
基于深度学习的人脸识别技术研究
2019-01-03 02:30刘施乐
电子制作 2018年24期
刘施乐
(浙江省杭州高级中学贡院校区,浙江杭州,310003)
0 引言
计算机视觉(Computer Vision)是专门对计算机图形学进行研究的重要领域。而人脸识别是目前计算机视觉研究的热点。人脸识别最主要的功能是对不同的人进行特征识别与区分,是一种重要的生物鉴别方法,其在智能安防、金融、智慧出行等领域有重要的应用价值。
人脸识别精度的提升,受益于深度学习方法在图像识别领域的研究和应用。传统的图像识别方法主要基于手工设计并提取特征,随着卷积神经网络的提出,尤其是2012年在ImageNet挑战赛使用深度卷积神经网络,使用计算机进行图像分类的精度日益提高,并在ImageNet 1000挑战中首次超越了人类识别分类的能力[1]。人脸识别算法的核心是通过训练深度神经网络,提取人脸特征并进行准确的分类,最终实现人脸与个体信息的匹配。在此基础上,人脸关键点检测,基于人脸的年龄预测、表情识别等都取得了一定的进展并广泛应用。尤其是活体检测,红外光感技术的不断突破与应用,人脸识别已经从学术界逐渐向工业界落地,比如目前肯德基,盒马鲜生等实体店已经开启了人脸识别的商业应用。
1 人脸识别关键技术
和人类大脑进行人脸识别的过程类似,使用机器进行人脸识别的输入为摄像头捕捉到的待识别的人脸图像,输出为该图像的人物ID。 具体的实现流程如图1所示,在获取照片后,经过裁剪和对齐等预处理,获得带识别的图像输入,然后通过特征提取机制或者降维等算法,对人脸进行特征提取,将提取到的特征向量与待匹配的人脸特征向量进行比较,最后使用欧式距离或者余弦距离对其相似度进行计算,最终得到最匹配的人脸ID。

图1 人脸识别流程
举例来说,如数据库中分别存储了已经提取到的 N 个人脸数据,我们的目标也就是从N个人脸中选出最匹配的人脸。N 个人脸的特征可以表示为:

当有待匹配的照片输入时,使用同样的特征提取结构对照片进行相同的处理,得到其特征信息,并将其与上述N个特征分别进行相似度距离的匹配,从而得到最终配置的人脸,即:

综上所述,该算法的核心即对人脸的输入图片进行准确的特征提取,使得相似照片之间的特征向量距离较近,而差异较大的照片距离较大。
2 基于卷积神经网络的特征提取
人脸识别属于机器学习中的有监督学习方法,通过建立模型、策略、算法的统计机器学习三要素[2],并使用(人脸图像:人脸ID)的有标签数据对深度学习网络模型进行训练,并使用一定的优化方法得到模型的参数,最终得到可以提取人脸特征的网络模型,并以此进行人脸的识别。
如图2所示的全连接神经网络,其输入为人脸图像的总维度(3×224×224),输出为要提取的特征向量的维度(如1024),中间是0-n个串行连接的隐藏层,使用多个网络层次的根本原因是增加模型的非线性,从而提高其拟合效果。
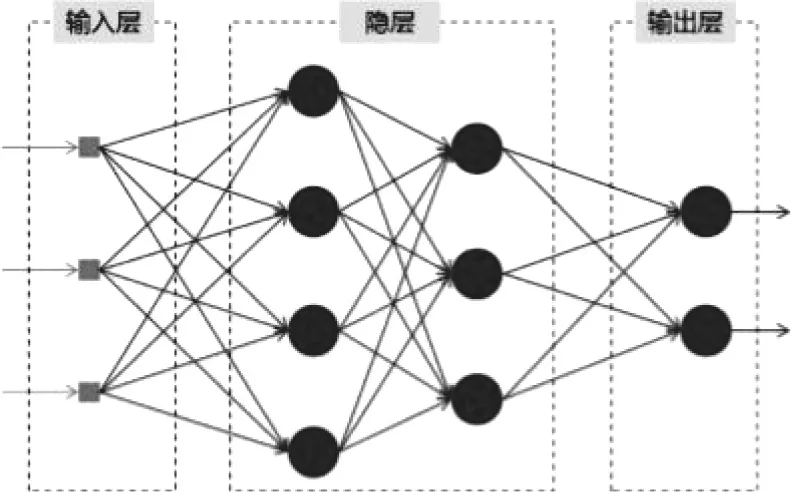
图2 全连接神经网络
对于人脸识别问题,最终的目标是神经网络的输出尽可能的表征人脸的具体特征,因此我们可以用一个1024×1的一维向量来表征人脸。图2中模型中的最终输出就可以是1024个神经元。由此可以看出,通过简单的全连接神经网络,最终对图像进行了压缩,使得一张3×224×224的向量简化为1024×1的特征向量,使得特征分布更为密集,方便后续的相似度判断。
全连接神经网络虽然理解简单,但是其过多的全连接造成了模型的冗余,过多的权重参数导致难以训练,模型的泛化能力也不尽如人意。针对全连接神经网络权重参数冗余的问题,卷积神经网络通过使用权值共享和局部感受视野的方法,实现了权重数量的大幅度降低,同时其多层次的局部感受视野带来了图像抽象层次的逐步扩大,从而可以较好的实现图像的特征抽取。
随着反向传播算法和计算机硬件性能的提升,尤其是GPU性能的提升,大规模的神经网络算法得到的广泛的应用。简单来说,就是通过增加隐藏层的数目,实现更加复杂函数的拟合。但是在图像处理领域,简单的增加网络层次有一定的局限性:全连接神经网络对图像输入数据来说,数据维度过大,导致神经网络参数过大。在此基础上提出了使用卷积神经网络(CNN)的方法进行图像数据处理,其计算思路如图3所示。
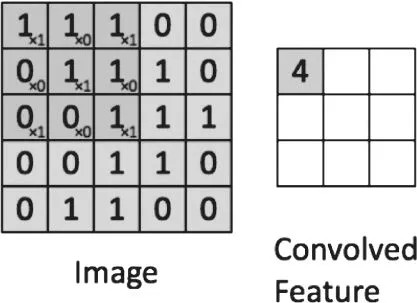
图3 卷积操作
卷积神经网络的核心即局部处理和参数共享。如图3所示,通过使用卷积核对输入数据的局部进行统一处理;并且共享同一个卷积核从而实现参数的共享。这样,大大降低了权重参数的数目,同时由于图像数据本身带有局部特性,因此这种方法也有利于提取图像的局部特征而不是孤立的以像素点的方式对待数据。
另外,卷积神经网络还使用了池化的方法进一步降低参数的维度。如图4所示,典型的卷积神经网络将卷积、池化、全连接操作有机的组织在一起,从而实现降低参数维度、提取局部特征最终实现图像的特征分类。
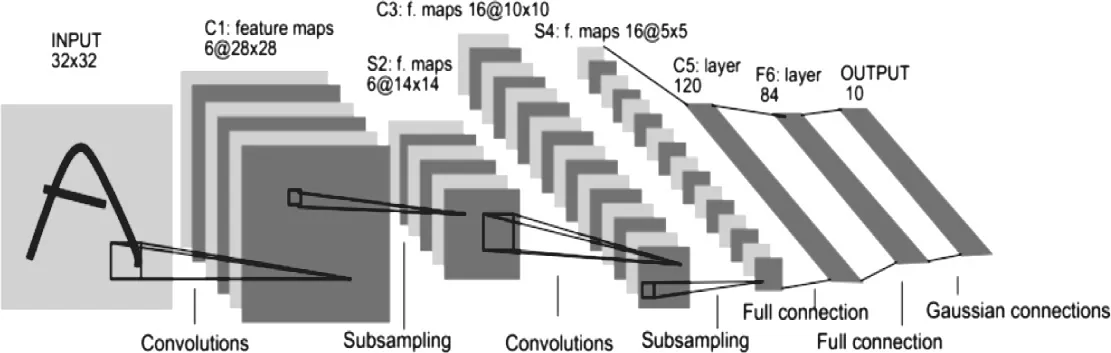
图4 典型的卷积神经网络
3 特征区分度与损失函数
对人脸进行准确识别的基础是特征向量之间的区分度要能真实的反映现实中人脸之间的区分度。例如,当两张人脸差距较大时,其特征向量间的距离也要较大,而对同一个人来说,其特征向量距离要足够小。该问题反映在模型中,就是模型损失函数的设计问题。损失函数代表了给定的标签数据(Ground Truth)与预测值之间的差距,对于分类问题来说,我们希望其特征向量与输入的特征向量基本匹配,并对差距较大的向量进行惩罚,最终获取学习能力较强的模型。交叉熵是分类问题中比较常见的损失函数,当预测值越接近真实值时,损失函数越小。单个样本的交叉熵损失函数如下所示,其中y为真实值,y^为预测值,当两者越接近时,其L越小。
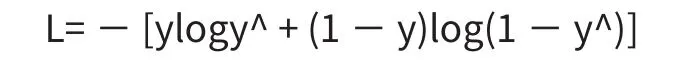
使用卷积神经网络获取特征之后,需要对其学习到的特征进行评价,通过一定的设计技巧,迫使网络学习到对分辨不同的人其特征也要更有效。Facebook在CVPR2014中提出的DeepFace[3],使用了经典的交叉熵损失函数(Softmax)进行问题优化。该模型在LFW数据集上取得了97.35%的准确率,已经接近了人类的水平。之后Google推出了FaceNet[4],使用了三元组损失函数(Triplet Loss)替代了常用的Softmax交叉熵损失函数。

图5 三元损失函数
如图5所示,该三元损失函数决定了神经网络学习的目标,即anchor作为输入的标准,positive与anchor是同一张人脸图像,negative与anchor是差距很大的图像。我们的目标就是尽可能让negative远离anchor,让positive靠近anchor,从而达到学习人脸特征更加准确,区分度更高。随着卷积神经网络结构性能的不断提升,目前很多工作的重点都在于设计更好更高效的损失函数。
4 应用领域与展望
使用深度学习方法进行人脸检测在公开数据集上已经达到了超越人类的表现,如FaceNet在LFW上达到了99.63%的准确度。随着准确度的不断提高,以及数据集数量和质量上的增长,人脸识别有了越来越广泛的落地场景。如无人零售领域,支付环节极大的依赖于人脸识别的精度;在智能安防领域,大规模的智能人脸捕捉和实时识别都对人脸识别提出了较高的要求,尤其是在现实场景中,获取到的人脸往往不是完美的正面且光线条件复杂,这就对大数据集,新技术提出了更高的要求。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
作文中学版(2022年1期)2022-04-14
保定学院学报(2022年2期)2022-04-07
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
学生天地(2020年31期)2020-06-01
电子制作(2019年14期)2019-08-20
科技传播(2019年24期)2019-06-15
数学学习与研究(2018年15期)2018-11-12
动漫星空(2018年9期)2018-10-26
