
基于改进Trie树的变形敏感词过滤算法
2018-12-22 07:53叶情
现代计算机 2018年33期
叶情
(四川大学计算机学院,成都 610065)
0 引言
随着互联网的飞速发展,我们在享受网络科技带来便利的同时,各种非法言论(如反政治、暴力血腥、黄赌毒等)经常在网络中蔓延,不可避免地受到这些信息的侵害。尽管有关部门已经采取一系列监控管理措施来优化网络环境,但仍有不法分子通过各种手段在网络中散播不利于网络环境的言论,严重影响社会主义的精神文明建设。为改善网络环境、减少不良信息传播,在从法律、道德等方面进行约束的同时,还必须通过技术手段对网络信息进行过滤,优化网络环境。
目前,国内外对于敏感词的识别研究形成了较为成熟的体系,并且广泛应用于各大网络平台中。例如网易的易盾敏感词过滤系统能有效识别出文本中的敏感词。由于中文存在字词结构复杂、语义多变、词库量大等特点,因此对于变形敏感词的过滤处理存在较大困难。目前,对变形敏感词的研究还处于起步阶段,相关研究成果较少。文献[10]针对变形敏感词提出一种新的过滤算法,将文本中的特殊字符进行预处理转为中文字符再进行检测,该方法能检测出一类特定敏感词,提高了文本检测的精度。文献[11]采用机器学习的方法,将Bigram、词干等作为特征值来对文本信息做分类处理,以检测出变形敏感词。文献[7]提出一种基于语言的字符串匹配算法,该算法可以有效地识别发音相似的敏感词,但对于其他类型的敏感词缺乏分析。
基于以上研究,本文对常见变形敏感词进行归纳分类,提出一种基于改进Trie树的变形敏感词过滤算法,不仅可以过滤普通敏感词,对变形敏感词的识别也起到了良好的效果。
1 敏感词过滤算法预处理
1.1 变形敏感词处理
经过对变形敏感词的研究与分析,对现有的变形敏感词进行了分类总结,将变形敏感词大致分为以下3类:
第一类:添加特殊字符的敏感词,在敏感词之间添加非中文符号或者用符号替代敏感词中的某个字。例如:在“法轮功”这个敏感词之间插入非中文字符形成变形敏感词“法@轮&&&功”、用“*”替代“法轮大法”一词中的某个字形成变形敏感词“法轮*法”等。
第二类:使用拼音、同音字、谐音字等将敏感词变形,例如:“法轮 gong”、“台独分子”。
第三类:经过拆分、繁体化的敏感词,例如:“三去车仑工力”、“口马口非”、“進寶”等。
1.2 文本分立预处理
对文本进行分立处理是敏感词过滤的第一步,针对1.1介绍的三种变形敏感词,分别采用不同的分立处理方法。对于第一类,若在敏感词中插入多个特殊字符,将只用一个“*”代替。对于第二类中的拼音分立情况较为复杂,英文字符串可能是拼音或者英文单词,因此在分立英文字符串时需要进一步处理。对第三类敏感词将直接进行分立处理。
对于英文字符串,常见的汉语拼音有409种组合。本文通过以正则匹配为核心进行拼音串识别,具体正则表达式如图1所示,如果是拼音字符串,将正确分立成单个拼音;如果不能分立成拼音,则分立为单个英文字符。

图1 正则表达式
1.3 基于中文的Trie树构建
Trie树的结点一般由英文字符组成,因此Trie树一个节点一般具有26个子节点。而中文则不同,常见汉字有将近7000多个,若按照英文的Trie树构建中文敏感词Trie树,将大大增加查找难度。因此,本文对英文Trie树结构进行改进,以适应中文敏感词Trie树的构建。
本文基于文献[12]中的决策树思想,并基于汉语拼音的组成,构建了改进的中文敏感词Trie树,该树能够支持多种变形敏感词的查找以及特殊字符的存储。由于汉语拼音的首字母由 23 个(去除“u”、“v”、“i”)字母组成,因此该树的根节点下创建24个子节点,其中0~22号节点分别存储首字母拼音的中文敏感词,23号的节点存储数字或者其他非中文和英文字符开头的敏感词,并且在存入汉字及其拼音的同时标记该节点是否为终端节点。改进后的敏感词Trie树结构如图2所示,其中根节点和第一层子节点是固定不变的,图中深色结点表示终端结点。
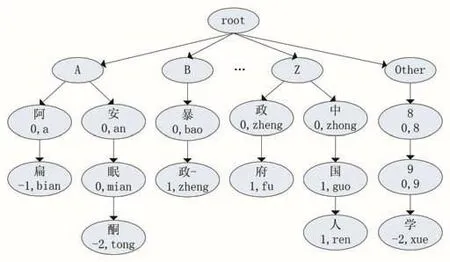
图2 中文敏感词Trie树
2 敏感词过滤算法的具体实现
对于存在普通敏感词的文本,经过文本分立处理后,可直接在词库中进行过滤;在对变形敏感词匹配过程中,针对第三类变形敏感词,本文在构建敏感词库时,已经尽可能地将这种变形敏感词加入,直接利用Trie树进行匹配即可。而对于第一类和第二类变形词,需要特殊的匹配算法进行过滤。
2.1 第一类变形敏感词的最大匹配算法
对于第一类敏感词,特殊符号可能仅代替其中一个敏感词字符,也可能仅仅是间隔其中的汉字,起到干扰作用,因此在匹配时分两种情况进行模糊匹配。
例如敏感词“法轮*法”,其匹配过程如图3所示,当成功匹配“法轮”两个字符后,下一个待匹配的字符为“*”。若“*”不替代敏感词中的任何字符,则直接比较下个字符“法”与下层节点即第4层节点的字符,发现无法匹配。再将“法”与下一层即第5层节点的字符对比,发现刚好匹配,而这个匹配的节点同时为叶节点和终节点,所以本轮匹配结束。因此,我们认为检测文本中的“法轮*法”与敏感词库中的“法轮大法”相匹配。同理,“法轮*功”则与“法轮功”匹配。
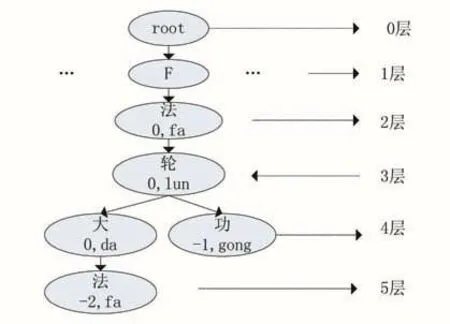
图3 第一类变形词匹配举例
2.2 第二类变形敏感词的最大匹配算法
对于第二类变形词,当遇到连续拼音串时,本文基于最大匹配原则,采用此正则表达式对拼音串进行分割,例如“Yeqing”可正确分割成“Ye qing”。在对拼音进行匹配时,由于匹配情况较为复杂,需要额外空间存储节点,规定用pinYin数组存储拼音串,用pre数组存储待定匹配节点,用node数组存储已匹配的节点。由于一个拼音可能对于多个汉字,因此在检测拼音串时,pre数组存储该拼音对应的所有节点。若上轮存在成功匹配的节点,则存入node中,本轮匹配将从pre数组中的子节点出发,直至匹配到终端节点为止。
算法1查找某个文本分立单元相匹配的所有子节点


3 实验及结果分析
3.1 数据集处理
本实验的环境为Intel i5处理器,8GB内存,编程语言为Java。实验中敏感词库的敏感词来源于国内几大权威网站的敏感词库以及部分网络新词汇整理归纳而成。词库中的敏感词一共4700个,在实验过程中,词库会不断进行更新。
首先对一个给定文本片段的敏感词进行检测,对比本文敏感词检测算法与文献[7]中的ST-DFA算法的检测结果如图4所示。从结果中可看出,本文的敏感词检测算法对于变形敏感词的过滤精度高于ST-DFA算法。

图4 敏感词检测对比结果
为了进一步检验该算法的正确性,从全网数据库中随机抽取了含有疑似敏感词的1000篇文本作为测试数据集。为了方便后续的结果统计,人工地将1000篇文章根据含有敏感词类型进行分类汇总,其中普通敏感词一共1376个,变形敏感词274个,为减小实验误差,需要将变形词的原型敏感词加入词库中。对敏感词检测结果分可为两种情况,正确肯定(True Posi⁃tive,TP):预测为真,实际为真;错误肯定(False Posi⁃tive,FP):预测为真,实际为假。并通过计算该算法的查准率和查全率验证其效率,其计算公式如下:

3.2 实验结果分析
为了提高实验效率,将数据集随机整合为4组数据进行测试,第一组包含250篇,第二组包含300篇,第三组300篇,第四组150篇.并计算四组数据的查准率和查全率如表1所示。
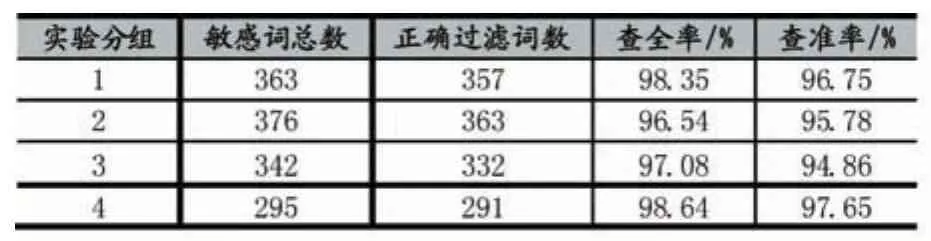
表1 敏感词过滤结果
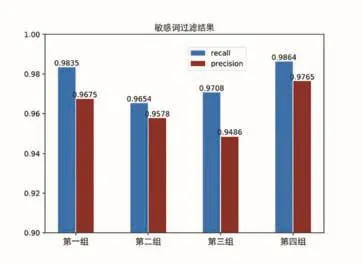
图5 敏感词过滤结果
此外,对实验中的变形敏感词过滤结果进行分析,对于变形敏感词的查全率和查准率,公式(1)、(2)同样适用。其结果如表2所示。

表2 变形敏感词过滤结果
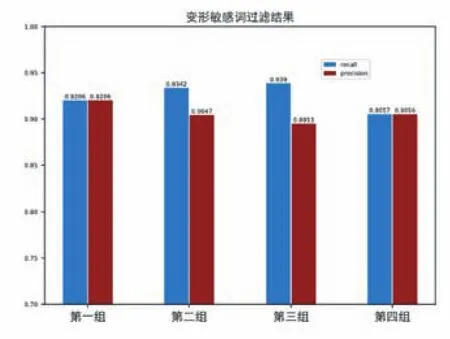
图6 变形敏感词过滤结果
通过对以上实验数据分析,敏感词的平均查全率为 97.65%,相比 ST-DFA算法查全率 95.46%高2.19%,平均查准率上为96.26%,较ST-DFA算法高1.23%。在对变形敏感词的过滤的平均查全率到达了92.49%,达到了较高的变形敏感词过滤效果。
4 结语
本文通过对网络中普遍存在的变形敏感词进行了分类汇总,根据其特点构建一棵改进的Trie树。并通过对文本进行文本预处理,采用变形敏感词匹配等算法进行文本过滤。通过多次实验表明,该算法不仅能有效地检测出文本中在敏感词库中存在的敏感词,还能检测出各类变形敏感词,提高了文本检测的精度和广度。下一步工作将对变形敏感词进行更加细化、规范的分类,进一步提高变形词过滤的精度。
猜你喜欢
汉字汉语研究(2020年2期)2020-08-13
动漫界·幼教365(大班)(2020年7期)2020-06-26
现代计算机(2019年30期)2019-12-11
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
电脑爱好者(2017年5期)2017-05-04
小天使·一年级语数英综合(2015年8期)2015-07-06
小天使·一年级语数英综合(2015年2期)2015-01-14
网友世界(2009年12期)2009-03-05
