
增强型深度确定策略梯度算法
2018-12-19 08:34:10陈建平何超刘全吴宏杰胡伏原傅启明
通信学报 2018年11期
陈建平,何超,刘全,吴宏杰,胡伏原,傅启明
增强型深度确定策略梯度算法
陈建平1,2,3,4,何超1,2,3,刘全5,吴宏杰1,2,3,4,胡伏原1,2,3,4,傅启明1,2,3,4
(1. 苏州科技大学电子与信息工程学院,江苏 苏州 215009;2. 苏州科技大学江苏省建筑智慧节能重点实验室,江苏 苏州 215009; 3. 苏州科技大学苏州市移动网络技术与应用重点实验室,江苏 苏州 215009; 4. 苏州科技大学苏州市虚拟现实智能交互及应用技术重点实验室,江苏 苏州 215009;5. 苏州大学计算机科学与技术学院,江苏 苏州 215006)
针对深度确定策略梯度算法收敛速率较慢的问题,提出了一种增强型深度确定策略梯度(E-DDPG)算法。该算法在深度确定策略梯度算法的基础上,重新构建两个新的样本池——多样性样本池和高误差样本池。在算法执行过程中,训练样本分别从多样性样本池和高误差样本池按比例选取,以兼顾样本多样性以及样本价值信息,提高样本的利用效率和算法的收敛性能。此外,进一步从理论上证明了利用自模拟度量方法对样本进行相似性度量的合理性,建立值函数与样本相似性之间的关系。将E-DDPG算法以及DDPG算法用于经典的Pendulum问题和MountainCar问题,实验结果表明,E-DDPG具有更好的收敛稳定性,同时具有更快的收敛速率。
深度强化学习;样本排序;自模拟度量;时间差分误差
1 引言
强化学习的基本思想是通过最大化智能体(agent)从环境中获得的累计奖赏值,以学习完成目标的最优策略[1]。依据策略表示方法和求解的不同,可以将强化学习方法分为3类:“评论家”算法,该算法利用值函数对策略进行评估,最终利用最优值函数求解最优策略;“行动者”算法,该算法利用类似启发式搜索的方法从策略空间中找出最优策略;“行动者—评论家”算法,行动者部分用于动作的选取,评论家部分用于评估动作的好坏,利用值函数信息指导策略的搜索[2]。然而对于上述任意一类算法,在学习过程中,都需要人工设定状态表示方法,而通过深度学习方法,可以实现状态特征的自动学习,以实现“端到端”的任务学习。目前,深度学习作为在机器学习领域的一个研究热点,已经在图像分析、语音识别、视频分类、自然语言处理等领域获得令人瞩目的成就。深度学习的基本思想是通过多层的网络结构和非线性变换,组合低层特征,形成抽象的、易于区分的高层表示,以发现数据的分布式特征表示[3]。深度学习模型通常由多层的非线性运算单元组合而成,将较低层的输出作为更高一层的输入,通过这种方式自动地从大量训练数据中学习抽象的特征表示[4-5]。
谷歌的DeepMind团队将深度学习和强化学习结合起来,提出深度强化学习方法,并将深度强化学习应用于围棋问题。2016年,Alpha Go[6]在人机围棋比赛中以4:1战胜围棋大师李世石,而新版的Alpha Zero[7]可以不需要任何历史棋谱知识,不借助任何人类先验知识,仅利用深度强化学习进行自我对弈,最终能以100:0的战绩完胜Alpha Go。目前,深度强化学习已经成为人工智能领域的研究热点。Mnih等[8-9]将卷积神经网络与传统的Q学习[10]算法相结合,提出了深度Q网络(DQN, deep Q-network)模型。DQN将未被处理过的像素点(原始图像)作为输入,通过样本池存储历史经验样本,同时利用经验回放打破样本间的联系,以避免网络参数的震荡。但是DQN只能解决离散的、低维的动作空间问题,将DQN应用到连续动作领域最简单的做法是将连续动作离散化,但是这会导致离散动作的数量随动作维度的增加而呈指数型增长,同时对连续动作进行简单的离散化会忽略动作域的结构,然而在很多情况下,动作域的结构对于问题的求解是非常重要的,因此,目前基于DQN算法提出了很多关于DQN的变体。Hasselt等[11]在双重Q学习算法[12]的基础上提出了深度双重Q网络(DDQN, deep double Q-network)算法。Schaul等[13]在DDQN的基础上提出了一种基于比例优先级采样的深度双Q网络(double deep Q-network with proportional prioritization)等。然而,这些改进的算法都不能够很好地解决连续动作空间问题。在连续动作空间中,策略梯度是常用的方法,它通过不断计算策略期望总奖赏关于策略参数的梯度来更新策略参数,最终收敛于最优策略[14]。因此,在解决深度强化学习问题时,可以采用深度神经网络表示策略,并利用策略梯度方法求解最优参数。此外,在求解深度强化学习问题时,基于策略梯度的算法能够直接优化策略的期望总奖赏,并以端对端的方式直接在策略空间中搜索最优策略。因此,与DQN及其改进算法相比,基于策略梯度的深度强化学习方法适用范围更广,策略优化的效果也更好。Lillicrap等[15]将DPG(deterministic policy gradient)算法[16]与DQN相结合,提出了DDPG(deep deterministic policy gradient)算法。DDPG可用于解决连续动作空间的强化学习问题。实验表明,DDPG不但在一系列连续动作空间的任务中表现稳定,而且求得最优解所需要的时间步也远低于DQN,但是DDPG需要大量的样本数据,且算法的收敛速度也有待提高。
本文在DDPG算法的基础上提出了增强型深度确定策略梯度(E-DDPG, enhanced deep deterministic policy gradient)算法。针对DDPG算法收敛速度慢的问题,E-DDPG算法在原始样本池的基础上构建了两个样本池——高误差样本池和多样性样本池。高误差样本池将TD(temporal-difference)error作为启发式信息对样本进行排序,以提高误差较大的样本的选取概率。同时,多样性样本池利用自模拟度量方法度量样本间的距离,在原始样本池的基础上,选择低相似样本,以提高样本池中样本的多样性,提高算法的执行效率。在算法学习过程中,训练样本将分别从高误差样本池和多样性样本池按比例选取,以兼顾样本多样性以及样本价值信息,提高样本的利用效率和算法的收敛性能。实验结果表明,与DDPG算法相比,E-DDPG算法具有更快的收敛速度以及更好的收敛稳定性。
2 相关理论
2.1 马尔可夫决策过程
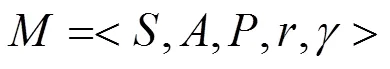
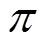
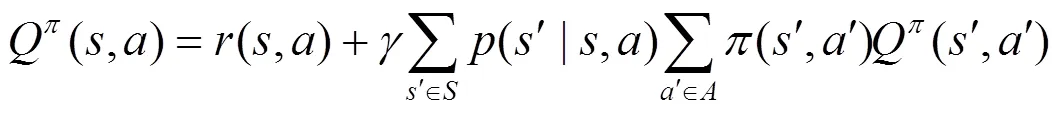
式(1)也被称作Bellman公式。
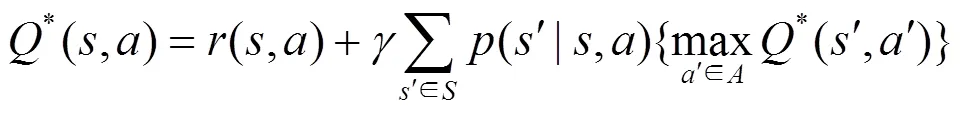
式(2)被称作最优Bellman公式。
2.2 深度确定策略梯度算法
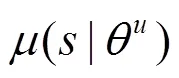
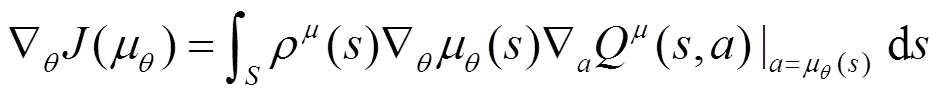
在随机策略中,策略梯度取决于状态和动作,而在确定策略中,策略梯度仅取决于状态。因此,与随机策略梯度算法相比,确定策略梯度算法收敛需要的样本相对较少。

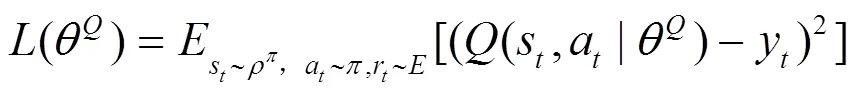
其中,有
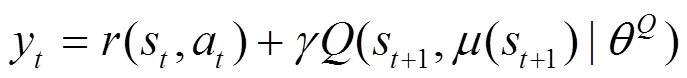

值得注意的是,确定策略梯度算法缺少对环境的探索,而DDPG算法通过引入随机噪声来完成策略探索。通过添加随机噪声,使动作的选择具有一定的随机性,以完成一定程度的策略探索,具体如式(6)所示。
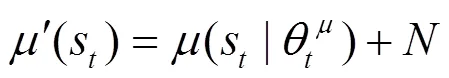
2.3 自模拟度量与状态之间的距离
为了度量MDP中状态的关系,自模拟关系被Givan等[17]引入MDP中。简而言之,如果两个状态满足自模拟关系,那么这两个状态就共享相同的最优值函数以及最优动作。
从定义1可以得出,任意两个状态要么满足自模拟关系,要么不满足自模拟关系。这种度量方法过于苛刻,且限制其使用的范围。Ferns等[18]提出了一种可用于衡量两个状态之间远近关系的自模拟度量方法(bisimulation metric)。
计算两个状态距离的算法如算法1所示。
算法1 状态之间距离度量算法
5) end for
7) end for
3 增强型深度确定策略梯度算法
3.1 样本池的构建

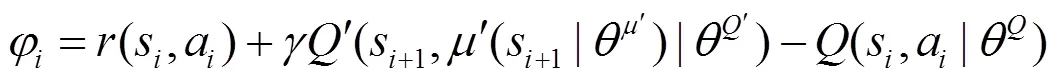
同时,为了保证选取样本的多样性,引入自模拟度量方法。从原始样本池0和高误差样本池2中随机选取的样本,可能存在很多近似样本,甚至是重复样本,这会降低算法的执行效率。因此,考虑间隔个情节,利用算法1计算出原始样本池0中样本之间的距离,将低相似性样本放入多样性样本池1,以保证所选择样本的多样性。此后,算法1将分别从多样性样本池1和高误差样本池2按一定比例选取样本,进行学习,同时兼顾样本多样性以及高价值样本信息,进一步提高算法的执行效率。
3.2 行动者—评论家网络参数更新
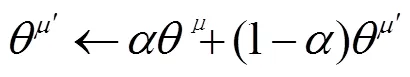
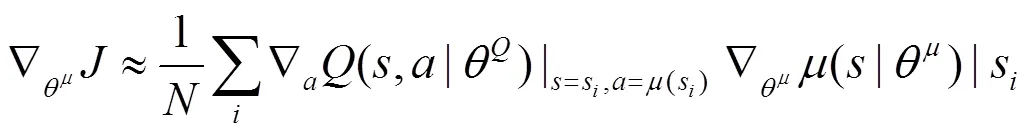
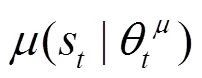
3.3 E-DDPG算法
根据3.1节和3.2节的介绍,下面给出详细的E-DDPG算法的流程,如算法2所示。
算法2 E-DDPG算法
2) for= 1 todo
4) 利用自模拟度量方法,将低相似性样本放入多样性样本池1
5) 获得初始观察状态1
6) for= 1 todo
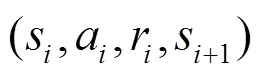
14) else
21) end if
22) end if
23) end if
24) end for
25) end if
26) end for

3.4 关于多样性样本池的分析
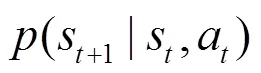
证毕。
因此,利用自模拟度量方法计算样本间的距离,利用该距离确定样本间的相似性可以进一步反映样本在值函数空间中的相似性。从参数更新的角度而言,在算法学习过程中,高相似性的样本具有较低的价值,而低相似性的样本将提高算法的更新效率,进而加快算法收敛速度。
3.5 关于高误差样本池的分析
在强化学习中,从历史样本池中进行均匀采样,可能会导致较多的更新集中在某一些低价值的样本上,如果将更新集中在某些特殊的样本上,则会使算法的更新更加高效。在均匀采样训练的过程中,会浪费大量时间和计算资源进行很多无用的更新,随着学习的不断进行,有用的更新区域不断增加,但是与将更新集中在高价值的样本上相比,学习的效率和效果差了很多。在连续状态空间中,这种非集中式搜索的效率将会非常低下。
本文以TD error作为启发式信息,将训练中高价值的样本挑选出来构建高误差样本池,在接下来的训练中,通过提高这些高价值样本的选取概率,进而更快地获得有用的更新区域。由于关于TD error的阈值是人为设置的,若仅仅从高误差样本池2中选取训练样本,可能导致错过部分高价值样本,因此,算法同时也从多样性样本池中选择一定比例的样本。实验结果表明,该方法可以提高算法的收敛速度。
4 实验结果分析
4.1 Pendulum问题
1)实验描述
为了验证算法的有效性,本文将DDPG算法和E-DDPG算法用于经典Pendulum问题。图1给出了Pendulum问题的示意。
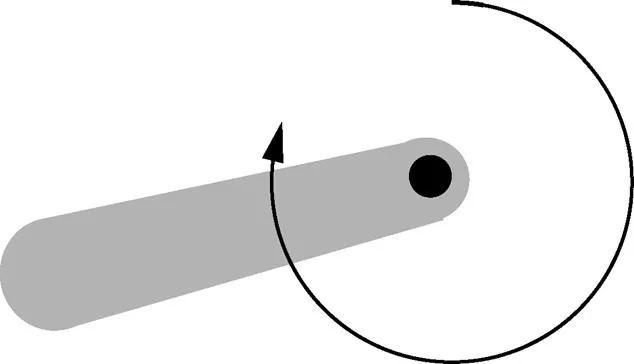
图1 Pendulum问题的示意
一个倒立的钟摆,摆杆绕中间转轴随机摆动。agent的任务是学习到一个策略,使摆杆保持竖直。本文实验环境是OpenAI gym,状态是三维的,其中,二维表示钟摆的位置,一维表示钟摆的速度。状态可以表示为

动作是一维的,表示对钟摆的作用力,取值范围为[−2,2]。动作可以表示为
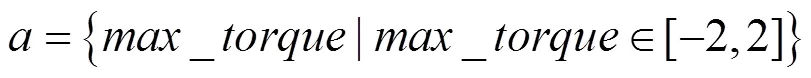
奖赏函数可以表示为
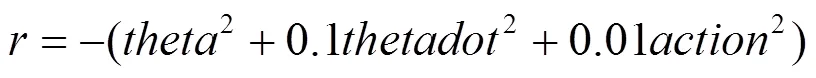
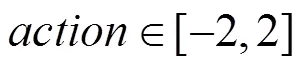
其中,等于式(9)的计算值的概率是0.1,等于0的概率是0.9。
2) 实验设置
实验运行硬件环境为Inter(R) Xeon(R) CPU E5-2660处理器、NVIDIA GeForce GTX 1060显卡、16 GB内存;软件环境为Windows 10操作系统、python 3.5、TensorFlow_GPU-1.4.0。
在该实验中,DDPG算法收敛需要8.1 h,未引入自模拟度量的E-DDPG算法收敛需要5.2 h,而引入自模拟度量的E-DDPG算法收敛仅需要2.4 h。
3) 实验分析
DDPG算法、E-DDPG算法应用于经典的Pendulum问题上的性能比较(在实验过程中,每个算法都独立执行3 000个情节)如图2所示,各种算法在不同情节下,目标任务达到终止状态时的总回报值(回报值是通过目标任务从开始状态达到终止状态时总的奖赏值)。其中,横坐标是情节数,纵坐标是算法执行10次的平均回报值。从图2可以看出,E-DDPG算法在300个情节时基本收敛。DDPG算法虽然在400个情节时取得较高的回报值,但是还在震荡并没有收敛,直到1 200个情节才收敛。因为E-DDPG算法引入了TD error,加大了对具有更高价值的样本的选取概率,同时因为采用自模拟度量方法更新多样性样本池1,使选取的训练样本多样性得到保证,从而进一步加快算法的收敛速度。此外,从图2还可以看出,两种算法在收敛后,E-DDPG算法每个情节的回报值震荡的幅度比DDPG算法的震荡幅度更小,这充分说明E-DDPG算法的稳定性比DDPG算法更好。
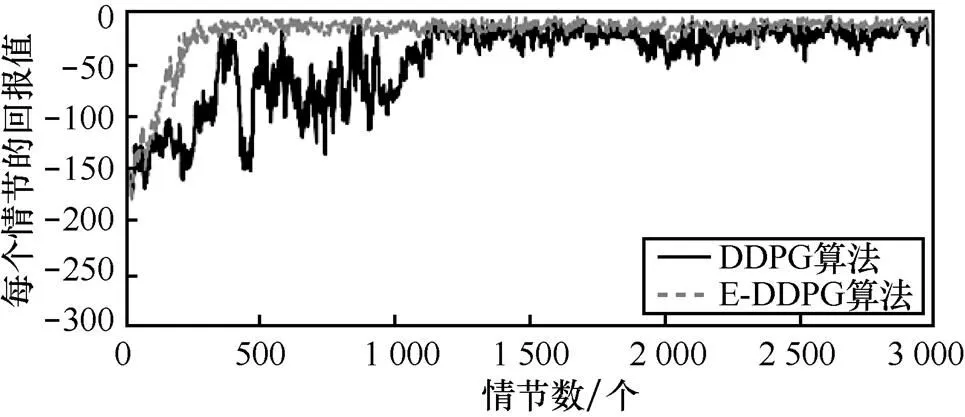
图2 Pendulum问题中两种算法的性能比较
引入自模拟度量E-DDPG算法、未引入自摸E-DDPG算法和DDPG算法进行的实验对比,结果如图3所示,其中,设置自模拟度量间隔的情节数=30。从图3可以看出,没有引入自模拟度量方法的E-DDPG算法在700个情节算法才收敛,引入自模拟度量方法的E-DDPG算法在300个情节算法就收敛,而DDPG算法在1 200个情节才收敛。因为自模拟度量方法使训练的样本具有更好的多样性,提高了训练的效率,从而加快了训练的速度。
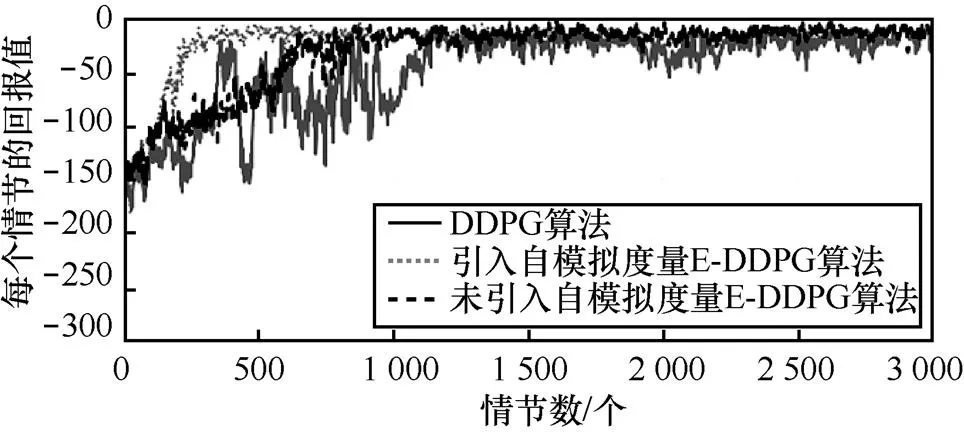
图3 Pendulum问题中E-DDPG算法是否引入自模拟度量方法与DDPG算法的实验对比
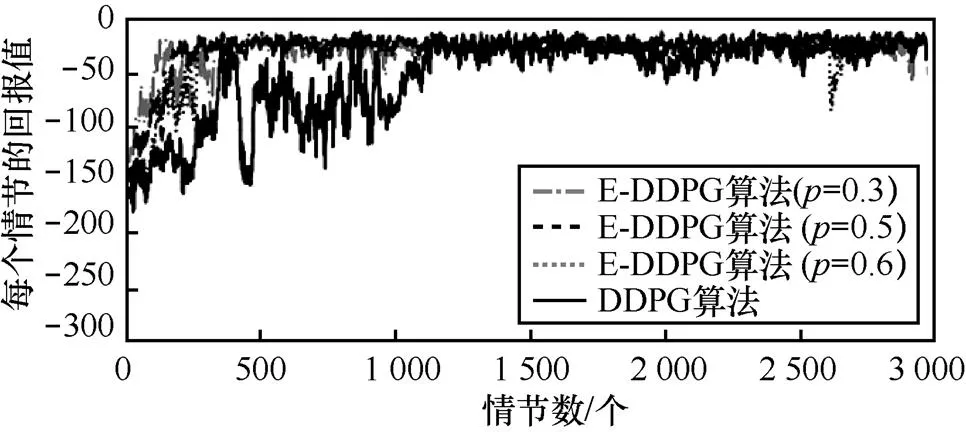
图4 Pendulum问题中E-DDPG算法不同TD Error和DDPG算法的实验对比
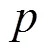
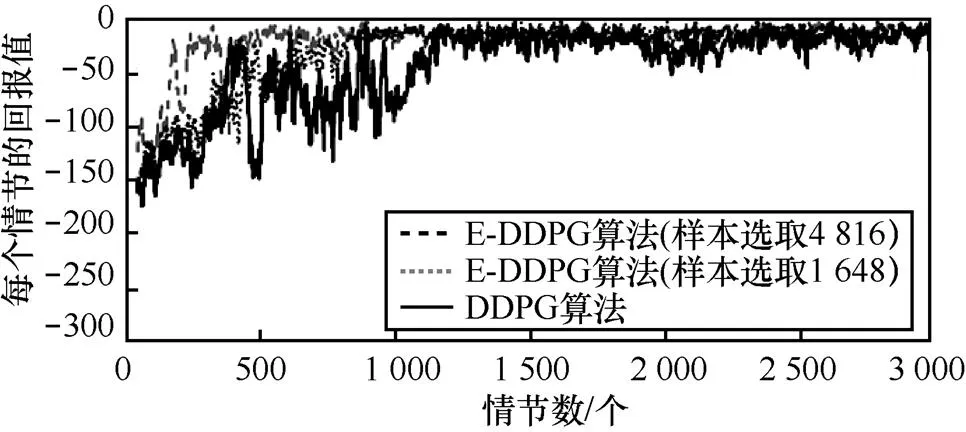
图5 Pendulum问题中E-DDPG算法不同样本选取比例和DDPG算法的实验对比
4.2 MountainCar问题
1) 实验描述
为了验证算法的有效性,本文将DDPG算法和E-DDPG算法用于经典的MountainCar问题。图6给出了MountainCar问题的示意。
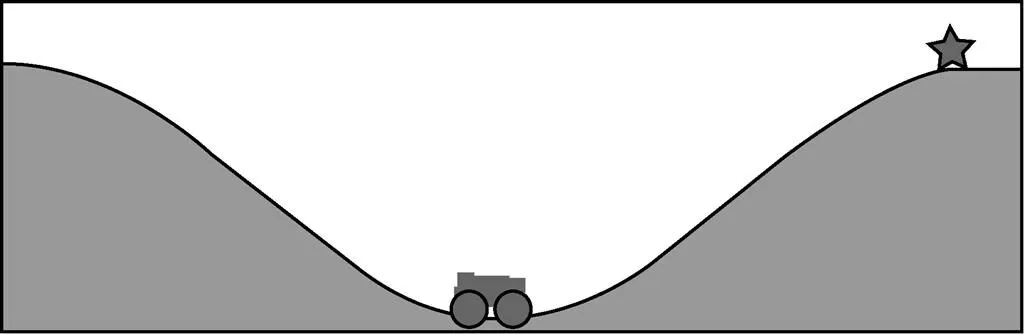
图6 MountainCar问题的示意
曲面表示一个带有坡度的路面,小车处在坡底,由于动力不足,小车无法直接加速冲上坡顶,因此必须通过前后加速借助惯性到达坡顶,即图6中右侧“星”形标记的位置。本文实验的环境是OpenAI gym,状态是二维的,其中,一维表示位置,另一维表示速度,状态可以表示为
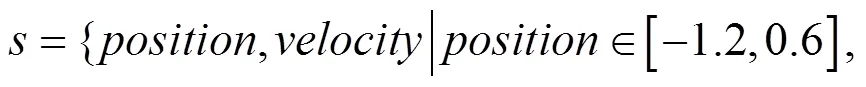
动作是一维的,表示小车的加速度,取值范围为[−1,1]。动作可以表示为
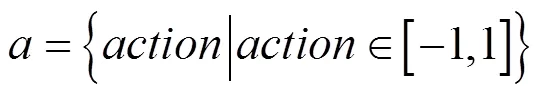
在情节开始时,给定小车一个随机的位置和速度,然后进行交互学习。当小车到达目标位置(图6中的“星”形位置)或当前执行的时间步超过1 000时,情节结束,并开始一个新的情节。当小车到达目标位置时,立即奖赏是100;其他情况下,小车的立即奖赏满足

2)实验设置
实验运行硬件环境为Inter(R) Xeon(R) CPU E5-2660处理器、NVIDIA GeForce GTX 1060显卡、16 GB内存;软件环境为Windows 10操作系统、python 3.5、TensorFlow_GPU-1.4.0。
在本实验中,DDPG算法收敛需要7.5 h,未引入自模拟度量的E-DDPG算法收敛需要4.7 h,而引入自模拟度量的E-DDPG算法收敛仅需要1.6 h。
3) 实验分析
DDPG算法、E-DDPG算法应用于经典的MountainCar问题上的性能比较(在实验过程中,每个算法都独立执行2 000个情节)如图7所示,各个算法在不同情节下,目标任务达到终止状态时总的回报值(回报值是通过目标任务从开始状态达到终止状态时总的奖赏值)。其中,横坐标是情节数,纵坐标是算法执行10次的平均回报值。从图7可以看出,E-DDPG算法在120个情节基本收敛。DDPG算法虽然在220个情节时取得较高的回报值,但是还在震荡并没有收敛,直到780个情节才收敛。
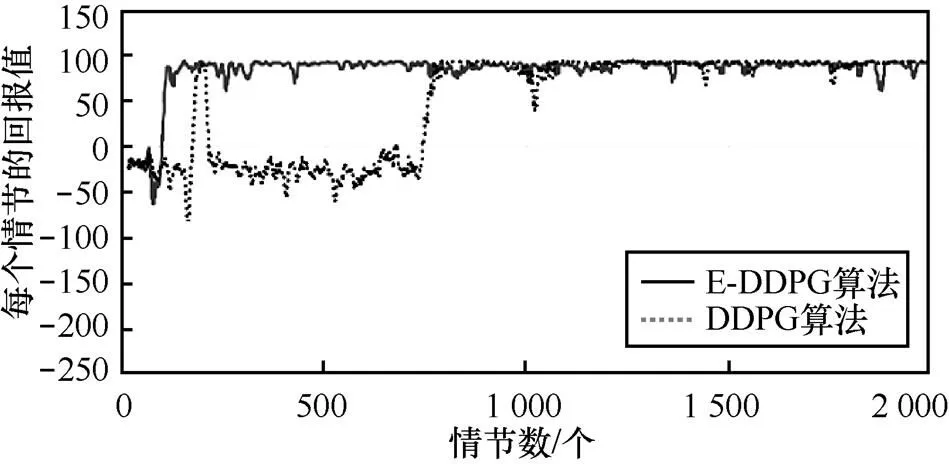
图7 MountainCar问题中两种算法的性能比较
E-DDPG算法是否引入自模拟度量方法进行的实验对比如图8所示,其中,设置自模拟度量间隔的情节数=30。从图8可以看出,没有引入自模拟度量方法的E-DDPG算法在470个情节算法才收敛,引入自模拟度量方法的E-DDPG算法在120个情节算法就收敛了,而DDPG算法在780个情节才收敛。这是因为自模拟度量方法使训练的样本具有更好的多样性,提高了训练的效率,从而加快了训练的速度。实验表明,自模拟度量方法能够加快算法的收敛速度。
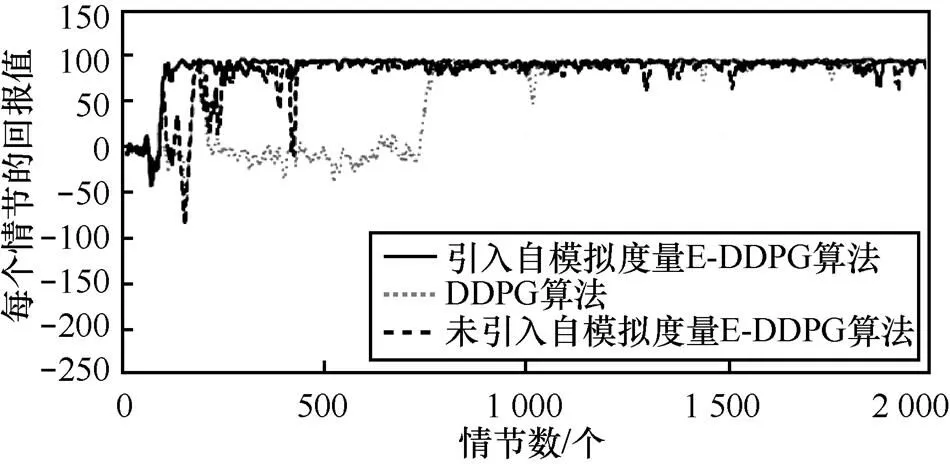
图8 MountainCar问题中E-DDPG算法是否引入自模拟度量方法的实验比较
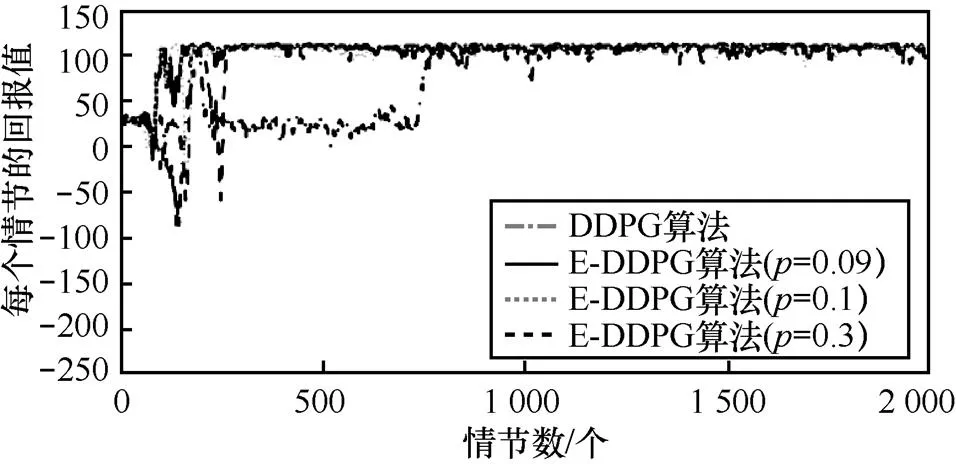
图9 MountainCar问题中E-DDPG算法不同TD Error和DDPG算法的实验比较
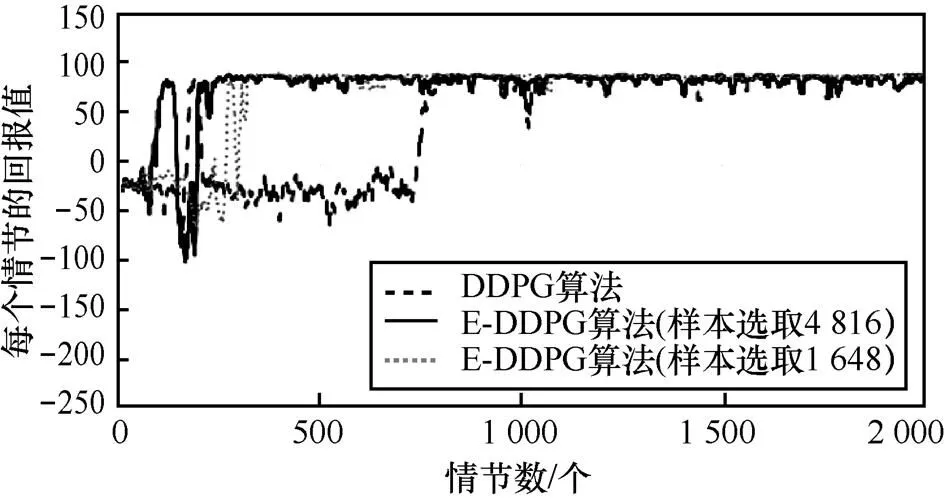
图10 MountainCar问题中E-DDPG算法不同样本选取比例和DDPG算法的实验比较
5 结束语
本文针对DDPG算法在大规模状态动作空间中存在收敛速度较慢的问题,提出了E-DDPG算法。该算法在深度确定策略梯度算法的基础上,重新构建两个新的样本池——多样性样本池和高误差样本池。其中,多样性样本池主要利用自模拟度量方法对原始样本池中的样本相似性进行度量,选择低相似性样本,并在学习过程中持续更新;高误差样本池主要通过计算时间差分误差对所选择的训练样本进行排序,选择具有高价值的高误差样本,以提高后续参数更新的有效性。将算法应用到Pendulum问题,从算法性能角度与DDPG算法进行比较。实验结果表明,E-DDPG算法比DDPG算法收敛速度更快,同时算法的稳定性也更好。针对TD error阈值和多样性样本池与高误差样本池训练样本比例等参数的人工设置不同,对算法性能的影响分别进行了实验。实验结果表明,虽然TD error阈值选取和样本选取比例不同会导致E-DDPG算法性能不一样,但是与DDPG算法相比还是有较好的效果。
本文主要以Pendulum问题和MountainCar问题作为实验平台验证算法性能,从实验结果可以看出,算法具有较好的收敛性和稳定性。但是E-DDPG算法中TD error的选取和样本比例的选取都是人工设置的,且不同的设置参数会对算法收敛性和稳定性产生不同的影响。因此,接下来的工作是进一步分析如何设置TD error和样本选取比例,让算法可以获得最好的收敛性和稳定性,使算法具有更强的通用性。
[1] SUTTON R S, BARTO G A. Reinforcement learning: an introduction[M]. Cambridge: MIT press, 1998.
[2] 朱斐, 刘全, 傅启明, 等. 一种用于连续动作空间的最小二乘行动者-评论家方法[J]. 计算机研究与发展, 2014, 51(3): 548-558. ZHU F, LIU Q, FU Q M. A least square actor-critic approach for continuous action space[J]. Journal of Computer Research and Development, 2014, 51(3): 548-558.
[3] 孙志军, 薛磊, 许阳明, 等. 深度学习研究综述[J]. 计算机应用研究, 2012, 29(8): 2806-2810. SUN Z J, XUE L, XU Y M, et al. Overview of deep learning[J]. Application Research of Computers, 2012, 29(8): 2806-2810.
[4] LECUN Y, BENGIO Y, HINTON G. Deep learning[J]. Nature, 2015, 521(7553): 436-444.
[5] HINTON G E, OSINDERO S, TEH Y W. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006, 18(7): 1527-1554.
[6] SILVER D, HUANG A, MADDISON C J, et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016, 529(7587): 484-489.
[7] SILVER D, SCHRITTWIESER J, SIMONYAN K, et al. Mastering the game of go without human knowledge[J]. Nature, 2017, 550(7676): 354-359.
[8] MNIH V, KAVUKCUOFLU K, SILVER D, et al. Playing atari with deep reinforcement learning[C]//Workshops at the 26th Neural Information Processing Systems. 2013.
[9] MNIH V, KAVUKCUOFLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533.
[10] WATKINS C J C H. Learning from delayed rewards[J]. Robotics and Autonomous Systems, 1989, 15(4): 233-235.
[11] VAN H V, GUEZ A, SILVER D. Deep reinforcement learning with double q-learning[C]//The AAAI Conference on Artificial Intelligence. 2016.
[12] HASSELT H V. Double Q-learning[C]//The Advances in Neural Information Processing Systems. 2010.
[13] SCHAUL T, QUAN J, ANTONOGLOU I, et al. Prioritized experience replay[C]//The 4th International Conference on Learning Representations. 2016: 322-355.
[14] SUTTON R S, MCALLESTER D, SINGH S, et al. Policy gradient methods for reinforcement learning with function approximation[J]. Advances in Neural Information Processing Systems, 2000, 12: 1057-1063.
[15] LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[C]//The 4th International Conference on Learning Representations. 2015.
[16] SILVER D, LEVER G, HEESS N, et al. Deterministic policy gradient algorithms[C]//The International Conference on Machine Learning. 2014.
[17] GIVAN R, DEAN T, GREIG M. Equivalence notions and model minimization in Markov decision processes[J]. Artificial Intelligence, 2003, 147(1-2): 163-223.
[18] FERNS N, PANANGADEN P, PRECUP D. Metrics for finite markov decision processes[C]//The 20th Conference on Uncertainty in Artificial Intelligence. 2004.
Enhanced deep deterministic policy gradient algorithm
CHEN Jianping1,2,3,4, HE Chao1,2,3, LIU Quan5, WU Hongjie1,2,3,4, HU Fuyuan1,2,3,4, FU Qiming1,2,3,4
1. Institute of Electronics and Information Engineering, Suzhou University of Science and Technology, Suzhou 215009, China 2. Jiangsu Province Key Laboratory of Intelligent Building Energy Efficiency, Suzhou University of Science and Technology, Suzhou 215009, China 3. Suzhou Key Laboratory of Mobile Networking and Applied Technologies, Suzhou University of Science and Technology, Suzhou 215009, China 4. Virtual Reality Key Laboratory of Intelligent Interaction and Application Technology of Suzhou, Suzhou University of Science and Technology, Suzhou 215009, China 5. School of Computer Science and Technology, Soochow University, Suzhou 215006, China
With the problem of slow convergence for deep deterministic policy gradient algorithm, an enhanced deep deterministic policy gradient algorithm was proposed. Based on the deep deterministic policy gradient algorithm, two sample pools were constructed, and the time difference error was introduced. The priority samples were added when the experience was played back. When the samples were trained, the samples were selected from two sample pools respectively. At the same time, the bisimulation metric was introduced to ensure the diversity of the selected samples and improve the convergence rate of the algorithm. The E-DDPG algorithm was used to pendulum problem. The experimental results show that the E-DDPG algorithm can effectively improve the convergence performance of the continuous action space problems and have better stability.
deep reinforcement learning, sample ranking, bisimulation metric, temporal difference error
TP391
A
10.11959/j.issn.1000−436x.2018238
陈建平(1963−),男,江苏南京人,博士,苏州科技大学教授,主要研究方向为大数据分析与应用、建筑节能、智能信息处理。

何超(1993−),男,江苏徐州人,苏州科技大学硕士生,主要研究方向为强化学习、深度学习、建筑节能。
刘全(1969−),男,内蒙古牙克石人,博士,苏州大学教授、博士生导师,主要研究方向为智能信息处理、自动推理与机器学习。

吴宏杰(1977−),男,江苏苏州人,博士,苏州科技大学副教授,主要研究方向为深度学习、模式识别、生物信息。
胡伏原(1978−),男,湖南岳阳人,博士,苏州科技大学教授,主要研究方向为模式识别与机器学习。

傅启明(1985−),男,江苏淮安人,博士,苏州科技大学讲师,主要研究方向为强化学习、深度学习及建筑节能。
2018−03−22;
2018−08−01
傅启明,fqm_1@126.com
国家自然科学基金资助项目(No.61502329, No.61772357, No.61750110519, No.61772355, No.61702055, No.61672371, No.61602334, No.61502323);江苏省自然科学基金资助项目(No.BK20140283);江苏省重点研发计划基金资助项目(No.BE2017663);江苏省高校自然科学研究基金资助项目(No.13KJB520020);苏州市应用基础研究计划工业部分基金资助项目(No.SYG201422)
The National Natural Science Foundation of China (No.61502329, No.61772357, No.61750110519, No.61772355, No.61702055, No.61672371, No.61602334, No.61502323), The Natural Science Foundation of Jiangsu Province (No.BK20140283), The Key Research and Development Program of Jiangsu Province (No.BE2017663), High School Natural Foundation of Jiangsu Province (No.13KJB520020), Suzhou Industrial Application of Basic Research Program Part (No.SYG201422)
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
数学物理学报(2021年6期)2021-12-21 06:24:38
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
应用数学(2020年2期)2020-06-24 06:02:50
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
