
三种面部性别识别算法的比较
2019-01-03 06:29:48丁文倩金立左
机械设计与制造工程 2018年12期
李 宇,丁文倩,金立左,潘 泓
(东南大学自动化学院,江苏 南京 210096)
人脸是一个丰富的信息来源,能提供诸如身份、年龄、性别和种族等信息。自动面部性别识别有许多潜在的应用情景,如生物识别认证、视频监控、相册管理、图像检索、计算机互动等。比如在身份识别过程中,先行确定性别,可以减少一半的数据库搜索时间。
极限学习机(extreme learning machine,ELM)[1]主要用于计算单层前馈神经网络中隐藏层的个数。其中,在计算隐含层矩阵广义逆的时候,因奇异值分解(singular value decomposition,SVD)的复杂度高,会影响到计算效率。FASTA-ELM[2]用近端梯度下降算法计算ELM的输出权重,因而能在不使用SVD的情况下计算输出权重的最小范数,并且可以推广到隐藏层矩阵较大的情况中。FASTA-ELM算法的最大优势在于,不需要对稀疏元素解空间进行反复迭代搜索,通过自适应步长选择省去了一些梯度计算步骤,使用后向下降步骤以保证算法收敛。
多尺度融合决策算法[3]通过提取不同图像的分辨率,基于各个特征进行分类,并对分类后的特征进行融合,获得所需要的结果。文中主要使用的特征有基于边缘方向直方图的形状特征,基于LBP(local binary patterns,局部二进制模式)的纹理特征。提取完特征后,接着使用支持向量机(support vector machine,SVM)对单尺度和多尺度下同样的特征进行决策融合。
面部性别识别是一个二元分类问题。每个分类问题都需要有效的特征表示,因为它严重影响分类器的性能。特征描述中的关键问题是计算成本、鲁棒性和泛化能力。特征描述符对于未见的试验样品应当具有低计算成本、高鲁棒性并且性能良好这些特点。LBP 具有高计算效率、高鉴别能力的特点,使用LBP进行面部识别,最初是由Ahonen等[4]倡导的,随后它被广泛用于面部识别和面部性别识别,在一些由于拍照姿势、光照等原因对成像产生显著影响的图片中,Shan等[5]进行了试验,取得了很好的效果。LBP 在很多方面具有优势,比如计算简单、强度变化时的不变性和代码开源。同时,LBP 也有一些严重的缺点,如对噪声和非单调照明变化的敏感性,并且会将灰度级差(the gray-level difference,GLD) 的幅度信息完全丢失。本文通过将GLD量化为多个级别来概括LBP的概念,采用多量化局部二进制模式 (multi-quantized local binary patterns,MQLBP)[6]对GLD的符号和幅度信息进行编码。
为了更加直观地展示对比结果,本文主要在PAL(a lifespan database of adult facial stimuli)和FERET(the face recognition technology)数据集中进行测试。在PAL数据集中,对FASTA-ELM 算法和多尺度二进制模型进行比较探索;在FERET数据库中,对FASTA-ELM算法和多尺度融合决策算法进行比较探索。
1 FASTA-ELM算法
在ELM中计算输出权值矩阵,常用的方法就是采用近似梯度下降算法,直接求解最小范数的最小二乘问题,当中需要使用到SVD。其中隐含层矩阵的求解应视作一个优化问题,采用FBS(forward-backward splitting )梯度下降算法求解。首先在FASTA-ELM中,使用自适应步长选择和非单调线性搜索以加快收敛速度。因此,在大规模病态矩阵中,与其搜索目标所有可能的步骤,不如采用自适应选择步长,使得梯度下降问题的维度变得非常小,从而加快算法收敛速度。然后再采用FASTA- ELM的后向下降步骤来检查每个目标,以保证选择的子梯度收敛。
1.1 极限学习机
给定一个训练样本集{(xi,yi)|xi∈Rn,yi∈Rm,i=1,…,N},激励函数为g(x),隐藏单元为N′个。
具体训练过程如下:
1)给定任意的输入权值ωj和bj,j=1,2,…,N′;
2)计算隐含层输出矩阵H;
3)计算输出权值矩阵β,β=H+T,其中T为最终的输出矩阵。
ELM中训练误差的最小值如式(1)所示,输出权重的范数如式(2)所示。
(1)
Minimize:β
(2)
式中:Minimize为最小值优化函数;βi为第i个输出权值矩阵;x为输入值;Ti为第i个隐含层的输出矩阵。
以上是由黄广斌教授于2006年提出的ELM算法的最初模型。经过不断发展,如今多采用式(3)定义的Standard-ELM(S-ELM):
(3)

1.2 Fast adaptive shrinkage / thresholding algorithm(FASTA)
FBS主要采用如下形式解决问题:
Minimize:h(τ)=f(τ)+g(τ)
(4)
式中:τ∈R;h(τ)为目标函数;f(τ)为一个可微函数;g(τ)为一个任意的凸函数。由于g不可微且任意取值,无法直接用梯度下降算法求得,因而g的最近邻解决方式如式(5)所示。
(5)
式中:proxg(z,ρ)为所求的g函数;argminτ为最小值函数;z为初始猜测值;ρ为步长。
对FBS算法分两步进行改进。
第一步对f采用前向梯度下降:
τk+1=τk-ρkf′(τk)
(6)
式中:τk+1为第(k+1)次预测值;τk为第k次预测值;ρk为步长,是标量,表示k次迭代过程中梯度下降速度。即沿着f的负向梯度方向对τk进行迭代,找到梯度下降最快的方向。
第二步采用后向梯度下降:

Minimize:h(τ)=f′(Aτ)+g(τ)
(7)
式中:A为参数矩阵。
1.3 FASTA-ELM
在实际情况中,当隐含层矩阵变大时,会导致特征分解不稳定,计算时间成本增加,因而人们开始使用FASTA算法来计算ELM的输出权重。本文对式(3)进行如下改进:
g(τ)=β1
(8)
(9)
FASTA-ELM算法的最大优势在于,不需要对系数元素解空间进行反复迭代搜索,而是通过自适应步长的选择,省去一些梯度计算步骤,并使用后向下降步骤以保证算法收敛。FASTA-ELM算法流程如下。
输入:数据N=xi,yi,迭代次数k,停止条件S,节点个数W。给定任意的输入矩阵权重以及阈值(ω,b),加入激励函数q(xi,ω,b),计算隐含层矩阵H:
不满足条件S时循环执行:
通过近端梯度下降求解公式(7)中的τ。
输出:ELM的输出权值矩阵。
2 多尺度融合决策
多尺度融合决策算法使用多尺度融合进行面部性别识别,首先提取不同分辨率图像的特征,然后基于这些特征得到一个分类器以及融合的决策。图1所示为该方法的决策流程,其中方形表示数据,椭圆形表示操作步骤。图中的分类器,每个仅能接收一种特征类型作为输入,不同特征的不同决策组合将在实验环节中进行讨论。采用这种方法的主要原因就是不同性别之间存在的面部特征差异,基于这一假设,后续实验将会验证。文中主要采用颜色、形状与纹理特征作为3种描述符,由于颜色判断不是必须的,因而文中采用的都是灰度图像。

图1 多尺度决策融合流程图
2.1 图像特征
本文采用与梯度方向直方图类似的边缘方向直方图作为图像特征,二者主要区别在于本文中的输入图像为灰度图像,无法对直方图进行归一化处理。通过算子[-1,0,1]T和[-1,0,1]可以得到水平方向和垂直方向边缘,用v和h分别表示水平方向和垂直方向的边缘像素,二者分别通过将边缘检测图像与原始图像卷积得到。边缘方向θ用式(10)表示:
(10)
边缘强度m用式(11)表示:
(11)
式(10)中的角度被分为每18°一个区间,即将360°分为20个区域,则每个像素都是对边缘方向和边缘强度的累加。因此,直方图近似于边缘取向的加权分布,其中权重对应于边缘的幅度。
2.2 纹理特征
本文使用LBP提取纹理特征。选取中心像素点C和近邻像素点P,令近邻像素点和点C的距离为R。用直方图表示纹理特征:
TT=hh(I(0)-I(C),I(1)-I(C),…,I(P-1)-I(C))
(12)
式中:TT为点P的灰度差异值;hh为邻近点P与中心点C之间的像素差;I(x)为邻近点x的灰度值。因为给定的与中心像素强度的差异的平均强度值的变化是不变的,所以如果仅考虑先前算子中符号的差异,就可以得到灰度差异值:
TT=hh(s(I(0)-I(C)),…,s(I(P-1)-I(C)))
(13)
式中:s(·)为符号描述符,如果为负的则值为0,否则为1。可以通过将二进制值乘以二项式系数来获得LBP特征的唯一值。
(14)
式中:LBP(P,R)为LBP特征值。
LBP可以生成2P种不同的值,即生成的特征向量的大小是2P。
2.3 融合决策
在模式识别过程中有很多方法可以用于信息融合,主要的区别在于融合是发生在特征提取层还是决策层。在前一种情况下,不同来源的信息被融合到单个特征向量中,然后将该特征向量馈送到分类器中;在后一种情况下,在每个分类器作用后再进行融合决策,每个分类器都可以用不同的特征或相同的特征进行训练。总之,分类器应该使其错误发生在融合之前。在本文中,采用第二种方法进行决策融合。本文融合了不同分类器的决策,这些分类器用于单个尺度捕获的不同类型的特征或者在不同尺度捕获的相同类型特征的训练。
对于决策过程,本文使用多数表决规则,其中di(i=1,…,m)表示m个分类器中每个分类器的决策,每个决策都是用整数表示,0表示女性,1表示男性。多数表决规则如式(15)所示。
(15)
式中:dmaj为最终的决策结果。
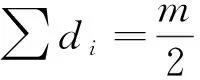
3 多量化局部二进制模式
为彻底评估MQLBP和LTP(local ternary pattern)特征对于性别分类任务的适用性,并证明基于这些特征的分类性能优于基于二值量化LBP特征的分类性能,笔者提出一种新的方法,通过量化将GLD分成多个级别。本文将得到的多量化局部二进制模式用多个不同的实验进行评估,以此证明增强了鉴别能力、噪声耐受性和泛化能力。
3.1 LBP
坐标(xc,yc)处中心像素的LBP编码如式(16)所示,也如2.2中的式(14)所示:
(16)
式中:gc和gp分别为半径R的圆形邻域中的中心像素及其第p个邻近像素的像素强度;参数P为相邻像素的总数。函数f1(l)如式(17)所示:
(17)
3.2 LTP
为了降低LBP对噪声的敏感度,采用如图2(b)所示的三级量化方案,得到局部三元模式方法。使用附加的阈值参数和式(18)所示的函数将GLD量化为3个级别。
(18)

图2 4种量化函数
为了减少特征维度,三态码被分成两部分以通过编码的正量化和负量化级别来生成两个二进制模式[7]。
3.3 MQLBP
从式(16)可以看出LBP计算主要有三个步骤:
1)计算中心像素及其相邻像素之间的GLD;
2)使用仅保留符号信息的二进制量化函数对GLD进行编码;
3)由二进制模式转换为十进制形式得到LBP编码。
假设在8位灰度图像中,第一步算得GLD范围为(-255,255);第二步使用二进制量化函数对GLD进行编码;第三步进行LBP编码,输出0和1。换句话说,差分运算器的输出范围被量化成两个等级,如图2(a)所示,这样的二值编码函数使得计算更加简单。然而,LBP编码丢失了差异幅度的信息,限制了辨别的能力。因此,笔者提出将LBP与对比信息相结合,提升性别分类的性能。使用局部方差(local variance)计算对比度信息的数学式如下:
(19)
式中:VARP.R(xc,yc)为局部方差值;μ为相邻像素点和中心像素点的GLD均值。
由于方差测量能提供连续值输出,本文采取量化特征空间的方式获得直方图描述符。然而,这种方法存在两个主要问题:1)需要附加训练阶段,以确定直方图面元的截止值;2)正确选取bins的数量,如果选择较少数目的bins,会降低其辨别能力,而大量的bin却会增加特征尺寸,可能导致直方图不稳定。
为了避免出现上述问题,本文提出了一种广义形式的LBP,以隐含地捕获来自灰度级差的幅度和符号信息。LBP广义形式的基本思想建立在量化GLD算子的输出范围上。然而,本文建议将输出范围量化为多个级别,而不是限制为二进制量化,因此得到的模式将被称为多量化局部二进制模式(MQLBP)。使用如图2(b)和(c)所示的阈值参数t对GLD进行多级量化,需要注意的是MQLBP在概念上是不同于LTP的。如图2(b)中所示,LTP将GLD量化为3个固定等级,MQLBP扩展了将GLD量化为所需级数的想法。此外,当GLD被量化为中等水平(水平0)时,LTP会忽略符号信息以限制其辨别能力。如图2(c)和(d)所示,本文提出的方法通过对称量化GLD相对于零克服了这个限制。对等级L(L>0),量化函数fL(x,t)如式(20)所示。
(20)
由式(20)可知,在最初LBP中使用1级量化,将整个输出范围分割成两个不同的部分。在每个较高的量化级,每个子部分被进一步量化为两个不同的分段,因此共产生2L个分度。其中对应于第i个分度AN的MQLBP编码计算如式(21)所示。

(21)
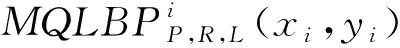
为了使用MQLBP描述每一个面部图像,需计算空间增强直方图,即将每个MQLBP图像划分成不重叠的矩形块以计算它们,连接起来就可以构建一个特征向量的局部直方图,所有MQLBP图像的这些特征向量进一步级联就可以构建最终面部描述符。
显然,特征维度与在计算MQLBP中使用的级别数量成正比。为了展示更多的MQLBP的辨别能力,同时保持较低的特征维度,本文在实验中仅考虑2层MQLBP。
4 实验结果
为了对上述3种方法进行对比,本文将算法应用到具体的面部性别分类问题中,选取FERET和PAL数据库,通过对其中的面部图像进行性别分类,来分析3种方法的优缺点。
为了从面部提取特征,采用LBP特征提取算子,将面部分为8块,bins的数量确定为59。因此,最终特征向量是8×8×59=3 776bins。
本文使用True Positive(TP)和True Negative(TN)来计算识别率Raterecognition,如式(23)所示:
(22)
式中:Raterecognition为样本总数。
4.1 实验数据库
PAL数据集包含575个面部图像(225名男性和350名女性),图像的分辨率为640×480。为定位面部区域,采用Viola-Jones等[8]提出的面部检测器,每个检测到的脸部被归一化为64×64大小的图像。FERET数据库是最具挑战性的面部识别数据集之一,数据库中的面部图像用姿态(前沿、左侧和右侧轮廓)、光照条件来概括,本文使用900张图,其中男性、女性面部图像各占一半。
4.2 实验对比
1)在PAL数据库中进行面部性别测试,结果见表1。
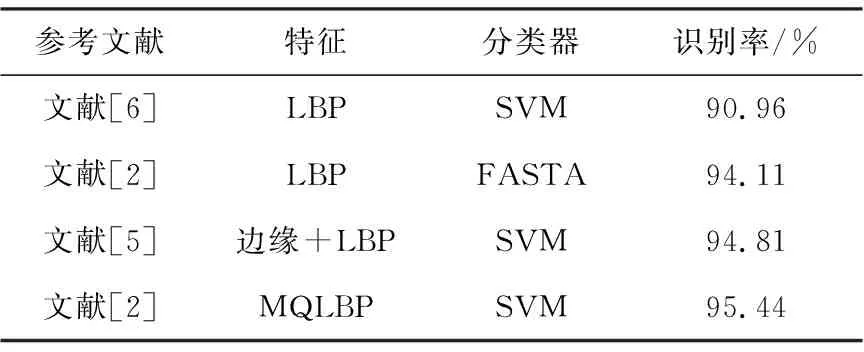
表1 PAL数据库面部性别测试结果表
2)在FERET数据库中进行面部性别测试,结果见表2。
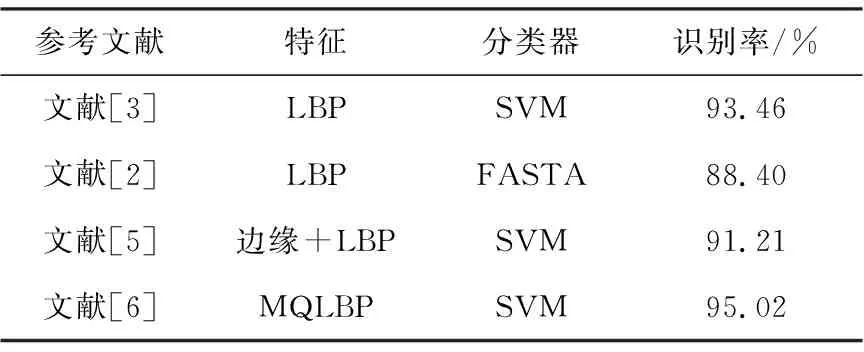
表2 FERET数据库面部性别测试结果表
5 结束语
S-ELM通过正交投影、特征分解或迭代的方法,解决输出权重的问题,然而隐藏层中隐含节点数量增加时,计算的时间、空间复杂度都显著增加,特别是隐藏层矩阵条件变得不稳定,会影响S-ELM的泛化能力。
将决策融合方法运用到FERET数据库中,可以改善识别结果。在实验过程中,能整合来自不同尺度的信息,即使仅来自单个特征的信息,也比在单个尺度融合来自不同特征的信息更重要。
实验结果表明,MQLBP具有更好的泛化能力和处理噪声的能力、更优的辨别能力。这3个优点是以增加特征向量长度为代价的,因而需要更多的计算时间。LBP对中心像素和相邻像素之间的灰度级差采用二进制量化,然而这种简单而有效的方法丢弃了灰度级差的幅度信息。为了解决这个问题,本文通过扩展矢量量化概念,使LBP不仅限于二进制量化,即采用MQLBP方法对灰度级差的符号和幅度信息进行编码,提高了辨别能力。结果清楚地表明,MQLBP方法具有三重优势,包括更高的性别分类精度、改进的噪声鲁棒性和更好的泛化能力。
FASTA-ELM、多尺度融合决策和多量化局部二进制模式,各有优点,各有侧重,同时也有相互重合的地方,值得进一步研究。
猜你喜欢
高中数理化(2024年1期)2024-03-02 17:52:40
湘潭大学自然科学学报(2022年2期)2022-07-28 05:26:40
中等数学(2021年8期)2021-11-22 07:53:38
数学大王·低年级(2019年10期)2019-11-25 08:23:26
中等数学(2019年4期)2019-08-30 03:51:44
摄影之友(影像视觉)(2018年12期)2019-01-28 09:01:02
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
计算机工程(2015年8期)2015-07-03 12:20:21
