
量子遗传算法优化神经网络的氯碱生产应用
2018-12-18 13:41马浩天杨友良马翠红
中国氯碱 2018年11期
马浩天,杨友良,马翠红,王 禄
(华北理工大学电气工程学院,河北 唐山 063200)
在氯碱电解槽电解过程中,因为操作不准确和参数测量的不稳定以及对多参数信息的综合分析能力有限,所以对于氯碱电解生产控制策略往往是不充分的。在现有作业制度和电解设备不需要做大改动情况之下,通过对氯碱电解槽的电解过程进行参数优化,控制并调整各工艺参与以提高生产效率,降低能耗,具有一定的实际意义。
神经网络的非线性映射能力非常强,它是一种单向传播的多层神经网络,在没有任何先验公式的基础上,可以通过训练自动总结出数据间的函数关系。但是神经网络有一些缺点,就是初始的权值与阈值的随机设定会导致收敛速度较慢并容易陷入局部的极小值。遗传算法可以用来优化神经网络的阈值和初始权值,但是遗传算法本身也是存在着一定缺点的,比如算子设定、初始种群的选择等。为了解决这些问题,该文把K均值聚类的计算方法结合量子遗传算法,利用K均值聚类算法将遗传算法中的初始种群划分为多个子种群,另多个子种群分别进化;对于传统的方法之中使用的固定旋转角,为了提高算法的收敛速度采用动态调整策略。用改进量子遗传算法来在BP神经网络的初始阈值与权值之中进行寻优,最后通过仿真实验检测离子膜模型建立的效果。
该文利用神经网络的训练数据,建立好函数关系,并将该函数作为目标输入函数,利用复合形法对离子膜效率进行在线优化,取得了很好的经济效益。
1 离子膜氯碱电解简介
离子膜氯碱电解技术是目前世界上较为先进的电解生产工艺,其与金属阳极法、石墨槽法、水银法相比,具有能耗低、污染少、NaOH浓度高等优点。
离子膜技术的特点是利用选择性离子交换膜将电解槽的阴阳极室分隔开来,其膜原理是将阳离子Na+从阳极室带到阴极室,并且阻止阴极室的OH-离子通过。这样避免了液体与气体之间的混合,又保证了电解室带电离子的平衡,从而产生高质量与高纯度的产物。
离子膜的效率即是对OH-离子的排斥能力以及对Na+的迁移能力。实际离子膜效率的计算公式为:

式中:q—碱液流量,kg/h;
cNaOH—碱液质量的百分数,%;
NA、NB—A列和B列的电解槽数,一般每个电解槽的槽数是30个;
IA和IB—A列和B列的电流,kA;
T—计算膜效率的时间间隔,h。
离子膜生产过程中,离子膜效率越高,电解效率越高,电解能耗越低,因此可以带来可观的经济收益。所以,为了保证高质量、高效率的生产过程,对电解槽的优化控制是非常有必要的。但是影响电解槽生产效率的因素有很多,主要变量有,NaOH浓度、淡盐水浓度、电流密度、槽温等。该文用改进后的量子遗传算法优化BP神经网络对离子膜效率进行软测量,然后再对离子膜的被控变量的设定值进行在线优化调整,保证离子膜的性能达到最佳,从而达到节能降耗的目的。
2 BP神经网络的结构及学习算法
2.1 BP神经网络的结构
神经网络是由一个个神经元[4]来组成的。图1是单输入神经元,其中x是输入端,ω是权值,b是阈值,f是激励函数,而y是输出。输入值x经过与权值、阈值的计算,得到激励函数的输入y=f(ωx+b)。其中,f的函数型该文选择S型函数。
BP神经网络是多层前馈神经网络见图2。网络的结构包括输入层、输出层和隐含层。其每一层由并行神经元构成,未在同一层神经元都相互连接,同一层之间没有连接,并且各层神经元都选择任意激励函数。

图1 单输入神经元

图2 BP神经网络结构
2.2 BP神经网络的学习算法
BP神经网络的学习算法组成:输入样本和误差,其中输入样本为正向传播而误差是反向传播。训练网络时,权值和阈值是随机的,用来训练的样本从输入端计算到输出端,然后再将其与设定值进行比较,若误差值未达标,则将误差变化值信号反向传播回去,同时修改每层神经元的权值与阈值。前向传播与反向传播来回计算,直到输值与设定值误差平方和达标或者计算次数达到设定的最大值,以此来获得最合适的连接权值和阈值。假设输出层神经元是m个,且输出值为,期望值为y,误差平方和E得:

权值的修正值是:

式中,Δωij—ij之间的权值,Ij—激励函数,η—学习的速率。
3 量子遗传算法
量子遗传算法的原理是使用量子特性之中的比特概率幅代表染色体编码,这样使染色体的状态信息能够增加很多,然后种群的更新则使用量子旋转门来实现,最后达到对目标函数寻优的目的。
3.1 量子比特编码
一般计算中,一个比特的值为二进制0和1。然而在量子特性中,一个量子比特,不仅仅代表两个数值,其能够代表|0〉和|1〉之间的无限个中间态,也就是说量子比特的状态是|0〉和|1〉的线性组合:

式中,α和β 为复数,被称作量子态概率幅。|α|2和|β|2分别表示量子位在|0〉和|1〉状态间的概率,而且满足以下条件:

包含m个量子比特位系统:

式中,|αi|2+|βi|2=1(i=1,2,…,m)。m 个比特位可以有2m种状态,且其中的状态由2m个概率幅决定。所以,量子遗传算法在种群多样性和全局搜索能力比一般遗传算法更加优秀。
3.2 量子旋转门更新
该算法更新种群的方法是旋转门。操作方法如下:

式中,θ为旋转角,大小以及方向按照表1来选择,θ=s(αi,βi)δ。
表1中,f(x)是适应度函数,xi和besti分别代表第i个当前的染色体与最优的染色体的二进制编码;s(αi,βi)代表旋转角方向,s(αi,βi)其中的符号确定染色体收敛方向;δ代表旋转角,能够影响算法收敛速度,δ范围是 0.005π~0.1π。
3.3 量子遗传算法流程
(1)先设定好种群的大小n和量子编码的位数m。其中每个个体如公式(6)所示,所有的 αi、βi初始化成
(2)根据个体概率幅生成相对应的二进制编码。具体的操作:产生[0.1]的随机数,若随机数大于|αi|2或者|βi|2,则取 1,否则取 0。
(3)计算个体适应度值,并记录适应度最大个体,作为下一代的进化目标。
(4)判断终止条件是否满足,如果满足则算法终止,不满足则执行下一步。
(5)计算量子旋转旋转角,并更新每个个体概率幅值。
(6)代数加1,然后继续进行(2)步骤。
4 改进的量子遗传算法
4.1 基于K均值的多种群聚类算法
量子遗传算法中,种群之中的其余个体需要朝向最优解的方向来更新自己的染色体,更新时由其本身与当前最优个体的概率幅值来决定。但如果当前的最优解个体是当前全局次优解,那就会陷入局部最优。

表1 量子旋转门的调整策略
为了解决这种问题,此文加入多种群的计算方法。将整体的种群进行分化,划分成多个子种群并且每个自种群向着其中最优的种群来进化,并且在进化到一定的代数时,通过移民方法来交换个体,这样可以加快算法收敛速度,且避免过早收敛现象。但传统多种群算法仅仅是将父种群随机的划分为多个子种群,其有盲目性和随机性,不符合自然进化规律。所以这里利用K均值聚类的算法划分种群。
K均值聚类算法:任意选择其中的K个对象用作初始聚类中心,并计算群体之中个体与聚类中心的距离,令每个个体归属于其最近聚类中心。聚类中心和其被分配的个体代表一个子种群。如果所有个体都被分配,那么各个种群聚类中心将会根据聚类之中现有个体来重新计算。此过程不断重复直至群体不再变化。
基于K均值的多种群的量子遗传算法如下:
步骤1利用以上方法将父种群划分为k个子种群。
步骤2各个子种群利用量子旋转门来进行更新,然后计算出所有个体的适应度值。
步骤3各个子种群进行移民操作:相邻子种群适应度最高的个体来代替本子种群适应度最低的个体。
步骤4每一个子种群之中要选择出适应度值最好的那个个体保存到精华群。若最优个体的最少保持代数小于设定值,则转到步骤1,否则迭代终止。其中精华群里面的最优个体则为最优解。
子种群进化时的计算是由动态组建完成,且利用其他子种群的最优个体代替本子种群最劣个体,此种方法能促进各个子种群间的信息交换,增加跳出局部最优的概率。精华种群的作用是保证各子种群的最优解不被丢失。
4.2 量子旋转门自适应调整策略
种群更新时需要比较各个个体与当前的最优个体的二进制编码来决定转角,若f(x)≥f(b),则需要调整个体中相对应比特位,令(αi,βi)朝着x的方向进行旋转。δ大小决定收敛速度,δ设定为固定值,计算过程中保持不变。但是此种方法有所不足:若设置过大,则会导致算法早熟;设置过小,则致迭代次数过多,收敛过慢。为解决此问题,需要一种自适应调整策略,令旋转角随每个个体与当前最优个体差异大小来变化。
文献[5]提出使用公式(8)的策略来调整旋转角,公式如下:

式中,fmax和fmin分别代表当前种群里面个体的最大适应度值和最小适应度值,f代表的是当前个体适应度值。
由公式(8)可知,若当前个体的适应度值比较小,且与最优个体的适应度值相差较大时使用较大旋转角,相反则用较小旋转角。且无论f是哪种情况,δ的取值都在δmax与δmin之间来取值。
5 离子膜效率预测模型的建立与分析
5.1 影响因素的选择
由于影响离子膜效率的因素有很多,如果这些因素全部输入到控制模型之中,这样不仅会使计算结构变的复杂,并且会拖慢运算速度,降低运算精度,使控制系统的泛化能力不足,达不到预期的可行性。在氯碱电解过程中,很多影响因素都具有耦合性,并且有些影响因素对于生产过程的影响相对来说较小。所以,建立控制模型之前,需要简化影响因素的输入,使模型较为清晰,增加实现程度。
本文采用的是核主元素分析法(Kernel Principal Component Analysis,KPCA)简化数据属性。核主元素分析法就是利用“核技巧”将线性的主成分分析法(Principal Component Analysis,PCA)进行拓展,成为非线性的PCA,对于传统PCA来说,KPCA具有主成分特征更加明显,参数维数较少,贡献率更加集中等优点,是一种处理非线性指标的理想分析方法。
现场采集生产数据后,根据基本原理,计算KPCA的“累计贡献率”的过程如下。
(1)将n个指标(每个指标有m个样品)数据写成(m×n)维的矩阵:

(2)计算核矩阵K;
(3)修正核矩阵得到KL;
(4)使用Jacobi迭代方法来计算KL的特征值λ1,…,λn即对应的特征向量 v1,v2,…,vn;
通过施密特正交化方法,单位正交化特征向量,得到 α1,α2,…,αn;
计算特征值的累积贡献率 B1,B2,…,Bn,根据给定的提取效率p,如果Bt≥p,则提取t个主分量α1,α2,…,αt。
所以,根据核主元素分析法,在槽温、电流密度、电压、NaOH浓度、淡盐水浓度这5个变量中,选择出3个主元作为模型的输入。分析结果见表2。
核主元素分析法的原则是要求每个元素的累计贡献率达到85%以上即可,由表2可知,只要选择前两个元素就能够满足,但是在分别仿真2个主元、3个主元、4个主元、5个主元作为输入时仿真得到的预测误差百分比,见表3。

表2 核主元素分析法分析结果

表3 膜效率预测误差
由表3可知,用2个主元输入模型到用3个主元输入模型时,膜效率误差有明显下降。以3个主元、4个主元、5个主元来输入模型时,膜效率的误差虽然降低,但是误差变化不大。所以,为了既保证原有样本的基本信息,又能简化神经网络的输入模型,需要选择前5个主元作为输入模型,分别是槽温(x0)、NaOH 浓度(x1)和淡盐水浓度(x2)。
5.2 模型建立与分析
本文采用改进的多种群量子遗传优化BP神经网络算法建立氯碱电解槽膜效率软测量模型。数据来自于某化工企业的生产过程记录值。
经过预先的数据处理后得到756组样本数据,然后随机采取656组数据作为其中的训练样本数据,其中的100组数据作为测试数据。此时可以利用这些数据在matlab平台上进行仿真,设置3-7-1的神经网络结构,把x0,x1,x2这3组数据作为输入数据,y作为输出数据来进行神经网络的训练。

图3 氯碱电解膜效率输出曲线图

图4 氯碱电解膜效率预测误差百分比曲线图
学习速率是0.01,设定误差为0.000 1,迭代次数是500。父种群的规模是200,子种群的个数是5,个体的量子编码和二进制编码长度是20,最优的个体保持的代数为10的时候终止算法。令期望输出和实际输出间的均方误差的倒数作为适应度的函数值,即1/MSE(y-y′)。氯碱电解的膜效率和误差百分比的仿真结果分别见图3和图4。
图3和图4的仿真结果表明,基于BP神经网络遗传算法对氯碱电解过程中的膜效率进行优化,能将膜效率很好的预测出。
6 离子膜效率优化
得到离子膜效率的软测量模型之后,即可对离子膜的效率进行优化,优化的目的是计算出在给定的生产负荷下,最佳的电解槽温度、碱液浓度和淡盐水的浓度,并将其作为设定值输入到控制系统,从而来提高离子膜的生产效率。
因为得到的软测量模型中的变量较少,所以本文选用复合形法来进行离子膜效率的寻优。
从预测模型中得到的离子膜效率的目标函数是

式中,x0,x1,x2为自变量分别代表的是槽温、碱液浓度和淡盐水浓度。在实际问题中要求的是极大值,令J=-η=-f(x0,x1,x2),J极小值的绝对值就是η的极大值。用复合形法求目标函数J极小值的过程如下。
(1)复合形一共有2 n个顶点,本文中n为3,假设给定的初始复合形中第一个顶点坐标(x00,x10,x20),并且此顶点坐标应满足相应的约束条件;
(2)在三维空间变量之中,再确定初始复合形其余的5个顶点。
利用伪随机数按照约束的条件来产生第j个顶点,X(j)=(x0j,x1j,x2j),j=1,2,…,5,其中各个分量xij(i=0,1,2)为:式中:r为0~1之间的伪随机数;ai和bi是变量xij的常量约束条件,即 ai≤xij≤bi。

(3)确定好复合形2n=6个顶点后,计算每个顶点的目标函数值

(4)确定最坏点XR与次坏点XG
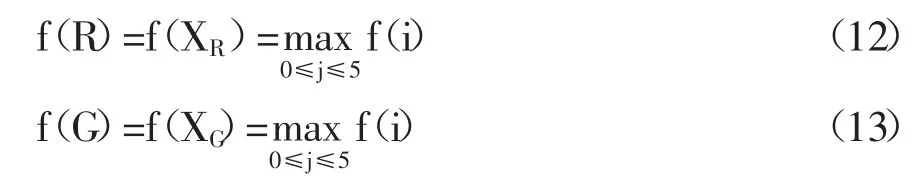
(5)计算最坏点XR的对称点

(6)确定新顶点替代最坏点XR构成新的复合形,方法如下:
若f(XT)>f(G),则用下式修改XT:XT=(XF+XT)/2,直到f(XT)≤f(G)为止,若重复M次未找到XT使f(XT)≤f(G),则直接跳出来重新选择初始的复合形顶点计算,若连续N次直接跳出都未能寻出结果,则选取N次之中最好的结果作为最优解输出[6];
然后检查XT是否满足所有的约束条件,如果对于某个分量XiT不能够满足常量的约束条件,即如果 XiT<ai或者 XiT>bi,则令 XiT=ai+δ或者 XiT=bi-δ。其中δ是一个很小的正数,一般取δ=1×10-6。然后重复(6)。
此时令XR=XG,f(R)=f(XT),重复(4)~(6),直到各顶点的距离小于设定的精度为止,即可获得目标函数的最优值。
离子膜效率优化的结果见表4。

表4 最优膜效率及试验条件仿真结果
表4的仿真结果表明,此种方法得到的最优膜效率93.96%,和其对对应的生产条件。所以,此种方法能够达到预期目标,并能够应用于实际生产之中。
本文从某化工厂采集的756组样本数据的离子膜平均效率为92.85%。所以由此可知,此种方法能够将氯碱电解槽的离子膜效率提升0.5%左右,可以为氯碱生产带来可观的经济效益。
7 结语
本文以氯碱电解槽生产过程为背景,提出利用改进的多种群量子遗传优化BP神经网络建立离子膜效率的软测量,然后用遗传算法对离子膜的电解效率进行优化。此次利用神经网络遗传算法计算出的膜效率为93.36%,在优化之前,电解设备的膜效率仅为92.85%。通过此次优化,膜效率能够提升0.5%左右,带来的经济效益约为200万元/a,从而为氯碱生产过程提供了优化操作指导,可以成为其节能减排的一种方法[7]。
猜你喜欢
化工管理(2022年14期)2022-12-02
计算机仿真(2022年8期)2022-09-28
中学生数理化(高中版.高考理化)(2020年3期)2020-05-30
中国盐业(2018年16期)2018-12-23
郑州大学学报(工学版)(2018年2期)2018-04-13
制造技术与机床(2017年12期)2017-02-02
中国有色冶金(2015年2期)2015-03-06
中国氯碱(2014年12期)2014-02-28
中国氯碱(2014年12期)2014-02-28
中国氯碱(2014年10期)2014-02-28
