
基于优选波长的复合肥总氮含量可见/近红外光谱分析
2018-12-14 01:44汪六三王儒敬鲁翠萍汪玉冰
发光学报 2018年12期
王 键, 汪六三, 王儒敬, 鲁翠萍, 黄 伟, 汪玉冰
(1. 中国科学院合肥物质科学研究院 合肥智能机械研究所, 安徽 合肥 230031; 2. 中国科学技术大学, 安徽 合肥 230026)
1 引 言
我国是农业大国,同时也是施肥大国,化肥的质量一直是农业的热点,高质量的化肥提高了农产品的产量,增加了农民的收入,同时,也为企业的发展打下了坚实的基础。随着我国化肥产品的不断发展,对化肥产品的要求也随之不断提高,但是就目前化肥产品的总体情况来看,化肥产品质量的合格率较低,而且产品的生产并不是非常稳定[1]。企业为了节约成本,减少了化肥抽样样本的个数,使得抽样的样品不能全面地反映生产线的化肥质量。同时,由于化学方法的局限性,使得检测周期变长,滞后性变得非常明显,化学试剂的持续使用对环境也会造成一定的伤害。这些都是化肥企业急需解决的难题。
近红外光谱技术是一种利用物质有机官能团(如C—H、O—H、N—H等)对近红外光的选择性吸收测量物质中一种或几种成分含量的技术。其具有分析速度快、效率高[2]、成本低、再现性好等特点。近红外光谱技术在农业领域有着广泛的应用,如谢越等[3]建立了生物炭的近红外光谱快速分析定量分析方法。刘燕德等[4]利用近红外光谱技术对柑桔黄龙病进行快速无损检测研究。近红外光谱技术在复合肥养分测定方面国内外也做了一定的研究。Janse等[5]使用扫描近红外光谱,实现批量混合肥料的快速检测,经济有效地控制了化肥质量。王献忠[6]采用近红外光谱快速测定复合肥中的总氮量,决定系数达到了0.98以上。苏彩珠等[7-8]进行了近红外漫反射检测复合肥中钾含量和总氮含量的成分,实验结果表明可以对复合肥中的成分连续快速检测,适合大批量样品。郭峥、袁洪福等[9]提出了利用复合肥水溶液的近红外透射光谱进行化学计量学建模,实现了复合肥料多养分的快速检测。宋乐等[10]提出了基于NIRS 测定复合肥料中尿素、缩二脲和水分含量的新方法,有较好的应用前景和实际意义。研究表明,采用近红外光谱对化肥成分进行测量是可行的。
针对复合肥快速检测问题,本文通过近红外光谱结合基础波长加优选波长的方法测定复合肥中总氮含量,为复合肥氮素的快速检测提供了一种新方法。
2 实 验
2.1 复合肥总氮样本及校正集验证集划分
本实验共选取某化肥生产基地不同批次的51个样品,其中2,11,14,19,29,36,45,49号样品表面着有不同的颜色,剩余样品表面颜色均为白色,所有样品都是颗粒状固体。
复合肥的总氮含量由其化肥质检部门测定提供,其分布如表1所示。

表1 51份样品总氮含量测定结果表
Kennard-Stone(KS)算法是根据样本间光谱的欧氏距离来计算样品间差异,为了寻求样本间差异的最佳表达式,用K/S算法能选出更有代表性的样品[11]。本实验通过K/S对选取的复合肥样品进行校正集与验证集的划分。校正集和验证集样本总氮含量统计结果如表2所示。

表2 校正集与验证集样本总氮含量统计结果表
2.2 光谱预处理方法
可见/近红外光谱采集的光谱信息既包含了有用信息也包含了噪声,为了提高复合肥近红外光谱分析的精度,在建模之前,需要用预处理的方法消除噪声的干扰。光谱的预处理技术通常使用的是平滑、一阶导数、二阶导数、标准正态变量转换以及多元散射校正。在实际预处理数据时,会同时使用多种预处理技术相结合,更好地得到稳定的模型。本文采用MSC和一阶导数对光谱进行预处理。
2.3 模型建立方法
偏最小二乘回归(PLS)分析模型是最为常用的化学计量学建模方法,它由Wold等于1983年提出。与传统多元线性回归相比,偏最小二乘法不但能同时分解光谱信息矩阵和浓度矩阵,而且还能很好地消除噪声的干扰[12]。对于PLS,其因子数的选取直接关系到模型的实际预测能力,使用的主因子数过少,则不能充分表达样品的光谱信息;使用的主因子数过多,就会加入噪声,降低模型的实际预测能力。因此,合理确定参加建立模型的主因子数是充分利用光谱信息和滤除噪声的有效方法之一[13-14]。
2.4 模型评价指标
最小二乘回归(PLS)建模方法中,判断模型好坏的基本参数有:模型预测决定系数(R2),直接决定了模型预测值与实测值之间的相关程度;预测标准差(SRMSEP),它反映所建立的模型做预测时,实际值与预测值之间的偏离程度;相对分析误差(KRPD),反映了模型预测的能力,其值越大,回归模型的预测能力就越好。一个预测能力强的模型具有较高的模型预测决定系数和相对分析误差。
(1)
(2)
(3)

2.5 波长选择
由于光谱变量之间存在多重相关性,如果不进行波长的优选,直接采用全波长建模,会大大增加模型的计算负担,最重要的是,模型的预测精度可能大大降低,主要是由于建模过程中引入的无关变量和相互之间存在共线性的变量造成的。通过特定的方法进行波长的选择可以建立更好的回归模型。本文确定波长的方法为采用基础波长结合优选波长的方法,基础波长由不同波段的验证集评价数据决定,优选波长采用以下算法确定:
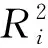
Step2:从notWaveSpedata集合中依次只取一个波长加入到waveSpedata集合中建立模型,得到R2值,加入到R_Square数组。遍历notWaveSpedata集合后,得到R_Square数组。
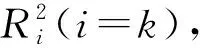
3 结果与讨论
3.1 样品光谱采集
本实验采用的光谱检测仪为中国科学院合肥智能机械研究所自主研发的可见/近红外光谱分析仪,该系统的光谱仪为海洋光学(Ocean Optics)的USB4000和NIRQuest512-2.5, 整个光谱范围为345.8~2 516.8 nm,仪器如图1所示,测量的复合肥原始光谱如图2所示。从光谱图可知,样品在345.8~1 000 nm范围的吸光度大小有明显的差异,这是由于复合肥样品存在不同颜色所造成的。


图2 复合肥样品原始光谱图
3.2 光谱预处理方法选取
由于复合肥样本为颗粒状,需要考虑散射的影响。MSC(多元散射校正)是最广泛的应用于近红外光谱预处理技术,主要用来消除样品粒径大小不一致以及分布不均引起的散射影响。由Martens等人在1983年首次引入[12]。同时考虑到噪声的影响,本文采用MSC加一阶导数进行光谱的预处理。图3、图4分别是经过MSC变换处理,MSC加一阶导数处理后的光谱图。经过预处理之后,样本光谱差异更加明显,吸收峰得到加强。
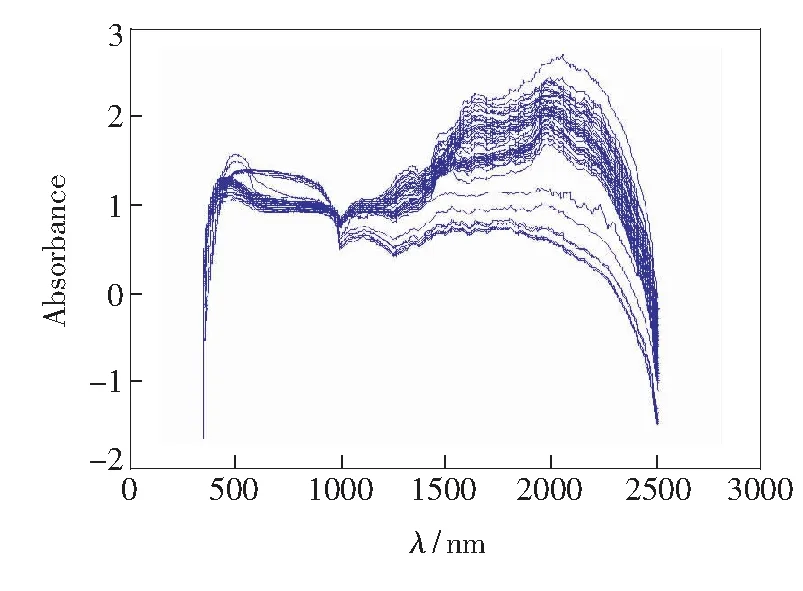
图3 经MSC预处理的光谱图
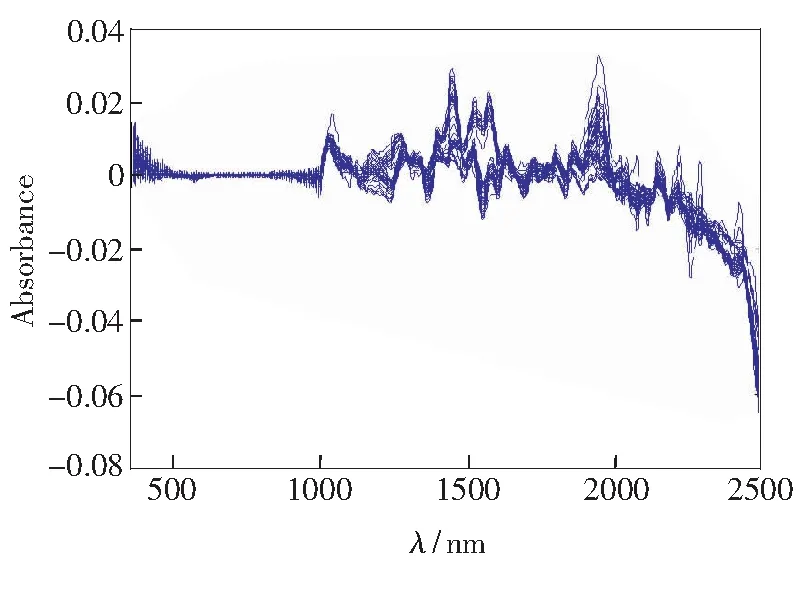
图4 经MSC和一阶导数预处理的光谱图
3.3 最佳主因子确定
由前文可知,主因子数的选取直接关系到模型的实际预测能力。目前常用的选择最佳主因子数的方法有两种:一是交叉验证最小预测残差平方和确定模型的最佳因子数;二是希望交叉验证均方根与校正标准偏差的比值越小越好。本文对波长1 000~2 500 nm采用留一法交叉验证最小预测残差平方和得到主因子数与PRESS值的关系,如图5所示。理想状态下,PRESS值先增大,后迅速减小到整体最小值,最后增大到平稳状态。从图可知,曲线趋势接近理想状态,当主因子数为6时,此时的预测残差平方和为最小。
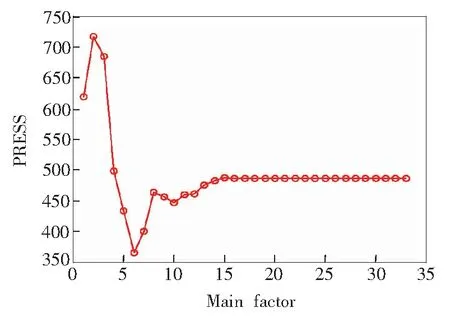
图5 主因子数与预测残差平方和关系图
3.4 PLS模型的建立
由上文可知,光谱变量之间存在多重相关性,不同的波段所含信号的信噪比不同,选择太多的波长建模,可能会引入大量的干扰信号。为了解决上述问题,提出了基础波段加优选波长的建模方法,通过比较建模后验证集样本的评价数据,最终确定建模波长范围。表3给出了不同波长范围下建模的验证集样本评价数据。
由表3可知,当建模数据波长范围在1 000~2 500 nm时,评价指标预测决定系数值达到了0.760 4,SRMSEP=2.044 4,KRPD=2.043 1,相比于其他波长范围内建模,该波段内建模最好。图6给出了上述波长范围下的验证集化肥样本总氮含量真实值与预测值散点图。从图6可知,验证集化肥样本总氮含量的真实值和预测值之间的相关性并不是特别好。由于初始建模波长并不是全波段波长,虽然剩余的波长基本上是对建模无用的干扰噪声,但是可能含有某些有用的信息,所以接下来将对未被选择波长作进一步的筛选。
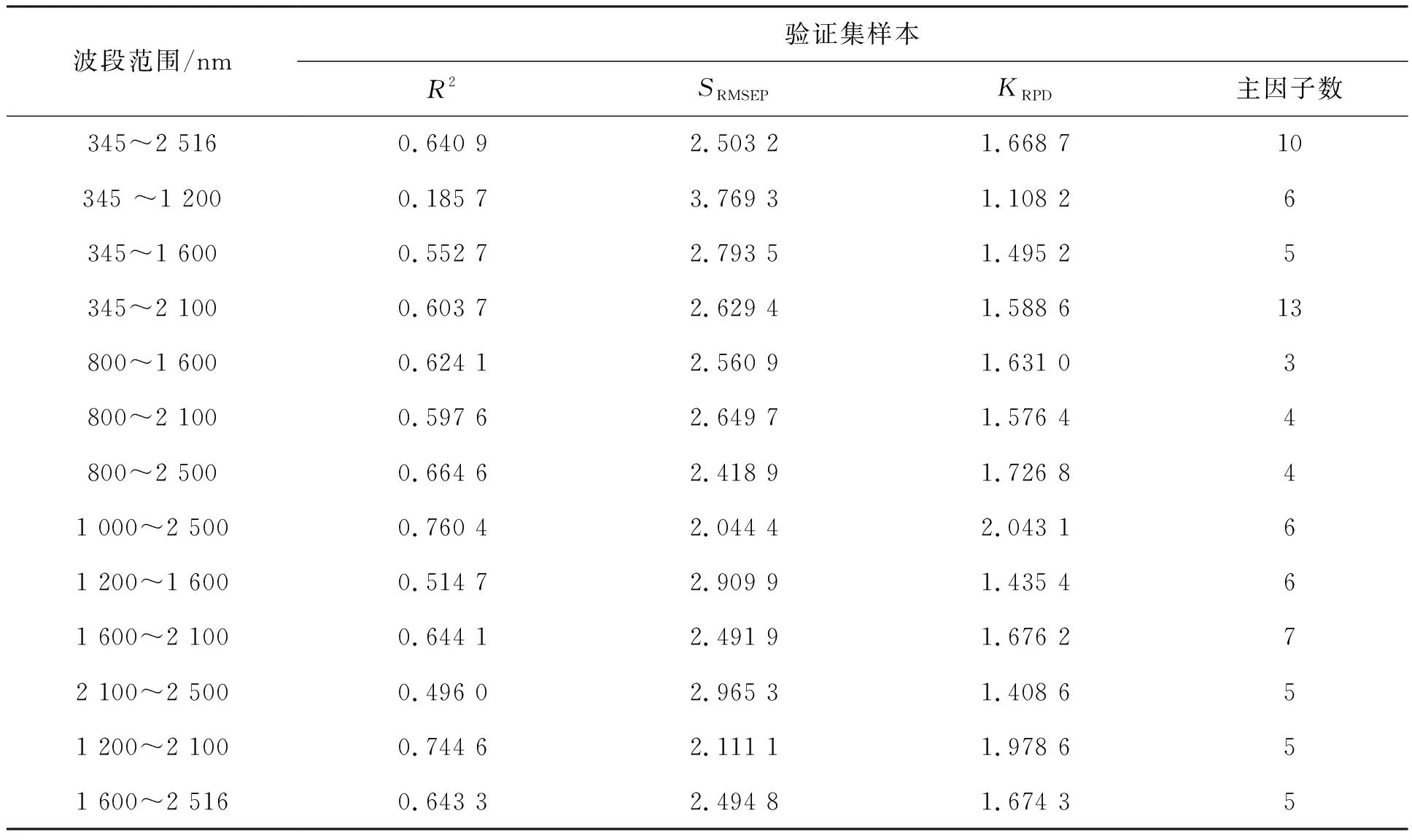
表3 不同波长范围下建模的验证集评价数据
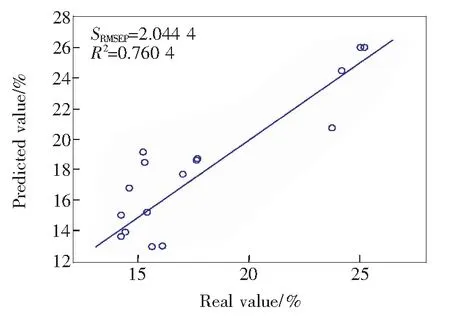
图6 验证集样本总氮含量真实值与预测值散点图
3.5 确定优选波长
按照上述算法进行波长挑选,得到加入优选波长后,波长的个数与模型预测决定系数以及预测标准差的关系如图7、图8所示。由图可知,随着波长数的增加,预测决定系数增加,预测标准差降低;当加入波长数超过49后,预测决定系数和预测标准差不再增加。考虑到在加入波长为40左右时,指标基本上不发生变化,所以本文选择加入波长数为42。
通过以上分析,建立了预测复合肥总氮含量的PLS模型。图9给出了验证集样本总氮含量的真实值与预测值散点图。表4给出了采用优选波长建模和未采用优选波长建模后的评价数据。从图中可知,模型对验证集样本的总氮含量预测决定系数R2达到了0.99以上,同时SRMSEP也只有0.393 8。从表中我们可以看出,采用优选波长后,相对分析误差(KRPD)达到了10以上,预测标准偏差降到了原来的1/5左右,说明模型的预测效果很好。
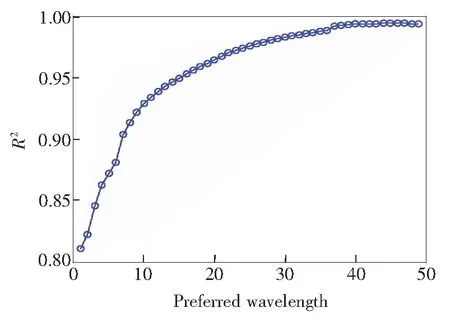
图7 优选波长预测决定系数曲线图
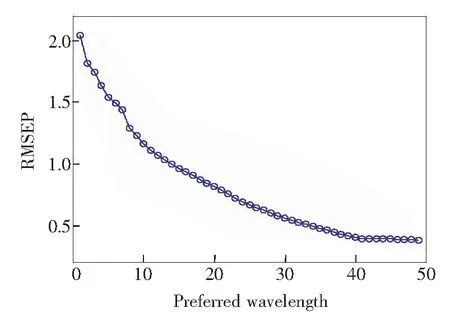
图8 优选波长预测标准差曲线图
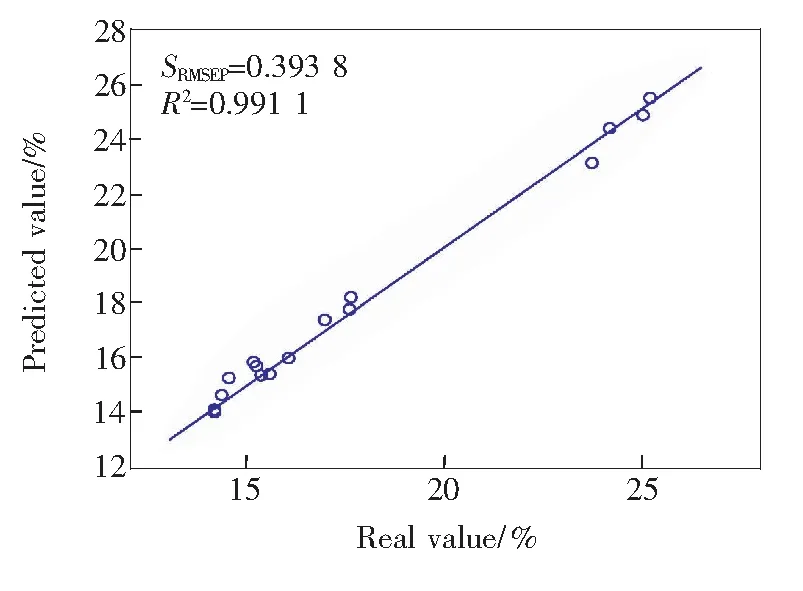
图9 验证集样本总氮含量真实值预测值散点图
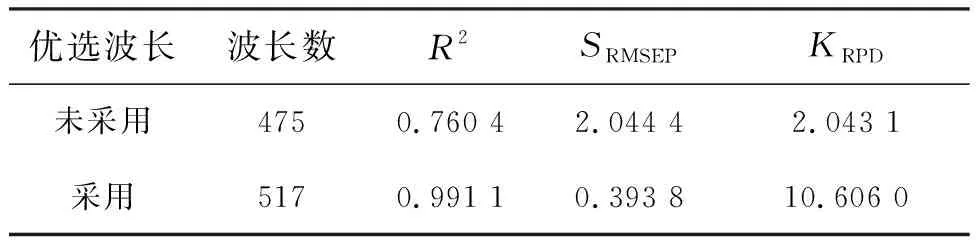
表4 不同波长数建模后的评价指标
4 结 论
本文通过可见/近红外光谱分析仪采集到51份复合肥光谱信息,并使用多元散射校正和一阶导数进行预处理,建立了多个波段的总氮含量的PLS模型,通过比较,在波长为1 000~2 500 nm范围内建模比其他波段范围内建模预测性能更好。同时,在分段建模的基础上,通过优选波长算法,筛选对模型有用的波长数据,提高了模型的预测精度。实验结果表明:不加入优选波长算法,波长数为475个,预测决定系数为0.760 4,模型KRDP=2.043 1;在加入优选波长算法后,波长数据增加42个,预测决定系数达到0.991 1,模型的KRPD=10.606 0,大幅提升了模型的预测能力。同时也验证了研制的可见/近红外光谱分析仪可以对复合肥中的总氮含量实现快速连续测量。特别是对大批量的样本,具有很强的应用价值,未来将利用复合肥自动检测装置,实现复合肥生产线上大批量样本总氮成分实时在线测定。
猜你喜欢
中国化肥信息(2022年8期)2022-11-30
中国化肥信息(2022年9期)2022-11-23
中国化肥信息(2022年2期)2022-04-19
电脑与电信(2021年10期)2021-02-10
今日农业(2020年19期)2020-11-06
南方农业学报(2020年4期)2020-06-04
南方农业学报(2020年10期)2020-01-21
科学与财富(2018年12期)2018-06-11
中国照明(2016年4期)2016-05-17
中国当代医药(2015年26期)2015-03-01
