
基于二次映射的哈希负载均衡方法
2018-12-24 03:26:34王永亮
信息记录材料 2018年12期
王永亮
(华为软件技术有限公司南京研究所江苏南京 210012)
1 引言
在互联网应用中,面对海量的数据,通常采用分布式集群服务器进行数据存储,不可避免的面临集群服务器之间的负载均衡问题。同时集群服务器之间可能是异构的,更是增加了负载均衡的难度,本文描述一种基于二次映射的哈希(Hash)负载均衡方法,能够很好的支持同构或者异构的存储服务器集群的负载均衡。
2 基于二次映射的哈希负载均衡设计
负载均衡策略分为静态负载均衡策略和动态负载均衡策略,静态负载均衡策略实现简单、方便,如果规划设计合理就能达到良好的效果;动态负载均衡策略根据系统的负载情况动态的进行调整,较灵活,但是实现复杂。
由于存储系统涉及到数据的增删改查,服务器集群各个节点有状态、不对等,因此存储系统的负载均衡算法和普通的无状态的集群负载均衡算法不同;在存储系统中,较广泛使用哈希算法对数据请求进行静态负载均衡,这种方式能解决大多数的问题,但是在服务器集群扩容或者缩容时,通常需要进行大量的数据迁移;并且难以适应服务器异构的情况;一致性哈希算法是对普通哈希算法的改进,在扩容或者缩容时能较少的进行数据迁移,但是并不能方便的对热点数据进行精准的控制,并且如果前期规划的数据槽位或者哈希函数的选择不合理,针对热点数据的处理会有极限。
在基于二次映射的哈希负载均衡算法中,所有的数据请求根据一级哈希函数映射到不同的分区Section,然后对分区Section再次进行二级哈希映射,将映射到同一分区Section的数据关键字映射到不同的槽位Slot上;槽位Slot和服务器Node之间通过Map表进行关联;将数据进行分区,各个分区互不影响;将同一分区中的数据进行分槽位映射,可以针对数据热点分区增加槽位;槽位和服务器节点进行Map映射,可以控制各个服务器节点分配的槽位和槽位数量。因此此算法可以方便的处理数据热点和负载不均的问题。
2.1 数据模型
此算法的数据模型如图2-1所示。
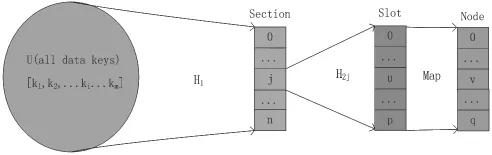
图2-1 数据模型
所有的数据请求的key∈U,U=[k1,k2,ki,…,km],其中m为不同的key的个数;请求数据key与分区Section的关系为:j=H1(ki),其中j∈[0,n],i∈[0,m],H1为选定的一级Hash函数,j为第j个分区Section,ki为第i个key;
每个分区映射到多个槽位Slot,设第j个分区section映射到p个槽位上,数据key与槽位Slot的关系为:u=H2j(Kij)其中u为第j个分区的第u个槽位Slot,kij满足j = H1(kii),H2j为分区j选定的二级Hash函数;
一级Hash函数和各个分区的二级Hash可以从某一全域Hash函数族中随机选择,这样可以确保在二级Hash后减少Hash冲突。
服务器节点Node与槽位Slot的关系为Map表映射,可人为配置或者自动配置,类似如表2-1所示。不同分区的槽位可以映射到相同的服务器节点。

表2-1 数据槽位和服务器节点配置样例表
2.2 服务器节点的扩容和缩容
在系统设计完成并上线运行后,随着在线数据量及业务请求量的增加或者减少,根据服务器负载情况,需要对服务器集群进行扩容或者缩容。
数据单个分区对应的槽位在系统设计时可能无法准确的进行评估,随着系统数据量的增多和数据请求量的不均衡,在服务器节点之间会出现负载不均衡的问题;此时需要对高负载的服务器节点进行数据槽位迁出,将多余的槽位迁出都其他负载低的服务器节点或新增服务器节点上;在迁移数据槽位都无法均衡各个服务器的负载的时候,就需要增加热点数据对应分区的槽位个数;由于各个分区独立,因此单个分区槽位的增加并不会影响其他分区的数据,达到了较少迁移数据的目的。
服务器存储的数据减少后,为了节省成本通常会选择对服务器集群进行缩容;此时针对数据减少的分区,减少服务器节点数量,将减少的服务器节点上的对应的槽位迁移到剩余的对应分区的服务器节点上即可。不会影响到其他数据槽位和其他分区。
3 实验结果
采用此负载均衡算法进行了模拟实验,实验场景如下:
(1)使用随机数产生负载请求数据;
(2)从全域Hash函数族中选择一个一次Hash函数作为从数据key到分区Section的映射;
(3)从全域Hash函数族中选择一个二次Hash函数作为各个分区数据到对应分区槽位Slot的映射;
(4)配置各个分区Section的槽位Slot到服务器节点Node的对应关系。
实验模拟结束后,各个数据的分布如图3-1所示;各个服务器节点的数据负载分布如图3-2所示。

图3-1 数据分布

图3-2 服务器节点数据负载分布
从实验结果可以得出,基于二级映射的哈希负载均衡算法可以较好的完成服务器节点间的负载均衡。
4 总结
在海量存储系统中,通常需要集群服务器进行存储,为了均衡各个服务器之间的负载,需要考虑选择对应的负载均衡算法,本文提出了一种基于二次映射的哈希负载均衡算法,能够很好的完成在服务器节点间的负载均衡,并能方便的解决数据热点和服务器的扩容、缩容,为存储系统的负载均衡提供了新的思路和方法。
猜你喜欢
环球时报(2022-03-29)2022-03-29 17:14:11
哈尔滨轴承(2020年2期)2020-11-06 09:22:36
发明与创新·大科技(2019年12期)2019-03-17 09:23:31
知识经济·中国直销(2018年7期)2018-07-27 02:49:52
工业设计(2016年8期)2016-04-16 02:43:34
中国教育信息化(2015年12期)2015-08-24 07:58:36
计算机工程(2015年8期)2015-07-03 12:20:04
电测与仪表(2015年8期)2015-04-09 11:50:16
电测与仪表(2015年10期)2015-04-09 11:48:20
电测与仪表(2015年7期)2015-04-09 11:40:16
