
基于隐马尔可夫模型的中文分词
2018-12-22 07:53吴帅潘海珍
现代计算机 2018年33期
吴帅,潘海珍
(上饶师范学院数学与计算机科学学院,上饶 334001)
0 引言
中文分词是中文自然语言处理中的基础环节,由于中文的词语之间没有明显的分隔符,使得中文相对其他语言的分词难度更大,中文分词的质量和分词效率将会影响建立在其基础上的高级应用。中文分词也是中文自然语言处理中的瓶颈问题,解决好了中文分词,将会给其他相关领域的研究带来突破性的发展。中文分词的研究工作已经持续了三十多年,分词的准确度和速度得到非常大的提高,目前比较流行且效果比较好的方法是基于统计的机器学习方法。
隐马尔可夫模型是一种基于统计的机器学习模型,可以通过观测数据来预测数据最可能的原始状态,这点正好满足中文分词的要求,将汉字序列切分成一个个独立且最合理的词。首先为中文文本建立统计模型,利用隐马尔可夫假设简化模型,降低计算的复杂度,最后通过Viterbi算法来预测最佳的词方式。本文分析了隐马尔可夫模型实现中文分词的基本原理、过程及分词模型的Python实现。
1 中文分词算法
近年来,专家学者们提出了许多的中文分词算法,可以归纳为三大类:基于词典匹配的算法、基于统计的算法和基于理解的算法。基于词典匹配的算法是按照一定的策略将文本中准备分析的字符串与词典中的词语进行匹配,若在词典中找到某个字符串,则识别出文本中的词语;基于统计的算法是基于人的直观理解,任意相邻的汉字出现的频率越高,说明它们组成词的可能性就越大;基于理解的算法是让计算机模拟人对句子的理解,达到识别词的效果,分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象,该方法还处于理论研究,未有实际的应用。中文分词中存在歧义识别和未登录词识别两大难点。各类算法的具体比较见表1。
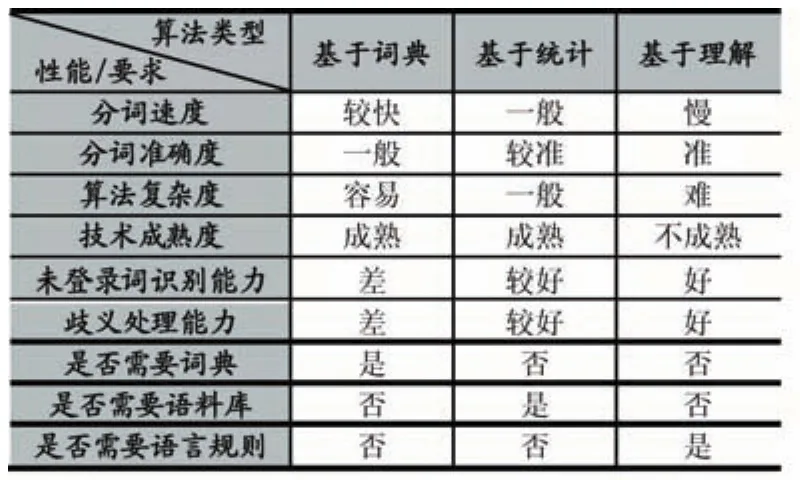
表1 三类分词算法的比较
2 隐马尔可夫模型概述
2.1 隐马尔可夫模型
隐马尔可夫模型(Hidden Markov Model,HMM)描述了含有隐藏变量的马尔可夫随机过程,该模型涉及两个序列和三个概率矩阵,即可观察的观测序列O、隐藏的状态序列Z、初始的状态概率矩阵π,状态转移概率矩阵A及状态生成观测的概率矩阵B。HMM可表示为{O,Z,π,A,Bλ=(π,A,B)},λ=(π,A,B)决定 HMM 模型,PIπ和A决定观测序列,B决定状态序列。
HMM具有三个基本问题:概率计算问题、学习问题和预测问题。概率计算问题是计算在模型λ下观测序列O的概率P(O/λ),直接求解的方法不可行,计算量非常大,有效的方法是前向-后向算法。学习问题是已知观测 O 估计模型λ=(π,A,B)λ=(π,A,B)的参数,有监督可用极大似然估计法、无监督可用Baum-Welch算法。预测问题是给定观测序列,求出最有可能的对应的状态序列,可用近似算法和Viterbi算法。
2.2 应用原理
中文的词是由汉字构成,每个汉字在构词时都有一个确定的位置。字在词中出现的位置可用BMSE四种标签表示,B表示词的开始位置、M表示多字词的中间位置、E表示词的结束位置,S表示字单独成词。如“明月湖的荷花露出迷人的笑脸”对应的词位标签序列为“BMESBEBESBE”,分词结果为“明月湖/的/荷花/露出/迷人/的/笑脸”。
文本中的每个字构成观测序列,每个字的词位标注构成状态序列。中文分词就转换为求解字的词位标注问题,基于已加工好的语料库训,训练得到HMM的参数λ=(π,A,B),再通过Viterbi算法得到待分词文本的词位标注序列,从而得到最佳分词。
3 HMM在中文分词中的实现
隐马尔可夫模型实现中文分词主要由三个步骤组成,即训练、预测和分词,如图1所示。

图1 HMM的中文分词过程
(1)训练
通过统计语料库中相关信息训练HMM中的三个参数PI、A和B。A表示字的词位状态转移矩阵,B表示词位到词的混淆矩阵。从语料库中可以获得每个词位出现的次数,每个字符出现的次数,通过频率代替概率得到三个参数的值。
公式中Z={B,M,E,S}为字的词位序列,O={字符集}为观测序列,freq(Zi,Zj)表示ZiZj在语料库中相邻同时出现的次数,freq(Oj,Zi)表示字符Oj和Zi某个词位同时出现的次数。HMM在分词中的状态转移概率矩阵为:

计算过程中会出现频数为零或很小的值,为了避免出现计算结果的下溢,对频数取对数,如Aij=log(freq程序中采用的是北京大学加工的1998年《人民日报》语料库,该语料库具有较为完整的加工规范说明,目前较为成熟,被研究人员普遍采用。
若训练样本的数据不足,混淆矩阵B会过于稀疏。矩阵B的形式为:

给定观测序列学习HMM模型参数,采用Baum-Welch算法[4]训练分词模型,参数估计公式分别为:

算法的实现代码如下:

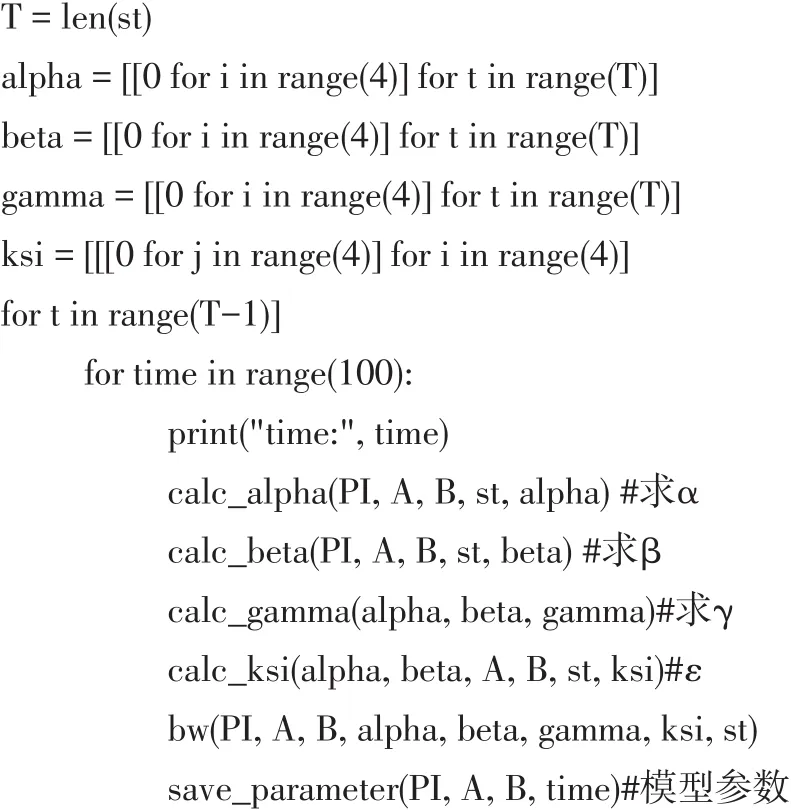
(2)预测
从语料库中训练HMM分词模型后,可通过Viter⁃bi算法来预测未知语言中汉字的词位标记从而达到分词的目的,可以求得全局最优的分词结果。Viterbi算法实际是用动态规划来求解隐马尔可夫模型预测问题,即用动态规划求概率最大路径。δt定义在时刻t状态为i的所有单个路径(i1,i2,…,it) 中的概率最大值为:

递推公式为:
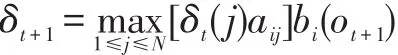
定义在t状态为i的所有单个路径中概率最大的路径的第t-1个结点为:


(3)分词
一般情况下,完成文本的标注序列后,需要进行分词,分词的方法是从左到右,采用最大匹配模式。程序中分词的实现如下所示。
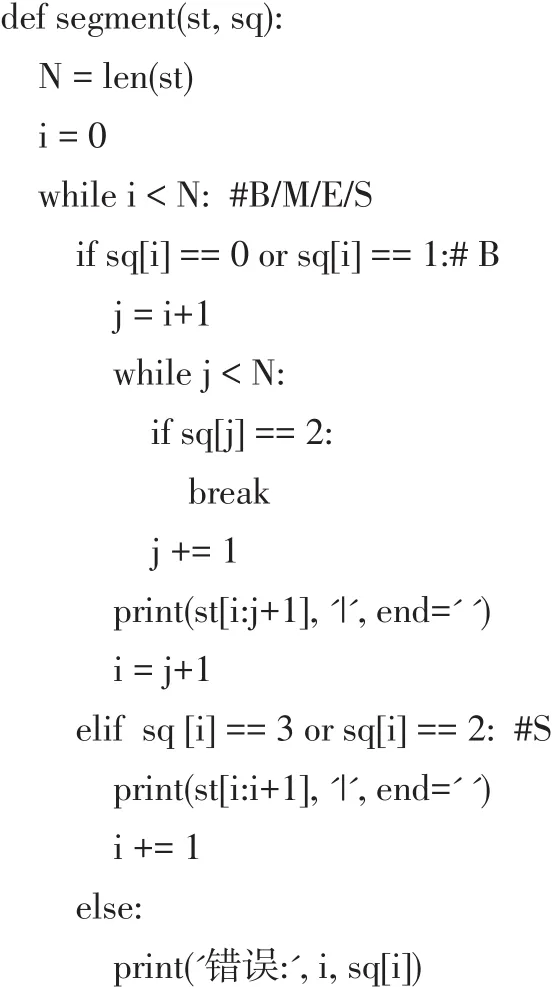
基于HMM的分词模型经常会将一起出现频率高的字组切分成词,如“我的”、“每个”等,会出现错误分词的现象。有训练语料时,训练模型的时间较短。HMM是生成模型,即使没有先验语料,也可以使用EM方法进行估计,估计原则是使每个序列的P(X)最大,这个优势是判别模型无法比拟的。
4 结语
本文分析隐马尔可夫模型的理论基础,论述基于隐马尔可夫模实现中文分词的基本原理。HMM分词模型只考虑词前后关系,未考虑词的上下文之间的关系,但在中文分词中表现较好,HMM可以求得全局最优的分词结果。中文分词涉及的范围非常广,由于中文本身的特殊性,中文分词算法在不断地发展和完善,在分词速度更快、精度更高、歧义词、未登录词、新词的识别等方面会得到突破。
猜你喜欢
外语学刊(2021年1期)2021-11-04
校园英语·月末(2021年13期)2021-03-15
天津外国语大学学报(2020年1期)2020-03-25
计算技术与自动化(2019年3期)2019-11-05
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
科技创新导报(2019年31期)2019-04-07
财会学习(2018年6期)2018-03-07
