
由粗到精的三维等距模型对应关系计算
2018-12-27 03:23:42史纪东
重庆邮电大学学报(自然科学版) 2018年6期
杨 军,史纪东
(兰州交通大学 电子与信息工程学院,兰州 730070)
0 引 言
在2个或多个模型间,或者相邻视频帧之间建立正确的对应关系是一项非常重要的基础性研究工作[1]。对应关系在计算机图形学和计算机视觉等领域有广泛的应用,例如模型插值[2],模型属性迁移[3],模型注册[4],场景识别[5],模型匹配[6],统计模型分析[7]等。
由于三维模型是通过大量的三角网格在空间拼接构建而成,因此,计算源模型与目标模型间对应关系的过程,就可以描述为一种组合优化问题。也就是说,计算源模型与目标模型间的最优对应关系,就是在所有可能存在的对应关系集合中寻找到一组误差最小,匹配结果最理想的对应关系。在计算三维模型对应关系的过程中,等距是一个非常重要的属性,即模型在发生刚性变换(如旋转、平移和反射等)或非刚性变换(如扭曲、拉伸、缩放和折叠等)之后,模型上任意两点间的距离度量仍保持等距不变。但由于建模过程中存在的缺陷以及几何计算中存在的离散化误差,即使是针对不同姿态下的同一刚体模型,也不能保证两点间的距离度量保持完全等距不变。
由于现实世界中大多数的形变是等距的,而且具有相似语义属性的模型具有相似的度量结构,因此,在对应关系的研究工作中,有很多基于模型等距属性的研究方法。合理地利用模型的等距属性,可以简化对应关系的计算。文献[8]将测地卷积神经网络(geodesic convolutional neural networks,GCNN)应用到模型间对应关系的计算中。当模型发生等距变形时,通过定义一个基于极坐标的测地距离函数,实现对模型特征信息的提取,进而利用网络结构中的每一层对提取的信息进行训练,并通过滤波器系数对目标函数进行优化,输出最后的模型间的对应关系。然而,对于表面存在纹理特征的模型,该网络结构并不能通过训练得到理想的特征描述符。文献[9]将计算三维模型间对应关系的问题转化为计算三维网格模型上最优路径的问题。通过动态规划算法不断减小等距误差,并利用完全匹配算法得到稠密对应关系。然而,由于初始采样阶段的采样点数量不足,缺少可以表征三维模型全局特征信息的描述符,从而导致后期匹配出现对称翻转问题,降低了计算对应关系的准确率。本文旨在构建2个等距模型间的稠密对应关系,然而在利用由粗到精匹配算法计算模型间稠密对应关系的过程中,单纯依靠测地距离度量进行计算,容易受模型自身对称性的影响而产生错误的对应关系,从而在初始匹配阶段不能得到理想的稀疏对应关系。本文首先通过引入初始谱植入匹配算法,将模型植入到谱域空间来分析,并计算得到模型间准确的稀疏对应关系;然后使用空间一致采样法并结合二分图匹配算法,通过由粗到精的匹配优化过程迭代获取每一层的对应关系,即将稀疏对应关系扩展至稠密对应关系。
1 相关研究工作
由于对应关系的应用非常广泛,三维模型间对应关系的研究成为了国内外研究的热点。在众多的对应关系计算方法中,谱植入是一类比较高效的方法,它将模型从一个空间植入到另一个空间中进行分析,如莫比乌斯(Möbius)植入方法、扩展的多维尺度分析法、谱分析方法以及基于拉普拉斯算子的方法等。
基于莫比乌斯植入的研究方法[10-12]在复平面通过保角植入方法将给定的模型植入到正则坐标框架中,使用相邻最近点近似估计Möbius变换后的等距误差,但是这类植入方法只适用于完整的(没有缺失部件或空洞)三维模型间的对应关系计算,并在计算过程中对某些变量的获取方式普遍存在近似估计的问题。为了消除在植入过程中由于近似估计某些变量而导致错误对应关系的问题,Aflalo等[13]提出了基于谱空间的扩展多维尺度分析法(spectral generalized multidimensional scaling,S-GMDS)。利用S-GMDS算法避免了传统植入过程中存在的非凸性情况,更好地提取了三维模型的结构特征信息,实现了三维模型的准确谱植入,计算得到了理想的对应关系。然而,该算法仍存在2个缺点:①当源模型与目标模型的尺度不一致时,该算法缺少尺度比例参数,无法计算得到模型间正确的对应关系;②由于S-GMDS算法是基于测地距离度量的计算。因此,当三维模型表面出现拓扑噪声时,需要引入扩散距离度量或者通勤时间距离度量对测地距离度量进行替换,以增强S-GMDS算法在部分模型(即模型存在缺失部件或空洞等)与完整模型之间的对应关系计算的健壮性。文献[14]提出了基于极点谱植入初始化的贪婪优化算法。通过基于高斯曲率的最远点采样算法获得采样点,利用基于全局度量(测地距离)的贪婪优化算法进行迭代优化,从而构建出三维等距模型间的稀疏对应关系。但是该算法构建对应关系时也会受到模型自身对称性的影响。2016年,杨军等[15]提出了一种基于热核描述符与波核描述符的融合特征描述符。通过计算三维模型的Laplace算子获得模型的特征向量和特征值,将所得到的特征值和特征向量作为基参数,分别计算源模型与目标模型的热核签名和波核签名,并将热核签名与波核签名融合为一个新的特征描述符,最终通过最小值匹配算法得到源模型和目标模型之间的对应关系。与单一使用热核签名或波核签名特征描述符相比,得到了更加准确的对应关系。但是,针对存在缺失部件或空洞的模型,该算法不能构建出准确的对应关系。
此外,利用模型的局部信息构建模型间的对应关系,也是一种广为应用的计算方法。特别是当模型发生非等距变换的时候,模型局部信息是一个很重要的属性,例如模型上每个顶点的高斯曲率。然而,当模型局部几何结构发生比较大改变的时候,单纯利用模型的局部几何信息来计算对应关系,往往得不到理想的结果。文献[16]研究在2个三维非等距模型间,构建源模型与目标模型上相同部件之间的对应关系。使用了特征函数分别对源模型与目标模型建立亲和度矩阵,利用亲和度矩阵分别定义源模型与目标模型上2个相同部件的稳定性参数,并利用该参数计算源模型与目标模型相同部件之间的对应关系。然而,特征函数计算出的匹配效果依赖于2个阈值参数,如何获取最优的阈值参数,算法还需要进一步改进。文献[17]利用照相机从不同角度对三维模型进行拍照,得到多角度多尺度的二维视图数据,利用深度卷积网络对二维视图数据进行训练,从而得到三维模型的局部特征描述符,根据局部特征描述符实现对模型间对应关系的计算。然而,该算法在计算部分模型与整体模型间对应关系时,对于残缺部件较多的部分模型,不能得到良好的模型间对应关系。
构建模型间的对应关系,还可以通过所计算的对应关系的稀疏度进行分类,有稀疏对应关系和稠密对应关系。Yusuf Sahillioglu等[18]利用EM算法,根据测地距离获取初始采样点,对模型进行谱植入操作并对齐,得到初始对应关系,最后利用贪婪优化算法对初始匹配结果进行优化,但该算法只能实现稀疏的对应关系计算。文献[19]在欧式空间使用测地距离计算三维等距模型的稀疏对应关系,通过由粗到精的迭代采样算法(coarse-to-fine,CtoF)和组合匹配算法,将源模型与目标模型之间的稀疏对应关系扩展到稠密对应关系。但是使用测地距离描述符计算对应关系,不能充分地描述模型上各个部分的更多细节特征,因此,在初期稀疏匹配阶段和后期稠密匹配阶段会出现对称反转的问题,从而导致匹配错误。
为了能够获取分布更为一致的采样点,提高对应关系的计算准确率。本文在文献[18-19]的基础上提出了一种基于初始谱植入计算三维等距模型稠密对应关系的方法。主要创新点和贡献:①在获取采样点的过程中,计算所有顶点的高斯曲率并进行排序,利用基于曲率的均匀一致采样策略(curvature-oriented evenly-spaced sampling,COES)对源模型与目标模型采样,这样获取的采样点更具代表性,能更好地反映模型的突出特征;②在初始匹配阶段,提出了以初始谱植入构建模型间稀疏对应关系的方法,避免了由于三维模型自身固有的对称性而导致错误的对应关系,减小了对应关系的等距误差,使稠密对应关系的正确率得到明显改善。
2 EM框架
在计算2个模型间对应关系的过程中,当完成采样工作以后,需要对源模型与目标模型上的采样点进行匹配,如何在不同的组合排列中寻找到最理想的一组对应关系,是一个十分关键的问题。本文将等距误差作为计算对应关系的依据,即等距误差最小化。
计算等距误差最小值的问题可以描述为计算似然概率的最大值问题,即
§|X,Q)
(1)
(1)式中:X=(S,T)表示基本输入数据,S和T分别为源模型与目标模型上的采样点集合;Q是一个矩阵,用qij表示矩阵Q中的元素,表示从源模型上的采样点si到目标模型上对应的采样点tj的匹配概率,因此qij之和为1;§表示源模型与目标模型之间的一组对应关系。由于本文的研究内容是计算2个等距模型之间的稠密对应关系,因此,对于源模型中的每个采样点,通过计算都会与目标模型中相应的采样点对应起来。
大量实验表明,期望最大化方法(expectation maximization,EM)可以较好地应用于计算似然函数最大化的问题。本文实验中,分别用§(k)与Q(k)保存§与Q在每一次迭代计算中的结果。从Q(0)开始,通过E步与M步可以计算出每一次迭代得到的矩阵Q(k)与对应关系§(k),直至Q(k)与§(k)的计算结果趋于收敛。E步和M步的计算如下
E-step:
Q(k)=E(Q|X,§(k-1))
(2)
M-step:

(3)
利用Gibbs分布函数可以计算出源模型上采样点si与目标模型上采样点tj之间对应关系的概率,即等距误差为
(4)
(4)式中:β是用来表示采样点离散程度的常数;Ti是归一化的常量;diso(si,tj)表示si与tj的等距误差,计算公式为
§(k-1))=
(5)
利用(5)式的计算结果,代入Gibbs分布函数,即(4)式,可得
(6)
根据计算得出的每一组对应关系的概率qij,将计算结果代入(3)式,计算似然函数最大值
(7)
结合(6)式和(7)式即可得到对应关系
(8)
要想获得最理想的对应关系,就必须在所有可能存在的对应关系集合中寻找到一组等距误差最小的对应关系。(7)式为似然函数,(8)式由(7)式推导得出,计算(7)式的最大值问题就转化为计算(8)式的最大值问题。由于(8)式中第一项为常量,对计算最大值没有影响,因此,舍弃第一项。第二项是负值,要想计算(8)式的最大值,也就是求出负号后边那一部分的最小值,即计算得到似然函数最大值,也就计算得出了等距误差值最小值。从而由(8)式推导得出(9)式。因此,计算得到模型间一组等距误差最小的对应关系,即计算得出似然函数最大期望值。

(9)
从初始阶段Q(0)开始, EM算法根据每次计算得到的结果§(k-1),迭代k次,利用(10)式计算等距误差的最小值,即可得到初始匹配阶段最理想的对应关系§(k)。

(10)
3 COES采样
基于曲率的均匀一致采样策略COES是一种依据三维模型各顶点高斯曲率数值大小进行均匀采样的方法。该方法首先计算模型的表面积,然后计算采样半径r,最后根据模型上各顶点的高斯曲率并结合半径r进行采样。半径r的计算公式为
(11)
(11)式中:A表示模型的表面积;r(k))表示第k层的采样半径;A(k-1)表示第k-1层中根据最大半径计算得到的采样区域的面积。COES采样方法的具体步骤如下。
步骤1计算模型上每一个顶点的高斯曲率,并且记录每一个顶点的索引值。
步骤2根据三维网格模型的点、线、面基本数据信息,计算模型上每个三角网格的面积,并进行求和运算以得出三维网格模型的表面积。
步骤3根据(11)式计算采样半径。
步骤4利用插入排序算法对各顶点高斯曲率值按从大到小进行排序,与此同时,更新顶点的索引值排序。将高斯曲率值最大的顶点作为初始采样点s1,并将顶点状态设置为已访问,然后结合半径r开始采样。以s1为起始点,遍历与其相邻的所有顶点,当发现存在未被访问的顶点时,将其作为新的起始点,并设置其状态为已访问,然后开始遍历该新起始点的所有邻接点,这样又会得到新的起始点。在遍历的过程中,从上一个起始点到确定新的起始点,是一个由内向外不断发散的动作。在此过程中,将遍历过的两两顶点之间的路径长度进行累加,并与半径r进行比较,当该路径长度大于等于半径r时,停止该路径的计算,从s1开始探索新的路径。直至以采样点s1为圆心,长度r为半径的圆内所有的顶点都已访问,即完成了围绕该采样点的计算任务。
步骤5从排序好的顶点列表中从上至下选取第2个未被访问的顶点作为第2个采样点,结合采样半径r继续进行采样。以此类推,直至三维模型上所有顶点都已访问,即完成M个采样点的选取。根据大量实验测定,M的取值与三维模型的表面积相关联,一般在4~6,本文设定M=5。图1是利用不同采样半径得到的COES采样结果。对于不用的采样点,包括落在以r为半径的圆内的其余顶点,使用不同的颜色进行标记。其中,图1a的采样半径为r=1.842 17E-005,图1b采样半径为r=3.223 8E-005。

图1 不同采样半径下的COES采样结果Fig.1 COES results under different sampling radius
在文献[20]中,对于第2个采样点的选取,不是按照从上至下将未访问的第2个顶点作为下一个采样点,而是采用了随机选择的策略。按照该策略进行采样,源模型与目标模型上的采样点就会随机分布于模型上的表面上,不同采样策略下的COES采样结果如图2所示。图2a是根据文献[20]得到的采样点结果,可以明显地看出,采样点分别分布于猩猩模型的腹部,背部,手臂关节处,只有一个采样点分布在猩猩模型的手指上,因此,采用这种采样点获取方法会降低对应关系匹配的正确率。而本文选取采样点策略的优势是,将高斯曲率数值大小作为采样依据,在源模型与目标模型上尽可能得到分布一致的采样点,从而有利于提高对应关系计算的正确率。图2b是根据本文算法得到的实验效果,可以看出,在猩猩模型的左爪与右爪的指尖上分别获得一个采样点,还有一个位于猩猩的脚趾上,其余2个也都位于特征明显的部位,因此,本文的采样点获取策略可以在模型上得到更具有代表性的采样点,从而可以提高对应关系计算的正确率。
4 初始匹配
在由粗到精的对应关系计算过程中,初始阶段的对应关系匹配效果对后期的多层匹配具有重要的意义。由于三维模型自身固有的对称性,往往会导致初始阶段的匹配效果不佳,进而影响后期的多层匹配,致使计算出的对应关系存在较多错误。因此,如何在初始阶段计算得到较好的稀疏对应关系,是本文研究的重点内容。
初始匹配的计算步骤如下。
步骤1使用Dijkstra算法计算任意2个采样点之间的测地距离g(si,tj),并计算出Uij作为测地亲和度矩阵的元素。
Uij=exp(-g2(i,j)/2σ2)
(12)
(12)式中,σ表示模型表面上最大的测地距离长度。
步骤2利用计算出的测地亲和度矩阵,通过多维尺度分析法(multi-dimensional scaling,MDS)将源模型与目标模型上的采样点集合分别植入到H维空间中。
步骤3在植入的过程中,尽管对源模型和目标模型都进行了相同的植入变换运算,但是由于植入过程中存在可能任意翻转的情况,从而会导致在植入空间出现采样点分布不一致的情况,因此,需要进行2H次对齐计算,才能获取最优的对齐结果Cm。
(13)
(13)式中:ti表示在植入空间中目标模型上的采样点;|sm|表示在植入空间中源模型上采样点的个数,其中,m表示在植入空间中源模型上每个采样点的邻接点个数。
步骤4由于在植入空间中,模型上任意2点间的欧氏距离近似等于原始三维空间中的测地距离,因此,可将测地距离作为欧氏距离的近似值,在植入空间中计算得到相应采样点的等距误差,从而减少时间消耗。
(14)
步骤5利用二分图匹配算法得到初始阶段的对应关系。
图3为利用本文的初始谱植入算法构建的猩猩模型间的初始稀疏对应关系,用黑色实线表示。

图3 猩猩模型初始匹配阶段的稀疏对应关系Fig.3 Initial sparse correspondence between gorilla pairs
5 稠密对应关系计算
构建2个模型间的稠密对应关系,是以初始匹配阶段构建的稀疏对应关系为基础。本文计算稠密对应关系采用分层迭代的思想,每一层包含采样、对应关系计算、优化等3个步骤。其中,层数参数通过手动进行设置。具体计算步骤如下。
步骤1计算采样点。根据初始匹配阶段的采样点依次计算出源模型上M个(目标模型上为M′个)采样点的圆面积,利用最大面积的数值更新采样半径r,并保存面积最大的采样点si,tj(1≤i≤M,1≤j≤M′)的索引值。从采样点si,tj开始,结合半径r,分别计算出围绕si,tj的M和M′个新的采样点。以此类推,计算出其余新的采样点。
步骤2计算对应关系。分别计算以si,tj采样点为中心,以r为半径的圆内的M个和M′个新的采样点的对应关系。在计算的过程中,使用组合排列的思想,针对每一个圆内的采样点进行匹配。将源模型的M个基点排成一列,目标模型上的M′个基点排成一列,它们之间共有C(M,M′)M!种组合方式。分别计算源模型上的第1个采样点到目标模型上的所有采样点的等距误差,将等距误差数值最小的对应关系保存下来。继续计算源模型的第2个顶点到目标模型上的所有采样点的等距误差,仍然将等距误差数值最小的对应关系保存下来。以此类推,即可从C(M,M′)M!种组合方式中计算出一组对应关系。至此,以si,tj采样点为中心的对应关系计算完毕,继续计算剩余采样点中的新的对应关系。
步骤3修正并进行优化。因为步骤2计算得到的结果并不完全正确,对于其中存在错误的对应关系,需要对其进行修正。文中首先对该层次计算得到的所有的对应关系重新排列,然后使用贪婪优化算法进行修正以达到优化的目的。对于(si,tj),如果存在diso(si,tm) 图4表示第k-1层的对应关系计算过程。由图4可知,在分别以si,tj为圆心的阴影区域内,计算得到源模型上M个(目标模型上为M′个)采样点,然后使用组合匹配算法计算M与M′个采样点之间的对应关系,待该层所有采样点对应关系计算完毕,使用贪婪优化算法对其进行优化。图5表示第k层的对应关系计算过程。从k-1层到k层,首先更新采样半径;其次利用更新后的半径,计算得到以si,tj以及在第k-1层已经存在的采样点(图4中黑色实心圆采样点)为圆心的区域内的第k层的采样点(图5中方形采样点);然后使用组合匹配算法分别计算源模型与目标模型间每一个圆内的采样点的对应关系;最后使用贪婪优化算法对其进行优化。全部层数计算结束后,即得到了源模型与目标模型间的稠密对应关系。通过这种方法,将全局问题转化为局部问题,分层次求解,不仅保证了对应关系计算的准确率,而且提高了计算的效率。 图4 计算第k-1层对应关系Fig.4 Calculation of the k-1th level shape correspondences 本算法在Microsoft visual studio 2012下,结合图形用户接口程序OpenGl编程实现。选择TOSCA模型库中的三维网格模型对文中算法进行了验证,并与文献[19]的方法进行了对比。针对具有相同顶点数和三角网格数的同一类模型,构建点点匹配关系来衡量上述2种算法的对应关系计算结果的正确性。 图5 计算第k层对应关系Fig.5 Calculation of the kth level shape correspondences 分别利用基于测地距离度量的算法[13]和基于谱植入的算法(本文算法)构建了TOSCA模型库中猫模型、猩猩模型、人体模型和跳芭蕾的女演员模型的初始匹配阶段的稀疏对应关系,分别如图6~图9所示。在初始匹配阶段,根据COES算法分别在源模型与目标模型上获得5个初始采样点。图6~图9中,实线表示采样点间正确的对应关系,虚线表示采样点之间错误的对应关系。可以看出,由于三维模型自身的对称性,导致使用测地距离度量进行初始对应关系计算时产生了错误的对应关系。在图6a的猫模型中,源模型的右后腿上的采样点对应到了目标模型的左后腿上;在图7a的猩猩模型中,源模型右爪上第2个指尖上的采样点对应到了目标模型的右爪上第3个指尖上;在图9a的跳芭蕾的女演员模型中,源模型胳膊上的采样点对应到了目标模型头部的采样点。而本文算法通过初始谱植入算法,并结合测地距离,在M维植入空间中构建初始稀疏对应关系。可以看出,本算法较好地解决了在初始匹配阶段由于模型自身对称性影响对应关系计算的问题,构建出了完全正确的初始稀疏对应关系,如图6b,7b,8b和9b所示。 图6 构建猫模型的初始对应关系比较Fig.6 Comparison of initial correspondences between cat pairs 图7 构建猩猩模型的初始对应关系比较Fig.7 Comparison of initial correspondences between gorilla pairs 图8 构建人体模型的初始对应关系比较Fig.8 Comparison of initial correspondences between human pairs 图9 构建跳芭蕾的女演员模型的初始对应关系比较Fig.9 Comparison of initial correspondences between ballerina pairs 图10~图13分别表示猫模型、猩猩模型、人体模型和跳芭蕾的女演员模型在稠密匹配阶段产生的稠密对应关系。在图10~图13中,a图表示基于测地距离的算法[19]计算得到的实验结果;b图表示基于初始谱植入算法(本文算法)得到的实验结果。在图10~图13中,实线表示采样点间正确的对应关系,虚线表示采样点间错误的对应关系。本文在完成初始匹配计算后,继续对每组模型分层迭代计算5次,得到最终的稠密对应关系,每组模型间的对应关系个数在500~700。可以看出,在图12a构建的模型间的对应关系中,明显可以看出,存在从源模型右手臂上的采样点到目标模型右腿上的采样点的错误的对应关系,以及在腿部存在因模型对称性引起的错误对应关系。在图12b中,虽然在源模型与目标模型的脚上存在一处明显的错误的对应关系,但是,较图12a对应关系的正确率得到了显著提升。在图13a 2个跳芭蕾女演员模型的对应关系中,存在多处由源模型右手上的采样点对应到了目标模型的左脚上的采样点的错误对应关系。在图13b中,这种现象得到了明显的改善,根据实验数据统计,图13b中的错误对应关系的数量较图13a中的错误对应关系数量减少了1/3。由图10,图11的实验结果同样可以看出,本文提出的基于初始谱植入的计算方法依然优于基于测地距离的计算方法。 图10 计算猫模型的稠密对应关系比较Fig.10 Comparison of dense correspondences between cat pairs 图11 计算猩猩模型的稠密对应关系比较Fig.11 Comparison of dense correspondences between gorilla pairs 图12 计算人体模型的稠密对应关系比较Fig.12 Comparison of dense correspondences between human pairs 图13 计算跳芭蕾的女演员模型的对应关系比较Fig.13 Comparison of dense correspondences between ballerina pairs 表1为本文算法与文献[19]算法的等距误差的比较,分别对比了初始匹配阶段与稠密匹配阶段的等距误差,根据等距误差可以衡量模型间对应关系的正确率。可以看出,与文献[19]相比,本文算法在初始匹配阶段与稠密匹配阶段的等距误差均有明显减小,因此,能够得到更为准确的对应关系。 表1 2种方法计算的模型间等距误差的比较 模型间对应关系问题是计算机图形学和计算机视觉领域的一个基本问题,更是一个难点问题。本文提出了以初始谱植入构建的稀疏匹配为基础,利用COES采样方法和组合匹配算法迭代计算三维等距模型间稠密对应关系的算法。实验结果表明,本文算法与文献[19]算法相比,在基本没有增加时间开销的基础上,减小了模型间对应关系的等距误差,使对应关系正确率在一定程度上得到了提高。然而,本文算法仍然存在改进的空间。一方面,稠密匹配阶段采样半径的初始化。考虑到计算稠密对应关系的时间成本,本算法采用手动设置采样半径的方式,因此,如何自动获取最优的初始采样半径,仍然需要进一步探索;另一方面,对于模型自身的对称性,以及模型构建过程中存在的瑕疵等,都会影响对应关系计算结果的准确率,因此,仍需要进一步探索对这些不良因素的处理方法。此外,解决更为广泛的模型间对应关系问题,例如语义相似的模型之间的对应关系、部分模型(缺少某个部件或存在空洞等)与完整模型之间的对应关系等,也是今后要继续研究的问题。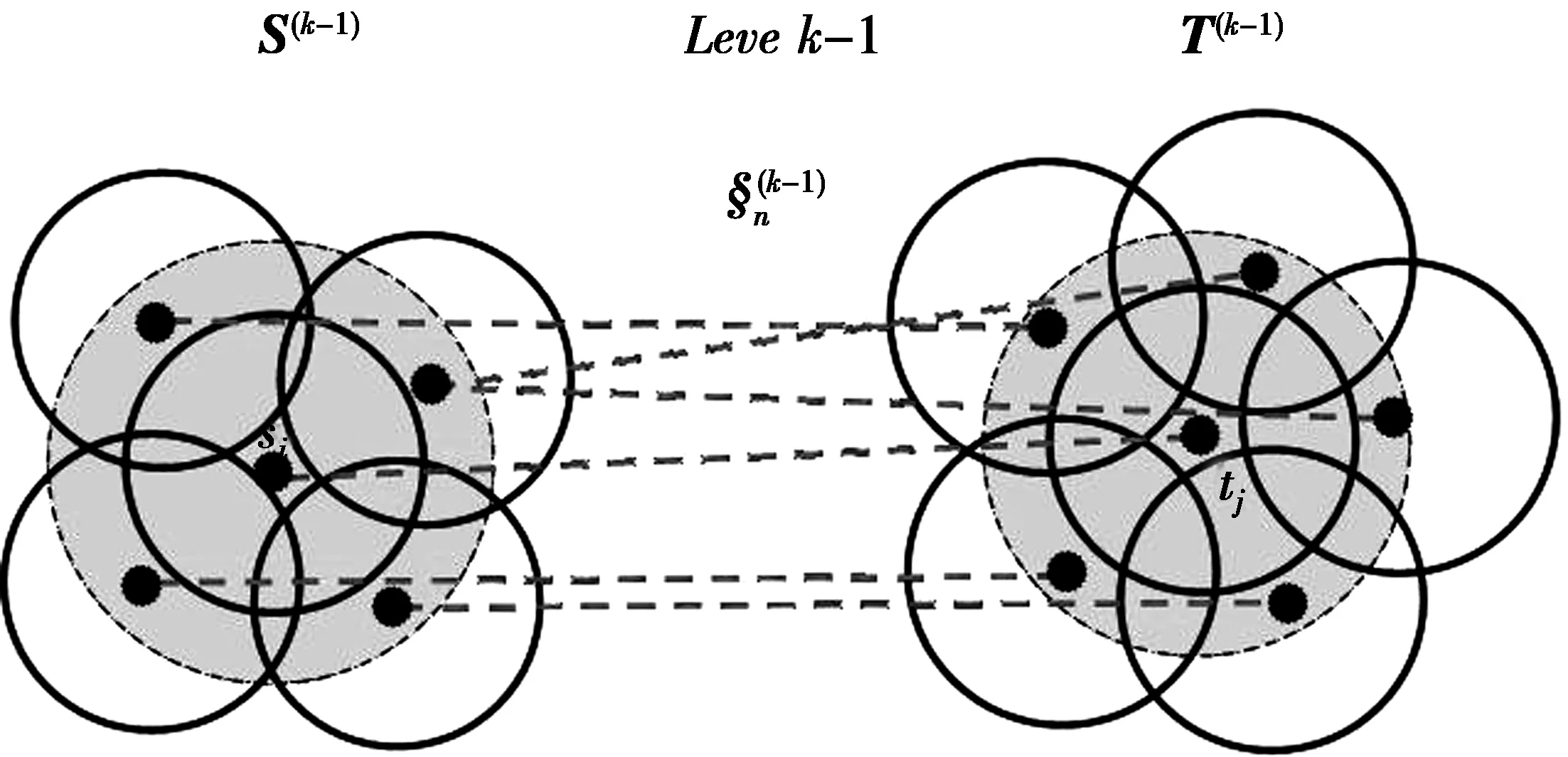
6 实验结果与分析










7 结束语
猜你喜欢
数学物理学报(2020年6期)2021-01-14 01:00:26
哈尔滨轴承(2020年2期)2020-11-06 09:22:26
今日中国·法文版(2020年7期)2020-07-04 02:53:48
制造技术与机床(2019年6期)2019-06-25 10:17:18
中国特种设备安全(2019年1期)2019-03-13 01:06:26
华东师范大学学报(自然科学版)(2017年1期)2017-02-27 13:41:05
数学物理学报(2016年3期)2016-12-01 05:36:26
山东青年(2016年2期)2016-02-28 14:25:41
中国海上油气(2015年3期)2015-07-01 16:32:08
中央民族大学学报(自然科学版)(2015年1期)2015-06-11 02:56:40
