
基于线性四分树的空间关键词最近邻查询方法研究
2018-11-30 01:46于启迪
计算机应用与软件 2018年11期
于启迪 吴 雷,2 马 昂
1(石家庄铁道大学经济管理学院 河北 石家庄 050043)2(燕山大学信息科学与工程学院 河北 秦皇岛 066004)
0 引 言
随着社会的飞速发展和科技的不断进步,信息在人们的生活中发挥着越来越重要的作用,人们对信息的需求一直在不断地增加。尤其随着互联网的高速发展,智能手机和移动终端的广泛普及,越来越多的应用中出现了地理位置信息与文本信息的相互交融。人们在每天的工作和学习生活中,不断地与这些应用进行着“交互”。空间文本信息已经成为人们生活必不可少的一部分,“我现在在哪?附近都有什么景点?我怎么去火车站?”等问题已经成为人们日常工作和生活的一部分,并逐步发展成为可以提高人们生活质量的基本信息服务模式,基于位置的服务便应运而生。
基于位置的服务LBS(Location Based Service),核心功能就是基于用户当前的位置信息,为用户提供相关的服务[1]。例如人们使用大众点评搜索附近的餐馆,或使用百度地图查找附近的景点。
作为位置服务的一种重要应用,同时满足空间位置和文本信息的查询即空间关键词查询(Spatial keyword query)得到了学术界和工业界的广泛关注。所谓空间关键词查询,即根据给定的用户的地理位置以及提出的关键词,在空间文本对象中查找符合用户要求的对象。在空间关键词查询领域中一种非常重要的操作就是Top-k查询[2-3],即根据给定的评分函数在数据集中返回得分最高的k个对象[4]。
空间关键词查询中针对关键词匹配方面的文本约束分为完全匹配和部分匹配两种[5]。其中完全匹配[6-9],要求查询返回的空间文本对象必须全部满足用户的查询关键词要求。而部分匹配[10-13],要求返回的空间文本对象具有的关键词与用户的查询关键词部分匹配即可。以图1为例,该区域中有6个空间文本对象,每个对象的地理位置和其具有的关键词及每个关键词所对应的权重(即关键词所占对象中的文本信息的重要程度)已知。例如,对象o1是一个专业游泳馆,对象o6是一个水上乐园。假设用户在查询点q想要查找一家游泳馆并且可以喝一杯果汁,(即q.T={swim,juice})。基于完全匹配语义要求的查询返回的结果为对象o3和o6,而基于部分匹配的语义要求查询返回的结果为对象o1和o2。这是由于虽然o1和o2均部分满足查询关键词要求,但o1和o2对应于查询文本信息所得的权重大于o3和o6对应于查询文本所得的权重,且对象o1和o2与用户距离更近。此时如果用户追求的是有品质的生活(如:想找一家高品质的游泳馆,只是顺便喝杯果汁),那基于文本信息部分匹配返回的结果更能满足用户的要求且距离更近。

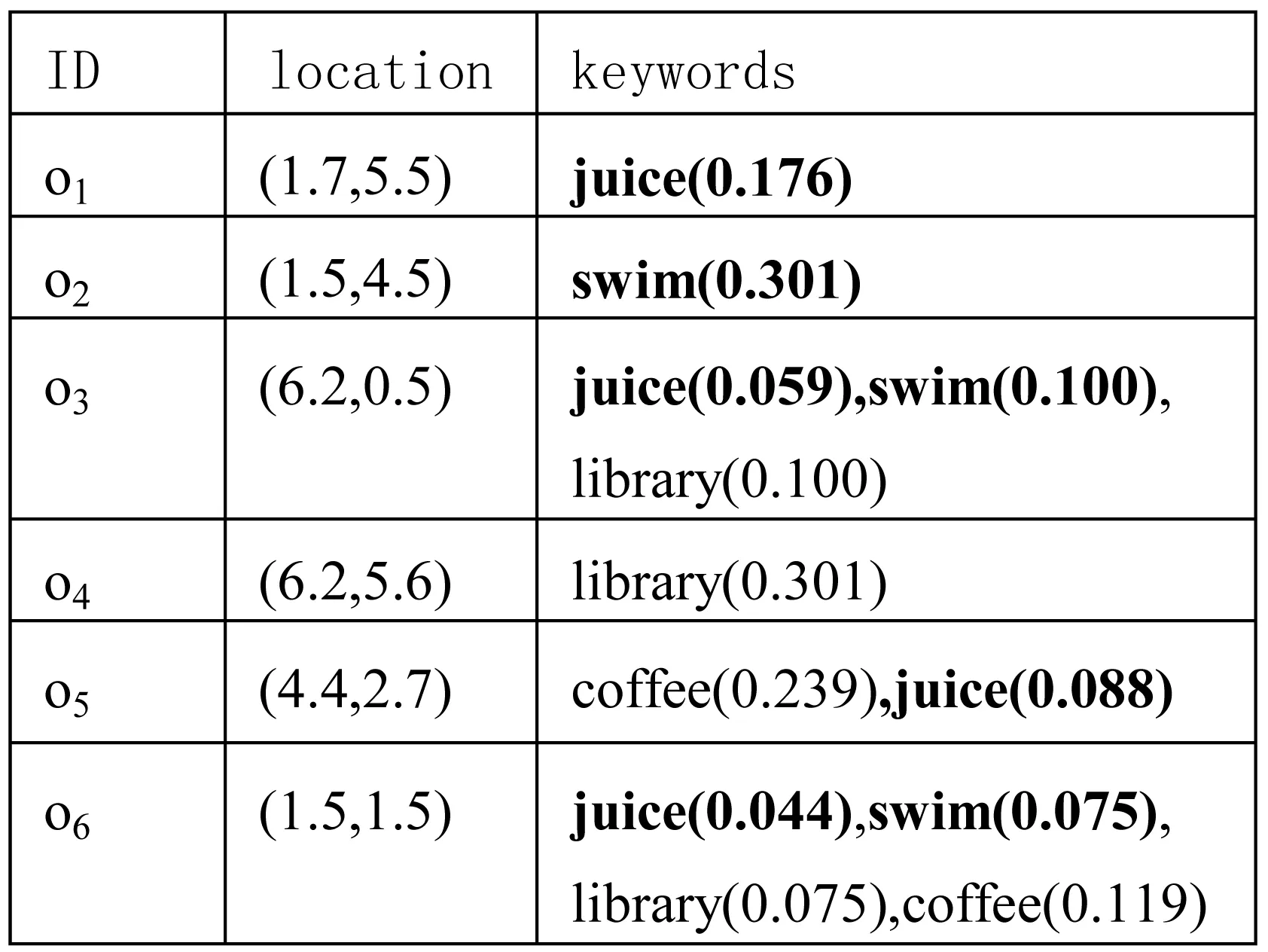
图1 一个查询的例子
随着信息技术的发展,数据无论在内容上或是形式上都呈现出多样性和复杂性,如何存储、管理这些数据成为该领域的难点,如何从大量数据中返回符合用户要求的结果,更给研究者们提出了新的挑战。众所周知,建立高效的空间索引能够提高空间数据的查询效率,有效的查询算法能有效地避免冗余计算,实现提前终止。在Top-k 查询问题上,还需要排序策略。所以,索引技术与查询算法的结合是解决快速查询的关键。
为了解决空间文本对象上的k最近邻查询问题,研究者们提出了许多索引技术和查询算法[5]。现有文献中提出了两种索引结构IR-tree[14]和IR2-tree[15]。在IR-tree索引中,根据所有对象的地理位置建立一棵R树,每个结点都关联一个倒排文件,因此可以在Top-k查询中立即消除不包含任何查询关键词的对象。当关键词数量较少时,IR-tree技术是有效的。然而,当查询关键词的数量增加时,IR-tree的性能会显著降低;此外,由于只建立了一棵树,树的维护成本较高。IR2-tree技术通过利用签名技术即根据查看结点包含的对象中出现的关键词的来决定是否进一步探索结点。然而,所有的空间文本对象也依然被组织在一个单一的R树中,当数据量增大时会显著影响搜索算法的性能[16]。为解决上述不足,文献[16]提出了倒排线性四分树索引结构IL-Quadtree,这种索引结构针对每个关键词都建立一棵线性四分树。当用户进行查询时,直接访问该查询关键词对应的线性四分树即可,直接忽略了那些不包含查询关键词的对象。然而,该工作仅关注了空间文本对象的在语义方面的完全匹配。
本文综合考虑用户的地理位置和查询文本信息与区域中的空间文本对象的信息匹配情况,对满足查询条件的空间文本对象进行排序,最终返回前k个对象。本文应用线性四分树提出了一种基于自适应虚拟四分树的Top-k查询算法Avqt,该算法可同时支持语义上的完全匹配和部分匹配。其中,通过计算被查询区域与用户所提出关键词的文本相似性,较早地将不满足查询要求的结点剪枝。
综上所述,本文贡献总结如下:
1) 从四分树本身层层递进四分的特点出发,提出了一种无需计算所有区域,基于自适应虚拟四分树的支持高效Top-k空间关键词查询算法Avqt。
2) 在真实数据集上进行了大量的实验,验证了提出的算法在Top-k查询中的有效性和高效性。
1 相关工作
空间文本对象指既有地理位置信息,又有文本信息的对象。空间关键词查询指根据给定用户的地理位置以及提出的关键词,在空间文本对象中查找符合用户要求的对象。其中,Top-k空间关键词查询成为研究的热点。2008年,文献[15]提出了一种新的解决Top-k空间关键词查询问题的索引结构——IR2树。IR2树是将R树和签名文件相结合,即将R树上的每个结点都存放一个签名文件,该签名文件包括了该结点的后代所包含的对象相关信息。在查询过程中,如果该结点的签名文件中确认没有包含全部查询关键字,则不需要进一步探索该节点,从而在一定程度上提高了剪枝效率。2009年,文献[17]首次提出了IR树,一种新型的结合倒排文件和R树的索引结构,并且在IR树的基础上相继发展了DIR树、CIR树,进一步提高了索引效率。2011年,文献[18]为提高Top-k空间关键词的查询性能提出来另一种形式的混合索引结构,称为S2I索引。S2I将关键词按出现的频率进行划分,对频繁出现和不频繁出现的关键词区别对待。对于频繁的关键词S2I为每个关键词建立一棵聚集R树,称为aR树,对不频繁的关键词,将与其相关的对象信息保存在一个块文件中。2013年,文献[16]提出了一种倒排线性四分树索引结构IL-Quadtree,针对每个关键词都建立一棵线性四分树。当用户进行查询时,直接访问查询关键词对应的线性四分树,忽略了那些不包含目标关键词的对象。
现有文献已经提出了各种类型的空间关键词查询。这些相关作品可以从两个方面进行分类:1) 查询是否包含空间约束;2) 关键词语义使用完全匹配还是部分匹配。
对于具有空间约束的研究,要求返回的空间文本对象的位置与查询区域相交或包含在查询区域[19-24]。其中,查询处理可分为两种:空间优先或文本优先。空间优先索引是先将空间进行划分建立索引树,然后在每个结点中存放有关的关键词的信息。当数据量巨大的时候,这类索引的效率会明显下降,并且剪枝困难,影响算法的效率[26]。另一类是文本优先的索引,包括I3[26]、S2I[27]等。这类索引针对每个关键词建一棵树,由于并不是所有的结点都存放关键词的信息,因此可通过检索不同树的相同结点,检验该区域是否包含所有的关键词,从而实现剪枝。
本文研究内容,从关键词语义来说属于部分匹配语义。从空间约束上来说属于文本优先索引。从索引结构来说本文采用倒排线性四分树索引结构,它结合了IR-Tree和四分树索引的优点,为每个关键词建立一棵B+tree树,这棵树中只包含满足该关键词的对象,不包含该关键词的对象便会被去除。运用线性四分树的四分的思想,提出虚拟四分树,对不满足条件的区域不再进行四分,从而极大地减少了数据访问量。另一方面,查询只访问具有用户查询关键词的空间文本对象,节省了索引占据的空间,并且索引将位置相近的对象聚合在磁盘中,减少了I/O次数,提高索引效率[16]。
2 问题的形式化描述
设空间数据库中一组空间文本对象集合O可表示为O={o1,o2,…,on}。其中,对于任意一个o∈O均包含空间位置信息l和文本信息T,表示为o=(l,T)。具体来说,o.l表示对象o在二维空间内的地理位置点;o.T={t1,t2,…,tn}表示一组关键词的集合。用户提出的查询记为q,其中q中包含用户的查询位置和一系列查询关键词集合以及查询要求返回的结果个数k,记为q=(q.l,q.T,q.k)。任意两个空间文本对象的相似性包括空间相似性和文本相似性两个方面。
定义1空间相似性。两个对象之间的空间相近程度用空间相似性表示,记为fs(q,o)。文本采用欧几里得距离来衡量查询对象与空间文本对象之间的空间相似性,其中用ζ(q.l,o.l)表示查询对象和空间文本对象之间的空间距离。设ζmax表示空间中任意两点的最远距离,其目的是将距离规范到区间[0,1]。此时,查询对象q与对象o的空间相似性定义为:
(1)
对象间空间距离的大小直接影响空间相似性。由式(1)可知,两个对象距离越远,即ζ(q.l,o.l)越大,其空间相似程度越低。因此fs(q,o)的值越小,两对象间的空间相似性越大。此外,若将对象o扩展为一个区域R,则该区域R与查询对象q的距离定义为q到该区域的最近距离。
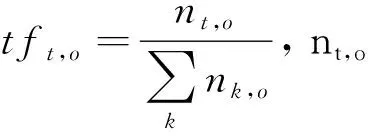
(2)
式中:maxP为整个区域中每个关键词的最大关键词权重加和,其目的是将权重规范到区间[0,1]。类似的,若对象o扩大为一个区域R,则该区域包含的关键词是所有被包含在区域R中的空间文本对象所包含的关键词的并,每个关键词的权重是该关键词在该区域内的最大权重。由式(2)可知ft(q,o)值越小,查询对象q与空间文本对象o的文本相似性越大。
由于本文在计算对象间文本相似性时使用的权重是对象中所有满足查询q的关键词的权重加和,式(2)中的文本相似性的计算实现了对OR语义的支持。此外,本文对OR语义的支持还体现在查询算法中。
定义3空间文本相似性。任意两个空间文本对象的相似性为同时考虑空间距离和文本内容的相似程度。结合式(1)和式(2),查询对象q与空间文本对象o之间的空间文本相似性定义为:
f(q,o)=αfs(q,o)+(1-α)ft(q,o)
(3)
式中:α是一个固定值参数,用来调节两对象间空间距离和文本相似性之间的相对重要程度,且α∈[0,1]。此时,f(q,o)的值越小,对象q与o的相似性就越大。
定理两个空间文本对象o1、o2。如果ζ(q.l,o1.l)≤ζ(q.l,o2.l),且对于任意一个t∈q.T,满足wt,o1≥wt,o2,则有f(q,o1)≤(q,o2)。
直观地来讲,定理反映为与查询对象q部分匹配的两个对象,在空间上,其中一个对象比另一个对象距离q更近,同时该对象的每个关键词的权重都比另一个对象更高时,那么该对象较另一个对象与查询q更匹配。该定理的证明较直观,具体证明过程省略。
根据定理可得出以下推论:
推论设一个空间文本对象集合R,用覆盖这些对象的最小边界矩形表示其位置,R的关键词是R中所有对象具有的关键词的并,记为R.T={o1.t∪o2.t∪…∪on.t},R中关键词的权重由关键词在R中所有对象中的权值最大值加和表示,记为R.wt∈R.T=∑o∈Rmax(wt,o)。因此对于区域R中任意一个对象o,均有f(q,R)≤(q,o)。
证明对象o在R的覆盖中,由推论可知,对象o到查询点q的距离小于等于空间文本对象集合R到查询点的距离,即ζ(q.l,R.l)≤ζ(q.l,o.l),所以由式(1)可知fs(q,R)≤fs(q,o)。由于对象o中的关键词是空间文本对象集合R中关键词的一部分,且空间文本对象集合R的文本权重是其包含的所有满足查询关键词的文本权重最大值的和,所以由式(2)可知ft(q,R)≤ft(q,o)。综合以上运用式(3),则f(q,R)≤(q,o)。
3 部分匹配空间关键词查询算法
本文的研究目标是要运用倒排线性四分树(详见3.1节),从空间文本对象组成的集合O中,寻找与查询q空间文本相似性最高的k个对象,即k最邻近查询。
3.1 倒排线性四分树 IL-quadtree
本文采用倒排四分树索引所有的空间文本对象。具体来讲,IL-quadtree是倒排文件和线性四分树的结合,对于每个关键词,维护一棵线性四分树,四分树中索引了所有包含该关键词的对象。图2显示了图1中包含关键词的对象所对应的倒排线性四分树。
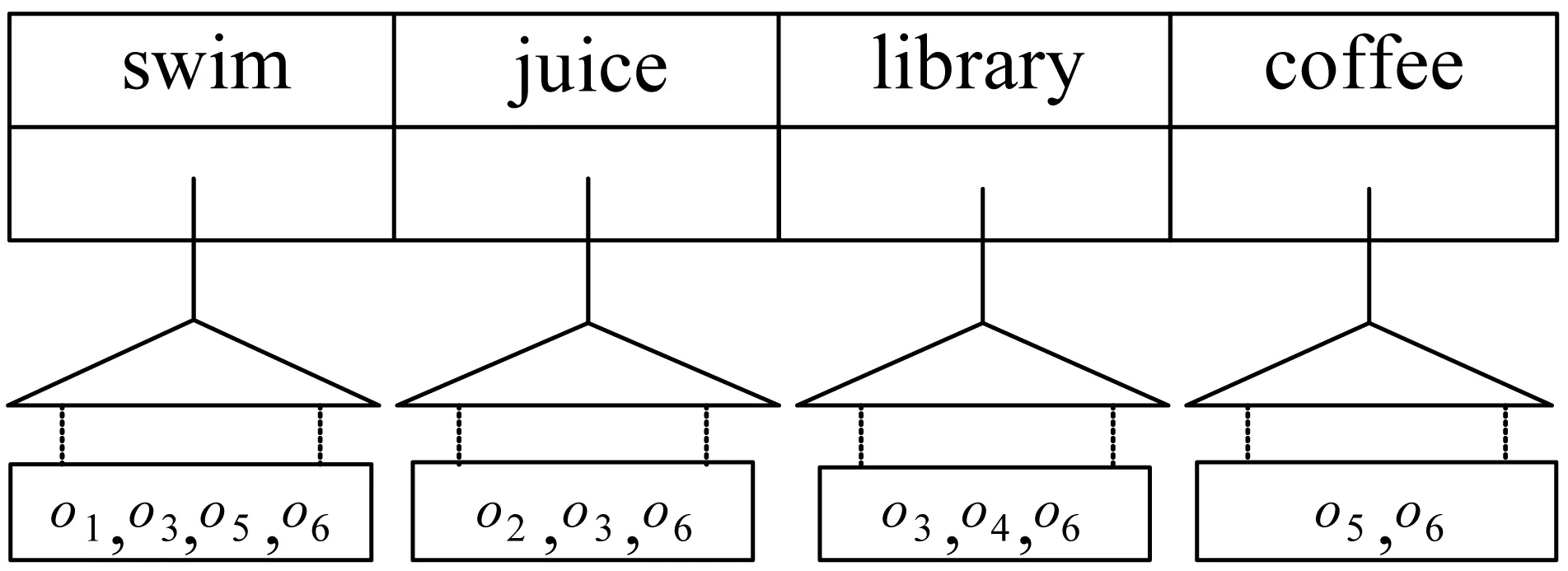
图2 聚集倒排线性四分树
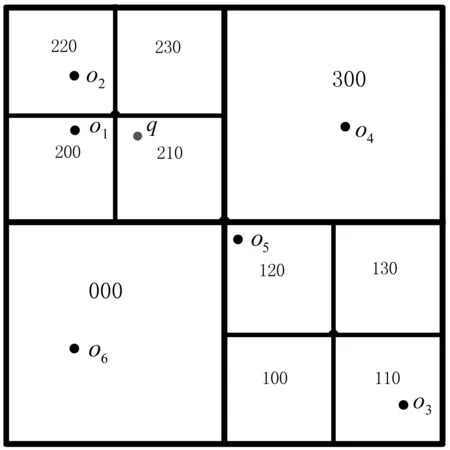
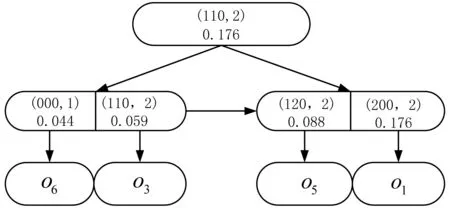
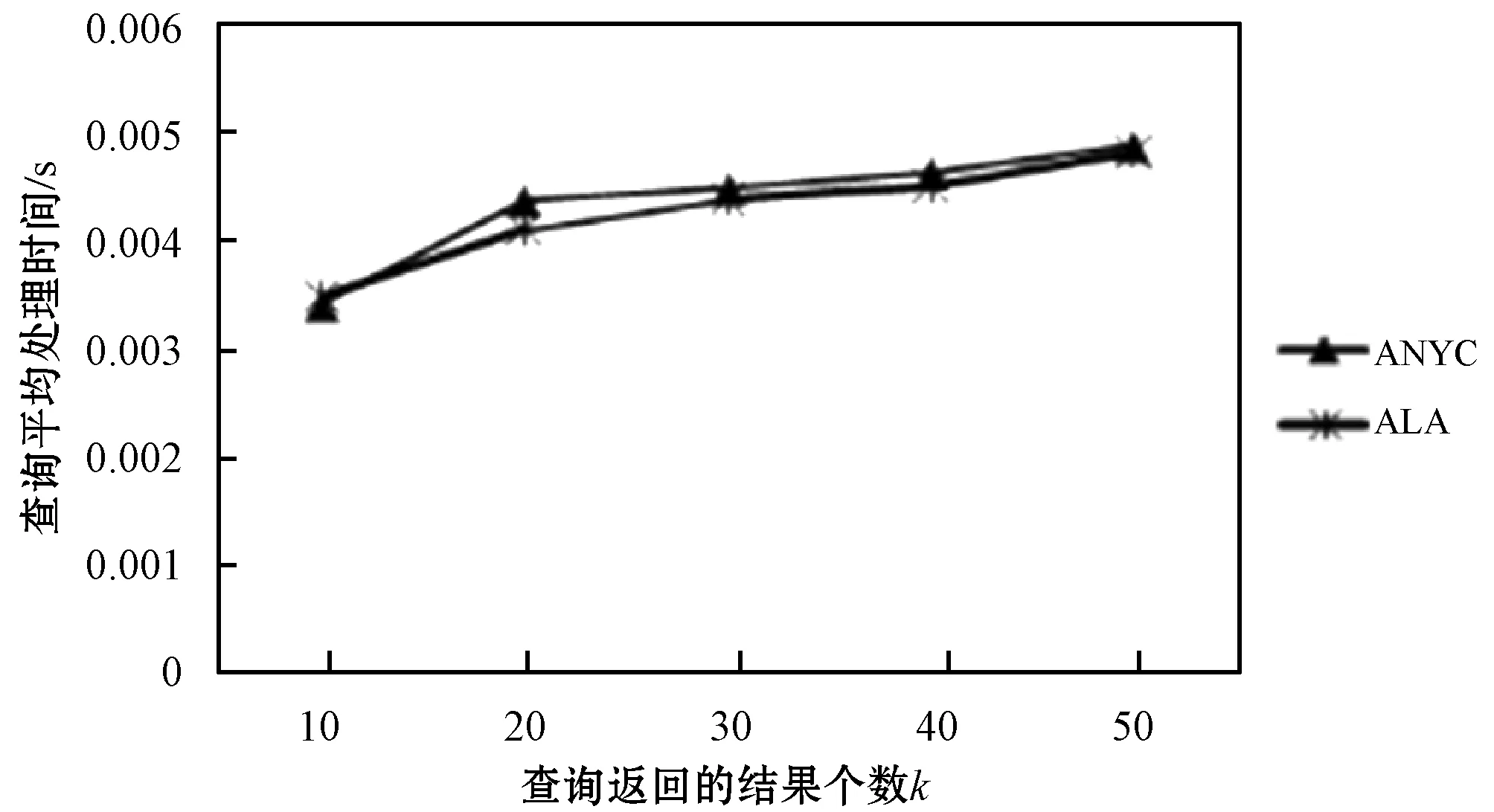
这些结点所在空间遵循一定的规则进行编码,最常用的地址码是四进制的或十进制的Morton码,本文采用四进制的Morton编码。文献[28]对Morton编码方法进行了详细说明,这里进行简要介绍。首先设定好区域要划分的最大深度r,每个区域单元的码值可由深度计算,则一个区域最多可被划分为2r×2r个区域单元。在空间的某一深度h(h≤r)下区域空间被四等分。四等分的区域根据一个标签方案进行标记,其中区域四个方向SW、SE、NW、NE分别标记为0、1、2、3,如图3所示。Morton码的左边第一位数字表示区域在深度为1时的所处的方向和位置,左边第二位数字是深度为2时区域所处的方向和位置,依次类推。因此,Morton码始终以数字r为准,所划分深度为h 图3 空间中四个区域的划分 利用上述编码方式,对空间中的四个区域SW、SE、NW、NE进行自顶向下的自适应的四等分。自适应的含义是对每一个象限都进行四等分,直至该区域仅包含一个对象或划分达到最大划分深度。因此,每个区域的划分深度不尽相同,划分深度依据该象限包含的对象数进行自适应的调节。图4是根据上述编码方式,将图1的空间区域进行划分(r=3)。划分后,每个区域的编码如图4所示。 图4 区域编码 依据上述编码规则,空间中的所有单元(cell)均可用四进制串表示。进而,可以采用最常用的B+tree存储所有非空单元,极大程度上减少存储空间。每个关键词均对应着一棵B+tree。其中每个非叶子结点均存储带有层次标号的Morton码值和该单元下包含的对象中关于该特定关键词的权重最大值。每个叶子结点存储其父类结点所包含的具有该特定关键词的对象。以图1为例,关键词“swim”对应的B+tree如图5所示,其中单元编号包括Morton码和单元所处的层次标识两部分组成。 图5 “swim”对应的线性四分树 本文采用最小最佳优先原则,基于根据查询关键词对应的IL-quadtrees上建立的虚拟四分树,提出了一种新颖的Top-k部分匹配查询算法。本文的目标即从带有同时带有空间位置和文本信息的空间文本对象集合O中,根据查询集合q,运用倒排线性四分树,寻找包含q中所有或部分关键字集合并且空间文本相似性尽可能大的k个对象。 具体来讲,查询结果需要满足空间与语义两方面要求:从语义的角度讲,查询结果中的点集合应包含所有或部分查询点语义;从空间的角度讲,查询点到对象点距离尽可能短,以满足空间上兴趣点接近预设地点的要求。 3.2.1 自适应虚拟四分树的建立 虚拟四分树之所以称为“虚拟”在于其物理上并不真实存在。预先设定好区域划分的深度,则四分树中每个区域的编码和每个区域的上层结点区域编码均可知。所以,根据已知的区域间的层级关系就能够建立一棵体现层级关系的虚拟四分树。由于虚拟四分树在对空间进行逻辑上的划分时,可对空间区域进行自适应的划分,会导致不同的层次相同编码的现象。因此本文采用对虚拟四分树进行四分时对被四分单元进行层次标号编辑,进而区分不同层次的码值,形成自适应虚拟四分树。图6显示了与图1对应的针对查询q的虚拟四分树,其中黑色表示查询访问可不再深入的单元,白色表示查询需继续访问的单元。假设区域被划分的最大深度为3,虚拟四分树的划分深度为该区域包含的对象数小于等于1时停止划分。则虚拟四分树的根节点为整个区域,即(000,0)表示该区域是处于第0层上码值为000的区域。虚拟四分树的第一层结点即第0层区域的下一层区域,编码为{(000,1),(100,1),(200,1),(300,1)}。虚拟四分树中第一层(000,1)结点的第二层结点,编码为{(000,2),(010,2),(020,2),(030,2)},依次类推,即可构建一棵完整的自适应虚拟四分树。 图6 自适应虚拟四分树 3.2.2 Avqt算法流程 Avqt算法将整个空间区域按照逻辑上四分树的思想运用自适应虚拟四分树进行划分,利用最小最佳优先原则查找符合要求的Top-k个空间文本对象。算法1中展示了Avqt算法的具体过程。在该算法中,用栈h存放从虚拟四分树中取得的被标记过层次的结点码值以及该结点与查询q之间的空间文本相似性值。栈h中的元素以该元素与查询点之间的空间文本相似性值为排序依据,升序排列。自适应虚拟四分树的划分程度为该区域下只有一个对象或该区域的层次已经处于预先设定好的最深层次r,满足其中一种即可认为该区域为叶子结点,否则为非叶子结点。首先找到与查询关键字q.T对应的聚集线性四分树记为tset。将虚拟四分树的根结点放入栈h中(第3行)。当栈h不为空时,从栈h中取出栈顶结点e(第5行)。判断结点e是否为空间文本对象(第9行),如果是,则将结点e直接放入结果集R中。如果不是,判断结点e的类型。如果结点e是非叶子结点(第12行),则依次计算e的四个孩子结点e’ 在tset中的关键词权重加同时运用式(3)计算e’与查询q之间的空间文本相似性f(q,e’)存入栈h中(第14-18行)。如果结点e为叶子结点(第22行),则将结点e在不同的与查询关键词对应的线性四分树上的对象取出,计算每个对象与查询q之间的空间文本相似性放入栈h中。最后,当结果集R中对象个数达到k时,算法终止。 算法在完全匹配语义上的扩展:算法1可以很容易地扩展到对完全匹配语义的支持。在完全匹配语义中,只需在取出线性四分树上某一层次的结点时,判断其是否在所有的聚集线性四分树中存在。如果是则证明该结点所在区域含有全部关键词。执行算法的相关计算即算法1中,在第14行和第22行加上相应的约束即可。 算法1基于自适应虚拟四分树的空间关键词查询算法(Avqt) Input:L Q:线性四分树, k:要求返回对象的个数, q:查询对象 Output, d:空间距离约束 Output:R:前k个f值最小的对象集合 1.R=∅; h=∅; 2.tset=所有与q.T相对应的LQ; 3.将虚拟四分树的根结点放入栈h; 4.while h≠∅ do 5. 从栈nbs中出栈顶结点e; 6. if |R|=k then 7. break; 8. end if: 9. if e是一个对象then 10. R:=R∪e; 11. else 12. if e 是一个非叶子结点 then 13. for 该结点的每一个孩子结点e’ 14. for tset中的每一棵LQ 15. 计算e’中关键字对应的权重加和; 16. end for; 17. 计算 f(q,e’); 18. 将代有层次标号的子结点e’和f(q,e’)入栈h; 19. end for; 20. else 21. for 叶子结点e 中的每一个对象o 22. for tset中的每一棵LQ 23. 计算o中关键字对应的权重加和; 24. end for; 25. 计算 f(o,q); 26. 将对象o和f(q,o)入栈 h; 27. end for; 28. end if; 29. end if; 30. end while; 31.return R; 本节将通过一系列的实验来验证本文提出的Avqt空间关键词查询算法的查询效率。 本文在公开的真实数据集上进行算法性能的评估。应用Foursquare签到数据集[29-30],采用数据集上纽约(NYC)和洛杉矶(LA)的签到数据。表1中列出了数据集的具体信息,包括对象数量,关键词数量与每个对象的平均关键词数量,其中数据集中的对象由该对象的地理坐标和一组文本描述组成。 表1 数据集的统计信息 一次最近邻查询由200个查询组成,通过改变算法中的各个参数和实验数据集的大小形成的不同查询平均处理时间来评价算法的性能。其中,查询点的坐标在整个被查询区域中随机生成,查询点所具有的多个查询关键词在整个被查询区域中的所有关键词中随机抽取。查询关键词的个数(l)被设置从1到5,查询返回的结果个数k被设置为从10到50,调节空间与文本的权重比例的参数α被设置为从0.1到0.9。默认l=3,k=10,α=0.3。 实验中的所有算法均用Java实现,运行于Intel(R) i5 2.30 GHz CPU处理器、4 GB内存的Windows 8计算机上。实验将本文提出的ORQN算法在两个数据集上进行对比。并对Avqt算法中的各参数和影响因素进行分析。 图7对比展示了Avqt算法在两个真实数据集上的算法的查询平均处理时间。由图7可知,Avqt算法在两个数据集上的平均处理时间相差不大,表明Avqt的算法性能较稳定,受不同区域情况的影响很小。由于Avqt在查询的过程中采用自适应虚拟四分树,将不满足查询的区域直接剪枝。且Avqt算法运用倒排线性四分树存储每个关键字的权重,查询过程中只需访问查询关键词对应的几棵线性四分树,极大地减少了计算的次数,提高了算法的效率。 图7 不同数据集上的算法性能 图8对比展示了查询平均处理时间在不同查询返回结果个数k下的变化。ALA和ANYC分别表示Avqt算法在LA数据集和NYC数据集下不同查询返回的结果个数k下所产生的平均响应时间的变化。由图8可以看出,Avqt算法的性能在两个数据集上均随着查询返回结果的个数的增加而相应的降低。这是由于查询返回的结果个数增加了查询的范围所导致的。 图8 不同查询结果数下的算法效率 图9对比展示了查询平均处理时间在不同查询关键词数l下的变化。Avqt算法在两个数据集上的平均查询处理时间均随着查询关键词个数的增加而增加,而增加幅度在逐渐降低,这是由于Avqt算法的剪枝能力均随着查询关键字个数的增加而不断地增强。 图9 不同数量查询关键词下的算法效率 图10对比展示了Avqt算法的查询平均处理时间在不同数据集大小下的变化。由图10可以看出,Avqt算法的性能随着数据集数量的增加而有所下降,这是由于随着数据集的增大,区域中空间文本对象的密度也在不断增大,造成了在查询的过程中自适应虚拟四分树须更多的访问区域下的对象。但图中两条线整体上比较稳定,说明Avqt算法能较好地适应较大的数据集。 图10 不同大小的数据集下的算法效率 图11对比展示了查询平均处理时间在不同参数α值下的变化。其中α为一个可调节参数,用来调节查询时对空间距离和文本相似程度的重要性的比例关系。由图11可以看出,当参数α在0.3附近时算法在两个数据集上的平均处理时间相差很小且曲线波动较小,此时算法性能较稳定。因此,本文将α等于0.3设置为默认参数值,以保证算法的稳定运行。 图11 不同参数值下算法的效率 随着移动互联网的高速发展和移动定位设备的广泛普及,基于位置的地理信息服务逐渐渗透进人们生活的方方面面。随之而来的空间关键词的查询研究成为位置服务领域研究的热点。如何在保证查询准确性的前提下,不断高效快速地满足用户的实际查询需求成为该研究面临的主要挑战。本文研究了基于自适应虚拟四分树高效Top-k空间关键词查询技术。综合考虑实际生活中用户的个性化的查询需求,实现高效快速地返回用户的查询结果,并通过大量的实验证明了所提算法的有效性和稳定性。未来考虑将此技术扩展到路网的研究中。
3.2 Avqt 部分匹配查询算法

4 实 验





5 结 语
猜你喜欢
电子制作(2022年1期)2022-01-28
中等数学(2021年9期)2021-11-22
电子制作(2021年14期)2021-08-21
河北画报(2020年8期)2020-10-27
密码学报(2019年3期)2019-07-16
卷宗(2018年14期)2018-06-29
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
俄罗斯问题研究(2013年1期)2013-03-11
