
基于拓扑稀疏编码预训练CNN的视频语义分析
2018-12-20 01:23程晓阳詹永照毛启容詹智财
计算机研究与发展 2018年12期
程晓阳 詹永照 毛启容 詹智财
(江苏大学计算机科学与通信工程学院 江苏镇江 212013)
近年来,随着互联网、多媒体设备的发展,网络多媒体视频数据呈几何级数增长,对无场景限制视频进行高层语义概念提取和识别技术具有愈加广阔的应用前景.同时,传统视频分类方法如基于标签文本的关键字匹配[1],在应对互联网海量视频数据及视频内容复杂度区分方面表现有待提升,而基于原始视频图像帧的全局特征(颜色、边缘检测、Gabor等)或先获取局部特征(Sift,MoSift等)[2-3],紧接着应用BoW等方法[4]将局部特征转换成全局特征描述,最后载入分类器的方法都不可避免手动设计特征提取方法的问题.当前,深度学习方法通过逐层特征变换,将样本在原空间的特征表示变换到一个新的特征空间[5],从而更加方便分类与预测,在计算机视觉、语音识别和自然语言处理等方面取得成功应用[6].在基于深度学习的视频语义分析研究领域,Wu等人[7]提出基于多线性主成分分析的深度学习模型(multilinear principal component analysis network, MPCANet)进行视频高层语义特征的学习和目标分类.Liu等人[8]提出基于堆叠过完备独立成分分析的模型(overcomplete independent component analysis, OICA)学习视频时空特征进行视频动作识别.Gammulle等人[9]提出基于卷积神经网络(convolu-tional neural network, CNN)和长短期记忆网络(long short-term memory, LSTM)结合的人体动作识别方法.研究表明:深度学习方法在提高视频语义分析准确性方面有重要作用.
对比手写体等图像目标识别任务,视频图像内容更复杂,表现出目标的旋转、缩放、平移等现象,所以需要在视频语义检测中使用的特征提取器在应对复杂现象时表现出鲁棒性,获取更多不变性的表征.Andrew等人[10]指出视网膜上视神经元具有相邻相似性,即当前神经元的激活会影响到周边神经元的激活程度,这样的近邻关联能够帮助特征学习中形成具有秩序性特征.Hyvärinen等人[11]在独立成分分析(independent component analysis, ICA)模型加入拓扑约束得到能够保证近邻成分具有强相关性的拓扑独立成分分析(topographic independent com-ponent analysis, TICA)并验证该拓扑特性对研究图像识别问题的益处,相似的实验[12-13]表明这种拓扑关联性具有较好的物体旋转、缩放、平移的不变性.考虑以往研究用于视频图像特征学习的卷积神经网络[14-17]主要关注于网络结构模型的设计,未考虑利用相邻神经元节点拓扑结构相关性信息,同层卷积核缺乏相关性的缺陷.本文引入与TICA相似的拓扑约束,并且考虑到隐层神经元特征空间排布的特性,结合结构化稀疏关联关系分析[18],提出考虑以平面神经元节点的拓扑结构关联关系作为拓扑结构约束项,形成新的拓扑稀疏编码器用作神经网络模型预训练[19],用以增加参数学习过程中的正则化,学习符合视频图像拓扑结构信息的视频图像特征表达.本文方法实现包括:1)对稀疏自动编码器(sparse auto encoder, SAE)[20]引入拓扑约束得到拓扑稀疏自动编码器(topographic sparse auto encoder, TSAE);2)在视频图像数据上基于TSAE构建无监督学习模型,作为神经网络的预训练模型[21],同时在其全连接层以有视频概念标签的视频图像进行逻辑回归微调网络参数,得到基于视频序列帧图像的特征提取器;3)构建视频全连接层特征映射,对全连接层也以有视频概念标签类别的视频进行网络参数的微调,学习得到基于视频段的特征表达;4)将此特征表达送入SVM中做建模和语义概念分类分析.为了验证本文特征提取方法的有效性,在TRECVID 2012,UCF11这2类视频数据集上与多种算法进行对比,实验结果表明:引入拓扑约束的预训练神经网络提取的特征分类效果更好.
本文的贡献主要有2个方面:
1) 考虑图像边缘性和神经元的近邻结构关联性,考虑加入新的拓扑结构信息约束项形成拓扑稀疏编码器,在视频图像特征的半监督学习中,用于预训练神经网络权重因子,使深度网络所学习的视频图像特征具有拓扑秩序信息;
2) 在视频特征学习的全连接层,综合有标签的视频序列的关键帧特征,建立逻辑回归约束,微调网络参数,实现了类别更具可鉴别的视频序列特征的优化.
1 相关工作
1.1 稀疏自动编码
SAE作为无监督训练模型自动学习一种非线性映射来提取输入数据的特征,如图像的边和拐角等.SAE模型的代价函数为

(1)
(2)
(3)
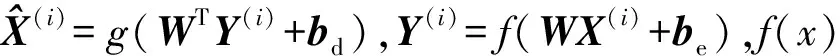
1.2 拓扑稀疏编码
稀疏编码作为稀疏自编码方法的变形,该模型学习目标是通过迭代直接学习数据的特征矢量和基向量.Andrew等人[10]在稀疏编码模型引入拓扑性约束形成拓扑稀疏编码,学习到具有某种“秩序”的特征矢量.拓扑稀疏编码的目标函数为

(4)
其中,对输入样本x,s表示样本数据的稀疏特征矢量,A表示将特征矢量从特征空间转换到样本数据空间的基向量.式(4)右边第1项是基向量将特征矢量重构为样本数据所产生的误差;式(4)右边第2项为权重衰减项,以保证基向量的每一项值足够小;式(4)右边第3项为拓扑稀疏惩罚项,ε用作“平滑参数”,拓扑特性的获得通过将用于图像特征提取的特征矢量s按2D矩阵的行排布成网格形式的方阵,当以某个特征节点为中心进行考虑时希望以网格中该节点周边相邻接区域的特征节点具有相似性,对应相邻区域为大小3×3的窗口方阵构成近邻分组,该分组在网格方阵上有部分重叠的滑动,并且分组窗口可以跨越2D矩阵的边界,以使每个特征节点都具有相同大小的近邻区域,将网格中相邻节点进行分组并按平滑的L1范式惩罚实现拓扑稀疏惩罚.计算上进一步将“分组”使用“分组矩阵”V实现,对应矩阵V的第r行标识根据邻接关系被分到第r组的特征节点,即特征节点c分到第r组则Vr,c=1.Kavukcuoglu等人[23]通过加权分组实现相似的拓扑特征过滤器映射,证实添加拓扑约束可以获得对图像旋转、缩放、平移局部不变性的特征,学习特征表达能反映图像的拓扑信息.以上方法在构建拓扑结构关联时,对每个特征节点生成相同大小的近邻分组.但是在用于视频图像特征学习时,未考虑视频图像边界非连续的特性.
本文针对视频图像目标提出考虑以平面神经元节点的拓扑结构关联关系构建拓扑结构约束项的新的拓扑稀疏编码器,用于学习更符合视频图像拓扑结构信息的特征表达,进而提高视频语义分析的准确率.
2 基于TSAE预训练CNN的视频特征学习
本文提出的基于拓扑稀疏编码预训练CNN视频特征学习如图1所示.该模型学习分为2个阶段:视频图像特征半监督学习阶段和视频段特征有监督优化学习阶段.对每一段视频按视频帧图像输入,经过无监督拓扑稀疏预训练的神经网络学习视频图像拓扑秩序信息特征,同时在其全连接层(FC1)以有视频概念标签的视频图像采用Softmax进行网络参数微调,从而学习获得视频图像特征;再将有概念标签的视频关键帧的图像特征通过经Softmax优化的全连接层(FC2)学习获得视频段特征;最后将视频段特征送入SVM进行视频语义概念建模与检测,其中网络的层次和其参数的设置是由实际实验的结果而确定.

Fig. 1 The overall framework of video image feature learning based on topographic sparse pre-training CNN图1 基于拓扑稀疏编码预训练CNN视频图像特征学习的整体框架
2.1 基于新的TSAE预训练CNN图像特征学习
卷积神经网络的设计包括卷积核、非线性激活函数设计和池化处理,卷积核的参数可通过无监督的稀疏自动编码器预训练学习获得.传统SAE学习特征不考虑相邻神经元节点提取特征的关联性.对于图像数据,某处像素点的值总是与周边像素点值密切相关,而在视觉神经网络中视神经元具有相邻相似性,故当前位置的像素值在输入神经网络中,如果当前神经元被激活,那么其附近神经元也应具有相似或相近的激活状况,因此在神经网络的学习中可以充分考虑这种周边结构状态相似性而形成拓扑分组加以约束,有助于视频图像特征的学习能获得某种“拓扑秩序”.为了使提取的图像特征表现出特有的拓扑秩序,即相邻神经元激活态相似,在稀疏编码中再加入神经元周围相邻的神经元激活值特征形成矢量的模作为约束项,从而建立拓扑稀疏编码.如图2所示,对于方形浅灰色(绿色)的神经元,其拓扑关联的神经元为方形深灰色(红色)神经元.TSAE模型将隐层编码神经元节点依照二维矩阵按行排布,为实现上的方便性,我们将隐层神经元节点基于相邻关系进行分组.每个隐层节点与其周边邻接的节点形成一个分组,即当以某个神经元为中心进行考虑时,希望在二维矩阵排布网格中该神经元周边相邻接区域的神经元具有相似性,以相邻区域窗口方阵构成近邻分组,以第1行、第1列开始是一个分组,第1行、第2列是另一个分组,分组在网格方阵上有部分重叠的滑动,结合分组矩阵的分组关系,可在式(1)的稀疏编码模型上加入分组的隐层状态矩阵的L2约束惩罚,形成相邻节点特征相似性的拓扑约束.

Fig. 2 The architecture of topographic sparse auto encoder图2 拓扑稀疏自动编码器结构图
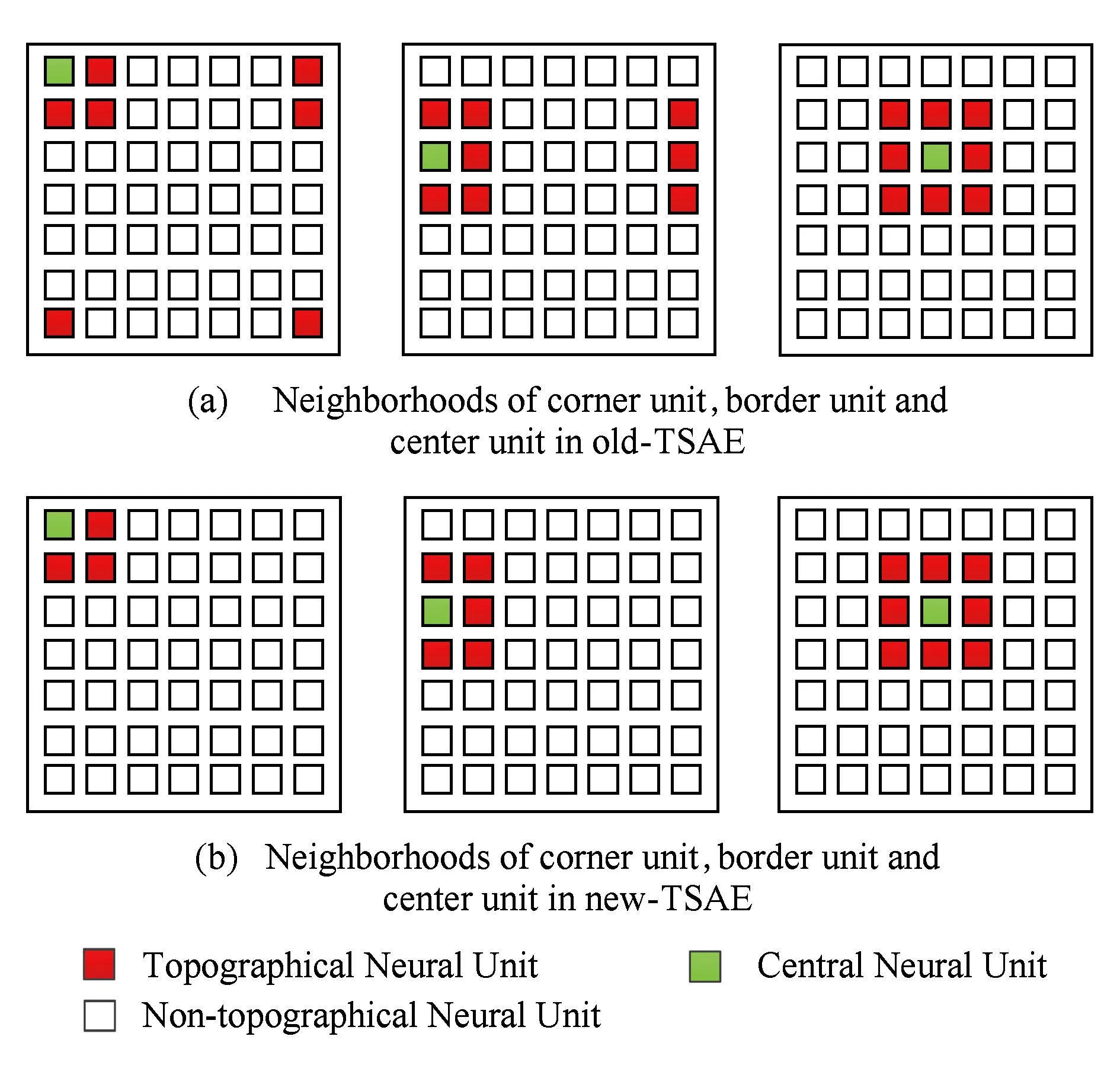
Fig. 3 Different neighborhoods for two kinds of TSAE图3 2种不同拓扑稀疏编码方法的近邻分组
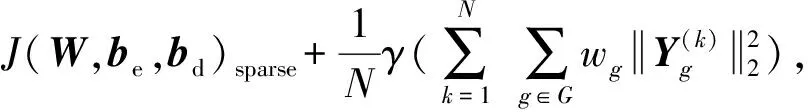
(5)
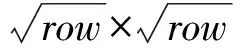
(6)
按行顺序编号的第i个神经元节点分在第r分组gr要满足的条件是:
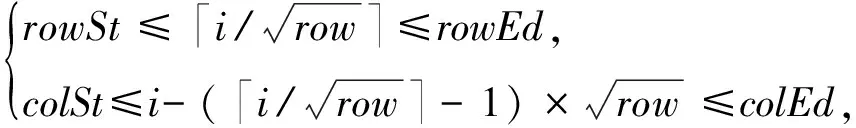
(7)
这里topoArea是邻接域半径,选择为1,即邻接域最大为3×3的矩形区域,分组间是有部分重叠的,各节点与邻居节点形成分组,各分组内部邻接节点数是不同的,隐层角点邻接域最小为2×2,边上点邻接域2×3,其他点最大邻接域3×3,分组内节点数倒数作为该分组节点拓扑约束权重因子,记为wg,这样的分组结构不同于old-TSAE中所有节点具有相同的邻接节点数,形成环状拓扑结构的邻接域.
本文通过拓扑稀疏编码模型预训练CNN,进而通过对深度卷积神经网络(deep convolution neural networks, DCNN)进行逐层[24]无监督学习视频图像的特征,在全连接层也进行拓扑稀疏编码模型预训练神经网络并用视频类别标签进行视频帧图像的监督优化学习.由于视频是彩色视频,将每一幅视频图像归一化为64×64,相应DCNN模型结构为:输入图像尺寸为3×64×64,第1个卷积层由ker1个尺寸3×vh1×vw1的卷积核构成,CNN处理得到特征图使用尺寸2×2的均值池化;第2个卷积层使用ker2个尺寸ker1×vh2×vw2卷积核,该层CNN处理得到的特征图使用尺寸2×2的均值池化,得到ker2×vh3×vw3特征,其中vh3=((64-vh1+1)2-vh2+1)2,vw3=((64-vw1+1)2-vw2+1)2;第3层为隐层节点数为H1的全连接层,对前一层输出特征经过全连接层映射得到H1×1的特征,即每幅输入图像经过DCNN提取得到维度为H1的矢量.
基于拓扑稀疏编码预训练DCNN的视频图像特征学习步骤有4个:
步骤1. 为第1个卷积层选择ker1个神经元节点,根据卷积核大小3×vh1×vw1,将训练集视频的全部RGB彩色视频图像帧分割成尺寸3×vh1×vw1的图像块,得到nBlock1图像块用于TSAE,经矢量化转换成nBlock1个具有col1=3×vh1×vw1个输入特征的矢量,按式(5)的拓扑编码经梯度下降优化求解预训练网络参数W1,be1和bd1.
步骤2. 将预训练得到的网络参数W1和be1作为第1个CNN层网络参数初值,将训练集中所有视频的每一帧图像输入到第1层CNN进行无监督特征学习和池化,得到的输出作为第2层CNN预训练模型的输入,即得到nFrames个ker1×(64-vh1+1)2×(64-vw1+1)2的特征图.
步骤3. 类似于第1层CNN的预训练,进行第2层CNN无监督预训练.将nFrames个ker1×(64-vh1+1)2×(64-vw1+1)2的特征图进行图像分块,此时对于单个特征图分割成尺寸大小为ker1×vh2×vw2的图像块,得到nBlock2图像块用于TSAE,经矢量化转换成nBlock2个具有col2=ker1×vh2×vw2个输入特征的矢量,按式(5)的拓扑编码优化求解预训练网络参数W2和be2,将预训练的网络参数W2和be2作为第2个CNN层网络参数初值,进行第2层CNN的无监督特征学习和池化,得到nFrames个ker2×vh3×vw3的特征图.
步骤4. 在全连接层(FC1),也类似于CNN的预训练方法,将nFrames个ker2×vh3×vw3的特征图进行TSAE优化求解预训练具有隐层节点数为H1的全连接层的网络参数初值,进行无监督特征学习.同时用有视频类别标签的视频帧图像进行监督优化学习.优化时,选择使用基于回归模型的Softmax对L个类别的分类最小化代价,进行全连接层网络参数优化微调.
在优化微调中,设第i帧的图像特征为x(i),其中x(i)的特征维数为col3=ker2×vh3×vw3,视频图像类别为y(i),将所有有标签的视频图像特征x(i)(i=1,2,…,N)连接到H1×1大小的FC1得到视频图像特征F(i)=gwf1,bf1(x(i)),全连接层映射函数为
gwf1,bf1(x(i))=sigmoid(Wf1x(i)+bf1),
(8)
其中,Wf1,bf1为FC1层网络因子权重和偏置参数,则分类假设函数为
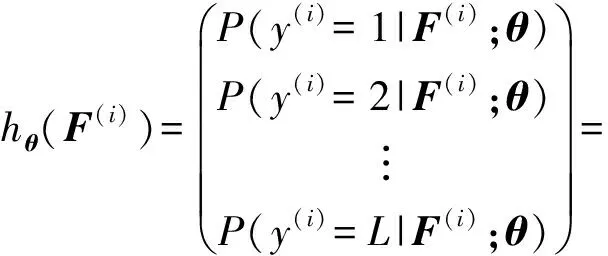
(9)
为了帮助优化全连接层神经网络(FC1),分类目标的最小化代价函数为
J(θ,Wf1,bf1)=
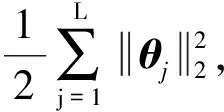
(10)
其中,θ为Softmax模型参数;Wf1;bf1为全连接层参数;1{y(i)=j}为示性函数,条件真时取值1否则为0.
经过Softmax模型对全连接层网络(FC1)参数优化微调,FC1即可学习获得视频帧图像特征.
2.2 视频特征优化学习
对比图像识别任务,视频语义概念的检测是通过有序的视频图像信息完成语义概念检测任务,然而即使短的视频序列也会包含很多的图像帧,相似的图像帧导致冗余数据和噪音存在[25-26].实验证实基于视频关键帧也能有效实现视频事件的检测[27].本文视频段特征学习是用有视频概念标签的视频序列关键帧图像经过深度CNN获取视频图像特征,组成一个向量的视频段特征后连入全连接层,并进行优化学习.
对任意输入视频,对视频序列提取m个关键帧,对图像帧统一缩放到大小为64×64来表达视频序列信息.关键帧图像经过拓扑稀疏预训练的卷积神经网络提取得到视频图像特征,将关键帧的图像特征构建成视频序列特征V(i),V(i)表达为
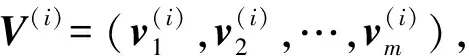
(11)

对视频的序列化关键帧的全局特征构建全连接神经网络(FC2),将所有有标签的视频序列特征V(i)(i=1,2,…,M)连接到H2×1大小的全连接层(FC2)得到视频特征,对应映射函数为
gwf2,bf2(V(i))=sigmoid(Wf2V(i)+bf2),
(12)
其中,Wf2,bf2分别为全连接层(FC2)的权重、偏置参数.在该全连接层视频特征学习中,选择使用基于回归模型的Softmax对L个类别的分类最小化代价,进行FC2网络参数优化微调.
经过Softmax模型对全连接层(FC2)优化学习后得到基于深度卷积神经网络的视频段全局特征提取器,分别用于提取视频训练集和测试集的关键帧序列特征,将训练集特征和标签用于训练SVM,将测试集的特征作为SVM的输入进行视频语义概念检测分析.
3 实验结果与分析
本文采用视频集Trecvid 2012和UCF11.其中Trecvid是由美国国家标准与技术研究院(NIST)主导的视频数据集,该数据集中每个视频帧速范围为12~30 fps,分辨率范围从320×640到1280×2 000.我们从中选取了10个类别:AirplaneFlying, Baby, Building,Car,Dog,Flower,Instrumental-Musician, Mountain,SceneText,Speech,并且为了数据的平衡,每个类别分别选择30个视频构成整个数据集,总视频图像帧数为21 500;UCF11数据集中有11个动作类别:Basketball,Biking,Diving,Golf swinging,Horse riding,Soccer juggling,Swinging,Tennis swinging,Trampoline jumping,Volleyball spiking,Walking,每个类别中分别有25个组,每组中有超过4个视频,我们从中选取共1 590个视频构成第2个数据集.图4为本实验数据集的部分关键帧图像.在数据集的处理上,首先对每个视频进行了统一的格式转换,然后将原视频转帧换成统一大小的彩色图像.实验环境为i7处理器和GTX 780 ti显卡,并基于python,CUDA6.5,theano 0.7基础实现.对于图像特征学习的网络结构参数的设置,我们经过反复实验调试,最终选择设置第1个卷积层的卷积核数ker1=225,核大小的vh1=vw1=7,第2个卷积层的卷积核数ker2=400,核大小的vh2=vw2=8,第1个全连接层隐层节点数H1=400.

Fig. 4 Part keyframes from datasets图4 视频数据集的部分视频关键帧
3.1 在Trecvid数据集上模型参数的选择与实验结果
在Trecvid数据集上,采用每次随机抽取120个样本为测试集,其他为训练集,视频关键帧数为3.实验结合文献[28]的超参数调整指导思想,经过多次实验,考虑网络综合性能最佳的情形,对参数进行了的优选设置,β=5,无监督学习率为1E-3,无监督学习批量为300,迭代次数为2 000;在监督优化学习时,学习率为1E-3,批量大小为30,迭代次数为3 000.考虑稀疏性参数ρ、权重惩罚项系数λ、拓扑权重惩罚项系数γ对模型分类精度的影响.本文对无拓扑稀疏编码、边界相连的拓扑稀疏编码和边界不相连的拓扑稀疏编码均做了优化选择,以其预训练CNN学习视频特征并用于视频语义概念检测的准确率最高的情形,确定相关参数的选择.
权重惩罚参数初始固定为0.001,稀疏性参数ρ的选择影响到特征的学习和最终用学习特征进行分类结果,如图5(a)可见,稀疏性参数很小时准确率很低,稀疏参数选择0.25时,获得最佳识别效果,因此在Trecvid数据集稀疏参数选择0.25最合适.对权重惩罚稀疏选择如图5(b),增加权重惩罚项系数可使过滤器权重参数下降加快,但可能导致权重惩罚过度,结合不同权重惩罚系数实验准确率,权重罚项系数选择0.003.在Trecvid数据上对拓扑项权重参数的选择进行实验,结果如图6所示最终拓扑权重参数选择0.003.

Fig. 5 The sparse and weight lambed parameters selection on Trecvid dataset图5 在Trecvid数据集稀疏参数、权重参数选择

Fig. 7 Visualization of filters learned by different pre-train models图7 不同预训练对应过滤器的权重可视化图

Fig. 6 Recognition rate of algorithms with different values of γ on Trecvid dataset图6 在Trecvid数据集参数γ不同值时识别准确率
结合以上实验参数,本文将无拓扑稀疏编码、边界相连的拓扑稀疏编码、边界不相连的拓扑稀疏编码模型应用到视频库随机切分的无标签图像块上进行无监督学习.对比展示这3种预训练方法的过滤器权重值可视化效果如图7所示.图7是以第1层CNN学习视频帧特征的7×7×3RGB图像块的神经元所对应过滤器权重值情况.从图7中对400个神经元所对应过滤器权重可视化可以看出,在非拓扑稀疏编码模型的神经元只能对数据中稀疏的信息进行响应,并且呈现出无序形式;而对于边界相连的拓扑稀疏编码的情况,通过添加拓扑约束,稀疏编码器所学到的特征具有周边相似性,权重可视化呈现出旋状渐变趋势,即当前的神经元如果对某一方向的边缘发生响应,则周边的神经元会对稍微偏离前者的方向进行响应,使之能够学习到更有序的特征.但对上下、左右边界神经元均具有相似的响应权重.相比于边界相连的拓扑稀疏编码和本文提出的边界不相连的拓扑稀疏编码,它同样具有所学到的特征具有周边相似性,同时消除了对上下、左右神经元均具有相似的响应权重,即过滤器权重对特征空间上下边缘、左右边缘无需这种相似性约束.事实上,视频图像的上下、左右边缘并非是连续的空间,因此,采用所提出的拓扑稀疏编码预训练CNN用于学习视频图像的特征,更符合视频图像的表达.
对全连接层(FC2)单元个数的选择也进行了实验.从表1可以看出,对于全连接层神经元为300时,训练集和测试集的准确值小于其他情况;而当神经元个数超过400时,准确值有所下降;随着神经元个数的增加,所需要训练的时间也不断增大,在考虑准确值和所需要的时间基础上,本文选择400作为全连接层的神经元个数.
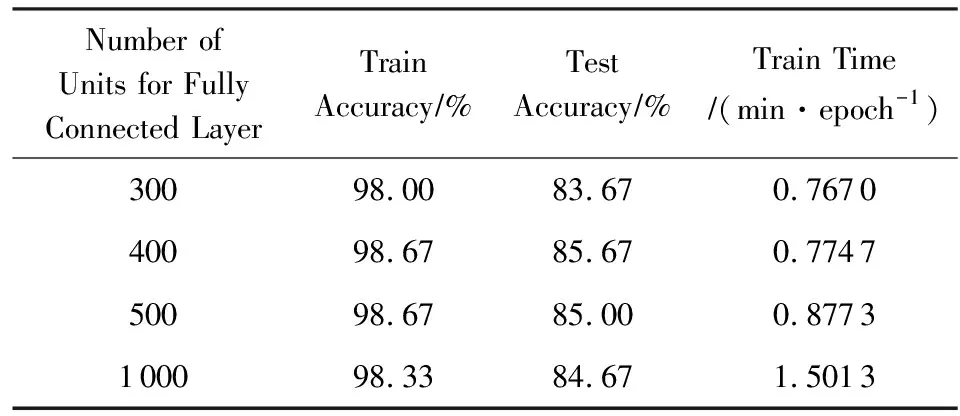
Table 1 Accuracy and Train Time with Different Number ofUnit for Fully Connected Layer
实验同时在优选参数的基础上,对比检验当本文模型使用不同层数的预训练卷积神经网络的实验效果,以及对比分别使用Softmax和SVM这2种不同语义概念检测方法的实验结果,如表2所示,实验结果可见单层预训练卷积层实验结果最低,而预训练的卷积层为2层、3层时,神经网络识别表现比较稳定,综合各方面考虑所以最佳的预训练卷积层次为2层卷积预训练.同时对比直接使用Softmax进行语义概念检测和经过Softmax优化后将特征送入SVM进行语义概念检测,结果表明使用SVM建模预测效果较好,因此本文模型选择使用2层卷积预训练,并经过Softmax进行视频段特征优化学习,最终使用SVM建模进行视频语义概念的检测.
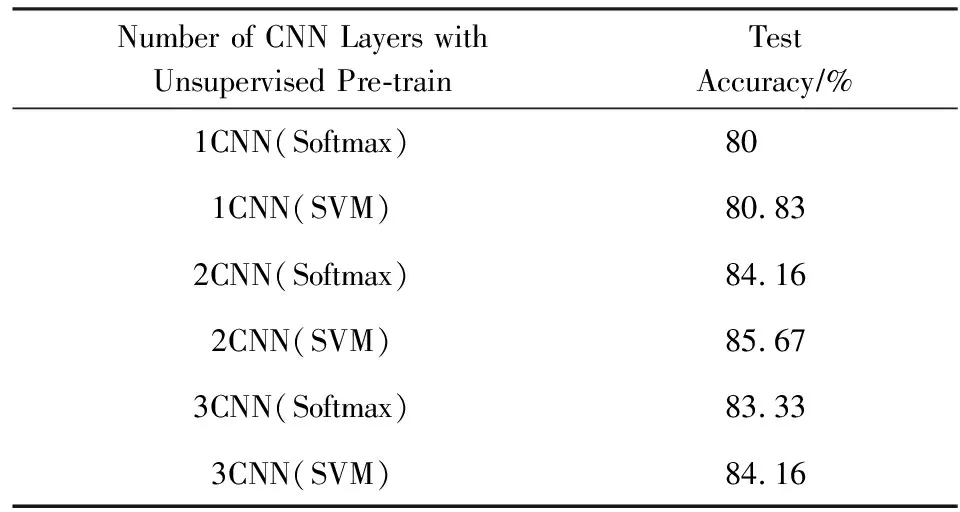
Table 2 Accuracy with Different Number of CNN Layerwith Unsupervised Pre-Train
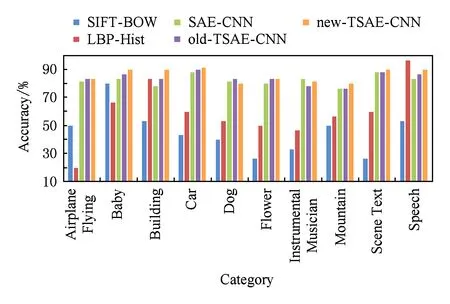
Fig. 8 Category on 10 semantic concepts from Trecvid2012图8 在Trecvid2012数据集10种语义上的识别准确率
本文选取多种不同的特征提取和深度学习方法进行了10倍交叉实验.SIFT-BOW表示先对关键帧序列分别提取SIFT算子,然后采用BOW方式将其转换成的全局特征[29];LBP-Hist表示先对关键帧进行LBP的特征提取,然后采用直方图的形式将其转换成全局特征[30];SAE-CNN是采用SAE进行CNN预训,用CNN学习视频特征;old-TSAE-CNN是使用边界相连的拓扑稀疏编码预训练的CNN,而new-TSAE-CNN是使用边界不相连的拓扑稀疏编码预训练CNN,用CNN学习视频特征.所有视频特征均采用SVM建模和语义概念分类分析.实验比较了SIFT-BOW,LBP-Hist,SAE-CNN,old-TSAE-CNN,new-TSAE-CNN方法在10种语义概念的识别结果,如图8所示,本文提出的new-TSAE-CNN方法对绝大多数的语义概念检测的准确率均优于其他方法.同时与MPCANet和OICA方法的结果进行了对比,各方法平均语义概念识别的结果如表3所示.在Trecvid数据集上基于CNN的模型在语义概念检测,总体结果均优于传统的特征提取方式.验证了与传统的SIFT和LBP特征提取模型相比,CNN模型本身具有较好的泛化能力,对CNN进行预训练可以使CNN模型提取具有特定泛化特性的特征[31].old-TSAE与SAE这2种方法在预训练损失函数上相差拓扑约束项,old-TSAE预训练得到的结果均值优于采用无拓扑的SAE预训练的结果约1.5%,其原因是考虑了拓扑结构关联约束,促使卷积神经网络能提取视频图像中具有周边拓扑结构的信息,获得对视频图像目标旋转缩放等变化的不变性,丰富了视频图像特征的信息表达,有助于提高视频语义概念检测的准确性.本文提出边界不相连的拓扑稀疏编码(new-TSAE)预训练方法,比old-TSAE进一步获得2.0%的识别率提升,其内在原因是考虑了图像边缘非连续的拓扑结构约束,消除了视频图像上下边缘、左右边缘拓扑关联,新的拓扑约束既能保持学习到对视频目标旋转缩放等变化的不变性的特征,又能够消除原有拓扑结构中跨越视频图像区域边界特征关联的干扰,符合视频图像本身的没有跨图像边界关联的特性,促使卷积神经网络能提取更合理表达其拓扑结构信息的视频图像特征,更符合视频图像特征的表达.同时结果也表明本文提出的学习方法检测效果也优于MPCANet和OICA的特征深度学习方法效果.
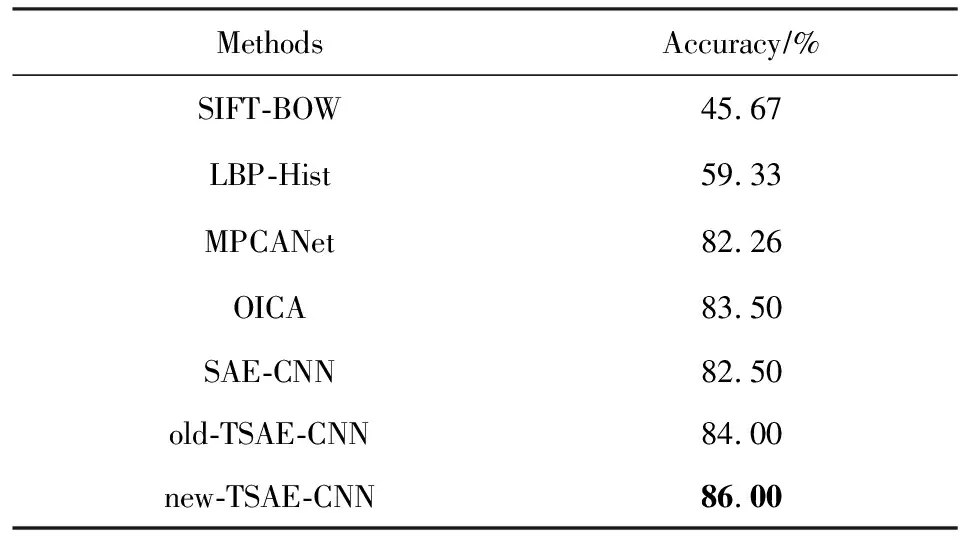
Table 3 Accuracy with Different Approaches onTrecvid Dataset
3.2 在UCF11数据集上模型参数的选择与实验结果
在UCF11数据集每次抽取318个样本为测试集,其他作为训练集,视频关键帧数为3,经过多次实验,β=5,无监督学习率为1E-3,无监督学习的批量为300,迭代次数为1 000;监督优化学习的学习率为1E-3,批量为100,迭代次数为3 000,其网络综合性能最佳.对稀疏性参数ρ、权重惩罚项系数λ、拓扑权重惩罚项系数γ和第2个全连接层神经元节点数的选择进行了实验,稀疏参数选择0.3,权重衰减参数选择0.003,拓扑权重参数选择0.003,第2个全连接层神经元节点数为400,可得到最佳结果.
在数据集UCF11上,采用10倍交叉实验,取平均值得到结果.实验比较了SIFT-BOW,LBP-Hist, SAE-CNN,old-TSAE-CNN,new-TSAE-CNN特征提取方法在11种语义概念的识别结果,如图9所示,本文提出的new-TSAE-CNN方法对绝大多数的语义概念检测的准确率均优于其他方法.同时与MPCANet和OICA方法的结果进行了比较,各方法平均语义概念识别的结果如表4所示.基于预训练CNN的方法在整体上表现优于传统特征提取方法,由于UCF11的样本量比Trecvid多,SIFT-BOW方法能够提取更有效的特征,故性能比LBP-Hist方法好.old-TSAE-CNN比SAE-CNN方法的视频语义概念检测准确率提高了约1.54%,其原因也是因为考虑了拓扑结构关联约束,促使卷积神经网络能提取视频图像中具有周边拓扑结构的信息,有助于提高视频语义概念检测的准确性.new-TSAE-CNN比old-TSAE-CNN方法的视频语义概念检测准确率又进一步提升了1.31%,其内在原因也是因为考虑视频图像边缘非连续的拓扑结构性质,消除了跨越视频图像区域边界特征关联的干扰,使卷积神经网络提取更符合视频图像拓扑结构的特征.同时从结果可以看出,对比相关深度学习方法MPCANet 和OICA,本文提出的方法用于视频语义分析具有一定的优势.

Fig. 9 Category on 11 semantic concepts from UCF11图9 在UCF11数据集11种语义上的识别准确率
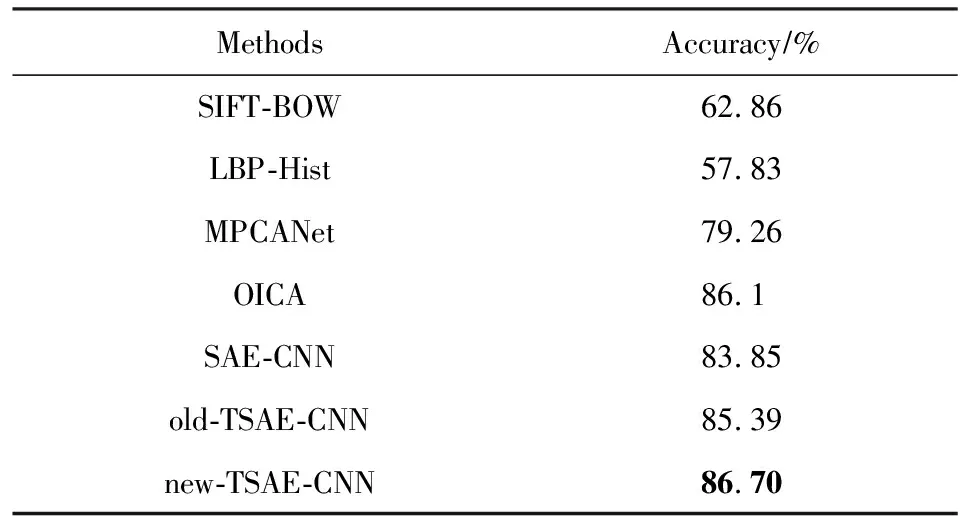
Table 4 Accuracy with Different Approaches onUCF11 Dataset
4 结 论
视频图像的拓扑信息能丰富视频图像特征的表达.本文针对传统的CNN模型未考虑利用隐层节点拓扑结构相关性信息,提出了引入分组的边界不相连拓扑稀疏编码预训练CNN、半监督学习视频图像特征,使卷积神经网络提取视频图像特征能更合理表达其拓扑结构信息,进而将视频段关键帧特征再构建全连接层,进行有监督的逻辑回归优化学习视频特征,从而得到具有反映时空特性的视频段特征表达.在数据集Trecvid 2012和UCF11上与多种相关方法进行了比较实验,实验结果表明:本文所提出的方法能使卷积神经网络提取视频图像特征更合理表达其拓扑结构信息,更符合视频特征的表达,更有助于提高视频语义概念检测的准确性.目前,部分研究将CNN 与LSTM结合学习视频特征,获得了优越的视频语义分析性能,其原因是在视频序列级上LSTM的语义模式表达更合理.下一步的工作,应在本模型上结合LSTM等深度学习方法进一步学习复杂的视频序列特征表达,进一步提高视频语义概念检测效果.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小学生学习指导(中年级)(2021年12期)2021-12-30
电子产品世界(2021年8期)2021-01-16
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
中国计算机报(2019年49期)2019-02-07
疯狂英语·新读写(2018年3期)2018-11-29
中国新闻周刊(2017年36期)2017-10-21
创新时代(2016年8期)2016-10-21
长江学术(2016年4期)2016-03-11
