
基于相容性分析的医疗诊断专家系统
2018-12-04 02:14:46季长清李媛媛唐晓君
计算机工程与应用 2018年23期
肖 鹏,刘 娜,季长清,李媛媛,路 莹,唐晓君
1.大连工业大学 信息科学与工程学院,辽宁 大连 116034
2.大连大学 物理科学与技术学院,辽宁 大连 116622
3.大连交通大学 软件学院,辽宁 大连 116052
1 引言
医疗专家系统[1]是专家系统研究的一个重要方向,其目标是通过具有大量专门知识的计算机程序来模拟医学专家的分析过程,以解决医疗诊断中的各种复杂问题。因此,作为人工智能应用的一个重要分支,医疗诊断专家系统比医学专家拥有更多的专业知识和更快的解答问题能力,已经在医疗诊断领域发挥着良好的辅助作用。
如图1所示,一个典型的医疗诊断专家系统[2]主要由以下6部分组成:病例数据库、医学知识库、知识获取、推理模型、解释机制和用户GUI。其中,病例数据库,医学知识库是医疗诊断专家系统数据的来源和基础;用户GUI和解释机制属于人机交互部分;知识获取的有效性及其数据处理决定了推理过程要用到的数据正确性;推理模型实现知识推导求解进而得出诊断结论,其好坏直接决定了最后结论的正确与否。因此,知识获取和推理模型是医疗诊断专家系统的核心部分,采用什么样的数据处理方式和知识推理模型是医疗诊断专家系统研究的重要内容。
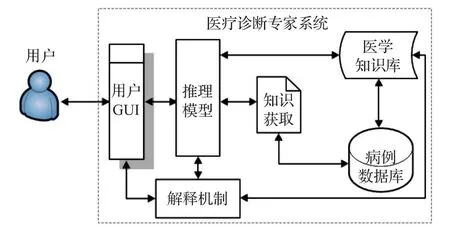
图1 医疗诊断专家系统组成
近年来,医学诊断专家系统的研究[3-19]得到了广泛关注,其关键技术在医学临床上也得到了深入的应用。随着医学诊断专家系统的不断发展,其推理模型也成为医学专家系统研究的一个热点和关键点,并有了一些相关的研究。医学诊断专家系统的推理模型主要有处方产生式推理模型[3-7]、模糊推理模型[8-13]和机器学习推理模型[14-19]等。大部分推理模型都依赖于权值设定,而权值设定又完全依赖于医生的经验值。因此,权值给定质量直接影响了诊断结果,有待进一步研究和改进,以期找到更实用的权值设定和自动赋值方法。
本文研究了大量医学病例数据的自身相容性问题,这些数据在某些属性上具有相容性,即病例的相似性和关联性。例如,在肺炎病人众多的表现症状中,发烧是常见的表现症状,是其重要属性;同时发烧和咳嗽又具有一定的关联性。如何利用数据相容性分析来建立属性权值自动设定模型,以增加医学诊断的准确度,是推理模型研究的一个新方向。另一方面,在实际应用中医学专家系统会对所有属性进行分析,这大大增加了计算量和分析问题的复杂性。如何对属性进行有效的降维也有待进一步研究。
本文针对医学病例数据的特点及相容性分析进行了研究,提出了一种基于属性相容性分析的医疗诊断方法。此方法先利用属性相容性分析对医疗数据进行数字化处理,根据属性之间的关联度构造属性相关矩阵;接着利用属性相关矩阵对属性进行剪枝处理,以减少无效属性的计算;基于相容性分析构造较为实用的权值设定数学模型;最后在进行病例相似度计算时采用群体决策策略来完成最终诊断。
2 相关工作
医学诊断推理模型是从大量病理知识和病例中推导求解进而得出最后诊断结果。对于医学诊断推理模型人们做了大量的研究工作,早期的工作主要集中在简单的产生式系统推理模型中。陈漫红[3]等人将产生式系统推理引入到青光眼诊断专家系统中,其推理机制的核心是采用深度优先语义遍历和正向启发式推理策略。产生式系统推理模型简单明了,但无法诊断症状复杂且与其他疾病存在共同症状的疾病,其应用有限并且缺乏有效筛选机制。
针对多种疾病可能性的症状难诊断这一难题,很多研究人员将概率理论引入到诊断推理过程中。于佳[4]等人将统计分析应用到甲状腺超声诊断中。文献[5-7]试图利用贝叶斯定理推算出引发症状的症病置信度,当置信度达到某一概率时,诊断规则才会被触发,减少了不确定性误诊的可能性。但在现实生活中这些概率数据收集困难,其往往是通过大量数据统计得到,或是由权威专家给出。这些统计数据自身的可靠性和代表性直接决定了推理结论的正确与否。
模糊逻辑能模拟人脑方式进行模糊综合判断,推理解决常规方法难以应付的规则型模糊信息问题。因此,模糊推理模型自提出以来就成为诊断专家系统的经典模型,后续很多学者在模糊逻辑基础之上进行了相关模型的研究[8-13]。研究者普遍采用模糊集规则来进行医疗诊断系统的设计,然而模糊诊断知识获取困难,自我学习能力差,容易发生误诊。另外,加权模糊规则的设置还有赖于医生的经验。这些都影响了基于模糊逻辑的医疗诊断专家系统的实际应用。
目前机器学习推理在医疗专家系统中的研究已成为热点。机器学习推理能摆脱主观因素和不确定性带来的干扰,直接进行确定性推理,被广泛地应用在各种专家系统中。陈蔼祥[14]等人提出了一个ADST系统,利用支持向量机、决策分类树和朴素贝叶斯三种不同的方法进行结节病和肺结核的诊断。郑明杰[15]等人关注机器学习方法在肺音分类中的应用。随着机器学习和人工智能算法的不断发展,越来越多的复杂算法[16-19]被引入到医疗诊断专家系统研究中来。Inbarani[16]等人提出了粒子群算法和粗糙集相结合的医疗诊断方法。冯娇娇[17]等人将人工神经网络模型应用到慢性肾病诊断中。文献[18]将数据挖掘应用到医疗专家系统中,借助数据挖掘技术提取医院数据,加快了医疗数据的利用。文献[19]将TF-IDF权重改进算法应用到智能导医系统中,依据患者症状进行两类TF-IDF权重计算得到可能疾病,以引导患者准确挂号。
机器学习大大加快了医疗诊断专家系统学习获取知识的过程和效率,提高了系统的智能化和准确化。然而,机器学习也存在着局限性和不足:机器学习推理模型过分依赖于以往的诊断数据,学习效果和实用性有限,如不同症状属性对诊断结果的影响不同,其权值的设定原则也受诊断数据影响;机器学习训练对所需的病例样本在数量上和代表性上有较高要求,系统设计人员很难用一个有效固定标准来衡量。与上述工作不同,本文考虑的是基于相容性分析的机器学习方法。针对现有诊断推理模型在病例推理过程中过于依赖权值设定和医生经验值的问题,本文提出了一种基于属性相容性分析的医疗诊断方法,以解决属性冗余和权值赋值的难题。
3 相容性分析
医学病例库一般由大量属性组成,这些属性大部分为文本型数据,不利于数据的分析处理。对这些属性进行数字化处理之后,需要对所有属性进行降维简约化处理以减少计算量和分析复杂性。相容性分析作为一种有效的特征属性提取方法,被普遍应用于网络流量分析[20]、图像处理[21]等领域。本文所提的医疗诊断专家系统首先对病例库的文本属性进行数字化处理,然后利用相容性分析进行剪枝并提取有效属性和设定权值,最后根据相似度计算结果和群体决策理论进行辅助诊断。
现在假设有病例数据库集合L={L1,L2,…,Ln,…,LN},集合中每一个病例记录由多个属性和疾病结果组成,即某病例记录Ln由向量<f1,f2,…,fm,…,fM,r>构成。其中 f1,f2,…,fm,…,fM为病例的M个属性特征,r为所患疾病结果。其数据形式未处理前如表1所示。
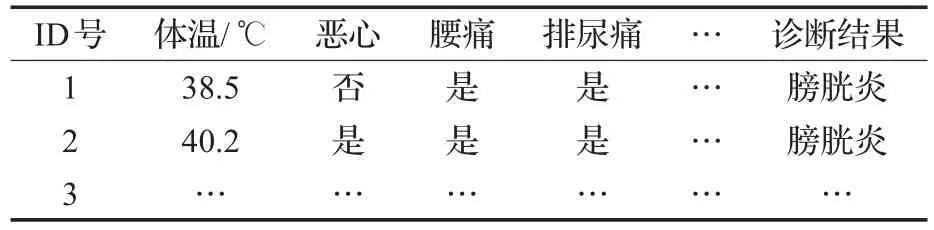
表1 某医学病例数据库样例
现有待诊断病例集合Q={q1,q2,…,qk,…,qK},对于任意一个q,存在着相似度向量<d1(q,l),d2(q,l),…,dm(q,l),…,dM(q,l)>,其中 q∈Q,l∈L ,dm(q,l)代表着待诊断病例q和病例记录l在第m个属性特征上的距离。基于dm(q,l)公式,可以计算集合Q和L之间所有dm距离,以方便进行相容性分析计算。
对每一个病例重复这个过程,可以得到一个M×M的协方差矩阵A,其第i行和第 j列的协方差Aij如公式(1)所示:
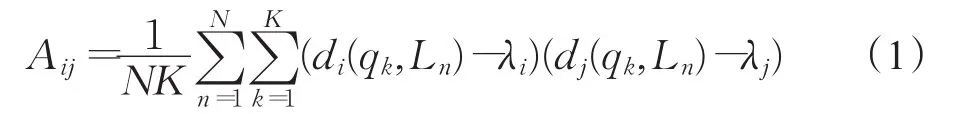
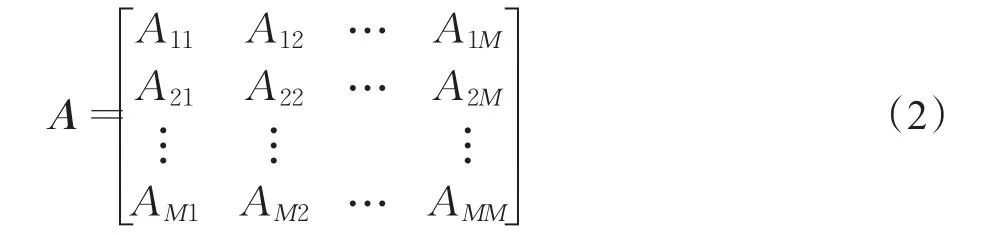
于是,协方差矩阵A如下所示:
计算出协方差矩阵A,下面就可利用相容性分析的方法进一步分析。相容性分析是针对数据各属性成员之间的相关性进行分析,并构造属性相关矩阵。针对已有 M 个属性特征 f1,f2,…,fm,…,fM,利用公式(3)来构造属性相关矩阵。

其中Rij表示第i个属性 fi和第 j个属性 fj之间的相关性,其值越大,相关性越大。
于是,得到了属性相关矩阵如下:
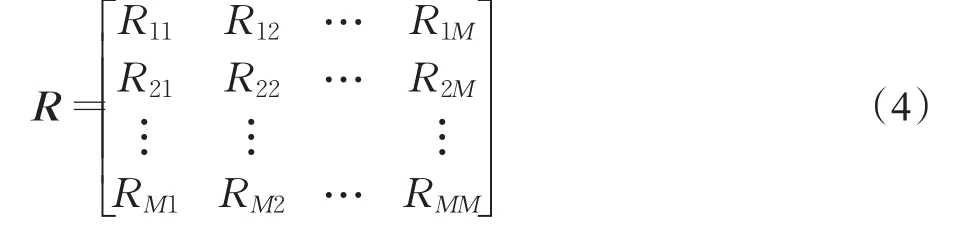
利用属性相关矩阵,可以从众多属性特征中提取相关性较大的属性进行后续的计算处理,并对相关性较小的属性进行剪枝处理。相容性分析能有效地减少病症的冗余属性,达到了降维和减少计算的作用。
4 基于相容性分析的医疗诊断算法
本文针对医疗病例数据提出的医疗诊断推理模型如图2所示。
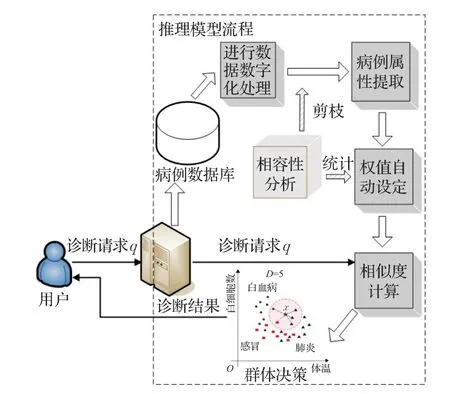
图2 推理模型流程图
系统主要由数据数字化处理、病例属性提取、权值设定、相似度计算和群体决策等几个步骤组成。相容性分析是整个推理模型的基础,其强大分析能力能很好地解决属性剪枝和权值自动设定的处理要求。
首先,病例数据由临床产生,形成的大规模病例数据库可用于分析计算。在针对病例数据库自身特点进行数据数字化处理之后,利用相容性分析方法计算出病症属性的相容性,并进行重要属性特征的提取,减少了无效属性的计算,实现了数据的剪枝处理。针对各属性特征的重要性不同,利用相容性进行权值的自动设定计算。系统在接收到用户的诊断请求即查询点q之后,计算其与病例数据库中所有样本的加权相似度。最后根据相似度计算结果进行群体决策,并将最终诊断结果返回给用户。
接下来本文将重点介绍此流程中的重要数学模型及关键处理技术。
4.1 权值设定模型
考虑到属性的值对结果影响不同,传统的基于权重的数字化方法常根据属性贡献大小来赋值。贡献大的属性在数字化时赋一个较大的值,贡献小的就赋一个较小的值,而不是把是非逻辑的文本属性值简单地设定为1或0。但是属性的数字化赋值往往由人为经验得出,不可避免受医学专家主观意识的影响。为了使权值客观地反映出属性对诊断结果的影响,本文通过对病例数据库进行相容性分析,自动学习得到各属性权值。在数字化过程中,对于是非逻辑的文本型属性值可设定为1或0,通过机器学习,根据不同属性的重要性来自动获取其权值,客观地反映了临床病例数据经验,排除人为因素干扰。
现有病例数据库集合L={L1,L2,…,Ln,…,LN},其中任一个病例记录Ln由向量<f1,f2,…,fm,…,fM,r>组成,f1,f2,…,fm,…,fM为病例的M个属性特征,r为所患疾病结果。
通过数据相容性分析可得到各属性对结果影响程度的百分比统计信息,其集合形式为S={s1,s2,…,sn,…,sM}。假设存在着权重影响因子集合 α={α1,α2,…,αn,…,αM},其值由公式(5)决定。

根据权重影响因子集合α,可以计算得到权重集合W={ω1,ω2,…,ωn,…,ωM},其计算公式如下:

其中,i的取值范围为i=1,2,…,M。
权值自动设定模型从病例数据库中学习得到权值。由概率统计理论可知,如果属性 fi为真使得某疾病结果r被诊断的频率高,那么属性 fi对诊断结果为r是重要的,其权重ωi就高,反之亦然。本文的权值设定模型通过机器学习自动得到权重集合,减少了人为设定权值所带来的干扰和误差。有了权重集合,就可以根据学习来的权重大小,在编码过程中自动赋予相应数值,实现查询病例与病例数据库样本之间相似度计算。
4.2 相似度计算
本文通过基于权值的疾病相似度计算来进一步确定疾病的可能性。所用到的部分符号定义如前文所示。对于任意待诊断病例q,其与任一病例数据样本l之间的相似度计算如下:

其中q∈Q,l∈L,di(q,l)代表着待诊断病例q和病例记录l在第i个属性特征上的距离。
在相似度计算中,将病例的不同病症属性基于样本库的统计分析进行差别化对待,使其不受量纲的影响,自动化设定权值,满足了实际应用需求。
4.3 群体决策策略
临床诊断的正确性和医学不确定因素有直接关系,不确定信息来源于知识库中的不确定性、病人数据中的不确定性和推理中的不确定性等。例如,很多疾病具有极其相似的病症属性,给推理过程带来很大不确定性。尤其在基于最大相似度的判断方法中,单个病例的不确定因素对医学决策过程影响更大。为了解决这一问题,提出了诊断过程群体决策概念,如图3所示。以二维空间为例,三种疾病数据样本和待诊断病例x被映射到体温和白细胞数两属性的二维坐标系中。为减少单一的最大相似度计算带来的误差和不确定性诊断,以群体决策投票来决定最终诊断结果。
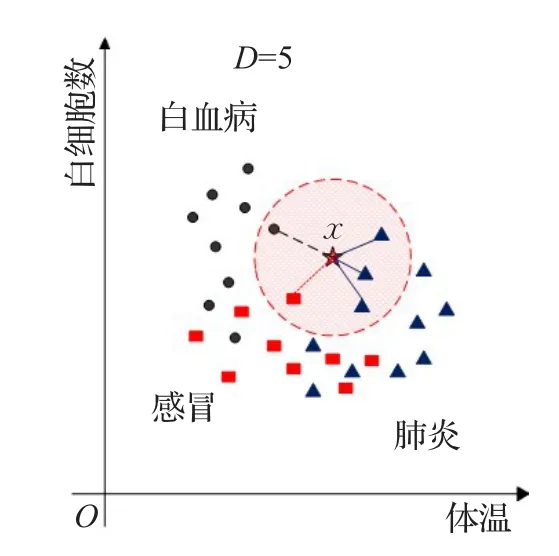
图3 群体决策策略
以群体决策人数D=5为例,先根据公式(7)计算待诊断病例x和所有病例样本之间的相似度,取与其相似度最大的前五个病例样本,即距离最短的前五个数据点。这五个病例样本中的绝大多数所患疾病结果r决定了待诊断病例x的诊断结果。如图所示,最终待诊断病例x被诊断为肺炎。由于篇幅所限,本文所给例子是以二维空间为例,但所提方法可以任意扩展到高维,满足病症属性多样性需要。
现有病例数据库集合L={L1,L2,…,Ln,…,LN}、待诊断病例集合Q={q1,q2,…,qk,…,qK}、疾病类别集合R={r1,r2,…,rj,…,rJ}。其中某病例记录 Ln由向量<f1,f2,…,fm,…,fM,r>构成,f1,f2,…,fm,…,fM为病例的M个属性特征,r为所患疾病结果且r∈R。
给定一个待诊断病例x∈Q,其属于哪种疾病的先验概率P(r|x),其最大似然分类如公式(8)所示:

若群体决策人数为D,则群体决策的概率为:

其中a(x)表示前D个最相似病例样本,sim(x,li)表示待诊断病例x与样本li的相似度计算,y(li,rj)为指示函数,其值由公式(10)得到:

即当li∈rj时,y(li,rj)值为1,否则 y(li,rj)值为0。
由于在相似度计算中值越小相似度越大,待诊断病例x所属疾病类别为:
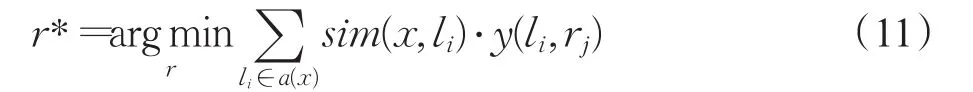
对于病症属性交叉和重叠普通存在的医学病例数据而言,群体决策策略能有效地减少误诊率和提高诊断效率。
5 实验评测
在本章中,介绍了实验环境及测试数据情况,本文中所提到的方法采用MATLAB编写,均在Windows平台下实现。
5.1 实验配置
所有实验均在Windows 7 64位系统中实现运行,主机配置如下:Intel®Core™ i3-2350 2.30 GHz CPU,500 GB SCSI硬盘,4 GB内存。
实验数据来源于某医院信息系统数据库中的真实病例。这些数据包含了病人病症特征和医生给出的正确诊断结果。它真实地反映了临床医学数据库中的数据特征。为了实现病历数据到实验数据的转化,进行了数字化处理,并对原数据属性特征做了最大化的保留。实验中将数据集随机分成两部分,一部分作为病例数据库集合,另一部分作为待诊断病例集合。
5.2 实验结果
图4展示了病例样本数量对诊断准确率的影响,实验从病历数据库中随机抽取病例作为病例样本,且每种疾病按100条和1 000条两种比例抽取。为了验证群体决策的效果,实验将群体决策人数D设置成从2到50之间变化,参与计算的病症属性数目为6。

图4 病例样本数量与诊断准确率关系
由图4可知,病例数据库集合的样本密度对诊断准确率的影响很大,样本越多,诊断准确率越高。而且采用1 000样本/疾病种类的诊断精度要远远高于采用100样本/疾病种类的诊断精度。另外,还能看出D的取值并不是越大越好,在本实验中,D=5具有较好的实验效果。在最开始决策人数较少时,群体决策达到了应有的少数服从多数的效果。一旦D值过大,相反还影响了诊断准确度。这也是和不同疾病的病症数据相融合有很大关系,过分扩大决策人数数量相反还加重了疾病诊断的模糊性。因此,在群体决策中针对不同数据集特点探索适当的决策人数是很有必要的。
图5展示了病症属性数量与诊断准确率关系,即属性相容性对实验精度的影响。实验中的病例数据集合样本按1 000样本/疾病种类比例抽取,属性特征的提取按相容性分析中的高值依次获取。
如图5所示,显然诊断准确率随着属性数量的增大而增长,病症属性越多,计算所得诊断结果准确率越高。在群体决策人数D相同的情况下,参与诊断的病症属性多的准确率远远高于病症属性少的准确率。正如所预测的那样,相容性分析对准确率的影响是明显的。当然,参与计算的属性数目多,计算开销也会相应增大,这一点在后面的时间开销实验中作评估。
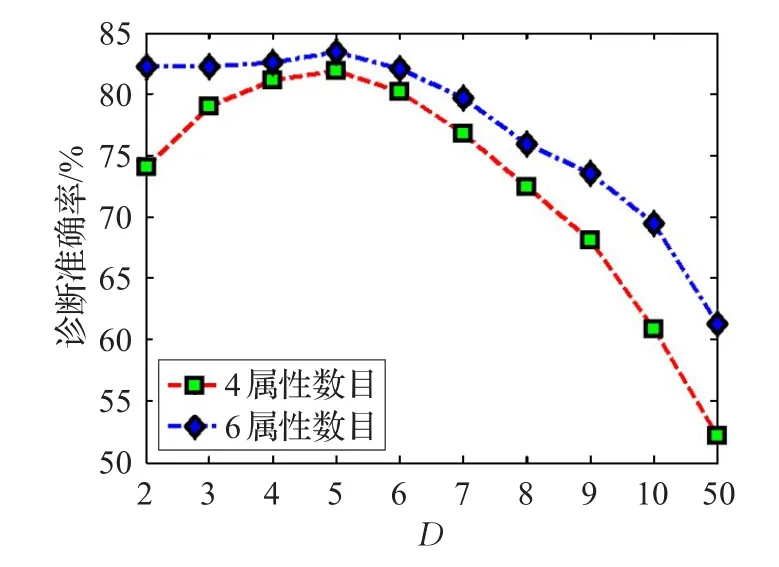
图5 病症属性数量与诊断准确率关系
图6 展示了病症属性数量及D取值对运行时间的影响。实验采用4种属性数目和6种属性数目进行对比。待诊断病例集合记录数为5 000条数据,病例数据集合样本密度为1 000样本/疾病种类,群体决策人数D设置为从2到50之间变化。
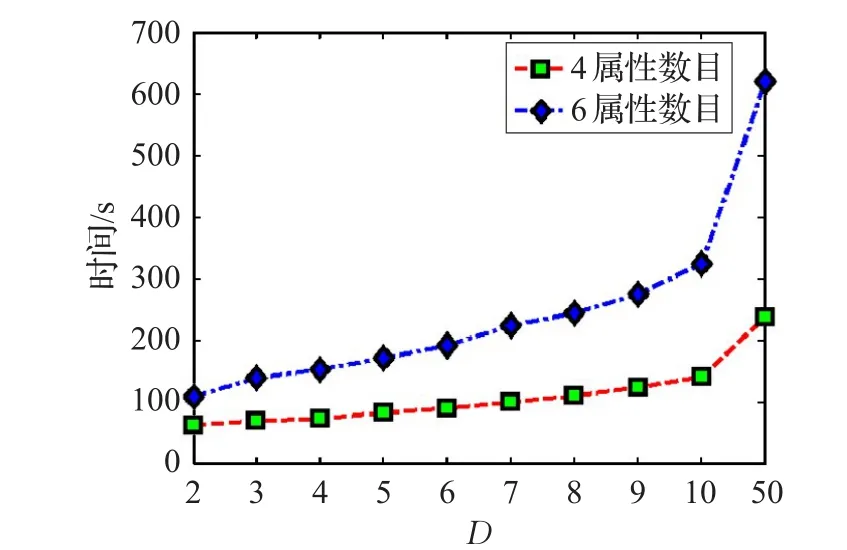
图6 运行时间对比
如图6所示,随着D数目的增长,诊断时间也随着增长。在相同D值的情况下,属性数目越多,诊断执行时间越长,并且两者差距越来越大。当D=50时,计算复杂度更是急剧增长。可见,数据维数和D所带来的计算次数对运行时间有着深远的影响。
图7展示了不同样本密度情况下两种方法的运行时间对比,其中本文采用的权值自动设定方法由相容性分析学习所得,权值人工设定方法中各权值由人工设定。为公平起见和减少人为经验干扰,人工设定方法各权值为平均值,归一化为1。实验中的病例数据集合样本按样本/疾病种类比例抽取,从100到600之间变化。属性特征的提取按相容性分析中的高值依次获取。群体决策人数D=5。

图7 不同方法比较
如图7所示,权值自动设定方法诊断准确率要高于权值人工设定方法。且在当样本密度较小的情况下,这一优势更明显,这也验证了权值自动设定借助机器学习的优势。还可以看出,两种方法诊断准确率都随着样本密度的提高而提高,这和个体数量及其相容性特征有着很大关系。
从实验结果可以看出,无论是所需测试样本密度还是诊断准确率上,基于相容性分析的诊断方法都具有较高的准确率和性能。
6 结束语
本文研究了医疗诊断病例数据的相容性分析问题。为了解决医疗诊断专家系统权值设定和自动赋值的难题,将相容性分析引入到医疗诊断中,并提出了一种基于属性相容性分析的医疗诊断方法。针对权值赋值问题,利用基于属性的相容性分析对医疗数据进行数字化处理,提出了较为实用的权值设定数学模型;针对疾病症状属性多影响诊断结果问题,利用属性之间的关联度构造属性相关矩阵,并对属性进行剪枝处理;为了减少误诊率,系统采用群体决策策略来完成诊断。最后,针对所提方法进行了实验模拟。实验结果表明,该方法具有一定的有效性和实用价值。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
中国交通信息化(2018年5期)2018-08-21 03:37:40
自动化学报(2017年7期)2017-04-18 13:41:02
现代商贸工业(2016年24期)2017-01-13 20:44:23
四川大学学报(哲学社会科学版)(2015年3期)2015-02-28 13:59:59
