
基于多架构混搭模式的极地海洋数据库建模技术研究
2018-12-25 11:04:12宋晓梁建峰李维禄苗庆生韩璐遥韦广昊
极地研究 2018年4期
宋晓 梁建峰 李维禄 苗庆生 韩璐遥 韦广昊
(国家海洋信息中心, 天津 300171)
提要 通过对极地海洋数据的特征及应用需求分析, 基于“一种架构支持多类应用”的传统数据库模式已无法满足需求, 本文提出采用“多种架构支持多类应用”模式的数据库设计理念, 通过研究极地海洋数据分类分层管理体系, 开展极地海洋原始数据层、基础数据层、综合数据层、成果数据层的存储管理机制、数据库体系架构设计、数据库模型设计等关键技术研究, 开发数据库查询检索功能, 满足用户对极地海洋数据的多样化查询检索、空间可视化展示、关联分析等需求, 实现极地海洋数据的有效存储、高效应用和开放共享。
0 引言
目前极地海洋数据获取已呈现出全时空覆盖、综合性观测、常态化调查以及局部精细化补充调查的新局面, 各个国家已经推出新的海洋观测/监测/调查计划, 包括 Argo、海王星、OOI、GOOS、IOOS等多个观测计划[1-5], 并发射了多颗海洋观测卫星[6-8], 通过卫星遥感、各类浮标、雷达等新型观测手段, 提升了极地数据获取能力。
目前国内针对极地数据存储管理, 通常采用单一的数据库技术进行数据库建模, 但是面对多源、异构、多模态、数据量大且动态增长等特征的极地海洋数据[9-10], 利用单一的数据结构组织存储方式进行处理管理, 只能实现简单的数据管理, 数据利用率及可视化程度都较低, 难以满足用户多样化的数据查询检索、高性能计算、综合分析、关联分析、聚类分析等应用需求。
随着数据库技术的发展, 针对结构化、非结构数据库应运而生, 比较常见的有以 Oracle、SQLServer为代表的事务型数据库, 以Greenplum、Gbase 8a为代表的高性能并行数据库, 以Hadoop为代表的非结构化数据库, 目前我国 IT、金融、公安等行业针对不同数据类型、业务专题, 采用“OldSQL+NewSQL”或“OldSQL+NoSQL”等混搭模式的尝试, 取得了良好效果。本文针对极地海洋领域, 首次提出“OldSQL+NewSQL+NoSQL”混搭模式的数据库存储方式应用到极地海洋领域,面对非结构化数据、时间序列数据、空间数据等多类型的极地数据, 针对存储、管理、分析、应用、服务等应用分析需求, 开展数据库模型设计与关键技术研究。
本文利用多源数据模型建模技术, 通过数据结构模型、组织模型、存储模型和业务模型等模型的构建, 对多类型极地数据按类别分别实现数据的分类与分层设计, 针对不同层次数据库开展不同应用模式的数据库架构设计, 实现基于OldSQL结构化基础数据库技术的面向极地海洋结构化标准数据集的数据库设计与建模方法研究,基于NewSQL并行数据库技术面向结构化极地海洋大数据的综合数据智能分析、数据均匀分布策略与数据检索技术研究, 基于 NoSQL非结构化数据库技术的面向非结构化极地海洋数据的多级索引技术研究。
1 极地海洋数据库的构建
1.1 极地海洋数据库总体架构
采用“OldSQL+NewSQL+NoSQL”混搭模式的数据库存储方式开展极地海洋数据库的设计与实现(图1)。其中, 事务型数据库系统主要面向原始数据和基础数据层, 针对极地海洋元数据、空间数据、基础业务数据, 通过事务处理引擎、时间序列引擎、空间数据引擎和高可用解决方案构建极地海洋结构化基础数据库; 分布式并行数据库系统主要面向综合数据层, 采用列存储分布式并行数据库集群构建,为超大规模数据管理提供高性能计算、综合分析平台, 为各类海洋数据分析与计算等提供支持; 非结构化Hadoop数据库系统主要面向成果数据层, 针对需要分析利用文本、音视频文件、时间序列等非结构化数据, 建立Hadoop数据库, 实现非结构化数据的关联分析、聚类分析、深度学习等应用研究。

图1 极地海洋数据库总体架构设计Fig.1.The overall architecture design of polar marine database
1.2 极地海洋数据分类设计
极地数据来源丰富, 且各类来源获取的数据类型、数据频率、获取方式均存在差异, 通过分析不同数据来源特点, 对开展极地数据库设计具有指导性作用。极地数据按获取来源可分为: 对地观测数据、地基观测/监测数据、极地考察数据和计算模拟数据。
1.2.1 对地观测数据
主要包括长期走航重复断面业务化观测数据、重点区域定点阵列式观测数据、空间地理测绘及卫星遥感观测数据等。
1.2.2 地基观(监)测数据
主要包括陆地生态环境观(监)测数据、冰川环境观(监)测数据、空间环境综合监测数据等。
1.2.3 极地考察数据
极地考察数据是通过极地航次任务采集获取的数据, 根据考察计划定期更新数据, 可按照极地考察航次进行分类, 实现所有航次考察数据的管理。
1.2.4 计算模拟数据
通过统计分析、数值分析、计算模拟等手段进行数据处理, 得到的数据。
1.3 极地海洋数据分层设计
按照数据来源、数据处理层次、应用系统设计角度对极地数据进行分层设计, 将极地数据分为: 原始数据层、基础数据层、综合数据层和成果数据层, 可满足不同人员、不同业务领域、不同研究目标的需求。
1.3.1 极地海洋原始数据层
原始数据是指采用南北极陆-海-空观(监)测平台、北极陆-海-空观(监)测平台和极地考察等手段, 获取得到的极地冰川[11-13]、极地海冰[14]、极地物理海洋[15]、极地气象[16-17]、极地大气空间物理[18-19]、极地地质[20]、极地地球物理[21]、极地化学[22-23]、极地生物生态[24-27]、极地遥感[28]等原始资料。
1.3.2 极地海洋基础数据层
基础数据层是指针对极地原始资料按照资料来源、学科类型进行定向分类整理, 开展数据校验、重复性检查、数据解码和质量控制等标准化处理, 形成的标准数据文件。
1.3.3 极地海洋综合数据层
综合数据层是指针对多源异构标准数据集,按照学科类型、获取方式, 进行格式统一、标准统一、基准统一、计量单位统一、综合排重等整合提取转换, 以及时空维度排序、衍生参数计算、数据订正等处理, 将同类学科/要素、相同获取方式资料按照方区或时间维度进行组织存放, 形成综合数据层。
1.3.4 极地海洋成果数据层
成果数据层主要包括数值型产品和图形产品,是指针对极地标准化数据进行制作加工形成的极地表面冰流速矢量图、海冰密度专题图、极地高空物理图集、极地地形图、极地地球物理剖面图、极地重力异常图、重力基底深度图、极地岩系分布地质图、水深地形图、极地影像产品等。
2 数据库建模
2.1 OldSQL数据库建模
OldSQL关系型数据库主要包括元数据库、空间数据库和基础数据库。本文中OldSQL关系型数据库采用Oracle 12g版本进行数据库设计与实现。
2.1.1 元数据库设计建模
1.元数据库概念设计
极地海洋原始数据库面向极地海洋数据管理人员, 基于元数据导航方式进行管理, 按照数据来源、学科、可公开程度等内容开展数据的归类和整理, 开展原始数据库中各类文件清单表、清单索引表、表关联关系等模型设计。通过元数据库与原始极地文件建立一一对应关系, 实现原始数据文件的溯源和快速查询。
2.元数据库逻辑设计
元数据库主要记录了资料的汇交过程信息和在资料库中的基本管理信息, 是基于模型设计针对字段名称、字段类型、字段长度、主外键等内容开展的数据库表结构设计。元数据的要素主要包括: 元数据标识、元数据标题、航次名称、任务名称、学科类型、观测仪器、搭载平台、内容摘要、接收时间、空间范围、文件数、数据量、资料接收人、汇交单位、载体形式、密级、存放路径等, 极地考察元数据逻辑设计图, 如图2所示。
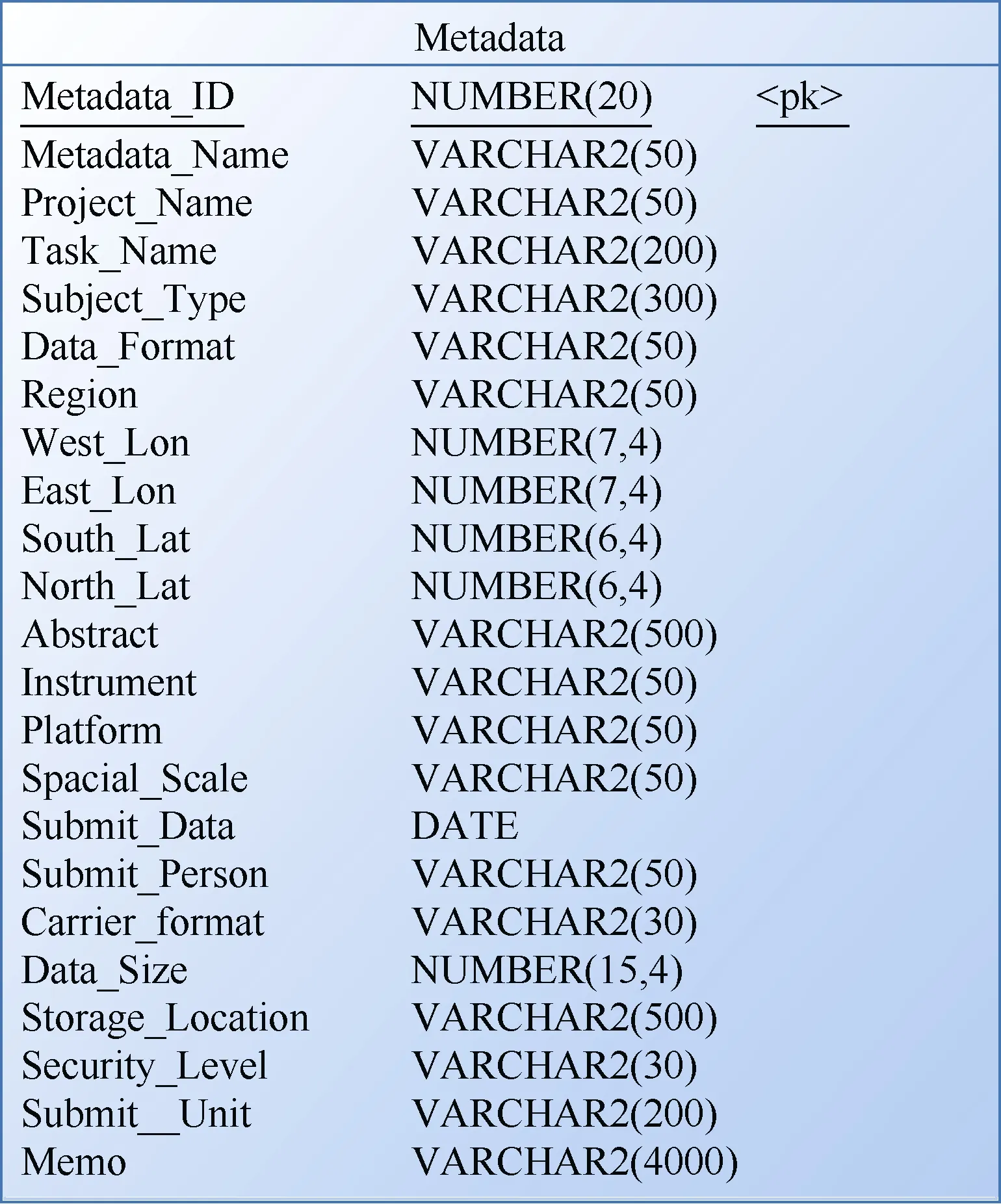
图2 元数据库逻辑设计图Fig.2.Metadata database logic design diagram
2.1.2 基础数据库建模
基础数据面向极地海洋数据管理人员, 基于业务信息(如项目、航次等)对极地海洋要素进行组织和管理, 要建立数据、航次、设备、时间、空间之间的关联关系, 数据具有以行为单位, 二维数组表现、强调数据的最小冗余度和最大一致性约束等特点, 所以基础数据库采用 OldSQL结构化数据库设计实现。
1.基础数据库概念设计
根据航次、设备类型、学科类型、资料类型、资料格式、数据观测频率、数据传输频率等设计数据库结构, 对海洋各类数据进行概念上的抽象和表达, 用各种对象表示数据内部实体间的关系,确定各个对象、属性之间的相互联系和约束。
2.基础数据库逻辑设计

图3 基础数据库逻辑设计图Fig.3.Basic database logic design diagram
2.1.3 空间数据库建模
空间数据库主要用于存储空间特征的矢量、栅格、电子地图等极地海洋地理信息数据, 传统基础数据库(业务数据)的组织与管理无法满足基于空间特性的极地海洋信息的空间检索、分析和可视化等功能,所以采用空间数据库技术, 根据数据空间特性开展数据要素的组织管理, 实现面向网格的、大数据量的空间信息提取、分析、可视化和数据挖掘等功能[31-32]。
1.空间数据库存储模型设计
空间数据模型采用ESRI的Geodatabase数据模型。在统一的空间数据模型中进行矢量与影像数据的模型设计。极地海洋空间数据的管理采用物理存储层、数据适配层、逻辑展示层等三层构建的管理体系, 如图4所示。

图4 极地海洋空间数据存储模型Fig.4.Polar marine spatial data storage model
1)物理存储层
物理存储层存储各种形式的极地海洋地理信息数据, 包括数据库二维表、空间数据集及以文件方式存储的数据。
2)数据适配层
数据适配层连接数据的逻辑组织结构和物理存储方式, 使复杂多样的极地海洋地理信息数据能够独立于数据的存储方式, 面向管理应用需要进行逻辑结构组织, 提供数据浏览、查询、提取等服务。
在确定填料前,施工人员要重点检测施工段的土壤质量,根据实际情况选用最佳的填料进行填充。一般来说,路堤填料有着良好的施工效果,这是由于其填料的渗水性较强,含水量较少。此外,在对路堤填充的过程中,要避免选择淤泥与杂物填充,要控制填充材料的水分含量。
3)逻辑展示层
逻辑展示层面向最终的用户。系统向用户提供灵活的配置能力。用户可根据不同的应用需求和数据类型, 对逻辑层进行配置和展示。
2.矢量数据建模
矢量数据通过比例尺+坐标系统+图幅编号/图名对数据进行管理, 利用 MDB数据作为主数据标识, 匹配图廓、测线、坐标等空间特征信息,通过 Featureclass、Feature Dataset方式存储在ArcSDE Geodatabase中, 支持对空间图层、空间参考、属性字段、比例尺等信息的自定义操作。
3.栅格数据建模
栅格数据主要包括卫星遥感影像、航空遥感影像、网格DEM产品等。采用资料名称+格网间距+资料范围等对数据进行管理, 利用影像或者海底DEM作为主数据标识, 匹配影像、产品空间覆盖范围等空间特征信息, 栅格数据建模支持面向多种空间数据源的各种栅格目录模型的定义,采用 Mosaic Dataset方式进行存储, 并生成FOOTPRINT服务通过ArcSDE Geodatabase中相应的空间数据库表实现数据访问和查询检索。
2.2 NewSQL数据库建模
NewSQL数据库面向数据分析处理人员, 采用海量并行处理(Massively Parallel Processing,MPP)技术, 构建分布式并行数据库集群, 为超大规模的极地数据管理提供大数据高性能计算、综合分析应用等技术支撑。NewSQL数据库采用按列或按行混合存储数据, 每张表或表分区可以根据应用需要, 分别指定存储和压缩方式, 并行数据库设计难点在于数据均匀分布、数据压缩存储技术、数据索引技术研究。
2.2.1 数据均匀分布策略
按照极地海洋数据特征, 进行数据库表结构设计, 按照数据均匀分布策略, 尽可能将数据均匀分布在每一个节点上, 尽量避免某个服务器节点压力过大, 最大限度发挥每个硬件设备性能,常用的分布方法有哈希分布方法和随机分布方法,本文采用 Hash分布策略将数据表按行均匀分布至相应的数据库节点上。
首页按照时间、范围、值域划分表分区, 建立数据库分区表(图5), 分区表建立的sql语句:
Create table table_name (dt date, num int) distributed by (dt)
然后依据哈希分布算法把相同的记录在同一个Segment节点, sql语句:
create table table_name distributed by (column[,…])

图5 数据均匀分布逻辑图Fig.5.Data distribution logic diagram
2.2.2 并行数据检索技术研究
通过 Hash分布策略实现极地海洋数据表按行均匀分布至服务器节点, 基于列式存储形式,利用数据压缩算法对每列数据进行压缩存储, 建立B-Tree数据库索引技术, 实现数据库索引建模,为数据的并行检索和分析操作提供技术支撑。
2.3 NoSQL数据库建模
NoSQL数据库面向数据挖掘分析处理人员,针对非结构化极地海洋数据文件, 采用分布式体系架构, 构建基于列式存储、可伸缩的分布式数据库, 实现对极地海洋文件、音视频文件、海洋时间序列数据等资料的关联分析、聚类分析、深度学习。
NoSQL数据库设计难点在于数据索引设计, 优化的数据索引模型是提高数据查询检索速度的关键。常见的索引技术有单个索引和组合索引, 当查询条件过多时, 单索引技术存在全表扫描次数过多,导致查询速度越来越慢等缺点; 当查询条件冗余过多时, 组合索引技术存在系统存储压力过大等缺点。
根据极地海洋数据文件特性, 本文提出基于序列号和基于条件项的多级索引模型设计(图6,图7), 基于序列号检索是通过观测站名称或者站代码进行检索, 而基于条件项的检索是通过数据描述信息, 如观测单位、数据名称、观测要素等,基于数据实际应用需求, 开展基于 Hadoop技术框架下的多级数据索引模型设计。

图6 多级索引模型设计(第一级)Fig.6.Multi-level index model design(first level)

图7 多级索引模型设计(第二级)Fig.7.Multi-level index model design (second level)
3 数据库应用与测试
3.1 数据库查询
面向不同用户层的业务需求, 基于“OldSQL+NewSQL+NoSQL” 混搭数据库模式, 实现了多级别、多层次、多主题的数据检索与应用服务。
3.1.1 元数据导航检索
基于极地元数据库, 参照文献检索的方式,开展数据的查询检索与服务, 用户可通过模糊查询、精确查询、多条件组合查询等形式, 实现元数据的快速导航。
3.1.2 数据地图空间漫游
基于极地基础数据库、空间数据库, 提供地图实时缩放、全图显示、坐标定位、地名定位等功能, 实现海量极地空间数据的快速浏览, 及遥感影像数据的读取及浏览。
3.1.3 主题数据检索
基于并行数据库, 提供多主题极地综合分析数据的查询检索, 并提供航次轨迹路线图、网格分布图(图8)、时间分布图等可视化展示, 便于用户进一步的综合分析应用。

图8 极地物理海洋网格分布图Fig.8.Polar physical ocean grid map
3.2 数据库查询效率测试
3.2.1 实验测试环境
软硬件测试环境: 并行数据库集群是由配置相同的Dell R910服务器组成, 服务器具体配置:CPU为 Intel Xeon E7-4807 1.86 GHz, 内存容量16 GB, 每台服务器配备3块SAS硬盘, 容量300 GB,网络环境为千兆局域网。
实验测试数据: 实验数据根据极地调查资料模拟, 数据格式为文本文件, 总数据量大小约2.6 GB。
3.2.2 查询响应对比
以温盐、海流和气温要素为测试用例, 以传统结构化存储方式与NewSQL并行存储方式对比,测试执行查询语句的响应时间。其中温盐记录约700万条, 海流记录约80万条, 气温记录约3万条。数据查询响应时间对比图, 如图9所示。
4 结语

图9 查询响应性能对比图Fig.9.Query response performance comparison chart
本文通过分析极地海洋数据的特点及应用需求, 采用“多种架构支持多类应用”的混搭数据库存储模式, 将通过极地科考、国际交换获取及加工处理后的所有元数据、空间数据、矢量数据、栅格数据、事件序列数据、成果数据等, 开展数据分类、分层体系设计, 通过开展数据库建模、清单索引、多级索引、空间关联关系等设计, 开发数据库查询检索功能, 满足用户对极地海洋数据的查询检索、可视化展示、高性能计算、关联分析等需求, 实现极地海洋数据的科学管理和有效应用。
猜你喜欢
小哥白尼(趣味科学)(2022年5期)2022-08-15 08:34:32
奥秘(2022年6期)2022-07-02 13:01:13
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:02
电子制作(2018年17期)2018-09-28 01:56:44
通信电源技术(2018年5期)2018-08-23 01:15:36
当代音乐(2018年4期)2018-05-14 06:47:13
琴童(2017年7期)2017-07-31 18:33:48
小学科学(2017年5期)2017-05-26 18:25:53
小学阅读指南·低年级版(2017年1期)2017-03-13 20:06:52
现代防御技术(2014年6期)2014-02-28 18:26:29
