
基于运动特性的HEVC帧间模式快速决策算法
2018-12-04 02:14:24张亚军
计算机工程与应用 2018年23期
张亚军,李 强
重庆邮电大学 通信与信息工程学院,重庆 400065
1 引言
随着高清、超高清和高帧频数字视频消费需求的增长,人们对数字视频的压缩效率提出了更高的要求。由于H.264/AVC在编码效率、并行处理等方面存在着局限性,已经难以满足高清视频应用发展的需求。为了满足海量高清视频数据的传输和存储要求,ITU-T视频编码专家组(Video Coding Experts Group,VCEG)和ISO/IEC运动图像专家组(Moving Picture Experts Group,MPEG)于2010年1月联合成立了视频编码联合协作小组(Joint Collaborative Team on Video Coding,JCT-VC),专门制定下一代视频编码标准。2013年4月JCT-VC正式发布了新一代高效率视频编码标准。虽然HEVC仍采用预测、变换加熵编码的混合框架结构,但通过采用灵活的图像四叉树结构、条和片划分、多角度帧内预测、运动信息融合、高精度运动补偿、自适应环路滤波等技术,大大提高了视频的编码效率。与H.264/AVC相比,HEVC在相同视频质量的情况下可节省50%以上的编码比特流[1],但编码计算量增大了2~3倍。HEVC的高复杂度阻碍了其在视频领域的快速应用。如何在保证一定的视频质量的情况下,降低HEVC的计算量,是目前很多专家和学者研究的重点。
据统计,在HEVC框架中,帧间编码的计算量占整个编码的69%左右,因此,如果能有效降低帧间编码算法复杂度,就能加快编码端的处理速度。目前国内外很多学者对帧间预测模式决策算法展开了研究,提出了很多具有应用价值的帧间编码快速算法。如文献[2]利用当前CU与空间相邻CU深度的相关性及视频内容的运动一致性,跳过相邻CU很少使用的深度,提前终止当前CU划分过程。文献[3]根据视频图像运动的快慢,设置了两个不同的阈值用于判别运动程度,以提前终止CU划分过程。文献[4]根据当前帧与参考帧中对应块位置CU及其左侧CU深度信息预测当前CU深度范围,以缩小可能的CU深度遍历数,从而减少CU划分过程。文献[5]根据预测当前CU对应最有可能的PU模式个数来减少当前PU模式的选择。文献[6]依据当前块的纹理运动简单性,跳过一些Inter模式来加速编码过程;文献[7]通过设置率失真阈值来提前结束帧间PU模式选择;文献[8]通过运动特性来提前终止当前CU深度的选择,从而降低编码复杂度;文献[9]通过CU深度时空相关性来预测当前CU的范围,减少深度的遍历次数。文献[10]依据当前CU及对应PU的空时域相关性,通过减少CU深度和PU模式遍历个数来加速编码过程。
上述文献中的算法大多利用视频内容在空时域上的相关性减小CU深度遍历和PU模式决策过程来降低编码时间,但在视频的运动平坦区域所遍历的PU模式中,依然存在一定的PU模式冗余信息。比如文献[10],所采用的CU深度快速算法虽然在一定程度上提升了CU的遍历过程,但没有充分考虑编码区域运动及纹理的复杂性与所要遍历CU深度范围之间的对应关系,在PU模式快速决策过程中只考虑了帧间PU的相似性,没有考虑与其帧内相邻CU及其上一深度CU对应的PU的相关性。因此上述编码过程依然存在一定的信息冗余,仍有减小编码时间的可能性。本文利用视频运动快慢与帧间PU类型划分之间的相关性,提出了一种基于运动特性的帧间预测模式快速决策算法。首先根据当前CU与其相邻空时域CU深度的相关性,降低当前CU深度遍历次数。如果当前CU周围CU深度相同,利用平滑区域CU深度快速决策算法来缩小当前CU深度遍历范围;如果当前CU周围CU深度不同,则采用复杂区域CU深度快速决策算法来降低当前CU深度遍历范围。然后根据当前CU上一深度及其空时域相邻CU所对应的帧间PU模式特性与运动快慢的关系,对运动平坦区域提前终止一些PU模式的遍历过程,对运动中等区域及运动复杂区域跳过一些不必要PU模式遍历,从而减少帧间PU模式选择的个数以降低编码复杂度。
2 HEVC帧间模式加速决策算法
2.1 HEVC中CU和PU的特性
HEVC的每帧图像由多个片(Slice)构成,每个片又划分为多个深度为0的编码树单元(Coding Tree Unit,CTU),即大小为64×64的CU。一个CTU可继续划分为深度为1、2和3的CU,其对应的CU尺寸大小分别为32×32、16×16和8×8。与H.264/AVC中16×16固定尺寸编码块相比,HEVC中的CTU四叉树划分结构具有更灵活的尺寸类型,使得帧内和帧间编码更具有多样性,从而提高视频的压缩效率。
图1和图2分别是CTU的划分及四叉树结构,每个CU是否继续划分由图2的四叉树结构来决定。图1的每个CU可以继续划分为如图3所示的2个或4个PU。PU模式包括合并模式(Merge Mode)、跳过模式(Skip Mode)、帧间模式(Inter Mode)和帧内模式(Intra Mode)四种类型。帧内预测模式都是对称模式,有2N×2N和N×N两种,只有在最小尺寸为8×8大小的CU时,才可以继续划分成4个4×4的预测块,其他情况下,CU和PU的尺寸大小相同。
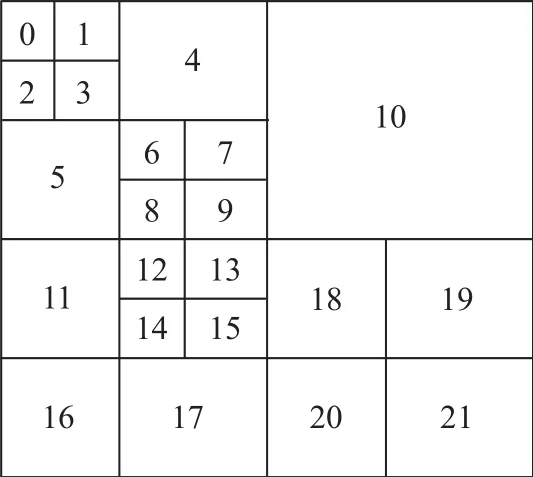
图1 CTU的划分
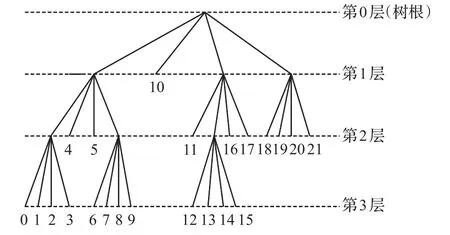
图2 编码四叉树结构示意图
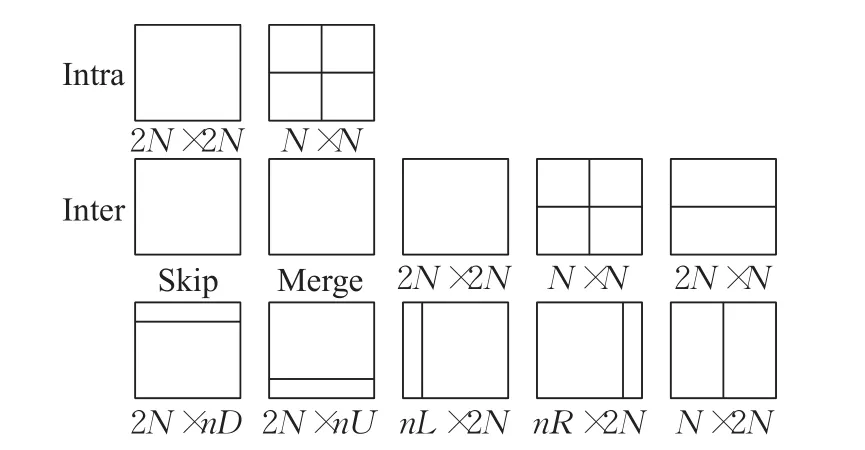
图3 HEVC的帧间PU划分模式
帧间预测模式有6种对称模式和4种非对称模式,包 括 Skip、Merge、Inter 2N×2N、Inter 2N×N、Inter N×2N、Inter N×N、Inter 2N×nU、Inter 2N×nD、Inter nL×2N和Inter nR×2N共10种。后4种是非对称模式,即非对称运动划分(Asymmetric Motion Partitioning,AMP)。非对称模式在HM中是可选模式,只有当CU的尺寸大于8×8时才可以使用。非对称模式把CU面积按1∶3进行划分以提高帧间预测的准确性,进而提高压缩效率。当CU尺寸为8×8时,禁止使用Inter N×N和4种帧间AMP模式,以降低帧间预测中的编码运算量。Merge模式是HEVC新引进的帧间预测模式,采用“运动合并”技术处理运动参数,无需传送MV信息,只传候选PU块的索引值,由解码端采用运动推理方法来获得运动信息[11]。Skip模式是Merge模式编码块标志(Coded Block Flag,CBF)为0的一种特殊情况,即残差为0。HEVC的测试模型(HEVC Test Model,HM)采用全搜索遍历方式,首先在CU层遍历所有的深度,然后在每次递归过程计算出相应候选PU的率失真值的大小,选择最小率失真对应的PU作为最佳PU。这种方法能得到高质量的视频,节省编码比特率,但大大增加了编码的运算量。
由于当前CU与空时域相邻CU深度之间存在着一定的相关性,这些CU对应的PU模式在空间划分上也具有一定的相似性。本文将利用当前CU的运动特性来减少不必要的CU深度遍历,实现CU深度范围的快速决策,降低HEVC帧间预测的运算量。为了分析CU最终划分的深度信息与视频序列的运动、纹理之间的关系,本文在HM16.9平台上对表1所示的5种具有不同运动特征的标准测试视频序列进行编码,统计出了不同类型视频序列的CU深度特性。在编码测试中,量化参数(Quantity Parameter,QP)设置为 32,采用随机接入(Random Access,RA)配置,对每个测试序列编码60帧。

表1 5种测试序列的不同CU深度比例分布
表2是5种测试序列深度值的分布比例,S4序列有25.4%的CU深度值等于0,S2序列有98.8%的CU深度值大于0,而S2和S3序列均有近一半的CU深度值为3。这表明运动平坦,纹理简单的序列深度值小的比例较高,相反,运动剧烈,纹理复杂的序列深度值大的比例较高;由序列S0、S1及S4的CU深度分布可知,CU深度值比例分布取决于序列的运动快慢程度与纹理特性。鉴于序列CU深度与序列运动和纹理特征的关系,若在CU深度划分前能提前预测出CU深度范围,跳过一些CU深度值所占比例低的遍历过程,则可加快编码速度。
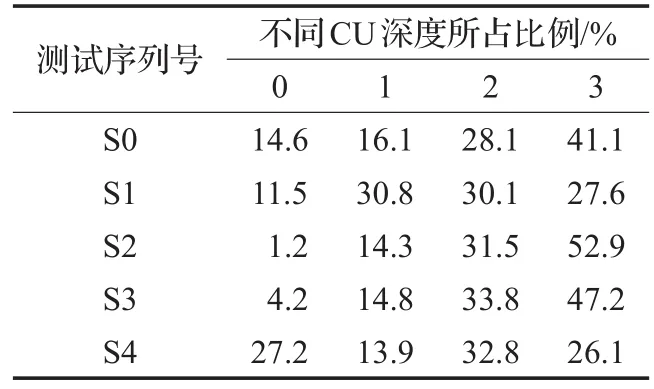
表2 5种测试序列的不同CU深度比例分布
2.2 CU深度加速预测
文献[12]根据当前CU深度值大小与其相邻时空域CU的关联性,定义了如式(1)所示的当前CU(下面称为CUcurrent)的预测候选集合S。
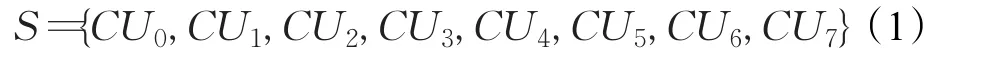
图4中的 CU0、CU1、CU2和 CU3分别表示 CUcurrent空域相邻的左侧、左上侧、上侧和右上侧的编码单元,CU4和CU5分别是前后参考帧中与CUcurrent对应位置的编码单元,CU6和CU7分别是CUcurrent的上一级和上二级对应的编码单元。

图4 CU current的空时域相邻CU及上级深度CU
2.2.1 复杂区域的CU深度范围快速预测
本文将空时域相邻候选CU深度值不同的区域称为复杂区域,利用CUcurrent周围相邻CU的深度值,通过式(2)和式(3)预测出CUcurrent的深度值。
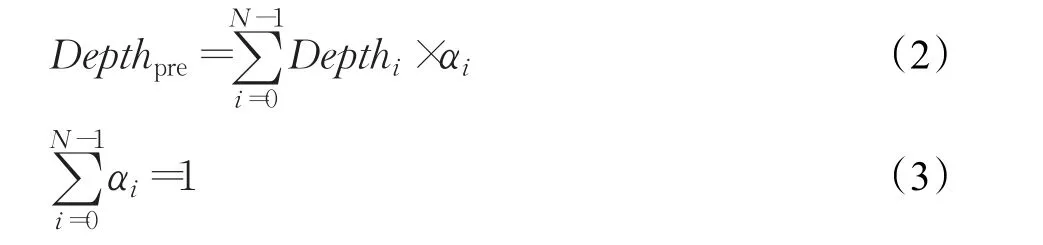
其中,Depthpre为CUcurrent的加权预测深度值;i表示候选CU对应下标号;N是候选CU的个数,该算法下N取6;Depthi为第i个候选CU的深度值;αi表示第i个候选CU深度值的权重。通过对大量的测试序列进行编码,统计出CUcurrent与其时空域相邻CU和上级深度CU之间的相关性,得到如表3所示的CU之间的相关系数。依据表3中的数据给予空时域和上级CU分配相关的权重系数如表4所示。
为了加快对CUcurrent的深度遍历过程,本文采用CU深度范围(Depth Range,DR)来表示CUcurrent需要遍历的深度区间。当得到CUcurrent的深度预测值Depthpre后,对Depthpre分别加减0.5,然后取整作为CUcurrent深度预测范围的最大值与最小值。

表3 当前CU与候选CU之间的相关系数

表4 候选CU与其对应权重值大小
2.2.2 平滑区域的CU深度快速决策
本文将空时域相邻候选CU深度值相同的区域称为平滑区域。对于平滑区域,从预测候选集S中选取空域相邻编码块CU0和CU2的深度值,以及时域相邻对应块CU4和CU5的深度值来预测CUcurrent的深度范围。具体实现过程如下:
(1)如果4个候选CU的深度值都为0,表明前后两帧CU附近区域相对静止,CUcurrent提前终止划分,CUcurrent深度值为0;
(2)如果4个候选CU的深度值都为1,则CUcurrent深度预测范围DR为[0,2];
(3)如果4个候选CU的深度值都为2,则CUcurrent深度预测范围DR为[1,3];
(4)如果4个候选CU的深度值都为3,则CUcurrent深度预测范围DR为[2,3]。
2.2.3 CU深度加速预测算法流程
CU深度加速预测算法流程如图5所示。首先,从预测候选集S中选取C Ucurrent的时空域相邻编码块CU0、CU2、CU4和 CU5,选出这4个编码块深度值的最大值和最小值,分别记为Dmax和Dmin;然后判断Dmax与Dmin是否相等,如果相等,按平滑区域对CUcurrent深度范围DR进行快速预测,否则按复杂区域预测CUcurrent深度范围DR。预测时,式(2)和式(3)中的N取6,即选取CUcurrent的时空域相邻编码块CU0、CU1、CU2、CU3、CU4和CU5的深度值来预测其深度范围DR;最后,遍历DR,确定CUcurrent的深度值。
这种采用先确定CUcurrent的深度范围DR,然后在DR中进行遍历,最后确定CUcurrent的深度的方法将大大减少帧间编码的时间。
2.3 帧间PU模式加速预测
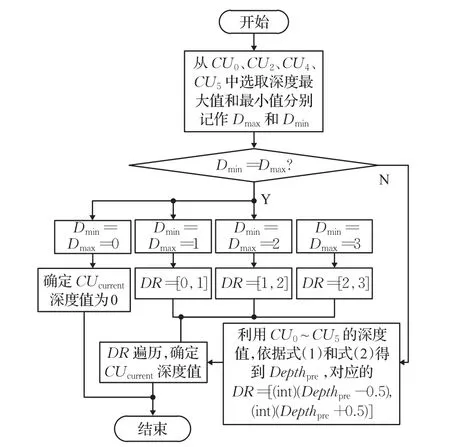
图5 CU深度范围预测流程
当前CU与空时域相邻CU所遍历的PU模式在空间划分上也具有类似的相关性。由于每个CU对应的PU模式有11种,如果能减小当前CU对应PU模式遍历的范围,就能加速帧间模式的选择过程,从而降低帧间编码过程的运算量。由于CUcurrent与CU6在空间划分上有被包含关系,与空域相邻CU0、CU1、CU2和CU3有纹理相似性关系,与时域相邻CU4具有运动一致性关系。因此,当CU4与CUcurrent深度相同或者CU6比CUcurrent深度值小1时,就可以利用CU4或CU6对应的PU模式作为当前PU模式的遍历范围。为了表述方便,本文对于PU划分的9个帧间预测模式和2个帧内预测模式,采用表5所示的对应编号来表示。图6是本文帧间PU模式快速预测算法流程,根据视频编码区域运动的剧烈程度,CUcurrent的PU遍历模式过程如下:
(1)判断 CUcurrent相邻的 CU0、CU2及上一级 CU6中的对应PU模式是否存在m0;若存在,可判断CUcurrent所处的区域是静止或是处于同向极其缓慢的运动状态,且视频纹理极其简单,此时,CUcurrent所需遍历的PU模式为m0和m1;否则,按下面步骤执行。
(2)如果CUcurrent和CU4深度值相同,表明此时的前后参考帧对应CU块具有运动一致性,依次如下处理:
①当CU4对应的PU模式是m1,那么对应CU块所处的区域是均匀运动,且视频纹理简单。此时,CUcurrent所需遍历的PU模式为m0和m1。
②当CU4对应的PU模式是m2,那么对应CU块所处的运动区域应是中等运动,且视频纹理较平缓。此时,CUcurrent所需遍历的PU模式为 m1、m2、m3、m4和 m5。

表5 PU划分模式及对应编号
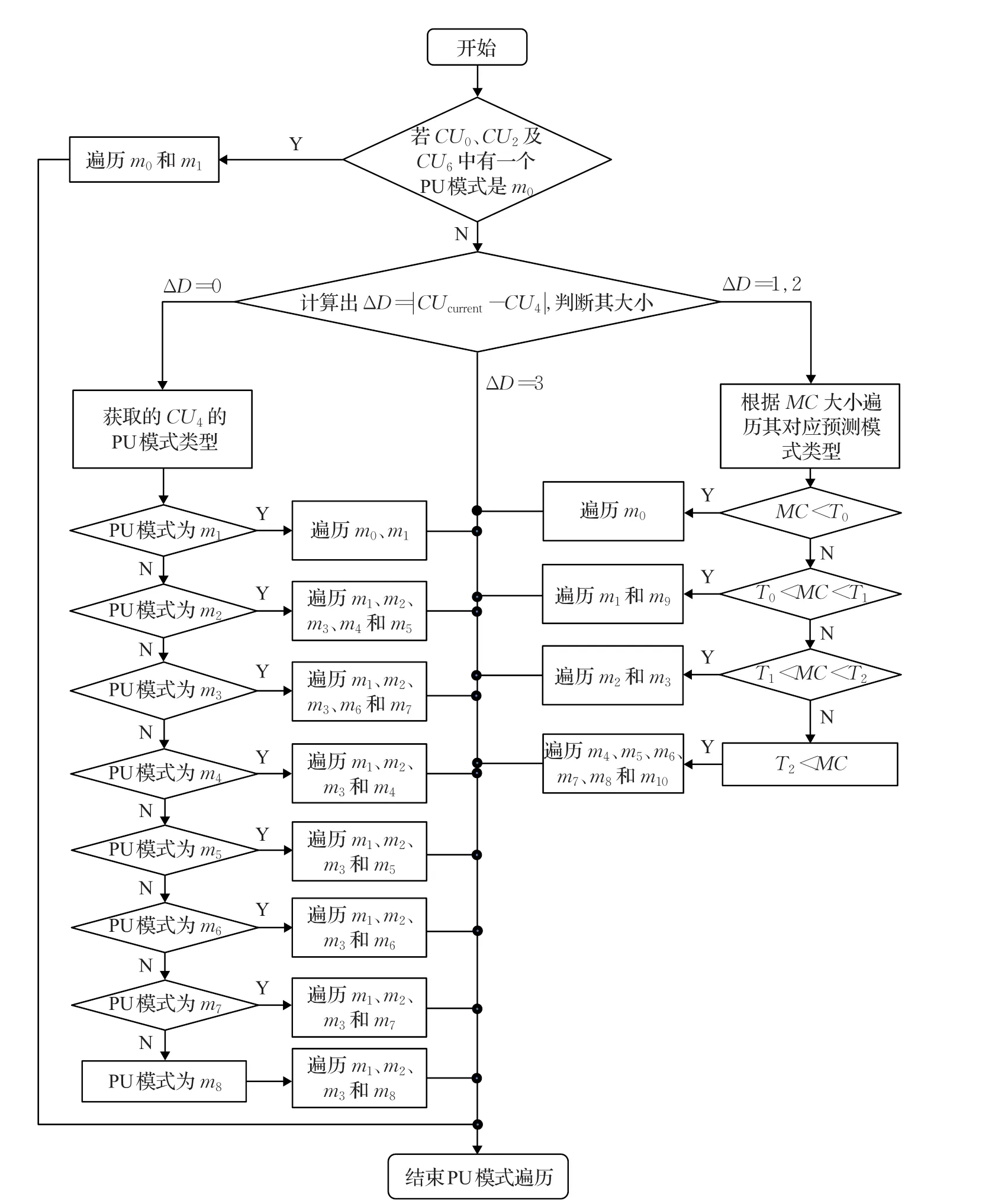
图6 PU预测算法流程图
③当CU4对应的PU模式是m3,那么对应CU块所处的运动区域是中等运动,且视频纹理较平缓。此时,CUcurrent所需遍历的PU模式为 m1、m2、m3、m6和m7。
④当CU4对应的PU模式是m4,那么对应CU块所处的运动区域是剧烈快速运动,且视频纹理较复杂。此时,CUcurrent所需遍历的PU模式为 m1、m2、m3和 m4。
⑤当CU4对应的PU模式是m5,那么对应CU块所处的运动区域是剧烈快速运动,且视频纹理较复杂。此时,CUcurrent所需遍历的PU模式为 m1、m2、m3和 m5。
⑥当CU4对应的PU模式是m6,那么对应CU块所处的运动区域是剧烈快速运动,且视频纹理较复杂。此时,CUcurrent所需遍历的PU模式为 m1、m2、m3和 m6。
⑦当CU4对应的PU模式是m7,那么对应CU块所处的运动区域是剧烈快速运动,且视频纹理较复杂。此时,CUcurrent所需遍历的PU模式为 m1、m2、m3和 m7。
⑧当CU4对应的PU模式是m8,那么对应CU块所处的运动区域是剧烈快速运动,且视频纹理较复杂。此时,CUcurrent所需遍历的PU模式为 m1、m2、m3和 m8。
(3)如果CUcurrent和CU4深度值不等且两者之差ΔD等于1或2,说明CUcurrent与时域相邻CU对应的PU模式划分存在差别,通常运动越剧烈纹理越复杂的区域PU划分得越细小。为了准确地预测CUcurrent对应PU模式类型范围,本文用模式复杂度(Mode Complexity,MC)来描述PU模式的复杂类型,MC的计算公式如式(4)所示,MC越大表明运动复杂度越高。式(4)中的N是预测候选集合S中候选CU的数量,这里N的取值为8;ki用来判断候选CU是否可用,ki取1表示候选CU可用,ki取0表示候选CU信息不可用;ωi为不同预测类型对应的权重值大小;αi为表4中第i个候选CU深度值的权重的大小。

依据所选用的PU结构划分关系,将表5中的11种不同预测模式按复杂程度合并为4种预测类型,然后分别赋予权重值ωi为0.5、1.0、1.5和3.0,每种预测类型及其包含的PU模式如表6所示。本文依据运动剧烈程度将运动区域分为4种复杂度区间,分别用集合S、T、U和V来表示。每种运动类型之间的临界阀值分别用T0、T1和T2来表示,依据对测试序列进行编码得到的经验值,可分别设为0.8、2.0和4.0。复杂度区间所对应的遍历模式类型如表7所示。
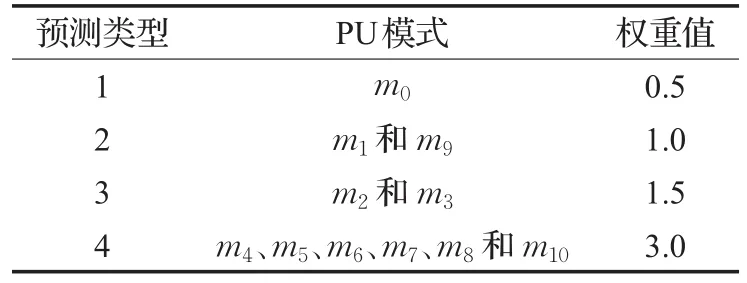
表6 不同模式类型对应的权重值
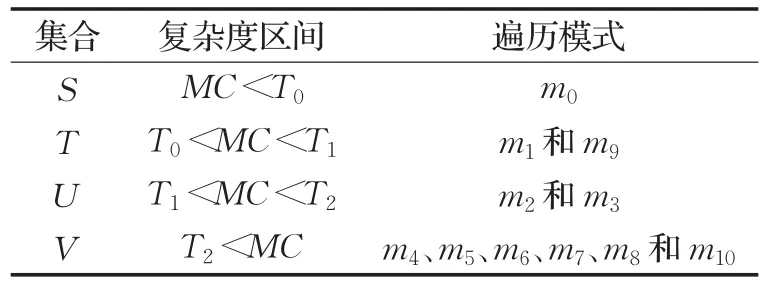
表7 4种运动类型及其对应的区间
(4)如果CUcurrent深度与CU4的深度值之差为3,说明其对应的PU空间划分差别也非常大,CUcurrent的PU模式不采用CU4的PU模式,结束CUcurrent的PU模式划分,转入下一深度CU对应的PU模式判断。
2.4 帧间预测模式加速决策算法
本文基于时空域相邻CU的运动特性,从CU深度划分和PU模式选择两方面来加速帧间的预测过程。
首先,预测出当前CU的深度。依据CUcurrent空时域相邻候选CU深度值是否相同,将编码区域分为复杂区域和平滑区域两种类型,针对不同的区域类型按图5所示的流程,选择不同的预测算法来加速CU深度的决策过程。
然后,判断CUcurrent的PU模式。依据CUcurrent深度与空时域相邻CU及上一深度CU对应的PU模式在空间划分上的相似性来减少CUcurrent的对应PU模式的遍历范围,加速PU模式的选择。PU模式的快速选择流程如图6所示。
3 实验结果及分析
本文算法在HM16.9上进行了实现,编码端的基本参数如下:最大CU尺寸为64;最大划分深度为3;量化步长QP分别取22、27、32和37;选取测试序列分为A、B、C、D、E共5种类型,共18组标准测试序列作为编码对象,这5种类型测试序列的分辨率分别为2 560×1 600、1 920×1 080、832×480、416×240和1 280×720,且每个测试序列的输入比特深度为8;其他配置参数及测试条件参考了HM提案JCTVC-J1100[13]。根据文献[13],采用RA接入方式的编码器测试A、B、C和D类4种测试序列;采用低延时(Low Delay,LD)接入方式的编码器测试B、C、D和E测试序列;测试所用的硬件平台为泰克公司的图像质量分析仪PQA600A,其配置为12核CPU,2.30 GHz主频,32 GB内存,64位Windows7操作系统。
为了测试编码率失真性能在4个QP下的变化,采用BDBR(Bjntegaard Detla Bit Rate)和BDPSNR(Bjntegaard Detla Peak Signal to Noise Ratio)[14]作为测试指标。使用式(5)计算得到的PSNR来评价图像编码的质量[15]。
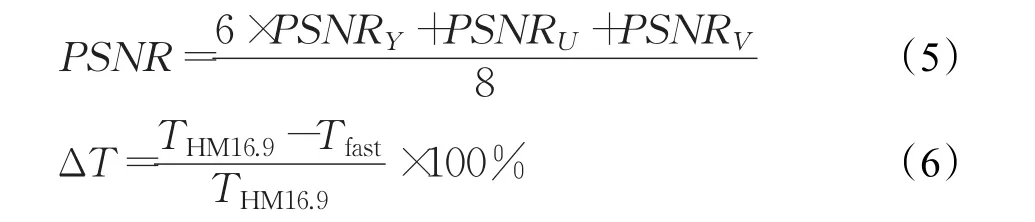
式(5)中,PSNRV和PSNRU表示色度峰值信噪比,PSNRY表示亮度峰值信噪比。利用式(6)计算得到的编码时间变化率来评估算法的加速性能。式(6)中的THM16.9和Tfast分别为HM16.9和采用本文算法的编码器对测试序列编码所需的时间。
表8和表9分别为本文提出的CU深度加速预测算法和PU模式加速预测算法在RA、LD两种接入方式下的性能测试结果。对比HM16.9算法,在RA编码方式中,平均输出比特率在分别增加了1.43%和2.16%的情况下,平均编码时间分别减小了28.58%和48.97%,而视频的平均PSN R都只降低了0.06 dB;在LD编码方式中,平均输出比特率分别增加1.64%和1.68%的情况下,平均编码时间分别减小了25.53%和46.86%,视频的平均PSN R损失均不高于0.05 dB。测试数据表明,本文算法在RA和LD两种不同接入方式下都能有效地降低CU深度划分的复杂度,减少PU模式的遍历范围,加速了帧间编码过程。
为了评估本文帧间模式快速算法的整体性能,在HM16.9平台上,对文献[10]中的算法进行了实现,并分别对本文算法和文献[10]算法进行了性能测试,测试结果如表10和表11所示。在RA编码方式下,本文算法和文献[10]算法相对HM16.9,平均编码时间分别降低了53.93%和48.48%,采用本文算法的平均编码输出比特率增加了2.92%,略高于文献[10]的2.36%,而编码后视频失真度基本一致,平均PSNR均下降了0.09 dB。本文算法针对高分辨率的A类和B类视频序列,相对于HM16.9,平均编码时间降低了58.36%,而对于中低分辨率的C类和D类视频序列,平均编码时间降低了50.05%,说明本文算法针对高清视频序列有更好的编码加速性能。在LD编码方式下,本文算法和文献[10]算法相对HM16.9,平均编码时间分别降低了56.64%和49.96%,采用本文算法的平均编码输出比特率增加了2.98%,同样略高于文献[10]的2.08%,且编码后视频失真程度更小,平均P SNR减小均不超过0.07 dB。
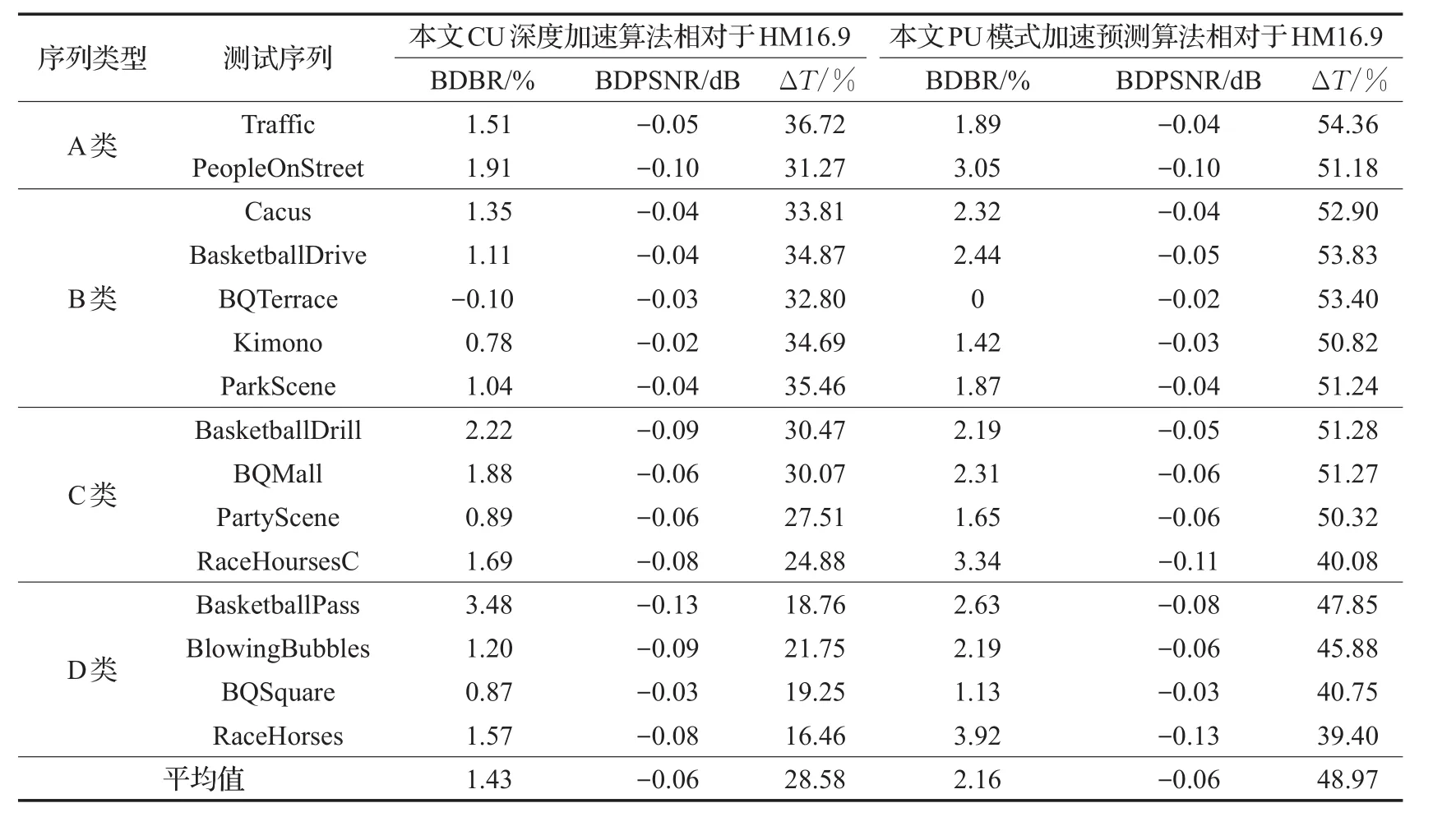
表8 CU深度加速预测算法和PU模式加速预测算法在RA配置下性能比较
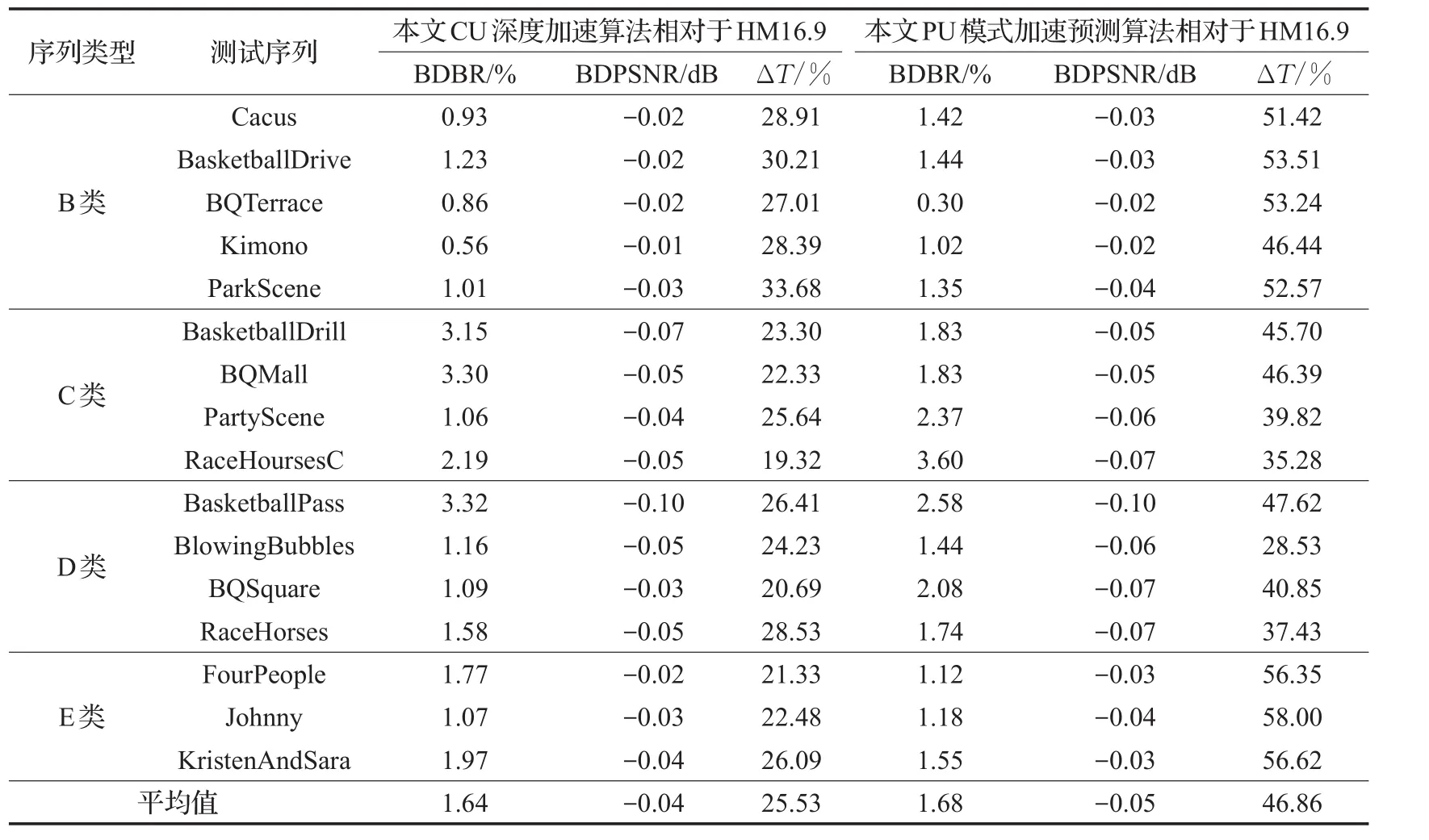
表9 CU深度加速预测算法和PU模式加速预测算法在LD配置下性能比较
对运动剧烈的测试序列,如BasketballDrive、BasketballDrill、RaceHoursesC、BasketballPass和RaceHorses,在RA编码方式下本文算法平均编码时间降低了52.14%,文献[10]算法降低了45.89%;而在LD编码模式下本文算法平均编码时间降低了56.15%,文献[10]算法降低了46.03%。说明相对文献[10]算法,本文算法在两种编码方式下均能有效降低运动剧烈视频序列的编码运算量,并且本文算法在LD编码方式下效果更显著。
4 结束语
为了有效降低HEVC的编码时间,本文通过对CU深度划分和PU模式选择过程的分析,提出了一种基于运动特性的帧间预测模式快速算法。首先,依据视频运动及纹理特性,采用时空域相邻CU来预测当前CU深度范围,加速编码单元的划分过程;然后,利用CU的PU在深度上下级和相邻时空域上的相似性,减少PU类型的遍历过程。实验仿真结果表明,本文提出的改进算法在视频质量基本没有损失,输出比特率增加较小的前提下,大幅度降低了平均编码时间。
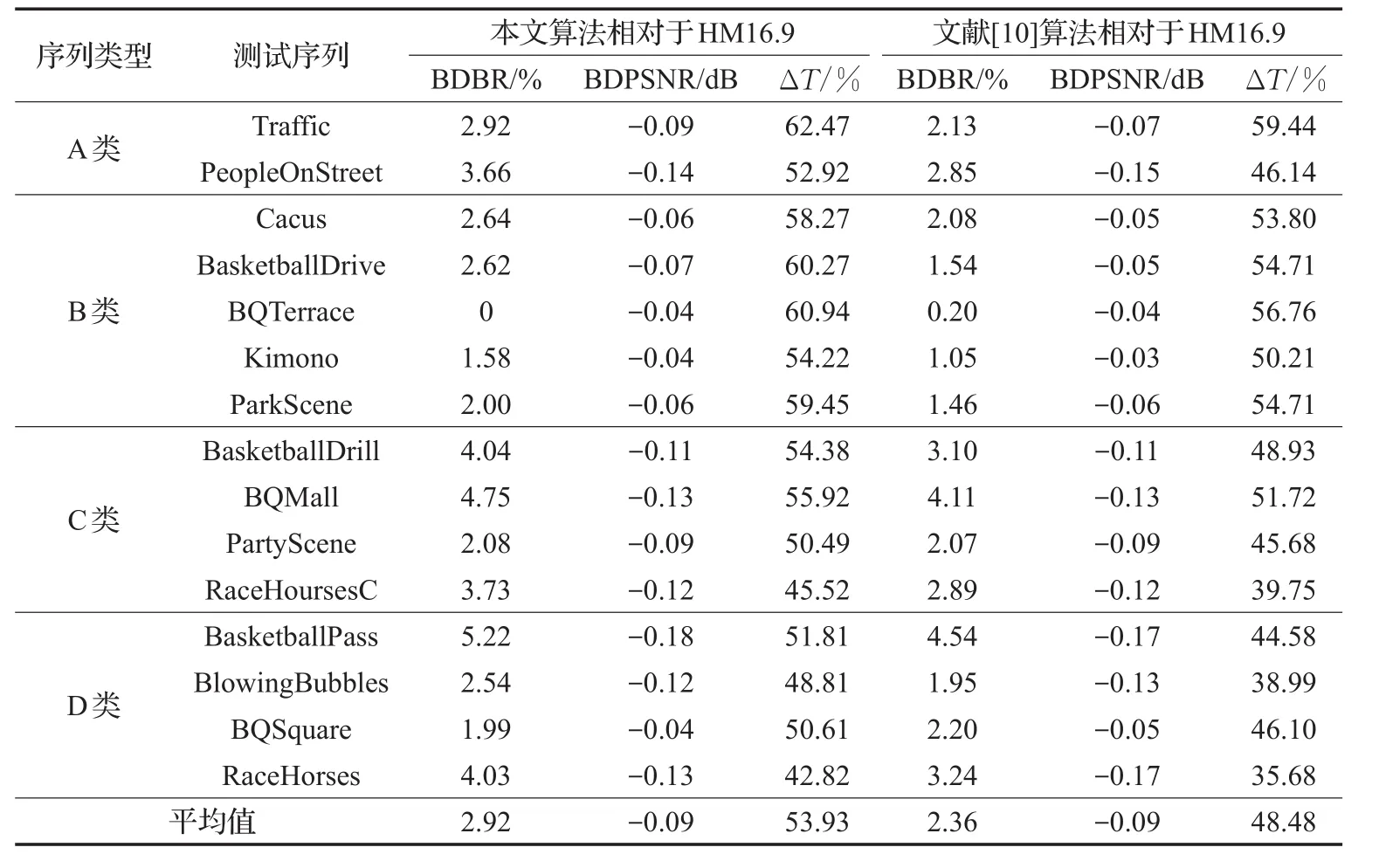
表10 本文算法与文献[10]算法在RA配置下性能比较

表11 本文算法与文献[10]算法在LD配置下性能比较
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09 06:12:12
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
汉字汉语研究(2020年2期)2020-08-13 07:52:48
电子制作(2019年22期)2020-01-14 03:16:24
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
疯狂英语·新读写(2018年3期)2018-11-29 22:37:11
