
基于全卷积网络的中小目标检索方法
2018-12-20 01:10彭天强孙晓峰
计算机研究与发展 2018年12期
彭天强 孙晓峰 栗 芳
1(河南工程学院计算机学院 郑州 451191) 2(河南工程学院国际教育学院 郑州 451191) 3(郑州金惠计算机系统工程有限公司 郑州 450001)
随着大数据时代的到来,互联网图像资源迅猛增长,这种爆炸式的图像增长激发研究人员提出有效的基于内容的图像检索系统.基于内容的图像检索主要包括2种类型:1)给定查询图像,检索出与查询图像相似的图像,这种类型称为整体相似性检索;2)给定特定目标的查询图像,检索出所有包含该目标的图像,这种类型称为中小目标的图像检索.本文主要解决中小目标的检索问题,即给定查询目标,从数据集中检索出包含该目标的图像并定位到目标区域.该问题具有非常广泛的应用前景,比如以图搜图、商品搜索、车辆搜索以及用于视频监控的可疑目标的搜索等.
近年来,深度学习在各种计算机视觉任务上都取得了重大的突破.由于深度卷积神经网络(convo-lutional neural networks, CNNs)强大的非线性表示能力,能够理解图像更深层次的信息,它在目标检测[1]、图像分类[2-3]和图像分割[4]等方面都表现出了良好的性能.将CNNs应用于图像检索任务,主要体现在2个方面:1)在预训练CNNs模型的基础上,提取其中某一层的特征图谱(feature map),对其进行编码得到适用于检索任务的图像特征[5-8];2)基于特定检索任务进行有监督的端到端的训练[9-11].这些算法主要对图像进行整体的特征表示,用于完成图像整体相似性搜索,无法有效完成中小目标的图像检索.另一种是将目标检测的思路应用于图像检索,主要体现在2个方面:1)穷举所有的目标候选区域,然后分别评估这些区域是否包含目标;2)利用训练样本,端到端地学习目标的位置和类别.这些算法虽然可以完成中小目标的图像检索,但是需要特定目标的样本进行端到端的训练,在样本数据相对较少或者无样本数据的情况下,不能有效地完成中小目标的图像检索.
针对以上问题,本文提出一种基于预训练模型的中小目标图像检索算法,在无样本数据进行端到端学习的情况下,能够高效地检索到包含目标的图像,并返回包含目标的区域.本文的基本思路是在不同尺度、不同比例的图像上进行窗口滑动,每个窗口与查询目标作比较,以找到包含查询目标的最优位置,但这种方法需要计算每个滑动窗口的视觉特征表示,需要很多的计算量,而全卷积网络提供了一种有效的特征表示方法,只需要一次前向全卷积就可以得到多个滑动窗口的特征表示.因此,本文提出一种基于全卷积网络的中小目标图像检索算法,与其他方法相比,本文有4个特点:
1) 构建全卷积神经网络,对于任意尺寸的图像,输入该全卷积网络,得到该图像的特征表示或者特征矩阵表示,特征矩阵的每一个位置对应着原图像上的一个目标区域.
2) 为了检索到不同大小的目标,对被检索图像进行多尺度多比例变换,输入全卷积神经网络得到多个特征矩阵.
3) 在无样本进行训练的情况下,基于预训练模型,有效地完成中小目标的检索.
4) 与基于CNNs的图像检索算法相比,本算法适用于中小目标的检索;与基于目标检测的检索算法相比,本算法适用于无样本数据训练的中小目标检索,具有更高效、更优的检索定位效果.
1 相关工作
基于预训练CNNs模型的特征表示已广泛应用于图像检索任务.文献[8]提出了一种简单、有效的编码方法SPoC(sum-pooled convolutional),并通过实验论证了该编码方法检索效果最优.文献[12]考虑了特征的平移不变性以及尺度不变性,提出了一种新的特征编码方法.首先在多尺度上取区域;然后在每个区域中取每层中最大元素(maximum activations of convolutions, MAC),MAC特征具有平移不变性;然后将所有区域的MAC特征相加构成一个R-MAC(regional maximum activation of convolutions)特征表示,这种特征具有尺度不变性.实验表明:该算法R-MAC特征优于MAC特征以及SPoC方法.在利用样本进行端到端训练的图像检索算法中,文献[10]改进R-MAC算法,将R-MAC的特征表示方法进行端到端的训练,得到相应的图像特征,取得了不错的检索结果.文献[11]提出了一种用于车辆检索的CNNs架构,并利用簇聚类损失(coupled clusters loss, CCL)去替代三元组损失(triplet ranking loss)进行端到端的学习车辆的特征表示,适用于特定目标的有监督的检索.以上这些算法均是基于图像的全局特征表示,适用于图像的整体相似性检索,不适用于中小目标的图像检索.
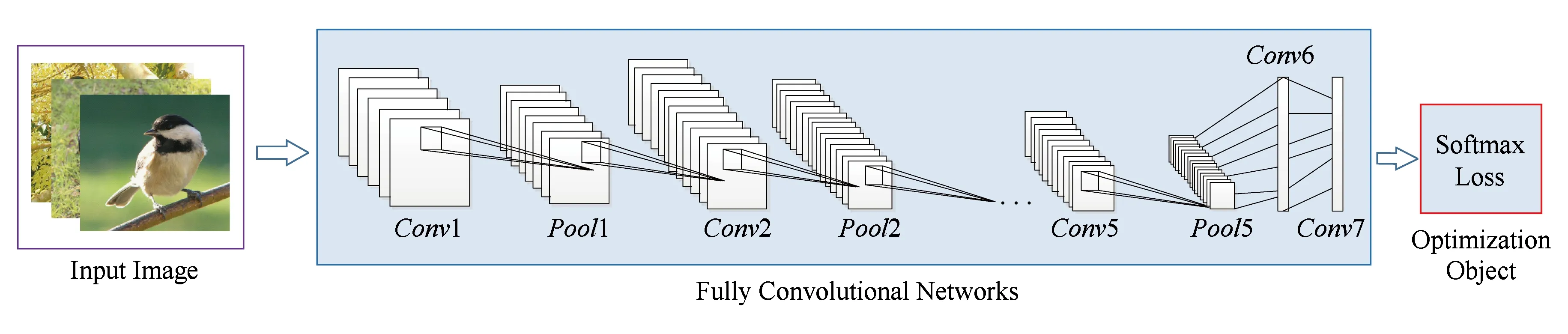
Fig. 1 An illustration of the architecture of our FCN图1 本文全卷积网络的框架图
将目标检测的思想应用于图像检索,对于数据库中的每张图像,首先利用目标候选区域提取算法(region proposal)[13-15]提取目标候选区域;然后将这些目标区域作为输入图像,利用预训练网络提取目标区域的CNNs特征;最后计算每个目标区域与查询目标的相似性值,将最大相似值作为查询目标与该图像的相似性值.这种算法虽然可以完成中小目标的检索问题,但是候选区域提取算法一般会提取出1 000~2 000个目标候选区域,然后分别对这些区域提取CNNs特征,这样会导致处理单张图像的时间过长、检索效率低.文献[16]将Faster R-CNN(region-based convolutional network)[1]的RPN(region proposal network)得到的目标区域以及相应的特征用于图像检索,若直接利用Fast R-CNN训练得到的RPN用于表示目标区域,目标区域定位效果不好,该算法比较适合于利用样本数据进行有监督的端到端微调,不适应于基于预训练模型的中小目标检索.
全卷积网络(fully convolutional networks, FCN)架构主要用于图像分割[4,17]和目标检测[18-20].FCN可以接受任意大小的输入图像,且经过一次卷积可以得到多个区域的特征.受FCN特性的启发,本文提出基于全卷积网络的中小目标检索算法,用于完成无样本数据或者样本数据不足时,基于预训练网络的中小目标检索算法.本文的基本思路是给定查询目标,在待检索图像上进行窗口滑动,将每个窗口基于预训练全卷积网络进行特征表示,并与查询目标作相似性比对以得到包含查询目标的最优位置,而根据FCN的特性,经过一次全卷积就可以得到多个窗口的特征表示.实验结果表明:本论文提出的基于FCN的目标检索算法,其检索性能及定位效果较优.
2 基于全卷积网络的中小目标检索方法
为了解决中小目标的检索问题,本文提出了一种基于全卷积网络的中小目标检索算法.首先,构建全卷积网络,在大数据集上训练模型.其次,给定查询目标图像,利用全卷积神经网络,得到目标图像的特征表示.然后,对数据库中的图像,利用预训练全卷积模型,得到该图像的特征表示或者特征矩阵表示,特征矩阵的每一个位置对应着原图像上的一个目标区域.为了检索到不同大小的目标,需要对数据库中的图像进行多尺度多比例变换,分别输入全卷积神经网络得到多个特征矩阵.最后,将查询目标特征,与待检索图像的特征矩阵的每一个特征进行相似性比对,得到匹配最优位置及相似值.
2.1 全卷积网络架构
本文利用预训练全卷积网络模型对图像进行特征表示用于中小目标检索.本文所采用的全卷积网络的架构如图1所示.在训练阶段,该模型接受的输入为图像及其相应的标签信息.该模型主要包括2个部分:1)全卷积神经网络,用于学习图像的特征或特征矩阵表示,该网络中不包含全连接层; 2)损失层,Softmax分类损失.首先,输入图像通过全卷积网络得到图像的特征表示;然后进入损失层,计算损失函数,并优化该损失函数学习得到模型参数.
全卷积网络用于学习图像的特征表示,以AlexNet模型[2]结构为例,全卷积网络的配置如表1所示.训练网络时,输入图像大小为227×227.
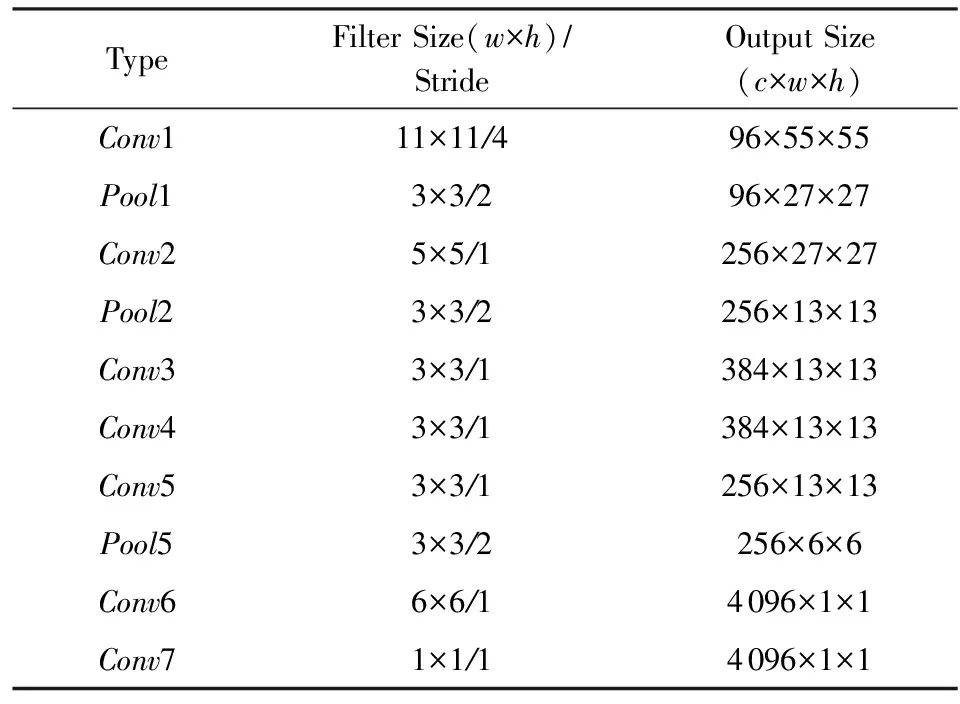
Table 1 The Configurations of FCN表1 全卷积网络配置
2.2 基于全卷积网络的特征表示
全卷积神经网络训练完成后,给定输入图像,通过全卷积网络可以得到图像的特征向量或特征矩阵表示.对于目标图像,将图像进行缩放,使其大小与全卷积神经网络模型的输入尺寸保持一致(例如缩放至227×227),然后输入全卷积网络得到目标实例的特征向量表示.对于数据库中的被检索图像,若其图像大小小于全卷积神经网络模型的输入尺寸,将图像进行缩放至与全卷积神经网络的输入尺寸保持一致,然后输入全卷积网络得到被检索图像的特征向量表示;若其图像大小大于等于全卷积网络的输入尺寸,保持原图像大小不变,由于原图像大小大于全卷积神经网络模型的输入尺寸,则得到该输入图像的特征矩阵,特征矩阵的每个位置上的特征是对原图像上一个区域的描述,相邻位置的特征对应着原图像上相邻的区域.AlexNet模型为例,给定输入图像的大小为300×250,得到图像特征矩阵的大小为4×2,即共8个区域的特征,每个区域对应于原图的一个227×227区域,水平相邻区域之间相差32个像素,垂直相邻区域之间也相差32个像素,其区域效果如图2所示:
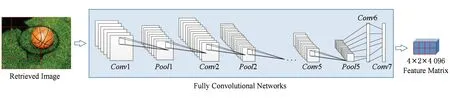
Fig. 2 The feature representation for retrieval image图2 被检索图像的图像表示
考虑到基于全卷积网络得到的特征矩阵,相当于在原图像上取一定大小的窗口(如227×227),然后按照一定的步长(如32像素)进行窗口滑动.经过一次前向卷积,就可以得到这些区域的特征表示.这种固定窗口大小、固定步长的窗口滑动,可能会导致没有一个区域刚好覆盖查询目标,从而会导致不能正确地检索并定位到目标,例如在图2中,得到的8个区域都不能刚好覆盖篮球,每个区域都包含了一部分背景.在实际应用中,可以根据目标特征,对被检索图像进行多尺度、多比例变换,以检索到不同大小、不同形状的目标.例如在新的尺度s下得到的区域窗口大小为227×227,相当于在原图上区域窗口的大小为(227/s)×(227/s),从而区域窗口可以覆盖被检索图像上不同大小的目标区域;若对图像进行r=2∶1比例变换后,在新比例下的区域窗口大小为227×227,相当于在原图上区域窗口的大小为(227/2)×227,如此区域窗口可以覆盖纵向长的目标,类似地,当对图像进行r=1∶2变换后,区域窗口可以覆盖横向长的目标.
2.3 中小目标检索方法
基于全卷积神经网络的中小目标检索,其流程图3所示.
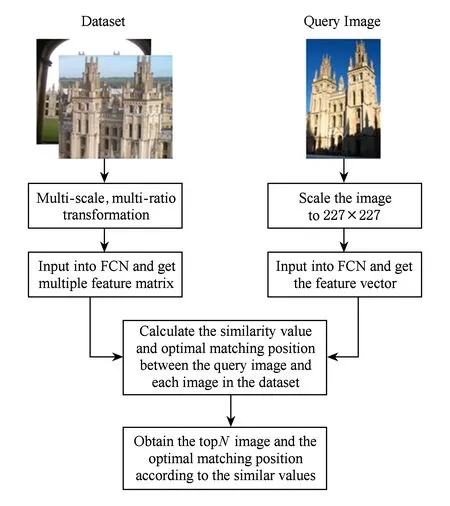
Fig. 3 The flow chart of middle or small object retrieval based on our method图3 本文中小目标检索的流程图
在离线阶段,对数据库中的每张图像进行多尺度、多比例缩放,然后输入全卷积神经网络,得到每张图像在每个尺度、比例上的特征矩阵.为了在数据库中检索到不同大小的目标,特别是仅占整张图像较少区域的中小目标,首先对图像进行多尺度变换,可以根据实际应用确定所需的尺度因子,例如图像的尺度因子可以选择s=0.5,1.0,1.5,2.0,2.5,3.0.为了在数据库中检索到不同形状比例的目标,在每个尺度上进行多比例变换,可以选择3个长宽比例因子r=1∶1,1∶2,2∶1.将图像在每个尺度s上,按照比例因子r缩放后,直接输入全卷积网络,卷积层Conv7的特征矩阵作为该尺度比例下的特征描述,特征矩阵中的每一个位置对应着输入图像的一个区域的特征描述.在该阶段,算法的复杂度为O(N×r×s),其中N表示数据库中被检索图像的个数.
在线检索阶段,给定目标检索图像,将图像进行缩放,使其大小与全卷积神经网络模型的输入尺寸保持一致,得到图像的特征向量表示.给定数据库中的图像在每个尺度、比例下的特征矩阵,将目标检索图像的特征与该特征矩阵中每个位置的特征进行余弦距离计算,将距离的最大值作为该尺度上与目标图像的最匹配值;将每个尺度、每个比例下与目标检索图像的最匹配值的最大值,作为该图像与目标图像的相似值,并保存相应的最匹配区域.然后将相似值按照降序排列,得到与目标图像最相似的TopN图像列表及其最优匹配位置.
3 实验设置与性能评价
3.1 实验设置
为验证本文方法的有效性,在图像集上对本文方法进行了评估:
1) Oxford5K[21]数据集.该数据集包括5 063幅图像,其中55幅标准的查询图像,每个目标选取5幅图像,涵盖了牛津大学的11处标志性建筑.图像库共标注为4种可能的标签:Good表示1幅包含清晰目标或建筑的图片;OK表示不少于目标整体的25%部分可以清楚地显示;Bad表示没有目标建筑出现示;Junk表示不高于目标整体的25%部分可以清楚显现或者目标遮挡、变形严重.将仅包含目标的包围盒区域作为查询目标图像.
2) Logo数据集.该数据集是在互联网上搜集的图片,包括CCTV、中国移动、中国联通、可口可乐4种logo,每种类型100张图像,另外再加上100张干扰图像,共500张图像.图4给出了该数据集中的部分示例图像.查询目标图像为仅包含logo的图像,图5给出了查询图像示例.

Fig. 4 Sample images from the logo dataset图4 数据集中的部分图像示例

Fig. 5 Query images for the logo dataset图5 Logo数据集的查询图像示例
本文主要考虑在样本数据不足时,基于预训练模型的特征表示在检索任务中的性能.将本文方法的检索性能与其他的图像检索方法做比较,包括基于预训练CNNs的整体特征表示方法SpoC[8],MAC[11],R-MAC[11]算法,基于SS(selective search)[13]目标检测算法的SS+Fc7,以及基于Faster R-CNN特征表示的检索算法[16],将该检索算法记为Faster R-CNN.
SpoC,MAC,R-MAC算法采用预训练Alexnet的Conv5层的特征,这些算法的特征表示方法均来自于作者公开的源代码;基于目标候选区域提取算法的方法SS+Fc7,首先利用Selective Search算法得到目标候选区域,然后输入预训练Alexnet得到Fc7层的特征,用于表示目标区域,其中Selective Search算法的实现来自于作者公开的源代码;基于Faster R-CNN的目标检索算法利用预训练的目标检测VGG-16得到RPN区域以及每个区域的RPA特征,其中预训练模型来自于Faster R-CNN公开的模型.本文也采用Alexnet作为基础架构,在ImageNet数据集上训练全卷积网络,训练完成后,采用Conv7层的特征表示每个区域.
为了评估图像检索性能并与已有方法作比较,本文采用查准率均值(mean average precision,MAP)对检索性能进行评估.平均精确度(average precision,AP)为查准率-查全率曲线所包含的面积,相关的定义为

(1)

(2)
对于Oxford5K数据集,MAP为每组5幅查询图像AP的平均值.对于Logo数据集,在每个查询目标检索出的Top100图像集上计算AP值.
本文的训练过程基于开源Caffe实现的.
3.2 在标准数据集Oxford5K上检索性能分析
为了验证本文方法的有效性,将本文的算法与基于CNNs编码的整体特征表示方法SpoC,MAC,R-MAC以及基于目标检测的算法SS+Fc7,Faster R-CNN在Oxford5K数据库上对全部11个查询目标的检索准确度作了比较,MAP对比结果如表2所示:
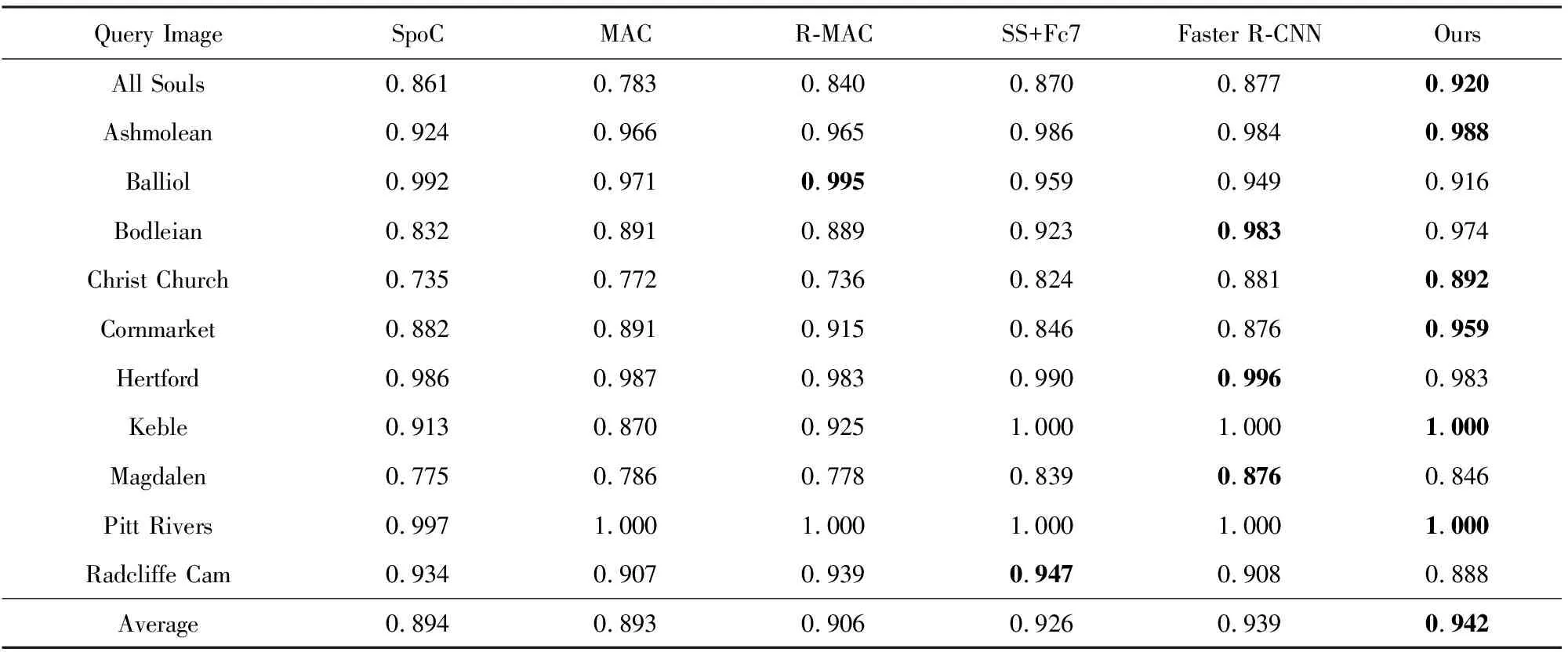
Table 2 MAP of Different Methods Compared on Oxford5K表2 各方法在Oxford5K数据集上MAP结果对比
Note: Blackbody indicates the best result in the compared methods.
从表2可以看出,对于不同的查询目标而言,SpoC,MAC,R-MAC方法的MAP值相近且R-MAC方法略高于SpoC,MAC方法,因为这3种方法均是对图像的整体特征算法,而R-MAC方法在不同尺度上对区域进行划分并分别对区域进行整体表示,得到了更好的特征表示.基于目标检测的算法SS+Fc7,Faster-RCNN以及本文算法的MAP值相近,且比3种图像的整体表示算法的MAP值高出3%~5%,因为后面的3种算法均对图像进行了区域划分,分区域与查询目标进行匹配,而不是将图像作为整体与查询目标进行匹配,因此提高了目标检索准确度.
由于在Oxford5K数据集上,本文方法与SS+Fc7、Faster R-CNN算法的MAP相差不大,于是将这3种算法在查询时间及区域定位效果进行比较.表3给出了3种方法在处理数据库中的1幅图像所消耗时间的平均值.从表3可以看出,Faster-RCNN耗时最短,SS+Fc7算法耗时最长,本文算法耗时略高于Faster R-CNN算法,因为SS+Fc7算法首先对图像进行划分,得到多个目标候选区域,然后分别输入卷积神经网络得到每个区域的特征表示,多次重复地输入卷积神经网络导致耗时较长;Faster R-CNN将目标区域的获得和区域特征的表示统一到一个框架中,只需要一次前向卷积网络,就可以得到多个区域的特征表示,加快了计算速度;本文算法虽然也只需要一次前向全卷积网络,就可以得到多个区域的特征表示,但是为了适用于不同大小、不同形状的目标,对图像进行了多尺度、多比例变换,从而导致其耗时略高于Faster R-CNN.
表4和表5给出了基于目标检测的算法和本文算法在Oxford5K数据库上目标区域定位结果的部分样例.不难看出,本文算法的区域定位效果最优,而SS+Fc7算法的区域定位效果不好,因为它利用SS提取图像中非限定类别的目标,而Oxford5K数据集上的查询目标只是整体目标的一部分,而不是独立的目标;Faster-RCNN算法的区域定位效果也不好,因为直接利用预训练的Faster-RCNN模型得到的RPN与预训练的目标相关,需要利用相关目标数据进行端到端的训练微调,才能得到较好的目标定位,在文献[16]中也说明了该问题.
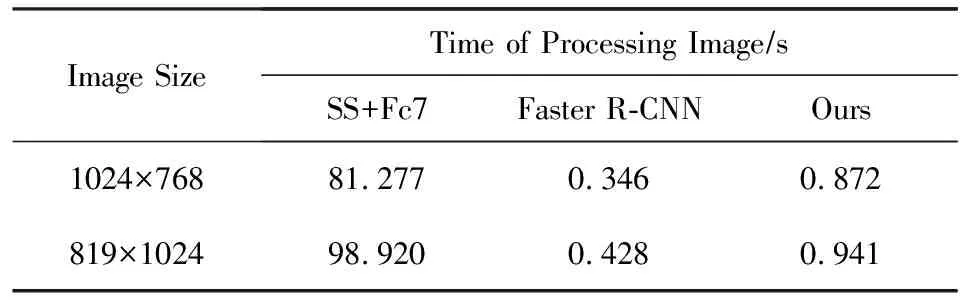
Table 3 Time Comparison of Processing Images for theThree Methods

Table 4 Examples of Image Retrieval and Object Locations for Query Object with Longer Width表4 图像检索和横长目标定位样例
从在标准数据集Oxford5K上的实验对比可以看出,本文方法与基于CNNs图像整体表示的算法相比,适合于中小目标的检索且能够定位到目标区域.与基于目标检测的检索算法相比,其耗时虽然略高于Faster-RCNN算法,但是其MAP值以及区域定位效果更优.
3.3 Logo数据集上检索性能分析
为了进一步验证本文算法的普适性及有效性,将本文算法与已有算法在Logo数据集上进行检索测试.Logo数据集是从互联网上搜集的图像.表6给出了各个查询目标的AP值.从表6中可以看出,本文算法的AP值最高,远远高于基于CNNs的图像整体表示算法和基于Faster R-CNN的目标检索算法,高出了将近45%,比基于SS+Fc7算法的AP值高了6%.这是因为在Logo数据集中,查询目标仅占数据库被检索图像的部分区域,因此将数据库图像进行整体表示与查询目标匹配准确率较低;基于Faster R-CNN预训练模型的RPN区域不能很好地定位目标区域,导致匹配准确率低;基于SS+Fc7的算法利用低级图像特征提取图像中非限定类别的目标区域,且查询目标是一个独立的完整目标,所以SS能够较好地定位到目标区域,从而得到了较高的AP值.表7给出了SS+Fc7,Faster R-CNN以及本文算法的Top4检索及目标定位结果.从表7中可以看出,SS+Fc7和本文算法目标定位效果较优,而Faster R-CNN算法的区域定位效果不好.
为了进一步说明本文算法在小目标检索中的效果,图6给出了各个logo图标在被检索图像中的检索定位样例.从图6可以看出,logo图标仅占被检索图像的一小部分区域,与整张图像相比logo属于小目标,在无训练样本的情况下,采用本文算法能够很好地在整图中检索并定位到“小的”logo图标.

Table 5 Examples of Image Retrieval and Object Locations for Query Object with Longer Height表5 图像检索和纵长目标定位样例
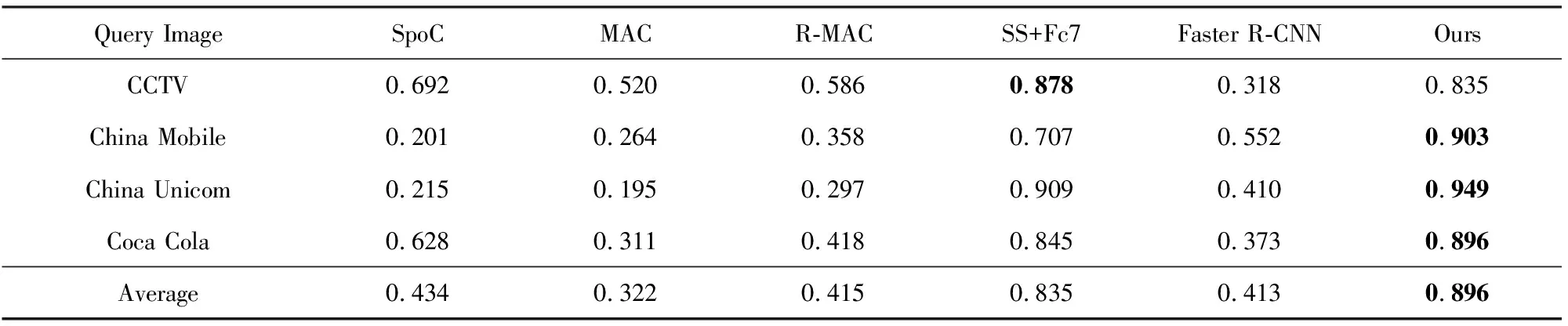
Table 6 AP Comparison of Different Methods on Logo Dataset表6 各方法在Logo数据集上AP结果对比
Note: Blackbody indicates the best result in the compared methods.

Table 7 Examples of Top4 Retrieval and Object Locations for Query Object表7 Top4检索结果和目标定位样例
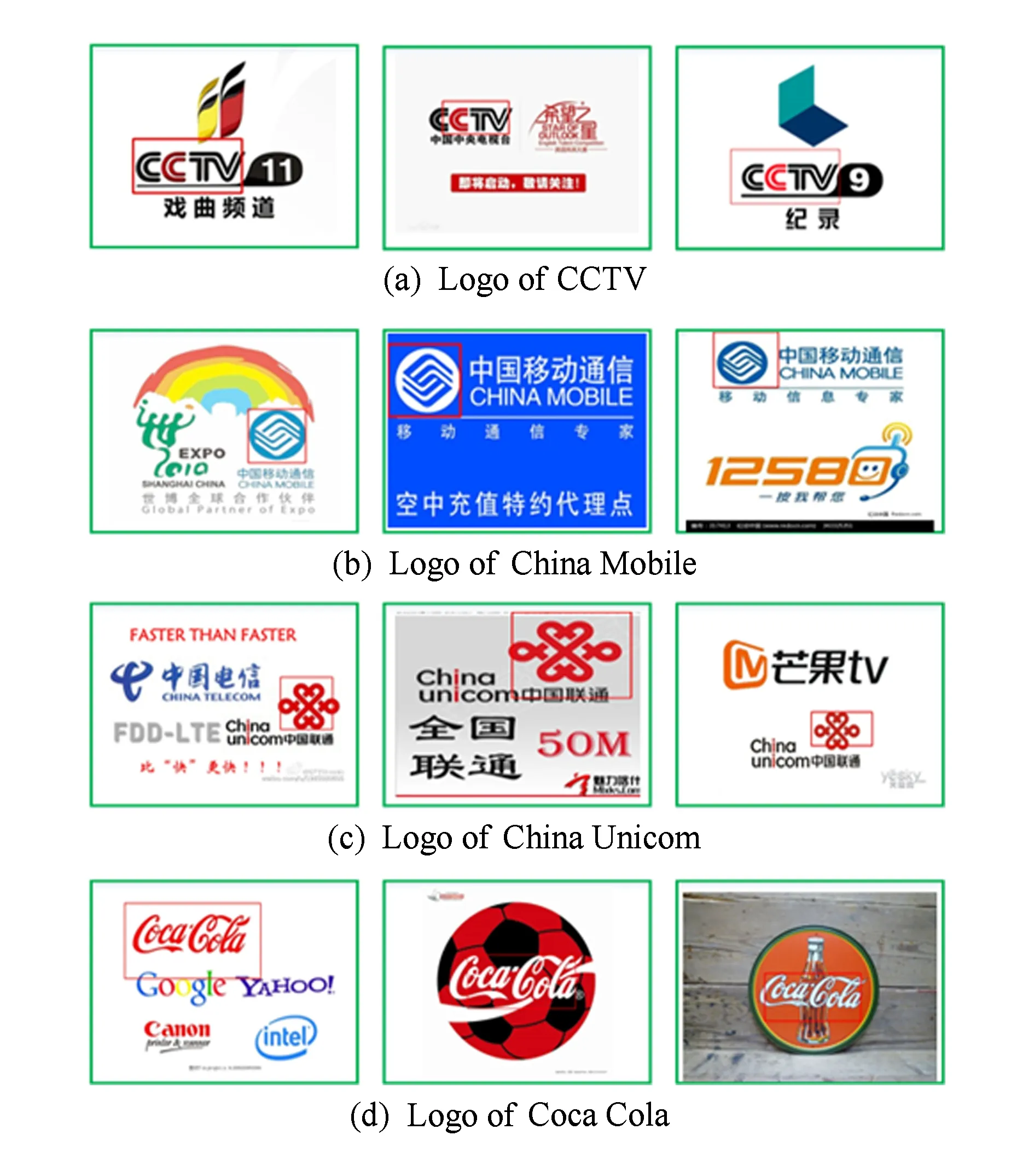
Fig. 6 Examples of retrieval and object locations for each logo图6 各logo的检索定位效果样例
4 总 结
本文提出了一种简单而有效的基于全卷积神经网络的中小目标检索方法.基于预训练全卷积网络对被检索图像进行特征矩阵表示,经过一次全卷积网络就得到了多个区域的特征表示,并引入多尺度、多比例变换以检索定位到不同大小的目标.本文主要探索在样本数据不足时,如何对目标进行有效的特征表示,以完成中小目标的检索及定位,与现有其他检索算法相比,本文的方法检索性能及定位效果最优.本文所采用的全卷积网络架构,不是最优的架构,可以采用层数更深、表达能力更强的架构进行训练,以得到对目标更好的特征描述.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
导航定位与授时(2020年5期)2020-09-23
电子制作(2019年13期)2020-01-14
中国外汇(2019年20期)2019-11-25
科学与财富(2019年27期)2019-10-25
数码世界(2019年9期)2019-09-07
电子制作(2019年14期)2019-08-20
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
海峡姐妹(2018年2期)2018-04-12
