
基于SVM-Logistic组合模型的P2P借款者信用风险评估
——以微贷网为例
2018-12-07 02:54都红雯卢孝伟
生产力研究 2018年10期
都红雯,卢孝伟
(杭州电子科技大学 经济学院,浙江 杭州 310018)
一、引言
随着经济和网络的不断发展,互联网与传统金融业相结合,互联网金融成为全新的热门话题,作为互联网金融典型代表之一的P2P网贷平台,2005年起源于英国,随后迅速在欧洲、美国、亚洲等地发展,唐宁引进了我国的第一家网贷平台-宜信。在之后十多年的时间,P2P网贷平台在我国开启了爆发式的增长,速度相当惊人,2015年12月18日,宜人贷在纽交所正式上市,这也标志着P2P网贷平台的发展进入一个新纪元。网贷之家发布了《P2P网贷行业2018年5月月报》,月报数据显示,2018年4月,P2P网贷行业单月实现了1 826.6亿元的整体成交量,截至2018年5月底,P2P网贷行业历史累计成交量达到了71 584.64亿元,突破了七万亿大关。与此同时,P2P网贷平台各种问题和弊端也暴露出来,据网贷之家数据显示,截至2018年5月,问题平台累计达到4 270家。这些不断出现问题的平台也给互联网金融的发展带来了诸多负面影响,借款人的信用风险评估与管理也成为了亟待解决的问题。
国外有不少学者对P2P网贷信用评估模型提出了自己的看法,如Fisher(1936)提出信用评分即将个人的情况分级分类,并归类评分;Wiginton(1980)年将Logistic模型率先用于信用风险评估;而Vapnik(2005)提出SVM模型拥有比神经网络模型具有更优的分类精度,对数据假设条件依赖性小,比传统的Logistic模型样本要求低,因而在信用统计方法中广泛传播。Gestel和Baesens(2003)也认为SVM模型在信用风险管理中比神经网络模型和Logistic模型更具有优势,并率先将SVM模型运用于信用风险管理。Carmen(2008)通过对比发现,组合模型比单个模型具有更优的风险预测结果。
而在国内,陈静(1998)率先使用传统的回归模型进行借款人信用风险管理;沈翠华在2005年个人信用评估中首次提出使用SVM模型;张杰、王凡(2008)在对上市公司的信用风险评估中使用了SVM-Logistic组合模型,总结出该组合模型比二者单一模型的预测精度高的特点;向晖(2011)通过对比组合模型和单个模型优缺点后,认为组合模型能为个人信用风险评估准确性和稳健性的最优选择问题给出解决方案。
通过上述论点的研究以及对组合模型和单个模型特点对比研究,本文采用Logistic和SVM模型进行组合,并结合平台本身构建适合其自身特点的信用评价体系,以满足金融创新背景下的平台借款者信用评估的需求。
二、模型的构建
(一)选择组合模型
1.单一模型原理与比较。目前,对个人信用评分方法主要分为统计和非统计两类。统计类一般是贝叶斯网络、Logistic回归模型和决策树等;非统计方法是SVM模型和神经网络模型等。其具体比较如表1所示。

表1 各大信用评分方法比较
2.组合模型的必要性及选择。上述方法都是单一的模型,而在对借款者信用评估的建模过程中,需要考虑预测精度,这些模型都有其各自的优点,预测精度高、稳健性强、或者解释性强等,也有其各自的劣势,其共性是都不能完全在信用评估的内外部因素之间进行有效解释。因而近年来不少学者将单一模型进行组合以期进行信用评估。靳云汇(2005)使用了将Logistic和神经网络模型进行组合的方法;谢行恒(2007)在信用评估中使用了RBF-Logistic混合模型;向晖(2011)将单一模型和多种混合模型进行对比,发现混合模型的稳健性、预测的精度、解释性等都优于单一的模型。
因此,笔者决定将Logistic模型与SVM模型组合进行信用风险评估主要从以下几个方面考量:
(1)SVM模型和Logistic模型具有一定的互补性。SVM模型的预测精度高,而Logistic模型的预测精度低;SVM模型的劣势是稳定性差,解释性低,而Logistic模型的优势是稳定性较好,解释性高。因此二者结合可以互相弥补不足。
(2)两个模型都可以解决非线性问题,且二者对数据的假设要求条件低。
由此可见,SVM和Logistic模型作为组合模型,不仅能体现SVM模型的高精度和Logistic模型的高稳定性,而且Logistic又补足了SVM低解释性的缺点,优化结果。

图1 SVM-Logistic组合模型流程图
图1为组合模型的流程,即为样本数据输入后,率先运用SVM模型进行信用评分,将SVM得出的结果作为一个解释变量和其他的用户个人变量一起作为Logistic模型的解释变量。
(二)SVM和Logistic模型原理
1.SVM的基本原理。SVM一种新式的数据挖掘方法,是常见的一种判别方法。在数据挖掘的领域中广泛运用,SVM模型的核心是将处于低维的样本映射到高维空间中,在高维空间将样本数据以最大间距分隔开来。
假设有线性可分的训练样本(X1,Y1),……,(X1,Y1),X1∈Rd,Y1∈{-1,+1},i=1,…,l,那么一定存在将样本分开的间隔平面ωX+b=0



的条件。二者中位于最优分割超平面上的样本,能使等号成立,这些样本成为SVM。
像本文中信用评分运用的是线性不可分的样本时,则需要把样本通过映射函数转化到高维空间中,转化的映射函数称为核函数。一般的核函数有:

2.Logistic模型的基本原理。Logistic模型是一种广泛运用的线性回归判别模型。假设存在一个因变量Y,表示事件发生可能性大小,当自变量X的值达到阈值时,表示事件Y发生,例如当X>0时,Y=1;反之,Y=0。在本文中,Y=1代表事件发生,Y=0代表事件未发生。假设因变量和自变量 Xi线性相关,即 Yi=α+βXi+δ,则有:


(三)SVM-Logistic组合模型的实现
第一步是通过SVM对样本进行分类;第二步是将SVM得出的自变量和其他变量一起作为自变量带入Logistic模型中,继续进行信用评估。
将P2P借款人发生逾期违约的情况记为Y=1,反之,记为Y=0,则SVM-Logistic模型为:

在式(8)中,P代表借款人逾期违约的概率,1-P为借款人按期还款的概率,P越大,违约概率越大,反之越小。本文将第一阶段通过SVM得到的结果作为特征向量,再加上一组特征向量X={X1,X2,…,Xn},总共有 n+1 个自变量,以上述变量搭建SVM-Logistic组合模型来对借款者进行信用风险评估,得出最终结果。
三、实证检验
成立于2011年7月的微贷网,是中国首家专注于汽车抵押借贷服务的P2P网贷平台。据网贷之家公布的2018年6月网贷平台评级TOP50中,微贷网位居第6名,成交量排名第7,处于行业较领先的地位。截止2018年7月31日,微贷网累计成交额1 984.5亿元,交易总笔数超过470万笔,在整个P2P网贷平台中表现出较强的综合实力且有较为良好的后续发展趋势,具有一定的代表性。因此,本文选取微贷网作为研究P2P网贷公司的例子,即以微贷网平台作为研究对象,构建P2P网贷个人借款者信用风险评估模型。
(一)微贷网的借款者情况
微贷网的网站呈现借款人信息界面中主要包括但不限于以下有用信息:项目情况下的项目总额、项目期限、预期利率;借款人信息中的性别、年龄、婚姻状况、籍贯、行业、工作性质、收入及负债情况、还款来源与征信情况;借款车辆信息中的购买价和抵押价、行驶公里数;借款记录中的历史还清期数、待还期和历史逾期次数等。
笔者通过运用网页数据抓取软件“爬山虎采集器”,收集了2018年7月的散标借款者的数据,共6 917个有效样本。其中的借款金额最大值为585 000元,最小借款金额为4 500元,均值为73 562.36元;借款期限最长为36个月,最短为1个月,均值为2.73个月;借款利率,最大值为6.3%,最小值为5.8%,均值为6.03%。
在6 917位借款者中,其年龄分布为18~22岁166位,占比 2.4%;23~25岁 446位,占比 6.45%;26~30 岁为 1 353 位,占比 19.56%;31~42 岁为2 910位,占比 42.08%;43~50岁为 1 535位,占比22.19%;51~60岁为 454位,占比 6.56%;60岁以上为45位,占比0.66%,可见该平台的借款人员主要集中在26~50岁的人群。借款人的性别方面,女性1 240位,男性借款人5 677位。婚姻状况,已婚5 647位,占比81.64%,未婚的1 270位,占比18.36%。
汽车购买价格主要分为以下几档:100万元以上汽车 393辆,占比 5.7%;80万 ~100万元 325辆,占比4.7%;60万 ~80万元181辆,占比 3.6%;40万 ~60万元673辆,占比9.73%;20万 ~40万元1 580辆,占比22.8%;20万元以下3 765辆,占比54.4%。
在该平台的借款人借款历史还清期数大部分在50期以前,约占据了95%的比例。在该平台的借款待还期数,待还期为2—4期的占了59%,待还期在5—12期的占了28%,分布主要还是集中在2—4期。借款人中有过逾期情况的占20.95%,没有历史逾期的占了79.05%。
(二)评估指标选取
本文首先参考美国的FICO评分系统和国内的芝麻信用评分系统对借款者信用风险评估的方式,借鉴其个人信用风险评估体系的各项指标及评分,同时结合微贷网本身的相关指标,对评估指标做一个初步的选取。
FICO评分系统对个人信用风险评估一级指标分为五类,分别是个人基本信息、不动产信息、拥有信用类型、信用情况和债务情况。个人基本信息包括职业信息和工作年限;不动产信息包括住房和居住年限;拥有信用类型包括信用卡数和银行账户数;信用情况包括了信用档案年限和逾期记录;债务情况则是用户债务比例。
芝麻信用评分系统对个人信用风险评估指标也是分为五类,分别是历史信用、行为偏好、履约能力、身份特质和人脉关系。历史信用包括了信用卡张数、信用卡额度和信用卡级别;行为偏好包括了账户活跃、消费金额、消费场景和消费层次等;履约能力包货了账户资产、有无住房和有无车辆等信息;身份特质则包括了职业类型、学历级别、住址稳定和手机稳定程度;人脉关系包含了社交广度、社交深度和人脉信用度。
通过对上述FICO和芝麻信用的评分指标和分值分级的研究,本文采用FICO评价的分值赋予方式,参考了芝麻信用评估的方法,挑选了微贷网中可用的指标以构建评估指标体系。评估指标分为三类,分别是个人信息、抵押物信息和平台借贷信息。个人信息包含了性别、年龄和婚姻状况;抵押物信息包含了购买价格和行驶公里数;平台借贷信息包含了历史还清期数、待还期和历史逾期数。
(三)数据量化
本文决定对微贷网8个指标进行如下的量化:
性别,赵旭等(2016)经过实证研究发现,男性违约的可能性比女性的要高,而且男性借款通过率仅为女性的60%,所以对男性赋值3,女性赋值7。
年龄,经研究发现,年龄在18~22岁的借款人,一般是无收入人群或是低收入人群,年龄在23~30岁的群体,收入相对低,工作较不稳定,而60岁以后的面临着退休,收入相对在职是要低的,因而31~60岁之间的人群收入是相对稳定的。因此赋值18~22岁之间的为2,23~30岁之间的为4,31~60 岁的为 8,61 岁及以后的为 4。
婚姻状况,微贷网借款者的婚姻状况分为已婚和未婚两种。本文认为已婚的家庭,具备双收入来源,更加有还款能力,并且有更大的责任感,因此未婚的赋值0,而已婚的赋值5。
抵押物的购买价格,微贷网以车作为抵押物,而不同的车有不一样的购买价格,购买价格体现了借款者的购买能力。根据不同的购买价格赋不一样的值。20万元以下为 2,20万 ~40万元为4,40万~60万元为6,60万~80万元为8,80万~100万元为9,100万元以上为10。
行驶公里数,5万公里以内为 10,5万~10万公里为8,10万~20万公里为6,20万~30万公里为 4,30万~40万公里为 2,40万 ~50万公里为1,50万公里以上为0。
历史还清次数,还清一次,为2分,之后每增加一笔还款加1分,最高为10分。
待还期,由于微贷网自身原因,只有还款中的借款人有待还期,而申请借款的不存在待还期,待还期数越大说明还款能力越弱,因此0次为10,每增加一次减1,10次及以上为0。
历史逾期数,不违约为5,逾期每增加一次减1,5次及以上则为0。
以上为8个输入变量的量化分析,量化后的样本使用SVM-Logistic模型进行评估。在本文中,先用5 917个样本进行训练,训练后再用1 000个样本加以测试其准确性。
(四)主成分法处理指标
在使用SVM-Logistic组合模型进行信用风险评估前,先用主成分分析法对指标进行处理,将性别(X1)、年龄(X2)、婚姻状况(X3)、购买金额(X4)、历史还清次数(X5)、待还期(X6)、历史逾期期数(X7)、行驶公里(X8)作为解释变量,导入 SPSS 软件中分析降维,进行显著性检验,结果显示,KMO值为0.76,Bartlett的值在0.05的检验标准之下,数据通过检验,可以进行主成分分析降维。
提取特征值大于1的主成分使用SPSS软件,得到以下3个主成分:

由上式所示主成分Y1中年龄和婚姻状况的权重较大,本文将其命名为基本因子。主成分Y2,历史还清期数和待还期的系数比较高,命名为网贷因子。主成分Y3的系数中,购买金额的权重较大,因此命名为购买因子。
(五)SVM-Logistic模型在信用风险评估中的应用
使用组合模型进行风险评估,具体操作如下:
第一步:通过各个核函数分类结果比较,选取合适的核函数用于信用评估。
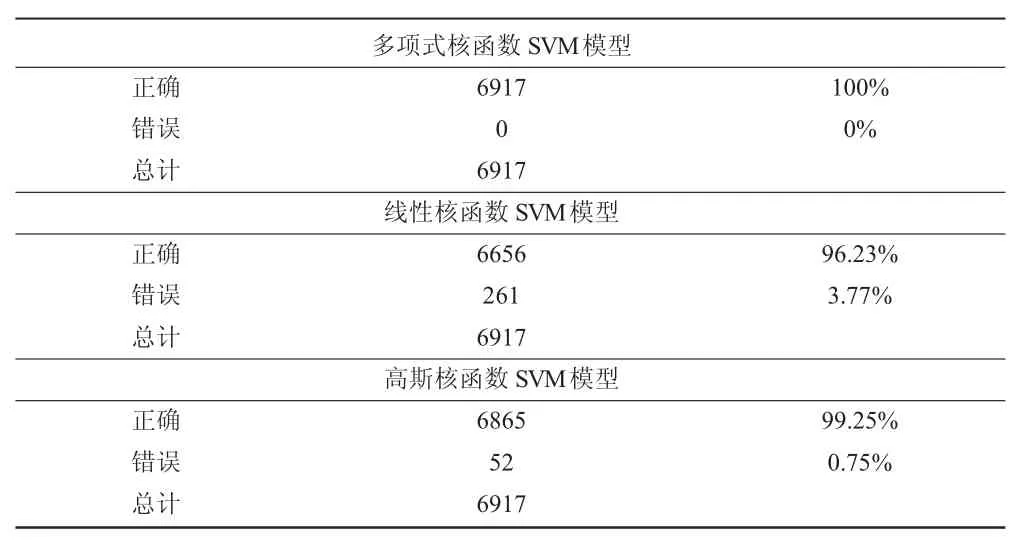
表2 三类核函数模型精度对比
通过比较表2中三种不同核函数的精度发现,三种核函数的预测结果都不相同,多项式核函数的预测结果精确度极高,线性核函数则差强人意,高斯核函数的预测结果也很高,但仍不如多项式核函数,因此本文使用多项式核函数进行分类。
第二步,使用多项式核函数进行样本分类,并将结果作为一个自变量带入Logistic模型中参与训练测试。
(六)SVM-Logistic组合模型的实证结果与检验

表3 三类模型训练集与预测集结果对比
通过表3中的训练集结果来看,Logistic模型的预测性较差,组合模型与SVM模型的预测结果几乎相同,说明组合模型和单一模型在训练集上具有较高的预测精度。而从表4中测试集分类结果看来,组合模型的精度仍高于单一模型,单一模型相较于组合模型而言,两者的波动相对较大,所以可以得出结论,组合模型精度高,准确性好。

表4 组合模型回归结果
根据表4可知,这三个主成分的P值都是在0.05标准以下的,都通过了检验,因此将以上主要成分代入SVM-Logistic二元回归模型得到以下模型:

进一步可以求得违约率为:

上述公式(13)中,P越接近于1,借款者逾期违约概率大,反之能按期还款。因此从组合模型的公式中可以看出,待还期X6和历史逾期期数X7越高,即得分越低的借款者,违约概率越大,而婚姻、年龄、购买金额得分越高的借款者,越不容易违约。
(七)指标修正
在上述结论的基础上,通过缺失各个变量的方法测度各指标的重要性。结果显示:组合模型在缺失历史逾期次数时,预测准确率有较大提升,从76%提升到了86%,说明该指标对信用风险评估产生了干扰;年龄、婚姻状况、购买金额和行驶里数的缺失对预测准确率没有影响;性别和历史还清次数的缺失使预测准确率有了提高,但是波动很小,模型具有较好的稳定性;而待还期的缺失,反而使得预测准确率下降,说明该指标对网贷借款者的信用行为有较大的影响,不可缺失。
综上所述,选择剔除历史逾期次数这个指标,1 000个测试样本的预测准确率达到了86%,因此得到了修正后的评估指标如表5所示,与最初构建的指标相差了一个历史逾期次数。

表5 修正后的评估指标表
使用SVM-Logistic模型对微贷网借款人信用风险进行了评估,模型得到准确率从初始的76%提高到了86%。微贷网上的借款者信息中,性别、年龄、婚姻状况、购买价格、行驶公里、历史还清期数和待还期这7个指标成为了构建SVM-Logistic组合模型的重要指标,同时SVM-Logistic模型回归结果为微贷网平台的借款者信用风险评估提供了参考,减小了投资者的投资风险,适用于网络借贷中借款者的信用风险评估。
四、结论与建议
本文根据微贷网的特点及相关指标,借助FICO和芝麻信用评分法进行指标选取及量化,建立了借款者信用评估模型,利用该平台的借款数据进行了SVM-Logistic组合模型的实证分析,进行信用风险评估测试,得出评估结果。在此基础上,对评估指标进行优化,使评估指标也能适用于其他平台。根据实证结果,对于微贷网平台来说,借款者的性别、年龄、婚姻状况、汽车购买金额、历史还清期数、待还期和行驶里数等指标都是模型的重要因素,然而指标中包含了微贷网独有的指标行驶里程数和汽车购买金额。剔除这两个指标之后的剩余指标,借款者个人的基本信息较多,因此对于P2P网贷平台来说,借款者的基础信息对P2P网贷借款者的信用风险评估有很重要的意义。其中性别、年龄、婚姻状况在模型中的系数都是负的,与预测结论成负相关,表明女性较男性违约风险小,已婚的较未婚的违约风险小,年龄在31~60岁之间的较其他年龄的违约风险小。
为了促进P2P行业的良性发展,结合本文的研究结果,提出以下建议:
第一,加快设立网贷行业统一的信用风险评估标准。信用风险评估是金融网贷方向上的一大热点,网贷行业由于在我国处于兴起阶段,还没有统一的信用风险评估标准。使用一种统一的评估标准,高效精确评估、遴选借款申请者,对P2P网贷行业的发展相当关键。P2P网贷是一种全新的线上借贷模式,可以使借贷双方摆脱空间限制,让不能正常从银行借款的借款者筹集资金,也能让贷出者享有一定的投资收益。通过SVM-Logistic信用评估模型得出的评估结果可以运用于P2P网贷平台风险评估,有助于提升P2P网贷平台的风险监控管理能力,进而促使网贷行业良性发展。因此各大平台应联手建立统一的P2P网贷信用风险评估标准,使得P2P行业得以健康发展。
第二,政府应主导建立共用的个人信用记录数据库,银行向网贷平台开放个人用户的信用记录以用于平台的信用管理。现阶段,网贷平台鱼龙混杂,各平台只能在平台内部进行信用公布和管理,却不能平台共享借款人的违约记录等。建议各大网贷平台能建立共享的违约人名单机制,从整体上提升平台借款者信用识别能力。此外,将借款者违约情况纳入其个人档案中,促使其按期如数还款。
猜你喜欢
法制博览(2019年29期)2019-12-13
中国外汇(2019年10期)2019-08-27
上海财经大学学报(2019年3期)2019-06-04
瞭望东方周刊(2018年4期)2018-02-01
商周刊(2017年17期)2017-09-08
商周刊(2017年17期)2017-09-08
辽宁经济(2017年6期)2017-07-12
当代经济(2016年26期)2016-06-15
黑龙江科学(2016年22期)2016-03-16
新疆财经大学学报(2015年3期)2015-12-10
