
属性权重未知的正态随机多属性决策方法
2018-12-21 07:14龚本刚王嘉丽张孝琪
统计与决策 2018年23期
龚本刚,王嘉丽,张孝琪
(安徽工程大学 管理工程学院,安徽 芜湖 241000)
0 引言
现实中,随机多属性决策问题中决策属性值服从或近似服从正态分布的随机变量(简称正态随机变量)是较为常见的形式[1]。例如,“产品的使用寿命”、“产品的市场需求”及“顾客的等待时间”等属性值通常都是正态随机变量的形式[2,3]。这类属性值具有正态随机变量的多属性决策通常称为正态随机多属性决策(Stochastic Multiple Atribute Decision Making,SMADM)。近年来,关于正态随机多属性决策问题已取得一些研究成果,主要从两个方面展开:一是利用随机占优准则判断两两方案间的随机占优关系,对方案进行排序[4,5];二是利用SMAA(Stochastic Multi-objective Acceptability Analysis)方法对方案的权重空间进行计算,给出使每个方案成为最优决策的权重向量[6]。但是上述运用随机占优决策方法进行排序时,假设决策者完全理性,决策过程是建立在期望效用理论的基础上,然而在实际决策过程中,决策者决策时往往会表现出有限理性的行为特征;SMAA是运用蒙特卡洛仿真对方案权重空间进行计算分析,分别得出使每个方案成为最优决策的权重向量,而不能给出全方案排序[4]。
针对上述问题,部分学者考虑决策者有限理性的行为特征,运用前景理论(Prospect Theory,PT)进行随机多属性决策分析。如文献[7]将前景理论和SMAA相结合,提出一种随机多属性决策方法;文献[8]针对属性值为离散随机变量的决策问题,提出一种基于累积前景理论和集对分析的动态随机多准则决策方法;文献[9]通过构建出正态分布数字特征,推断各区间数值发生概率计算参考点,提出基于前景理论和统计推断的决策方法;以上基于前景理论的随机多属性决策方法是通过构建决策权重函数和属性价值函数,计算各方案前景值,进而对方案进行排序。然而当决策过程中事件在自然状态下概率未知或对各属性前景值进行融合求解方案综合前景值时,需要进行非线性运算,这样在决策过程中可能会带来部分决策信息的丢失。
证据理论(Dempster-Shafer Theory,DST)作为一种不确定性推理方法,被广泛应用于各个领域[10,11]。而证据推理(Evidential Reasoning,ER)作为证据理论的一种改进,能够有效处理具有不确定性的定量和定性问题,并对非线性信息有效地进行融合。本文将证据推理与前景理论结合,提出一种考虑权重未知的正态随机多属性决策方法。首先将正态随机变量离散化,利用证据推理构造基本信任分配(Basic Probability Assignment,BPA)函数,也称为Mass函数,用来处理和表示属性值在自然状态下离散区间内发生的未知概率,从而构造决策权重函数;将备选方案离散化后的随机变量作为动态参考点,构造价值函数;进而利用熵权法计算属性权重;运用证据推理将各属性前景值和属性权重进行信息融合,最终获得各方案综合前景值。该方法在决策时不仅考虑将决策者行为因素,同时也能够给出全方案排序。
1 问题描述
考虑一个具有属性权重未知的正态随机多属性决策问题,设有m个备选方案,记为A={A1,A2,...,Am} ,n个评价属性,记为C={c1,c2,...,cn} ,各属性间相互独立。方案Ai(i=1,2,...,m) 关于属性cj(j=1,2,...,n)的属性值Xij为连续型随机变量,Xij服从参数为μij和σij的正态分布,记为分别为均值和方差。在属性值Xij的连续区间内有N种取值情况,其取值概率未知,即属 性 权 向 量 为,属性权重未知。D=(Xij)m×n为初始随机决策矩阵。试确定这些备选方案的排序并择优。
2 决策方法
运用证据推理-前景理论对正态随机多属性问题进行决策时,需要构建决策权重函数和属性价值函数,并对得到的属性前景值进行融合,进而计算备选方案综合前景值。前景理论的核心在于计算现有水平与参照点的偏离程度,由于备选方案属性值均为正态随机变量,不便直接进行运算,所以将属性值离散化,求得属性值离散区间的具体数值。该方法不仅便于对正态分布随机变量进行运算,更有效降低了将随机变量作为区间数进行运算而忽略区间内部具体变化所导致的误差。具体决策方法如下:
2.1 构造Mass函数,计算离散区间属性值概率
首先,将正态随机变量Xij离散成连续的子区间,并确定各随机变量每个区间的基本概率分配,然后利用Pignistic概率转换方法求出概率值。
在正态分布空间中对随机变量进行区间划分,确立上下界。即根据正态分布的3σ原理,随机变量Xij~N会落在区间(μ-3σ,μ+3σ)范围内,即为对应的上下界。各区间相对应的概率密度函数为:
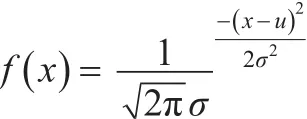
在正态分布空间中,以均值μ作为分界线,分别对U轴的正向和负向进行划分,分成N个区间,则分界线两边区间数为N 2,每等份为假设随机变量X的离散值为zijk,则zijk=(μijk-3σijk)+k·Δij(k=0,1,...,N) 。 设第k个小区间的范围为[Uk,Uk+1],则第k个区间对应的基本概率分配值为:
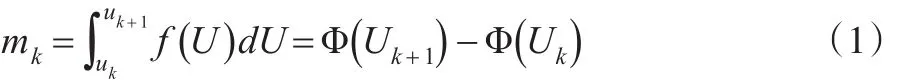
mk表示对区间k的精确信任程度,当Mass函数仅在识别框架的单点子集上定义时,表示为概率,即Pijk=mk。为保证最后求解的概率之和为1,对其归一化处理,即:

2.2 参考点确定及属性前景值矩阵构建
前景理论考虑决策者面对不确定信息进行决策时是有限理性的,在对备选方案进行评估或预测时会选择一个参考点。目前相关研究一般会都是假定参考点为固定的。但在实际决策时,参考点是可以改变的[7]。当参考点改变时,备选方案相对参考点来说可能为收益或者损失,从而最后得到的前景值为收益和损失的综合值,避免了参考点固定时前景值仅为收益或者损失的情况,使其评价结果更为合理[12]。
针对正态随机多属性决策问题,本文将其他备选方案作为动态参照点。由于属性值为正态随机变量,若将其区间化会忽视其区间内的具体变化趋势。因此,本文将随机变量离散化,将各备选方案属性值中每一个区间的ztjk(t =1,2,...,m) 与zijk一一对应,求解得到的属性前景值可避免属性值数量较少且只取一个参照点时存在极值的情况,有助于提高属性间区分度。同时降低将其他备选方案属性值作为参照点时的数据影响,提高备选方案的区分度和决策结果实际应用价值。具体如下:
首先,将各备选方案的属性离散值ztjk作为动态参考点,可以得到各属性离散值的价值函数:
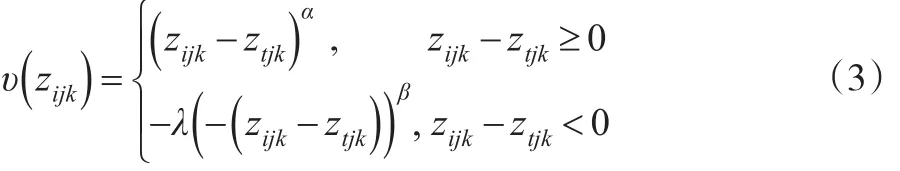
然后,根据属性离散区间在自然状态下的发生概率pijk,计算离散值zijk面临“收益”和“损失”的决策权重:

根 据 文 献 [13],取α=β=0.88,λ=2.25,γ=0.61,δ=0.69。运用公式(3)、公式(4)可得到各属性前景值:
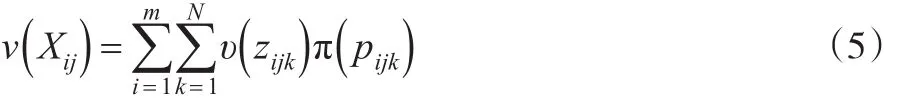
由此,初始决策矩阵D=[xij]m×n转换为属性前景值矩
2.3 属性权重计算
信息熵作为一种测量信息量的有效工具,在计算过程中可以降低人为主观因素所造成的偏差。为此,有部分学者将信息熵引入决策领域,将其作为一种决策属性权重求解方法[14,15]。借助于文献[15]的思想,对属性权重值进行计算。
首先,计算离散后的属性值与各动态参考点之间的证据距离:

进而得到该属性的距离熵:

其中

2.4 计算备选方案综合前景值
证据推理的信息合成规则可以在没有任何先验信息的条件下实现证据的融合。首先,将问题描述中方案Ai所在的识别框架设为Θi,方案Ai的属性值作为证据。而属性值ν(Xij)作为证据对Xij的置信度。
Mass函数构造如下:
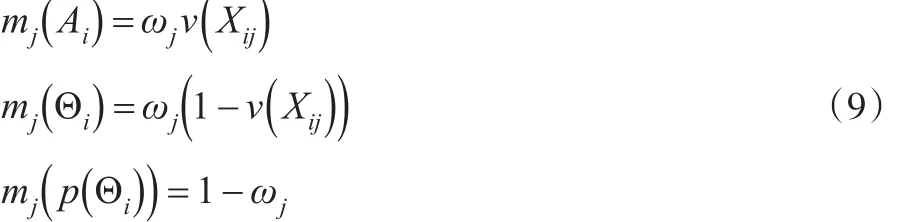
其中,i=1,2,...,m;j=1,2,...,n;mj(Ai)是属性值cj的基本信任分配函数,表示证据对方案Ai的支持度;mj(p(Θ ) )表示未指派给任意方案Ai的支持度。对k+1个证据进行融合,得到如下合成公式:
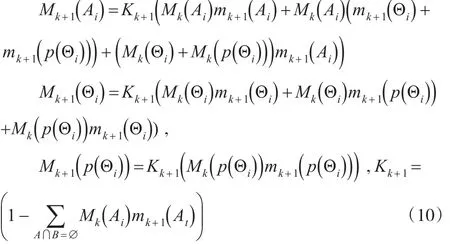
其中i,t=1,2,...,m;j=1,2,...,n。通过对所有n个证据进行组合,最终可以获得方案Ai的综合前景价值[16]:

根据公式(11)得出的综合前景值进行排序,综合前景值越大则方案越优,进而得到最优备选决策方案。
综上所述,该方法决策步骤如下:
步骤1:将正态随机变量离散化,利用证据理论将概率密度函数转化为基本信任分配函数,并根据式(1)、式(2)计算自然状态下正态分布离散区间的属性值概率;
步骤2:以其他备选方案为动态参考点,利用式(5)求解各属性前景值;
步骤3:基于距离熵和熵权法对离散后的正态随机变量进行处理,通过式(8)计算属性权重;
步骤4:运用式(11)计算各备选方案的综合前景值,并进行方案排序。
3 算例分析
利用文献[16]中的算例来验证本文提出方法。考虑某风险投资公司对一个项目进行投资,现有5个投资方案(A1,A2,A3,A4,A5) ,考核指标即决策属性指标:投资额 C1(万元),风险损失值C(2万元),风险盈利值C(3万元)。每一个方案Ai所对应属性值Ci的评价结果均为正态随机变量,初始决策矩阵D(见表1)。试确定最优投资方案。
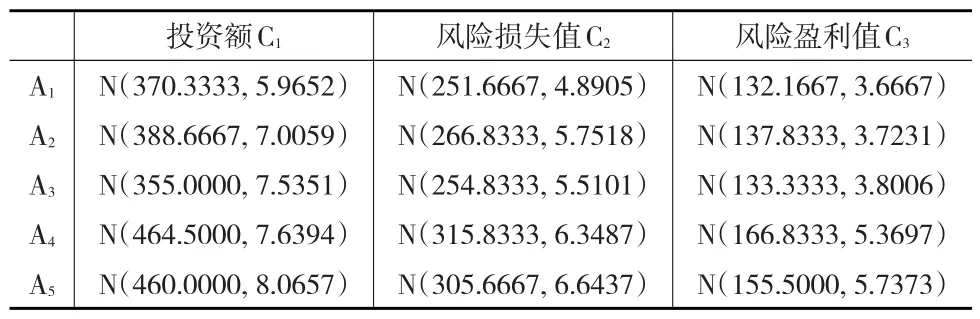
表1 初始随机决策矩阵D
首先将正态随机变量离散成N个数据,N随机取值为100。利用式(5)求得各备选方案下属性前景值(见表2)。

表2 N=100时,备选方案的属性前景值
求得属性前景值后,运用距离熵结合熵权法,通过式(8)求解属性权重(见表3)。

表3 N=100时,属性权重
最后运用式(11)将属性前景值和属性权重融合,求得各方案综合前景值,可得各方案的排序结果为A3≻A1≻A2≻A5≻A4,最优方案为A3(见表4)。

表4 N=100时,备选方案的综合前景值
进一步将属性值离散为1000个数据,即N=1000,计算备选方案Ai(i=1,2,3,4,5) 关于属性cj(j=1 , 2, 3) 的前景值(见表5)。
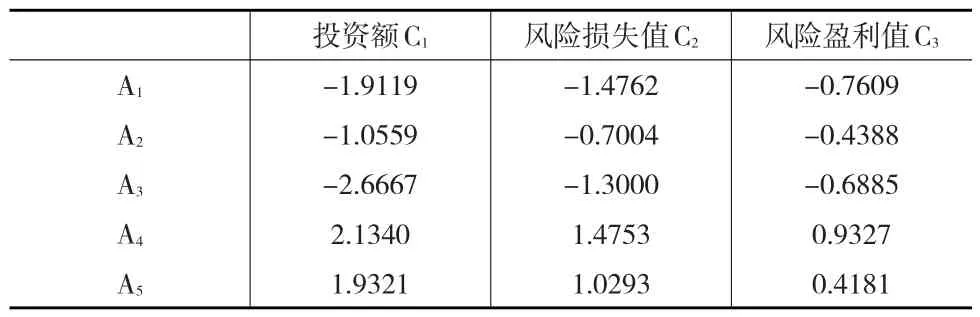
表5 N=1000时,备选方案的属性前景值
求解得出属性前景值,进一步求解属性权重(见下页表6)。

表6 N=1000时,属性权重
如表7所示方案的排序结果为A3≻A1≻A2≻A5≻A4,方案A3最优。

表7 N=1000时,备选方案的综合前景值
由于篇幅所限,不将N所取数值全部列出,图1反映离散数据N变化时方案的排序结果。

图1 不同离散区间数下各方案综合前景值的变化趋势
由图1可以看出当N的值逐渐增大时,备选方案排序结果保持不变。表明在离散数量不同的情况下备选方案排序具有一致性、稳定性。本文备选方案排序为A3≻A1≻A2≻A5≻A4,其中方案A3为最优决策方案。文献[16]的排序结果为A3≻A1≻A2≻A4≻A5,最优方案相同,对比得出排序结果基本一致。
方案4和方案5的排序有所变动,从表1可以看出方案5在“投资额”、“风险损失值”上的属性值均低于方案4;而由图1可以看出,方案5的综合前景值随离散区间数量变化时,相较于方案4更加稳定。根据前景理论中的风险规避原则,当决策者面临盈利能力相当的决策方案时,更倾向于接受稳定性较高的盈利方案。因此,在考虑决策者偏好时,判定方案5优于方案4更加合理。
4 结论
针对属性值信息不完全的正态随机多属性决策问题,本文给出一种基于证据推理-前景理论的正态随机多属性决策方法。将连续型正态随机变量离散化,运用Mass函数获取属性离散区间概率值,有效处理了属性值在自然状态下离散区间内发生的未知概率。并且在实际决策过程中,前景理论考虑决策者期望,更加符合现实生活中人的决策情况。结合熵权法获取客观权重,避免专家决策的主观影响;利用证据推理进行信息融合,减少计算过程决策信息丢失。
与已有的正态随机多属性决策方法相比,本文具有以下优点:
(1)运用证据推理有效处理了正态随机变量中离散区间属性值概率难以获取的问题,同时又保证方案最后排序时的决策信息丢失最少;
(2)决策时通过决策参照点变化来反映决策者有限理性的行为特征,这符合人类决策思维,符合决策者的真实选择;
(3)随机变量离散区间数产生变化时,方案排序结果保持不变,具有较强的稳定性。实际决策中可根据决策者需求选择不同的离散区间数量;
本文所提出的方法为解决权重未知、属性值为正态随机多属性决策问题,提供了一条新的途径,不仅对不确定性证据进行客观处理,并且更加贴近决策者实际情况,保证计算步骤中信息丢失最少,使决策结果更加科学精确。
猜你喜欢
建材发展导向(2021年6期)2021-06-09
湖北农机化(2020年22期)2021-01-18
矿产勘查(2020年6期)2020-12-25
今日农业(2020年17期)2020-12-15
浙江大学学报(理学版)(2020年6期)2020-12-07
中国外汇(2019年11期)2019-08-27
数学学习与研究(2019年8期)2019-06-21
消费导刊(2019年3期)2019-01-28
自动化学报(2017年2期)2017-04-04
太空探索(2016年10期)2016-07-10
