
基于路径旅行时间分析的交通异常检测方法
2018-12-06 07:08:14熊雨沙王骋程郑治豪鲁恒宇
电子科技大学学报 2018年6期
王 璞,熊雨沙,王骋程,郑治豪,鲁恒宇
(中南大学交通运输工程学院 长沙 410075)
交通异常状态检测是当前交通领域中一个非常重要的研究方向。迄今为止,国内外已有的相关研究多数利用了线圈[1-2]、视频[3-5]、红外传感装置[6]等固定传感设备采集数据。然而,由固定传感设备采集的数据多限于检测器断面[7],使交通异常检测受到了很大局限。随着全球定位系统(GPS)的日益普及,许多城市已可以实现对移动对象的实时跟踪,用装有GPS接收器的车辆作为移动传感器来采集交通状态信息,具有成本低、灵活性强、数据量大等优点[8]。近年来,基于车载GPS数据的研究主要集中于车辆路径选择模式及路段异常判别两个方面。
在车辆路径的选择模式方面,文献[9]将路径分割为若干子路径,通过比较子路径组成的相关多维向量,找出其中的异常子路径,从而发现城市的异常路径选择行为;文献[10]挖掘相同OD之间的不同路径,提出了用流量构成描述向量的方法,挖掘人类出行异常模式子图,并利用社交媒体数据进行异常信息的补充;文献[11]提出了基于车辆移动轨迹在线检测异常轨迹的算法。这类方法研究重点在于发现人类的出行规律。
在路段异常判别方面,文献[12]通过比较观测路段与其他路段的相似性,构造包含历史趋势信息的状态向量,提取出离群点作为异常值;文献[13]通过比较路段真实值流量和期望值流量,判断路段是否为异常路段。基于路段的异常判断能直观清晰地反映路段通行情况,但缺乏对路段之间内在联系和相互作用的融合,难以确定异常产生的根源并进行疏导;文献[14]针对车辆运行状态如速度、加速度等的变化,推测当前行驶路段是否异常,但这类方法需要考虑不同等级路段固有属性对车辆通行状态的限制,应用难度较大。
为了解决现有交通异常检测方法遇到的难点,本文提出一种基于路径旅行时间分析的交通网络异常检测算法。该算法以Map-matching技术和DBSCAN聚类算法为基础,且与传统方法相比具有以下特点:
1) 以路径为研究对象。
与基于路段的交通异常检测方法相比,基于路径的交通异常检测具有以下优点:首先,该方法可以获得更多样本量,减小偶发情况对整体检测结果的影响。其次,该方法能综合考虑连续路段交通状况的累加影响,对不同程度交通状况的检测结果更为精确。最后,异常路径的发现能直观显示交通异常状况影响区域,多个异常路径的累加更容易形成交通异常子网,便于发现交通异常的影响程度及传播规律。
2) 以旅行时间为判断标准。
本文利用浮动车GPS数据得到的路径旅行时间数据能够避免路段固有属性比如车道数、路面状况等对上述指标的影响,无需相应的路段参数即可对交通状况进行判断,方法简单,通用性强。
1 路网数据与出租车GPS数据
1.1 路网数据
使用由图1所示,26 242个节点和43 134条边组成的高精度深圳路网数据。为了提高算法效率,将城市分割为83×43个1000 m×1000 m的地理子区,以地理子区为单位进行交通异常检测。
1.2 出租车GPS数据
采用由13 584辆配备GPS接收器的出租车采集的GPS数据,平均数据采集频率为15 s/次,使用2014年10月所有工作日共916 851 503个GPS坐标记录。由于出租车空载寻客时一般车速较慢,路段速度不具有代表性,因此删除出租车在空载状态下的GPS数据。由于少量GPS采集设备故障,还需要对GPS数据进行清洗,删除出租车日出行次数(由载客状态转变为空载状态为一次出行)大于500次的GPS设备所产生数据。为保证单位时间内充足的GPS记录数量,只使用6:00-23:00时间段的数据。经过以上数据预处理,平均每天有13 446 868条出租车坐标点记录被保留下来。
2 出租车行驶路径的获取
在一个地理子区中,满足以下条件的GPS轨迹点组成轨迹 T = p1→ p2→ … → pn。
1) GPS轨迹点有可能匹配到与其临近的任意一条路段上,所以需要采用缓冲半径公式,以GPS轨迹点为中心确定搜索范围,选择范围内的路段作为候选匹配路段,有:
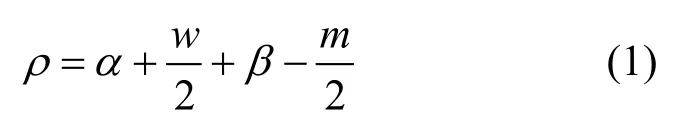
式中,参数α是道路网定位误差;参数w是单向道路的宽度;参数β是车辆定位的最大误差;参数m是车辆宽度[15]。经调研,深圳市最宽道路为深南大道,路面净宽80 m,除去16 m绿化带宽度,单向道路宽32 m,其他参数的取值参考文献[15]:α=5,β=10,m= 2 ,得到ρ=30。本文将搜索范围略微扩大,取值35 m,并删除35 m范围内没有路段的GPS轨迹点。
2)pi对应的时间标签值递增。
3)pi和pi+1之间的时间间隔小于45 s。
如图1所示,虚线框表示一个地理子区,图中p1→ p2→…→ pn为地理子区中一条满足条件的轨迹。

图1 深圳路网和地理子区GPS轨迹
为了计算出租车的行驶路径和路段的通行速度,使用ST-matching地图匹配算法[16]将GPS轨迹匹配到路段上。该算法以路径为匹配对象,结合了路网拓扑结构和地理信息,是一种全局的地图匹配算法,对低频的GPS数据也能保持较高的匹配精度,并能方便地获取路径和路径的旅行时间。算法步骤如下:
1) 获得候选路径。
对于一条GPS轨迹 T = p1→ p2→…→ pn,当pi与路段的距离小于d=35 m时,将加入pi的候选匹配边集合中,pi在上的投影则为pi的第j个候选匹配点,将n个轨迹点相邻两点的候选匹配点两两组合,可得到该轨迹的若干条候选匹配路径。
2) 空间分析。
ST-matching算法中,路网的地理信息和拓扑结构都被用来评价候选匹配路径与GPS轨迹的匹配程度,地理信息评价值用观测可能性来衡量,拓扑结构评价值用传递可能性来衡量。
观测可能性用pi与的距离来衡量pi匹配到的概率。定义pi匹配到的观测可能性 f ()为:
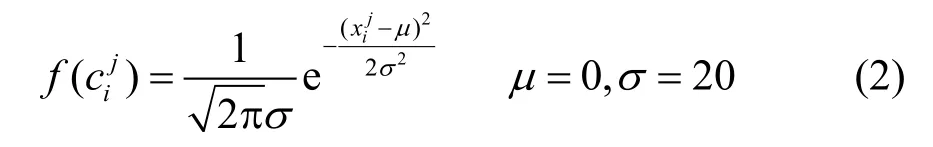
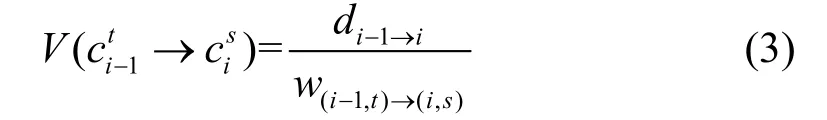
式中, di-1→i=dist(pi-1,pi)为pi-1与pi之间的欧式距离;为和的最短路径长度。
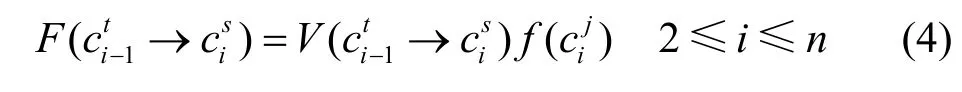
3) 路径匹配。
匹配可能性最高的路径为T的最终匹配路径为:
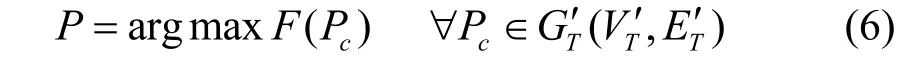
图2表示一条待匹配轨迹 T = p1→ p2→…→pn,三角形标识的点都是待选的候选匹配点,p5和p6各有两个候选匹配点,实线和虚线分别为两条候选匹配路径,经计算,经过和的路径匹配度更高。该路径的旅行时间为起点与终点,即p1与p6的时间标签的差值,pi-1到pi的行驶速度为:
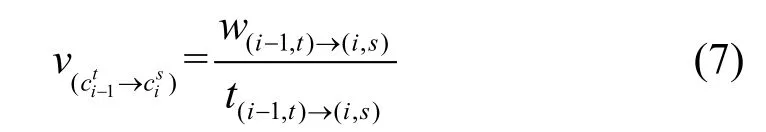
式中, w(i-1,t)→(i,s)是pi-1到pi的最终匹配点之间的最短路径; t(i-1,t)→(i,s)是它们之间的时间差。如果同时间段一条路段上有多个速度记录,可计算得到路段的平均通行速度。
由于所使用的路网精度较高,可能存在因起点或终点不在同一条路段的细微差别,而将两条轨迹判定为经过不同路径的情况。为了保证路径判定有一定的容差率,将地理子区进一步划分为100 m×100 m的格子,如果两条轨迹途经的细分网格相同,则认为它们经过同一条路径。

图2 地图匹配算法示例
3 路径的交通异常判断算法
本文采用基于密度的DBSCAN聚类算法[17]对通过同一条路径所有轨迹的旅行时间进行聚类。该算法需要确定两个参数:EPS邻域和最小样本数MinPts,参数的选择对聚类的结果影响较大,较小的EPS和较大的MinPts会导致算法对路径旅行时间异常的判断不够敏感,反之,会过于敏感。使用欧式距离计算两点之间的距离为:
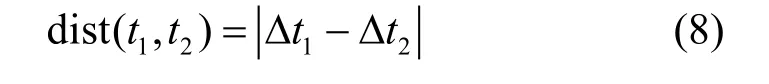
30 min是目前交通状态短时预测常用时间段之一[18],且能保证一条路径有足够数据量来进行聚类分析,所以,使用30 min作为时间窗,定义每个时间窗的数据为一个聚类数据集,并将聚类数据集中的每个实例除以数据集中实例的最大值,实现所有实例的归一化。根据文献[17]对参数EPS值和MinPts值选取方法的介绍,先确定MinPts取值为4,然后找到4-距离的突增位置来确定参数EPS的值,方法如下:首先计算每两个实例之间的欧式距离,找到与每个实例最邻近的第4个实例,二者之间的距离称为4-距离。然后对一个聚类数据集中实例的4-距离进行概率统计,发现绝大多数数据集的4-距离概率呈指数分布。最后对概率分布进行指数拟合,选取斜率为-1处对应的4-距离作为EPS值。图3a是对某个聚类数据集的4-距离进行归一化后的概率分布图,图3b是将图3a中局部区域放大后,做拟合曲线斜率为-1处的切线,对应的横坐标为EPS取值。
经过聚类后,聚类数据集中的实例被分成m个团簇,定义拥有最多实例的团簇为中心团簇,中心团簇中最大值为初始异常阈值,初步认为数据集中、所有小于初始异常阈值的对象是初始正常值,初始正常值的平均值 t为路径在所测时间段的正常旅行时间。由于存在少量聚类数据集,使实例的4-距离不满足指数分布,且拟合的效果不稳定,为减少DBSCAN参数对阈值计算结果的影响,根据常用异常检测方法三倍标准差准则[19],计算初始正常值的标准差σ。定义 t+3×σ为路径在该时间段内的异常阈值。如图4所示,图4a为某条路径10月份工作日10:20-12:30所有旅行时间,虚线为每30 min路径旅行时间的异常阈值。每10 min计算一次待测路径的平均旅行时间,图4b为某条待测路径在10:20-12:30不同时间窗进入地理子区时,路径的平均旅行时间,与对应时间窗的异常阈值对比,虚线空心点所表示的旅行时间值超出了异常阈值,由图可知,异常持续了50 min,即11:00-11:50。

图3 DBSCAN算法参数选择
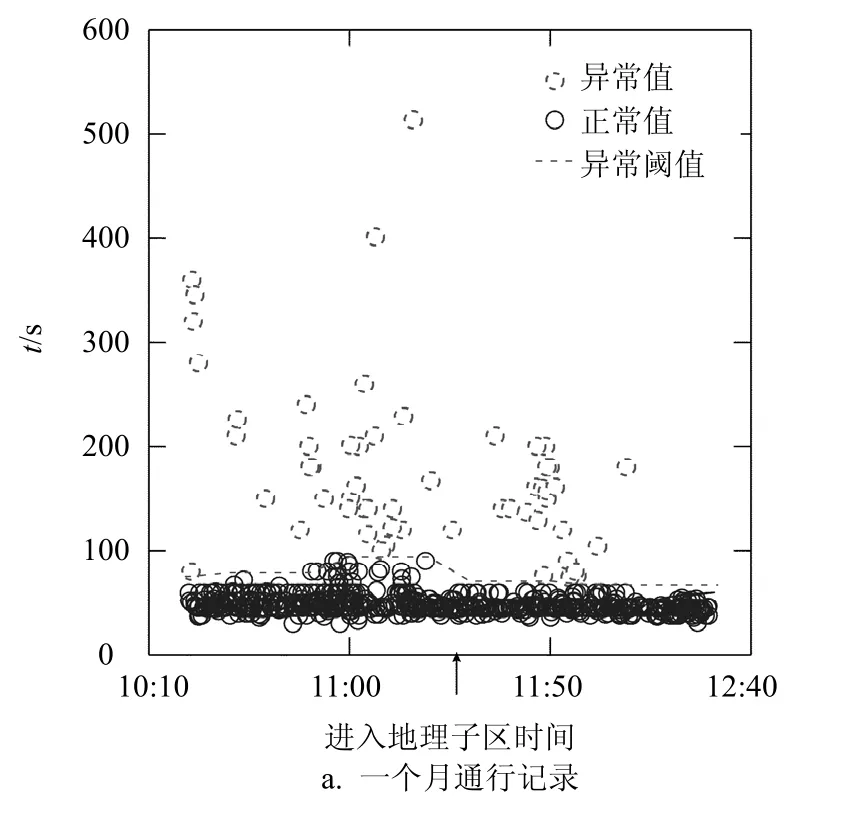
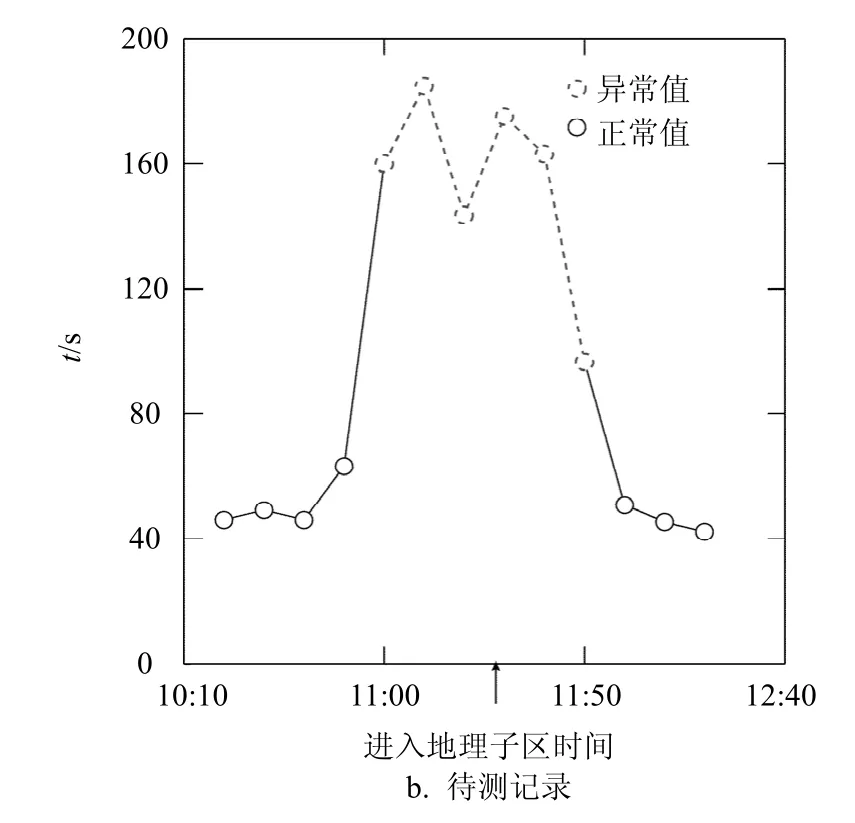
图4 路径旅行时间异常判断
4 地理子区交通异常检测案例
交通事故或交通拥堵等交通异常事件的显著特点是造成路段通行速度降低,因此,大量的研究基于路段的速度、流量等属性进行路段状态识别。然而,这种异常识别方法也存在一些不足。一些路段的速度表现出不规则的波动给交通异常判断带来困难,如图5a和图5b所示。因此,选择路径的旅行时间作为研究对象,能综合考虑多个邻接路段的通行情况,减小异常检测误差,如图4b所示。
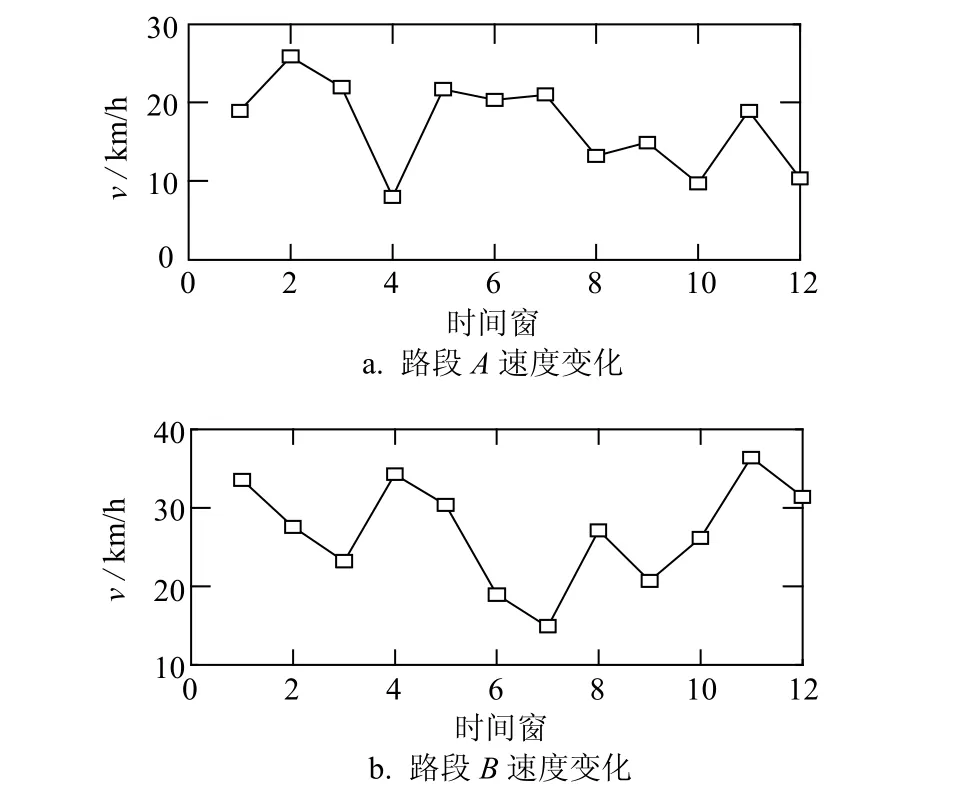
图5 路段速度计算
使用上一节阐述的方法计算各路径的异常阈值,图6为某地理子区中检测出的4条异常路径旅行时间随时间的变化,4条路径的旅行时间均在第6个时间窗开始突增并超出异常阈值,于第8个时间窗附近达到相对高峰之后逐步恢复正常。由图6a可知,该条路径正常通行时的旅行时间约50 s,而旅行时间异常值最高达280 s。

图6 路径旅行时间随时间变化
为衡量异常路径覆盖路段受影响程度,引入R值进行计算:计算路径在各个时间窗的受影响程度=平均旅行时间/t,取受影响程度最大的时间窗进行各路段R值的计算:

式中,vr为一个月中该时间窗的平均通行速度;va为受影响程度最大时间窗的平均通行速度。图7a所示为路径1在第8个时间窗依次经过路段vr和va的对比。
图7b中加粗路段为异常路径覆盖路段,由R值分布可看出各路段受影响的程度。

图7 路段速度分析
为验证该交通异常检测结果,从新浪微博中搜索信息,发现如表1所示事件。

表1 微博实例
该事件初始定位在图7b所示的地理图标位置,事件描述与所测交通异常基本相符,微博所反映的事件发生在11:28,为图6中箭头所示位置。而算法在11:00就检测出交通异常,比微博发出提前28分钟,微博发出时间基本位于路径旅行时间最大的时间窗内,从微博内容可看出此时交警还在赶往途中。图6b展示了交通异常的产生和消散过程,图7b展示了交通异常的集中区域。
将地理子区内所有交通异常路径经过的节点和边组成的网络定义为“基于路径的交通异常子网”,如图8a中的粗线所示。建立基于路段的交通异常子网用于比较。定义路段在检测时间窗的车辆行驶平均速度μc,路段在工作日相同时段的车辆行驶平均速度为μm,标准差为σe,当μc< μm-3 × σe时认为路段的车辆行驶速度发生异常。提取车辆行驶速度发生异常的边组成的网络,得到“基于路段的交通异常子网”,如图8b、图8d所示。
在发生交通事故的时间窗:基于路径的交通子网连成一个大团簇,如图8a所示;而基于路段的交通异常子网分布较为杂乱,有几个零散的团簇,如图8b所示。在交通运行正常的时间窗:基于路径的交通子网根本不存在,如图8c所示;而基于路段的交通异常子网还是有一些零散的小团簇存在,这是由于个别路段偶发速度波动引起的,如图8d所示。可以看出,基于路径的交通异常子网在交通正常与异常状态下的区别更为明显,有助于提高交通异常判断的准确性,上述结果也体现了基于路径的交通异常检测方法的优势:有利于减小偶发情况对整体检测结果的影响。
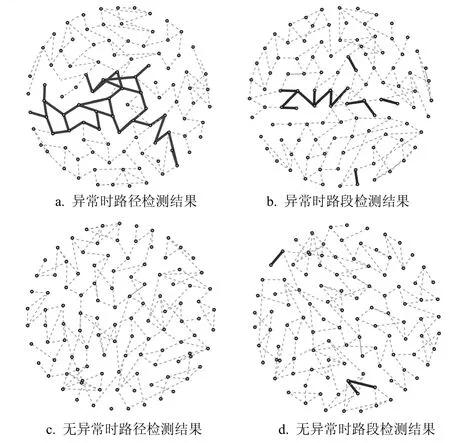
图8 异常网络规模
5 结 束 语
近年来,随着数据分析挖掘技术的发展,路段旅行时间和拥堵的判别方法已经日益成熟,出行者在出行时可以借助各种软件,查看到各个路段的实时路况信息,比如拥堵情况、运行速度、限速情况等。但是,局部的、可以自行消散的路段异常出现频繁,使交管部门较难准确识别出真正存在严重问题的区域。
本文针对有一定规模的道路交通异常突发情况,提出了基于路径旅行时间的交通异常检测算法。该算法不同于常用的基于路段通行能力和状态进行异常检测的方法,可以减少由单一的路段信息和车辆偶然因素导致的异常误判,检测出具有规模的、自行消散困难的、异于历史通行状态的交通异常网络,为交通管理部门提供可信度更高的交通异常监测结果。算法在现实路网和真实数据环境下的应用证明其检测的交通异常时空信息及时有效,所检测出的带有时间和空间信息的交通异常,能为交通管理者疏导交通提供重要管控和决策信息。
本文研究得到霍英东青年教师基金基础研究课题(141075)及中南大学创新驱动计划(2016CSX014)的资助,在此表示感谢。
猜你喜欢
工会博览(2022年5期)2022-06-30 05:30:18
中国交通信息化(2021年2期)2021-07-22 07:34:40
IEEE/CAA Journal of Automatica Sinica(2021年2期)2021-04-22 03:54:26
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
建材发展导向(2019年11期)2019-08-24 06:34:56
现代装饰(2018年5期)2018-05-26 09:09:39
电子测试(2017年15期)2017-12-18 07:19:27
中国三峡(2017年2期)2017-06-09 08:15:29
智能系统学报(2015年4期)2015-12-27 09:38:39
