2020-01-15
中文信息(2018年6期)2018-08-29
东坡赤壁诗词(2018年3期)2018-07-16
中国新通信(2017年3期)2017-03-11
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
