
融合上下文感知计算的协同过滤算法
2018-12-29 02:16:56杨媛媛张桂芸
天津师范大学学报(自然科学版) 2018年6期
杨媛媛,张桂芸,刘 洋
(天津师范大学计算机与信息工程学院,天津300387)
近年来,利用上下文感知进行推荐成为推荐算法研究最为活跃的领域之一,但如何利用上下文信息以及有效融合上下文信息依然是一个开放性的话题.截至目前上下文还没有一个统一的定义,很多时候需要根据具体应用系统或者用户需求引入合适的上下文类型及其具体属性[1].在基于上下文的推荐系统研究中,上下文信息有很多分类,根据上下文在推荐生成过程中所起的作用,可以将其分为3类,分别是上下文预过滤、上下文后过滤以及上下文建模[2-3].目前大多数研究都停留在上下文过滤层面,并没有有效融合上下文信息.文献[4]通过移动端传感器,利用上下文信息的预过滤,筛选用户行为上下文与音乐之间的关系,并基于此对用户进行推荐,这种方式对移动端的推荐具有借鉴意义,但泛化能力弱,难以应用到其他推荐场景中.文献[5]利用上下文后过滤进行推荐结果优化,并融合多种排序算法生成最终推荐结果,进而改善音乐的推荐效果,为融合上下文信息提供了一个很好的方向,但是该算法只停留在利用上下文信息进行过滤阶段,对上下文信息利用不充分.文献[6]在推荐过程中首先结合上下文信息进行过滤,然后对用户兴趣建模分析,提高电视平台的推荐准确率,但对上下文信息的利用只存在于数据筛选和过滤层面,没有在算法推荐过程中充分融合上下文信息.本文深入挖掘上下文信息并进行建模,针对当下应用最广泛的协同过滤算法,详细分析算法的各个环节,在传统算法的基础上进行优化,提出一种上下文感知计算的协同过滤推荐算法,算法将上下文信息与项目相似度进行融合建模,深度利用上下文信息进行推荐,在保留传统算法优势的同时,尽可能最大化融合上下文信息.本文假设相似的项目具有相似的上下文信息,因此选择在相似度计算过程中融合上下文信息,从而改善推荐精度,该算法可以在很大程度上满足用户的偏好和选择,更符合用户应时应景的需求,算法适用于非文本信息的推荐场景.以个性化音乐推荐为例,对用户及音乐的上下文信息进行分析,为用户进行个性化推荐,并在公开的音乐数据集上进行了实验.
1 相关理论基础
1.1 传统的基于项目协同过滤算法
基于项目的协同过滤算法主要分为2步:先计算项目之间的相似度,然后根据项目的相似度和用户的历史行为为用户生成推荐列表[7-8].项目相似度的度量方法主要包括3种:余弦相似性、Pearson相关系数和修正的余弦相似性[9].本文采用最经典的余弦相似度.对于项目 i和项目 j,N(i)、N(j)分别表示喜欢项目 i、j的用户集合,项目 i、j之间的相似度用 sim(N(i),N(j))表示,其计算公式为

其中:|N(i)|、|N(j)|分别为喜欢项目 i、 j的用户数(也就是对项目有过标记,打分等行为的用户数量),而分子|N(i)∩N(j)|为同时喜欢项目 i和项目 j的用户数.根据项目相似度,为用户生成最喜欢的K个项目,即生成推荐列表,步骤如下:
(1)建立用户-项目倒排表,为每个用户生成用户喜欢的项目列表.
(2)遍历用户-项目倒排表,建立项目的同现矩阵Mp×p=(mij),mij=|N(i)∩N(j)|.
(3)通过式(1)计算项目相似度,得到相似度矩阵 Cp×p.
(4)针对指定用户u,生成该用户可能最喜欢的K个项目的推荐列表,用户u对未知项目j的兴趣度puj为

其中:N(u)为 u喜欢的项目的集合,S(j,K)为和项目j最相似的K个项目的集合,rui为指定用户u对项目i的兴趣度.
1.2 上下文及上下文感知计算
上下文是一个非常宽泛的概念,在不同的研究领域有不同的定义.本文使用Dey的定义[10].上下文感知信息分为4种,包括时间、地点、天气和温度的物理上下文;用户的身份角色、社交对象等社会上下文;用户的心情、行为目标、经验、认知能力等的状态上下文;推荐信息类型(文本、图片、视频等)的交互媒体上下文[11-12].音乐数据中包含如情绪、风格、主题、年代、乐器等上下文信息.若某个数据有k个有效的上下文属性,则此数据的上下文集合可定义为
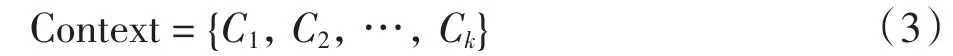
上下文Ci的离散属性取值集合为{ci1,ci2,…,cij,…}.若定义音乐数据的上下文Context={C1,C2},C1表示“主题”,C2表示“流派”,则C1的取值集合可定义为{情歌,红歌,儿歌},C2的取值集合可定义为{古典,嘻哈、摇滚}.
本文运用上下文建模方式,将项目的上下文相似度与项目相似度加权融合,虽然这种方式计算较为复杂,但对于提高项目相似度的计算精度有很大帮助,进而提高推荐算法的精度.
2 融合上下文感知计算的协同过滤算法
2.1 融合上下文相似度的项目相似度计算
本文假设项目的上下文相似度越高,则项目的相似度就越高.在音乐推荐里,设歌曲a、b、c的用户评分一样,即 sim(a,b)=sim(b,c)=sim(a,c).但若歌曲 a、c的属性“主题”为“情歌”,b的属性“主题”为“红歌”,则应该 sim(a,c)≠sim(a,b)=sim(b,c).因此本文依据项目i、j共同拥有的上下文属性值数目,计算项目的上下文相似度.假设 C(i)、C(j)分别为项目i、j拥有的上下文属性值集合,则项目i和j的上下文相似度计算公式为
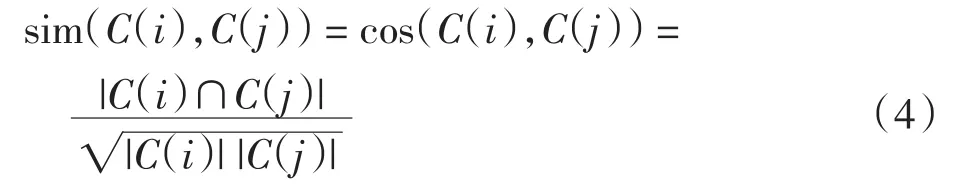
其中: |C(i)|、|C(j)|分别为项目 i、 j拥有的上下文属性值数目,分子|C(i)∩C(j)|为项目 i和项目 j共同拥有的上下文属性值数目.
引入权重因子α(0<α<1),计算融合上下文相似度的项目相似度,项目i、j的相似度计算公式为
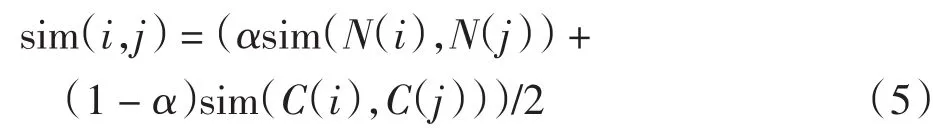
2.2 融合上下文感知计算的协同过滤算法设计思想
本文设计的融合上下文感知计算的协同过滤算法的基本步骤如下:
(1)首先建立用户-项目倒排表.遍历倒排表,填充项目的同现矩阵,同现矩阵建立之后通过式(1)计算项目的余弦相似度,同现矩阵归一化处理后记为An×n.
(2)建立上下文感知信息-项目倒排表,统计不同项目拥有的共同上下文感知信息,建立项目的上下文信息同现矩阵.利用式(4)计算项目上下文相似度,归一化之后的同现矩阵记为Bn×n,bij为项目i、j的上下文相似度.
(3)将得到的2个相似度矩阵带入式(5)计算得wij=(αaij+(1- α)bij)/2,进而得到融合上下文相似度的项目相似度矩阵,记为Wn×n.
(4)建立所有用户对项目的兴趣矩阵,记为Rn×m,矩阵值riu为用户u对项目i的兴趣度(评分),用户没有评分的项目兴趣度记为0.矩阵的列是全部用户的集合,行是所有项目的集合.
(5)遍历用户兴趣度矩阵,计算出所有用户对未知项目j的兴趣度值,通过下式计算用户u对未知项目j的兴趣度 puj:

(6)将步骤(3)和(4)的项目相似度矩阵 Wn×n和用户兴趣矩阵Rn×m相乘得到用户对未评分的项目的兴趣度,根据兴趣度值排序,得到最后的推荐结果.
3 实验及结果分析
3.1 实验数据集
实验采用的数据来自Last.fm在线音乐系统的用户行为记录,包括用户的社交信息、音乐标签、用户的聆听信息等.Last.fm数据集包含2 000位用户(user)对18 000多首歌曲(item)形成的超过105条的用户聆听纪录,以及超过1.8×105条用户对音乐的标注信息.利用这些信息生成项目相似度矩阵,矩阵维度为35 612×35 612,行和列分别是item ID,矩阵元素值为不同item之间的相似度.本文将以上用户对音乐的行为数据按照3∶1的比例分为训练集和测试集进行实验.
以下举例说明实验过程.首先建立用户-项目倒排表,将用户喜欢的所有项目及用户对项目的兴趣度值生成列表,示意数据见表1.
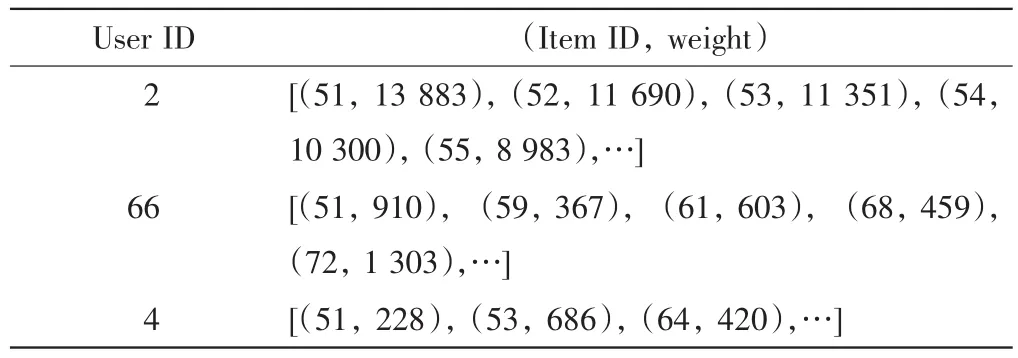
表1 用户-项目表(部分示意数据)Tab.1 User-item table(partial schematic)
遍历倒排表,建立项目的同现矩阵,如用户2对项目(51,52,53,54,55)有评分,则记同现矩阵中(51,51),(51,52),(51,53),(51,54),…的值为 1,以此类推.利用式(1)进一步处理得到相似度矩阵A.接着建立上下文感知信息-项目倒排表,示意数据见表2.

表2 上下文感知信息-项目表(部分示意数据)Tab.2 Context perception information-music item table(partial schematic data)
如项目(1324,11103,7343,5704)包含相同的上下文感知信息,则记上下文信息同现矩阵中(1 324,11103),(1324,7343),(1324,5704),(11103,7343)等的值为1,以此类推,直到遍历完倒排表中所有信息,利用式(4)处理得到上下文相似度矩阵B.然后利用式(5)进一步计算得到融合上下文相似度的项目相似度矩阵W.最后按用户分组,如根据用户2对51,52,53,…的评分记录,建立兴趣矩阵R[(51,13 883),(52,11 690),(53,11 351),(54,10 300),(55,8 983),…],通过式(6)计算用户对未知项目的兴趣度,选出兴趣度最大的K个项目作为推荐结果.
表3为音乐数据上下文感知信息的部分示意数据,其中context-aware表示item所含有的上下文感知信息,为音乐流派信息,包括音乐风格、音乐情绪等.

表3 音乐数据上下文感知信息(部分示意数据)Tab.3 Music data context perception information(partial schematic data)
3.2 评测指标
本文通过准确率评测算法的精度[10].实验结果中将改进的协同过滤算法为用户u推荐的K个项目记为R(u),用户u在测试集上喜欢的项目集合为T(u),准确率计算公式如下
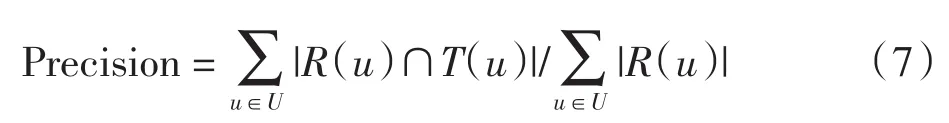
3.3 实验结果分析
算法中有2个参数需要根据实际情况进行参数调优.一个参数是用户可能感兴趣的项目数K,它是通过算法计算的用户对项目的兴趣度值进行排序得到的,由高到低取K个项目.根据经验,K最多不会超过150,因为推荐数过多会造成推荐无意义.K一般根据经验取初始值,之后在实验过程中逐步调整,使推荐算法的准确率达到最高.另外一个参数是式(5)中的α(0<α<1).在实验中通过调整参数K和α,使得推荐效果达到最优.当α=0时,算法即为改进之前的传统算法.
首先,实验中随机挑选3个用户,分析不同用户在推荐效果上产生的差异及准确率变化.之后计算整体训练集和测试集上所有用户的推荐准确率,一方面将单个用户和整体用户的推荐效果进行对比,另一方面将传统的协同过滤推荐算法和改进后的算法的推荐效果进行对比分析.
随机选取userID442、userID946和userID263,得到3个用户在不同α和K下的推荐准确率及准确率趋势图,结果分别见表4~表6和图1~图3.

表4 userID442在不同α和K下的推荐准确率Tab.4 Recommendation accuracies of userID442 underdifferent α and K %
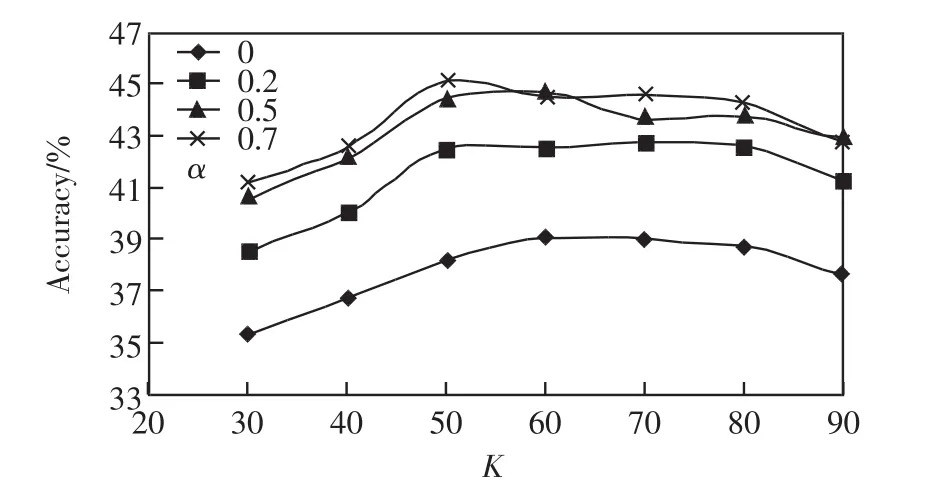
图1 userID442在不同α和K下的推荐准确率趋势图Fig.1 Trend of recommendation accuracies of userID442 under different α and K
由表4可见,α在0.5~0.7、K在60~70之间时,user442的推荐结果准确率达到最高值.由图1知,随着α的增长,推荐结果的准确率逐渐提高,因此融合上下文感知信息会提高推荐精度,但是α=0.5和α=0.7这2条准确率曲线有一部分重合,这说明只考虑项目的上下文关系或只考虑项目的用户相似性都不能取得理想的结果.

表5 userID946在不同α和K下的推荐准确率Tab.5 Recommendation accuracies of userID946 under different α and K%
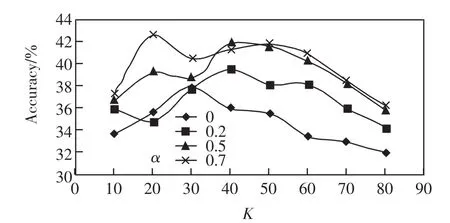
图2 userID946在不同α和K下的推荐准确率趋势图Fig.2 Trend of recommendation accuracies of userID946 under different α and K
由表5可见,α在0.5~0.7、K在20~50之间时,user946的推荐结果准确率达到最高值.由图2知,α的提高,使推荐结果的准确率得到明显增长.α在0.5~0.7之间时,准确率的曲线有部分交叉,曲线有重叠的现象,表明推荐结果的区分度不大,这个结果说明在上下文感知信息和项目相似度进行融合的时候,过分依赖上下文感知信息也不能得到很好的结果.
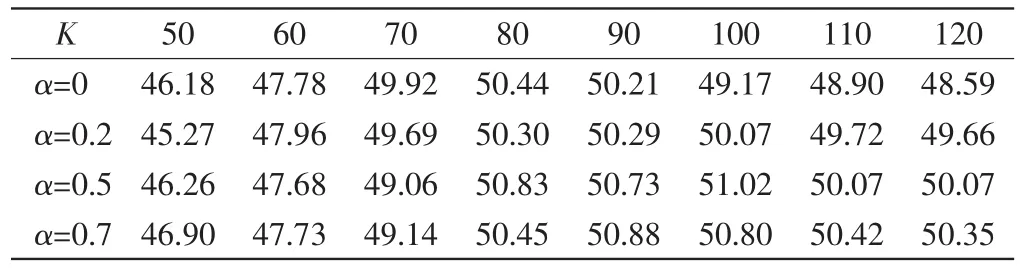
表6 userID263在不同α和K下的推荐准确率Tab.6 Recommendation accuracies of userID263 under different α and K %
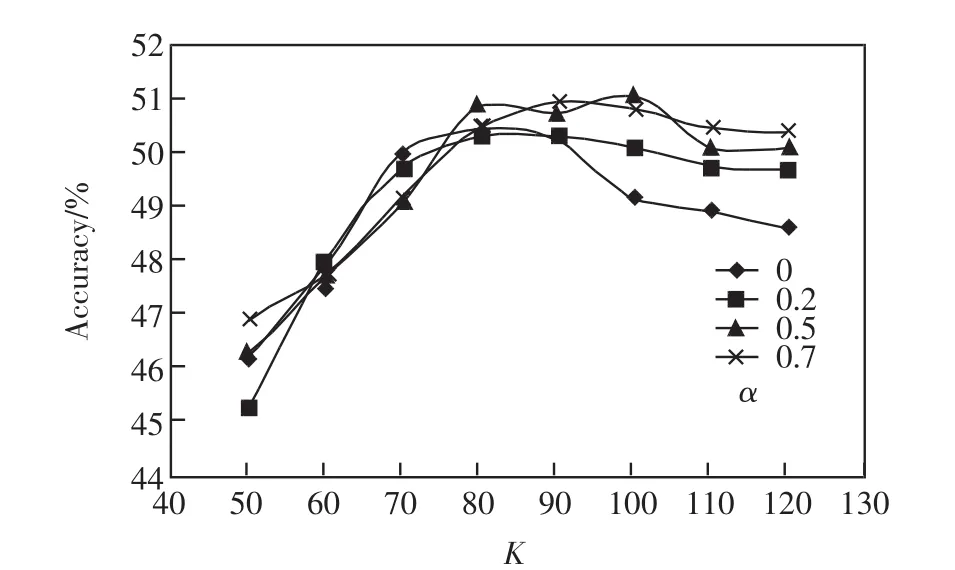
图3 userID263在不同α和K下的推荐准确率趋势图Fig.3 Trend of recommendation accuracies of userID263 under different α and K
由表6可见,α在0.5~0.7、K在80~100之间时,user263的推荐结果准确率达到最高值.由图3知,随着α的提高,推荐结果的准确率小幅增长.在不同的α值下,准确率的曲线有明显的交叉,数据重叠痕迹明显,这是因为user263的历史记录比较丰富.但随着α值的升高,依赖上下文感知信息比例的增加使准确率出现小幅增长.
在整体的训练集和测试集上根据式(7)进行准确率计算.结果见表7和图4.

表7 所有用户在不同α和K下的推荐准确率Tab.7 Recommendation accuracies for all users under different α and K %

图4 所有用户在不同α和K下的推荐准确率趋势图Fig.4 Trend of recommendation accuracies for all users under different α and K
由表7可知,针对所有用户,K在40~80之间时准确率达到峰值.由图4可见,随着α值的提升,算法的推荐准确率明显增长.但是相比α=0的情况,随着K值的变化,推荐准确率有较强的波动.α值在0.5~0.7之间时,准确率的增长不明显.从数据集整体的推荐结果来看,融合上下文感知信息确实可以提高推荐算法的精度.但是,由表7和图4也可发现,数据集上所有用户的平均准确率低于实验选出的3个用户,这是因为用户-项目数据的稀疏,有些用户的历史行为记录较少导致推荐准确率不高,进而拉低整体的推荐准确率,另外整体计算时,基数过大,也会造成推荐准确率降低.
通过对整体数据集以及不同用户的推荐结果进行分析发现,参数α在0.5~0.7,K在50~80之间时取得较好的推荐结果,而受实际数据的影响,推荐准确率随K取值的变化波动比较大,但是K的值会随着α的变化获得一个稳定的区间.综上,实验结果验证了本文提出的融合项目上下文感知信息的协同过滤算法提高了推荐准确率,并确定了参数的最优取值范围.
4 结语
在传统的基于项目的协同过滤推荐算法基础上,结合项目的上下文感知信息,对算法进行优化,并在公开的音乐数据集上进行实验,结果显示本文算法提升了推荐精度,说明算法是有效的.该算法中上下文感知信息的选取非常重要,本文重点考虑音乐数据的流派特性,之后还可以考虑融合地点及用户心情等上下文感知信息,以进一步提高推荐精度.
猜你喜欢
今日农业(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:38
现代出版(2020年3期)2020-06-20 07:10:34
中国交通信息化(2018年5期)2018-08-21 03:37:40
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
南都周刊(2015年4期)2015-09-10 07:22:44
