
汉维句子对齐长度计算单位的研究
2018-12-22 07:53塞麦提麦麦提敏吐尔根伊布拉音
现代计算机 2018年33期
塞麦提·麦麦提敏,吐尔根·伊布拉音
(新疆大学,乌鲁木齐 830046)
0 引言
机器翻译、跨语言信息检索等自然信息处理系统都需要双语语料库等大数据资源。在建立大型双语语料库中,自动句子对齐和句子长度相似度计算是重要的技术之一。自动句子对齐的方法基本上可分为三类,即基于长度的方法[1-3]、基于词汇的方法[4-5]和混合的方法[6-7]。其中,Brown(1991)和 Gale(1993)等的基于长度的句子对齐方法最有名。该方法分别采用以单词或字符作为句子长度计算单位,对Hansard语料库进行英法句子的对齐试验。其研究结果显示,长度计算单位不同,句子对齐算法的准确率有差异。
在汉维句子对齐研究方面,毕雪华[8]、牛洪梅[9]和热西旦[10]等先后做了实验性探索。他们的基于长度的句子对齐算法都以字符作为汉维句子长度的计算单位。将字符作为长度单位进行句子对齐是拼音文字之间可以采取的方法。维文是拼音文字,汉文则不是拼音文字,汉文字符和维文字符属于不同层面的语言单位,其功能和特点完全不同。以字符作为句子长度单位的方法可能不太适合于汉维语的特点。因此,基于多种长度单位的汉维句子对齐算法都值得尝试。
本文对汉语字符、汉语汉字、维语单词、维语字符等句子长度单位的4种组合进行统计与实验分析,以便确定汉维句子长度计算的最佳单位,为计算汉维双语句子对齐的概率提供可靠的依据,最终提高汉维句子对齐的效率。
1 基于长度对齐模型
基于长度的句子对齐算法可利用简单的统计模型,是因为原文和译文的长度满足一定的比例关系,即原句子越长译文越长,反之亦然。基于这种考虑,句子对齐问题变成利用原文和译文句子的长度关系,求解每一对双语句子的互译概率的问题。因此,在基于长度的对齐方法中,首先对已对齐的语料进行训练,获取概率参数,然后给每个句对分配一个概率得分,用此得分进行动态规划,以找到最大可能的句子对齐。
于是,得到基于长度的句子对齐模型如下:

式(1)中,L(AiS)和 L(AiT)分别表示原文句子 AiS和译文句子AiT的长度。
该对齐模型的关键在于求解概率:

而根据概率学中的条件概率公式有:

式(2)中,由于对于任意的 AiS、AiT、Prob(L(AiS),L(AiT))都可以认为是一个常数,因此在进行概率计算时可以略去该常数。Prob(AiSóAiT)表示不考虑长度条件下AiS和AiT互为翻译的概率,该概率可以用双语句子的对齐模式概率来估计。
通过这些方法确定Prob(A|S,T)的值以后,通过概率学原理可求得概率 Prob(L(AiS),L(AiT)|AiSóAiT)。
然后,采用动态规划算法,通过计算两个片段的最小距离的办法确定句子对齐情况。动态规划算法可总结为下面的递归等式:

其中,si,tj(i=1,2,…i;j=1,2,…,j)分别为两个文本中的句子,算法开始时 D(i,j)=0。
2 长度计算方法与分析
2.1 长度计算方法
句子长度计算单位的确定是基于长度的句子对齐算法首要解决的问题。计算单位不同,双语句子之间的长度关系的概率不同。对于汉语和维语而言,句子长度的计算单位不像印欧语系语言那么容易确定。汉语句子长度的计算单位有单词、纯汉字(不包括标点符号等)、字符,维语句子长度的计算单位有单词和字符(字母)等。理论上,汉语和维语句子的长度关系有以下六种组合:①汉语单词/维语单词②汉语单词/维文字符③汉语汉字/维语单词④汉语汉字/维语字符⑤汉语字符/维语单词⑥汉语字符/维文字符。其中,①③⑤⑥比较适合于汉维语的特点,也有一定的比较性。因此,本文只对这4种组合进行相关的统计与分析。
2.2 训练语料
本文训练语料是新疆大学的“汉维双语平行语料库”。该语料库一共收集550个样本语料,总规模为4809873字(词),其中汉文部分3174122汉字,维文部分1635751词。按句子总数计算,一共216200句子,其中汉文句子105845,维文句子110355,句子对齐后的句对总数为100742。该语料库包括文学、法律、公文、学术、新闻、日常会话等六种语体的双语语料。
2.3 句子长度相关性分析
为了比较不同句子长度计算单位,对上述训练语料的汉维句子长度及其相关性进行统计,获得基于不同长度单位的句子长度相关系数和分布图。通过统计发现,较长的汉语句子趋向于翻译成较长的维语句子,而较短的汉语句子则趋向于翻译成较短的维语句子。但是,计算单位不同,汉维句子的长度关系的相关性和分布不同。
图1是以汉语单词和维语单词作为长度计算单位的句子长度分布图。
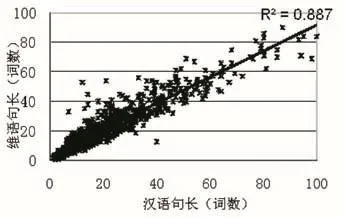
图1 子长度分布图(汉语单词/维语单词)
根据图1,以单词作为句子长度单位时,汉维句子长度关系不太稳定,相关系数R的平方值也较小。
图2是以汉语字数和维语词数作为长度计算单位的句子长度分布图。
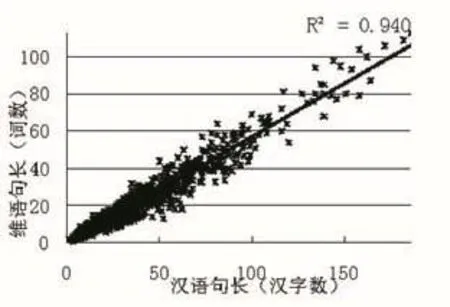
图2 子长度分布图(汉语汉字/维语单词)
图3是以汉语字符数和维语词数作为长度计算单位的句子长度分布图。
根据图2和图3,与以汉字作为长度单位的分布比较,以汉语字符作为长度单位的分布相对集中,其句子关系相对稳定。排除标点符号、数字等非汉字字符的方法降低了句子长度关系的稳定性。

图3 子长度分布图(汉语字符/维语单词)
图4是以汉语字符数和维语字符数作为长度计算单位的句子长度分布图。

图4 长度分布图(汉语字符/维语字符)
从图1-4可以看出,汉维句子长度的分布具有一定的规律性。以汉语词语和维语词语(图1)或汉语汉子和维语词语作为长度单位(图2)时,汉维句子长度的分布相对稀疏。以汉语字符数和维语词数为长度单位(图3)时,汉维句子的长度关系更为稳定。以汉语字符数和维语字符数作为长度单位(图4)时,的分布相对集中,其相关系数接近于第三种组合(图3),但是汉维句子长度比值较大时,对句子长度的变化不太敏感。
根据句子长度分布图,可以初步判断,在汉维句子对齐中不宜同时采用词数(或字符数)作为句子长度的计算单位,而采用汉文字符数和维文单词作为句子长度单位是比较合适的。当然,这一假设需要通过实验验证。
3 子对齐实验与结果
3.1 参数统计
基于长度的对齐模型的第一个条件是式(2)中评价函数 Prob(L(AiS),L(AiT))满足标准正态分布时,该模型才可以获得较高的准确率。本文对训练语料进行统计,得到汉维句子长度比例的数学期望值c和方差S2的参数值。c是通过计算汉维句子长度比值的平均值得到,S2是通过计算(Lc-Lu*c)2Lu的平均值得到。其中,Lc为汉语句子长度,Lu为维语句子长度。相关分析结果表明,句子长度随机变量的分布情况相当接近于以c和S2为参数的正态分布。基于不同句子长度实验参数统计如表1所示。

表1 实验参数值
根据表1,在汉维对齐的语料中,约1个汉语单词对应0.96个维语单词;1个汉语字符对应4.06个维语字符;1.76个汉字对应1个维语单词;1.97个汉语字符对应1个维语单词。
基于长度的对齐模型的第二个必要条件是:汉维句子长度满足一定的比例关系。如表1所示,无论采用什么样的计算单位,汉语和维语句子在长度方面高度相关(相关系数都大于0.9)。其中,以汉语字符和维语单词为计算单位时,相关系数更接近于1。相关系数R可用以下公式计算:

式(4)中,x和y分别表示汉维句子的长度。
此外,句子对齐模型还需计算式(2)中的Prob(AiSóAiT)(句子对齐模式的概率),本文对训练语料进行统计获得的对齐模式的概率如表2所示:

表2 对齐模式的概率统计
3.2 实验结果
为了比较不同计算单位对句子对齐的影响,进一步验证上述假设,从新疆大学“汉维双语平行语料库”中,随机抽取分别属于文学、法律、公文、学术、新闻等5种语体的10个样本(一共1482句对)作为测试语料。分别采用不同的长度计算单位,进行基于长度的句子对齐实验。实验评价标准如下:

实验结果如表3所示:
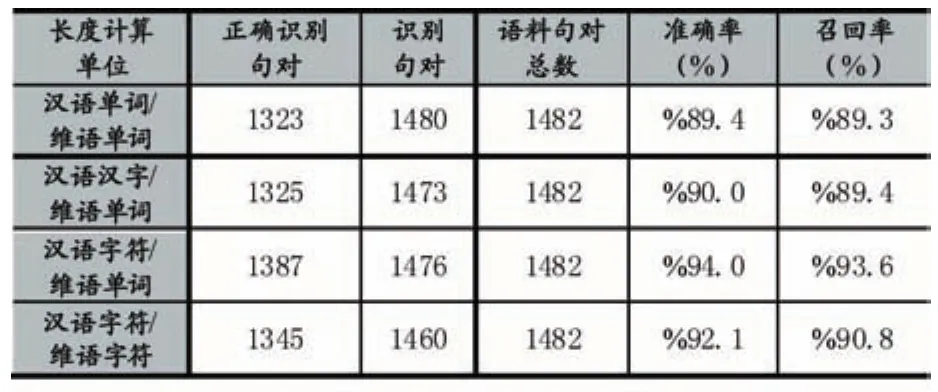
表3 句子对齐实验结果
根据实验结果,句子长度计算单位不同,句子对齐的准确率和召回率都有差异。其中,以汉语字符和维语单词作为长度计算单位时,句子对齐的准确率和召回率高于其他三种方法,分别达到94%和93.6%。文献[13]的实验结果也显示,选用这种长度计算单位时,利用锚点等多种信息的混合句子对齐的准确率提高了2.7%。
通过分析实验结果,可得出以下结论:
(1)以汉语单词作为长度计算单位进行句子对齐,准确率比较低。这主要是因为汉语句子进行分词才能计算句子长度,分词的复杂性,往往导致较大误差。此外,句子内的单词数相对于字符数较少,容易出现数据的稀疏。一旦句子词数的计算发生误差,便会造成句子长度比值的较大幅度改变,从而导致后续句子对齐的错误。
(2)将字符作为句子长度的计算单位是拼音文字之间可以采取的方法,可是在计算汉维句子长度时,显然是不可取的。因为,维文是拼音文字,汉文则不是拼音文字。汉文字符和维文字符在功能和特点上很不一样,属于不同层面的语言单位。因此,以字符作为句子长度单位不太适合于汉维这两种文字的特点。
(3)根据上述统计和实验结果,互译的句子中汉语字符数和维文词数具有高度相关性,句子长度比值更近似于正态分布,汉语字符和维文词语的功能基本相同。因此,汉文字符和维文单词是汉维句子对齐的最佳长度计算单位。
4 结语
传统的基于长度的汉维句子对齐算法大都以字符作为句子长度的计算单位。本文分别对句子长度计算的4种不同方法进行统计分析,根据实验结果,汉维句子对齐的最佳长度计算单位是汉语字符和维语单词,其准确率和召回率都高于其他方法。因此,在句子对齐中,以汉语字符和维语单词作为长度计算单位是正确的选择。
猜你喜欢
厦门大学学报(自然科学版)(2021年4期)2021-06-22
小学生学习指导(低年级)(2020年10期)2020-11-26
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑知识与技术(2019年23期)2019-11-03
电脑爱好者(2019年8期)2019-10-30
作文大王·低年级(2017年11期)2017-12-05
学苑创造·A版(2017年1期)2017-01-19
外语教学理论与实践(2014年2期)2014-06-21
