
storm平台下工作节点的内存电压调控节能策略
2018-11-30 05:57:36蒲勇霖于炯鲁亮卞琛廖彬李梓杨
通信学报 2018年10期
蒲勇霖,于炯,,鲁亮,卞琛,廖彬,李梓杨,4
storm平台下工作节点的内存电压调控节能策略
蒲勇霖1,于炯1,2,鲁亮2,卞琛2,廖彬3,李梓杨1,4
(1. 新疆大学软件学院,新疆 乌鲁木齐 830008;2. 新疆大学信息科学与工程学院,新疆 乌鲁木齐 830046;3. 新疆财经大学统计与信息学院,新疆 乌鲁木齐 830012;4. 新疆润物网络有限公司,新疆 乌鲁木齐 830002)
针对传统大数据流式计算平台节能策略并未考虑数据处理及传输的实时性问题,首先根据数据流处理的特点与storm集群的结构,建立有向无环图、实例并行度、任务资源分配与关键路径模型。其次结合拓扑执行关键路径与系统性能的分析,提出一种storm平台下工作节点的内存电压调控节能策略(WNDVR-storm, energy-efficient strategy for work node by dram voltage regulation in storm),该策略针对是否有工作节点位于拓扑执行的非关键路径上设计了2种节能算法。最后根据系统数据处理及传输的制约条件确定工作节点CPU使用率与数据传输量的阈值,并对选定的工作节点内存电压做出动态调整。实验结果表明,该策略能有效降低能耗,且制约条件越小节能效率越高。
大数据;流式计算;storm;关键路径;内存电压;能耗
1 引言
近年来,大数据相关研究及应用已成为学术界和企业界关注的热点,其计算模式主要包括流式计算、批量计算、图计算与交互计算等[1-5],且在全球范围内部署了许多大规模的数据中心,其高能耗、高污染与高费用等问题也在日益突出[6]。因此,如何有效地解决新兴信息技术带来的高能耗问题,一直是广大学者共同探讨的焦点。据统计,目前IT领域二氧化碳的排放量占全球比例的2%,预计到2020年这一比例将翻倍[7]。根据美国《纽约时报》报道:全球数据中心每年总用电量超过3 000亿kW·h,相当于30座核电厂的总发电量,而巨大的能量却仅有6%~12%的能源被用于响应用户的请求[8]。特别是随着大数据时代的到来,更多的能源被用于海量数据的处理,但其能效不断降低。因此提高大数据计算过程中的能效,是减少大数据处理能耗成本的有效途径。
目前,数据处理的实时性是衡量大数据应用性能的一个重要指标,流式计算作为新的高性能、可容错的分布式计算平台,存在着能耗过高的问题[9],已经给产业界带来了巨大的开销,因此对流式计算平台的节能优化是一个亟待解决的问题。无论是出于降低能耗保护环境,还是降低大数据运营成本的目的,研究流式计算的节能策略都有着广阔的应用前景。
流式计算平台利用内存读写延迟极低的特性,有效地提高了数据的处理效率,但同时伴随着较高的能耗。现有的流式大数据处理框架以twitter的storm[10]平台为代表。storm是一个开源主从式架构的分布式实时计算平台,其编程模型简单,数据处理高效,支持多种编译语言,且支持拓扑级容错机制,相比于不开源的Puma[11]与社区冷淡的S4[12],storm的应用场景更为广泛;相比于目前流行框架spark streaming[13],storm在数据处理实时性方面效果更佳。此外由于新版本特性的加入、与其他开源项目的无缝融合以及更多库的支持,storm逐步成为学术界和产业界新的研究热点,被称为“实时处理领域的hadoop”[14]。
一个流式计算拓扑及其所包含的一系列任务可通过有向无环图(DAG, directed acyclic graph)表示,有向无环图中的一个顶点代表系统某一个特定任务,一条边表示任务之间存在的依赖关系。当数据流到来后,任务直接在其被调度到的工作节点内存中完成,仅极少部分数据被保存至硬盘。storm平台在进行数据处理及传输时,将有向无环图中的每一个特定任务均匀地分配到每一个工作节点的工作进程中,然而storm平台并未考虑不同工作节点的性能和能耗差异及其带来的工作节点之间的网络传输开销和节点内部进程与线程间的通信开销,忽略了能耗效率问题,导致能效低下。针对storm平台存在的能效过低的问题,本文主要贡献如下。
1) 通过分析storm集群拓扑及节点结构,提出有向无环图、实例并行度、任务资源分配及拓扑关键路径的定义,用于表示数据流在系统内部的工作状态确定集群系统的拓扑情况,为节能算法研究提供理论基础。
2) 通过对拓扑关键路径进行分析,确定是否存在拓扑非关键路径工作节点,从而提出关键路径节能算法(DVRCP, DRAM voltage regulation on critical path)与非关键路径节能算法(DVRNP, DRAM voltage regulation on non-critical path),并证明2种算法内存电压的调控范围。此外根据数据处理限制条件对系统工作节点CPU使用率与数据传输量的阈值进行判别,并通过数据流的处理及传输确定阈值的4种情况,使得系统在满足网络带宽、内存和CPU约束的前提下得到系统能耗最低值,并为工作节点的内存电压调控节能策略的设计提供算法支撑;
3) 通过对系统性能进行评估,确定算法的可行性,提出storm平台下工作节点的内存电压调控节能策略(WNDVR-storm, energy-efficient strategy for work node by DRAM voltage regulation in storm),使系统在拓扑执行过程中根据工作节点真实情况确定系统工作节点数据处理阈值,动态调节内存电压以减少系统中的能耗损失。实验通过4个基准测试从不同的角度证明了算法有效性。
2 相关工作
现有针对大规模的数据处理可归为3类:流式数据处理模式、高性能批量数据处理模式以及二者混合的处理模式。其中,高性能批量数据处理模式主要以hadoop为核心进行算法的改进,通常主要对框架内在区域进行切割划分,以休眠部分磁盘区域或通过动态组件失活(dynamic component deactivation)在一段时间内关闭硬件的部分组件达到节能的目的[15~17]。混合处理模式主要以MapReduce为核心进行算法的改进,主要以任务完成后关闭相关节点[18]、作业调度[19]以及配置参数优化[20]等提高能源利用率来达到节能的效果[21~24]。这2种方案在一定程度上解决了大数据处理的能耗问题,但无法直接作用于现有流式计算平台。针对这一问题现有国内外专家学者提出了针对流式计算性能优化与能耗节约方面的策略。文献[25]与文献[26]总结了在大数据流式计算平台中针对大数据呈现出的实时性、突发性、易失性、无限性、无序性等特征,给出理想的大数据流式计算平台在数据传输、系统框架优化以及应用接口等方面的关键核心技术。此外,类比现有流式计算框架性能与能耗的优缺点,从系统容错、能耗与性能等方面阐明了已有算法面临的挑战。为更好地解决系统能耗与性能的问题,现有学者提出了基于硬件[27]与软件[28]两方面的节能策略并进行研究。
硬件节能策略主要对系统动态电压和电源进行缩放管理,替换高能耗的电子元件,以达到节能的目的。其方法操作简单、效果明显,但在大规模的集群部署中存在成本过高的问题。软件节能策略是现在研究的热点,现阶段软件节能策略主要从与虚拟机结合的角度出发,通过对虚拟机进行部署调整[29-30]考虑数据不可控性以及减少网络数据传输开销来达到节能的目的。文献[31]针对虚拟化数据中心(VNetDC, virtualized networked data center),提出了云计算SaaS计算模型下针对实时流式应用的最小化能耗调度策略。该研究充分考虑到大数据传输不稳定、不可控以及实时流数据量大等特性,在响应时间约束条件不变的前提下,最小化计算与网络传输的总能耗。文献[9]提出大数据流式计算环境下的实时节能资源调度模型(re-stream),通过建立系统CPU利用率、能耗以及响应时间之间的数学关系,并运用分布式流式数据计算理论,定义了整个拓扑执行的关键路径,综合运用拓扑非关键路径上能耗感知的任务整合策略和拓扑关键路径上性能感知的任务调度策略,使响应时间和能耗均达到最低值。文献[32]从有向无环图优化的角度出发,提出弹性自适应性数据流图模型,并使用该策略进行合理的资源分配,以寻求最小化响应时间和最大化吞吐量,从侧面降低了系统能耗。综上所述,以上研究都是从满足流式计算的特性出发提出合理的流式计算节能模型。但针对storm平台框架的节能优化,在减少通信开销和降低能耗等方面仍存在很高的探索价值。
针对流式计算框架的节能优化策略,已有部分学者进行了相应的研究。文献[33]提出一种带有能耗感知的任务整合(ETC, optimizing energy consumption with task consolidation in cloud)技术,该技术的实行通过限制流式计算系统中CPU的使用率,使其低于额定阈值,整合与巩固了虚拟集群间的任务,从而实现了能源方面的任务整合,降低了系统能耗。然而,任务在集群间处理及传输时具有较高的网络延迟,且网络传输的开销较大。文献[34]提出一种虚拟机调度的算法,建立每个虚拟机的能耗评估模型,该策略根据流式计算系统提供的不同数据计算资源,评估不同虚拟机间的能耗,且该实验方案通过xen虚拟化系统实现。但该策略在理想状态下完成,缺乏实际应用场景的实验基础。
文献[35]提出基于流式计算的2种副本调度节能算法——性能与能量均衡副本(PEBD, performance-energy balanced duplication)算法和能量感知副本(EAD, energy-aware duplication)算法,其节能策略的核心思想是当系统内部不执行相应的数据调度时,立刻降低系统的电压。该策略既保证了系统内任务快速执行,同时满足处理相同拓扑关键路径的任务,系统内部能耗不会有显著提高。其中副本可以避免因延迟而带来的系统性能的降低。该策略有2个明显的优点:1)能耗所带来的任务副本可以减少能源的互联,缩短了任务处理的周期;2)提高了整个系统的性能。然而该策略存在部署难度较高、适用平台相对单一的问题。
文献[36]提出了面向storm平台的实时数据节能策略(re-storm),该策略建立CPU占用率、系统响应时间模型与能耗之间的数学模型,并根据storm平台实时性的特点定义整个拓扑的关键路径。通过运用拓扑非关键路径上的能耗感知任务整合策略,使得部分位于拓扑非关键路径上的任务分配到拓扑关键路径上,从而降低了系统整体能耗。该策略很好地解决storm平台中的拓扑非关键路径上任务处理能耗问题,但仍有以下几点有待优化:1)算法有效降低系统整体的能耗,但是算法的时间复杂度显著上升,对系统性能造成一定的影响;2)该策略仅考虑CPU能耗情况,但对别的集群部件能耗情况并未提及;3)该策略使用的为自己定义的拓扑训练集,并非公认已有的拓扑,因此缺乏一定的通用性。
本文与上述研究的不同之处在于以下3点。
1) 文献[32-35]均是通过对系统拓扑进行分析,但并未对如CPU使用率、数据的传输量等已有变量进行能耗建模的研究。本文从CPU使用率、数据的传输量与内存电压3个方面考虑系统的真实情况并建立了相关模型,从而确定工作节点在不同状态下合适的阈值选择,确保系统在不同外在因素下都可以满足节能策略的执行要求。
2) 文献[36]虽然提及了计算拓扑成本的要求,但并未对计算拓扑成本进行进一步的分析建模,本文通过对计算成本进行定义,验证storm集群对数据进行处理及传输产生的必要开销,降低已有算法忽略的部分时间开销。
3) 实验基于Intel公司发布在GitHub上的storm-benchmark-master基准测试[37],而非作者自己定义的拓扑,因此更具有代表性,此外,与CPU的动态电压调控节能策略(DVFS, dynamic voltage frequency scaling)[38]进行对比,验证算法的可行性。
3 相关模型及定义
本节首先对storm集群的拓扑结构和任务并行度进行定义,并在此基础上对拓扑时间计算成本、拓扑关键路径工作节点的选择判断、工作节点内存电压取值范围与节点工作状况4个方面进行了定义,根据以上分析确定工作节点内存带来的能耗问题。
3.1 storm的相关模型
WNDVR-storm在处理数据的过程中,根据单位时间内数据处理及传输的元组数量确定系统工作节点是否位于拓扑执行的关键路径上,由系统的资源占用情况确定工作节点内存电压的取值范围。在满足系统数据处理及传输的约束条件下,通过系统工作节点数据传输量与CPU使用率确定其工作节点阈值,动态调节系统工作节点的内存电压[39-40],减少原系统在处理数据时因高电压而产生的无用功耗,进而降低系统能耗。由此,可建立有向无环图模型表示storm集群数据处理与工作节点的关系。


图1 数据处理有向无环图


图2 实例并行度模型

图3 任务资源分配模型
3.2 拓扑关键路径与拓扑关键路径总成本
本节主要在研究storm平台的基础上,根据定义2对拓扑关键路径总成本进行分析,通过研究发现storm集群处理数据对拓扑计算成本带来较大的影响。
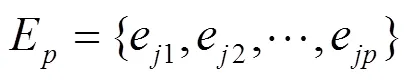


将式(1)代入式(2)可得:




设元组a传输的最迟开始时间为(),元组在拓扑上最迟完成时间为(),最迟开始时间()可以通过遍历有向无环图计算但方向相反,且存在最早开始时间等于最迟开始时间,为

在不引起拓扑关键路径时间延误的前提下,元组a传输的最迟开始时间,为

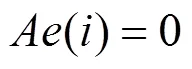

其中,1为源自数据流A经过的有向边1的集合。


其中,2为指向数据流A经过的有向边1的集合。
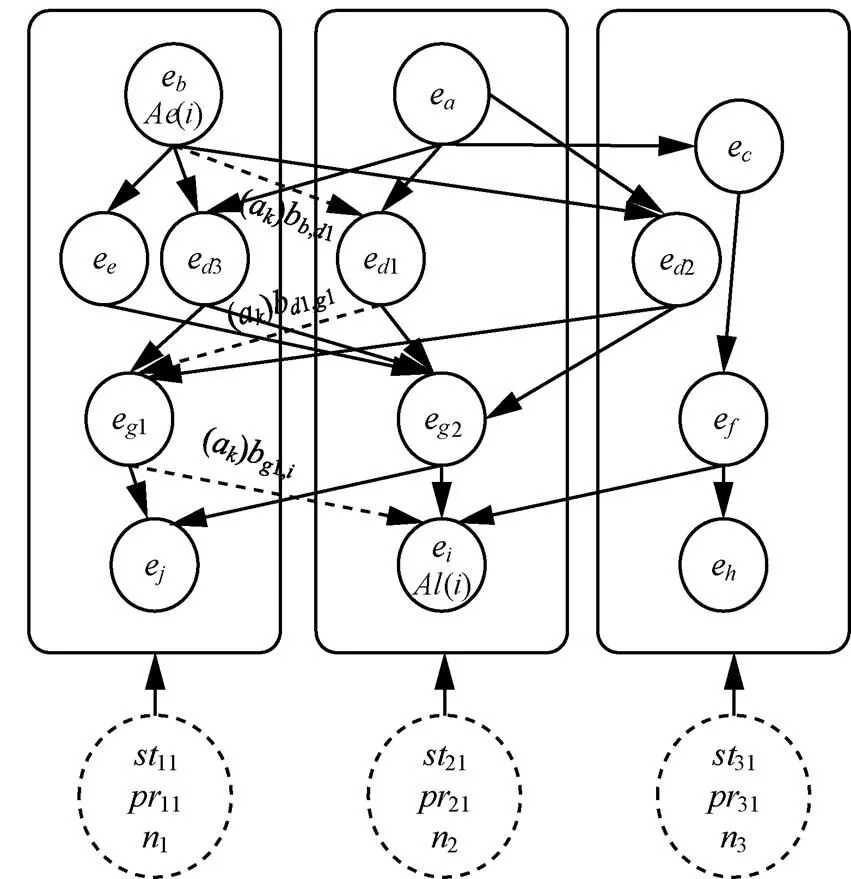
图4 拓扑执行关键路径的数据传输及处理情况
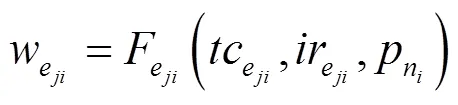

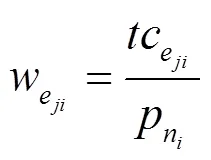



由线程计算成本与线程间通信成本可知,拓扑总的成本为拓扑关键路径总成本W。令拓扑关键路径上所有线程的集合为E={e1,e2,…,e},e∈E,线程之间总通信成本为B={b1,c2,b2,c3,…,b(p−1),cp},b,cj∈B,则拓扑关键路径总成本W为

将所有线程计算成本与线程间通信成本代入式(13),得到拓扑关键路径总成本W为

对于单个元组,将式(9)与(11)代入式(13),拓扑关键路径总成本W为

3.3 拓扑非关键路径工作节点内存电压调控模型
根据3.2节提出的拓扑非关键路径节能算法,3.3节通过建立拓扑非关键路径工作节点内存电压调控模型,确定了拓扑执行非关键路径工作节点内存电压的取值范围。此外,通过定义数据处理及传输约束条件确定了工作节点CPU使用率与数据传输量的阈值,动态调控系统内存电压。
storm平台能耗主要体现在CPU使用率、网络带宽与内存3个方面,其中CPU使用率的能耗最高,内存其次而网络带宽的能耗最低。但是动态调节CPU电压降低能耗的策略[41]已经实现,如通过动态调节CPU频率高低来达到节能的效果[42]等,已广泛应用到IT行业的不同领域中。然而通过调节内存电压来达到节能效果的策略还不成熟,系统内存常电压存在额定值。
此外,针对工作节点是否存在拓扑执行的非关键路径上设计了2种节能算法,当工作节点存在拓扑执行的非关键路径上时,系统实施拓扑非关键路径节能算法,且拓扑执行的非关键路径节能算法不改变系统性能;当工作节点不存在拓扑执行的非关键路径上时,系统实施关键路径节能算法,且关键路径节能算法对系统性能造成一定的影响需要进行相应的评估。




此外,通过DVRNP算法,根据5 min内系统处理及传输数据的采样结果,确定工作节点是否在拓扑执行的非关键路径工作节点,并计算所有拓扑执行的非关键路径工作节点内存电压的取值范围。

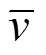
3.4 拓扑关键路径工作节点内存电压调控模型
根据3.2节提出的关键路径节能算法,3.4节通过定义性耗比确定了系统性能与能耗之间的关系。此外,根据性耗比建立了拓扑关键路径工作节点内存电压调控模型,确定了系统电压最低值。
节能算法以不改变storm集群性能为前提,而storm集群的性能主要体现在元组在拓扑执行关键路径上的处理及传输时间,因此在storm集群下执行节能算法需要以不影响元组在拓扑执行关键路径上的处理及传输时间为前提。

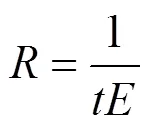
定理1 在storm集群中,元组在拓扑执行关键路径上的处理及传输时间与系统总能耗的性耗比为
其中,C是由多次实验并验证得到的性耗比误差参数,存在取值范围。


因此,有
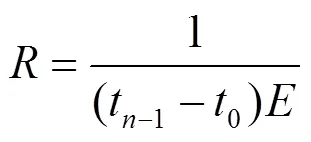




此外,通过DVRCP算法,根据5 min内系统处理及传输数据的采样结果,确定工作节点是否在拓扑执行的关键路径上,并计算所有拓扑执行的关键路径工作节点内存电压的取值范围。
4 工作节点内存电压调控节能策略
本章主要介绍storm平台下工作节点的内存电压调控节能策略,该策略在不影响系统性能的前提下,根据系统工作节点数据流的处理及传输情况对系统工作节点内存电压进行调控以达到节能的目的。节能算法流程如图5所示。算法主要分为以下几个步骤。
步骤1 通过采样计算原系统线程与信道的时间成本。
步骤2 计算拓扑执行的关键路径。
步骤3 确定拓扑关键路径工作节点与拓扑非关键路径工作节点。
步骤4 确定工作节点N的阈值。
步骤5 根据不同的节能算法计算系统总能耗。

图5 节能算法流程
4.1 阈值调控模型
根据第3节确定storm集群基本的数据传输及处理情况,由于storm平台下工作节点的内存电压调控节能策略针对是否有工作节点位于拓扑执行的非关键路径上设计了2种节能算法,并根据不同的节能算法计算工作节点内存电压的取值范围。此外,由storm集群数据处理及传输情况确定工作节点CPU使用率与数据传输量的阈值,动态调节内存电压来达到节能的目的。该算法只需根据3.3节与3.4节确定工作节点内存电压的取值范围,并由定义5对工作节点CPU使用率与数据传输量的阈值进行选择,动态调控系统内存电压,其过程不会对storm集群的实时性造成较大的影响,算法的基本流程如下所示。
算法1对拓扑执行非关键路径上工作节点的内存电压的界限进行定义,并根据工作节点的CPU使用率与数据传输量定义相应的阈值,以对工作节点内存电压进行动态调控,确定storm集群不同状态下的功率值。
算法1 非关键路径节能算法
输入
/*拓扑执行关键路径上的工作节点*/
输出
系统的功率,根据工作节点CPU使用率与数据传输量的阈值判断系统的功率。
3) end while
/*拓扑非关键路径上工作节点的内存电压上升*/
6) end if
20) end switch
根据3.3节确定拓扑执行非关键路径上工作节点的内存电压的最小值,而内存常电压额定值为最大值,算法的1)~6)行根据元组在拓扑执行关键路径上的处理及传输时间不变的前提下,计算拓扑执行非关键路径上工作节点的内存电压的最小值;由定义5判断相关参数是否满足设定的阈值,动态调节拓扑非关键路径上工作节点内存电压,确定此时系统的功率。7)~20)行通过系统数据处理及传输的约束条件确定合适的阈值:当满足1时,拓扑非关键路径上工作节点内存电压为最低值,系统功率为1;当满足2时,动态调控拓扑非关键路径上工作节点内存电压,系统功率为2;当满足3时,动态调控拓扑非关键路径上工作节点内存电压,系统功率为3;当满足4时,拓扑非关键路径上工作节点内存常电压为额定值,系统功率为4。
算法2对拓扑执行关键路径上工作节点的内存电压的界限进行定义,并根据工作节点的CPU使用率与数据传输量定义相应的阈值,以对工作节点内存电压进行动态的调控,确定storm集群不同状态下的功率值。
算法2 关键路径节能算法
输入
输出
系统的功率,根据工作节点CPU使用率与数据传输量的阈值判断系统的功率。
3) end while
6) end if
20) end switch

4.2 工作节点内存电压调控节能策略
能耗和功耗都是系统能量消耗的量度,但其意义不同。工作节点内存电压调控节能策略是为了降低单位时间内系统处理及传输数据的能耗。能耗是系统功率与运行时间的乘积(单位为J)。计算式为[43]

由此可见,能耗反映的是一段时间内系统能量消耗的总和。已知原系统能耗包括内存能耗、CPU能耗、网络带宽能耗与磁盘能耗等,因此,原系统的能耗oec为

其中,E为系统内存的能耗,CPU为系统CPU进行数据处理的能耗,NET为数据传输网络带宽的能耗,HDD为系统磁盘的能耗,other为其他外在因素带来的能耗。
数据流通过I/O读/写入内存堆栈区后,通过内存寻址将内存中的数据提交到主控节点nimbus,根据主控节点的分配任务策略,在系统数据处理及传输的约束条件下进行阈值判断,而后通过工作节点对数据进行处理计算,并经过内存中spout/Bolt实现数据的处理及传输,此外,数据处理及传输的阈值由系统性能与能耗共同决定。根据数据流的处理及传输情况对系统工作节点内存电压进行动态调控,高于工作节点CPU使用率与数据传输量的阈值内存电压上升,低于工作节点CPU使用率与数据传输量的阈值内存电压下降,从而确定系统的功率,此过程在内存堆栈区完成。此外,系统工作节点内存电压最低值由3.3节与3.4节决定,系统工作节点内存常电压最高值为额定值,经计算后的数据通过bolt在内存中进行传输直到将数据推进内存全局变量区,该过程会对数据进行存取且会产生时延。此时系统的能耗Ec为


其中,W为storm集群进行数据处理及传输时间的必要成本,将式(15)代入式(28),根据不同的节能算法可分两种情况计算系统节约的能耗,如式(29)所示。

其中,式(29)的参数与式(15)、式(28)相同,式(29)为数据流经内存后系统节约的总能耗。经过阈值判别后的数据流通过系统工作节点进行处理,数据处理的相关算法如下所示。
算法3 数据的传输及处理算法
输入
输出
全局变量区,处理后的数据进入内存全局变量区。
/*如果系统实施非关键路径节能算法*/
/*此时能耗为1*/
7) else
/*此时能耗为2*/
9) end if
/*构造数据流模型*/
/*获得数据文件中的一条数据流*/
/*内存堆栈区推进为内存全局变量区*/
13) end for
算法3为系统进行工作节点内存电压调控节能策略的真实情况,1)~4)行为数据信息选择获取及处理数据的总时间,5)~9)行为判断不同节能算法产生的能耗,10)~13)行为对系统数据流模型的构建及数据处理环境的改变。
4.3 算法评估
算法3主要表示系统内数据的传输及处理产生的能耗,根据工作节点CPU使用率与数据传输量的阈值确定数据的传输路径,与原系统时间复杂度相同,为

工作节点内存电压调控节能策略的时间开销主要取决于算法1和算法2的时间复杂度,这两个算法不应过于复杂而影响整个系统的性能,因此下文将分析算法1和算法2的执行开销。
设执行工作节点内存电压调控节能策略的时间复杂度为

其中,()为系统执行算法1或算法2的时间复杂度,()为系统执行算法3的时间复杂度。算法1主要对拓扑非关键路径工作节点内存电压取值范围进行选择判别,系统性能并未发生改变,其中DVRNP算法在拓扑关键路径上执行的时间复杂度与原系统相同为(),在拓扑非关键路径上执行的时间复杂度为

其中,为根据系统数据处理总时间内存电压改变的次数,内存额定常电压为1.5 V,则内存电压改变的次数不超过150次,对系统性能影响很小。
算法2主要计算拓扑关键路径工作节点内存电压取值范围,系统性能会发生改变。则拓扑执行关键路径工作节点电压调控的时间复杂度为
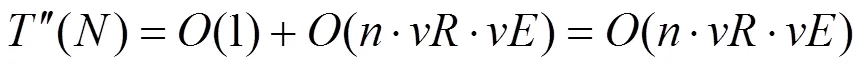
其中,为根据系统性耗比电压改变的次数,为根据系统能耗电压改变的次数,则内存电压改变次数不超过22 500次,这对系统性能造成一定的影响。
此时,系统实施DVRNP算法的时间复杂度为

系统实施DVRCP算法的时间复杂度为

工作节点内存电压调控节能策略分为DVRNP算法与DVRCP算法,其中实施DVRNP算法系统性能不存在影响,在这里不做考虑。系统实施DVRCP算法能耗与性能之间存在一定的关系,即性耗比。假设系统中运行50 000元组的数据,原系统基准测试完全处理50 000 元组数据用时1 s,能耗为6.32 kJ,常数C为0.9;工作节点内存电压调控节能策略后系统运行基准测试完全处理50 000 元组数据用时1.05 s,能耗为4.37 kJ,常数C为0.7。原系统性耗比为0.007 12,实施策略后系统性耗比为0.00 826,由此可见,实施DVRCP算法后的整体性能优于原系统,因此工作节点内存电压调控策略在时间复杂度上是完全可行的。
4.4 算法实现与部署
要在storm集群中部署工作节点内存电压调控节能策略,需要在storm集群中获取storm UI REST API相关信息,其中可通过/api/v1/topology获得拓扑的所有信息,包括线程到工作节点的映射关系及各类参数的配置信息。此外,可通过/api/v1/cluster获得当前系统的各类状态信息,包括线程、进程与节点间的所有通信开销及映射关系。对于拓扑中各线程的CPU资源使用信息,可通过Java API函数中ThreadMXBean类的getThreadCpuTime(long id)方法获得,其中系统ID为线程的ID;对于实验中数据传输频率及所传数据元组的多少则通过./ storm UI > /dev/null 2>&1 &命令检测,其中显示core表示该命令执行成功,传输结果通过累加获取,整个过程在/bin目录下完成。此外,CPU使用率与数据传输频率的数据通过nmon[44]软件获取,且操作系统中数据处理信息与硬件相关参数可通过/proc目录下相关文件获取。代码编译完成后,通过打jar分组至主控节点nimbus的storm_HOME/lib目录下,并在/conf/storm.yaml中配置好相关参数后运行。改进后的storm架构如图6所示。
对图6改进后的storm架构中的相关名词进行解释。
1) 监控器(control monitor):在一段时间内,收集各线程占用的内存,网络带宽和CPU数据处理、传输时间及各线程之间的数据流大小。
2) 数据库(database):存储任务分配信息和监控器传来的数据处理及传输时间信息,并实时更新。
3) 自定义调节器(custom regulator):在自定义调节器中确定系统工作节点内存电压的调控范围,并根据系统数据处理及传输约束条件对工作节点CPU使用率与数据传输量的阈值进行判别,以调节合适的内存电压。

图6 改进后的storm架构
5 实验及结果分析
搭建的storm集群有一个主控节点nimbus、16个工作节点supervisor与3个关联节点zookeeper,且整个集群在无其他任务运行的条件下进行实验。
本文实验目的为验证工作节点内存电压调控节能策略的有效性,其主要的测试标准有集群的吞吐量、能耗、数据的处理响应时间等。实验算法采用WordCount、Sol、RollingSort与RollingCount[37]作为基准测试用例,最后对实验结果进行分析。
5.1 实验环境
为证明WNDVR-storm的有效性,实验需要的storm集群部署在19台普通PC机上,且每台PC机的内存统一为4 GB。根据不同节点的运行情况,storm集群节点及数据处理环境的配置参数如表1所示。

表1 storm环境配置参数
其中,控制台节点进程UI、主控节点进程nimbus、关联节点进程zookeeper1(leader)运行在同一台PC机上,工作节点进程supervisor 1~16与关联节点进程zookeeper2、3(follower)分别部署在18台不同PC机上,此外,根据不同的节点类型选定3台PC机进行nmon测试监控,记录CPU使用率、数据传输频率及内存占用率等。整个storm集群内各节点硬件参数配置相同,现记录storm集群内处理1 GB数据,PC机配置参数如表2所示。

表2 storm集群内PC机配置参数
为全面测试工作节点内存电压调控节能策略的有效性,实验选取4组不同基准测试用例对该策略进行测试,分别是网络带宽敏感型(network- sensitive)的Sol、CPU敏感型(CPU-sensitive)的WordCount、内存敏感型(memory-sensitive)的RollingSort以及storm真实场景下的应用RollingCount,各基准测试运行时工作进程(worker)的数量与当前所需的工作节点一一对应,其余参数保留其默认配置,具体基准测试参数配置如表3所示。
其中,设置topology.workers为16,表示各基准测试运行时仅在一个工作节点内分配一个工作进程;设置topology.acker.executors为16,表示保证数据流的可靠传输,各工作进程除了运行分配给它的线程之外,还额外运行一个Acker Bolt实例;此外,设置的每个message.size等于一个元组的大小。
此外,内存电压取值范围根据3.3节与3.4节不同工作节点内存电压调控模型确定,实验通过二分法测得位于拓扑执行关键路径上的工作节点的内存电压调控选择在1.20~1.50 V不断改变,位于拓扑执行非关键路径上的工作节点的内存电压调控选择在1.32~1.50 V不断改变。在2 min内不停地传输元组,记录单机内存不同状态的能耗如表4所示。

表3 基准测试参数配置

表4 DDR3 1066内存能耗的数据测量值
5.2 工作节点CPU使用率与数据传输量的阈值选择
根据4.1节实验环境参数设置完成以下实验,由于工作节点内存电压调控节能策略使用storm平台,因此在节能的同时需要保持计算的效率,即不能影响系统的性能。为便于实验检测,根据4种基准测试用例设置metrics.poll的值为5 000 ms,metrics.time的值为300 000 ms,即每组实验每5 s刷新一次数据,共统计5 min。
根据上述条件,现有storm集群存在19台普通PC机,通过nmon软件检测5 min内storm集群处理一份数据文件,统计系统CPU使用率与数据传输量的变化,为后续实验奠定基础。

图7 原系统执行RollingCount后,数据处理及传输约束条件
通过storm UI可以检测出整个storm集群存在2个拓扑执行非关键路径的工作节点与14个拓扑执行关键路径的工作节点,后续的实验以此为前提,图7系统执行RollingCount后数据处理及传输约束条件。由图7可以看出,计算后CPU使用率的平均值约为62.8%,数据传输量的平均值约为49 632 tuple/s。同理可得,系统执行RollingSort后,CPU使用率的平均值约为59.6%,数据传输量的平均值约为46 528 tuple/s;系统执行WordCount后,CPU的使用率的平均值约为86.4%,数据传输量的平均值约为97 329 tuple/s,系统执行Sol后,CPU的使用率的平均值约为23.2%,数据传输量的平均值约为98 361 tuple/s。现通过表1~表3中的环境配置相关参数进行24次实验。根据图7系统数据处理及传输约束条件,分别对CPU敏感型的WordCount、网络带宽敏感型的Sol与内存敏感型的RollingSort进行测试,且每个基准测试进行4次实验。根据系统数据处理及传输约束条件平均值,由不同工作节点内存电压调控节能算法确定工作节点的不同阈值,并对实验结果进行对比分析。该实验通过storm UI观测工作节点数据处理情况,根据数据传输量、CPU使用率与内存功率来确定合适工作节点CPU使用率与数据传输量的阈值,实验结果如图8所示。
从实验结果中可以看出,storm集群的功率随工作节点CPU使用率与数据传输量选定阈值的不同而改变。由图8的6组实验测试可知,实验组test11、test21、test31、test41、test51与test61为原系统不进行节能算法且不改变工作节点CPU使用率与数据传输量的阈值,在50 s之前系统数据处理的功率逐步上升,且稳定在50 s左右,其原因为数据传输速率逐步稳定,而数据传输及处理在不同的工作节点上的功率不相同。但对于不同的基准测试,系统根据不同的阈值情况,通过实施不同的节能算法,使功率明显低于原系统,具体计算结果在表5中进行统计。
由表5可知,系统执行DVRCP算法后的功率低于执行DVRNP算法后的功率。且根据实验test13、test23、test33、test43、test53与test63的结果可知,系统工作节点CPU使用率与数据传输量的最佳阈值由实验前期采样结果以及实验选择不同的拓扑决定。因此,后续实验工作节点CPU使用率与数据传输量的阈值根据实验前期采样结果与选择的不同拓扑训练集决定。
5.3 工作节点内存电压调控节能策略实验结果分析
根据工作节点是否在拓扑执行的关键路径上,工作节点内存电压调控节能策略可分为2种节能算法,并根据数据处理限制条件对工作节点CPU使用率与数据传输量的阈值进行判别,从而动态调节系统不同电压,当系统数据处理高于工作节点CPU使用率与数据传输量的阈值时内存电压上升,当系统数据处理低于工作节点CPU使用率与数据传输量的阈值时内存电压下降。现通过不同的基准测试对策略进行测试,并通过对比CPU的动态电压调控节能策略[38],验证算法的可行性。根据5.2节实验test13、test23、test33、test43、test53与test63选择的阈值,通过测试5 min内系统不停地传输元组的能耗,对系统进行CPU敏感型的WordCount、内存敏感型的RollingSort以及网络带宽敏感型的Sol共3组不同的基准测试,其中基准测试WordCount与Sol为理想状态下系统的能耗情况,RollingSort为整个系统工作节点内存环境的能耗情况。图9展示了0~5 min内系统在3种基准测试下的能耗情况。

图8 3种不同基准测试的工作节点CPU使用率与数据传输量的阈值情况

表5 两种节能算法下系统的功率情况
由图9可以看出,随着时间的增加,系统的能耗不断上升,且系统实施3种节能算法后的能耗明显小于原系统,而DVFS算法明显优于其他2种节能算法。但DVFS算法已广泛应用到IT行业的不同领域,而内存的电压调控节能策略还不成熟,且CPU的工作电压远高于内存的工作电压,因此DVFS算法节能效果更明显。对于DVRNP算法与DVRCP算法,由图9(a) 的WordCount测试与图9(b)的Sol测试表明,在220 s前DVRNP算法的节能效果优于DVRCP算法的节能效果,根据3.4节可知,DVRCP算法受系统元组在拓扑执行关键路径上的处理及传输时间的影响,因此220 s前DVRNP算法的节能效果比较好;在220 s后系统执行DVRCP算法的节能效果优于DVRNP算法的节能效果,根据5.2节采样确定storm集群存在2个拓扑执行的非关键路径工作节点与14个拓扑执行的关键路径工作节点,因此220 s后DVRCP算法的节能效果比较好。而图9(b) RollingSort测试的能耗相对较高的原因为包含了如系统必要时间计算成本W等物理因素,在180 s后系统的数据处理及传输基本稳定,系统能耗逐步达到平衡。

图9 系统在3种基准测试下的能耗情况
RollingCount是storm平台下的一个大数据典型基准测试,其特点为持续在内存中遵循某个统计指令(如同一件商品的出现次数)计算,然后每隔一段时间输出实时计算后的结果,可以广泛应用到各类需要大数据实时计算的场景,例如实时热门广告、商品、微博等的统计。本实验采用RollingCount对系统的真实功率进行测试,首先根据5.2节对RollingCount基准测试的阈值进行选择,图10为0~5 min内对storm集群19台PC机采用RollingCount测试的功率情况。

图10 系统执行RollingCount测试后的功率情况
由图10可以看出,系统工作节点CPU使用率与数据传输量的阈值在CPU使用率为65%、数据处理量为50 000 tuple/s的情况下,2种算法的节能效果最好,且系统执行DVRNP算法与DVRCP算法后的功率明显小于原系统。因此后续系统执行RollingCount测试的实验工作节点CPU使用率与数据传输量的阈值以CPU使用率65%、数据处理量50 000 tuple/s为准。由图10计算,系统执行DVRNP算法的功率的平均值为924.2 W,系统执行DVRCP算法的功率的平均值为791.1W,因此系统执行DVRCP算法的功率低于系统执行DVRNP算法的功率。为计算系统的能耗,需对系统不同时期的能耗结果进行累加,现计算19台PC机5min内的能耗情况,计算结果如图11所示。
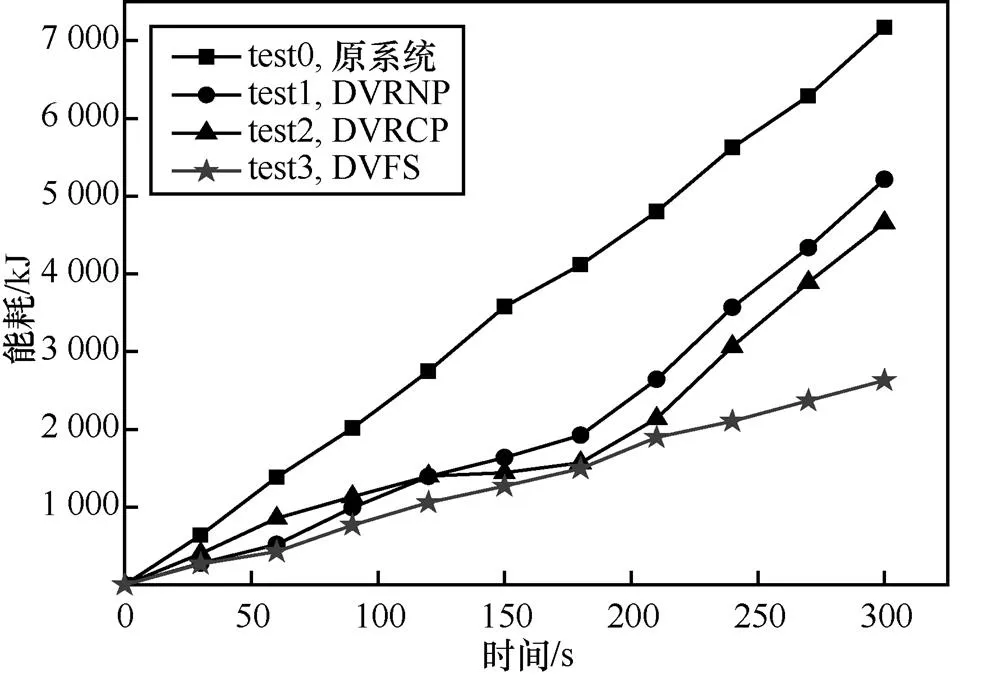
图11 系统执行RollingCount测试后计算系统的能耗结果
由图11可以看出,原系统能耗基本不受系统数据处理及传输的影响,而系统实施3种不同的节能算法后,能耗增加比率也在随着时间的变化不断发生改变,而CPU的工作电压远高于内存的工作电压,故DVFS算法节能效果优于其他2种算法,但调节CPU的电压容易对系统的性能造成影响,不适合storm系统的运行。对于DVRNP算法与DVRCP算法而言,在180 s之前,数据传输量较少,相对触发CPU使用率阈值的可能较低,系统工作节点内存电压普遍较低,将系统实施DVRNP算法与DVRCP算法分别与原系统能耗作对比,系统实施DVRNP算法将原系统的能耗降低到54.3%,系统实施DVRCP算法将原系统的能耗降低到53.0%;在180 s之后,数据传输量超过系统阈值,且触发CPU使用率阈值的可能性较高,系统工作节点内存电压增大,将系统实施DVRNP算法与DVRCP算法分别与原系统能耗作对比,系统实施DVRNP算法将处理能耗降低到原系统的97.1%,系统实施DVRCP算法将处理能耗降低到原系统的93.3%。因此,现统计系统5 min内处理及传输数据的总能耗,其中原系统总能耗为7 170.3 kJ,实施DVRNP算法后的系统能耗为5 212.7 kJ,实施DVRCP算法后的系统能耗为4 656.8 kJ。系统实施DVRNP算法与DVRCP算法分别与原系统能耗作对比,系统实施DVRNP算法将原系统的能耗降低了28.5%,系统实施DVRCP算法将原系统的能耗降低了35.1%。综上所述,工作节点内存电压调控节能策略取得了比较理想的效果。
由于缺少更多的物理节点,实验通过虚拟机建立更多的虚拟节点以评估算法的局限性,实验分别设置36、56、76和96个工作节点与原系统16个工作节点进行比对,以能耗降低的百分比为评估指标,实验结果如图12所示。

图12 实施2种算法系统的节能效果
图12为理想状态下实施2种算法系统的节能效果,由图12可知,系统实施2种节能算法并未随着工作节点的增加而产生影响。但在理想状态下并未考虑数据的处理及传输速率等因素,现根据真实节点数量的增加情况,计算数据的处理及传输速率,具体的计算结果如图13所示。

图13 系统实施2种算法对系统数据的处理及传输速率的影响
由图13可知,实施DVRNP算法对系统数据的处理及传输速率基本不会产生影响,但实施DVRCP算法会随着集群节点数的增加,而使系统数据的处理速率降低,工作节点间数据传输速率下降,系统性能下降,且数据的处理及传输速率降低会影响系统整体的通信开销,由此,根据图13可得出DVRCP算法的理论函数为

其中,V为数据的处理及传输速率,N为节点数,代入图13的数据,化简得到式(37)。

由此可知,实施DVRCP算法随着工作节点数量的增加会对系统性能等因素造成一定的影响,因此工作节点内存电压调控节能策略存在一定的局限性。
工作节点内存电压调控节能策略应该以保证性能为前提,其中DVRNP算法对系统性能没有影响,在此不做分析。然而DVRCP算法对系统性能造成一定的影响,其主要的影响为元组在拓扑执行关键路径上的处理及传输时间增加,因此需要对DVRCP算法进行评估,评估的方法为选用性耗比,图14为5 min内系统性耗比的变化。

图14 性耗比
根据3.4节可以看出,实施DVRCP算法后系统的性耗比与原系统性耗比基本相等,现由图14测试16个工作节点的结果可知,系统实施DVRCP算法对storm集群的性耗比并不构成影响,但是元组在拓扑执行关键路径上的处理及传输时间与系统总能耗乘机的倒数存在误差,实验中不同服务器之间的性耗比并不相同,经实验反复测试,获得实验存在误差常数C在[0.75, 1.34]之间。原系统16台服务器的平均性耗比为0.073 75;实施DVRCP算法后系统16台服务器的平均性耗比为0.081 5。由此,可见DVRCP算法对系统的性能不构成影响,因此DVRCP算法是完全可行的。
6 结束语
随着大数据技术的不断发展,各种流式计算平台和系统不断产生,storm作为大数据流式计算的主流平台,已逐渐在学术界和产业界引起广泛关注,然而storm系统并未考虑因自身性能带来的能耗问题。近年来现有研究改进了storm数据调度存在的某些问题,但依旧存在系统能耗过高以及应用场景单一等问题。针对上述问题,本文提出了WNDVR-storm,即针对工作节点是否在拓扑执行的关键路径上分别提出2种节能算法,计算不同工作节点内存电压取值范围,并通过数据处理及传输制约条件,以此对工作节点CPU使用率与数据传输量的阈值进行判别,根据数据流的处理及传输情况对系统电压进行动态调节,从而降低了系统不必要的能耗损失。经4种基准测试论证了算法的可行性,工作节点内存电压调控节能策略有效地提高了storm平台的能量利用率。
下一步的研究工作主要包括以下几点。
1) 从storm平台的性能出发,以不改变甚至提高系统性能为前提,实现storm平台的节能。可通过提高storm平台的计算速率,降低数据处理时间以实现系统的节能,如将系统部分CPU处理的非文本数据替换到图形处理器(GPU, graphics processing unit)中处理。
2) 可以增大storm平台的网络带宽,网络带宽越大,数据量的传输速率越快,从而使得系统整体性能提高,可从侧面提高系统节能效果。因此,可以考虑网络带宽方面的节能策略,以减少数据处理时间来达到降低storm平台能耗的目的。
3) 可通过降低storm平台的内存延迟,提高系统的整体性能,如果延迟降低,则数据传输时间变短,从而达到以提高性能为前提并从侧面降低系统能耗的目的。
[1] 孟小峰, 慈祥. 大数据管理: 概念、技术与挑战[J]. 计算机研究与发展, 2013, 50(1): 146-169.
MENG X F, CI X. Big data management: concepts, techniques and challenges[J]. Journal of Computer Research and Development, 2013, 50(1): 146-169.
[2] 孙大为. 大数据流式计算: 应用特征和技术挑战[J]. 大数据, 2015,1(3): 99-105.
SUN D W. Big data stream comuting: features and challenges[J]. Big Data Research, 2015,1(3): 99-105.
[3] CHEN C L P, ZHANG C Y. Data-intensive applications, challenges, techniques and technologies: a survey on big data[J]. Information Sciences, 2014, 275(11): 314-347.
[4] RANJAN R. Streaming big data processing in datacenter clouds[J]. IEEE Cloud Computing, 2014, 1(1): 78-83.
[5] KAMBATLA K, KOLLIAS G, KUMAR V, et al. Trends in big data analytics[J]. Journal of Parallel and Distributed Computing, 2014, 74(7): 2561-2573.
[6] 邓维, 刘方明, 金海, 等. 云计算数据中心的新能源应用: 研究现状与趋势[J]. 计算机学报, 2013, 36(3): 582-598.
DENG W, LIU F M, JIN H, et al. Leveraging renewable energy in cloud computing datacenters: state of the art and future research[J]. Chinese Journal of Computers, 2013, 36(3): 582-598.
[7] 廖彬, 张陶, 于炯, 等. 温度感知的MapReduce节能任务调度策略[J].通信学报, 2016, 37(1): 61-75.
LIAO B, ZHANG T, YU J, et al. Temperature aware energy-efficient task scheduling strategies for MapReduce[J]. Journal on Communications, 2016, 37(1): 61-75.
[8] 蒲勇霖,于炯,鲁亮,等. 基于实时流式计算系统的数据分类节能策略[J].计算机工程与设计,2017, 38(1): 59-64
PU Y L, YU J, LU L, et al. Energy-efficient strategy based on data classification in real-time stream computing system[J]. Computer Engineering and Design, 2017, 38(1): 59-64
[9] SUN D, ZHANG G, YANG S, et al. Re-Stream: Real-time and energy-efficient resource scheduling in big data stream computing environments[J]. Information Sciences, 2015, (319): 92-112.
[10] TOSHNIWAL A, TANEJA S, SHUKLA A, et al. Storm @Twitter [C] //Proc of the 2014 ACM SIGMOD Int Conf on Management of data. ACM, 2014: 147-156.
[11] BORTHAKUR D, GRAY J, SARMA J S, et al. Apache hadoop goes realtime at Facebook[C] //The 2011 ACM SIGMOD Int Conf on Management of data. 2011: 1071-1080.
[12] NEUMEVER L, ROBBINS B, NAIR A, et al. S4: Distributed stream computing platform[C] //The 10th IEEE Int Conf on Data Mining Workshops (ICDMW 2010). 2010: 170-177.
[13] ZAHARIA M, DAS T, LI H, et al. Discretized streams: an efficient and fault-tolerant model for stream processing on large clusters[C]//The 4th USENIX conf on Hot Topics in Cloud Computing. 2012: 10.
[14] FISCHER M J, SU X, YIN Y. Assigning tasks for efficiency in hadoop[C]//The 22th annual ACM Symp on Parallelism in algorithms and architectures. 2010: 30-39.
[15] ALBERS S. Energy-efficient algorithms[J]. Communications of the ACM, 2010, 53(5):86-96.
[16] TCHEMYKH A, PECERO J E, BARRONDO A, et al. Adaptive energy efficient scheduling in Peer-to-Peer desktop grids[J]. Future Generation Computer Systems, 2014, 36(7):209-220.
[17] POLLAKIS E, CAVALCANTE R L G, STANCZAK S. Traffic demand-aware topology control for enhanced energy-efficiency of cellular networks[J]. EURASIP Journal on Wireless Communications and Networking, 2016, 2016(1):61-77.
[18] LIU G X, XU J L, HONG X B. Internet of things sensor node information scheduling model and energy saving strategy[J]. Advanced Materials Research, 2013, 773(1):215-220.
[19] WANG X, WANG Y, CUI Y. A new multi-objective bi-level programming model for energy and locality aware multi-job scheduling in cloud computing[J]. Future Generation Computer Systems, 2014, 36(7):91-101.
[20] HE F Y, WANG F. Research on energy saving for multi-back after blending water from one station system’s parameters optimization[J]. Advanced Materials Research, 2014, 1023:187-191.
[21] MILI M R, MUSAVIAN L, HAMDI K A, et al. How to increase energy efficiency in cognitive radio networks[J]. IEEE Transactions on Communications, 2016, 64(5):1829-1843.
[22] CHEN X, YANG H, ZHANG W. A comprehensive sensitivity study of major passive design parameters for the public rental housing development in Hong Kong[J]. Energy, 2015, (93): 1804-1818.
[23] WANG H, CHEN Q. A semi-empirical model for studying the impact of thermal mass and cost-return analysis on mixed-mode ventilation in office buildings[J]. Energy & Buildings, 2013, 67(4):267-274.
[24] YANG T, MINO G, BAROLLI L, et al. Energy-saving in wireless sensor networks considering mobile sensor nodes[J]. Computer Systems Science & Engineering, 2011, 27(5): 317-326.
[25] 孙大为, 张广艳, 郑纬民. 大数据流式计算: 关键技术及系统实例[J].软件学报, 2014, 25(4): 839-862.
SUN D W, ZHANG G Y, ZHENG W M. Big data stream computing: Technologies and instances[J]. Journal of Software, 2014, 25(4): 839-862.
[26] LI K C, JIANG H, YANG L T, et al. Big data: algorithms, analytics, and applications[M]. Florida: CRC Press, 2015: 193-214.
[27] BONAMY R, BILAVARN S, MULLER F. An energy-aware scheduler for dynamically reconfigurable multi-core systems[C]// International Symposium on Reconfigurable Communication-Centric Systems-On-Chip. 2015:1-6.
[28] 蒲勇霖, 于炯, 鲁亮, 等. 大数据流式计算环境下的内存节能策略[J].小型微型计算机系统, 2017, 38(9): 1988-1993.
PU Y L, YU J, LU L, et al. Energy-efficient strategy for memory in big data stream computing environment[J]. Journal of Chinese Mini-Micro Computer Systems, 2017, 38(9):1988-1993.
[29] TRIHINAS D, PALLIS G, DIKAIAKOS M D. JCatascopia: monitoring elastically adaptive applications in the cloud[C]//The 14th IEEE/ACM Int Symp on Cluster, Cloud and Grid Computing (CCGrid). 2014: 226-235.
[30] VAN D V J S, VAN D W B, LAZOVIK E, et al. dynamically scaling apache storm for the analysis of streaming data[C]//The 2015 IEEE 1st Int Conf on Big Data Computing Service and Applications. 2015: 154-161.
[31] CORDESCHI N, SHOJAFAR M, AMENDOLA D, et al. Energy-efficient adaptive networked datacenters for the QoS support of real-time applications[J]. The Journal of Supercomputing, 2014, 71(2): 448-478.
[32] BASKIYAR S, ABDEL-KADER R. Energy aware DAG scheduling on heterogeneous systems[J]. Cluster Computing, 2010, 13(4): 373-383.
[33] HSU C H, SLAGTER K D, CHEN S C, et al. Optimizing energy consumption with task consolidation in clouds[J]. Information Sciences, 2014, 258(3):452-462.
[34] KIM N, CHO J, SEO E. Energy-credit scheduler: an energy-aware virtual machine scheduler for cloud systems[J]. Future Generation Computer Systems, 2014, 32(2):128-137.
[35] ZONG Z, MANZANARES A, RUAN X, et al. EAD and PEBD: two energy-aware duplication scheduling algorithms for parallel tasks on homogeneous clusters[J]. IEEE Transactions on Computers, 2010, 60(3):360-374.
[36] PATAN R, RAJASEKHARA B M. Re-storm: real-time energy efficient data analysis adapting storm platform[J]. Jurnal Teknologi, 2016, 78(10):139-146.
[37] 鲁亮,于炯,卞琛,等. 大数据流式计算框架Storm的任务迁移策略[J]. 计算机研究与发展, 2018, 55(1): 71-92.
LU L, YU J, BIAN C, et al. A Task Migration Strategy in Big Data Stream Computing with Storm[J]. Journal of Computer Research and Development, 2018, 55(1): 71-92.
[38] MATTEIS T D, MENCAGLI G. Keep calm and react with foresight: strategies for low-latency and energy-efficient elastic data stream processing[J]. Journal of Systems and Software, 2016, 51(8):1-12.
[39] PAMLEY M R, ORRO J M, KEOWN W F, et al. Dynamic memory voltage scaling for power management: US, US20100250981[P]. 2010.
[40] 蒲勇霖, 于炯, 王跃飞, 等. 大数据流式计算环境下的阈值调控节能策略[J]. 计算机应用, 2017, 37(6):1580-1586.
PU Y L, YU J, WANG Y F, et al. Energy-efficient strategy for threshold control in big data stream computing environment[J]. Journal of Computer Applications, 2017, 37(6):1580-1586.
[41] HONG S P, YOO S J. Dynamic voltage scaling method of CPU using workload estimator and computer readable medium storing the method: US, US7685446[P]. 2010.
[42] HWANG I, PEDRAM M. A comparative study of the effectiveness of CPU consolidation versus dynamic voltage and frequency scaling in a virtualized multicore server[J]. IEEE Transactions on Very Large Scale Integration Systems, 2016, 24(6):2103-2116.
[43] 林闯, 田源, 姚敏. 绿色网络和绿色评价: 节能机制、模型和评价[J].计算机学报, 2011, 34(4): 593-612.
LIN C, TIAN Y, YAO M. Green network and green evaluation: mechanism, modeling and evaluation[J]. Chinese Journal of Computers, 2011, 34(4): 593-612.
[44] GRIFFITHS N. Nmon performance: A free tool to analyze AIX and Linux performance[EB/OL]. (2017-06-25)[2017-07-03]. http://www. ibm. com/ developerworks/aix/library/au-analyze aix.
Energy-efficient strategy for work node by DRAM voltage regulation in storm
PU Yonglin1, YU Jiong1,2, LU Liang2, BIAN Chen2, LIAO Bin3, LI Ziyang1,4
1. School of Software, Xinjiang University, Urumqi 830008, China 2. School of Information Science and Engineering, Xinjiang University, Urumqi 830046, China 3. School of Statistics and Information, Xinjiang University of Finance and Economics, Urumqi 830012, China 4. Xinjiang Runwu Network Limited Company, Urumqi 830002, China
Focused on the problem that traditional energy-efficient strategies never consider about the real time of data processing and transmission, models of directed acyclic graph, parallelism of instance, resource allocation for task and critical path were set up based on the features of data stream processing and the structure of storm cluster. Meanwhile, the WNDVR-storm (energy-efficient strategy for work node by dram voltage regulation in storm) was proposed according to the analysis of critical path and system performance, which included two energy-efficient algorithms aiming at whether there were any work nodes executing on the non-critical path of a topology. Finally, the appropriate threshold values fit for the CPU utilization of work node and the volume of transmitted data were determined based on the data processing and transmission constraints to dynamically regulate the DRAM voltage of the system. The experimental result shows that the strategy can reduce energy consumptioneffectively. Moreover, the fewer constraints are, the higher energy efficiency is.
big data, stream computing, storm, critical path, DRAM voltage, energy consumption
TP311
A
10.11959/j.issn.1000-436x.2018213
蒲勇霖(1991−),男,山东淄博人,新疆大学博士生,主要研究方向为内存计算、流式计算、绿色计算等。

于炯(1964−),男,新疆乌鲁木齐人,博士,新疆大学教授、博士生导师,主要研究方向为并行计算、分布式系统、绿色计算等。
鲁亮(1990−),男,新疆乌鲁木齐人,新疆大学博士生,主要研究方向为分布式系统、内存计算、绿色计算。
卞琛(1981−),男,江苏南京人,博士,新疆大学副教授,主要研究方向为分布式系统、内存计算、绿色计算等。
廖彬(1986−),男,新疆乌鲁木齐人,博士,新疆财经大学副教授、硕士生导师,主要研究方向为分布式系统、数据库理论与技术、绿色计算等。
李梓杨(1993−),男,新疆乌鲁木齐人,新疆大学硕士生,主要研究方向为流式计算、内存计算等。
2017−07−18;
2017−12−25
蒲勇霖,puyonglin1991@foxmail.com
国家自然科学基金资助项目(No.61262088, No.61462079, No.61562086, No.61363083, No.61562078);国家科技部科技支撑项目(No.2015BAH02F01);新疆维吾尔自治区研究生科研创新项目(No.XJGRI2016028)
The National Natural Science Foundation of China (No.61262088, No.61462079, No.61562086, No.61363083, No. 61562078), The Science and Technology Support Projects of Ministry of National Science and Technology(No. 2015BAH02F01), The Research Innovation Project of Graduate Student in Xinjiang Uygur Autonomous Region (No. XJGRI2016028)
猜你喜欢
技术与市场(2024年4期)2024-05-09 00:51:12
——以某大厦地下停车场第二层开挖管道工程为例*
项目管理技术(2023年11期)2023-12-06 03:06:54
昆钢科技(2022年2期)2022-07-08 06:36:14
当代水产(2021年10期)2022-01-12 06:20:28
建材发展导向(2021年23期)2021-03-08 01:05:38
电脑爱好者(2020年15期)2020-09-12 14:22:28
当代陕西(2019年13期)2019-08-20 03:54:22
山西建筑(2019年10期)2019-04-01 11:02:48
华人时刊(2018年15期)2018-11-10 03:25:26
测绘科学与工程(2014年5期)2014-02-27 07:06:14
