
一种基于TDMA的多信道MAC协议*
2019-01-02 06:56毛建兵王叶群
计算机与数字工程 2018年12期
张 桃 毛建兵 王叶群
(中国电子科技集团公司第三十研究所 成都 610041)
1 引言
Ad Hoc网络是通信技术热点的研究内容之一,其独特的多跳去中心化动态组网方式,使得Ad Hoc网络在军事通信、灾后应急通信、临时会议、无线传感器网络等方面都有着很高的应用价值。在Ad Hoc网络中,MAC协议主要负责信道的接入控制以及信道资源的分配。MAC协议的性能对整个Ad Hoc网络的性能有着重要的作用。MAC协议有很多种类型,其中基于TMDA的MAC协议比较适合Ad Hoc网络[1]。当前基于TDMA的MAC协议[2]有很多种,在其对应的环境下,有不错的参考价值。Simple-TDMA是一种简单的固定时隙分配MAC协议,具有实现简单和时隙分配公平的特点[3],但信道利用率不高,吞吐量较低。USAP协议是一种经典的动态时隙分配协议,能实现对时隙的无冲突分配且不会出现死锁[4]。但是USAP协议的帧长固定,为给全网所有节点提供足够多的可利用时隙,会出现大量未分配时隙,降低信道利用率。同时,节点申请时隙时要长时间侦听信道,导致接入延时过大[5]。FPRP协议是一种帧长固定的动态TDMA协议,采用五步握手机制,不会出现时隙浪费[6]。同时,FPRP协议解决了隐藏终端和非孤立死锁的问题[7]。但FPRP协议没有考虑节点负载不同导致时隙分配的不公平以及采用单信道通信使信道利用率过低接入时延过大。
针对FPRP协议的不足,本文提出了一种基于多信道的MC-FSHP协议,通过子网划分,提升信道利用率降低接入时延。改进FPRP协议的多跳贝叶斯算法,使其能根据负载动态调整竞争概率。对FRPR协议的帧结构进行修改,使其能扩展到多信道的环境。改进五步预留过程,提升信道利用率和降低控制开销。
本文有两个前提:
1)默认全网节点的时钟已同步,且后续入网节点会自动获取当前时间。
2)节点以半双工的模式工作,只能收或发送数据,不能同时收发数据。
2 FPRP协议概述
与固定TDMA协议对比,动态TDMA协议能根据当前网络的网络状况,不断地调整时隙分配策略,提高信道资源利用率,从而提升全网的性能[8]。FPRP协议是一种典型的动态TDMA协议,全网中的节点根据自身需求,通过一定的竞争机制来竞争属于自己的发送时隙。FPRP是动态竞争时隙的,因此其每个TMDA帧都不完全一样,灵活性很高,适用于Ad Hoc网络[9]。另外,FPRP协议具有分布式特性。整个网络中给定一个节点,这个节点进行时隙竞争的时候只考虑两跳范围内节点,而不用考虑两跳范围之外的其他节点。换言之,FPRP协议对整个网络的规模不敏感,五步预约时隙可以看作是局部的预留过程。因此,全网可以同时进行多个局部预留过程而互不干扰。五步预留的详细过程[10]在此就不再赘述。
3 MC-FSHP协议设计
FPRP协议存在着许多问题,当节点数量增加,整个协议对信道的分配效率、接入时延、竞争成功率等会迅速下降。两跳范围内节点数变多,参加竞争的节点数也会变多,则 p值变小,导致一个预约周期竞争失败的概率大幅提升。而要保证当前时隙能被某一节点竞争成功,就必须得增加预约周期。这将使整个协议对信道的分配效率大幅度降低,增加额外的接入时延。此外,为保证节点能竞争时隙发送数据,帧结构中RS的个数需要增加,这将导致信道利用率的下降。多跳贝叶斯算法中,每个节点的地位是相同的,没有考虑某些节点业务负载重而有的节点业务负载轻,每个节点参加竞争的概率是大致相同的。随着时间推移,负载重的节点缓存溢出将导致丢包。
针对上面的问题,提出了MC-FSHP协议。通过对多个信道的应用,提高信道利用率。同时,引入节点负载度,提出了新的竞争算法,调整竞争的概率 p防止节点数据不断累积,提升节点竞争的公平性。下面详细介绍MC-FSHP协议。
3.1 子网分群
MC-FPRP协议采用了基于子网划分的固定信道分配方式,当全网节点数超过的阈值时,整个网络会进行分群,分群完成后,每个子网工作在相互正交的信道上,互不干扰。每一个节点都有不重复的节点ID,并维护一跳邻节点的节点ID、工作的信道ID的路由表。初始建网完成后,每一个节点通过路由交互,获得全网的完整拓扑。选举出中心节点,由中心节点进行全网节点数统计,当节点数超过规模时,中心节点进行分群处理。如果分群消息采用广播的方式,容易造成节点接收不到分群消息。因此,中心节点采取单播的方式发送分群消息,收到分群消息的节点立即执行信道切换和子网选择。分群完成后,根据网络拓扑,选取子网交界处的节点为网关节点。网关节点除了满足子网交界处节点外还必须满足同一个子网中只有一个网关节点或者是同一个子网中网关节点超过一个时必须得相距两跳远。
3.2 MC-FSHP协议帧结构
在图1中,与FPRP协议的帧结构对比,MC-FSHP协议帧在RF中新增加了一个网关预约时隙,在IF中新增加了一个网关数据时隙,预约周期去掉了一个阶段。由于网关节点业务量大,所以在帧结构中固定分配了一个时隙给网关节点,只有网关节点才能占用RGS,网关节点发送数据时优先使用RGS。当RGS已经被占用,网关节点需要继续竞争时隙时按普通节点的方式参与竞争。
由于多信道的引入,每一个子网中的节点数量都比之前全网节点数大幅度降低。帧结构中预约时隙的数量可以减少,降低了控制开销。同时,预约周期的长度缩短,进一步降低控制开销。
分析FPRP协议的五步预留过程,可以进行优化。第四步是为了解决孤立节点死锁问题。但是在整个网络中,进行子网划分之后,出现孤立死锁的现象几率极低,就算是有节点发生了孤立死锁问题也不会对整个网络的性能造成影响。在MC-FSHP协议中,保持前三步和FPRP协议一样,对后面的进行修改。
第四步:TN节点以0.5的概率给一跳邻节点发送撤销包(Elimination Packet,EP),如果没有发送EP的TN节点收到了EP,则其变更为普通节点,在相应的时隙状态保持接受状态。TN节点的两跳领节点广播封包(Packing Packet,PP)。与TN节点相距三跳的节点通过PP分组知道其预约成功。

图1 MC-FSHP协议帧结构
3.3 基于负载的冲突解决算法
每个节点都有其缓冲数据区,设节点的缓冲数据区总容量为C,当前缓冲数据区中的数据量为Cn,则定义当前节点的负载度F为[12]

从节点负载度的定义可知,当缓冲区总容量不变时,节点负载度和节点分组产生速率成正比,即分组产生速率越大,节点负载度越大。
为进一步提升竞争的公平性,本文提出了一种基于负载的冲突解决算法(Collision Resolution Algorithm,CRA),设置最小的竞争节点nmin以及最大的竞争节点数nmax,防止nc过大或过小。算法流程如下:
Step 1:在五步预留的初始阶段,按照下面的公式设置nc。

nc1为上一轮五步预留之后的nc值,在第一个预约时隙的初始阶段,将nc1初始化为一个常量nc0。
Step 2:在第一个五步预留完成后,节点监听信道根据下面的方式对nc进行调整。
空闲:

上式中,0<k2<k1<1。
冲突:
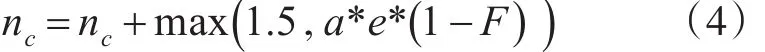
上式中,1<a<1.5,e为常数,当连续监测到冲突3次时,a=a2。
预约成功:设该节点距离预约成功的节点距离为x跳远。
x=0,即本节点预约成功。

x=1,即本节点距离预约成功的节点一跳远,退出当前时隙竞争,按下式调整nc。

x=2,即本节点距离预约成功的节点两跳远,退出当前时隙竞争,按下式调整nc。
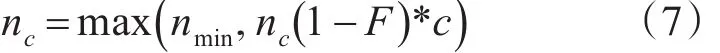
x=3,即本节点距离预约成功的节点三跳远,可以继续竞争当前时隙,按下式调整nc。
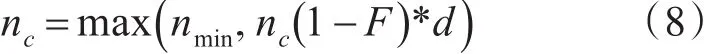
其中,0<d<1<b,c<2。
最后,节点以调整后的概率P=1/nc参加下一个时隙的竞争。
3.4 MC-FSHP整体流程
MC-FSHP协议的整体流程图如图2所示。判断节点是否为网关时隙时仅由网关节点自己判断,不会给整个网络带来额外的开销。正常情况下,网关节点的业务量大,基本不会浪费掉分配给其的固定时隙。此外,由于网关节点可以直接占用网关时隙,降低了网关节点的接入时延。

图2 MC-FSHP协议整体流程图
3.5 MC-FSHP协议性能分析
文献[13]提出,静态Ad Hoc网络拓扑图可以看成是一张图G(V ,E ),其中V表示网络中所有节点的集合,E表示网络中节点与节点之间的邻居关系集合[13]。两个相邻节点a和b,他们之间的链路用Lab表示。一跳邻节点和两跳邻节点可表示为

上式中,Oab=1表示a和b是一跳邻节点,Tab=1表示a和b是两跳邻节点。
TDMA协议的一个主要目标就是以最小的TDMA帧长实现信道的最大利用率[14]。假定一个TDMA帧一共有M个时隙,m表示TDMA帧中的第m个时隙,全网有N个节点,且规定每个节点至少能分配到一个时隙,则对于其中的一个节点i所占用的时隙可以表示为

上式中,tmi=1表示TDMA帧中的第m个时隙属于节点i。则节点i的信道利用率ρi定义为

由上式知全网节点的平均信道利用率ρ为

因此,TDMA协议主要目标可以概括为求最小的M和最大的ρ。约束条件为

以图3为例,未分子网前全网一共20个节点,经子网划分成为两个子网。
节点1、3、8、14需要发送数据参加当前时隙的竞争,节点1和3、节点1和14点是两跳邻节点,其他几个发送节点之间均为两跳外节点,节点10和节点17为子网划分后的网关节点。未划分子网前,如果要求每个节点都能分配到一个时隙,则M最小值应该为20。划分子网后,同样的要求,则M的最小值为10。节点1和节点3在未分子网前其属于两跳邻节点,不能划分到相同时隙。但是子网划分以后,其分属于不同的子网,能够划分同一个时隙而互不影响。以第四节的参数设置进行计算
FPRP协议中节点1竞争成功概率:

节点3竞争成功的概率:

同理计算MC-FSHP协议中节点1竞争成功的概率:

节点3竞争成功的概率 p13=0.25。
则从上面的简单分析可知,MC-FSHP协议实现了时隙的频域复用和空间复用[15],提升了信道利用率和节点竞争成功概率。MC-FSHP协议具体的性能将在第四节中详述。

图3 子网划分前后对比图
4 MC-FSHP协议仿真
本协议主要与FPRP协议进行仿真对比,在OPNET中,每种类型仿真均统计20次仿真结果求平均值。具体的参数设置如表1。
4.1 负载均衡时性能仿真
4.1.1 节点时隙占用率仿真
FPRP协议和MC-FSHP协议的分组产生速率均设置为 16pkt∕s∕node,MC-FSHP 协议的单个子网中的节点数不超过16个,全网中节点总数分别设置为 16、24、32、40、48、56、64。仿真结果见图 4。图4中,MC-FSHP协议的节点平均占用时隙次数明显高于FPRP协议。由对信道利用率的定义可知,平均占用时隙次数提升,则MC-FSHP协议的信道利用率得到了大幅提升。随着全网节点数量增加,平均时隙占用次数逐渐减少,但MC-FSHP协议的节点平均时隙占用次数下降的速度要慢很多。这是由于MC-FSHP协议进行了子网划分,使得单个子网中节点数不会过多,且两个节点就算是一跳邻居节点但是子网不同也能分配到同一个时隙。

表1 仿真参数设置

图4 平均时隙占用次数仿真对比
4.1.2 吞吐量和接入时延仿真
全网中节点总数设置为54个,所有节点的分组产生速率相同且逐渐提升。从图5中可知,随着分组产生速率提升,全网吞吐量迅速提升。当分组产生速率偏小时,节点负载小,FPRP协议能够很好地完成时隙分配。因此在低负载时,两种协议的差距不大。但当负载逐渐提升,MC-FSHP协议的优越性开始体现。子网划分带来更高的时隙复用率以及CAR算法比FPRP协议采用的多跳贝叶斯算法更具有公平性,MC-FSHP协议的性能与FRPP协议拉开明显差距。当分组产生速率过大时,节点的负载过大,而时隙总数有限,两种协议的吞吐量都趋于饱和。MC-FSHP协议的接入时延明显低于FPRP协议,这是因为CAR算法具有更高的竞争成功率以及更低的控制开销造成的。

图5 负载均衡时吞吐量和接入时延仿真
4.2 负载不均衡时性能仿真
全网节点数设置为54个,全网节点的分组产生速率服从[0,60]的均匀分布,仿真时间设置为60s。分组产生速率为整数,单位为 pkt∕s∕node。从下图可知,当节点负载不均衡时,MC-FSHP协议的吞吐量远高于FPRP协议而接入时延远低于FPRP协议,且吞吐量和接入时延的随时间的变化更加平稳。这是因为MC-FSHP协议采用基于负载的CAR算法,当节点负载不均衡时,更高的时隙复用率,对信道资源更加合理的分配,使MC-FSHP协议的性能达到最佳。

图6 负载不均衡时吞吐量和接入时延仿真
5 结语
本文研究、设计并仿真实现了一种多信道的MAC协议。采用子网划分,将FPRP协议拓展在到多信道,改进FPRP协议的五步预留过程,提升信道利用率,降低接入时延。提出了一种基于负载的CAR算法,节点可以根据自身负载动态调整竞争概率,保证了时隙分配的公平性,更高效地利用信道资源。本文中采用的信道划分方法比较简单,后学工作将研究更加高效的子网划分方法,以及如何动态地切换信道。
猜你喜欢
学习月刊(2022年6期)2022-12-18
沈阳航空航天大学学报(2022年3期)2022-11-08
铁道机车车辆(2021年2期)2021-05-21
沈阳航空航天大学学报(2020年6期)2021-01-27
计算机应用(2020年10期)2020-10-18
大众投资指南(2020年10期)2020-07-24
中国新通信(2019年21期)2019-03-30
青年歌声(2019年2期)2019-02-21
航天器工程(2018年2期)2018-04-24
物流科技(2017年10期)2017-11-22
